
Abstract
Digitalization has led to creation and management of knowledge using information and communication technology tools (ICT) and systems. Implementing such tools and systems across the lifecycle is a tedious process and not to forget customizing them to the company’s processes is an additional challenge. Hence, data in a company is spread across multiple ICT in heterogeneous data formats and are sparsely connected together. Connecting the various data sources to enable a single point of access of information in a company can improve performance, quality, reduce costs and time to market. The usage of semantic technologies enables meaningful and structured unification of these distributed data sources and therefore, is providing advantages such as reusability, interoperability, and information flow across the entire value chain. Extending these capabilities with smart services and intelligent algorithms, is advantageous for the user. The user will then receive context sensitive information and additional suggestions that increases the speed, quality and efficiency of work. This paper aims at describing the design, developing and validation of an assistance system for semantic product data, in cooperation with Rolls-Royce Deutschland, an aerospace manufacturing industry, using semantic technologies and machine learning.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Semantic technologies
- Ontology in manufacturing
- Semantic product data
- Information and knowledge management
1 Problem Statement
Along the product life cycle of durable capital goods, such as aircraft turbines, product data is generated across various phases and they are stored and managed using various information technology systems. This leads to the generation of a heterogeneous landscape with respect to data, processes and tools. Hence, in industries it is often a challenge to understand and obtain a big picture of the entire lifecycle, track changes, manage, collaborate and interoperate across processes [1,2,3]. This places a greater importance on availability and interconnectivity of product data across work processes such as production, assembly, maintenance or quality assurance, to improve efficiency of the processes and save costs and time. In general, the challenges faced in manufacturing industries trying to use the advantages of digitalization to improve product lifecycle processes can be classified as: 1. Diversity and complexity of IT tools and systems that are used for various activities. Hence, leading to lack of horizontal and vertical integration in a company; 2. As a consequence of usage of diverse tools, heterogeneous data is generated, which often leads to redundancy and inconsistency; 3. An increasing amount of data that is not being analyzed and managed to support decision making processes [4, 5].
These challenges are also faced in Rolls-Royce Deutschland similar to other industries. There are various IT systems and tools which generate heterogeneous data across the value stream. Not all information is fully transparent across the lifecycle of the product. As a consequence the designer is not always informed about the problems in manufacturing, assembly or supply chain. To tackle these challenges there are various approaches, such as, using a common IT-backbone, using internet technologies to make data easily available [5], using common information models and developing standard interfaces between various IT tools and systems [6]. However, these approaches are relatively static [7] and sometimes involve high levels of effort, time and money to restructure existing processes and infrastructure. Hence, an approach is required which minimizes these impacts and takes into consideration the intuitive communication of complex facts in which the interrelationships of information over the product life cycle and across system boundaries are connected and visualized. In this context, the approach of semantic product data linking is used [8]. This approach has achieved considerable progress in recent years through the development of efficient tools and the continuous further development of Semantic Web technologies [3, 9].
In this paper, we propose an ontology based assistant system to support activities in Rolls-Royce Deutschland by providing solutions to the above stated challenges. For this, a user- and task-specific information visualization is developed and implemented. The main objective of the research is the prototypical implementation of a semantic product data assistance system that serves the information needs in engineering and applies intelligent algorithms and machine learning for a reasoning system.
2 State of the Art
Semantic technologies are based on the World Wide Web Consortium (W3C) standards. They are widely used to interlink data stored on various systems, build vocabularies and handle data with rules [10]. They have already been utilized in structuring and managing complex and large amount of heterogeneous data in media and publishing, bio and medical informatics, life sciences and the World Wide Web design [11, 12]. Ontologies are a part of semantic technologies which enables the definition of data and their relationships [13]. In the manufacturing domain, ontologies have been developed for the purpose of knowledge management [14, 15], knowledge exploration [16] and manufacturability, verification and knowledge reuse [17]. In order to develop a complete application based on ontologies there are many elements to be considered. Referring to the basic architecture of Semantic Web [18] the elements are: the data to be connected or integrated into the ontology, the structure, format and size of data, rules which provide additional logic [19] and querying of the linked data. Additional interactive elements to be considered are the architecture of the user interface with which the user interacts and receives context sensitive information and its connection to the semantic layer. To support the development of such applications there are several commercial and non-commercial tools, languages and configurations available. Nonetheless, there is a lack of tools that support a complete end to end development and implementation of ontologies in an industrial environment [20]. This can be attributed to the fact that, developing solutions for corporate applications also involves the need to interface with existing infrastructure and tools such as databases and product design systems [21]. In addition, they also need to follow the policies and conventions of the company.
3 Research Approach
The research approach is based on the Design Science Research Methodology (DSRM) for Information Systems Research [22]. The steps conducted in this research are shown in Fig. 1.

Research approach steps
This paper is addressing the complete set of steps from one to six, which is the initial cycle of defining the problem, analyzing, developing and evaluating the results. The main research questions in this research are:
-
1.
How to integrate heterogeneous data sources from various ICT?
-
2.
How can relevant context-sensitive knowledge be generated and presented to improve processes?
-
3.
How to use intelligence in terms of algorithms to provide value added smart services along industrial processes?
4 Capturing Requirements by Deduction of Use Cases
To collect requirements, two workshops with twenty-five experts from different Rolls-Royce Deutschland departments were conducted. The focus groups were based on design, production planning and assembly. The workshop resulted in the derivation of seventy-nine user stories. The user stories consist of elements such as its name and description, the role of the user it refers to as well as the goal of the user and from which data sources it originates. In addition, the user stories were also clustered into groups based on their similarities and connections. An example of the user stories documented and structured is show in Table 1.
From the user stories five use cases were derived and selected for further implementation, based on priority, availability of data and the ease of collaboration with Rolls-Royce Deutschland team. These five use cases are:
-
1.
I am a designer and want to understand different variations of my component class in order to make better decisions about new designs (operational data, service data, manufacturing and assembly aspects, suppliers, configuration, ERP).
-
2.
I am a designer and want to understand the production variability of the part in order to assess and optimize the ability of the manufacturing process in terms of tolerances.
-
3.
I am an engineer and would like to view life cycle data to optimize the part.
-
4.
I as an assembler, I want to give feedback to the engineers to improve the design (voice of the fitter, production planner).
-
5.
I am an engineer and want to evaluate the activities around a component to identify important points.
To further detail these five use cases, ten interviews with representatives from the concerned departments were conducted. The questions to detail the use case were divided into four categories, namely “Description of the role”, “Use case – Actual state”, “Use case - Desired state” and “Business case”. The same is outlined in the Fig. 2.

Key questions for use case description
The interviews results were transcribed, analyzed and integrated into five comprehensive use case descriptions, in the form of a document based on [23], with elements depicted in Fig. 3. The detailing of the use case helps in understanding the role of the user and the system, with the related IT systems and also the activities which take place.

Use case description (generic document form)
5 Development of Semantic Assistance System Demonstrator
In this section, the steps followed to design and develop the semantic assistance system are described. First, the derivation procedure for the system architecture requirements is discussed, followed by the derivation of the requirements of the use case, and finally the details about the design and development of the assistance system are detailed. For the design of the system architecture, it was important to identify the data flow paths in the company concerning the use cases. The data flow architecture tool developed by Fraunhofer IPK [24] was used for this purpose. The tool aims at depicting the details of the data flow with process and organizations, virtual and digital models, and information tools and IT systems involved across the activities. Hence, the entire development environment can be idealized and the actual and target states can be compared. This enables the mapping and comparison of a wide variety of scenarios and their effects, which can be used to describe the target vision. With the help of the tool and additional workshops to integrate the new tool into the existing IT landscape at Rolls-Royce Deutschland, it was possible to extrapolate the essential information for fulfilling the requirements and the associated IT systems and artifacts for the use cases.
5.1 Implementation of a Use Case in the Assistance System
To be able to test and work with the architecture use case 3 (voice of the fitter, production planner), was selected. In particular, the voice of the fitter data was used for the demonstrator. This use case mainly consists of the problems fitters have on the assembly floor. These include issues like missing components, missing tools and potential quality problems on components and assembly to name a few. The fitter reports these issues to a voice of the fitter (VoF) team. The team tries to help the fitter to find a solution for their issue by searching various IT systems and sending emails to responsible colleagues, as well as tracking their responses. The issue resolution is a time consuming process, which requires a lot of expertise and effort. It is sometimes critical to assist the fitter as soon as possible, because there are situations in which these issues can lead to a stop in the assembly process, thus resulting in economic losses for the company. Hence, the assistance system was linked to a semantic network, which refers to three data sources. The data sources comprise relevant details about the parts of a particular engine model, VoF cases and concession decisions about reported non-conformances associated with the engine. The aim of the assistance system is to assist the VoF team by visualizing information about the VoF cases, concessions and the geometry of the part with an issue on the assistance system without having to check other tools and systems. In addition, through the semantic network the user can also check for previous cases with similar problems with their solutions on the assistance system. Hence, enabling the usage of previous knowledge and speeding up the solution finding and decision making processes.
5.2 Architecture Design
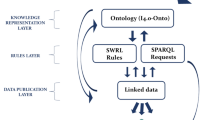
Based on the results of data flow analysis the components of the system architecture were identified. In addition, results from a series of workshops, literature research [25, 26] and iterative and agile development solutions the architecture for the demonstrator was derived. The architecture for the assistance system utilizes various components to provide context sensitive information to the user from various data sources, and supports integration of machine learning algorithms. These components involved are further organized into layers as shown in Fig. 4.

System architecture and key research topics
The application layer hosts the web based user interface. The query layer facilitates the request and response functions. The semantic middleware layer consists the semantic network in the form of ontologies and the triple store. The data layer and the data structuring layer take care of accessing and structuring data sources in order to integrate them within the semantic network. The key research topics along these layers as show in Fig. 4 are user experience (UX) design and application programming interface (API) design, query processing and interfacing to the semantic network, knowledge interpretation and information extraction. The machine learning integration depends on the application, hence can be integrated on various layers.
The architecture formed the backbone for selection of suitable standards, tools, frameworks and software. The research aims at using primarily open source tools to ensure a cost efficient solution whilst keeping a maximum amount of adaptability for the development of the assistance system demonstrator. Eclipse was chosen as the integrated development environment (IDE). Apache Tomcat is used as the web server, which is compatible and interoperable with Eclipse. MariaDB was chosen as the buffer databank used to store the data required. The programming language used is Java Enterprise Edition as it provides the necessary support in the form of object-oriented programming for developing the demonstrator. To enable versioning management of the collaborative development Gitlab was used. The layers mentioned in the architecture and the associated software tools and structure are explained in the following paragraphs:
The application layer hosts the web based user interface. The interface acts as the front end of the assistance system with which the user interacts and receives context sensitive information as desired. It is important to note that the design has to be user and use case centric. Hence, the design of the web-based user interface contains several elements that should be considered during the development process. The elements considered are functional user requirements, user experience requirements, design of the information access and visualization, design of the user interaction and visual design. These key requirements were used as foundations to design the interface. Workshops with the end users were conducted to evaluate the alternatives and select the most suitable layout based on the ranking from the users and the use case needs. The chosen layout of the web interface is shown in the Fig. 7.
The query layer is responsible for the request and response activity which connects the web based front end with the semantic network. That is, based on the user’s requests or interaction with the front end, request algorithms are triggered to receive the right information from the semantic network. This layer connects to the semantic network via a SPARQL endpoint [27]. The design of the requests is important to determine the SPARQL request to the semantic network. For example, when the user clicks on a button requesting for all the parts with similar problems, the ontology is queried for all parts with similar problems and the results of the query are pushed to the front end.
The semantic middleware layer hosts the semantic network. The semantic network consists of the ontology, the mapping files to map the ontology with the data instances, the rules and the derived triples. The triples generated from combining the ontology and the mapped data are stored in a triple store. The process of development of the semantic network began with the modelling of the ontology, Protégé is the tool used [28]. The model of the ontology was developed considering relationships in the original databank sources [29, 30] and the expected system queries [31]. The ontology is shown in Fig. 5, the main classes are based on the three main data sources, information about the physical part (Part_Phys), concessions and VoF case details (VoF_Case). The classes are assigned with data properties that link instances with further details about the instance, for example, the particular part has a “Part_name” data property which is assigned to the domain “Part_Phys” and range “xsd:string”. To connect the individuals in the classes with relationships object properties are defined. For example, to determine which “Part_Phys” has a problem, the object property “Part_has_VoF” is defined with domain as “Part_Phys” and range as “VoF_Case”. The corresponding mappings are shown in Fig. 6. The three object properties in the ontology are represented by the arrows between the classes as shown in Fig. 5.

Ontology modelled in Protégé

Ontop plugin screenshots of mappings in the Mapping manager
As the data from the three data sources could be easily converted and stored in a relational database, they were converted and added into the MariaDB databank. The next step was to map the ontology with data. An open source tool called Ontop was used for this purpose [32]. It is an ontology-based data access (OBDA) tool which comes as a plugin with Protégé and hence is compatible with the architecture. It also has performed well in comparison to other competitors on various benchmark tests [32]. Ontop is connected to the MariaDB using the Java DataBase Connectivity (JDBC) driver. Figure 6 shows the screenshot of the mappings created using the Mapping manager.
Class axioms and relation-constraints, which are controlled by reasoning and serve knowledge interpretation, are now binding for the individuals. In this way, queries become simpler and easier to understand, but with the additional advantage that the data is still enriched with meaning, paving the way for context-based interpretation and knowledge discovery for e.g. learning algorithms or reasoning. In order to facilitate query answering, the generated files from Ontop and Protégé, namely, the owl file, mapping files, and properties files were added onto a tool called Eclipse RDF4 J. It is an open source framework for creating, parsing, storing, reasoning, interfacing and querying RDF data [33, 34]. The tool is compatible with Ontop and generates an Ontop virtual RDF store. This acts as SPARQL endpoint on the Apache Tomcat server for answering queries.
The data structuring and data layer consists of the work data generated by Rolls-Royce Deutschland processes. They are stored in different systems, with different formats and structures. In order to support the development of the semantic network the data for the use cases were structured and converted. The data associated with the physical part and concessions were extracted from the Product Data Management (PDM) system and concessions system respectively, into excel sheets, which were then loaded into the MariaDB in a relational database format. The VoF cases already exist as a set of relational database tables, these were also uploaded into the MariaDB database.
Machine learning algorithms can be integrated into the architecture based on application needs. It is important to determine the function of machine learning, the data sets to be used, the algorithm and the method of machine learning to be considered. The three applications considered for the given use cases were:
-
1.
Visualization of context sensitive information based on user behavior, where the assistance system learns from the user interactions with the system, and reacts by providing context sensitive information on the next request.
-
2.
Provision of suggestions based on previous problem solving history using machine learning algorithm assisting in decision making process.
-
3.
Self-learning ontologies to enable addition of new data into ontologies without manual intervention.
Currently for the above mentioned second application the machine learning model is being developed by using a topic detection algorithm called Latent Dirichlet allocation. The possible integration of the model into the system is also being investigated.
6 Evaluation and Preliminary Results
The assistance system is developed to assist VoF team members with their daily tasks of solving problems faced by the fitters during assembly processes. The developed system presents the team with context sensitive information in the information field area, from various data sources, which provides relevant details to quickly carry out investigative work to solve problems. The assistance system demonstrator was evaluated with an expert VoF team member. The front end of the evaluated demonstrator is shown in Fig. 7. The user was instructed about the aim and general functions available in the assistance system. Then the user was allowed to interact with the tool. The tool testing stage ended with an interview to receive a qualitative feedback and suggestions with respect to the features and the functioning of the tool. This lead to the development of further requirements for improvement of the tool.

Front of assistance system
The user was then asked to fill the questionnaire presented by F.D Davis to measure perceived usefulness, perceived ease of use, and user acceptance of the tool [35]. The rating was based on a five-stage scale with a total of ten questions with criteria ranging from “not at all” to “entirely”, with a rating of 1 to 5 respectively. The answered questionnaire was evaluated, the perceived usefulness average was 4.75 out of 5, perceived ease of use was rated as 4.25 and user acceptance as 5. Hence, indicating that the user acknowledged the advantages of the tool to support daily work. However, the evaluation indicated that there is scope for improvement of the tool with respect to the user interface and additional features to integrate the tool into the work environment.
7 Conclusion and Outlook
By following a methodological research approach, the semantic assistance system demonstrator was analyzed and developed for a particular use case. It is a web based semantic system, which assists the user in accessing context sensitive data in an industrial scenario in which different information tools and heterogeneous data sources exist. This reduces the time taken to search for information in different tools and also helps in accessing historical knowledge to support decision making processes. The demonstrator is a step towards solving the current issues in the field of knowledge management and traceability of data across the value chain. The 3D models integrated into the tool were from the design phase stored in the PDM system, concessions and VoF data from production phase stored in SAP system and VoF tool respectively. The alpha version was tested for usability, which resulted in positive feedback to the tool and development of requirements for further improvement suggestions. Hence, enabling the realization of the use of semantic technologies in an industrial environment for providing context-sensitive information and services from various tools and formats.
In the future, the aim is to further develop the demonstrator by implementing the suggestions provided by the end users. The ontology and the assistance system will be scaled up to include more use cases and data. This provides a basis to test two main factors namely, efficiency and scalability with enterprise scale data and load. In addition, the assistance system will be integrated with machine learning results which enable the user to receive suggestions based on previous historical decisions made. The machine learning will also be explored for user behavior analysis and self-learning ontology to enable context-sensitive information presentation and automatic new data integration into the assistance system respectively.
The demonstrator shall in future be used as an incubator for a number of different and arising use cases – as a platform for both design and manufacturing engineers. In particular in the aerospace industry, such platforms integrating and evaluating information from various different data sources are not yet available. By connecting those different data sources together, and by applying intelligent algorithms and machine learning, a step change in understanding of integrative tasks between design and manufacturing is expected.
References
Manuel, H., Falk, U., Walter, B.: Challenges in product lifecycle management. In: Australasian Conference on Information Systems (2016)
Lee, J., Chae, H., Kim, C.-H., Kim, K.: Design of product ontology architecture for collaborative enterprises. Expert Syst. Appl. 36(2), 2300–2309 (2009)
Otte, J.N., et al.: An ontological approach to representing the product life cycle. AO 14(2), 179–197 (2019)
Deloitte, A.G.: Industry 4.0: challenges and solutions for the digital transformation and use of exponential technologies. https://www2.deloitte.com/content/dam/Deloitte/ch/Documents/manufacturing/ch-en-manufacturing-industry-4-0-24102014.pdf
Kiritsis, D., Bufardi, A., Xirouchakis, P.: Research issues on product lifecycle management and information tracking using smart embedded systems. Adv. Eng. Inform. 17(3–4), 189–202 (2003)
Franke, M., Klein, P., Schröder, L., Thoben, K.-D.: Ontological semantics of standards and PLM repositories in the product development phase. In: Proceedings of the 20th CIRP Design Conference, pp. 473–483 (2010)
Agarwal, S., Haase, P.: Process-based integration of heterogeneous information sources. In: GI Jahrestagung (2004)
Graube, M., Pfeffer, J., Ziegler, J., Urbas, L.: Linked data as integrating technology for industrial data. In: 14th International Conference on Network-Based Information Systems, Tirana, Albania, pp. 162–167 (2011)
Ferrara, A., Nikolov, A., Scharffe, F.: Data linking for the semantic web. Int. J. Semant. Web Inf. Syst. 7(3), 46–76 (2011)
W3C, Linked Data. https://www.w3.org/standards/semanticweb/data#summary
Miah, S.J., Gammack, J., Kerr, D.: Ontology development for context-sensitive decision support. In: Third International Conference on Semantics, Knowledge and Grid (SKG 2007), Xi’an, Shan Xi, China, pp. 475–478, October 2007
The truth about triplestores. https://ontotext.com/wp-content/uploads/2014/07/The-Truth-About-Triplestores.pdf
Ontotext, What is Semantic Technology? https://www.ontotext.com/knowledgehub/fundamentals/semantic-web-technology/
Li, S.-T., Hsieh, H.-C., Sun, I.-W.: An ontology-based knowledge management system for the metal industry. In: WWW (2003)
Cheng, H., et al.: Manufacturing ontology development based on Industry 4.0 demonstration production line. In: 2016 Third International Conference on Trustworthy Systems and their Applications (TSA), Wuhan, China, pp. 42–47 (2016)
Ahonen, E.Q., Watson, D.P., Adams, E.L., McGuire, A.: Alpha test results for a housing first eLearning strategy: the value of multiple qualitative methods for intervention design. In: Pilot and Feasibility Studies, vol. 3, p. 46 (2017)
Li, Z., et al.: An ontology-based product design framework for manufacturability verification and knowledge reuse. Int. J. Adv. Manuf. Technol. 99(9–12), 2121–2135 (2018). https://springerlink.bibliotecabuap.elogim.com/content/pdf/10.1007%2Fs00170-018-2099-2.pdf
Tim, B.-L.: Semantic Web - XML2000: Architecture. https://www.w3.org/2000/Talks/1206-xml2k-tbl/slide10-0.html
Eine, B., Jurisch, M., Quint, W.: Ontology-based big data management. Systems 5(3), 45 (2017)
Holanda, O., Isotani, S., Bittencourt, I.I., Elias, E., Tenório, T.: JOINT: Java ontology integrated toolkit. Expert Syst. Appl. 40(16), 6469–6477 (2013)
Hoppe, T., et al.: Corporate semantic web – applications, technology, methodology. Inform. Spektrum 39(1), 57–63 (2016)
Peffers, K., Tuunanen, T., Rothenberger, M.A., Chatterjee, S.: A design science research methodology for information systems research. J. Manag. Inf. Syst. 24(3), 45–77 (2007)
Hee, K.: Object-oriented modeling, simulation and automatic generation of PLC ladder logic. In: Affonso, L. (ed.) Programmable Logic Controller. InTech (2010)
Lindow, K., Riedelsheimer, T., Lünnemann, P., Stark, R.: Betrachtung des Entwicklungsumfeldes durch die methodische Datenflussanalyse. ProduktDaten J. 2, 52–56 (2017)
Thangaraj, M., Sujatha, G.: An architectural design for effective information retrieval in semantic web. Expert Syst. Appl. 41(18), 8225–8233 (2014)
Guermah, H., Tarik, F., Hafiddi, H., Nassar, M., Kriouile, A.: An ontology oriented architecture for context aware services adaptation. ArXiv abs/1404.3280 (2014)
Harris, S., Seaborne, A.: SPARQL 1.1 Query Language. W3C Recommendation, 21 March 2013. https://www.w3.org/TR/2013/REC-sparql11-query-20130321/
Horridge, M.: A practical guide to building OWL ontologies. http://mowl-power.cs.man.ac.uk/protegeowltutorial/resources/ProtegeOWLTutorialP4_v1_3.pdf
Telnarova, Z.: Relational database as a source of ontology creation. In: Proceedings of the International Multiconference on Computer Science and Information Technology, Wisla, pp. 135–139 (2010)
Louhdi, M.R.C., Behja, H., El Alaoui, S.O.: Transformation rules for building OWL ontologies from relational databases. In: Computer Science & Information Technology (CS & IT), pp. 271–283 (2013)
Chujai, P., Kerdprasop, N., Kerdprasop, K.: On transforming the ER model to ontology using Protégé OWL tool. IJCTE 6(6), 484–489 (2014)
Calvanese, D., et al.: Ontop: answering SPARQL queries over relational databases. SW 8(3), 471–487 (2016). http://www.semantic-web-journal.net/system/files/swj1004.pdf
rdf4j, Welcome to RDF4 J. https://rdf4j.org/
Oleksiy, K.: Lecture 5: Programming with Semantic Web (RDF4 J and Jena APIs). University of Jyväskylä (2018)
Davis, F.D.: Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Q. 13(3), 319 (1989)
Acknowledgements
This project is funded by the Europäischer Fonds für regionale Entwicklung (EFRE).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Gogineni, S., Exner, K., Stark, R., Nickel, J., Oeler, M., Witte, H. (2019). Semantic Assistance System for Providing Smart Services and Reasoning in Aero-Engine Manufacturing. In: Garoufallou, E., Fallucchi, F., William De Luca, E. (eds) Metadata and Semantic Research. MTSR 2019. Communications in Computer and Information Science, vol 1057. Springer, Cham. https://doi.org/10.1007/978-3-030-36599-8_8
Download citation
DOI: https://doi.org/10.1007/978-3-030-36599-8_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-36598-1
Online ISBN: 978-3-030-36599-8
eBook Packages: Computer ScienceComputer Science (R0)