
Abstract
For more than a decade, in the context of Microcalcifications detection, radiologists previously use traditional techniques to analyze mammographic images, which leads to a lower precision in the detection of lesions. The effective method of treating breast cancer is to detect it in early stages to increase the chances of cure and reduce the mortality rate, and to do this we propose in this paper to develop a computer aided diagnostic system (CAD) named Earlier Breast Cancer Computer Aided Detection (EBCCAD) which aim is to detect and classify breast cancer images and to replace the previous techniques already used to enhance radiologists performance in determining the pathologic-disease stage of Mccs and to discriminate between normal and abnormal tissues. The results obtained are promising given the rate of good classification obtained by the approaches proposed in the classification phase which lead us to evaluate the proposed system for real cases.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Breast cancer
- Computer Aided Diagnosis (CAD)
- Earlier Breast Cancer Computer Aided Detection (EBCCAD)
- Microcalcifications (MCCs)
- Segmentation
- Classification
1 Introduction
Breast cancer is hormonally regulated malignancy and it is the most invasive and regular kind of cancer among women worldwide, it starts when cells in the breast region begin to grow out of control and they undergo changes that make their growth or behavior abnormal. These cells usually form a tumor that can often be seen on an x-ray as a lump.
The microcalcifications are the first indicator of breast cancer, it appears as a small deposits of calcium in the breast, not all Microcalcification are malignant but their distribution within the breast can be useful to detect the clusters that contains benign or malignant lesions. The Tumor is malignant if the cells can grow into surrounding tissues or spread to distant areas of the body (metastasis case) [2]. The disease can start from different parts of the mammary gland. Most mammary cancers begin in the ducts that carry milk to the nipple (ductal cancers). Some start in the glands that make breast milk (lobular cancers) as show in Fig. 1.

Breast cancer.
1.1 Mammography Images
Screening mammography has delivered many benefits since its introduction, the Mammography is a technique of radiography particularly adapted to the woman’s breasts. It consists to detect abnormalities as soon as possible before they cause clinical symptoms such as: palpable nodule, skin changes, discharge, inflammation, etc. [3].
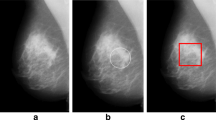
Mammography is usually taken in different directions called incidences. A good incidence is to visualize the maximum breast tissue by spreading it as much as possible on the X-ray plate. Depending on the examined breast part, different implications are used. The most frequently used incidences are the incidence of the face also called Cranio Caudale (CC), the oblique external incidence called Medio Lateral Oblique (MLO) and the incidence of profile (Fig. 2) [4].

Overview of our proposed system.
2 Breast Cancer Detection
2.1 Related Work
Image processing techniques were widely expanded in the 1990s, allowing the processing and analysis of medical images such as mammography for the prevention of breast cancer. Several studies and researches have been carried out in this context. The objective is to detect in the microcalcifications that can be a sign of cancer especially when they are isolated or grouped into clusters [4] (Fig. 3).

(a) Original image, (b) Filtered image.
In [5], the authors used a method based on Data Mining, after pre-processing Weiner filtering is used to remove unwanted content and to improve the quality of the images, then the segmentation of mammogram part from breast cancer using k-means and the features extraction proceeded by the use of Support Vector Machine, the final step is classification were they proposed the K-nearest neighbor (KNN) to classify the output as benign or malignant.
Also, in [6], authors used method based on Variational level set evolution, wavelet decomposition, fuzzy c-means clustering and support vector machine, for extracting breast region, partial differential equation based variational level set process was applied followed by mesh-freebased radial basis function to remove progression of level set. For enhancing the quality of mammogram images, unsharp masking and median filtering are proposed to segment the suspicious abnormal areas, fuzzy c-mean clustering is used. Finally, the support vector machine is used to classify the suspicious regions into abnormal and normal classes.
In [7], authors use high order statistics to detect microcalcifications. They firstly decompose the mammographic images into sub-band using a filter bank. Then each sub image is divided into square regions whose asymmetry and Kurtosis will be estimated, if a region has a positive and high value of asymmetry and kurtosis then it is considered as a region of interest (ROI) which means microcalcifications suspicious area.
As the previous work, in [8] authors detect microcalcifications using the fuzzy shell method after decomposing mammographic images with wavelet transformation. Obtained horizontal or vertical image is used to identify the region by surrounding the microcalcifications clusters using the asymmetry and Kurtosis parameters. Then Fuzzy shell clustering is used to perceive the nodular structure of the ROI.
The Saranya et al. [9] presented an automatic system based on artificial neural networks (ANN) to detect and classify microcalcifications stage, in which 10 geometric and textural characteristics were used.
In [10], Singh and Gupta introduced a simple and easy approach for detection of cancerous tissues in mammogram based on average and thresholding technique in the segmentation phase; then using the Max-Mean and Least-Variance technique to detect tumor masses.
Pereira et al. [11] proposed a segmentation method for tumor detection in mammography images based on Wavelet analysis and genetic algorithm.
3 Proposed Approach
The main purpose of our researches is to contribute to detect earlier signs of breast cancer which can help mostly and effectively in reducing the rate of women mortality and largely increases the chances of survival by prescribing the personalized correct and efficient treatment. In this context our current work focuses. The Fig. 4 outlines our proposed system which can be described in following steps: (1) preprocessing, (2) segmentation, (3) features extraction and (4) classification of mammographic images which can be detailed below.

(a) Pre-processed image (b) Segmented image with WS.
3.1 Preprocessing Step
Digital mammography images often contain significant noise and artifacts, so to reduce them and improve the image quality, filtering must be done to make images as clean as possible. In this work, we propose to use median filter [12] because it allows removing impulsive noise with respects to the edges of tissues (Fig. 4).
3.2 Segmentation Step
After improving the image quality, the next step is to extract the ROI, i.e., the region containing the microcalcifications. This will be done using image segmentation approaches, hence the name segmentation phase. The aim of segmentation is to make the representation of an image significant and easy to analyze.
The most straightforward definition that can be given to the segmentation is to partitioning an image into multiple regions with respect to some criteria to detect and locate objects and boundaries in general context [13]. For medical images [14], they can be tissues, structures, lesions, etc.
Despite this simple definition, image segmentation still a delicate and critical task in image processing.
In the following, we will provide details for the different used image segmentation approaches in this work.
Contrast Enhancement
Before starting the segmentation approaches, we must go through the phase of contrast enhancement since it will be necessary to facilitate the visual interpretation and understanding of images. Digital images have the advantage of allowing us to manipulate the values recorded for each pixel relatively easily; useful information is often contained in a limited set of numerical values among the possible values (256 in the case of 8-bit data).
Contrast enhancement is achieved by changing the initial values to use all possible values, thus increasing the contrast between the targets and their environment.
There are many definitions of contrast. One of the most known, Michelson’s contrast [13], was introduced to give a measure of the visibility of interference fringes on test patterns whose luminance varied sinusoidally from \( {\text{L}}_{ \hbox{min} } \) to \( {\text{L}}_{ \hbox{max} } \) as given as
Where \( {\text{L}}_{ \hbox{min} } \) and \( {\text{L}}_{ \hbox{max} } \) are the maximum and minimum luminance values in the image.
Mathematical Morphology
Mathematical Morphology (MM) was introduced by Matheron [16] as a technique for analyzing the geometric structure of metal and geologic samples. It was extended to image analysis by Serra [15]. The basic idea of Mathematical Morphology is to study a set using another set called structuring element; at each position of this structuring element we check if it at the border or it is included in the initial set, and then we construct the output set. The MM is based on four operators: dilation, erosion, opening and closing as detailed below. Let F(x,y) the grey-scale two dimensional image and B the structured element.
The dilatation of F(x, y) by structured element B(s, t) is denoted by:
The erosion of F(x, y) by B(s; t) is denoted by:
The opening and closing operators of F(x, y) by B(s, t) are represented respectively as follows:
In Mathematical Morphology, a common technique for improving contrast is the top hat transformation; it is defined as the difference between the original image and its opening. Opening an image is the collection of foreground parts of an image that fit a particular Structed Element (SE). Therefore, the bright points of the original image are highlighted using this transformation. The bottom-hat transformation is defined as the difference between closing the original image and the original image. Closing an image is the collection of background pieces of an image that fit a particular SE. Therefore, the darkest areas of the original image are highlighted by this technique. By applying the ‘white top hat’, microcalcifications are well detected using as structuring element a disc of diameter less than 5 mm (Fig. 5) [17].

(a) Pre-processed image, (b) Detection of the MCCs by White Top-hat technic.
The Watershed Method
Watershed method originates from geography [16]; it is a good and powerful image segmentation technique because it provides more accurate segmentation with low computation task. The watershed method splits an image into regions based on the image topology; it is often preceded by a pretreatment step. Generally, a filtering step is initiated, followed by the calculation of a gradient or the calculation of an image indicating the transition zones that are to be detected. The image can be seen as a relief if the gray scale of each point is associated with an elevation. The calculation of the watershed is then the final step in the segmentation procedure. When the Watershed is applied, we note that there is an over segmentation because this method is sensitive to any local minimal in the mammography image, indeed it tends to over-define watersheds.
So, we have to eliminate these non-significant local minima and keep only those that correspond to the objects of the image. To solve this problem, we applied the Watershed under constraint of markers; the marker is one or more connected components which make it possible to locate the regions to be segmented in an image, these connected sets of points forming part of the objects to be segmented. We have chosen as internal marker the ’top hat method; in this technique, elements smaller than the structuring element are extracted. It means that we consider as markers the elements that are inside the top hat method; this transformation is defined as the difference between the image and its opening (Fig. 6).

(a) Pre-processed image, (b) Segmented image with SM.
Split/Merge Approach
The split and merge (SM) algorithm [18] was first introduced in 1974 by Pavlidis and Horowitz. This algorithm is similar in principle to the region growing algorithm. The main difference stems from the nature of the aggregate elementary regions. This technique is used for image segmentation, it allows the image to be divided into four regions based on the homogeneity criterion then similar regions are merged to construct the result (the segmented image). The SM is based on the quad tree structure; the steps through which this algorithm passes are as follows:
-
Specifying the homogeneity criterion that will be used in the test;
-
Divide the image into four regions of the same size;
-
Calculate the criteria for each region;
-
This process will be repeated until all regions pass the homogeneity test.
There are several ways to define the criterion of homogeneity; among these methods we cite:
-
Variance: The gray level variance will be defined as follows.
$$ \upsigma^{2} = \frac{1}{{{\text{N}} - 1}}\sum \left[ {{\text{I}}\left( {{\text{i}},{\text{j}}} \right) - {\bar{\text{I}}}} \right]^{2} $$(6) -
Local and global mean: If the mean of a region is high in comparison to the mean of the original image, then this region is homogeneous.
-
Uniformity: the region is homogeneous if its grey levels are constant or inside a given threshold.
We applied this method to detect MCCs contained in mammographic images because this technique is a global and local method: global during division, and local during merging. The result of this application as illustrated in Fig. 7 provides information on the MCCs as well as some areas that are not the suspect zones.

Construction of a binary pattern and calculation of the LBP code [19].
In this comparative study of different images segmentation methods from different natures, we were able to observe that mathematical morphology is efficient and effective compared to others, proven by the numerical results obtained (Table 2). For this purpose, in the rest of the system, at the classification phase, only the results of segmentation by the MM will be considered.
3.3 Features Extraction Step
The extraction of discriminating characteristics is a fundamental step in the recognition process, prior to classification. The characteristics are usually numerical, but they can be strings, graphs or other quantities. It consists in producing a vector regrouping the information extracted from the image called descriptor vector. This descriptor translates information from an image into a more compact form.
In the following section we will present LBP and Tamura methods used in this work to extract the image characteristics.
Local Binary Pattern
Local binary patterns were initially proposed by Ojala in 1996 [19] in order to characterize the textures, present in images in gray levels. They consist in attributing to each pixel P = I(I,j) of the image I to be analyzed, a value characterizing the local pattern around this pixel. These values are calculated by comparing the gray level of the central pixel P with the values of the gray levels of the neighboring pixels.
The concept of LBP is too simple; it proposes to assign a binary code to a pixel according to its neighbors. This code describing the local texture of a region is calculated by thresholding a neighbor with the gray level of the central pixel, in order to generate a binary pattern, all neighbors will then take a “1” value if their value is greater than or equal to the current pixel and “0” otherwise (Fig. 8).

(a) Original images, (b) Filtered images.
The pixels of this binary pattern are then multiplied by weights and summed in order to obtain an LBP code of the current pixel.
Tamura
The Tamura approach [20] is interesting for the search of images by content; it describes the possible textures, because it adopts an approach based on psychological studies and on visual perception.
The authors propose six visual texture parameters:
-
Coarseness:
For each x value of the pixel positioned in (i, j),
i.e. x = value(i,j) :
$$ {\text{A}}_{\text{k}} \left( {{\text{x}},{\text{y}}} \right) = \frac{1}{{2^{{2{\text{k}}}} }}\mathop \sum \nolimits_{{{\text{i}} = {\text{x}} - 2^{{{\text{k}} - 1}} }}^{{{\text{x}} + 2^{{{\text{k}} - 1}} + 1}} \mathop \sum \nolimits_{{{\text{j}} = {\text{y}} - 2^{{{\text{k}} - 1}} }}^{{{\text{y}} + 2^{{{\text{k}} - 1}} - 1}} {\text{x}}\left( {{\text{i}},{\text{j}}} \right) $$(7)Then, calculate the horizontal and vertical differences respectively:
$$ {\text{E}}_{\text{k}}^{\text{H}} \left( {{\text{x}},{\text{y}}} \right) = \left| {{\text{A}}_{\text{k}} \left( {{\text{x}} + 2^{\text{k}} ,{\text{y}}} \right) - {\text{A}}_{\text{k}} \left( {{\text{x}} - 2^{\text{k}} ,{\text{y}}} \right)} \right| $$(8)$$ {\text{E}}_{\text{k}}^{\text{V}} \left( {{\text{x}},{\text{y}}} \right) = \left| {{\text{A}}_{\text{k}} \left( {{\text{x}},{\text{y}} + 2^{\text{k}} } \right) - {\text{A}}_{\text{k}} \left( {{\text{x}},{\text{y}} - 2^{\text{k}} } \right)} \right| $$(9)Then, for each pixel, choose the k value that maximizes horizontal and vertical differences:
$$ {\hat{\text{k}}}\left( {{\text{x}},{\text{y}}} \right) = {\text{argmax}}_{\text{k}} \left\{ {{\text{E}}_{\text{k}}^{\text{H}} \left( {{\text{x}},{\text{y}}} \right),{\text{E}}_{\text{k}}^{\text{V}} \left( {{\text{x}},{\text{y}}} \right)} \right\} $$(10)This value is supposed to represent the size of a “granule” centered on the pixel (x, y).
Finally, the value of the coarseness parameter is obtained as the average of the sizes of the best granules found on the whole image:
$$ {\text{f}}_{\text{crs}} = \frac{1}{\text{N * M}}\mathop \sum \nolimits_{{{\text{x}} = 1}}^{\text{N}} \mathop \sum \nolimits_{{{\text{y}} = 1}}^{\text{M}} {\hat{\text{k}}}\left( {{\text{x}},{\text{y}}} \right) $$(11) -
Contrast:
$$ {\text{f}}_{\text{con}} = \frac{\upsigma}{{\left( {\upalpha_{4} } \right)^{\upgamma} }} $$(12)Where γ is a positive constant. According to the experiences of Tamura et al. [19], γ = 1/4 gives the best results.
-
Direction:
Tamura calculated the horizontal gradient \( \Delta_{\text{h}} \) by differentiating between the three grayscales on the left side of the pixel p (i, j) and the three grayscales on the right side:
$$ \Delta_{\text{k}} \left( {{\text{i}},{\text{j}}} \right) = \mathop \sum \limits_{{{\text{k}} \in \left\{ { - 1,0,1} \right\}}} \left( {{\text{p}}\left( {{\text{i}} + 1,{\text{j}} + {\text{k}}} \right) - {\text{p}}\left( {{\text{i}} - 1,{\text{j}} + {\text{k}}} \right)} \right) $$(13)The vertical gradient \( \Delta_{\text{v}} \) is the difference between the three levels of grey at the top and bottom of the pixelp (i, j):
$$ \Delta_{\text{v}} \left( {{\text{i}},{\text{j}}} \right) = \mathop \sum \nolimits_{{{\text{k}} \in \left\{ { - 1,0,1} \right\}}} \left( {{\text{p}}\left( {{\text{i}} + {\text{k}},{\text{j}} + 1} \right) - {\text{p}}\left( {{\text{i}} + {\text{k}},{\text{j}} - 1} \right)} \right) $$(14) -
Presence of lines:
$$ {\text{f}}_{\text{lin}} = \frac{{\mathop \sum \nolimits_{{{\text{i}} = 1}}^{\text{M}} \mathop \sum \nolimits_{{{\text{j}} = 1}}^{\text{M}} {\text{P}}\left( {{\text{i}},{\text{j}}} \right){ \cos }\frac{{2\uppi\left( {{\text{i}} - {\text{j}}} \right)}}{\text{M}}}}{{\mathop \sum \nolimits_{{{\text{i}} = 1}}^{\text{M}} \mathop \sum \nolimits_{{{\text{j}} = 1}}^{\text{M}} {\text{P}}\left( {{\text{i}},{\text{j}}} \right)}} $$(15) -
Regularity:
$$ {\text{f}}_{\text{reg}} = 1 -\upalpha\left( {\upsigma_{\text{crs}} +\upsigma_{\text{con}} +\upsigma_{\text{dir}} +\upsigma_{\text{lin}} } \right) $$(16)Where α is a standardization factor.
-
Roughness:
$$ {\text{f}}_{\text{rgh}} = {\text{f}}_{\text{crs}} + {\text{f}}_{\text{con}} $$(17)These parameters are calculated to construct a texture vector. The first three parameters (coarseness, direction, contrast) have a strong connection with human perception. It would seem that the human eye is most sensitive to the coarseness of the texture, then to its contrast and finally to the direction. This type of characteristics may seem interesting to compare the visual content of the images because it corresponds directly to the way in which the human perceives them.
Gabor Filters
GABOR [21] or Gaussian filters are a special class of linear filters, they are oriented filters. These filters have an impulse response, there are applied by convolution, which are composed of a sinusoidal component and a Gaussian component these filters correspond to a weighting by a Gaussian function in the frequency domain.
Where:
the rotation angle \( \upphi \) of (X, Y) in regard to (x,y) gives the orientation of the Gaussian envelope in the space domain.
And \( {\text{g}}\left( {{\text{X}},{\text{Y}}} \right) = \frac{1}{{2\uppi \upsigma ^{2} }}{\text{e}}^{{\frac{{ - (\frac{\text{X}}{\uplambda})^{2} + {\text{Y}}^{2} }}{{2\upsigma^{2} }}}} \) is a two-dimensional Gaussian function of axis ratio \( \uplambda \) and the expansion factor \( \upsigma \).
Gabor filters are configurable in frequency as well as orientation. Their use makes it possible to extract the contours of the images to characterize their texture, it is quite possible to use these characteristics to obtain a vector that allows us to better describe the texture of our input image and then classify it in its pathological stage.
3.4 Classification Step
Classification allows grouping all the image pixels into a limited number of classes that correspond most closely to the main components of the image; it is a method to establish image cartography.
Two types of classifications can be distinguished: unsupervised where information about the objects to be classified is not previously relied upon, and supervised is based on the identification of the objects known as “reference sites”. Considering the a priori information provided by the used database (MIAS) about the pathology of mammographic images, we have opted for the supervised classification of which three most commonly used classifiers are chosen, namely K-nearest neighbor, Support vector machine and Decision tree.
K-Nearest Neighbor
The k nearest neighbors (KNN) approach is a powerful nonparametric method for estimating and determining the class of an image. This method [22] consists in determining for each new individual who is to be classified the list of k-nearest neighbors among the individuals already classified.
The KNN method is a technique that is generally based on the calculation of the Euclidean distance between an unclassified image and the other images contained in the learning base according to the chosen value of k.
Let’s take for example an input sample \( {\text{y}}_{\text{i}} \) with m features \( \left( {{\text{y}}_{{{\text{i}}1}} ,{\text{y}}_{{{\text{i}}2}} , \ldots ,{\text{y}}_{\text{im}} } \right) \), so the Euclidean distance between \( {\text{y}}_{\text{i}} \) and \( {\text{y}}_{\text{l}} \) with m features \( \left( {{\text{y}}_{{{\text{l}}1}} ,{\text{y}}_{{{\text{l}}2}} , \ldots ,{\text{y}}_{\text{lm}} } \right) \) is as follows:
Finally, classification is done by assigning the class of the element that occurs most frequently among the k training samples and is closest to the element in question.
Support Vector Machine
The Support Vector Machine (SVM) [23], also called the ”Large Margin Separator» ; it is from an automatic learning algorithm family that solves the classification problem; its purpose is to separate the data points by using a separating surface in a way that the distance between the data points and the separating surface is maximum, this distance called the “Margin”. The separating surface assumes that the data are linearly separable, which is not possible in most cases, thus the need to separate the data in a greater vector space [18]; this is called the kernel trick. We consider the separation of the vectors of the training base into two separate classes:
Where \( {\text{x }} \in {\text{R}}^{2} \) and \( {\text{y}} \in \left\{ { - 1 ,1 } \right\} \).
With the equation of the hyperplane:
If there is a maximum separation between the closest vectors to the hyperplane, then we have the redundancy at the equation mentioned above. Therefore it is necessary to consider a vapnik (1995) canonical hyperplane, where the parameters w and b will be constrained by:
This parameter setting is necessary to simplify the formulation of the problem.
The hyperplane separation canonical form is as follows:
And the distance between the hyperplane and the data point x is as shown below:
Hence the hyperplane that optimally separates the data is the one that minimize:
Decision Tree (algorithm C4.5)
The algorithm C4.5 was developed by Quinlan in 1993 [24]. The decision trees are a very effective method of supervised training. The aim is to partition a data set into groups that are as homogeneous as possible in terms of the variable to be predicted. We take as input a set of classified data, and we provide as output a tree that looks like an orientation diagram where each end node (sheet) represents a decision (a class) and each non-end node (internal) represents a test.
This method uses a more elaborated “gain ratio” criterion, the purpose of which is to limit the proliferation of the Tree by penalizing variables that have many modalities, C4.5 practices pruning to classify the attributes and build the decision tree. First, we will calculate the entropy which represents the information contained in a distribution:
And now we will define a function that allows choosing the test that should label the current node by calculating the gain information, its formula is as follows:
With T is a test.
3.5 Experimental Result
In this work, we used mammographic images from the Mini-Mias database to detect microcalcifications earlier.
The Mammographic Image Analysis Society (MIAS) is an organization of UK research groups interested in the understanding of mammograms and has generated a database of digital mammograms. Mammographic images are available via the Pilot European Image Processing Archive (PEIPA) at the University of Essex.
3.6 Pre-processing Evaluation
Visual Results
The following figure shows some mammographic images from our databases that have undergone the median filter as pre-processing. The obtained results are shown in this Fig. 8(b). At first view, the images are enhanced, especially the boundaries between breast tissues and microcalcifications.
Numerical Results
We used the PSNR Peak Signal-to-Noise Ratio [25] is an estimate of the reconstructed image quality relative to the original image, it represents a mathematical measure based on the difference in pixels between these two images, his expression is given by the following formula:
Where s = 255 for an 8-bit image. And MSE is the Mean Square Error computed by averaging the squared intensity of the original (input) image and the resultant (output) image pixels.
Where e(m,n) is the error difference between the original and the distorted images, and M * N represent the size of the images.
Table 1 summarize the overall results the metrics PSNR that show the effectiveness of the proposed filter in the preprocessing phase since the PSNR give values that are all above 30 db which confirms the improvement of the visual quality through this filter.
3.7 Segmentation Evaluation
Visual Results
The segmentation results carried out of the mammographic images pre-processed (Fig. 9) by the three respective methods: MM, SM and WS are provided in Fig. 10. It can be seen that for the first column ‘MM’, the microcalcifications (or ROI) are well identified; this region is a slightly broadened for the second column ‘SM’, while it is much widened for ‘WS’. These extended regions include pixels that are considered as microcalcifications when they are not. Therefore, the MM approach’ provides better results without need of improvement as for the two others. This conclusion is proved by the numerical evaluation as we will see hereunder.

Segmented images by: (a) MM, (b) SM and (c) WS.

Rate of classification.
Numerical Results
To measure the quality of segmented images, we used the structural similarity measure (SSIM) [26] which employs a local spatial correlation measure between the reference image pixels (O) and the test images (S) that is modulated by distortions, his expression is given by the following formula:
Where:
\( \upmu_{0} \) the average of O; \( \upmu_{\text{s}} \) the average of S; \( \upmu_{\text{o}}^{2} \) the variance of O;
\( \upmu_{\text{s}}^{2} \) the variance of S; \( \upsigma_{\text{os}} \) the covariance of O and S;
\( {\text{c}}_{1} = \left( {{\text{k}}_{1} {\text{L}}} \right)^{2} \), \( {\text{c}}_{2} = \left( {{\text{k}}_{2} {\text{L}}} \right)^{2} \) two variables to stabilize the division with weak denominator;
L the dynamic range of the pixel-values ((typically this is \( 2^{{{\text{bitsperpixel}} - 1}} \)));
\( k_{1} \) = 0.01 and \( k_{2} \) = 0.03 by default.
Also, we used the DICE index, it measures the similarity between two images based on the number of common pixels. The DICE is commonly used when evaluating the performance of segmentation methods; it measures the spatial overlap between the ground truth and the automated segmentation [27]. The value for the DICE is between 0 (no overlap) and 1 (perfect overlap). The DICE Similarity Coefficient is calculated as:
As show from Table 2, the segmentation values of SSIM and DICE for the Mathematical morphology gives better value than the others one. As it gives an optimal segmentation, we relied on it to perform the classification.
Evaluation of Classification
The description and classification allow us to classify our mammography images. In this work, we have made several hybridization algorithms of descriptions in order to obtain a better rate of good classification. The graphs (Figs. 2 and 11) below illustrate the results obtained by the different classification approaches.

Rate of sensitivity, specificity, kappa.
The proposed classifiers allow to obtain binary results, i.e. they allow to specify if the mammographic image contains micro-calcifications, by mentioning if the tissue is benign or malignant. For the classifier KNN we have proceeded with our classification with k = 1 (a nearest neighbor), while for SVM it is a question of estimating a hyper plane to separate the data into two classes, and for the C4.5 method it allows to take as input the data and convert them into a tree where the last leaf represents a decision and each intermediate sheet represents a test.
The graph above represents the classification rates obtained by the different classifiers proposed using several descriptors in the experimentation phase as well as their hybridization, and keeping only those that give us the best result.
In our computer aided diagnostic system, we were based on majority voting to give a reliable and correct classification according to the different results obtained from the selected classifiers.
As shown from Fig. 11 comparing the three classifiers using under different texture features, we note that the KNN classifier outperforms the others and gives better recognition rate in most majority cases. This assessment is confirmed by the respective sensitivity, specificity and kappa measurements which reach the optimal value 1 easily (Fig. 12).
4 Conclusion
This paper presents a computer aided diagnostic system (CAD) for detecting and segmenting Microcalcifications using Digital Mammograms from Mini-Mias Database. It uses a split & Merge and the Technics of Mathematical Morphology (Mathematical Morphology and the Watershed method) to perform segmentation . A preprocessing method based on Median Filter used to denoise image and the step of contrast enhancement is applied to make MCCs clear as possible. Then the classification step in order to determine the pathological stages of mammography images.
References
National Cancer Day. Collective will to fight this devastating disease (FR), November 2018
National Cancer Institute. Breast Cancers, March 2016
Cheikhrouhou, I.: Description and classification of breast masses for breast cancer diagnosis. Doctoral thesis, pp. 32–45, June 2012
Anders, T., Daniel, F., Sören, M., Tony, S., Zackrisson, T.S.: Breast cancer screening with tomosynthesis-Initial experiences, Radiat. Prot. Dosimetry. 181–182 (2011)
Khairunizam, W., Zunaidi, I.: An efficient data mining approaches for breast cancer detection and segmentation in Mammogram. J. Adv. Res. Dyn. Control Syst. (2017)
Kashyap, K.L., et al.: Mesh free based variational level set evolution for breast region segmentation and abnormality detection using mammograms. Int. J. Numer. Meth. Biomed. Eng. 34(1), 2907 (2018)
Gurcan, M., Yardımci, Y., Enis, A.C., Ansari, R.: Detection of microcalcifications in mammograms using higher order statistics. IEEE Signal Process. Lett. 4(8), 213–216 (1997)
Balakumaran, T., Vennila, I., Shankar, C.G.: Detection of Microcalcification in Mammograms Using Wavelet Transform and Fuzzy Shell Clustering. Int. J. Comput. Sci. Inf. Secur. (2010)
Saranya, R., Showbana, R.: Automatic detection and classification of microcalcification on mammographic images. IOSR J. Electron. Commun. Eng. (IOSR-JECE) 9(3), 65–71 (2014)
Singh, A.K., Gupta, B.: A novel approach for breast cancer detection and segmentation in a mammogram. In: Eleventh International Multi-Conference on Information Processing (IMCIP-2015) (2015)
Pereira, D., Ramos, R., Zanchetta do Nascimento, M.: Segmentation and detection of breast cancer in mammograms combining wavelet analysis and genetic algorithm. Comput. Methods Programs Biomed. 114, 88–101 (2014)
Verma, K., Singh, B.K., Thoke, A.S.: An enhancement in adaptive median filter for edge preservation. In: International Conference on Intelligent Computing, Communication & Convergence (ICCC-2014), vol. 30 (2015)
Wang, X.: Graph based approaches for image segmentation and object tracking. Doctoral thesis, pp. 2–3, September 2014
Sharma, N., Aggarwal, M.: Automated medical image segmentation techniques. J. Med. Phys. 3–14 (2011)
Hautière, N., Aubert, D., Jourlin, M.: Measurement of local contrast in images, Application to the measurement of visibility distance through use of an on-board camera. In: LIVIC-Laboratory on Vehicle Interactions Drivers Infrastructure and Laboratory Signal Processing and Instrumentation. Signal Processing, vol. 23, no. 2, p. 3 (2006)
Beucher, S., Meyer, F.: The morphological approach to segmentation: the watershed transformation. In: Mathematical Morphology in Image Processing, pp. 437–453 (1993)
Thapar, S., Garg, S.: Study and implementation of various morphology-based image contrast enhancement techniques. CSE Department, IT Department, pp. 2–5 (2012)
Horowitz, S.L., Pavlidis, T.: Picture segmentation by a directed split and merge procedure. In: Computer Methods in Images Analysis (1977)
Houam, L.: Contribution to the analysis of X-ray textures of osseuses for the early diagnosis of osteoporosis. Doctoral thesis, pp. 78–79, December 2012
Idrissi, N.: Navigation in image databases: taking into account texture attributes. Doctoral thesis, University of Nantes, pp. 36–38, October 2008
Pujol, A.: Contribution to the semantic classification of images, June 2009
Lahbibi, W.: AlgorithmKNN: K-nearest neighbor (2013)
Bousquet, O.: Introduction to Vector Machine Support (SVM), November 2001
Marée, R.: Automatic classification of images by decision tree, pp. 38–39 (2005)
Al-Najjar, Y., Chen Soong, D.: Comparison of ImageQuality Assessment: PSNR, HVS, SSIM, UIQI. Int. J. Sci. Eng. Res. 3(8), August 2012. ISSN 2229-5518
Rouse, D., Hemami, S.: The role of edge information to estimate the perceived utility of natural images, Visual Communications Lab, School of Electrical and Computer Engineering, Cornell University, Ithaca, NY, vol. 14853, pp. 2–3
Babalola, K.O., Patenaude, B., Aljabar, P., Schnabel, J., Kennedy, D., Crum, W., Smith, S., Cootes, T.F., Jenkinson, M., Reuckert, D.: Comparison and evaluation of segmentation techniques for subcortical structures in Brain MRI. Division of Imaging Science and Biomedical Engineering (ISBE), pp. 3–4
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Khoulqi, I., Idrissi, N. (2020). Segmentation and Classification of Microcalcifications Using Digital Mammograms. In: Ben Ahmed, M., Boudhir, A., Santos, D., El Aroussi, M., Karas, İ. (eds) Innovations in Smart Cities Applications Edition 3. SCA 2019. Lecture Notes in Intelligent Transportation and Infrastructure. Springer, Cham. https://doi.org/10.1007/978-3-030-37629-1_29
Download citation
DOI: https://doi.org/10.1007/978-3-030-37629-1_29
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-37628-4
Online ISBN: 978-3-030-37629-1
eBook Packages: EngineeringEngineering (R0)