
Abstract
In this paper, we examine the implications of the party cartel model of congressional policy making on the level of redistributional social welfare spending in the United States. The party cartel model predicts an inverse relationship between the level of spending on social welfare programs and median family income of the district that the median member of the majority party represents. Specifically, the higher the median district income of the median member of the majority party, the smaller the amount of social welfare spending Congress will allocate. To test this hypothesis, we estimate a random coefficients model using time series cross sectional data on congressional Budget Authorization for redistributional social welfare spending. We find that for each $1000 increase in median district income for the median member of the majority party, each redistributional Budget Authority sub-function decreases by an average of $489 million (for a total decrease of $3.91 billion overall). Therefore, the party cartel model appears to be a significant predictor of the level of income redistribution in the U.S.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others

7.1 Introduction
For this project, we combine the party cartel theory of congressional policy making Cox and McCubbins (2005) with Meltzer and Richard’s (1981) theory of income redistribution. We use a congressional district’s median income as a proxy for a member of Congress’ ideal point with respect to income redistribution, and we use redistributional categories of Federal Budget Authority as a measure of income redistribution. We find that for every $1000 increase in median district family income for the median member of the majority party, the level of income redistribution falls by $489 million.
This is the first research to directly examine the effect of the institutional rules of Congress on income redistribution. The traditional Meltzer and Richard model assumes a direct democracy median voter model of policy making. In creating such a parsimonious model, Meltzer and Richard may be making two errors. The first error is in their assumption of direct democracy. Voters do not vote directly on policy in the U.S. Instead, they vote for a representative who then votes on policy. Even if it is assumed that the representative from each congressional district represents the median voter from that district, and the median member of the legislature sets policy, there is no reason to believe that the policy that would be chosen by the median voter in the population will correspond to the policy enacted by the median member of the legislature. It is not always the case that the median of the median will be the median. In a related work, one of us finds that the degree to which congressional districts are gerrymandered with respect to income can cause the policy preferred by the median voter and the policy preferred by the median member of Congress to diverge (Ragan 2013).
The second area of concern with the Meltzer and Richard model is that most modern models of the U.S. congressional system do not simply assume the median member of Congress sees their ideal point become policy. Once one takes into account the institutional structure of Congress, the level of redistribution can depend crucially on intra-chamber and intra-branch dynamics. In order to incorporate these institutional features, we extend the Meltzer and Richard approach to modeling the “size of government.” In place of the direct democracy median voter as the policy maker, we substitute the party cartel model of congressional policy making.
The results may give us some insight into two puzzles in the political economy literature. The first is, “What accounts for the growth in the size of government in the United States?” Social welfare spending has risen from 4% of gross domestic product (GDP) in 1929 to 21% in 2002.Footnote 1 Researchers who have empirically tested Meltzer and Richard’s model have found mixed results. In Meltzer and Richard’s (1983) own test of their theory, they find that a 1% change in the ratio of mean to median income changes total redistribution by 1.5 billion dollars.Footnote 2 Gouveia and Masia (1998) tested an extended version of the Meltzer and Richard model using panel data from the 50 states, and they find that there is little evidence to support the predictions of the Meltzer and Richard model.Footnote 3 The second puzzle is,“Why do we see different patterns of redistribution in the United States versus other Western Democracies?” At a more practical level, this research may help us determine whether a common modeling simplification in political economy is really an oversimplification.
7.2 Literature Review
We draw upon two distinct literatures for this paper. The first is the political economy literature dealing with the “size of government.” The second is the congressional politics literature examining the influence of political parties on policy outcomes.
7.2.1 Rational Size of Government
The “size of government” literature is primarily concerned with explaining the growth in the size of federal spending. Researchers in this area typically investigate the growth of social welfare programs that redistribute income. These models contain a “Robin Hood” story of the poor using the ballot to take resources from the rich. The Meltzer and Richard (1981) “Rational Size” model uses a stylized model of policy formation in order to generate the level of redistribution in their theory. Their model uses a direct democracy framework in which voters express their preferences for redistribution directly by voting rather than through their vote for a representative. Voters’ preferences for redistribution are determined by their location in the income distribution. Voters who find themselves below the mean income prefer higher taxes and transfers to their end of the distribution. Conversely, voters who are above the mean income prefer lower taxes and transfers from their end of the distribution.Footnote 4 Income distributions are skewed to the right, and accordingly the median voter’s income is below the mean income. Meltzer and Richard use a straightforward application of Black’s median voter theorem 1948 and claim that we should expect to see relatively high levels of redistribution. This incentive to “soak the rich” is only tempered by the realization of the median voter that upper distribution voters will work less if taxes become too high, thereby reducing transfers. The prediction of the Meltzer and Richard model is that the greater the distance between the median and mean income, the greater the amount of redistribution. Acemoglu and Robinson (2005) find that greater inequality will usually lead to higher tax revenues. Bartels (2018) similarly finds that greater economic inequality results in more redistribution.
Some researchers have questioned the connection between income redistribution and inequality altogether. Roemer (2009) questions the positive relationship between income distribution and the tax rate. He finds that an increasing median income can actually lead to a decrease in the tax rate as elites use their political power to lower their tax rates. Kelly and Enns (2010) find results consistent with Benabou (1996), concluding that income inequality increases are self-reinforcing due to a conservative response from many voters resulting in less redistribution than would be expected in the Meltzer and Richard world. Pickering and Rockey (2011) find that Meltzer and Richard (1981, 1983) fail to account for the complexity of government. In a similar spirit to this chapter they modify the model to create a more institutionally informed model of public good preferences where it is the public’s ideology that determines the size of government. Noting that Meltzer and Richard’s (1981) model does not account for the large variance in redistribution across democratic governments, Iversen and Soskice (2006) transform redistributive policies into a multidimensional game that includes the electoral system. The electoral system in turn determines the number and strategies employed by political parties and governing coalitions. The resulting party structure is what directly affects the level of redistribution. McCarty et al. (2016) conclude that during the Great Recession in 2008–2009, the rise of income inequality in the U.S. did not increase the median income voter’s preference for redistribution.
The Meltzer and Richard model is still used in many models of income redistribution. For a survey of more current work on redistribution that uses similar policy models, see Persson and Tabellini (2000, ch. 6). There is a missing piece in this “size of government” puzzle, and it is that the process by which the preferences of voters become law is subject to highly partisan influences. The recent $819 billion “American Recovery and Reinvestment Act of 2009” passed the House without a single Republican voting in favor. The appropriations and budgeting process has become increasingly partisan, with many bills passing on party line votes (Schick and LoStracco 2000). The “size of government” literature black boxes the political process; however, in this paper, we seek to substitute a model of congressional politics for this black box.
7.2.2 Congressional Models and Policy Outcomes
Most researchers examining the implications of congressional policy models are primarily interested in comparing the predictive power of the several competing models of congressional politics. Aldrich (1995), Aldrich and Rohde (1998), Krehbiel (1998), Groseclose et al. (1999), Binder (1999), Brady and Volden (2005) and Cox and McCubbins (2005) all use various tests of some of the more indirect implications of models of congressional politics. There are, as of yet, only two papers that directly test the implications of models of congressional politics on actual policy outcomes. Aldrich et al. (2005) examine the predicted effect of each of the major models of congressional policy making on the appropriations process. They find (using the conditional party government model of Aldrich and Rohde (2001)) that the location of the median member of the majority party has a substantial impact on federal appropriations and that party influence alone accounts for $1.3 trillion in federal appropriations from 1969 to 1994. Anderson (2008) examines the effect of congressional politics on federal budget categories. She finds that none of the models of congressional politics can empirically demonstrate a link between members’ ideal points and policy outcomes.
7.3 Theory
In this paper, we replace the median voter of the population as the de facto policy setter in the Meltzer and Richard model with the median member of the majority party in Congress, based on the party cartel model of congressional policy making (Cox and McCubbins 1993, 2005). This theory includes the importance of agenda setting in congressional policy making. For a bill to reach the floor of the House, a majority of the majority party must allow it on the agenda. This means that the median member of the majority must consent, if a bill is to be considered by the entire House. The median member is able to exert “negative agenda control.” That is, he or she blocks any legislation from consideration by the floor that would make the majority party worse off if passed.
The party cartel model is single dimensional, and assumes that each policy is considered one issue at a time (Cox and McCubbins 2005, p. 38). The theory assumes that all bills that the median member of the majority party allows to reach the floor of the House will be considered under an open rule.Footnote 5 As such, all bills that reach the floor are amended to the ideal point of the median member of the house (F) and subsequently pass. Given this, the majority party must decide whether they prefer the status quo or the ideal point of the median member (F). In the party cartel model, the preference of the majority party is represented by the location of the median member of the majority party (M). There is a region of the policy space called the “blockout zone.” If the status quo policy for a particular issue falls within this region, then the majority party will block all legislation on that issue. The blockout zone consists of all alternatives falling between M and 2M-F.Footnote 6 The top portion (a) of Fig. 7.1 illustrates the blockout zone when M is to the right of F and the bottom portion (b) illustrates the blockout zone when M is to the left of F.

Examples of party cartel blockout zones
Cartel theory predicts that, (1) no issue on which the status quo is preferred to the floor median by the median of the majority party will be scheduled for a vote, and (2) no bill opposed by a majority of the majority party’s members ever passes. Hence, the median of the majority party must vote “yea” for a bill to pass.Footnote 7 Clearly, the location of the median member of the majority party (M) is an important determinant of policy outcomes. We will retain the assumption from Meltzer and Richard’s (1981) model that individuals vote based on their position in the income distribution. Further, We will assume that members of Congress reflect the preferences of the median voter in their district. These two assumptions are not all that far fetched. As it turns out, the income of the median voter in a district is a strong predictor of how a member votes on roll call votes (McCarty et al. 2006).
Given these assumptions, what does the party cartel theory predict regarding income redistribution? Unfortunately, as of yet there is no reliable way to map status quos and legislator ideal points into the same policy space.Footnote 8 Given this limitation, the location of the median member of the majority party is used as a proxy for the location of policy outcomes (Aldrich et al. 2005; Anderson 2008). Given this proxy, we put forth the following hypothesis: The higher the median district income of the median member of the majority party, the lower the level of income redistribution in the U.S.
7.4 Empirical Tests
The data set consists of yearly data from 1953 to 1998 (t) for eight Budget Authority categories (i). Picking an empirical specification for this sort of time-series cross-sectional data requires careful consideration. With longitudinal data where i is much larger than t, researchers typically use one of several well understood estimators like fixed effects, random effects or Arellano-Bond 1991. All of these techniques get their asymptotic properties (consistency) from their large cross section. Here, however, the cross sections are short (i = 8) and the time series are longer but not very long (t = 45). The cross-sections are far too short for any probability limits to be met, so these estimators could produce inconsistent estimates for this data set. Traditionally, researchers using the feasible generalized least squares model known as the Swamy-Hsiao method (Swamy 1968; Hsiao 2003). (Beck and Katz 2011, 2007; Beck 2008) find that the Swamy-Hsiao method has poor small sample properties, and they recommend the use of a random coefficient model (RCM) (Western 1998; Pinheiro and Bates 2000; Hsiao 2003) for time-series-cross-sectional data where the time dimension (t) is significantly larger than the cross sectional dimension (i).
The random coefficient model works well for situations in which each category of the cross-section is not identical, yet is not entirely unique. Using an estimator like ordinary least squares (OLS) individually on each category would likely lead to a consistent but inefficient estimate. Conversely, a fully pooled ordinary least squares regression would not be consistent but would be efficient.Footnote 9 The random coefficient model blends these two estimators using a weighted average. The technique shrinks back the estimates that would be found in a category by category OLS estimation toward the estimates that would be found in a fully pooled OLS estimation. The degree of the shrinkage is based on the amount of uncertainty in the estimates the random coefficient model makes. The more uncertain the estimates are, the more the random coefficient model shrinks the category-by-category (consistent, but inefficient) estimates back to the pooled (inconsistent but more efficient) estimates. This shrinking allows the RCM to find the best linear unbiased predictor for the data. Thus, in the class of E(β i) = β predictors, it has the lowest error loss. If the partial effects of the variables are different for each category of budget authority but not completely unrelated, then RCM will be an improvement (it will have lower RMSE) over category-by-category estimation or fully pooled models (Beck and Katz 2007). RCM will not find unit heterogeneity across the Budget Authority categories if it does not exist, and there is no danger in accidentally using it if heterogeneity is not present. The random coefficient model allows the data to tell us how heterogeneous the budget authority categories are rather than assuming it ex-ante. This heterogeneity is estimated as Γ in Eq. (7.1) and is a variance-covariance matrix between the βs from a category-by-category OLS estimation. It is estimated from the set of all positive definite matrices. RCM can also be thought of as a linear model like OLS, but with a complicated error term (Beck and Katz 2007).
Using a time series (1953–1998) of several categories of redistributional Budget Authority data and median district income as a proxy for members’ preference for redistribution, the following random coefficient model was estimated:
The dependent variable is the level of income redistribution. This is measured using federal Budget Authority data for eight Office of Budget and Management sub-functions. Budget Authority is the legal authority for Federal Agencies to make obligations that result in outlays. Three of the sub-functions—Unemployment CompensationFootnote 10, Food and Nutrition AssistanceFootnote 11, and Other Income SecurityFootnote 12—are mandatory spending categories. The level of spending for these sub-functions is governed by program law rather than the annual appropriations process. Changes in these programs generally redirect the slope of the trajectory of spending. The remaining five categories—Community DevelopmentFootnote 13, Regional DevelopmentFootnote 14, Training and EmploymentFootnote 15, Social ServicesFootnote 16 and Housing AssistanceFootnote 17—are all discretionary sub-functions. The level of spending in these categories is governed by the annual congressional appropriations process. Spending across these eight categories in a given year serves as the cross-sectional dimension of observation.Footnote 18 Figures 7.2 and 7.3 display the levels of spending for each of the Budget Authority Categories.

Budget authority for mandatory income redistribution sub-functions

Budget authority for discretionary income redistribution sub-functions
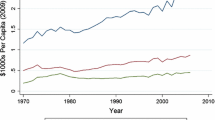
The main independent variable is the median district income of the median member of the majority party. This variable for each member of Congress is measured using the median family income of the member’s Congressional district.Footnote 19 In the Meltzer and Richard framework, the poorer voters are, the more redistribution they want. Our proxy takes this assumption and adds that members of Congress vote on redistribution policy in line with their district’s preference. McCarty et al. (2006) find that in terms of 1st dimension DW-NOMINATE scores,Footnote 20 “An increase in family income of two standard deviations is associated with a .225 shift to the right, larger than the shift associated with reducing the percentage of African Americans by the same two standard deviations.” A district’s median family income is strongly correlated with the way in which a member votes. It follows that members’ votes for redistribution would likely be highly correlated with district median family income. For years in which the Democrats held a majority in Congress, the median member of the majority party is the median Democrat in the chamber, and vice versa for years in which the Republicans held a majority in the House. In Fig. 7.4, the median family income for the median republican district is plotted with a red dotted line, and the median democrat district family income is plotted with a blue line. The solid black line indicates the median family income of the median district of the majority party. For all years in the data set, the median Republican district is consistently richer than the median Democratic district. The average difference between the median of the Republicans and the median of the Democrats ranges from $1157 to $3601, and the mean is $2198.

Location of the median member of the majority party with respect to median district family income
The first control variable is the population of the United States. As the population grows, the number of dollars allocated to income redistribution will rise. Second, the poverty rate of the United States is included.Footnote 21 As the poverty rate rises, the amount of income redistribution in mandatory redistribution will rise.Footnote 22 There may also be heightened pressure to increase Budget Authority for discretionary redistribution. A dummy variable is included for the mandatory Budget Authority categories. As mentioned before, the levels of Budget Authority in these categories are not directly set; rather, Congress sets the formula to determine who is eligible for the program. The Gross Domestic Product of the U.S. is included to control for the overall size of the economy. Finally, a lag of the dependent variable is included to control for serial correlation in Budget Authority across years.
7.4.1 Results
Recall that our main hypothesis is: The higher the median district income of the median member of the majority party, the lower the level of income redistribution in the U.S. This hypothesis was tested using the random coefficient model estimation from Eq. (7.1), and results are presented in Table 7.1.Footnote 23 We find that for each $1000 increase in the median district income of the median member of the majority party, the level of income redistribution falls by an average of $489 million for each Budget Authority category. This translates into a $3.91 billion overall decrease in total redistributional Budget Authority. A hypothetical switch in party control from the Republicans to the Democrats would result in a $1.07 billion decrease, on average, for each redistributional Budget Authority sub-function. The switch from the Democrats to the Republicans as the majority party in the House in 1994 resulted in a $4047.47 increase in the median district income of the median member of the majority party. The results here would predict a $1.95 billion decrease for each category, ceteris paribus.
7.4.2 Testing Meltzer and Richard
In order to examine the predictive power of the party cartel model with the traditional Meltzer and Richard theory, we estimate the same random coefficient model seen in Eq. (7.1), but replace the median family income of the median member of the majority party’s district with the distance between mean and median family income of the entire nation. Recall that Meltzer and Richard (1981) use Black’s (1948) median voter theorem as their policy making apparatus. Their prediction is: the greater the distance between the median and mean income, the greater the amount of redistribution. Figure 7.5 displays the difference between mean and median income for the years in the data set.

Difference between mean family income and median family income
To test Meltzer and Richard’s (1981) prediction, we estimate the following random coefficient model (Eq. (7.2)), with the:
The results are presented In Table 7.2, and we find that the difference between mean and median income is statistically significant, but the partial effect is the opposite of that predicted by Meltzer and Richard. For every $1000 that median and mean family income deviate, the level of redistribution falls by an average of − 2.74 billion dollars. This comports with the findings of Gouveia and Masia (1998), who find no evidence for the deviation of mean and median income affecting income redistribution at the state level.
7.5 Implications
In light of the failure of the traditional Meltzer and Richard (1981) model of income redistribution to stand up to empirical tests (Benabou 1996), we use this paper to explore the effects of Congressional politics on income redistribution. This is done by combining the party cartel theory of congressional policy making (Cox and McCubbins 2005) with the spirit of Meltzer and Richard’s model. Where Meltzer and Richard assume a direct democracy median voter model of policy making, we substitute the median member of the majority party in the U.S. House of Representatives. The location of the median member of the majority party appears to be more effective at accounting for the growth in the size of government in the United States than does the location of the median member of the population. Without a comparative data set, it would be premature to address the different patterns of redistribution seen in the U.S. versus other western democracies. The results do suggest, however, that the intricacies of a legislative system can have a real impact on policies such as income redistribution. The inclusion of Congress as the policy making procedure adds an important piece of the puzzle to the “size of government” literature. Researchers in political economy should strongly consider including such institutional details in their models and empirical tests.
Notes
- 1.
“Social Security Bulletin, Annual Statistical Supplement” (Security Administration 1981, 2002) “Represents program and administrative expenditures from federal, state and local public revenues and trust funds under public law. Includes workers compensation and temporary disability insurance payments made through private carriers and self-insurers. Includes capital outlay and some expenditures abroad”.
- 2.
Note that redistribution is Meltzer and Richard’s measure of the size of government.
- 3.
See Benabou (1996) for a review of articles which test the Meltzer and Richard model.
- 4.
Meltzer and Richard (1981, p. 915) assume that “Any voting rule that concentrates votes below the mean provides an incentive for redistribution of income financed by (net) taxes on incomes that are (relatively) high”.
- 5.
Under an open rule, the bill can be amended.
- 6.
The notation here follows Cox and McCubbins (2005). Since the extremes of the policy space are not defined, a more precise expression of the blockout zone would be M ±|M − F|.
- 7.
For proofs of these two predictions, see Cox and McCubbins (2005, p. 42).
- 8.
Peress (2013) includes a summary of why this problem is so technically difficult, as well as a proposed solution.
- 9.
The “fixed-effects” estimator is simply pooled ordinary least squares with a dummy variable for each cross-sectional category.
- 10.
Federal unemployment insurance.
- 11.
Food Stamps, WIC, and milk programs.
- 12.
Cash assistance, Social Security Insurance, Aid to Families with Dependent Children/Temporary Assistance to Needy Families and Earned Income Tax Credit.
- 13.
Housing and Urban Development, slum clearance, and urban redevelopment.
- 14.
Farmers Home Administration, Rural and depressed area development.
- 15.
Job training and employment and dislocated worker training grants.
- 16.
Block grants for social services and rehabilitation services.
- 17.
Subsidized housing, public housing and rental assistance.
- 18.
All Budget Authority Data compiled by True (2007) from Office of Budget and Management Data.
- 19.
Income data comes from Census data compiled by Adler (2003), and directly from the Census Bureau.
- 20.
DW-NOMINATE is an ideal point estimation technique that assigns members of Congress a two-dimensional ideal point based on their voting record. The first dimension score ranges from − 1 to + 1 and is largely thought to represent liberal (− 1) to conservative (+ 1) preferences on economic matters (Poole and Rosenthal 1997). For more information on NOMINATE see www.voteview.com.
- 21.
The poverty rate comes from the Census Bureau.
- 22.
Results using the unemployment rate rather than the poverty rate are similar but smaller in magnitude. These results are available upon request.
- 23.
The Appendix has OLS results sub-function by sub-function.
References
Acemoglu D, Robinson J (2005) Economic origins of dictatorship and democracy. Cambridge University Press, Cambridge
Adler S (2003) Congressional district data file [83rd to 105th Congress]. University of Colorado at Boulder
Aldrich J (1995) Why parties? University of Chicago Press, Chicago
Aldrich J, Rohde D (1998) Measuring conditional party government. Mimeo, New York
Aldrich J, Rohde D (2001) The logic of conditional party government: revisiting the electoral connection. In Dodd L, Oppenheimer B (eds) Congress reconsidered. CQ Press, Washington
Aldrich J, Gomez B, Merolla J (2005) Follow the money: models of Congressional governance and the appropriations process. Mimeo, New York
Anderson S (2008) Pivots and bills: testing models of appropriations. Mimeo, New York
Arellano M, Bond S (1991) Some tests of specification for panel data: Monte Carlo evidence and an application to employment equations. Rev Econ Stud 58(2):277–297
Bartels LM (2018) Unequal democracy: the political economy of the new gilded age. Princeton University Press, Princeton
Beck N (2008) Time-series cross-section methods. In: Box-Steffensmeir J, et al (eds) The Oxford handbook of political methodology. Oxford University Press, Oxford, pp 475–493
Beck N, Katz J (2007) Random coefficient models for time-series-cross-section data: Monte Carlo experiments. Polit Anal 15(2):182
Beck N, Katz J (2011) Modeling dynamics in time-series cross-section political economy data. Ann Rev Polit Sci 14(1):331–352
Benabou R (1996) Inequality and growth. NBER Macroecon Ann 11(1):11–74
Binder SA (1999) The dynamics of legislative gridlock, 1947–1996. Am Polit Sci Rev 93(3):519–533
Black D (1948) On the rationale of group decision-making. J Polit Econ 56(1):23–34
Brady D, Volden C (2005) Revolving gridlock: politics and policy from Jimmy Carter to George W. Bush. Westview Press, Boulder
Cox G, McCubbins M (1993) Legislative leviathan: party government in the house. University of California Press, Berkeley
Cox G, McCubbins M (2005) Setting the agenda: responsible party government in the U.S. House of Representatives. Cambridge University Press, Cambridge
Gouveia M, Masia N (1998) Does the median voter model explain the size of government? Evidence from the states. Public Choice 97(1–2):159–177
Groseclose T, Levitt S, Snyder J Jr (1999) Comparing interest group scores across time and chambers: Adjusted ADA scores for the US Congress. Am Polit Sci Rev 93(1): 33–50
Hsiao C (2003) Analysis of panel data. Cambridge University Press, Cambridge
Iversen T, Soskice D (2006) Electoral institutions and the politics of coalitions: Why some democracies redistribute more than others. Am Polit Sci Rev 100(2):165–181
Kelly N, Enns P (2010) Inequality and the dynamics of public opinion: the self-reinforcing link between economic inequality and mass preferences. Am J Polit Sci 54(4):855–870
Krehbiel K (1998) Pivotal politics. University of Chicago Press, Chicago
McCarty N, Poole K, Rosenthal H (2006) Polarized America: the dance of ideology and unequal riches. Cambridge University Press, Cambridge
McCarty N, Poole K, Rosenthal H (2016) Polarized America: The dance of ideology and unequal riches, 2nd edn. MIT Press, Cambridge
Meltzer AH, Richard SF (1981) A rational theory of the size of government. J Polit Econ 89(5):914–927
Meltzer AH, Richard SF (1983) Tests of a rational theory of the size of government. Public Choice 41(3):403–418
Peress M (2013) Estimating proposal and status quo locations using voting and cosponsorship data. J Polit 75(3):613–6311
Persson T, Tabellini G (2000) Political economics. MIT Press, Cambridge
Pickering A, Rockey J (2011) Ideology and the growth of government. Rev Econ Stat 93(3):907–919
Pinheiro J, Bates D (2000) Mixed-effects models in S and S-PLUS. Springer, New York
Poole KT, Rosenthal H (1997) Congress: a political-economic history of roll call voting. Oxford University Press, Oxford
Ragan R (2013) Institutional sources of policy bias: a computational investigation. J Theor Polit 25(4):467–491
Roemer JE (2009) Political competition: theory and applications. Harvard University Press, Cambridge
Schick A, LoStracco F (2000) The federal budget: politics, policy, process. Brookings Institution Press, Washington
Security Administration U (1981) Social security bulletin. Annual statistical supplement. Social Security Administration, Washington
Security Administration U (2002) Social security bulletin. Annual statistical supplement. Social Security Administration, Washington
Swamy P (1968) Statistical inference in random coefficient regression models. University of Wisconsin, Madison
True JL (2007) Historical budget records converted to the present functional categorization with actual results for fy 1947–2006. Lamar University and The Policy Agenda’s Project
Western B (1998) Causal heterogeneity in comparative research: a Bayesian hierarchical modelling approach. Am J Polit Sci 42:1233–1259
Acknowledgements
We would like to thank Robert Grafstein, David B. Mustard, Keith Dougherty, and Jamie Carson for their many comments and insights. Greg Robinson’s thoughts were especially helpful early in the project. Thanks to seminar participants at EITM V: Ann Arbor, Binghamton University, and Stony Brook University.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendix
Appendix
A sub-function by sub-function OLS was estimated for the same data as the RCM in the body of the paper. The results are displayed in Table 7.3. The standard errors are wrong because they are not taking advantage of the full structure of the data as in the case of the RCM.
Looking across the sub-function categories, the estimated partial effect of the location of the median member of the majority party has a similar magnitude and sign as the effect found in the random coefficient model for the sub-functions relating to food, income support, regional development, and job training.
For unemployment, social services, and housing, the effect is of the same sign (negative), but the effect is much larger than the estimate from the random coefficient model. The effect on community development is actually of the opposite sign than the random coefficient model estimate. However, the result is not remotely statistically significant.
Rights and permissions
Copyright information
© 2021 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter

Cite this chapter
Ragan, R., Khurana, S. (2021). A Congressional Theory of the Size of Government. In: Hall, J., Khoo, B. (eds) Essays on Government Growth. Studies in Public Choice, vol 40. Springer, Cham. https://doi.org/10.1007/978-3-030-55081-3_7
Download citation
DOI: https://doi.org/10.1007/978-3-030-55081-3_7
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-55080-6
Online ISBN: 978-3-030-55081-3
eBook Packages: Economics and FinanceEconomics and Finance (R0)