
Abstract
Recently, many Convolutional Neural Network (CNN) algorithms have been proposed for image super-resolution, but most of them aim at architecture or natural scene images. In this paper, we propose a new fractal residual network model for face image super-resolution, which is very useful in the domain of surveillance and security. The architecture of the proposed model is composed of multi-branches. Each branch is incrementally cascaded with multiple self-similar residual blocks, which makes the branch appears as a fractal structure. Such a structure makes it possible to learn both global residual and local residual sufficiently. We propose a multi-scale progressive training strategy to enlarge the image size and make the training feasible. We propose to combine the loss of face attributes and face structure to refine the super-resolution results. Meanwhile, adversarial training is introduced to generate details. The results of our proposed model outperform other benchmark methods in qualitative and quantitative analysis.
The work is supported by the National Natural Science Foundation of China under Grant No.: 61976132 and the National Natural Science Foundation of Shanghai under Grant No.: 19ZR1419200.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Human faces play an essential role in our social life. Face analysis has been widely used in related fields such as online transactions, face unlocking, and mobile payment. However, due to the diversity of the way to collect face image, many factors such as deformation, blur, and noise are often encountered in imaging, resulting in quality degraded face images. In order to achieve the necessary quality requirements of face analysis applications such as criminal investigation in security [1], face super-resolution technology is particularly important to improve resolution, sharpness, and information content for face images.

Illustration of the fractal residual block structure.
The previous studies [2, 3] only used the deep learning based method to reconstruct the low resolution face images, but the facial details were ignored, resulting the disappear of the face details. Other researches [4, 5] only used one single prior knowledge of the face for image reconstruction. The previous studies only use a specific magnification for training, and some important information was often lost.
In order to create a more realistic face reconstruction, it is essential to incorporate both local and global information. Inspired by the self-similarity of the fractal structure, we innovatively propose a new network cell, called fractal residual block (FRB) structure, as shown in Fig. 1. The general residual blocks are nested into a self-similar fractal structure. Such a structure makes it possible to integrate image details in multiple layers. Using the proposed fractal residual block as the basic modules, we propose a new face super-resolution model named Fractal-SRGAN, as shown in Fig. 2. The proposed fractal residual block can incorporate information on multiple resolutions and annotate the prior structure of face appearance. It is often difficult to learn large scale super-resolution mapping directly by a single step. In order to improve the training efficiency and reduce the training difficulty of the model, inspired by the work of LapSRN [6], we introduce the Laplace pyramid into the model. The implementation of Fractal-SRGAN involves adversarial learning to enhance the reconstruction and progressive generation mechanism to improve training efficiency. We carried out verification experiments on benchmark face datasets. The experimental results show that the proposed model has an excellent performance in the face image super-resolution task. Extension tests on the Mini-ImageNet dataset also validate the effectiveness of the proposed model.
The major contributions of our work are summarized as follows.
-
We creatively propose the fractal residual block, which serves to integrate both local and global information in more sufficient layers of details.
-
We actively introduce the priori knowledge of face structure and facial attributes by introducing the face structure loss and the face attribute loss, which assists the model to generate more accurate results.
-
In the process of model training, we introduce the Laplacian pyramid and adopt progressive training to improve the training efficiency.
2 Related Work
Generally, face image super-resolution refers to the process of recovering high-resolution face images from low-resolution face images. The research on face image super-resolution can be classified as three types, i.e., interpolation-based methods [7,8,9], reconstruction-based method [10,11,12] and learning-based methods [3, 4, 13, 14]. The previous two types of methods are usually hard to adapt to large amplification coefficients [15], while the learning-based methods are promising in handling various amplification coefficients.
Compared with the traditional learning-based methods, deep learning methods have distinct advantages in the reconstruction results and efficiency, and various CNN models have been designed to tackle super-resolution problems. Recently, Dong et al. [2] proposed the SRCNN to introduce the convolutional neural network (CNN) for super-resolution reconstruction. Kim et al. [4] proposed VDSR to emphasize the reconstruction residuals between low-resolution images and high-resolution images. Legid et al. [3] propose the SRGAN that utilize adversarial learning to generate details and avoid image flatness in super-resolution.
To generalized the learning-based super-resolution method for face images, a promising direction is to combine the prior information such as the edge loss or the artifacts of face appearance. Yang et al. [5] designed a face super-resolution algorithm based on edge priori information enhancement. Lim et al. [14] proposed the EDSR model on a modified SRResNet architecture and obtained improved PSNR results. Chen et al. [13] proposed to use facial structure prior information to assist facial image super-resolution.
3 Method
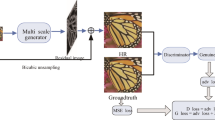
Our super-resolution network is essentially a generative adversarial network. It contains two main structures: a generator and a discriminator. In the generator, the input image firstly goes through several FRB modules to extract the feature maps, then goes through an upsampling layer to get a super-resolution result. Several combinations of such FRBs-upsampling form our progressive learning network. Furthermore, our FRB module can adopt the principle of self-similarity to get the image feature information of the previous network layer. Using the FRB module makes it possible for our model to complete the task of image super-resolution with higher magnification. In the discriminator, we add the face attribute and face structure feature to obtain more detailed facial reconstruction results.

The framework of the proposed FractalSRGAN model. The LR images firstly go through several FRB modules, then LR images are upsampled by the pixelShuffle module. Through this progressive training, our model generates more accurate SR images. The generated SR images and the HR images pass through the discriminator network to evaluate the quality of the generated SR images.
3.1 Fractal Residual Block
High-resolution images and low-resolution images have structural similarities in features. To utilize such information, we design the fractal residual block. An implementation instance is illustrated in Fig. 3. The feedforward calculation of the FRB module can be mathematically computed according to Eq. (1).
where x and y are the input \(FB_{n-1}\) and output \(FB_n\), and the function C(x) represents a convolution function.
Residual networks can effectively lighten the difficulty of training in deep neural networks through global residual learning, so we also use the global residual learning module in our network branch. Besides, deep networks with too many layers may experience performance degradation issues. The reason may be that many image details are lost after so many layers. In order to solve this problem, we introduce an enhanced residual unit structure called multipath local residual learning module, where the identity branch not only delivers rich image detail to the subsequent network layer but also help with gradient flow. The main difference between global residual learning module and local residual learning module is that the local residual learning module executes in the layer of each branch, while the global residual learning module performs between the input and output images, the fractal residual block has multiple local residual learning modules but only one global residual learning module.
As is shown in the Fig. 3, where \(F_1(x)\) is the local residual learning module of \(F_2(x)\) and \(F_2(x)\) is the local residual learning module of \(F_3(x)\), And so on. The fractal residual block used in Fig. 2 is the structure of \(F_3(x)\). So we called the model FractalSRGAN, our method without adversarial loss is so called FractalSRNet.

Implementation instance of the fractal residual block.
3.2 Generator Network
Compared with those direct reconstruction methods, progressive methods can provide better quality for higher magnification factors and lower parameters by sharing information between each super-resolution branch. As is shown in the top half of the Fig. 2, our generator network is a progressive structure, with each layer consisting of three fractal residual blocks and one deconvolution layer.
3.3 Discriminator Network
As is shown in the lower part of the Fig. 2, unlike the previous face super-resolution [13], in order to force the super-resolution network to encode the face attribute information, we add the face attribute and face structure feature to the discriminator network. The discriminator judges the picture true and false, at the same time, can distinguish the input face image, whether a new generated picture or an original photo. Provide face attribute constraint information for super-resolution results to improve the quality of super-resolution images.
3.4 Training Objective
In order to preserve the input picture’s face structure and property, our object function combines reconstruction loss \(L_{rec}\), perceptual loss \(L_{per}\), face structure loss \(L_{fan}\), face attribute loss \(L_{attr}\) and adversarial loss \(L_{adv}\).
Reconstruction Loss: Since the upsampled HR image’s content should be similar to the input LR image’s content, we use the Euclidean distance to force this similarity, and the reconstruction loss can be mathematically computed according to Eq. (2).
where \(I_s\) = \(G(I_l)\) is the super-resolution result, G is the super-resolution network, and \(I_h\) is the target image, \(I_l\) is the input low resolution image.
Perceptual Loss: We use the perceptual loss function instead of the mean square error because the perceptual loss function can obtain more detailed for the super-resolution results. Here we use the high-level feature map of the pre-trained VGG-16 network on the ImageNet dataset to help evaluate perceptually relevant features. The perceptual loss can be mathematically computed according to Eq. (3).
where \(\phi _{vgg}\) is the VGG-16 network pre-trained on the ImageNet.
Face Structure Loss: To constrain the spatial relationship between the face component and its visibility, we use a face alignment network to constrain the face component. The face structure loss can be mathematically computed according to Eq. (4).
where \(\phi _{fan}\) is the face alignment network FAN [16].
Face Attribute Loss: Each low-resolution facial image may be mapped to many high-resolution facial pictures in the process of high resolution. In order to reduce the ambiguity in the super-resolution process, we propose the face attribute constraint. The face attribute loss can be mathematically computed according to Eq. (5).
where \(a_{h}^{(i)}\) represents the i-th attribute in the N-dimensional face attribute vector of the target image and the \(a_{s}^{(i)}\) represents the i-th face attribute prediction probability result of the super-resolution image.
Adversarial Loss: GAN exhibits tremendous power in image super-resolution tasks [3], which produces realistic images with better visual effects than depth models based on pixel-by-pixel reconstruction loss. The main idea is to use a discriminant network to distinguish between super-resolution images and real high-resolution images. The adversarial loss can be mathematically computed according to Eq. (6).
where D represents the discriminator network.
Our model performs end-to-end training through the above equations. The final loss function can be mathematically computed according to Eq. (7).
where \(\lambda \) is the different parameters between different loss terms.
4 Experiments
4.1 Datasets
We perform face super-resolution experiments on two commonly used human face datasets: the Helen dataset [17] and the CelebA dataset [18], and one sub-dataset of ImageNet named Mini-ImageNet [19]. There are 202,599 individuals in CelebA and 2,330 individuals in Helen, while in the Mini-ImageNet, there are 60, 000 colour images with 100 classes, each having 600 examples. During the training phase, we follow the standard protocol, use CelebA’s large training set (162,770 images) for training, and using CelebA’s validation set (19,867 images) for verification. In the testing phase, we evaluate 19,962 test set images in the CelebA dataset, and Helen’s 330 test set images and Mini-ImageNet’s 12000 test set to ensure that there were no overlapping images during the training and testing phases.
4.2 Parameter Setting
Model Parameter. The model is trained by the Adam optimizer, setting the initial learning rate to 0.0002, and we empirically set the two parameters of the Adam optimizer \(\beta _1\) = 0.9, \(\beta _2\) = 0.999. The batch size is set to 32 due to memory limitations. As for the coefficient of the loss function, we choose as follows: \(\lambda _{per}=0.005\), \(\lambda _{fan}=0.003\), \(\lambda _{attr}=0.003\), \(\lambda _{adv}=0.003\). In the progressive training phase, we use three FRB modules in front of each PixelShuffle layer, and each such structure was able to carry out a super-resolution image with double amplification. Finally, we conduct our experiment with a factor of 8 magnification.
Training Settings. We take a 134 by 134 pixel size face area in the center of the image and adjust it to 128 by 128 using the bicubic interpolation without any pre-alignment. The bicubic interpolation method is also used to obtain a 16 \(\times \) 16 pixel size low-resolution image as input. The output image size of all methods is 128 by 128 pixel size.
Data enhancement. Data enhancement is a crucial way to generate sufficient training samples and improve the generalization capabilities of the model. We roughly crop the training image based on their facial area. We amplify the training set by randomly cropping the image and flipping it horizontally.

Qualitative comparison with the most advanced super-resolution methods. The first 3 samples are from the CelebA dataset and the last sample is from the Helen dataset. Super resolution scale factor is 8.
We compare the proposed method with several other mainstream super-resolution methods, including the face super-resolution algorithm FSRNet [13], PFSR [20] and SRFBN [21]. For a fair comparison, we reproduce the above algorithm and train the above model using the same training data. For all of the above methods, we use the default parameters provided by the author for training and prediction. We use an eight super-resolution scale factor to compare our algorithms with others.
4.3 Qualitative Comparison
As is shown in Fig. 4, the first three samples are from the CelebA dataset, and the last one is from the Helen dataset. The super-resolution results of the algorithms above on the CelebA and Helen datasets are shown.
It can be observed that the FSRNet [13] algorithm cannot fully generate real facial details, and the super-resolution face is still blurred, just better than the bicubic interpolation. SRFBN [21] can super-resolution images directly with an eight magnification factor and enhance face detail by feedback learning. Our methods (the FractalSRNet and the FractalSRGAN) and PFSR [20] both reconstructed the facial details, showing that the face image prior information helps to improve the texture information of the restored image further. Super-resolution results after using adversarial loss are more realistic and closer to natural images.
4.4 Quantitative Analysis
We quantitatively evaluate the performance of all methods across the entire test data set, employing average PSNR, SSIM, and FID scores.
Table 1 show that our approach achieves superior performance compared to other methods, and our super-resolution approach surpasses the most advanced face super-resolution methods in PSNR, SSIM, and FID standards. On the CelebA dataset, the PSNR value is increased by 1.18 dB, and the SSIM value is increased by 0.049, and the FID score is increased by 14.5 over the PFSR [20] method. On Helen dataset, our PSNR results outperformed the PFSR method by 0.95 dB, and the SSIM value increased by 0.043, and the FID score is increased by 17.04. On the Mini-ImageNet dataset, our PSNR results outperformed the second-best method by 0.9 dB, and the SSIM value increased by 0.0933, and the FID score is increased by 28.26.
4.5 Ablation Study
In order to illustrate the performance of each part of the proposed fractal residual block, we implement ablation study by using the \(f_1(x)\) structure, \(f_2(x)\) structure and \(f_3(x)\) structure shown in Fig. 1 as the FRB module respectively for experimental comparison. In addition, we also carry out experiments on the model without using the residual block and gave the experimental results. From the evaluation scores in Table 2, we prove that using the \(f_3(x)\) struct as the residual block serves to improve the performance of the model noticeably.

The result of user study to compare the performance results of the two proposed methods, the FractalSRNet and the FractalSRGAN, from the perspective of human eyes. We invited 6 participants, denoted as S1, S2,..., S6, and each performed 50 experiments. The horizontal axis represents the label of participants in the experiment, and the vertical axis represents the percentage of the better results between the two compared algorithms chosen by each participant.
4.6 User Study
Evaluating the model based on PSNR and SSIM may cause the model to lose the necessary high-frequency information, making the final result too smooth. Because the evaluation indicators are sometimes inconsistent with the subjective evaluation of human observers, we design a user study to compare and evaluate the FractalSRNet and FractalSRGAN methods. We invite six volunteers to participate in our experiment. The experiment is done as follows: we use the trained model to generate the super-resolution image using the CelebA dataset. Each participant selects the best image from two randomly selected models at a time, and each participant performs 50 experiments, totaling 300 samples. As can be seen from Fig. 5, the image generated by FractalSRGAN using adversarial loss is better in most samples. Although the use of adversarial loss reduces the PSNR and SSIM measures, it improves the super-resolution similarity.
5 Conclusion
We propose a super-resolution algorithm based on the Generative Adversarial Network combined with face attribute information and face structure information to parse tiny low-resolution face images. We not only use image pixel-level and feature-level similarity constraints but also use facial structure information and face attribute information estimated by LR input images. Combined with the pyramid network structure, it can generate more accurate multi-scale high-resolution images, surpassing existing models, and achieving better performance. For future work, we plan to use more prior knowledge, such as face segmentation feature maps, for better performance.
References
Nasrollahi, K., Moeslund, T.B.: Super-resolution: a comprehensive survey. Mach. Vis. Appl. 25(6), 1423–1468 (2014). https://doi.org/10.1007/s00138-014-0623-4
Chao, D., Chen, C.L., Kaiming, H., Xiaoou, T.: Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 38(2), 295–307 (2015)
Christian, L., et al.: Photo-realistic single image super-resolution using a generative adversarial network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4681–4690 (2017)
Jiwon, K., Jung, K.L., Kyoung, M.L.: Accurate image super-resolution using very deep convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1646–1654 (2016)
Yang, W., et al.: Deep edge guided recurrent residual learning for image super-resolution. IEEE Trans. Image Process. 26(12), 5895–5907 (2017)
Wei-Sheng, L., Jia-Bin, H., Narendra, A., Ming-Hsuan, Y.: Deep laplacian pyramid networks for fast and accurate super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 624–632 (2017)
Duchon, C.E.: Lanczos filtering in one and two dimensions. J. Appl. Meteor. 18(8), 1016–1022 (1979)
Zhang, L., Xiaolin, W.: An edge-guided image interpolation algorithm via directional filtering and data fusion. IEEE Trans. Image Process. 15(8), 2226–2238 (2006)
Kim, K.I., Kwon, Y.: Single-image super-resolution using sparse regression and natural image prior. IEEE Trans. Pattern Anal. Mach. Intell. 32(6), 1127–1133 (2010)
Elad, M., Feuer, A.: Restoration of a single superresolution image from several blurred, noisy, and undersampled measured images. IEEE Trans. Image Process. 6(12), 1646–1658 (1997)
Hu, H., Lisimachos, P.K.: An image super-resolution algorithm for different error levels per frame. IEEE Trans. Image Process. 15(3), 592–603 (2006)
Zhang, K., Gao, X., Tao, D., Li, X.: Single image super-resolution with non-local means and steering kernel regression. IEEE Trans. Image Process. 21(11), 4544–4556 (2012)
Yu, C., Ying, T., Xiaoming, L., Chunhua, S., Jian, Y.: FSRNET: end-to-end learning face super-resolution with facial priors. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2492–2501 (2018)
Bee, L., Sanghyun, S., Heewon, K., Seungjun, N., Kyoung, M.L.: Enhanced deep residual networks for single image super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 136–144 (2017)
Baker, S., Kanade, T.: Limits on super-resolution and how to break them. IEEE Trans. Pattern Anal. Mach. Intell. 9, 1167–1183 (2002)
Adrian, B., Georgios, T.: Super-fan: integrated facial landmark localization and super-resolution of real-world low resolution faces in arbitrary poses with gans. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 109–117 (2018)
Le, V., Brandt, J., Lin, Z., Bourdev, L., Huang, T.S.: Interactive facial feature localization. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds.) ECCV 2012. LNCS, vol. 7574, pp. 679–692. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-33712-3_49
Ziwei, L., Ping, L., Xiaogang, W., Xiaoou, T.: Deep learning face attributes in the wild. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 3730–3738 (2015)
Oriol , V., et al.: Matching networks for one shot learning. In: Advances in Neural Information Processing Systems, pp. 3630–3638 (2016)
Deokyun, K., Minseon, K., Gihyun, K., Dae-Shik, K.: Progressive face super-resolution via attention to facial landmark. arXiv preprint arXiv:1908.08239 (2019)
Zhen, L., Jinglei, Y., Zheng, L., Xiaomin, Y., Gwanggil, J., Wei, W.: Feedback network for image super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3867–3876 (2019)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Fang, Y., Ran, Q., Li, Y. (2020). Fractal Residual Network for Face Image Super-Resolution. In: Farkaš, I., Masulli, P., Wermter, S. (eds) Artificial Neural Networks and Machine Learning – ICANN 2020. ICANN 2020. Lecture Notes in Computer Science(), vol 12396. Springer, Cham. https://doi.org/10.1007/978-3-030-61609-0_2
Download citation
DOI: https://doi.org/10.1007/978-3-030-61609-0_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-61608-3
Online ISBN: 978-3-030-61609-0
eBook Packages: Computer ScienceComputer Science (R0)