
Abstract
Instead of custom-building a new ontology from scratch, knowledge resources can be elicited, reused and engineered to develop legal ontologies with the goal of promoting the application of good practices and speeding up the ontology development process. This paper focuses on the specificities of non-ontological resources in the legal domain, and provides some guidelines of how these can be reused and engineered to enable heterogeneous resources integration within a legal ontology. The paper presents some examples of these processes using a case-study in the consumer law domain.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Instead of custom-building a new legal ontology from scratch, knowledge resources are elicited from the legal domain, reused and engineered to develop legal ontologiesFootnote 1, promoting the application of good practices.
Knowledge resources have been classified as ontological resources (ORs) or non-ontological resources (henceforth named NORs) [1]. This division regards the level of formalization. We will focus on the latter type. There is much literature for reusing and reengineering ORs [2, 3] and also ontology design patterns, but little about extracting knowledge from NORs in the legal domain, probably due to its specificities, delved in this paper. This subject is relevant as it has consequences at different levels, from knowledge acquisition, to ontology engineering.
There is a large amount of NORs that embody knowledge in the legal domain, that represent some degree of consensus for the legal community and possess related semantics that allows interpreting the knowledge contained therein. In fact, within this domain, NORs may correspond to some legal sources which consist on legislation, but also other relevant sources of e.g., case law, doctrinal interpretations, social rules; it is essential to connect this existing legal material to the ontology, even if its majority is not formalised, and hence not necessarily interoperable. NORs from this realm can be embedded in different and scattered sources of hard and soft law, such as classification schemes, thesauri, lexiconsFootnote 2, textual corpora, among others, in a “patchwork” of “lego” pieces. The heterogeneity of the legal sources is observed at multiples levels: structural, semantic, and syntactic. To integrate information from multiple and heterogeneous knowledge sources, it is important to cope with the problem of legal knowledge representation, that consists in the balance between consensus and authoritativenessFootnote 3 [4] or, from the socio-legal perspective, dialogue and bindingness [5].
On the one hand, domain legal experts lack competencies in data modeling, and they often adopt technical tools (e.g., Protégé) without the necessary awareness of the technical consequences [6]. On the other hand, ontology developers, besides the data modeling perspective, should consider likewise compliance with the specificities of the juristic nature of legal NORs and of expert knowledge. A balanced combination would yield reliable actionable knowledge in a real world context, for a thorough understanding of the considered legal field is necessary to bring out explicit conceptualizations, to shape the design of the ontology and its population. Legal information specificities [7] and ontology interplay, in both its theoretical and engineering dimensions, are intrinsically connected. The interaction between legal concepts that affect the utilization of information is significative [6]. Hence, an interdisciplinary approach is essential towards representing machine-readable concepts and relationships from NORs in the legal domain, through the due processes of reusing and reengineering thereof. Hence, the research question of this paper is how to reuse non-ontological resources in the legal domain and their reengineering into ontologies. For such purpose we follow two complementary methodological approaches: (i) “Building Ontology Networks by Reusing and Reengineering Non Ontological Resources”, Scenario 2 from NeOnFootnote 4 methodology framework (henceforward called NeOn) that explains how to build ontologies by reusing and reengineering non-ontological resources [1, 8,9,10]; and (ii) the Methodology for building Legal Ontology (henceforth called MeLOn) [6], developed by Monica Palmirani.
The observations held in this paper are built upon the construction of two legal ontologies named Relevant legal information for consumer disputes (RIC) and RIC-ATPI, referring to the relevant information in the domain of air transport passenger incidents [11].
The remainder of the paper is structured as follows. Section 1 describes the specificities of NORs in the legal domain. Section 2 refers to the main methodologies to build ontologies with NORS; Sect. 3 explains the NORs reuse and reengineering processes. Section 4 concludes the paper emphasizing the challenges and lessons learned while reusing and reengineering NORs from the legal domain.
2 Specificities of NORs in the Legal Domain
In this section we define NOR, providing some examples and we discuss the specificities of possible inputs (knowledge resources available for reuse) for building possible outputs (ontologies).
2.1 Non-ontological Resources
Non-ontological resources consist in:
-
(i)
knowledge resources that embody knowledge in the legal domain;
-
(ii)
they represent some degree of consensus;
-
(iii)
whose semantics have not been formalized by an ontology yet, but they possess related semantics which allow interpreting the knowledge they hold. Sometimes this semantics is explicitly specified in natural language on the document, thus fostering its reuse; however, in other cases, the semantics is implicit and this lack of formalization prevents us from using them as ontologies.
Using consensuated NORs portrays benefits: it favors interoperability of the used vocabulary, makes faster the ontology development process, lessens the knowledge acquisition bottleneck problems, reuse, browsing/searching, and follows good practices. NORs in the legal domain can be glossaries, classification schemes, dictionaries, taxonomies, thesauri and text. Table 1 exemplifies possible NOR for the legal domain.
2.2 Specificities of NORs in the Legal Domain
Yet, even cognizant of these benefits and amount of NORs in the legal domain, there are specificities to look upon: they present a complex multi-layered informational structure that should be considered when building a legal ontology. Some of these features are recursively evoked within any legal knowledge engineering process.
-
i.
Validity of a legal source, bounded both in time and jurisdiction;
-
ii.
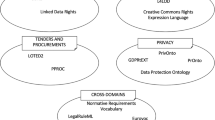
Level of formalization, in terms of being expressed in a logic formal system, as illustrated in Fig. 1, for they can possess weak or strong semantics, in the line of McGuinness [20]. Given the primacy of OWL ontologies, a description logics-centric discourse is justified.
Fig. 1. 
Examples of knowledge resources distributed according to its level of formalization. On the left bubble, they are non-formal (i.e. not expressed in terms of a logic formal system). On the right bubble, they are formal. The lines shows that the more to the right, the more complex the formal system behind is.
-
iii.
Hierarchy of the legal authority contained in legal sourcesFootnote 5. The legal domain itself defines a hierarchy of authority. Whilst legislation constitutes a primary source of law and it is binding, therefore, its authority is explicit, known soft law sources comprising binding norms with a soft dimension may not be so explicit. A possible agreed-upon typology of legal sources relies on the legal hierarchy authority, shown in an informal way in Table 2 (for comprehension reasons and not for a discrete selection of the valid sources). Figure 2 exemplifies a hierarchy of knowledge sources. As illustrated, legislation, contractual terms and case law occupy the base of the pyramid. EU Commission Interpretative Communications and Recommendations are policy documents serving the purpose of providing legal certainty, for they facilitate a more homogenous application of the EU Regulations and Directives, but lack on bindingness; these guidelines are intended to tackle the issues most frequently raised by national regulators and industry representatives. Reports and expert studies commissioned by the EU Commission, Eurobarometer, etc. help the preparation of texts and in decision-making, representing sources of knowledge but are non-binding.
Table 2. Classification of the primary and secondary sources of law Fig. 2. 
Example of a hierarchy of knowledge resources.
-
iv.
Open textured concepts. Inside the sources, vague concepts are subject to interpretation, e.g. reasonable measures, extraordinary circumstances, etc.
-
v.
Deontic legal operators. Deontic legal terms, such as right, obligation, prohibition, permission, and sanction a.s.o. occur within legal and other normative documents dispersedly located.
-
vi.
Conjoint heterogeneity and fragmentation of the legal sources. In the legal domain, NORs cannot be found in a single place, not even within one legislative text, but in a “patchwork” of “lego” pieces. Patchwork is the expression currently used to point at conjoint heterogeneity, e.g. privacy and data protection previous EU directive and from the intellectual property perspective, respectively [13, 14]. NORs “bricks” can be embedded in different and separate resources of hard and soft law, further articulated in case law and legal scholarship, scattered in a complex way in large textual corpuses, and reused in many different ways, depending on the area of law considered. They can be found in the sources indicated in Table 1;
-
vii.
Citations within and among sources;
-
viii.
Closed, shared or open status of the resources. As a result of the Open Data movement, legally backed by the PSI-DirectiveFootnote 6, fundamental legal sources of democratic societies, as legislation, court decisions and Parliamentary datasets, are freely available for reuse, and most of them have Uniform Resource Identifiers (URIs), being converted in linked data. Also the Eurovoc thesaurus, the IATE database, EU authority tables;Footnote 7 semantic interfacing between disparate national terminology repositories;Footnote 8 Identifiers such as the European Case Law Identifier (ECLI);Footnote 9 the European Legislation Identifier (ELI)Footnote 10 are open building blocks. Figure 3 depicts this status, from internal access to anyone.
Fig. 3. 
Closed, shared and open knowledge resources, from Openlaws (https://openlaws.com/).
-
ix.
Heterogeneity on its:
-
type: glossaries, dictionaries, lexicons, classification schemes and taxonomies, thesauri, textual corpora, etc.;
-
format: only some possess machine-readable format, e.g. XML, PDF, HML, RDF, and the majority is free text, which is hard to process;
-
structure: unstructured way, e.g. narratives; semi-structured, e.g. folksonomiesFootnote 11; and structured, e.g. databases, standards, catalogues, classifications, thesauri, lexicons, legal text, among others;
-
-
x.
Semantics of NORs. NORS may possess explicit and implicit semantics:
-
explicit: there are hierarchies, part-of relations and other structures explicitly expressed in natural language on the content documents, e.g. exceptions contained in legal text; and
-
implicit: interpreting the knowledge they contain, e.g. recitals of legislation; terminologies emanated from relevant institutions with explicit definitions.
-



These peculiarities should be taken into account while building a legal ontology, transferring the legal material into a computational context.
3 Methodological Reuse-Based Approaches on NORs
Research on a reuse-based approach in ontology engineering methodologies presents a wide set of methods and tools for the ontologization of NORs, but mainly specific to a particular resource type, or to a particular resource implementation, developing ad-hoc solutions to transforming available resources into ontologies.
NeOn methodology provides guidelines for building ontologies by reengineering knowledge resources widely used within a particular community. Therefore we have used this methodology in our work, inheriting the activities of “search, assessing and selecting” in the reuse process; and “reverse engineering, transformation and forward engineering” in the reengineering process, explained in Sects. 3.1 and 3.2 respectively. Nevertheless, NeOn does not refer to the domain specificities of legal knowledge encountered in Sect. 1.
There is relevant precedent work on ontology design within the legal domain, in particular, the MeLOn methodology, already implemented by a few scholars and used flexibly in ontology development projects within a diversity of use-cases in the legal domain [6, 15, 16]. This methodology was created for building legal ontologies in order to help legal experts modeling legal concepts using the principles of data modelisation. It comprises ten prescriptive methodological guidelines for building legal ontologies, from specification of requirements to implementatin and placing special emphasis to a thorough conceptual analysis and ontology evaluationFootnote 12 processes.
MeLOn regards NORs in its step 4 which entails the formation of a list of all the relevant terminology and subsequent production of a glossary of its main legal concepts. Accordingly, legislation, case law and other sets of legal norms should be consulted for determining the specific legal terminology. A glossary of terminology should have the form of a table with these column headings: term, definition by legal source (citing legal source, license, document, case law or legal theory, or common custom of the legal domain), link to normative/legal source, normalised definition (definition of term, made by the author of the new ontology, simplified or extended from a normative/legal source to fulfill the expectations of possible methodology users). The normalised definition should be a natural language description of the legal text using subject, predicate, object, with the aim to reuse the terms of the glossary as much as possible and avoid duplicative or ambiguous terminology. In this way a legal expert is forced to create triples that can be aggregated later on into more abstract assertions (TBox or ABox).
Notwithstanding the significance of the pioneering work discussed above, it leaves space for enhancement regarding the NORs reuse process, as it provides high-level guidelines for ontology construction, but could provide an account of methodological steps, details and techniques employed. Three activities from NeOn could be added to this comprehensive methodology: criteria to search NORs, assess the set of candidates and the selection of the most appropriate NORs in the legal domain. We envisage that these granularity (provided with definitions of the resources, tables, examples of NORs) targets ontology practitioners with different backgrounds, encompassing domain experts, but also ontology engineers, final users, linguists, etc. which are lay to legal specificities.
4 NORs Reuse and Engineering Processes
In this section we present the NOR reuse and the NOR reengineering processes.
4.1 NORs Reuse Process
The NOR reuse process refers to the process of choosing the most suitable available NORs for the development of ontologies that, to some extent, cover the domain of the ontology being built and that normally reflect some degree of community consensus. The reuse process entails three activities: search, assessment ad selection of NORs explained below.
-
(i)
Searching for NORs. This activity entails searching highly reliable websites, domain-related sites, and resources within organizations for NORs, using the terms included in the Ontology Requirement Specification Document, hence, according to the requirements and use-cases of the ontology;
-
(ii)
Assessing the set of candidate NOR, using three criteria: relevance, coverage and consensus, pursuant to the specificities delved in Sect. 1: primary and secondary sources of law, level of formalization, status of the resources, semantics and heterogeneity;
-
(iii)
Selecting the most appropriate NOR to be used to build the ontology;
The purposive criteria to select and assess NOR can rely on relevance dimensions and consensus and coverage, provided below. For each of the resource and whenever possible, both the purpose and the components stemmed thereof should be made explicit.
-
Domain Relevance (also denominated as “domain relevance or legal authority, legal importance”) [7, 16, 17] is two-folded, requesting the most important, or authoritative domain documents, within the specific legal domain, which the legal community considers relevantFootnote 13;
-
Cognitive Relevance: the resources convening the users’ cognitive and informational needs. Examples are conveyed in dataset of consumer’s complaints, studies on user’s search behaviour, studies on information-seeking behaviour of the considered users, etc.;
-
Situational Relevance: the resources unfolding the user’s problems or legal cases, which are mostly reported in case-law, in dataset of consumer com-plaints, and in domain reports;
-
Consensus and Coverage: consensus among agreed-upon knowledge is a subjective and not quantifiable criterion. However, the reused resources should contain terminology already consensuated by the legal community, therefore the effort and time spent in finding out precise labels for the ontology terms decreased. Besides Eur-lex (where legislation and case-law can be retrieved), the EU Commission website on the topical domain might configure the relevant sources.
It is often the case that legal NORs in different languages have to be reused. Besides the challenges posed by multi-jurisdictional environments, the language issues become a problem by themselves ˗ matching elements is hardened. These problems can be mitigated if linguistic models are used to mediate between resources. These linguistic models, like OntolexFootnote 14 represent language information differentiating between lexical entries, senses and concepts, easing the task of integration of cross-language resources.
4.2 Non-ontological Resource Reengineering Process
Reuse of NORs process implies their reengineering into computational ontologies, exploiting the expressiveness and reusability of the RDF/OWL semantic web standards for knowledge representation. This process comprises two activities [9]. The definition of such activities and some examples are shown below. However, it is important to consider that not all NORs should be reengineered, like legislation, as its self-contained authoritativeness and authenticity needs to be guaranteed in its textual grounding, with a clear reference to the texts.
-
(i)
NOR reverse engineering, whose goal is to identify NORs’ underlying components and then create representations of the resources at different levels of abstraction (design, requirements and conceptual model). As an example, provision-types and their instances can be manually harvested from the selected sources, in order to develop a representation of the resource, a conceptual structure (e.g. a taxonomy) or instance data for the ontology.
-
(ii)
NOR transformation, whose goal is to generate a conceptual model from each selected NOR. NOR transformation may include the following:
(ii.i) TBox transformation: transforms the content of the resource into an ontology schema (generating classes, relations, instances, as depicted in Fig. 4). Forms are usually useful to extract information due to its inherent classification scheme. As an example, the Air Passenger EU Complaint Form depicts domain incidents and their definitions (Fig. 5) used as classes in the RIC-ATPI domain ontology. Moreover, legal theory expresses the basic concepts (also called provision-types or systemic categories) common to (almost) all legal systems [22], e.g., obligation, permission, right, liability, sanction, legal act, cause, entitlement, etc. Legislative documents present (most of) these concepts and their stipulative definitions. The excerpt of the EC Regulation 261/2004 shown in Fig. 6 illustrates the extraction of anchoring provisions-types (requisite, right, exception, etc., that constitute classes of RIC ontology) that enable its transformation into the T-Box. The LegalRuleML metamodel [23] provides primitives and their definitions, such as Permission, Obligation, Prohibition that can give a taxonomic skeleton of a legal ontology.

NORs transformation activity. From the schema embedded in the resource, a conceptual model can be built.

Air passenger EU complaint form as an example of a classification scheme.

Extraction of provisions-types from the EU Reg. 261/2004.
(ii.ii) ABox transformation: converts the resource schema into an ontology schema, and resource content into ontology instances (generates classes, relations, instances and attributes);
(ii.iii) Population: transforms the content of the resource into instances of an existing ontology, as depicted in Fig. 7, where actual entities in this document (“Easyjet”, “Portugal”, “a denied boarding on 2011”) will be class-instances of an ontology (as in RIC-ATPI ontology);

Air transport passenger consumer complaint in Portuguese containing actual entities.
5 Conclusion: Discussion and Lessons Learned
This paper focuses on the specificities of NORs in the legal domain, and provides guidelines of how some knowledge resources may be reuse and engineered following both MeLOn and NeOn methodologies, to enable heterogeneous resources integration within a legal ontology, as they are highly heterogeneous in their data model and contents. We followed a text-based bottom-up approach to ontology building, in which conceptual and terminological knowledge is contained in legal document collections [22], demanding an expert-based analysis.
While reusing and engineering NORs, some problems occurred whilst other lessons were learned and are hereby described and discussed. We argue that this reuse/reengineering process should not only rely on a legal positivistic path of selecting and interpreting norms, for legal knowledge can be used for an amplitude of situated contexts and cases; thus, “the representation of meaning becomes a multi-faceted web of interactions between different components (methods, data, tools, places, time, people, organizations, users, and so forth) and importantly, this meaning is in flux”. Hence, “reordering of subjects and objects, or to truncate concepts to be simply attributes can render current representations of knowledge in triple form rather cumbersome to use” [21].
Verification by domain experts was complex; mainly a presentation of drafts was made possible. But tools as GrafooFootnote 15 are claimed to be more intuitive for a non ontologist; it is an open source tool that can be used to present the classes, properties and restrictions within OWL ontologies, or sub-sections thereof, as easy-to-understand diagrams. No specific management of the knowledge sources was followed, for they were not integrated into an information system (without a version, type, etc.) due to the fact that they were too many to be managed (legislation, case law, doctrine, etc.) and also considering the absence of guidelines. Much as there is criteria to add an entity or not to an ontology (through competency questions), there is no fixed criteria to manage legal resources. Therefore we denote that the management of the resources requires a breed of tools to store and manage them. We posit there was a limited reproducibility of the processes: the annotation of documents (PDFs etc.) with standard tools does not keep track of authorship, timestamp, etc. We are cognizant that annotations tools are necessary for commenting on NORs as a preliminary stage before building the ontology. Nevertheless, LIME editorFootnote 16 aims to annotate and connect the classes to the texts. In order to make explicit the hidden semantics of the resource constituents, we noticed the need of a domain expert. Furthermore, we used ad-hoc object properties of the resource components extracted directly from the text. We acknowledge the guidelines from MeLOn methodology to make explicit the hidden semantics in the relations of the NOR terminology, which depend mostly on domain experts and interpretation. We observed the need of clear criteria to select or disregard NOR resources from the legal domain. By adapting NeOn methodology, we have decided for three criteria: consensus, coverage and relevance dimensions (domain, situational, cognitive), but others could be accustomed. Reengineering transformation approaches for legal text are required regarding TBox transformation, ABox transformation, Population, forward engineering, and reverse engineering.
We plan deepening on the epistemic grounding of this position paper in the immediate future, taking into account cooperative expert sharing in knowledge-acquisition and a user based evaluation on using the methods for reusing and reengineering NORs into ontologies to gain evidence on whether the usage of such granular guidelines leads to users being able to design ontologies faster and/or better quality standards [18, 19]. It is noteworthy that “resources do not explicitly carry knowledge with them of how they were made, nor of how they should be understood, or used. Yet such knowledge is often vital to would-be consumers” [21], hence, we envision a way to describe some of them in a machine-readable so that users can make informed decisions about the suitability of resources for their tasks and locate them. We aim to use Akoma Ntoso standard [24] to provide semantic information on top of selected legal text.
Notes
- 1.
Ontologies are the chosen artifact to support the integration of data from multiple, heterogeneous legal sources, making information explicit and enabling the sharing of a common understanding of a domain.
- 2.
A lexicon is the vocabulary of an individual person, an occupational group or a professional field, Glossary of Terms for the Standardization of Geographical Names, United Nations Group of Experts on Geographic Names, United Nations, New York, 2002.
- 3.
Regarding authoritativeness and bindingness, knowledge representation in the legal domain entails some peculiar features, because it is supposed that authority is somewhat embedded into the text.
- 4.
- 5.
Legal knowledge structures are constructed in a different way than scientific knowledge structures. Whilst the natural sciences only deal with persuasive authority, meaning that the truth of a proposition does not depend on who states it, but only if empirical data supports it and/or is internally consistent, the law deals with binding authority, that is, statements from a particular source whose truth depends on that source, and other formal aspects, such as the law having been promulgated or statement being part of a verdict ratio decidendi.
- 6.
Directive 2013/37/EU, CELEX:32013L0037.
- 7.
The EU Metadata Registry: The Metadata Registry registers and maintains definition data (metadata elements, named authority lists, schemas, etc.) used by the different European Institutions involved in the legal decision making process gathered in the Interinstitutional Metadata Maintenance Committee (IMMC) and by the Publications Office of the EU in its production and dissemination process.
- 8.
The Legivoc project, http://legivoc.org/.
- 9.
Council conclusions inviting the introduction of the European Case Law Identifier (ECLI) and a minimum set of uniform metadata for case law, CELEX:52011XG0429(01).
- 10.
Council conclusions inviting the introduction of the European Legislation Identifier (ELI), CELEX:52012XG1026(01).
- 11.
A folksonomy is the result of personal free tagging of information and objects (anything with an URI) for one’s own retrieval, T. Vander Wal. Folksonomy coinage and definition. 2007. http://www.vanderwal.net/folksonomy.html.
- 12.
Evaluation parameters consist in: (i) completeness of the legal concepts definition; (ii) correctness of the explicit relationships between legal concepts; (iii) coherence of the legal concepts modelisation; (iv) applicability to concrete use-case; (v) effectiveness for the goals; (vi) intuitiveness for the non-legal experts; (vii) computational soundness of the logic and reasoning; (viii) reusability of the ontology and mapping with other similar ontologies.
- 13.
Cfr. Point (iii) in Sect. 1.2 of the paper.
- 14.
- 15.
S. Peroni, “Grafoo,” http://www.essepuntato.it/graffoo/.
- 16.
LIME editor, http://sinatra.cirsfid.unibo.it/demo-akn/.
References
Suárez-Figueroa, M.C., Gómez-Pérez, A., Motta, E., Gangemi, A. (eds.): Ontology Engineering in a Networked World. Springer, Dordrecht (2012). https://doi.org/10.1007/978-3-642-24794-1
Breuker, J., Valente, A., Winkels, R.: Use and reuse of legal ontologies in knowledge engineering and information management. In: Benjamins, V.R., Casanovas, P., Breuker, J., Gangemi, A. (eds.) Law and the Semantic Web. LNCS (LNAI), vol. 3369, pp. 36–64. Springer, Heidelberg (2005). https://doi.org/10.1007/978-3-540-32253-5_4
Gangemi, A., Sagri, M.-T., Tiscornia, D.: A constructive framework for legal ontologies. In: Benjamins, V.R., Casanovas, P., Breuker, J., Gangemi, A. (eds.) Law and the Semantic Web. LNCS (LNAI), vol. 3369, pp. 97–124. Springer, Heidelberg (2005). https://doi.org/10.1007/978-3-540-32253-5_7
Francesconi, E.: Semantic model for legal resources: Annotation and reasoning over normative provisions. Semant. Web Leg. Domain Semant. Web 7(3), 255–265 (2016)
Casanovas, P.: Semantic web regulatory models. Philos. Technol. 28(1), 33–55 (2015)
Mockus, M., Palmirani, M.: Legal ontology for open government data mashups, pp. 113–124 (2017). https://doi.org/10.1109/CeDEM.2017.25
van Opijnen, M., Santos, C.: On the concept of relevance in legal information retrieval. Artif. Intell. Law 2017(25), 65–87 (2017)
Villazón-Terrazas, B., Suárez-Figueroa, M.C., Gómez-Pérez, A.: A pattern-based method for re-engineering nonontological resources into ontologies. Int. J. Semant. Web Inf. Syst. 6(4), 27–63 (2010)
Villazon-Terrazas, B.M.: Method for reusing and re-engineering non-ontological resources for building ontologies. Ph.D. thesis, UPC (2012)
Suárez-Figueroa, M.-C., Gómez-Pérez, A., Fernández-López, M.: The NeOn methodology framework: a scenario-based methodology for ontology development. Appl. Ontol. 10, 107–145 (2015)
Santos, C., Rodriguez-Doncel, V., Casanovas, P., van der Torre, L.: Modeling relevant legal information for consumer disputes. In: Kő, A., Francesconi, E. (eds.) EGOVIS 2016. LNCS, vol. 9831, pp. 150–165. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-44159-7_11
Gianmaria, A., Boella, G., et al.: European legal taxonomy syllabus: a multi-lingual, multi-level ontology framework to untangle the web of European legal terminology. Appl. Ontol. 11(4), 325–375 (2017)
De Hert, P., Papakonstantinou, V.: The proposed data protection regulation replacing directive 95/46/EC: a sound system for the protection of individuals. Comput. Law Secur. Rev. 28(2), 130–142 (2012)
Hunter, D., Thomas, J.: Lego and the system of intellectual property, 1955–2015, 7 March 2016. SSRN: http://ssrn.com/abstract=2743140
Rahman, M.: Legal ontology for nexus: water, energy and food in EU regulations. Dissertation thesis, Alma Mater Studiorum Università di Bologna. Dottorato di ricerca in Law, science and technology, 28 Ciclo (2016)
Santos, C.: Ontologies for legal relevance and consumer complaints. A case study in the air transport passenger domain. Dissertation thesis, Alma Mater Studiorum Università di Bologna. Dottorato di ricerca in Law, science and technology, 29 Ciclo (2017)
van Opijnen, M.: A model for automated rating of case law. In: 2013 ICAIL, NY, pp. 140–149 (2013)
Ramakrishna, S., Górski, Ł., Paschke, A.: A dialogue between a lawyer and computer scientist: the evaluation of knowledge transformation from legal text to computer-readable format. Appl. Artif. Intell. 30(3), 216–232 (2016)
Casanovas, P., Casellas, N., Tempich, C., Vrandečić, D., Benjamins, R.: OPJK and DILIGENT: ontology modeling in a distributed environment. Artif. Intell. Law 15(2), 171–186 (2007)
McGuinness, D.: Ontologies come of age. In: Fensel, D., Hendler, J., Lieberman, H., Wahlster, W. (eds.) Spinning the Semantic Web: Bringing the World Wide Web to Its Full Potential. MIT Press, Cambridge (2003)
Gahegan, M., Luo, J., et al.: Comput. Geosci. 35, 836–854 (2009)
Francesconi, E., Montemagni, S., Peters, W., Tiscornia, D.: Integrating a bottom–up and top–down methodology for building semantic resources for the multilingual legal domain. In: Francesconi, E., Montemagni, S., Peters, W., Tiscornia, D. (eds.) Semantic Processing of Legal Texts. LNCS (LNAI), vol. 6036, pp. 95–121. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-12837-0_6
Athan, T., et al.: OASIS LegalRuleML. In: Proceedings of the Fourteenth International Conference on Artificial Intelligence and Law. ACM (2013)
Barabucci, G., Cervone, L., Di Iorio, A., Palmirani, M., Peroni, S., Vitali, F.: Managing semantics in XML vocabularies: an experience in the legal and legislative domain. In: 2009 Proceedings of Balisage (2010)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Santos, C., Casanovas, P., Rodríguez-Doncel, V., van der Torre, L. (2018). Reuse and Reengineering of Non-ontological Resources in the Legal Domain. In: Pagallo, U., Palmirani, M., Casanovas, P., Sartor, G., Villata, S. (eds) AI Approaches to the Complexity of Legal Systems. AICOL AICOL AICOL AICOL AICOL 2015 2016 2016 2017 2017. Lecture Notes in Computer Science(), vol 10791. Springer, Cham. https://doi.org/10.1007/978-3-030-00178-0_24
Download citation
DOI: https://doi.org/10.1007/978-3-030-00178-0_24
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-00177-3
Online ISBN: 978-3-030-00178-0
eBook Packages: Computer ScienceComputer Science (R0)