
Abstract
Rotation symmetry is a salient visual clue in describing and recognizing an object or a structure in an image. Recently, various rotation symmetry detection methods have been proposed based on key point feature matching scheme. However, hand crafted representation of rotation symmetry structure has shown limited performance. On the other hand, deep learning based approach has been rarely applied to symmetry detection due to the huge diversity in the visual appearance of rotation symmetry patterns. In this work, we propose a new framework of convolutional neural network based on two core layers: rotation invariant convolution (RI-CONV) layer and symmetry structure constrained convolution (SSC-CONV) layer. Proposed network learns structural characteristic from image samples regardless of their appearance diversity. Evaluation is conducted on 32,000 images (after augmentation) of our rotation symmetry classification data set.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Symmetry is an essential structural clue in recognizing single object, grouped objects or scene structure. Reflection and rotation symmetry detection in 2D and 3D visual data have been studied in the past half-century [10,11,12]. Recent improvements in rotation symmetry detection mostly depends on carefully developed representation of rotation symmetry structure based on salient and robust key point or region feature matching. Even skewed rotation symmetry is described in the representation based on the study of camera projection [11] or approximation by affine projection [3]. However, not all aspect of distortion and variation of rotation symmetry structure can be predetermined and described in the hand crafted representation revealing limitation in performance [12]. Deep learning approach has been shown significant improvement in many detection and recognition problems over existing methods employing hand crafted features and frameworks using shallow learning approaches. Yet, deep learning has been rarely applied to symmetry detection due to the huge diversity of visual appearance that forms rotation symmetry patterns.

Sample rotation and non-rotation symmetry images from our dataset
There have been deep learning approaches manipulating feature maps inside the network. While they are not able to learn a particular structure like rotation symmetry, they learn visual appearance regardless of any particular spatial structure variation. Jaderberg et al. [8] propose Spatial Transformer that allows the spatial manipulation of data within the network. This network is able to learn invariance to translation, scale, rotation. In Dieleman et al. [4], four operations (slice, pool, roll and stack) are inserted into convolutional neural network as a new layer to make it equivariant to rotations. Cheng et al. [2] make rotation invariance of a particular layer for object detection in VHR optical remote sensing images. The layer is trained for rotation invariance by additional loss function. Marcos et al. [13] encode rotation invariance directly in the convolutional neural network. They rotate convolution filters for each angles and pool in rotation dimension to extract rotation invariant features.

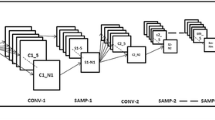
Proposed network by combining RI-CONV and SSC-CONV learning structural characteristic from image samples regardless of their appearance diversity
Brachmann and Redies [1] detect mirror symmetry from the filter responses of convolutional neural network that were trained on regular image data set. They compare the original and flipped max-pooling maps to find mirror pattern along the vertical axis. However, they use a conventional convolution layer working on visual appearance and there is no effort to develop a new network for structural characteristic. Ke et al. [9] propose side-output residual network to detect reflectional symmetries of objects. Funk and Liu [5] modifies existing CNN models [6, 14] and detect both reflection and rotation symmetries. Even though this is the first work using CNN for rotation symmetry detection reporting competitive evaluation results, they employ existing convolution scheme capturing visual information not structure information.
In this paper, we propose a novel neural network to learn structural characteristic of rotation symmetry regardless of their appearance diversity. To this end, we propose to employ two core layers. We include rotation invariant convolution (RI-CONV) layer implemented similar to [13]. We propose a symmetry structure constrained convolution (SSC-CONV) layer that finds rotational repetition in the depth map of RI-CONV layer. The contribution of our work includes (1) rotation symmetry detection data set consists of total 2000 images (32,000 after augmentation) and (2) new framework of convolutional neural network by combining RI-CONV and SSC-CONV learning structural characteristic from image samples regardless of their appearance diversity.
2 Proposed Method
In order to recognize rotation symmetry pattern in an image, structure of visual information has to be learned instead of visual appearance itself mostly has been required in prior work such as object recognition. In other words, rotation symmetry has to be learned from common structural characteristic of rotation samples: (1) repeated patterns (2) spread along the angular direction with (3) circularly aligned orientations. Convolution filter in CNN is trained to extract a common shape that is required for discrimination between classes building hierarchically features from cascaded layers. Therefore, existing convolutional neural networks in rotation symmetry classification may learn unexpected common visual features of training samples that are nothing to do with rotation symmetry structure. We propose new convolutional neural network for rotation symmetry image classification consists of rotation invariant feature extraction step and symmetry structure recognition step.

Rotation invariant feature extraction by rotation invariant convolution (RI-CONV) with orientation pooling similarly built to [13]
2.1 Rotation Invariant Feature Extraction
First we incorporate rotation invariance in our new network to capture repeated similar patterns regardless of their orientation amount. This allows following rotation symmetry structure recognition step becomes easier task. Convolution layer responds differently with original and rotated shapes. One of ways that convolution layer become rotation invariant is that filter has same value at each rotation way (in case of 3\(\,\times \,\)3 convolution filter, all values have to be same except value at center). Standalone rotation invariant filter has limited representation ability. To resolve the problem, we rotate convolution filters N times and convolve input image with each rotated filter [13]. Instead of filter rotation, input image can be rotated N times by corresponding angles and convoluted followed by back-rotation to original coordinate [4]. However, rotating input image is computationally expensive and requires additional back-rotation step. Given neural network and data set, batch normalization [7] and drop out [15] lead stable and optimal training. We use both batch normalization and drop out. Batch normalization normalize features in batch dimension to remove the covariate shift. Batch normalization in our network is conducted after convolutions considering all different rotation angles. Applying batch normalization to individual feature map is inappropriate, because what we want to obtain from the set of convolutions in different rotation angles is how single convolution filter grabs repeated patterns well regardless of their orientations. If we conduct the batch normalization at each feature map individually, different mean, variance, scaling and shifting factors will be applied to each feature maps which distort responses of following symmetry structure recognition step. We conduct batch normalization after concatenating all feature maps of rotation angles. After two sets of convolution and batch normalization, max-pooling on the feature map of each rotation is conducted. Finally after four sets of convolution and batch normalization including two times of max-pooling, orientation pooling is performed over the resultant N feature maps of rotation angles obtaining rotation invariant feature. Figure 2 shows all the layers of rotation invariant feature extraction step. Figure 3 gives example feature maps of each rotation angle and orientation pooling.
2.2 Symmetry Structure Recognition
In this step, we propose symmetry structure constrained convolution (SSC-CONV) layer to recognize the structure of rotation symmetry. Prior to this step, we insert 1\(\,\times \,\)1 convolution to the output of orientation pooling. 1\(\,\times \,\)1 convolution reduces the channels of feature map concentrating more on spatial structure rather than the variation in visual appearance. In general, plenty of appearance features can be extracted by convolutions in multiple channels. However in our network, diverse appearance features contained in such multiple channels are relatively less critical in recognizing symmetry structure. After 1\(\,\times \,\)1 convolution, we apply a set of circularly constrained convolution filters concentrating on rotational patterns in different scale (Fig. 4). Circular nature of constrained convolution filters capture rotation symmetry characteristic better than original square filters. In other words, representation scope of the convolution is reduced to circular shapes by removing unnecessary part of filters. Corners of square in convolution filter are not needed to find circle shape. Number of constrained filters and their scales can be adjusted depending on the size of target rotation object and expected classification precision. Large filter can find large circle shape and vice-versa. We give a hole in the circle shape convolution filter to fit the each scale filter at corresponding scales. In real images, rotation symmetry patterns can be skewed due to perspective projection. We give appropriate thickness of the circular bands in the constrained convolution filters to be robust to skewed rotation symmetry detection. Finally, we obtain the outputs of structure constrained convolution. Fully-connected layers classify rotation symmetry images.

Scheme of structure convolution symmetry structure constrained convolution (SSC-CONV)
3 Experimental Results
For the evaluation of our network, we built rotation symmetry classification dataset which have two classes (Rotation symmetry class and none-rotation symmetry class). Each class has 1000 images, images were collected by hand from free image website such as www.flickr.com and www.pixabay.com. In the network, input image size is 80\(\,\times \,\)80. We employ 8 times rotation at filters considering computational work. The number of rotations can be higher such as 16, 32 and 64. We use 64 filters (filter size is 5\(\,\times \,\)5) for the first two convolution layers and 128 filters for the next two convolution layers before the orientation pooling. After orientation pooling, we use 32 filters for 1\(\,\times \,\)1 convolution layer. Size of the feature map before structure constrained convolution is 20\(\,\times \,\)20\(\,\times \,\)32. Structure constrained convolution is applied with four different scale filters (5\(\,\times \,\)5, 9\(\,\times \,\)9, 13\(\,\times \,\)13, 17\(\,\times \,\)17). Size of the feature map before fully-connected layer is 20\(\,\times \,\)20\(\,\times \,\)16. All convolution operations are followed by batch normalization. Fully-connected part has 3 layers (size of first two fully-connected layer is 4096). Drop out is applied to the fully-connected layer using the rate of 0.65. For quantitative evaluation, we construct another convolutional neural network, which has regular convolutional neural network shape with similar capacity. It has six convolution layers followed by respective batch normalization and three max pooling layers in a similar structure of our network. The number of filters of regular CNN are 64, 128, and 256 for each pair of convolution layers. Filter size and fully-connected layer are all identical with our proposed network. Drop out is also applied with same rate. In the training, we set batch size as 32, learning rate as 0.0001. We randomly divide dataset into 90% of train images and 10% of test images for each class. Training data is augmented by image rotation, flipping and gray-scale. As a result, total number of training image is 28,800. We selected test set in total image randomly. Training and testing are repeated 10 times.
In Table 1, our proposed network shows improved accuracy (78%) and standard deviation over regular CNN (76%). Furthermore, proposed network holds 6,400 features before fully-connected layers, on the other hand regular CNN for the comparison holds 25,600 features. This indicates that our network extracts more meaningful and efficient features than regular CNN for rotation symmetry classification. This result tells us that when recognizing structure information such as rotation symmetry, spatial correlation of pixels is more critical than the visual appearance variation over channels.

Example misclassified result images
Figure 5 shows examples of misclassified results. First misclassified rotation symmetry image in Fig. 5(a) has partially occluded symmetry object by image region. This example tells us that the current network is not trained or structured to capture such impaired structure. Indeed, our constrained convolution filters cares only perfectly circular patterns (Fig. 4). If we add additional constrained convolution filters reflecting occluded structure, our network can be improved to deal with such occlusion. Rotation symmetry in the second misclassified rotation image is not from an object, but from overall placement of lots of stars. Convolution layer may have difficulty in capturing this weak clue for rotation symmetry. In the last misclassified rotation symmetry image, only boundary edges support the rotation symmetry object. Again, convolution layer fails to capture such weak symmetry pattern. First misclassified non-rotation symmetry image in Fig. 5(b) does not have any symmetry pattern. However it has background smoothly changing its color with almost no textures where almost uniform but rotationally symmetric region can be found by similar uniform patterns. Second misclassified non-rotation symmetry image has roughly circular region in the background. Last example of misclassified non-rotation symmetry image has two identical objects and non-textured background. Rotation symmetry pattern with two times of repetition easily can be found from anywhere of images that is hardly considered as rotation symmetry pattern. However, our network does not exclude such singular case from rotation symmetry.
4 Conclusion
In this work, we propose a new convolutional neural network adopting rotation invariant convolution layer and proposing symmetry structure constrained convolution layer. We built dataset for rotation symmetry classification with 2000 real images. Our evaluation results show that our proposed network compared with regular CNN improved performance even if regular CNN has more features. Our study and following experimental evaluation highlight potential future research on structure constrained CNN for general symmetry detection tasks.
References
Brachmann, A., Redies, C.: Using convolutional neural network filters to measure left-right mirror symmetry in images. Symmetry 8(12), 144 (2016)
Cheng, G., Zhou, P., Han, J.: Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 54(12), 7405–7415 (2016)
Cornelius, H., Loy, G.: Detecting rotational symmetry under affine projection. In: 18th International Conference on Pattern Recognition, ICPR 2006, vol. 2, pp. 292–295. IEEE (2006)
Dieleman, S., De Fauw, J., Kavukcuoglu, K.: Exploiting cyclic symmetry in convolutional neural networks. ICML (2016)
Funk, C., Liu, Y.: Beyond planar symmetry: Modeling human perception of reflection and rotation symmetries in the wild. In: ICCV (2017)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Ioffe, S., Szegedy, C.: Batch normalization: accelerating deep network training by reducing internal covariate shift. In: International Conference on Machine Learning, pp. 448–456 (2015)
Jaderberg, M., Simonyan, K., Zisserman, A., et al.: Spatial transformer networks. In: Advances in Neural Information Processing Systems, pp. 2017–2025 (2015)
Ke, W., Chen, J., Jiao, J., Zhao, G., Ye, Q.: SRN: side-output residual network for object symmetry detection in the wild. In: Proceedings IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, HI, pp. 1068–1076 (2017)
Lee, S.: Symmetry-driven shape description for image retrieval. Image Vis. Comput. 31(4), 357–363 (2013)
Lee, S., Liu, Y.: Skewed rotation symmetry group detection. IEEE Trans. Pattern Anal. Mach. Intell. 32(9), 1659–1672 (2010)
Liu, Y., Dickinson, S.: Detecting symmetry in the wild. In: International Conference on Computer Vision (ICCV) Workshops (2017)
Marcos, D., Volpi, M., Tuia, D.: Learning rotation invariant convolutional filters for texture classification. In: 2016 23rd International Conference on Pattern Recognition (ICPR), pp. 2012–2017. IEEE (2016)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: ICLR (2014)
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.: Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15(1), 1929–1958 (2014)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Yu, S., Lee, S. (2018). Rotation Symmetry Object Classification Using Structure Constrained Convolutional Neural Network. In: Bebis, G., et al. Advances in Visual Computing. ISVC 2018. Lecture Notes in Computer Science(), vol 11241. Springer, Cham. https://doi.org/10.1007/978-3-030-03801-4_13
Download citation
DOI: https://doi.org/10.1007/978-3-030-03801-4_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-03800-7
Online ISBN: 978-3-030-03801-4
eBook Packages: Computer ScienceComputer Science (R0)