
Abstract
Document classification is a challenging task with important applications. The deep learning approaches to the problem have gained much attention recently. Despite the progress, the proposed models do not incorporate the knowledge of the document structure in the architecture efficiently and not take into account the contexting importance of words and sentences. In this paper, we propose a new approach based on a combination of convolutional neural networks, gated recurrent units, and attention mechanisms for document classification tasks. We use of convolution layers varying window sizes to extract more meaningful, generalizable and abstract features by the hierarchical representation. The proposed method in improves the results of the current attention-based approaches for document classification.
J. Abreu and L. Fred—Contributed equally and are both first authors.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Text classification is one of the most classical and important tasks in the machine learning field. The document classification, which is essential to organize documents for retrieval, analysis, and curation, is traditionally performed by classifiers such as Support Vector Machines or Random Forests. As in different areas, the deep learning methods are presenting a performance quite superior to traditional approaches in this field [5]. Deep learning is also playing a central role in Natural Language Processing (NLP) through learned word vector representations. It aims to represent words in terms of fixed-length, continuous and dense feature vectors, capturing semantic word relations: similar words are close to each other in the vector space.
In most NLP tasks for document classification, the proposed models do not incorporate the knowledge of the document structure in the architecture efficiently and not take into account the contexting importance of words and sentences. Much of these approaches do not select qualitative or informative words and sentences since some words are more informative than others in a document. Moreover, these models are frequently based on recurrent neural networks only [6]. Since CNN has leveraged strong performance on deep learning models by extracting more abundant features and reducing the number of parameters, we guess it not only improves computational performance but also yields better generalization on neural models for document classification.
A recent trend in NLP is to use attentional mechanisms to modeling information dependencies without regard to their distance between words in the input sequences. In [6] is proposed a hierarchical neural architecture for document classification, which employs attentional mechanisms, trying to mirror the hierarchical structure of the document. The intuition underlying the model is that not all parts of a text are equally relevant to represent it. Further, determining the relevant sections involves modeling the interactions and importance among the words and not just their presence in the text.
In this paper, we propose a new approach for document classification based on CNN, GRU [4] hidden units and attentional mechanisms to improve the model performance by selectively focusing the network on essential parts of the text sentences during the model training. Inspired by [6], we have used the hierarchical concept to better representation of document structure. We call our model as Hierarchical Attentional Hybrid Neural Networks (HAHNN). We also used temporal convolutions [2], which give us more flexible receptive field sizes. We evaluate the proposed approach comparing its results with state-of-the-art models and the model shows an improved accuracy.
2 Hierarchical Attentional Hybrid Neural Networks
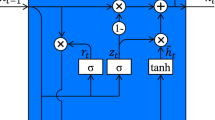
The HAHNN model combines convolutional layers, Gated Recurrent Units, and attention mechanisms. Figure 1 shows the proposed architecture. The first layer of HAHNN is a pre-processed word embedding layer (black circles in the Fig. 1). The second layer contains a stack of CNN layers that consist of convolutional layers with multiple filters (varying window sizes) and feature maps. We also have performed some trials with temporal convolutional layers with dilated convolutions and gotten promising results. Besides, we used Dropout for regularization. In the next layers, we use a word encoder applying the attention mechanism on word level context vector. In sequence, a sentence encoder applying the attention on sentence-level context vector. The last layer uses a Softmax function to generate the output probability distribution over the classes.
We use CNN to extract more meaningful, generalizable and abstract features by the hierarchical representation. Combining convolutional layers in different filter sizes with both word and sentence encoder in a hierarchical architecture let our model extract more rich features and improves generalization performance in document classification. To obtain representations of more rare words, by taking into account subwords information, we used FastText [3] in the word embedding initialization.
We investigate two variants of the proposed architecture. There is a basic version, as described in Fig. 1, and there is another which implements a TCN [2] layer. The goal is to simulate RNNs with very long memory size by adopting a combination of dilated and regular convolutions with residual connections. Dilated convolutions are considered beneficial in longer sequences as they enable an exponentially larger receptive field in convolutional layers. More formally, for a 1-D sequence input \(\mathrm {x} \in \mathbb {R}^{{ n}} \) and a filter \(f : \{0,..., k-1\} \rightarrow \mathbb {R}\), the dilated convolution operation F on element s of the sequence is defined as
where d is the dilatation factor, k is the filter size, and \( {s - d \cdot i}\) accounts for the past information direction. Dilation is thus equivalent to introducing a fixed step between every two adjacent filter maps. When d = 1, a dilated convolution reduces to a regular convolution. The use of larger dilation enables an output at the top level to represent a wider range of inputs, expanding the receptive field.

Our HAHNN architecture include an CNN layer after the embedding layer. In addition, we have created a variant which includes a temporal convolutional layer [2] after the embedding layer.
The proposed model takes into account that the different parts of a document have no similar relevant information. Moreover, determining the relevant sections involves modeling the interactions among the words, not just their isolated presence in the text. Therefore, to consider this aspect, the model includes two levels of attention mechanisms [1]. One structure at the word level and other at the sentence level, which let the model pay more or less attention to individual words and sentences when constructing the document representation.
The strategy consists of different parts: (1) A word sequence encoder and a word-level attention layer; and (2) A sentence encoder and a sentence-level attention layer. In the word encoder, the model uses bidirectional GRU to produce annotations of words by summarizing contextual information from both directions. The attention levels let the model pay more or less attention to individual words and sentences when constructing the representation of the document [6].
Given a sentence with words \( {w}_{it},t \in [0, T]\) and an embedding matrix \( {W_e}\), a bidirectional GRU contains the forward \(GRU \overrightarrow{f}\) which reads the sentence \(s_i\) from \(w_{i1}\) to \(w_{iT}\) and a backward \(GRU \overleftarrow{f}\) which reads from \(w_{iT}\) to \(w_{i1}\):
An annotation for a given word \( {w_{it}}\) is obtained by concatenating the forward hidden state and backward hidden state, i.e., \( {h_{it}} = [\overrightarrow{h_{it}}, \overleftarrow{h_{it}}]\), which summarizes the information of the whole sentence. We use the attention mechanism to evaluates words that are important to the meaning of the sentence and to aggregate the representation of those informative words into a sentence vector. Specifically,
The model measures the importance of a word as the similarity of \( {u_{it}}\) with a word level context vector \( {u_w}\) and learns a normalized importance weight \(\alpha _{it}\) through a softmax function. After that, the architecture computes the sentence vector \(s_i\) as a weighted sum of the word annotations based on the weights. The word context vector \(u_w\) is randomly initialized and jointly learned during the training process.
Given the sentence vectors \(s_i\), and the document vector, the sentence attention is obtained as:
The proposed solution concatenates \(h_i = [\overrightarrow{h_i}, \overleftarrow{h_i}]\) \(h_i\) which summarizes the neighbor sentences around sentence \( {i}\) but still focus on sentence \( {i}\). To reward sentences that are relevant to correctly classify a document, the solution again use attention mechanism and introduce a sentence level context vector \(u_s\) using it to measure the importance of the sentences:
In the above equation, v is the document vector that summarizes all the information of sentences in a document. Similarly, the sentence level context vector \(u_s\) can be randomly initialized and jointly learned during the training process. A fully connected softmax layer gives us a probability distribution over the classes. The proposed method is openly available in the github repositoryFootnote 1.
3 Experiments and Results
We evaluate the proposed model on two document classification datasets using 90% of the data for training and the remaining 10% for tests. The word embeddings have dimension 200 and we use Adam optimizer with a learning rate of 0.001. The datasets used are the IMDb Movie ReviewsFootnote 2 and Yelp 2018Footnote 3. The former contains a set of 25k highly polar movie reviews for training and 25k for testing, whereas the classification involves detecting positive/negative reviews. The latter include users ratings and write reviews about stores and services on Yelp, being a dataset for multiclass classification (ratings from 0–5 stars). Yelp 2018 contains around 5M full review text data, but we fix in 500k the number of used samples for computational purposes.
Table 1 shows the experiment results comparing our results with related works. Note that HN-ATT [6] obtained an accuracy of 72,73% in the Yelp test set, whereas the proposed model obtained an accuracy of 73,28%. Our results also outperformed CNN [6] and VDNN [7]. We can see an improvement of the results in Yelp with our approach using CNN and varying window sizes in filters. The model also performs better in the results with IMDb using both CNN and TCN.
3.1 Attention Weights Visualizations
To validate the model performance in select informative words and sentences, we present the visualizations of attention weights in Fig. 2. There is an example of the attention visualizations for a positive and negative class in test reviews. Every line is a sentence. Blue color denotes the sentence weight, and red denotes the word weight in determining the sentence meaning. There is a greater focus on more important features despite some exceptions. For example, the word “loving” and “amazed” in Fig. 2(a) and “disappointment” in Fig. 2(b).

Visualization of attention weights computed by the proposed model (Color figure online)
Occasionally, we have found issues in some sentences, where fewer important words are getting higher importance. For example, in Fig. 2(a) notes that the word “translate” has received high importance even though it represents a neutral word. These drawbacks will be taken into account in future works.
4 Final Remarks
In this paper, we have presented the HAHNN architecture for document classification. The method combines CNN with attention mechanisms in both word and sentence level. HAHNN improves accuracy in document classification by incorporate the document structure in the model and employing CNN’s for the extraction of more abundant features.
References
Bahdanau, D., et al.: Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473 (2014)
Bai, S., Kolter, J.Z., Koltun, V.: An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv preprint arXiv:1803.01271 (2018)
Bojanowski, P., et al.: Enriching word vectors with subword information. arXiv preprint arXiv:1607.04606 (2016). https://doi.org/10.1162/tacl_a_00051
Cho, K., et al.: Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078 (2014). https://doi.org/10.3115/v1/D14-1179
Kim, Y.: Convolutional neural networks for sentence classification. arXiv preprint arXiv:1408.5882 (2014). https://doi.org/10.3115/v1/D14-1181
Yang, Z., et al.: Hierarchical attention networks for document classification. In: Conference of the North American Chapter of the Association For Computational Linguistics: Human Language Technologies, San Diego, CA, USA, pp. 1480–1489 (2016). https://doi.org/10.18653/v1/N16-1174
Conneau, A., et al.: Very deep convolutional networks for text classification. arXiv preprint arXiv:1606.01781 (2016). https://doi.org/10.18653/v1/E17-1104
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Abreu, J., Fred, L., Macêdo, D., Zanchettin, C. (2019). Hierarchical Attentional Hybrid Neural Networks for Document Classification. In: Tetko, I., Kůrková, V., Karpov, P., Theis, F. (eds) Artificial Neural Networks and Machine Learning – ICANN 2019: Workshop and Special Sessions. ICANN 2019. Lecture Notes in Computer Science(), vol 11731. Springer, Cham. https://doi.org/10.1007/978-3-030-30493-5_39
Download citation
DOI: https://doi.org/10.1007/978-3-030-30493-5_39
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-30492-8
Online ISBN: 978-3-030-30493-5
eBook Packages: Computer ScienceComputer Science (R0)