
Abstract
Elastography ultrasound (EUS) provides additional bio-mechanical information about lesion for B-mode ultrasound (BUS) in the diagnosis of breast cancers. However, joint utilization of both BUS and EUS is not popular due to the lack of EUS devices in rural hospitals, which arouses a novel modality imbalance problem in computer-aided diagnosis (CAD) for breast cancers. Current transfer learning (TL) pay little attention to this special issue of clinical modality imbalance, that is, the source domain (EUS modality) has fewer labeled samples than those in the target domain (BUS modality). Moreover, these TL methods cannot fully use the label information to explore the intrinsic relation between two modalities and then guide the promoted knowledge transfer. To this end, we propose a novel doubly supervised TL network (DDSTN) that integrates the Learning Using Privileged Information (LUPI) paradigm and the Maximum Mean Discrepancy (MMD) criterion into a unified deep TL framework. The proposed algorithm can not only make full use of the shared labels to effectively guide knowledge transfer by LUPI paradigm, but also perform additional supervised transfer between unpaired data. We further introduce the MMD criterion to enhance the knowledge transfer. The experimental results on the breast ultrasound dataset indicate that the proposed DDSTN outperforms all the compared state-of-the-art algorithms for the BUS-based CAD.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Ultrasound imaging
- Breast cancer
- Deep doubly supervised transfer learning
- Support vector machine plus
- Maximum mean discrepancy
1 Introduction
B-mode ultrasound (BUS) is a clinical routine imaging tool to diagnose breast cancers. With the fast development of artificial intelligence technology, the BUS-based computer-aided diagnosis (CAD) has attracted considerable attention in recent years [1]. However, BUS only provides diagnostic information related to the lesion structure and internal echogenicity, which limits the performance of CAD to a certain extent.
Elastography ultrasound (EUS) imaging has emerged as an effective imaging technology for the diagnosis of breast cancers, which shows information pertaining to the biomechanical and functional properties of a lesion [2]. Joint utilization of both BUS and EUS provides complementary information for breast cancers to promote diagnostic accuracy [3]. However, the EUS devices are generally scarce in rural hospitals, which makes EUS not popular in diagnosing breast cancers in clinical practice.
Transfer learning (TL) aims to improve a learning model in the target domain by transferring knowledge from the related source domains [4, 5]. TL has achieved great success in various classification tasks, including CAD [6, 7]. Therefore, the performance of a single-modal imaging-based CAD model can be effectively promoted by transferring knowledge from other related imaging modalities or diseases [6].
It is worth noting that modality imbalance is a common phenomenon in clinical practice. That is, there are not only some paired BUS and EUS images with shared labels but also additional single-modal labeled BUS images in this work. Therefore, the source domain (EUS modality) has fewer samples than those in the target domain (BUS modality) in our work, which is contrary to the conventional TL applications. The inadequate data in the source domain also increase the difficulty for TL since it cannot provide enough supervision for TL. The conventional TL methods can handle this transfer task by performing the feature- or classifier-level transfer [4, 6, 8, 9]. However, these TL methods have no constraints on the labels of both the source and target domains, and therefore cannot fully use the label information to explore the intrinsic relation between two modalities and then guide the promoted knowledge transfer.
Learning using privileged information (LUPI) is a newly proposed TL paradigm developed on the paired data in source and target domains with shared labels [10]. Support vector machine plus (SVM+) is a typical classifier under the LUPI paradigm, which generally outperforms the conventional TL classifiers due to the supervision of the shared labels [10]. However, SVM+ cannot conduct TL for unpaired or imbalanced data also due to the limitation of the LUPI paradigm.
On the other hand, convolutional neural network (CNN) based TL methods generally achieve superior performance to the conventional TL approaches in many classification tasks [5]. Although the source domain generally includes a large number of labeled data while the target domain only has a few labeled data, most of these works focus on the knowledge transfer between unpaired data in an unsupervised way[11].
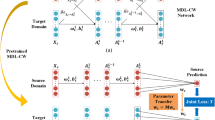
Therefore, it is necessary to develop a new TL paradigm that can effectively address the issue of TL for imbalanced medical modalities in a supervised way. To this end, we propose a novel deep doubly supervised transfer network (DDSTN) for the BUS-based CAD of breast cancers. As shown in Fig. 1, this new TL paradigm doubly transfers knowledge between both the paired and unpaired data between the source and target domains in a unified framework. Specifically, the SVM+ classifier performs the transfer for the paired ultrasound data with shared labels, while the two-channel CNNs conduct another supervised transfer for the unpaired labeled data by MMD criterion. The double transfer mechanism can effectively adopt both shared and unshared labels to mine the intrinsic transferred information, and then guide the knowledge transfer from the limited samples in the source domain.

Illustration of the proposed DDSTN paradigm.\( \left( {\varvec{X}_{s} ,Y^{p} } \right) \) and \( \left( {\varvec{X}_{t}^{p} ,Y^{p} } \right) \) denote the paired data with shared labels \( Y^{p} \) in the source domain \( {\mathcal{D}}_{s} \) and target domain \( {\mathcal{D}}_{t}^{p} \), respectively. \( \left( {\varvec{X}_{t}^{u} ,Y_{t}^{u} } \right) \) is the additional single-modal data in the target domain \( {\mathcal{D}}_{t}^{u} \).
The main contributions are twofold as follows:
-
1)
We propose a new doubly supervised TL paradigm to address the issue of TL for imbalanced modalities with labeled data, which can not only make full use of the shared labels to effectively guide knowledge transfer, but also perform additional information transfer between unpaired data. Therefore, more transferred knowledge promotes the classification performance.
-
2)
We develop a novel DDSTN algorithm to perform the doubly supervised TL from fewer EUS samples in the source domain to the BUS-based CAD for breast cancers. Specifically, DDSTN integrates the SVM+ paradigm for the TL of paired data and the deep TL network for transfer between the unpaired data into a unified framework. The experimental results show its effectiveness on the BUS-based CAD for breast cancers.
2 Method
2.1 Network Architecture of DDSTN
Figure 2 shows the flowchart of our proposed DDSTN, which consists of two components, namely, LUPI-based supervised TL module for paired data and MMD-based supervised TL module for unpaired data. There are two independent CNNs for the source and target domains, respectively, which mainly learn feature representation, and also perform knowledge transfer for both paired and unpaired data.

The network architecture of proposed DDSTN. SD and TD denote the source domain and the target domain, respectively. The black dotted box represents the loss of LUPI, and the light green dotted box represents the supervised MMD criterion. (Color figure online)
In this work, BUS and EUS imaging work as target domain and source domain, respectively. We define \( \left( {\varvec{X}_{s} ,Y^{p} } \right) \) and \( \left( {\varvec{X}_{t}^{p} ,Y^{p} } \right) \) to be the paired data with shared labels \( Y^{p} \) in the source domain \( {\mathcal{D}}_{s} \) and target domain \( {\mathcal{D}}_{t}^{p} \), respectively, and \( \left( {\varvec{X}_{t}^{u} ,Y_{t}^{u} } \right) \) is the additional single-modal data in the target domain \( {\mathcal{D}}_{t}^{u} \). The superscript \( p \) and \( u \) denote paired and unpaired, the subscript \( s \) and \( t \) mean the source and target domain.
The LUPI-based supervised TL module performs knowledge transfer under the guidance of shared labels to promote the classifier in the target domain. As shown in Fig. 2, the loss function of LUPI contains coupled SVM+ loss. We optimize both the two-channel networks simultaneously with this coupled loss.
The MMD-based supervised TL module shares the same network with the LUPI-based supervised TL module. We integrate the MMD learning criterion and hinge loss into a uniform supervised architecture. MMD is used to minimize the distribution imparity between two domains, and the hinge loss in SVM can help to learn a strong classifier. Since we introduce the label information, the unpaired data can be trained in a supervised way. Moreover, it is worth noting that the hinge loss is just the same as the LUPI-based supervised TL module.
In the training phase, the source and target networks are optimized under an overall objective function, while in the testing phase, only the learned target networks (BUS modality network) is used to predict the results.
2.2 Doubly Supervised Transfer Learning
We propose a doubly supervised transfer strategy to perform knowledge transfer across the imbalance modality. The overall object function incorporates two loss parts for transferring the paired and unpaired data, respectively, into the following formula:
where \( {\mathcal{L}}_{paired} \) is the LUPI paradigm for the TL of paired data and \( {\mathcal{L}}_{unpaired} \) is the MMD learning criterion for the TL of unpaired data.
LUPI Paradigm for TL of Paired Data.
The LUPI paradigm is adopted to perform transfer for the paired data with shared labels [10]. Here, the typical SVM+ classifier is used with the objective function as following:
where \( y_{i} \, \in \,Y^{p} \), \( \left\{ {\varvec{W}_{t} ,\,\varvec{W}_{s} } \right\}\varvec{ } \) and \( \left\{ {\varvec{b}_{t} ,\,\varvec{b}_{s} } \right\} \) denote the weight matrices and bias vectors of the last layer in both target and source domains, respectively. \( \lambda_{1} \, > \,0 \) is a hyperparameter that restricts the correcting capacity, \( C_{1} \, > \,0 \) is a coefficient that balances the hinge loss term and the regularization term,\( n^{p} \) is the number of paired data, and \( \left\| \cdot \right\| \) denotes the L2-norm of the weight matrix.
As shown in Fig. 2, the LUPI paradigm for the paired data has a coupled loss for two domains. Thus, EUS and BUS modalities are alternately taken as the source domain data to perform TL to improve the network of the target domain.
MMD Criterion for TL of Unpaired Data.
To conduct knowledge transfer between unpaired data, MMD is introduced to minimize the distribution imparity between two domains. By considering labels as the supervision to further improve the learning performance of the classifier, we design a new loss function for unpaired data:
where \( \varvec{x}_{{s_{k} }} \, \in \,\varvec{X}_{s} \), \( \varvec{x}_{{t_{j} }}^{u} \, \in \,\varvec{X}_{t}^{u} \), \( y_{{t_{j} }}^{u} \, \in \,Y_{t}^{u} \), \( \lambda_{2} \) is non-negative hyperparameter of MMD. \( \phi \left( \cdot \right) \) is a feature mapping function, we aim to find an optimal \( \phi \left( \cdot \right) \) that can train a robust classifier, \( n_{t}^{u} ,\,n_{s}^{u} \) are the number of BUS imaging and EUS imaging, respectively.
In order to minimize Eq. (3), we perform the domain adaption on the penultimate layer to transfer the knowledge from the source domain to the target domain for the unpaired features [14]. The supervised domain fusion loss makes the domains indistinguishable in the process of representation learning.
Doubly Supervised TL Strategy.
The final objective function for doubly supervised TL is formulated by combining the \( {\mathcal{L}}_{paired} \) and \( {\mathcal{L}}_{unpaired} \) as following:
where \( C_{1} \) and \( C_{2} \) are non-negative constants of LUPI paradigm and distance metric loss, respectively, \( \lambda_{1} \) restrict the correcting capacity of the classifier, and \( \lambda_{2} \) is non-negative hyperparameter of MMD.
The overall objective function is optimized by stochastic gradient descent [12]. As shown in Fig. 2, only the learned target domain network is used to predict the results. The objective function is given by:
where \( \varvec{X}_{t} \, \subset \,\left\{ {\varvec{X}_{t}^{p} ,\,\varvec{X}_{t}^{u} } \right\}, \) \( \varvec{W} \) and \( \varvec{b} \) are the learned parameters in the training stage.
3 Experiments
3.1 Data Processing
We evaluated the proposed DDSTN algorithm on a bimodal breast ultrasound dataset sampled by one of the authors, in which 106 patients (54 benign tumors patients and 51 malignant cancer patients) have both BUS and EUS modalities, while the other 159 patients (81 benign tumors patients and 78 malignant cancer patients) only have BUS data. The approval from the ethics committee of the hospital was obtained, and all patients had signed informed consent.
The bimodal ultrasound images were acquired by the Mindray Resona7 ultrasound scanner with the L11-3 probe by an experienced sonologist. All the malignant cancers have been proved by the pathological diagnosis. A region of interest (ROI) including the lesion region was selected by an experienced sinologist from each ultrasound image. Noting that for the paired BUS and EUS images, only the ROI in BUS image was manually selected, and the same location of ROI was then automatically mapped to EUS imaging to obtain the ROI.
3.2 Experimental Setup
The proposed DDSTN was compared with the following related or state-of-the-art TL algorithms.
-
1)
CNN-SVM: CNN-SVM is a single-channel CNN which is compared as a baseline, we selected ResNet18 as the classification network for single-modality BUS and replace the softmax classifier with SVM.
-
2)
CNN-SVM+ [13]: CNN-SVM+ is another baseline which consists of two-channel CNNs and an SVM+ classifier. BUS is considered as the diagnostic modality, while EUS is the source domain.
-
3)
DDC [14]: DDC is a typical deep TL algorithm which uses the MMD criterion as the distribution distance metric.
-
4)
DAN [15]: Deep adaptation networks (DAN) is an improved DDC algorithm that replaces the MMD with multi-kernel MMD and then calculates the multiple layer losses.
-
5)
Deep CORAL [16]: Deep correlation alignment (Deep CORAL) is a deep TL algorithm based on correlation alignment, which learns a second-order feature transformation to minimize the feature distance between the source and the target domain.
The 3-fold cross-validation was adopted to evaluate all the algorithms. Specifically, the 106 paired data were always fixed as training data for the LUPI-based TL module, and the 159 additional BUS data were divided into three groups. We selected two of three groups of additional BUS data and all the EUS images from the 106 paired data to form another training set for the MMD-based TL module, while the remaining one BUS group was set as testing data. The experiment repeated three times. The final results were presented with the format of the mean ± SD (standard deviation).
The commonly used classification accuracy (ACC), sensitivity (SEN), specificity (SPE) and Youden index (YI) were selected evaluation indices. Moreover, the receiver operating characteristic (ROC) curve and the area under ROC curve (AUC) were also adopted for evaluation.
3.3 Experimental Results
Table 1 shows the classification results of different algorithms. It can be found that the proposed DDSTN outperforms all the compared algorithms with the best accuracy of 86.79 ± 1.54%, sensitivity of 86.45 ± 1.44%, specificity of 87.31 ± 4.37%, and YI of 73.77 ± 3.17%. DDSTN improves at least 1.92%, 2.04%, 0.4%, and 3.85% on accuracy, sensitivity, specificity and YI, respectively compared with other algorithms (Table 1).
The experiments show that CNN-SVM+ achieves superior performance to CNN-SVM, which indicates the effectiveness of transferring information from EUS for the BUS-based CAD by LUPI paradigm. It also can be found that DDSTN improves at least 1.94% on accuracy, 2.38% on sensitivity, 0.40% on specificity and 3.85% on YI compared with DDC, DAN and Deep CORAL, which indicates the effectiveness of our doubly supervised TL paradigm. Moreover, DDSTN improves 1.92%, 2.04%, 2.03%, and 4.08% on accuracy, sensitivity, specificity and YI, respectively, over CNN-SVM+ , suggesting the positive effect of TL between unpaired data for learning an effective classifier.
Figure 3 shows the ROC curves and the corresponding AUC values of different algorithms. DDSTN again achieves the best AUC value of 0.871, which improves at least 0.028 over all the other algorithms.

ROC curves of different algorithms with the corresponding AUC values.
4 Conclusion
In summary, we propose a novel doubly supervised TL paradigm to address the issue of TL between imbalanced modalities with labeled data. The proposed DDSTN algorithm effectively performs the double supervised transfer between both the paired data with shared labels by the SVM+ paradigm and the unpaired data with different labels by the MMD criterion in a unified framework. The experimental results indicate that DDSTN outperforms all the compared algorithms on the BUS-based CAD for breast cancers.
In current work, we adopt MMD as the distribution distance metric for TL, and therefore we select DDC, DAN and Deep CORAL for comparison, since all these algorithms are developed based on MMD or MMD related criterion. In our future work, we will further improve the doubly supervised transfer network by studying other TL methods instead of MMD. Moreover, we will try to integrate the advantages of adversarial domain adaption networks in this new doubly supervised TL paradigm.
References
Cheng, H.D., Shan, J., Ju, W., Guo, Y., et al.: Automated breast cancer detection and classification using ultrasound images: a survey. Pattern Recogn. 43(1), 299–317 (2010)
Sigrist, R.M., et al.: Ultrasound elastography: review of techniques and clinical applications. Theranostics 7(5), 1303–1329 (2017)
Ara, S.R., et al.: Bimodal multiparameter-based approach for benign–malignant classification of breast tumors. Ultrasound Med. Biol. 41(7), 2022–2038 (2015)
Pan, S.J., Yang, Q.: A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 22(10), 1345–1359 (2009)
Tan, C., et al.: A survey on deep transfer learning. In: ICANN, pp. 270–279 (2018)
Cheplygina, V., de Bruijne, M., Pluim, J.P.: Not-so-supervised: a survey of semi-supervised, multi-instance, and transfer learning in medical image analysis. Med. Image Anal. 54, 280–296 (2019)
Lu, S., Lu, Z., Zhang, Y.D.: Pathological brain detection based on AlexNet and transfer learning. J. Comput. Sci. 30, 41–47 (2019)
Zheng, X., Shi, J., Ying, S., Zhang, Q., Li, Y.: Improving single-modal neuroimaging based diagnosis of brain disorders via boosted privileged information learning framework. In: Wang, L., Adeli, E., Wang, Q., Shi, Y., Suk, H.-I. (eds.) MLMI 2016. LNCS, vol. 10019, pp. 95–103. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-47157-0_12
Zheng, X., et al.: Improving MRI-based diagnosis of Alzheimer’s disease via an ensemble privileged information learning algorithm. In: ISBI, pp. 456–459 (2017)
Vapnik, V., Vashist, A.: A new learning paradigm: learning using privileged information. Neural Netw. 22(5–6), 544–557 (2009)
Pan, S.J., Tsang, I.W., Kwok, J.T.: Domain adaptation via transfer component analysis. IEEE TNN 22(2), 199–210 (2011)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. In: ICLR (2015)
Li, W., Dai, D., Tan, M., et al.: Fast algorithms for linear and kernel SVM+ . In: CVPR, pp. 2258–2266 (2016)
Tzeng, E., et al.: Deep domain confusion: maximizing for domain invariance. arXiv preprint arXiv:1412.3474 (2014)
Long, M., et al.: Learning transferable features with deep adaptation networks. In: ICML, pp. 97–105 (2015)
Sun, B., Saenko, K.: Deep coral: correlation alignment for deep domain adaptation. In: ECCV, pp. 443–450 (2016)
Acknowledgements
This work is supported by the National Natural Science Foundation of China (81830058, 81627804), the Shanghai Science and Technology Foundation (17411953400, 18010500600), the 111 Project (D20031) and the Nanjing Science and Technology Commission (201803027).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Han, X., Wang, J., Zhou, W., Chang, C., Ying, S., Shi, J. (2020). Deep Doubly Supervised Transfer Network for Diagnosis of Breast Cancer with Imbalanced Ultrasound Imaging Modalities. In: Martel, A.L., et al. Medical Image Computing and Computer Assisted Intervention – MICCAI 2020. MICCAI 2020. Lecture Notes in Computer Science(), vol 12266. Springer, Cham. https://doi.org/10.1007/978-3-030-59725-2_14
Download citation
DOI: https://doi.org/10.1007/978-3-030-59725-2_14
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-59724-5
Online ISBN: 978-3-030-59725-2
eBook Packages: Computer ScienceComputer Science (R0)