
Abstract
Recently network DEA models have been developed to examine the efficiency of DMUs with internal structures. The internal network structures range from a simple two-stage process to a complex system where multiple divisions are linked together with intermediate measures. In general, there are two types of network DEA models. One is developed under the standard multiplier DEA models based upon the DEA ratio efficiency, and the other under the envelopment DEA models based upon production possibility sets. While the multiplier and envelopment DEA models are dual models and equivalent under the standard DEA, such is not necessarily true for the two types of network DEA models. Pitfalls in network DEA are discussed with respect to the determination of divisional efficiency, frontier type, and projections. We point out that the envelopment-based network DEA model should be used for determining the frontier projection for inefficient DMUs while the multiplier-based network DEA model should be used for determining the divisional efficiency. Finally, we demonstrate that under general network structures, the multiplier and envelopment network DEA models are two different approaches. The divisional efficiency obtained from the multiplier network DEA model can be infeasible in the envelopment network DEA model. This indicates that these two types of network DEA models use different concepts of efficiency. We further demonstrate that the envelopment model’s divisional efficiency may actually be the overall efficiency.
Part of this chapter is based upon Chen, Y., Cook, W.D., Kao, C. and Zhu, Joe, Network DEA pitfalls: Divisional efficiency and frontier projection under general network structures, European Journal of Operational Research, Vol. 226 (2013), 507–515, with permissions from Elsevier Science.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others

Keywords
2.1 Introduction
Data envelopment analysis (DEA) is used to identify best practices or (efficient) frontier decision making units (DMUs), in the presence of multiple inputs and outputs (Charnes et al. 1978). DEA provides not only efficiency scores for inefficient DMUs, but also provides for frontier projections for such units onto an efficient frontier. In recent years, a number of DEA studies have focused on DMUs with internal network structures. For example, Cook et al. (2010) review DEA models for treating two-stage network structures. Others have developed DEA-based models for more complicated network structures (see Färe and Grosskopf (2000) and Tone and Tsutsui (2009)). While the focus of the current study is not to review all the existing network DEA approaches, we note that many of these approaches require significant modifications to the standard DEA structures. Therefore, a rational question to ask is whether the network DEA model retains the property of the standard DEA model, namely that it yields both (divisional) efficiency scores and a frontier projection in a single model.
Following a thorough review of the existing network DEA approaches, Chen et al. (2013) conclude that there are two types of structures based upon the standard DEA models used. One type is the multiplier-based network DEA models which calculate the overall network efficiency by integrating the ratio efficiency of each division in the network via geometric or arithmetic averages. Such a network model is then converted into a linear program that looks like the DEA multiplier model. The other type is developed by using the production possibility set for each division in the network. The resulting model takes on the appearance of the DEA envelopment model.
In the standard DEA context, the multiplier model is equivalent to the envelopment model which yields the DEA projection and the efficiency due to the linear programming duality. However, under the network structure, such duality may not lead to a particular pair of network multiplier and envelopment models, where frontier projections and divisional efficiency scores are generated in a single network DEA model.
The current chapter first uses a simple two-stage network structure to demonstrate that under the condition of constant returns to scale (CRS), the envelopment network DEA model does not necessarily provide information on divisional efficiency and only provides information on the frontier projection. This can be a pitfall when we use the envelopment network DEA approach. Such a pitfall is caused by the fact that the envelopment-based network DEA approach does not account for the intermediate measures (or links) in calculating the divisional efficiency. While the multiplier-based network DEA models provide both overall and divisional efficiency scores, their duals may not yield correct information on frontier projections without proper adjustments to those dual models.
Note in the standard DEA approach, variable returns to scale (VRS) is achieved by adding a convexity constraint into the CRS envelopment model or equivalently a free variable into the multiplier model. We demonstrate that under the network DEA model, the above equivalence no longer holds. We further show that envelopment and multiplier network DEA models are two very different approaches using different efficiency concepts. Further, divisional efficiency obtained from the multiplier network DEA model can be infeasible on the envelopment side. We also demonstrate that the envelopment model’s divisional efficiency may actually be the overall efficiency.
The rest of the chapter is organized as follows. Section 2.2 briefly introduces the multiplier and envelopment-based network DEA models under a simple two-stage network structure, where outputs from the first stage (division) are the only inputs to the second stage (division). Sections 2.3 and 2.4 then discuss the pitfalls for determining divisional efficiencies and frontier projections. In Sect. 2.5 we examine the VRS case. Section 2.6 is devoted to discussing network DEA models under general network structures. Conclusions follow in Sect. 2.7.
2.2 Two-Stage Network DEA
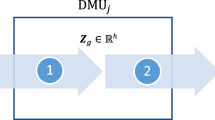
For simplicity, we consider a generic two-stage process as shown in Fig. 2.1, for each of a set of n DMUs. We assume each DMU j (j = 1, 2, …, n) has m inputs x ij , (i = 1, 2, …, m) to the first stage, and D outputs z dj , (d =1, 2, …, D) from that stage. These D outputs then become the inputs to the second stage, hence behaving as intermediate measures. The outputs from the second stage are y rj , (r =1, 2, …, s).

Two-stage process
For DMU j we denote the efficiency ratios for the first stage (division) as θ 1 j and the second as θ 2 j . Based upon the input-oriented DEA model of Charnes et al. (1978), we have the following standard DEA models for each stage (division):
where v i , w d , \( {\tilde{w}}_d \), and u r are unknown non-negative weights. In order to model the two-stage network based upon the two efficiency ratios defined in (2.1) the variables w d are set equal to \( {\tilde{w}}_d \) as in Kao and Hwang (2008) and in Liang et al. (2008). As a result, the two-stage overall efficiency ratio can be defined as θ 1 j • θ 2 j which is equal to \( {\theta}_j=\frac{{\displaystyle \sum_{r=1}^s{u}_r}{y}_{ro}}{{\displaystyle \sum_{i=1}^m{v}_i{x}_{io}}} \). To calculate the overall efficiency of θ j , Kao and Hwang (2008) present the following model (this model is called centralized model in Liang et al. (2008))
Model (2.2) can be converted into the following linear program
In a similar manner, we can develop output-oriented models. Model (2.3) yields the overall efficiency. After the overall efficiency is obtained, divisional efficiency can be obtained via efficiency decomposition (see Kao and Hwang (2008)). Specifically,
If we denote the optimal value to model (2.3) as θ * o , then we have θ * o = θ 1 * o • θ 2 * o . Note that optimal multipliers from model (2.3) may not be unique, meaning that θ 1 * o and θ 2 * o may not be unique. To test for uniqueness, we can first determine the maximum achievable value of θ 1 * o via
It then follows that the minimum of θ 2 * o is given by \( {\theta}_o^{2-}=\frac{\theta_o^{*}}{\theta_o^{1+}} \). This also gives an efficiency decomposition of θ * o = θ 1 + o • θ 2 − o .
Liang et al. (2008) provide a procedure for testing the uniqueness of efficiency decomposition. The maximum of θ 2 * o , which we denote by θ 2 + o , can be calculated in a manner similar to the above, and the minimum of θ 1 * o is then calculated as θ 1 − o = θ * o /θ 2 + o . Note that θ 1 − o = θ 1 + o if and only of θ 2 − o = θ 2 + o . Note also that if θ 1 − o = θ 1 + o or θ 2 − o = θ 2 + o , then θ 1 * o and θ 2 * o are uniquely determined via model (2.3).
Model (2.3) is based upon the ratio DEA efficiency and then is converted into a DEA multiplier-type linear program. Therefore, we can refer to this type of network DEA approach as multiplier-based. On the other hand, Tone and Tsutsui (2009) develop a slacks-based network DEA model by using the production possibility sets, where the intermediate measures z dj (d = 1, …, D) are called links. Relative to Fig. 2.1, the constraints for the slacks-based model take the form:
In Tone and Tsutsui (2009), models based upon (2.4) are referred to as the “fixed link” case.
Note that z do are outputs from the first stage and are inputs to the second stage. Therefore, based upon the standard DEA model, the production possibility set can be defined as
where we use \( {\tilde{z}}_{do} \) to denote unknown decision variables for the intermediate measures (or links as referred to in Tone and Tsutsui (2009)). As in Tone and Tsutsui (2009), these measures can be increased or decreased in the optimal solution of a network DEA model based upon (2.5). Tone and Tsutsui (2009) refer to (2.5) as the “free link” case.
The difference between (2.4) and (2.5) (or between “fixed link” and “free link”) is very minor. The slacks-based (envelopment) network DEA models based upon (2.4) and (2.5) will yield identical optimal slack values if the constraints related to \( {\tilde{z}}_{do} \) become binding at optimality. Otherwise, if these constraints are not binding, then the two models based upon (2.4) and (2.5) will yield different optimal slack values. If one uses a radial measure, the difference between (2.4) and (2.5) is negligible with respect to the radial efficiency scores. Therefore, in the discussion to follow, we will not specifically distinguish “fixed link” and “free link” for the intermediate measures.
A version of the input-oriented envelopment network DEA model under “free link” intermediate measures can be written as
Since the intermediate measures are the only outputs from stage-1, and the only inputs to stage-2, Tone and Tsutsui’s (2009) input-oriented slacks-based network DEA model will not have the divisional efficiency for stage 2. In other words, the divisional efficiency for stage 1 should be regarded as the overall efficiency, based upon Tone and Tsutsui’s (2009) definition under either “fixed link” or “free link”. In a similar manner, Tone and Tsutsui’s (2009) output-oriented slacks-based network DEA model will not have the divisional efficiency for stage 1, namely the divisional efficiency for stage 2 is the overall efficiency.
Moreover, as shown in Chen et al. (2009b), model (2.3) is equivalent to the following linear program, where the intermediate measures are treated as “free link” defined in Tone and Tsutsui (2009).
Model (2.7) can be viewed as the radial version of the two-stage network DEA model of Tone and Tsutsui’s (2009) based upon (2.5). In this case, model (2.7), like the input-oriented slacks-based network DEA model (2.6), can only generate the overall efficiency. In this regard, θ* cannot be treated as the divisional efficiency of stage 1.
Models developed based upon (2.4) or (2.5) can be called envelopment DEA network models, as they are similar to the standard envelopment DEA model format. If we add ∑ λ j = ∑ μ j = 1 into (2.4) or (2.5), the existing DEA literature claims that the VRS envelopment network DEA model is obtained, since this is how VRS envelopment model is obtained under the standard DEA model. However, we believe that this issue needs to be further examined.
2.3 Two-Stage Network: Divisional Efficiency Pitfall
Consider the numerical example given in Table 2.1 where we have five DMUs and two intermediate measures. Table 2.2 reports the optimal slacks and intermediate measures when (2.4) and (2.5) are used. The last three columns report the overall efficiency based upon (2.2), and its efficiency decomposition for divisional efficiency scores based upon Kao and Hwang (2008) and Liang et al. (2008).
It can be seen that the envelopment-based network DEA model can generate a score for overall efficiency and frontier projections, and the multiplier-based two-stage network DEA model (2.2) or (2.4) is able to generate the divisional efficiency scores for both stages. In other words, under the network DEA approach, both multiplier and envelopment-based models are needed to generate (i) overall efficiency, (ii) divisional efficiency, and (iii) frontier projections.
Under (2.5), model (2.2) or its equivalent model (2.7) yields the identical optimal intermediate measures as model (2.6). This also implies that the input-oriented slacks-based network DEA model does not yield information on divisional efficiency.
For the output-oriented situation, we can obtain the similar conclusion that while the multiplier network DEA model can decompose the overall efficiency into divisional efficiency scores, the slacks-based or envelopment network DEA model only yields information on the overall efficiency along with the frontier projection.
We finally consider the non-oriented case. For example, for (2.4) or (2.5), we can use sum of slacks or the ratio form from Tone and Tsutsui (2009). For example, we can have the following non-oriented envelopment network DEA model.
Or, it appears that we can build a radial version of (2.8), that is
where α and β represent the divisional efficiency scores for stages 1 and 2 respectively. Model (2.9) assumes “free link”. If “fixed link” is assumed, we use \( {\displaystyle \sum_{j=1}^n{\lambda}_j{z}_{dj}}={\displaystyle \sum_{j=1}^n{\mu}_j{z}_{dj}} \) in model (2.9).
However, as shown in Chen et al. (2009b), α* = 1 and 1/β* is equal to the overall efficiency obtained from model (2.2) at optimality. This indicates that α and β actually do not represent the divisional efficiency scores. This implies that the slack based measures cannot be used to represent the divisional efficiency scores in model (2.8).
Table 2.3 reports the results from (2.8). Both (2.4) (“fixed link”) and (2.5) (“free link”) yield identical optimal slacks and intermediate measures, namely, the inequality constraints in (2.5) are binding at optimality. It can be seen from the input slacks that DMUs 1 and 5 are efficient and DMUs 2, 3, and 4 are weakly efficient. This corresponds to the situation α* = 1. Based upon the last two columns of Table 2.2, stage 1 in DMU5 is not efficient, for example.
The above phenomenon can be regarded as a two-stage network DEA pitfall in calculating divisional efficiency. It is recommended that the envelopment-based network DEA model, for example, Tone and Tsutsui’s (2009), be used to calculate the frontier projection, and the multiplier-based approach is used to calculate the overall and divisional efficiencies.
This pitfall can be due to the fact that the envelopment-based network DEA model does not consider the optimal intermediate measures in its calculation of the divisional efficiency. In the current study, we argue that divisional efficiency should be based upon the DEA ratio efficiency as defined in (2.1) where (optimal) intermediate measures are considered. This is due to the fact that once the optimal intermediate measures are determined, they become inputs (or outputs) to a division.
2.4 Two-Stage Network: Frontier Projection Pitfall
While the envelopment-based network DEA model provides a frontier projection for inefficient DMUs, the dual to the multiplier-based network DEA model does not necessarily provide the frontier projection. For example, the dual to model (2.3) is
As shown in Chen et al. (2010) or Chap. 4, (θ*x io , z do , y ro ) is not on the frontier as the projection generated by model (2.10), and we have to determine an optimal z do . Based upon the discussion in the previous section, we know that for an inefficient DMU to be projected onto the network DEA frontier, its intermediate measures will have to be adjusted (increased or decreased). In fact, Chen et al. (2010) show that model (2.10) is equivalent to model (2.7). Therefore, the dual to the multiplier-based network DEA model (namely model (2.10)) has to be adjusted as model (2.7) in order to calculate the optimal intermediate measures so that we obtain the correct frontier projection as (\( {\theta}^{*}{x}_{io},{\tilde{z}}_{do}^{*},{y}_{ro} \)) or (θ*x io , ∑ λ * j z ij , y ro ).
Since Fig. 2.1 presents a simple network structure, we are able to modify the model (2.10) to model (2.7). In a complicated network structure, such task may not be possible.
Such frontier projections have an interesting aspect. We consider the two-stage network structure involving 24 Taiwanese non-life insurance companies studied in Kao and Hwang (2008). The two stages represent premium acquisition and profit generation respectively. The inputs to the first stage are operational expenses and insurance expenses, and the outputs from the second stage are underwriting profit and investment profit. There are two intermediate measures between the two stages, namely direct written premiums and reinsurance premiums.
Table 2.4 reports a set frontier projection points based upon model (2.7). Table 2.5 reports the overall efficiency and its decomposition based upon model (2.3). Note that none of the DMUs are efficient.
Because of the existence of intermediate measures, we cannot apply the standard DEA to each stage separately. However, since we now have the frontier, we should be able to apply the standard DEA to each stage after we include the projected DMUs in Table 2.4. In other words, we now have a set of 48 DMUs, of which 24 are projections of the original DMUs.
The last two columns of Table 2.5 report the CRS efficiency scores. Interestingly, these scores are equal to the standard CRS scores when the original 24 DMUs are evaluated. That is,, the added projected DMUs do not change the CRS efficiency scores. Note that the projected DMUs are obtained from the network DEA model and represent the frontier for the two-stage process. Such a frontier cannot be obtained from the standard CRS model.
The above discussion may indicate that the network DEA model behaves very differently from the standard DEA model, although it is built upon the standard DEA model.
Finally, we point out that one may argue that the dual variables to the multiplier model (2.3) could be used to obtain the frontier projections. However, without the help of transforming the model (2.10) (which is the dual to model (2.3)) to model (2.7), we cannot obtain the frontier projections directly based upon the dual variables. The same is true that we cannot obtain the divisional efficiency directly based upon the dual variables to the envelopment model (2.7). In other words, both models (2.3) and (2.7) are needed to calculate the divisional efficiency and frontier projections. We will further demonstrate this point in the next section.
2.5 Two-Stage Network: Variable Returns to Scale
Discussions in Sects. 2.3 and 2.4 are based upon CRS. Under the standard DEA approach, by adding the convexity constraint (e.g. ∑ λ j = 1), we obtain the envelopment model under VRS. Note that under the standard DEA approach, the VRS multiplier model is obtained by introducing a free variable. The issue here is whether the multiplier network model is equivalent to the envelopment network model under the VRS condition. To address such an issue is computationally difficult because model (2.2) for VRS version cannot be converted into a linear program. An alternative approach is to use an additive form of weighed average of divisional efficiency scores (Chen et al. 2009a). However, Chen et al. (2009a) discover that CRS scores are greater than the related VRS scores for several DMUs in the case of 24 Taiwanese non-life insurance companies. This may indicate that the properties related to returns to scale in the standard DEA model do not apply in network DEA.
Kao and Hwang (2011) recently developed an alternative approach to study efficiency decomposition under both CRS and VRS conditions. Based upon model (2.3), we denote E 0, E 10 , and E 20 to be the system, stage 1, and stage 2 CRS efficiencies of the two-stage system, respectively. Now, let T 0, T 10 , and T 20 be the respective technical efficiencies (under VRS), and S 0, S 10 , and S 20 the respective scale efficiencies. Since the outputs of the first stage are the inputs of the second, if one wants to improve the efficiency of the first stage via increasing its outputs, then the efficiency of the second stage will be affected. Therefore, Kao and Hwang (2011) used the input-oriented VRS model to calculate T 10 and the output-oriented VRS model to calculate T 20 , so that the intermediate products can remain intact. As in the conventional case, S 10 = E 10 /T 10 and S 20 = E 20 /T 20 . Note that the former is an input-oriented scale efficiency and the latter output-oriented one. The technical and scale efficiencies of the overall system are the products of those of the first and second stages, respectively, i.e., T 0 = T 10 × T 20 and S 0 = S 10 × S 20 .
To calculate the input-oriented VRS technical efficiency of stage 1 and the output-oriented VRS technical efficiency of stage 2, the production possibility based envelopment models are:
Based on Kao and Hwang (2011), T 10 and T 20 are calculated as follows:
The linearized forms for calculating T 10 and its dual are:
From the dual, which is an envelopment model, it is clear that ∑ n j = 1 α j Z dj , ∑ n j = 1 α j X ij , ∑ n j = 1 λ j X ij , ∑ n j = 1 μ j Y rj , and ∑ n j = 1 λ j Z pj (or ∑ n j = 1 μ j Z pj ) are the projections of VRS-Z d0, VRS-X i0, CRS-X i0, CRS-Y r0, and CRS-Z d0, respectively. The CRS efficiency of stage two is η, which is equal to 1/E 20 . The CRS efficiency of stage one is E 10 , or ηE 0(=η × E 10 × E 20 ).
Obviously, the dual model is very different from the envelopment-based model (2.11). Under careful inspection, one finds that the last three sets of constraints have nothing to do with calculating θ 1, and can thus be deleted. In other words, VRS technical efficiency can be calculated independently of the CRS efficiencies.
Similarly, the linearized forms for T 20 and its dual are:
The projections for VRS-Z d0 and VRS-Y r0 are \( {\displaystyle {\sum}_{j=1}^n} \)(β j /θ 2)Z dj and \( {\displaystyle {\sum}_{j=1}^n} \)(β j /θ 2)Y rj , respectively. Other interpretations are similar to that of the first stage. Again, the VRS technical efficiency can be calculated independently of the CRS efficiencies.
The models for stages one and two can be combined as:
The interpretations are straightforward. Note that θ 1 and θ 2 are independent, and can thus be calculated separately. If the model is developed under the envelopment form, then it will be something similar to model (2.9) with the convexity constraints of ∑ λ j = 1 and ∑ μ j = 1, which is obviously different from the dual of the VRS multiplier model derived here.
If there are multiple solutions, such that the decomposition of E 0 = E 10 × E 20 is not unique, then stage one (or stage 2) must be calculated first, then calculate the second stage by requiring the CRS efficiency of stage one is equal to E 10 , i.e. \( {\displaystyle {\sum}_{D=1}^D} \) w d Z d0 \( \operatorname{}{\displaystyle {\sum}_{i=1}^m} \) v i X i0 = E 10 .
The above discussion reveals the following interesting observation. While in the standard DEA model, the multiplier and envelopment models are equivalent, in the two-stage network DEA, such equivalence does not exist. This indicates that the multiplier-based and envelopment-based network DEA models are two different approaches. We will further illustrate this point in the next section. The next section will show that under general network structures, the multiplier and envelopment network models not only use different efficiency concepts, but also do not correspond with each other.
2.6 Multiplier Versus Envelopment Network DEA: Pitfall
We now assume that in addition to the intermediate measures (z dj , (d =1, 2, …, D)), there are inputs to the second stage pictured in Fig. 2.1. We denote these inputs to the second stage shown as x stage − 2 hj (h =1, 2, …, H), using the same notations from Li et al. (2012). Figure 2.1 then becomes
Model (2.2) now becomes
where θ o1 and θ o2 represent the ratio efficiencies for stages 1 and 2, respectively. Note that the “link” between the two stages is indicated by the same weights w d for the intermediate measures. Due to the additional inputs to the second stage \( \left({\displaystyle \sum_{h=1}^H{Q}_h{x}_{ho}^{stage-2}}\right) \), model (2.13) cannot be converted into a linear program. Li et al. (2012) introduce a heuristic method to solve this problem.
Model (2.13) is regarded as the multiplier model. To establish the envelopment DEA network model for Fig. 2.2, we follow Tone and Tsutsui (2009) and provide the following model based upon the concept of the production possibility set. Note that in this case, the intermediate measures are treated as “fixed link”.

Two-stage process with additional inputs to the second stage
We use radial measures θ 1, θ 2 rather than slacks-based measures in model (2.14), because in the standard DEA approach, the radial measure in the envelopment model is equivalent to the ratio efficiency defined in the multiplier model.
The issue here is whether θ 1* and θ 2* obtained from model (2.14) represent the efficiency scores for stages 1 and 2. To address this issue, we need to compare models (2.13) and (2.14). Since as demonstrated in Li et al. (2012), model (2.13) can only be converted into a nonlinear program, we are not able to compare model (2.13) and the dual to model (2.14). Note however that the data set used in Li et al. (2012) yields a unique efficiency decomposition (divisional efficiency). Therefore, we can compare the divisional efficiency scores obtained from models (2.13) and (2.14).
Table 2.6 provides the data for the R&D system for the 30 Provincial Level Regions in China used in Li et al. (2012). The two stages are technology development process, and economic application process. The inputs to the first stage are: R&D expenditure (R&DE), R&D personnel (R&DP) and the proportion of regional science and technology funds in regional total financial expenditure (S&TF/TFE). The intermediate measures are the number of patents and the number of papers. The second stage also has an input of contract value (CV) in technology market. The outputs from the second stage are GDP, total exports (TE), urban per capita disposable annual income (UPCDAI), and gross output of high-tech industry (GOHI).
Columns 2 and 3 of Table 2.7 report the unique divisional efficiency scores obtained from model (2.13) under Li et al.’s (2012) algorithm. Columns 4 and 5 report the divisional efficiency scores from model (2.14). We observe that except for 8 DMUs (6, 8, 9, 10, 16, 27, 29, 30), divisional efficiency scores from models (2.13) and (2.14) are very different. This indicates that models (2.13) and (2.14) produce different results under general network structures.
We next test whether the divisional efficiency scores for each DMU obtained from the multiplier model (2.13) are feasible solutions for θ 1 and θ 2 in the envelopment model (2.14). The last column in Table 2.7 indicates that DMUs 20 and 28’s model (2.13) divisional efficiency scores are infeasible under model (2.14). However, all DMUs’ divisional efficiency scores obtained from model (2.14) are feasible scores under model (2.13). In particular, model (2.14) yields projection points. If we apply model (2.13) to the projection points obtained from model (2.14), each DMU is efficient.
The above study indicates that (i) the multiplier and envelopment network DEA models are different with respect to defining divisional efficiency, and (ii) the projection points based upon the envelopment network DEA model are efficient under the multiplier network DEA model.
To further illustrate the above points, we modify the objective function of model (2.14) from (θ 1 + θ 2) to (θ 1 + θ 2)/2, which will not affect the solution. Then the dual of model (2.14) becomes:
Since the system efficiency can be defined as ∑ s r = 1 u r Y r0/\( \Big( \)∑ m i = 1 v i X i0 + ∑ H h = 1 q h X stage − 2 h0 \( \Big) \), the constraint of the dual should be \( \Big( \)∑ m i = 1 v i X i0 + ∑ H h = 1 q h X stage − 2 h0 \( \Big) \)= 1, rather than ∑ m i = 1 v i X i0 = 1/2 and ∑ H h = 1 q h X stage − 2 h0 = 1/2. This indicates that model (2.14) is too restrictive to provide correct solutions. (The objective function, (θ 1 + θ 2)/2, intends to represent the system efficiency.) Moreover, the multiplier w d should be positive. If we take these conditions into consideration, we would require that \( \Big( \)∑ m i = 1 v i X i0 + ∑ H h = 1 q h X stage − 2 h0 \( \Big) \) = 1, or ∑ m i = 1 v i X i0 = π and ∑ H h = 1 q h X stage − 2 h0 = 1 − π, and w d to be positive. Then the dual becomes:
Although, theoretically, π is free in sign, the constraint of ∑ m i = 1 v i X i0 = π ensures it to be positive (and so is 1 − π). The dual indicates that θ 1 and θ 2 are equal and do not represent divisional efficiencies, but rather they represent overall system efficiency.
The above discussion indicates that the so-called divisional efficiency scores in the envelopment model are not efficiency scores for divisions under the concept of ratio DEA efficiency, whether the network structure is a simple two-stage process or a general one.
2.7 Conclusions
The current chapter presents several pitfalls in network DEA modeling. We start the discussion with a simple two-stage network structure where only intermediate measures exist between the two stages and the first stage has inputs only and the second stage outputs only. This simple structure allows one to (i) establish an equivalence between the multiplier-based and envelopment-based network DEA models, and (ii) demonstrate the difference between the multiplier-based and envelopment-based network DEA models.
Under a general network structure, we demonstrate that the outcomes from the multiplier and envelopment models are not necessarily equivalent. The divisional efficiency scores obtained from the multiplier model can be infeasible under the envelopment model under the condition of CRS. We demonstrate that the divisional efficiency scores based upon the envelopment model do not necessarily represent divisional efficiencies, and may actually be the overall efficiency. This indicates that cautions needs to be taken when developing a network DEA model using production possibility sets.
It is our view that overall efficiency along with divisional efficiencies should be defined under the DEA multiplier (ratio) model, as in Kao and Hwang (2008) and Liang et al. (2008), for example. Such a definition is related to other definitions of efficiency used in engineering and science, as well as in business and economics. For example, the CCR efficiency was modeled on the definition from “combustion” engineering, where efficiency is defined as “the ratio of actual amount of heat liberated … to the maximum amount which could be liberated” (Charnes et al. (1978)). Many of the business efficiency measures appear in the form of ratios, such as earnings per share and profit per employee.
While in conventional DEA, the envelopment model or the distance function-based efficiency is equivalent to multiplier (ratio) efficiency, in the case of network DEA, the distance function-based envelopment models do not necessarily yield information on divisional efficiency. Although the envelopment network DEA models might give the appearance of providing optimal divisional efficiency, we show that in reality the envelopment efficiency is a measure of overall efficiency.
As a result of the current study, many existing production possibility set-based network DEA models including Tone and Tsutsui’s (2009) slacks-based approach need to be re-examined with respect to their rationale for the (divisional) efficiency definition. Our study indicates that current envelopment models are not able to calculate divisional efficiencies. However, this does not mean that it is impossible to calculate divisional efficiencies by using envelopment models; rather there would appear to be a need to develop new envelopment-based models for accomplishing this task.
Finally, due to the fact that we are not able to obtain multiplier divisional efficiency scores under the condition of VRS (because the resulting model cannot be solved as a linear program), we cannot perform such a comparison under the condition of VRS. Therefore, it is important to develop algorithms that will enable one to derive multiplier-based divisional efficiency under VRS.
References
Charnes, A., Cooper, W. W., & Rhodes, E. (1978). Measuring the efficiency of decision making units. European Journal of Operational Research, 2, 429–444.
Chen, Y., Cook, W. D., Li, N., & Zhu, J. (2009a). Additive efficiency decomposition in two-stage DEA. European Journal of Operational Research, 196, 1170–1176.
Chen, Y., Liang, L., & Zhu, J. (2009b). Equivalence in two-stage DEA approaches. European Journal of Operational Research, 193(2), 600–604.
Chen, Y., Cook, W. D., & Zhu, J. (2010). Deriving the DEA frontier for two-stage processes. European Journal of Operational Research, 202, 138–142.
Chen, Y., Cook, W. D., Kao, C., & Zhu, J. (2013). Network DEA pitfalls: Divisional efficiency and frontier projection under general network structures. European Journal of Operational Research, 226, 507–515.
Cook, W. D., Liang, L., & Zhu, J. (2010). Measuring performance of two-stage network structures by DEA: A review and future perspective. Omega, 38, 423–430.
Färe, R., & Grosskopf, S. (2000). Network DEA. Socio-Economic Planning Sciences, 34, 35–49.
Kao, C., & Hwang, S.-N. (2008). Efficiency decomposition in two-stage data envelopment analysis: An application to non-life insurance companies in Taiwan. European Journal of Operational Research, 185(1), 418–429.
Kao, C., & Hwang, S.-N. (2011). Decomposition of technical and scale efficiencies in two-stage production systems. European Journal of Operational Research, 211, 515–519.
Li, Y., Chen, Y., Liang, L., & Xie, J. (2012). DEA models for extended two-stage network structures. Omega, 40(5), 611–618.
Liang, L., Cook, W. D., & Zhu, J. (2008). DEA models for two-stage processes: Game approach and efficiency decomposition. Naval Research Logistics, 55, 643–653.
Tone, K., & Tsutsui, M. (2009). Network DEA: A slacks-based measure approach. European Journal of Operational Research, 197(1), 243–252.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2014 Springer Science+Business Media New York
About this chapter
Cite this chapter
Chen, Y., Cook, W.D., Kao, C., Zhu, J. (2014). Network DEA Pitfalls: Divisional Efficiency and Frontier Projection. In: Cook, W., Zhu, J. (eds) Data Envelopment Analysis. International Series in Operations Research & Management Science, vol 208. Springer, Boston, MA. https://doi.org/10.1007/978-1-4899-8068-7_2
Download citation
DOI: https://doi.org/10.1007/978-1-4899-8068-7_2
Published:
Publisher Name: Springer, Boston, MA
Print ISBN: 978-1-4899-8067-0
Online ISBN: 978-1-4899-8068-7
eBook Packages: Business and EconomicsBusiness and Management (R0)