
Abstract
Over the last years, a number of Knowledge Graph (KG) based Question Answering (QA) systems have been developed. Consequently, the series of Question Answering Over Linked Data (QALD1–QALD9) challenges and other datasets have been proposed to evaluate these systems. However, the QA datasets contain a fixed number of natural language questions and do not allow users to select micro benchmarking samples of the questions tailored towards specific use-cases. We propose QaldGen, a framework for microbenchmarking of QA systems over KGs which is able to select customised question samples from existing QA datasets. The framework is flexible enough to select question samples of varying sizes and according to the user-defined criteria on the most important features to be considered for QA benchmarking. This is achieved using different clustering algorithms. We compare state-of-the-art QA systems over knowledge graphs by using different QA benchmarking samples. The observed results show that specialised micro-benchmarking is important to pinpoint the limitations of the various QA systems and its components.
Resource Type: Evaluation benchmarks or Methods
Repository: https://github.com/dice-group/qald-generator
License: GNU General Public License v3.0
K. Singh and M. Saleem—These two authors contributed equally as first author.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


1 Introduction
Question answering (QA) systems provide users with an interactive way to extract useful information from various sources such as documents, knowledge graphs, relational tables, etc. by posing questions in natural language or as voice input. Since the initial stages of TREC challenge for QA over Web data in the year 1999 [33], researchers have developed several novel approaches that include question answering over structured and unstructured data sources [10, 11]. Publicly available Knowledge Graphs (KGs) provide a rich source of structured information. Since 2010 more than 62 QA systems have been developed over KGs including DBpedia [1], Freebase [3] and Wikidata [34] as underlying knowledge source [9]. The question answering approaches over KGs can be broadly categorised into three categories based on their implementation [24]: the first category is semantic parsing based QA systems that heavily use linguistic principles such as POS tagging, dependency parsing, and entity recognition for extracting answers of the input question. It is often the case that there is no (or little) training data. The second category is end-to-end machine learning based QA systems that require large amounts of training data (e.g., [10]). Lastly, a recently introduced collaborative QA systems development focuses on building QA systems by reusing several existing QA systems and components (e.g. OKBQA [4]). Several independent components (e.g. EARL [7], Falcon [18], SQG [36]) perform tasks such as named entity disambiguation, relation linking, and SPARQL query generator for building QA systems in collaborative efforts have also been released by the semantic web research community.
Research Gap: Irrespective of the approaches opted for by researchers for the implementation, QA systems and components over knowledge graphs have been evaluated using several standard datasets such as LC-QuAD [28], QALD [29], and WebQuestion [2]. Nearly all report the results using the global metrics of precision, recall, and F-score as performance indicators [33]. Benchmarking Frameworks such as Gerbil [32] or leader boardsFootnote 1 also follow the same principle and outline the final results based on the global performance metric. The results are calculated as average over all the (test) questions of the dataset and indicates the overall gain/loss in the performance w.r.t state of the art. However, it does not shed any light on the strength or weakness of a particular QA system and component. This allows the same issue to persist over time causing performance limitation of the QA system. For example, Muldoven et al. [16] pointed out in the year 2003 that answer type (boolean, count, list) and Wh-type questions (what, who, etc.) have an impact on the performance of the open domain QA systems. Saleem et al. [20] recently raised similar issues pertaining to QA systems over DBpedia. For instance, the overall winner of the 6th edition of the Question Answering over Linked Data Challenge (QALD6) was CANALI, which suffered limitations when the question started with "Give me". CANALI is outperformed by another QA systems UTQA for such type of questions [20]. Similarly, the capitalisation of entity labels (surface forms) in a sentence is an issue reported by Derczynski et al. [5] by performing an in-depth analysis of entity linking tools. Sakor et al. [18] and Singh et al. [26, 27] again reported this issue in state of the art entity linking tools evaluated over standard QA datasets. Therefore, it is evident that the common practice of reporting results average over all the questions of the dataset (often referred as macro evaluation) does not always reveal details on state-of-the-art pitfalls, limitations, strengths, and potentials for further QA research.
Motivation and Contributions. There are concrete pieces of evidence in the literature that question features such as “headword”, “answer type”, number of triples in SPARQL queries, explicit (exact string match between the entity candidate and KG mention) and implicit (no exact match i.e. mapping NYC to dbr:New_York_CityFootnote 2) nature of entities, etc. have an impact on the performance of the QA systems and the QA components [9, 18, 20, 26, 27]. Furthermore, question classification has been a long-standing field of research where researchers have focused on identifying several such features [12]. This motivates our work and in this article, we provide a reusable resource QaldGen for the community to select personalised question samples for microbenchmarking QA systems over the DBpedia knowledge graph. QaldGen uses state-of-the-art clustering algorithms to cluster most prominent questions by using distance metrics. QaldGen further allows researchers to select personalised question samples based on specific question features that evidently impact the performance of a QA system or component. We not only provide QaldGen for the QA system but also to evaluate several QA components that can be reused in collaborative QA frameworks for tasks such as named entity disambiguation (NED), relation linking (RL) (for mapping natural language relations to KG), and SPARQL query generator (Query Builder). Our contributions are two-fold:
-
 :
: -
QaldGenData - An RDF Dataset for Personalised Microbenchmarking: We automatically annotated a total 5408 questions from QALD9 and LC-QuAD datasets with 51 features and converted it into RDF format. This dataset can be reused in training machine learning approaches related to question answering.
-
 :
: -
QaldGen -A Personalised Question Sample Generator: We collected 51 question features from existing literature that impact the performance of the QA systems and components. A user can choose one or multiple question features to be included in the customised question sample for microbenchmarking. QaldGen selects personalised question samples of variable sizes using clustering algorithms from two standard datasets over DBpedia: QALD9 [17], containing 408 questions consolidating previous QALD editions and LC-QuAD [28], having 5000 questions. A user can customise questions (in terms of the number of question and the number of diverse features) using QaldGen to evaluate their QA system or the component either independently or using benchmarking frameworks such as Gerbil [32] or the Frankenstein platform [25].
 :
: :
:The rest of this paper is organised as follows: the next section describes our two resources and approach to build QaldGen. Section 4 presents the importance and impact of this work for the research community. Section 5 presents our plan for availability and sustainability of resources. Section 6 reviews the state of the art and we close with the conclusion and future work in Sect. 7.
2 QaldGen Question Sample Generator
In this section, we present the question sampling process in the QaldGen. We first discuss the
 dataset that we use as input for the QaldGen question sample generation framework. We then discuss the question sampling process along with the personalised micro benchmark generation.
dataset that we use as input for the QaldGen question sample generation framework. We then discuss the question sampling process along with the personalised micro benchmark generation.

A tree of features attached to QaldGen dataset questions. L(X) stands for number of words in X.TPs = number of triple patterns, Proj. Vars = number of projection variables
2.1 QaldGen Dataset
Our framework takes a set of natural language questions as input and selects the required sample of questions according to the user-defined criteria. We use our
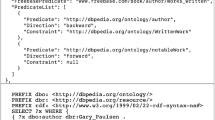
 dataset as input to QaldGen where customised question samples will be selected from. As mentioned before, this RDF dataset of QA is selected from QALD9 and LC-QuAD which contains a total of 5408 questions. A QA benchmark should be comprising of questions/tests of varying question features. To this end, we have attached a total of 51 important QA related features summarised in Fig. 1. We divide these features according to the question and the corresponding answer. The features attached to the question are related to the entities, relations and classes used in the SPARQL query, along with the natural language features such as headword, POS tags, etc. In addition, we store the number of words in the question and the origin (QALD9 or LC-QuAD) of the question. Each question has a SPARQL query to be executed to get the correct answers. We store SPARQL related features such as the number of projection variables, number of triple patterns, number of BGPs, filters, regex etc. A sample RDF representation of a QaldGen question is available in the listing 1.1. We re-used the Linked SPARQL Queries (LSQ) [19] vocabulary to represent the SPARQL query related features. In addition, we re-used properties from the QALD JSON datasets.
dataset as input to QaldGen where customised question samples will be selected from. As mentioned before, this RDF dataset of QA is selected from QALD9 and LC-QuAD which contains a total of 5408 questions. A QA benchmark should be comprising of questions/tests of varying question features. To this end, we have attached a total of 51 important QA related features summarised in Fig. 1. We divide these features according to the question and the corresponding answer. The features attached to the question are related to the entities, relations and classes used in the SPARQL query, along with the natural language features such as headword, POS tags, etc. In addition, we store the number of words in the question and the origin (QALD9 or LC-QuAD) of the question. Each question has a SPARQL query to be executed to get the correct answers. We store SPARQL related features such as the number of projection variables, number of triple patterns, number of BGPs, filters, regex etc. A sample RDF representation of a QaldGen question is available in the listing 1.1. We re-used the Linked SPARQL Queries (LSQ) [19] vocabulary to represent the SPARQL query related features. In addition, we re-used properties from the QALD JSON datasets.
The benefit of this dataset is that it can be directly queried using SPARQL and easily can be used in wide range of Linked Data and Semantic Web applications. In addition, each question has more features attached as compared to the original QALD9 and LC-QuAD datasets.

2.2 Question Sample Generation for Microbenchmarking
First, we define our question sampling generation problem and then explain the generation process. Our Question Sampling problem is defined as follows:
Definition 1 (Question Sampling Problem)
Let L represent the set of input natural language questions. Our goal is to select the N questions that best represent L as well as being more diverse in features, with \(N \ll |L|\).
Figure 2 shows the general steps involved in the QaldGen question sample generation process. The user provides the input
 RDF dataset, the required number N of questions and the selection criteria (as SPARQL query) to be considered in the question sampling for microbenchmarking. Then, the sampling is carried out in the following four main steps: (1) Select all the questions along with the required features from the input QaldGenData RDF dataset. (2) Generate feature vectors and their normalisation for the selected questions. (3) Generate N number of clusters from the questions. (4) Select single most representative questions from each cluster to be included in the final question sample requested by the user.
RDF dataset, the required number N of questions and the selection criteria (as SPARQL query) to be considered in the question sampling for microbenchmarking. Then, the sampling is carried out in the following four main steps: (1) Select all the questions along with the required features from the input QaldGenData RDF dataset. (2) Generate feature vectors and their normalisation for the selected questions. (3) Generate N number of clusters from the questions. (4) Select single most representative questions from each cluster to be included in the final question sample requested by the user.

QaldGen Sampling process.
Selection of Questions. We can select questions along with the required features by simply using SPARQL queries over QaldGenData RDF dataset. The QaldGen sampling framework retrieves the set of questions along with the required important features (can be any of the 51 features attached to each question) by using a single SPARQL query. For example, the SPARQL query given in Listing 1.2 retrieves all the questions from QaldGen RDF dataset along with the features: the total number of words, entities, relations, classes along with average words per entity in the question. In addition, it considers the number of triple patterns, the number of answers, the number of BGPs, and the number of projection variables. In other words, the user can select any number of features that are considered important for microbenchmarking. The result of this query execution is stored in a map that is used in the subsequent sampling steps. In Sect. 2.3, we show how this query can be modified to select customised samples for microbenchmarking.

Normalised Feature Vectors. The cluster generation algorithms (explained in the next section) require distances between questions to be computed. Each question (that was retrieved in the previous step) from the input QaldGenData dataset is mapped to a vector of length equal to the number of retrieved features. The vector stores the corresponding question features that were retrieved along with the input questions. To ensure that dimensions with high values do not bias the selection of questions for benchmarking, we normalise the question feature vectors with values between 0 and 1. This is to ensure that all questions are located in a unit hypercube. At this point, each of the individual values in every feature vector is divided by the overall maximal value (across all the vectors) for that question feature.
Generation of Clusters. As a next step, we generate N clusters from the given input QaldGen question represented as normalised feature vectors. For this step we used 5 existing well-known algorithms – FEASIBLE [21], FEASIBLE-Exemplars [21], KMeans++, DBSCAN+KMeans++, Random selection – which allow the generation of the required fixed number of clusters. Note DBSCAN+KMeans++ means that we applied DBSCAN first to remove the outlier queries and then applied KMeans++ to generate the required number of clusters. Please also consider that we need an additional normalisation of the remaining vectors after outliers are removed. Moreover, our framework is flexible enough to integrate any other clustering algorithm and allows the generation of a fixed number of clusters.
Selection of Most Representative Questions. Finally, we perform the selection of a single prototypical question from each cluster. This step is exactly the same as performed in FEASIBLE [21]: For each cluster S, compute the centroid c which is the average of the feature vectors of all the queries in S. Following this, compute the distance of each query in S with c and select the query of minimum distance to include in the resulting benchmark. The final output of the QaldGen sampling generator is an RDF file containing the finally selected natural language questions along with the complete list of attached features. Thus the RDF output can be directly queried using SPARQL. Current QA benchmark execution frameworks such as GERBIL [32] require the benchmark to be represented in JSON format. Thus, QaldGen is also able to select GERBIL compatible QA benchmarks.
Our framework also allows the generation of question samples using random selection. In addition, it allows the generation of samples using Agglomerative clustering [21]. However, Agglomerative clustering does not allow the creation of fixed size samples. The QaldGen website contains the CLI options for the generation of benchmarks.
2.3 Question Sample Personalisation
As mentioned before, our framework allows customised question sample generation according to the criteria specified by the user. This can be done by simply specialising the query given in Listing 1.2. For example, imagine the user wants to select customised samples with the following features: The question sample should only be selected from QALD9 and hence skipping LC-QuAD questions. The personalised sample should only contain “what”-type questions, and the number of triple patterns should be greater than 1 and there should be at least one answer of this question. The query for the selection of such a personalised benchmark is given in Listing 1.3. Users can use such personalised question samples to micro benchmark the QA system.

2.4 Diversity of Question Samples
The selected sample should not be mostly comprised of a similar type of natural language question. To ensure the overall quality of the selected sample, sufficient diversity in the micro benchmarking questions is important, which QaldGen is able to select using different clustering algorithms. We define their diversity as follows:
Definition 2 (Question Sample Diversity)
Let \(\mu _i\) mean and \(\sigma _i\) the standard deviation of a given distribution w.r.t. the i\(^{th}\) feature of the said distribution. Let B be a question sample extracted from a set of queries L. The diversity score D is the average standard deviation of the query features k included in the sample B:
The command line tool provided on the project website will report the diversity score after the generation of the desired QA benchmark.
3 Evaluation and Results
In this section, we describe our evaluation setup and the results.
3.1 Experiment Setup
Micro Benchmarking: We used three personalised question samples in our evaluation at a micro level: (1) a 200 question sample was used to compare the QA systems. We used the FEASIBLE-Exemplars clustering method because it had the highest diversity score. We used the query given in Listing 1.2 to select the input questions for QaldGen. (2) a 100 question sample was selected using FEASIBLE-Exemplars to test the named entity disambiguation (NED) tools. In this benchmark we only consider features related to the named entities like the number of entities, the number of words in entities etc. (3) a 100 question sample was generated using FEASIBLE-Exemplars to test the relation linking (RL) tools. In this sample, we only considered features related to the relations used in the questions like number relations, number of words in relations, etc.
QA Systems: We compared all the systems which took part in the QALD9 challenge [17] and which are currently part of Gerbil framework. However, only ganswer2 and QUEPY were online and returned answers. We used QaldGen extension integrated in Gerbil to calculate the results. This also illustrates the adaptability and compatibility of
 into a generic benchmarking framework. The results can be also found at persistent URI provided by GerbilFootnote 3.
into a generic benchmarking framework. The results can be also found at persistent URI provided by GerbilFootnote 3.
NED and RL Tools: We also extended our evaluation study at component level. We evaluated the top-2 components over LC-QuADFootnote 4 performing NED (DBpedia Spotlight [15] and TagMe [8]) and RL tasks (RNLIWODFootnote 5 and EARL [7]), respectively. For this study, we utilised the Frankenstein framework because these tools are already part of the frameworkFootnote 6. The customised questions selected by QaldGen are uploaded in Frankenstein to calculate the final results.
3.2 Experiment Results
Table 1 summarises our evaluation results and we employ the performance metric of Precision (P), Recall (R), and F-Score (F) for reporting the resultsFootnote 7. It is clearly observable in the table that the performance of QA systems and components fluctuate when customised question samples were selected using QaldGen. For instance, ganswer2 is the overall winner of QALD9, however, for a diverse set of 200 questions selected by QaldGen, QUEPY is the winner. This clearly show that performance of QA systems vary with the diversity of questions used in the evaluation. It is highly possible that a QA system is tuned for a particular type of question and may not perform well when exposed to question samples of varying diversity while performing microbenchmarking. In addition, a QA system designed for a particular use-case should only be tested with a use-case specific micro benchmark. Such systems will likely not perform well when tested with general QA benchmarks. For NED tools, TagMe remains the overall winner for macro and micro evaluation but its F-score drops sharply over customised sampling questions. When we consider specific question features (total number of entities as two and more than two words in the entity label) for generating a personalised question sample, the performance of TagMe is limited. In the case of RL tools, EARL outperforms RNLIWOD when we selected a personalised question sample with particular question features (explicit relations, number of relations = 1). It provides a clear indication of the strength of the EARL tool for a particular type of questions. Please note that in the scope of this paper, we are not analysing the architecture of the QA systems and components to understand the performance variation for specific question features. Our aim is to illustrate with empirical results that the term “baseline or state of the art” solely depends on the type of questions and considered features. Therefore, using our reusable resources, developers can better understand the strength or weaknesses of their tools by evaluating their tools at micro level.
 . For instance, QUEPY is the new baseline outperforming ganswer2 (overall baseline of QALD9 dataset) on the customised benchmark selected by QaldGen. Similar performance variation has been observed in the tools performing NED and RL tasks.
. For instance, QUEPY is the new baseline outperforming ganswer2 (overall baseline of QALD9 dataset) on the customised benchmark selected by QaldGen. Similar performance variation has been observed in the tools performing NED and RL tasks.4 Impact
38 QA systems from over 40 research groups in the semantic web community have participated in nine editions of QALD [17]. The LC-QuAD dataset has also gained recognition and is already cited 25 times since its release in October 2018 [28]. However the same issues of question ambiguity, capitalisation of entity labels, complex questions, implicit/explicit nature of entity and relation label, etc. are reported repeatedly in the evaluation studies [9, 20, 26].
In this article, we provide the semantic web community with two reusable resources for micro benchmarking of QA components and systems. Please note that we are not proposing any new benchmarking dataset or a benchmarking framework such as Frankenstein [25] or Gerbil [31]. We reuse the existing QA datasets (QALD9 and LC-QuAD) over DBpedia and in addition have developed
 that can be reused by QA developers to select personalised question samples for micro benchmarking their systems and components. This is the first step towards a more fine grained evaluation of QA systems and we expect the QA community to utilise
that can be reused by QA developers to select personalised question samples for micro benchmarking their systems and components. This is the first step towards a more fine grained evaluation of QA systems and we expect the QA community to utilise
 to dig deeper into the strength and weaknesses of their systems. Similar effort has also been started towards micro-benchmarking entity linking tools [35], however micro benchmarking of QA components and systems is a major research gap. Our second resource
to dig deeper into the strength and weaknesses of their systems. Similar effort has also been started towards micro-benchmarking entity linking tools [35], however micro benchmarking of QA components and systems is a major research gap. Our second resource
 can be reused by developers as a rich source of questions represented in RDF format with its features. Furthermore, we hope fine grained benchmarking of QA systems will trigger discussion within the community to release datasets with diverse question features.
can be reused by developers as a rich source of questions represented in RDF format with its features. Furthermore, we hope fine grained benchmarking of QA systems will trigger discussion within the community to release datasets with diverse question features.
5 Adoption and Reusability
The resources
 and
and
 are licensed under the GNU General Public License v3.0 and publicly available for reuse. Detailed instructions are provided for the easy adaptability of the resources. Developers can either use the proposed resources independently or can select personalised benchmarking questions using
are licensed under the GNU General Public License v3.0 and publicly available for reuse. Detailed instructions are provided for the easy adaptability of the resources. Developers can either use the proposed resources independently or can select personalised benchmarking questions using
 and adapt it for benchmarking frameworks. For community adaptation, both resources are made compatible with Gerbil [31] and Frankenstein framework [25]. Furthermore, Gerbil supports an easy extension of its core architecture and it is a widely used platform for calculating global performance metrics of QA systems and entity linking components. The maven version of
and adapt it for benchmarking frameworks. For community adaptation, both resources are made compatible with Gerbil [31] and Frankenstein framework [25]. Furthermore, Gerbil supports an easy extension of its core architecture and it is a widely used platform for calculating global performance metrics of QA systems and entity linking components. The maven version of
 has already been integrated with Gerbil. Therefore, researchers can choose customised benchmarking questions based on their needs, and use Gerbil to calculate the global performance metric for a sub-set of customised questions selected by
has already been integrated with Gerbil. Therefore, researchers can choose customised benchmarking questions based on their needs, and use Gerbil to calculate the global performance metric for a sub-set of customised questions selected by
 . The extension of Gerbil with QaldGen is already completed and it is available for public reuse in official Github repository of GerbilFootnote 8.
. The extension of Gerbil with QaldGen is already completed and it is available for public reuse in official Github repository of GerbilFootnote 8.
6 Related Work
QA Systems and Macro Benchmarking: TREC QA series [33] for evaluating open domain question answering was one of the earlier attempts in the direction of providing researchers with standard datasets and a performance metric for benchmarking QA systems. Question answering over KG gained momentum in the last decade after the inception of publicly available KGs such as DBpedia and Freebase. Datasets such as SimpleQuestionsFootnote 9 and WebQuestions [2] are commonly used for evaluating QA systems that employ Freebase as the underlying KG. For benchmarking QA systems over DBpedia, the QALD series was launched in 2011Footnote 10 and is currently running its 9th edition. In the last 8 years, over 38 QA systems using DBpedia as the underlying KG have been evaluated using QALD [9]. However, the maximum number of questions in QALD is 408 which hinders the development of machine learning based approaches. In contrast with QALD, LC-QuAD dataset provides a rich and diverse set of 5000 complex questions for DBpedia [28]. Recently developed QA systems and frameworks also report results on LC-QuAD [6, 13, 27]. However, the reported results across these datasets are on macro level i.e. an average on all questions of the dataset.
Question Classification and Micro Benchmarking: Question classification techniques aim to classify questions based on several features that may impact the overall performance of the QA system [12]. In the semantic web community, Usbeck et al. [30] first attempted to use question classification and question features such as headword, answer type, entity type, etc were extracted to provide a labelled representation of each question. Classifiers were trained using these features to choose a QA system among six that can potentially answer an input question. This approach resulted in an increase in the overall performance of the proposed hybrid QA system. Saleem et al. [20] used question classification to micro benchmark (i.e. reporting results based on the type of the questions containing specific features) QA systems to understand the strengths and the weaknesses. The authors conclude that a QA system which is the overall winner for all questions of the QALD-6 dataset is not always the winner for the questions with particular features. This empirical study also revealed that macro F-score (average on all questions) varies a lot based on the type of questions. For example, the highest reported F-score for all questions is 0.89 (CANALI QA system [14]). However, for a specific type of questions starting with “Give me” (e.g. Give me all cosmonauts.), F-score sharply drops to 0.34 and the UTQA QA system outperforms CANALI. Singh et al. [26, 27] extended the concept of micro-benchmarking to QA component level where exhaustive evaluations of 28 QA components including 20 named entity disambiguation, five relation linking, two class linking, and two SPARQL query generator have been performed using over 3000 questions from LC-QuAD. The authors observe significant fluctuation of the F-score even at the component level published in the extended study of Frankenstein framework [26]. For example, SINA [23] generates SPARQL queries which requires DBpedia URIs of entities and predicates present in the question as input. SINA is the baseline (F-Score 0.80) for the subset of 729 questions from LC-QuAD having SPARQL queries with two triples compared to the overall winner (F-score 0.48 reported by NLIWOD component) on all the questions of LC-QuAD dataset considered by authors. However, when the number of triples in SPARQL queries is four, SINA reports F-score 0.0 for a subset of 1256 questions. The above-mentioned micro-benchmarking studies provide a foundation to our work. We reuse all the question features reported by [20, 27] in QaldGen for micro benchmarking.
The work by Waitelonis et al. [35] proposes fine-grained benchmarking of entity linking tools using the Gerbil framework [32] based on the features of entity type (person, organisation, place). This work is most closely related to our approach. Unlike QaldGen, the above-mentioned work is limited to the entity linking tools whereas the novelty of QaldGen is to provide a reusable resource for the fine-grained micro-benchmarking study of the QA systems and reusable components for QA frameworks performing various tasks (e.g. NED, RL, Query Builder).
Finally, there are benchmark generators available for SPARQL queries [21] to test the runtime performances of triplestores, and SPARQL query containments [22] to test the query containments solvers. However, to the best of our knowledge, there was no QA over Linked Data benchmark generator available to generator customised benchmarks.
7 Conclusion and Future Work
In this paper, we present two reusable resources for generating personalised question samples for micro benchmarking question answering systems over knowledge graphs, more specifically DBpedia. Our first offered resource
 is QaldGen. QaldGen uses state of the art clustering algorithms to cluster the most diverse or similar questions based on the features that impact the overall performance of QA systems. QaldGen is compatible with Gerbil and Frankenstein framework. Hence developers can directly use these frameworks to compare their system with state of the art on specific questions selected by QaldGen for personalised micro benchmarking.
is QaldGen. QaldGen uses state of the art clustering algorithms to cluster the most diverse or similar questions based on the features that impact the overall performance of QA systems. QaldGen is compatible with Gerbil and Frankenstein framework. Hence developers can directly use these frameworks to compare their system with state of the art on specific questions selected by QaldGen for personalised micro benchmarking.
The second resource
 is a collection of 5408 questions from two standard datasets with a diverse representation of 51 features in each question. In the previous works [21, 27, 30], QA developers extracted such features multiple times for different research studies. Using
is a collection of 5408 questions from two standard datasets with a diverse representation of 51 features in each question. In the previous works [21, 27, 30], QA developers extracted such features multiple times for different research studies. Using
 , researchers can now select question features they would like to consider for training machine learning algorithms rather than extracting the features again from scratch. We believe that using our resources, researchers can now evaluate their systems on their specific needs. We also hope that our work will trigger discussion in the QA community to come up with a dataset containing more diverse question features and start reporting performance at the micro level. We plan to extend this work in three directions (1) extend questions to other knowledge graphs such as Wikidata (2) include more datasets in the
, researchers can now select question features they would like to consider for training machine learning algorithms rather than extracting the features again from scratch. We believe that using our resources, researchers can now evaluate their systems on their specific needs. We also hope that our work will trigger discussion in the QA community to come up with a dataset containing more diverse question features and start reporting performance at the micro level. We plan to extend this work in three directions (1) extend questions to other knowledge graphs such as Wikidata (2) include more datasets in the
 and (3) develop a similar micro-benchmarking approach for open domain question answering datasets such as reading comprehension.
and (3) develop a similar micro-benchmarking approach for open domain question answering datasets such as reading comprehension.
Notes
- 1.
- 2.
Prefix dbr is bound to http://dbpedia.org/resource/.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
References
Auer, S., Bizer, C., Kobilarov, G., Lehmann, J., Cyganiak, R., Ives, Z.: DBpedia: a nucleus for a web of open data. In: Aberer, K., et al. (eds.) ASWC/ISWC -2007. LNCS, vol. 4825, pp. 722–735. Springer, Heidelberg (2007). https://doi.org/10.1007/978-3-540-76298-0_52
Berant, J., Chou, A., Frostig, R., Liang, P.: Semantic parsing on freebase from question-answer pairs. In: Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, EMNLP 2013, pp. 1533–1544. ACL (2013)
Bollacker, K.D., Evans, C., Paritosh, P., Sturge, T., Taylor, J.: Freebase: a collaboratively created graph database for structuring human knowledge. In: ACM SIGMOD, pp. 1247–1250 (2008)
Choi, K.-S., Mitamura, T., Vossen, P., Kim, J.-D., Ngomo, A.-C.N.: SIGIR 2017 workshop on open knowledge base and question answering (OKBQA 2017). In: Proceedings of the ACM SIGIR, pp. 1433–1434 (2017)
Derczynski, L., et al.: Analysis of named entity recognition and linking for tweets. Inf. Process. Manag. 51(2), 32–49 (2015)
Diefenbach, D., Both, A., Singh, K., Maret, P.: Towards a question answering system over the semantic web. arXiv preprint arXiv:1803.00832 (2018)
Dubey, M., Banerjee, D., Chaudhuri, D., Lehmann, J.: EARL: joint entity and relation linking for question answering over knowledge graphs. In: Vrandečić, D., et al. (eds.) ISWC 2018. LNCS, vol. 11136, pp. 108–126. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-00671-6_7
Ferragina, P., Scaiella, U.: TAGME: on-the-fly annotation of short text fragments (by Wikipedia entities). In: Proceedings of the 19th ACM Conference on Information and Knowledge Management, CIKM 2010, Toronto, Ontario, Canada, 26–30 October 2010, pp. 1625–1628. ACM (2010)
Höffner, K., Walter, S., Marx, E., Usbeck, R., Lehmann, J., Ngomo, A.N.: Survey on challenges of question answering in the semantic web. Semant. Web 8(6), 895–920 (2017)
Huang, X., Zhang, J., Li, D., Li, P.: Knowledge graph embedding based question answering. In: Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, pp. 105–113. ACM (2019)
Li, F., Jagadish, H.V.: Constructing an interactive natural language interface for relational databases. PVLDB 8(1), 73–84 (2014)
Loni, B.: A survey of state-of-the-art methods on question classification (2011)
Maheshwari, G., Trivedi, P., Lukovnikov, D., Chakraborty, N., Fischer, A., Lehmann, J.: Learning to rank query graphs for complex question answering over knowledge graphs. arXiv preprint arXiv:1811.01118 (2018)
Mazzeo, G.M., Zaniolo, C.: Answering controlled natural language questions on RDF knowledge bases. In: EDBT, pp. 608–611 (2016)
Mendes, P.N., Jakob, M., García-Silva, A., Bizer, C.: DBpedia spotlight: shedding light on the web of documents. In: Proceedings the 7th International Conference on Semantic Systems, I-SEMANTICS 2011, Graz, Austria, 7–9 September 2011, pp. 1–8. ACM (2011)
Moldovan, D., Paşca, M., Harabagiu, S., Surdeanu, M.: Performance issues and error analysis in an open-domain question answering system. ACM Trans. Inf. Syst. (TOIS) 21(2), 133–154 (2003)
Ngomo, N.: 9th challenge on question answering over linked data (QALD-9). Language 7:1
Sakor, A., et al.: Old is gold: linguistic driven approach for entity and relation linking of short text. In: NAACL 2019. ACL (2019, to appear)
Saleem, M., Ali, M.I., Hogan, A., Mehmood, Q., Ngomo, A.-C.N.: LSQ: the linked SPARQL queries dataset. In: Arenas, M., et al. (eds.) ISWC 2015. LNCS, vol. 9367, pp. 261–269. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-25010-6_15
Saleem, M., Dastjerdi, S.N., Usbeck, R., Ngomo, A.N.: Question answering over linked data: what is difficult to answer? What affects the F scores? In: Joint Proceedings of BLINK 2017: Co-Located with (ISWC 2017), Austria (2017)
Saleem, M., Mehmood, Q., Ngonga Ngomo, A.-C.: FEASIBLE: a feature-based SPARQL benchmark generation framework. In: Arenas, M., et al. (eds.) ISWC 2015. LNCS, vol. 9366, pp. 52–69. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-25007-6_4
Saleem, M., Stadler, C., Mehmood, Q., Lehmann, J., Ngomo, A.-C.N.: SQCFramework: SPARQL query containment benchmark generation framework. In: Proceedings of the Knowledge Capture Conference, p. 28. ACM (2017)
Shekarpour, S., Marx, E., Ngomo, A.N., Auer, S.: SINA: semantic interpretation of user queries for question answering on interlinked data. J. Web Sem. 30, 39–51 (2015)
Singh, K.: Towards dynamic composition of question answering pipelines. Ph.D. thesis, University of Bonn, Germany (2019)
Singh, K., Both, A., Sethupat, A., Shekarpour, S.: Frankenstein: a platform enabling reuse of question answering components. In: Gangemi, A., et al. (eds.) ESWC 2018. LNCS, vol. 10843, pp. 624–638. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-93417-4_40
Singh, K., Lytra, I., Radhakrishna, A.S., Shekarpour, S., Vidal, M.-E., Lehmann, J.: No one is perfect: Analysing the performance of question answering components over the DBpedia knowledge graph. arXiv:1809.10044 (2018)
Singh, K., et al.: Why reinvent the wheel: let’s build question answering systems together. In: Web Conference, pp. 1247–1256 (2018)
Trivedi, P., Maheshwari, G., Dubey, M., Lehmann, J.: LC-QuAD: a corpus for complex question answering over knowledge graphs. In: d’Amato, C., et al. (eds.) ISWC 2017. LNCS, vol. 10588, pp. 210–218. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-68204-4_22
Unger, C., et al.: Question answering over linked data (QALD-5). In: Working Notes of CLEF 2015 - Conference and Labs of the Evaluation forum, Toulouse, France, 8–11 September 2015. CEUR-WS.org (2015)
Usbeck, R., Hoffmann, M., Röder, M., Lehmann, J., Ngomo, A.N.: Using multi-label classification for improved question answering. CoRR (2017)
Usbeck, R., et al.: Benchmarking question answering systems. Semant. Web J. (2019)
Usbeck, R., et al.: GERBIL: general entity annotator benchmarking framework. In: WWW 2015, pp. 1133–1143 (2015)
Voorhees, E.M., Harman, D.K. (eds.): Proceedings of The Eighth Text REtrieval Conference, TREC 1999, Gaithersburg, Maryland, USA, 17–19 November 1999, volume Special Publication, 500-246. National Institute of Standards and Technology (NIST) (1999)
Vrandecic, D.: Wikidata: a new platform for collaborative data collection. In: Proceedings of the 21st World Wide Web Conference, WWW 2012, Lyon, France, 16–20 April 2012 (Companion Volume), pp. 1063–1064. ACM (2012)
Waitelonis, J., Jürges, H., Sack, H.: Remixing entity linking evaluation datasets for focused benchmarking. Semant. Web 10(2), 385–412 (2019)
Zafar, H., Napolitano, G., Lehmann, J.: Formal query generation for question answering over knowledge bases. In: Gangemi, A., et al. (eds.) ESWC 2018. LNCS, vol. 10843, pp. 714–728. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-93417-4_46
Acknowledgments
This work has been supported by the project LIMBO (Grant no. 19F2029I), OPAL (no. 19F2028A), KnowGraphs (no. 860801), and SOLIDE (no. 13N14456)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Singh, K. et al. (2019). QaldGen: Towards Microbenchmarking of Question Answering Systems over Knowledge Graphs. In: Ghidini, C., et al. The Semantic Web – ISWC 2019. ISWC 2019. Lecture Notes in Computer Science(), vol 11779. Springer, Cham. https://doi.org/10.1007/978-3-030-30796-7_18
Download citation
DOI: https://doi.org/10.1007/978-3-030-30796-7_18
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-30795-0
Online ISBN: 978-3-030-30796-7
eBook Packages: Computer ScienceComputer Science (R0)
