
Abstract
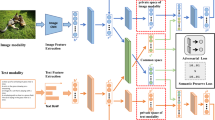
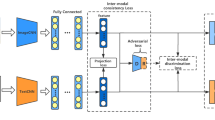
Cross-modal retrieval returns the relevant results from the other modalities given a query from one modality. The main challenge of cross-modal retrieval is the “heterogeneity gap” amongst modalities, because different modalities have different distributions and representations. Therefore, the similarity of different modalities can not be measured directly. In this paper, we propose a semantics consistent adversarial cross-modal retrieval approach, which learns a semantics consistent representation for different modalities with same semantic category. Specifically, we encourage the class center of different modalities with same semantic label to be as close as possible, and also minimize the distances between the samples and the class center with same semantic label from different modalities. Comprehensive experiments on Wikipedia dataset are conducted and the experimental results show the efficiency and effectiveness of our approach in cross-modal retrieval.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Rasiwasia, N., Costa Pereira, J., Coviello, E., Doyle, G., Lanckriet, G.R., Levy, R., Vasconcelos, N.: A new approach to cross-modal multimedia retrieval. In: International Conference on Multimedia, pp. 251–260 (2010)
Datta, R., Joshi, D., Li, J., Wang, J.Z.: Image retrieval: ideas, influences, and trends of the new age. ACM Comput. Surv. 40(2), 1–60 (2008)
Smeulders, A.W.M., Worring, M., Santini, S., Gupta, A., Jain, R.: Content-based image retrieval at the end of the early years. IEEE Trans. Pattern Anal. Mach. Intell. 22(12), 1349–1380 (2000)
Lu, H., Li, B., Zhu, J., Li, Y., Li, Y., Xu, X., He, L., Li, X., Li, J., Serikawa, S.: Wound intensity correction and segmentation with convolutional neural networks. Concurr. Comput. Pract. Exp. (2017). https://doi.org/10.1002/cpe.3927
Huimin, L., Li, Y., Chen, M., Kim, H., Serikawa, S.: Brain intelligence: go beyond artificial intelligence. Mob. Netw. Appl. 23(2), 368–375 (2018)
Peng, Y., Huang, X., Zhao, Y.: An overview of cross-media retrieval: concepts, methodologies, benchmarks and challenges. IEEE Trans. Circuits Syst. Video Technol. 1–14 (2017)
Serikawa, S., Huimin, L.: Underwater image dehazing using joint trilateral filter. Comput. Electr. Eng. 40(1), 41–50 (2014)
Wang, K., Yin, Q., Wang, W., Wu, S., Wang, L.: A comprehensive survey on cross-modal retrieval. CoRR (2016). arXiv:1607.06215
Cao, Y., Long, M., Wang, J., Yang, Q., Yu, P.S.: Deep visual semantic hashing for cross-modal retrieval. In: ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1445–1454 (2016)
Deng, C., Chen, Z., Liu, X., Gao, X., Tao, D.: Triplet-based deep hashing network for cross-modal retrieval. IEEE Trans. Image Process. 27(8), 3893–3903 (2018)
Kang, C., Xiang, S., Liao, S., Changsheng, X., Pan, C.: Learning consistent feature representation for cross-modal multimedia retrieval. IEEE Trans. Multimed. 17(3), 370–381 (2015)
Lu, H., Li, Y., Mu, S., Wang, D., Kim, H., Serikawa, S.: Motor anomaly detection for unmanned aerial vehicles using reinforcement learning. IEEE Internet Things J. (2018). https://doi.org/10.1109/JIOT.2017.2737479
Lu, H., Li, Y., Uemura, T., Kim, H., Serikawa, S.: Low illumination underwater light field images reconstruction using deep convolutional neural networks. Future Gen. Comput. Syst. (2018). https://doi.org/10.1016/j.future.2018.01.001
Tang, X., Yang, Y., Deng, C., Gao, X.: Coupled dictionary learning with common label alignment for cross-modal retrieval. IEEE Trans. Multimed. 18(2), 208–218 (2016)
Wei, Y., Zhao, Y., Canyi, L., Wei, S., Liu, L., Zhu, Z., Yan, S.: Cross-modal retrieval with cnn visual features: a new baseline. IEEE Trans. Cybern. 47(2), 449–460 (2016)
Li, X., Liu, Q., He, Z., Wang, H., Zhang, C., Chen, W.-S.: A multi-view model for visual tracking via correlation filters. Knowl. Based Syst. 113, 88–99 (2016)
Lin, Z., Ding, G., Hu, M., Wang, J.: Semantics-preserving hashing for cross-view retrieval. In: Proceedings of Computer Vision and Pattern Recognition, pp. 3864–3872 (2015)
Ou, M., Cui, P., Wang, F., Wang, J., Zhu, W., Yang, S.: Comparing apples to oranges: a scalable solution with heterogeneous hashing. In: Proceedings of the 19th SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 230–238 (2013)
Zhen,Y., Yeung, D.Y.: Co-regularized hashing for multimodal data. Neural Inf. Process. Syst. 2, 1376–1384 (2012)
Hardoon, D.R., Szedmak, S., Shawetaylor, J.: Canonical correlation analysis: an overview with application to learning methods. Neural Comput. 16(12), 2639–2664 (2004)
Jiang, Q., Li, W.: Deep cross-modal hashing. In: Proceedings of Computer Vision and Pattern Recognition, pp. 3270–3278 (2017)
Fei, W., Xinyan, L., Song, J., Yan, S., Zhang, Z.M., Yong, R., Zhuang, Y.: Learning of multimodal representations with random walks on the click graph. IEEE Trans. Image Process 25(2), 630–642 (2015)
Zhang, H., Yang, Y., Luan, H., Yang, S., Chua, T.S.: Start from scratch: Towards automatically identifying, modeling, and naming visual attributes. In: ACM International Conference on Multimedia, pp. 187–196 (2014)
Liu, Q., Xiaohuan, L., He, Z., Zhang, C., Chen, W.-S.: Deep convolutional neural networks for thermal infrared object tracking. Knowl. Based Syst. 134, 189–198 (2017)
Xu, X., He, L., Lu, H., Gao, L., Ji, Y.: Deep adversarial metric learning for cross-modal retrieval. In: World Wide Web (2018). https://doi.org/10.1007/s11280-018-0541-x
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. In: International Conference on Neural Information Processing Systems, pp. 2672–2680 (2014)
Wang, B., Yang, Y., Xu, X., Hanjalic, A., Shen, H.T.: Adversarial cross-modal retrieval. In: ACM on Multimedia Conference, pp. 154–162 (2017)
Peng, Y., Qi, J., Yuan, Y.: CM-GANs: cross-modal generative adversarial networks for common representation learning (2017). arXiv:1710.05106
Gong, Y., Ke, Q., Isard, M., Lazebnik, S.: A multi-view embedding space for modeling internet images, tags, and their semantics. Int. J. Comput. Vis. 106(2), 210–233 (2014)
Wang, K., He, R., Wang, W., Wang, L., Tan, T.: Learning coupled feature spaces for cross-modal matching. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2088–2095 (2013)
Zhai, X., Peng, Y., Xiao, J.: Learning cross-media joint representation with sparse and semisupervised regularization. IEEE Trans. Circuits Syst. Video Technol. 24(6), 965–978 (2014)
Wang, K., He, R., Wang, L., Wang, W., Tan, T.: Joint feature selection and subspace learning for cross-modal retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 38(10), 2010–2023 (2016)
Srivastava, N., Salakhutdinov, R.: Learning representations for multimodal data with deep belief nets. In: ICML Workshop, p. 79 (2012)
Ngiam, J., Khosla, A., Kim, M., Nam, J., Lee, H., Ng, A.Y.: Multimodal deep learning. In: Proceedings of the 28th International Conference on Machine Learning (ICML), pp. 689–696 (2011)
Feng, F., Wang, X., Li, R.: Cross-modal retrieval with correspondence autoencoder. In: Proceedings of the 22nd ACM International Conference on Multimedia, pp. 7–16 (2014)
van der Maaten, L., Hinton, G.: Visualizing data using t-SNE. J. Mach. Learn. Res. 9(11), 2579–2605 (2008)
Acknowledgements
Weihua Ou is the corresponding author of this paper. This work was partly supported by the National Natural Science Foundation of China (Grant No. 61762021, 61876093, 61402122, 61881240048), Natural Science Foundation of Guizhou Province (Grant No. [2017]1130), the 2014 Ph.D. Recruitment Program of Guizhou Normal University, Foundation of Guizhou Educational Department (KY[2016]027), HIRP Open 2018 Project of Huawei, the Natural Science Foundation of Educational Commission of Guizhou Province under Grant No. [2015]434, Guizhou Province Innovation Talents Team of Electrostatic and Electromagnetic Protection (No. QKHPTRC[2017]5653), Key Subjects Construction of Guizhou Province (ZDXK[2016]8).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this chapter

Cite this chapter
Xuan, R. et al. (2020). Semantics Consistent Adversarial Cross-Modal Retrieval. In: Lu, H. (eds) Cognitive Internet of Things: Frameworks, Tools and Applications. ISAIR 2018. Studies in Computational Intelligence, vol 810. Springer, Cham. https://doi.org/10.1007/978-3-030-04946-1_45
Download citation
DOI: https://doi.org/10.1007/978-3-030-04946-1_45
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-04945-4
Online ISBN: 978-3-030-04946-1
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)