
Abstract
Research activities relating to data envelopment analysis (DEA) have grown at a fast rate recently. Exactly what activities have been carrying the research momentum forward is a question of particular interest to the research community. This study finds these research activities, or research fronts, as well as some facts on applications in DEA. A research front refers to a coherent topic or issue addressed by a group of research articles in recent years. The large amount of DEA literature makes it difficult to use any traditional qualitative methodology to sort out the matter. Thus, this study applies a network clustering method to group the literature through a citation network established from the DEA literature over the period 2000–2014. The keywords of the articles in each discovered group help pinpoint its research focus. The four research fronts identified are “bootstrapping and two-stage analysis”, “undesirable factors”, “cross-efficiency and ranking”, and “network DEA, dynamic DEA, and SBM”. Each research front is then examined with key-route main path analysis to uncover the elements in its core. In the end, we present the prevailing DEA applications and the observed association between DEA methodologies and applications.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
18.1 Introduction
Data envelopment analysis (DEA) is a methodology for performance evaluation and benchmarking where multiple performance measures are present (Cook et al. 2014; Sherman and Zhu 2013). Charnes et al. (1978) establish an efficient frontier formed by the best performing decision making units (DMUs) and assign an efficiency index to each non-frontier units according to their distances to the efficient frontier. After more than 35 years of development, research activities relating to DEA are still growing at a very fast rate. Our search in the Web of Science (WOS) database indicates that during the period 2010–2014, around 2000 more DEA-related papers have been published, which is in addition to the 4500 existing collections prior to 2010 as reported by Liu et al. (2013a).
Amidst such a large amount of literature, it is getting more and more difficult to comprehend the development of the field without the guidance of survey type studies. Several previous studies have reviewed the general DEA literature. They include, in the sequence of their publication year, Seiford and Thrall (1990), Seiford (1996), Gattoufi et al. (2004a, b), Cooper et al. (2007), Emrouznejad et al. (2008), Cook and Seiford (2009), Liu et al. (2013a, b), etc. Seiford and Thrall (1990) review DEA development when the field was in its early stage. Seiford (1996) and Gattoufi et al. (2004a) extensively list the DEA literature up to the time when their articles was published. Cooper et al. (2007) review DEA models and measures from a theoretical perspective. Gattoufi et al. (2004b) and Emrouznejad et al. (2008) conduct bibliometric style surveys and present the DEA publication statistics. Cook and Seiford (2009) present a comprehensive review on the methodological developments since 1978. Liu et al. (2013a, b) survey the general DEA literature and examine how DEA is applied through a citation-based methodology.
There is also no lack of survey studies in specific DEA subfields. Studies that survey methods to further discriminate DEA results include Adler et al. (2002), Angulo-Meza and Lins (2002), and Hosseinzadeh Lotfi et al. (2013). Zhu (2003) and Hatami-Marbini et al. (2011) review the approaches to handle imprecise and fuzzy data in DEA. Zhou et al. (2008) and Song et al. (2012) survey energy and environmental studies that apply DEA. For financial institution and banking applications , Berger and Humphrey (1997), Fethi and Pasiouras (2010), and Paradi and Zhu (2013) conduct comprehensive surveys. Recently, Cook et al. (2010a), Castelli et al. (2010), and Kao (2014b) go over the developments in network DEA and two-stage process model.
All these surveys enrich the DEA literature and help advance our understanding of the field. They provide guidance to scholars who are new to the field and may have helped widen the view of long standing researchers. This current study attempts to play the same role as those previous surveys by applying a quantitative and systematic approach similar to that adopted in Liu et al. (2013a). In fact, this current study continues and complements the previous survey by Liu et al. (2013a) with up-to-date data. As regards to methodology, in addition to main path analysis, this study also adopts a widely used network clustering method to separate the literature into groups. Nevertheless, we deviate from Liu et al. (2013a) in that this study’s main focus is on research fronts of DEA. Aside from providing updates on the main trajectory of the overall DEA development and authors who have made significant contributions to the development, the current study answers an interesting question: What are the recent major activities that have carried the DEA research momentum forward?
Research fronts are areas in which many researchers put their focus in recent years. They are typically represented by a group of articles addressing the same or similar issues. In order to discover these coherent groups within the DEA field, we construct a citation network and apply a powerful network clustering method, the edge-betweenness based clustering (Girvan and Newman 2002), to separate the citation network into sub-networks. The clustering method demands that the resulting sub-networks have nodes tightly knitted within, but loosely connected to nodes outside the sub-network. We then apply key-route main path analysis assisted by keyword analysis to comprehend the research activities in each group. As to the time coverage, Liu et al. (2013a) observes two phases of DEA development with the latest phase beginning around 2000. It is quite reasonable to take that year as the starting point, and thus we take articles from 2000 through to 2014 to uncover research fronts.
The growth of DEA research is largely boosted by its broad applicability. Scholars have applied various DEA methodologies to study efficiencies and related management issues in a wide array of applications. Applications in different industry, nevertheless, seemed to be associated with certain methodologies. Some of such phenomena are rooted in the nature of applications while others are not. For those that are not, comprehending the phenomena opens opportunities for further innovation in the application research. The last part of this study applies keyword analysis to find association between methodologies and applications, along with some basic descriptive analysis on applications.
This paper is organized as follows. After the introduction, we briefly describe the methodology used in this study, in particular the edge-betweenness based clustering and the key-route main path analysis. Section 18.3 discusses data composition and presents the basic statistics. Section 18.4 offers the results of overall DEA development, which is essentially an update of the major results in (Liu et al. 2013a). Section 18.5 elaborates on the DEA research fronts. It is followed by a presentation of keyword analysis results on DEA applications in particular the association between methodologies and applications. The last section concludes and discusses future research avenues to pursue.
18.2 Methodologies
The methodologies to uncover research fronts are based on citation relationships among articles, or more exactly a citation network. In a citation network, each node represents an article, and it is linked to other nodes that it references or is cited by. Using network terminology, a citation network is a non-weighted and directed network. It is non-weighted, because the importance of each citation is regarded as the same. It is directed, as presumed knowledge flows directionally from a cited article to the article that references it.
This study adopts two methods to analyze the citation network established from the collected dataset. We apply the first method, the edge-betweenness based clustering (Girvan and Newman 2002) in association with the optimal modularity concept (Newman 2006), to find coherent groups in the citation network. The second method, key-route main path analysis (Liu and Lu 2012), helps examine the content of each group. The following sections briefly introduce these two methods.
18.2.1 Edge-Betweenness Based Clustering
Grouping articles that address similar issues is an essential step in discovering research fronts. We assume that citation relationships among articles can be used to determine any similarity between articles. If two articles reference several of the same articles and are also cited by several of the same other articles, then the probability of these two articles addressing the same issue is high; otherwise, they probably study quite different problems. Thus, articles that address the same issues form a tightly knitted ‘community’ in a citation network. Based on such a premise, this study adopts the widely used edge-betweenness based clustering (Girvan and Newman 2002) with the assistance of the optimal modularity concepts (Newman 2006) to group similar articles. Both the edge-betweenness clustering and modularity concepts are originated from physicist Mark Newman.
The modularity for a network is defined as “the number of edges (links) falling within groups minus the expected number in an equivalent network with edges placed at random” (Newman 2006). A network with high modularity is dense in connections between the nodes within groups, but sparse in connections between nodes in different groups. The best division for a network is the one that has the largest value of network modularity.
The edge-betweenness of a network link is “the number of shortest paths between pairs of vertices that run along it” (Girvan and Newman 2002). The links that connect groups in the network have high edge-betweenness. The edge-betweenness based clustering relies on this property and removes step by step links with the highest edge-betweenness. In the process, the groups are separated from one another and the underlying group structure is gradually revealed.
The clustering procedure begins with a calculation of edge-betweenness of all existing links in the network. The link with the highest edge-betweenness is then removed. One then recalculates edge-betweenness for the links that are affected by the previous removal, which is followed by removal of the current highest-rank link. Eventually, the network is divided into two groups. At this step, the modularity for such division is computed and recorded. The recalculation and removal steps continue. The modularity is calculated whenever there are existing groups that are divided further. The recalculation and removal steps are repeated until all the links in the network are removed. At this point, one traces back to the network division that has the largest modularity and obtains the grouping result. In practice, we adopt igraph (Csardi and Nepusz 2006) implementation of the algorithm under Microsoft Visual Studio development environment.
18.2.2 Key-Route Main Path Analysis
One of the more widely used extensions of main path analysis is the key-route main path approach (Liu and Lu 2012), which extends the main path analysis originally introduced by Hummon and Dereian (1989). A main path is a connected chain of significant links in an acyclic directed network such as a citation network. In general, the procedure for main path analysis consists of two steps. First, it finds the significance measure “traversal count” for each network link based on the network structure. Search path link count (SPLC) is the algorithm adopted in this study to measure the significance of the links. Second, it searches for the main path(s) based on traversal counts found in the first step. Here, the method as suggested by Hummon and Dereian (1989) searches only forward—that is, it establishes paths from a given network node by moving along the direction of links. The path(s) found this way run the risk of missing many top significant links. The key-route main path approach proposed by Liu and Lu (2012) begins the search from the top significant links, thus guaranteeing the inclusion of these links. It requires specifying the number of the top links (key-routes). For example, key-route 10 specifies that the search begins from the top 10 most significant links. By varying the number of key-routes, one is able to control the level of main path details.
The search in key-route main path analysis starts by picking one top link and searching backward from the tail node of a given link as well as forward from the head node of the same link. The search can be global or local (Liu and Lu 2012). This study adopts the global search, which means connecting the link that deliver the largest overall traversal count value. A path is obtained by joining both forward and backward search results with the link itself. One repeats the same process for all the specified top links. The final key-route main paths are a union of all the paths thus obtained. The key-route main path analysis has been successfully applied to detect technological changes (Chen et al. 2013a; Hung et al. 2014), conducting literature reviews (Chuang et al. 2014; Lu and Liu 2013, 2014), and tracing the decisions of legal opinions (Liu et al. 2014), etc.
18.3 Data
This study obtains data from the Thomson Reuters Web of Science (WOS) database service . Data are separated into two parts in time. Part I ranges from 1978 to 1999, whereas Part II ranges from 2000 to 2014. We use the combination of Parts I and II data to observe the overall DEA development and Part II data to examine the research front. Part I data were taken from the dataset used in a previous study by Liu et al. (2013a) and retrieved on August 2010. Part II data were retrieved from WOS on July 17, 2014.Footnote 1 Since research front is the main objective of this study and it is more likely to be observed from articles published in prestigious journals and highly cited articles, we limit our data to articles published in several prestigious journals as well as top cited articles. In other words, this study considers only articles that are either published in prestigious journals or are highly cited in the WOS database. Certainly, many articles meet both criteria.
In our preliminary dataset, there are more than 400 journals that published at least two DEA-related articles in the period 2000–2014. To select journals, we consulted two journal rating sourcesFootnote 2 and conducted a survey with experts in the field. Twenty experts were issued a survey letter and ten of them responded. In the end, 12 journals are selected, which are listed in Table 18.1.Footnote 3 All the journals selected receive good rankings in the two journal rating sources. More importantly, they are all endorsed by more than five of the experts we consulted as journals that publish quality DEA articles.
In addition to articles published in the 12 selected journals, this study includes the top 400 cited articles in Part I data and the top 500 articles in Part II data. In practice, the data search procedure first filters-in the top cited articles and then takes in those that are published in the selected journals from the remaining articles.Footnote 4 In the end, Part I data consist of 733 articles and Part II data consist of 1595 articles. The sum of both, 2328, is used to analyze overall DEA development.
18.4 Overall DEA Development
Liu et al. (2013a) conduct a citation-based literature survey using data collected in August 2010. The DEA literature has grown tremendously since then. As mentioned in the introduction section, around 2000 DEA papers have been published in the period 2010–2014. This section provides an update to the major results of Liu et al. (2013a). It should be kept in mind, however, that there is a difference in data criteria between this study and the previous one. The previous study includes all DEA articles in the analysis, whereas this study takes only the top cited articles and those articles published in the 12 selected journals.
18.4.1 Researcher Statistics
This section presents top DEA researchers in order to recognize their significant contributions to the field. In the WOS database, some authors are listed by different identities, e.g., by showing or not showing their middle initials. Before identifying the top researchers, we correct authors’ names so that each author has only one identity.
Table 18.2 lists the top 29 DEA authors in the order according to their g-index (Egghe 2006) followed by h-index (Hirsch 2005). It can be regarded as an update to Table 18.1 of Liu et al. (2013a), which covers researchers in the period 1978–2010, while the current table encompasses scholars in the period 1978–2014. The indices are calculated based on citation number listed in the WOS database on April 21, 2015. We also expand the list from top 20 to top 29 in order to maintain the same cutoff point, which is at g-index 19. The list contains certainly DEA pioneers Charnes, Cooper, Banker, etc. One notices that the indices for Charnes are smaller than those in the previous study (Liu et al. 2013a). This is because this current study includes fewer articles in general for all authors and that Charnes did not produce any more DEA papers after 1997. In comparison with the list in the previous study, the table now includes several new names.
18.4.2 Main Paths
Figure 18.1 presents the key-route main paths of DEA development from 1978 to 2014. The number of top key-routes is set to 20. In the figure, the arrow indicates the direction of knowledge flow, and the line thickness reflects the size of its traversal count. The thicker the line is, the more significant the route is. The figure is drawn with Pajek software (Batagelj and Mrvar 1998). The “key-route 20” main paths consist of 50 papers. Each paper in the figure is attached with a notation that begins with the last name of the 1st author followed by the 1st letters of the co-author’s last name and ends with the publication year of the paper. For example, the original paper by Charnes, Cooper and Rhodes in 1978 is indicated as CharnesCR1978.

Key-route main path of overall DEA development (for top 20 key-routes). Link weights are indicated with different line thickness. Thicker lines indicate heavier weights
The main paths take the shape of a tennis racket with one central path (handle) followed by a hoop that consists of papers in various subareas of DEA. There is no surprise that the main path begins from CharnesCR1978 (Charnes et al. 1978), which introduces the renowned CCR model. It then passes through the article that proposes the BCC model (BankersCC1984 (Banker et al. 1984)) and continues to SeifordZ1999a (Seiford and Zhu 1999a) before diverging into two paths. One can see that both the local and global main paths reported in Liu et al. (2013a) are embedded in the paths between CharnesCR1978 to Seiford1996 (Seiford 1996). The similarity between the previous and the current results ends at Seiford1996. New research activities after 2010 change the main paths. Following Seiford1996, which is a review article, SeifordZ1998f (Seiford and Zhu 1998b), SeifordZ1998d (Seiford and Zhu 1998a), and SeifordZ1999a make up a series of studies on sensitivity analysis and super-efficiency models.
Following SeifordZ1999a are two paths, each one including papers that focus on various topics in DEA. In a scientific field with a dominant subarea, all papers on the main paths can belong to the same subarea. On the other hand, in a scientific field with several subareas of roughly equal awareness, as is the case we have seen here for DEA, one can have papers in different subareas alternating on the main path. The subject of interest of the papers on the paths actually hints that the subareas are significant in the historical development of DEA.
The two paths following SeifordZ1999a contain papers discussing the subject of super-efficiency, slacks-based measure, network DEA, dynamic DEA (upper path), as well as banking and environmental studies (lower path). On the upper path, Zhu2001 (Zhu 2001) continues the development of applying a super-efficiency concept for the sensitivity analysis. Tone2002 (Tone 2002) introduces a slacks-based measure of super-efficiency. Avkiran2009a (Avkiran 2009b) proposes a four-stage approach designed to remove the impact of exogenous factors. Avkiran2009b (Avkiran 2009a) demonstrates network DEA in a slacks-based measure format using UAE bank data. ToneT2010b (Tone and Tsutsui 2010) develops a dynamic DEA model in a slacks-based measure framework. CookLZ2010 (Cook et al. 2010a) reviews the two-stage process DEA models that are a special case of network DEA models. ZhongYLH2011 (Zhong et al. 2011) investigates R&D performance in China. ChenDH2013 (Chen et al. 2013c) and FangLHC2013 (Fang et al. 2013) present novel variations on the super-efficiency model.
The lower path consists of two articles on banking and a series of articles that study environmental performance. SeifordZ1999c (Seiford and Zhu 1999b) is the first to introduce a two-stage process concept to study bank performance. MukherjeeNP2003 (Mukherjee et al. 2003) applies a similar two-stage process concept to measure the efficiency of banking service in India. The topic then turns to methods to deal with undesirable factors which are essential common in energy and environmental studies. Ramanathan2005b (Ramanathan 2005) applies DEA to forecast energy consumption and CO2 emissions. ZhouAP2008b (Zhou et al. 2008) conducts a comprehensive literature survey on the application of DEA to energy and environmental studies. It is followed by a series of works by Sueyoshi and colleagues (SueyoshiGU2010 (Sueyoshi et al. 2010), SueyoshiG2010b (Sueyoshi and Goto 2010b), SueyoshiG2011b (Sueyoshi and Goto 2011a), SueyoshiG2012 (Sueyoshi and Goto 2012), and SueyoshiG2013 (Sueyoshi and Goto 2013)), which evaluate performances of coal-fired power plants, petroleum industry, etc. with an emphasis on the methods used to deal with undesirable (bad) outputs.
The two paths cascade to LiuLLL2013b (Liu et al. 2013b), which surveys DEA applications through a bibliometric method. DaiK2014 (Dai and Kuosmanen 2014) proposes an approach that combines DEA with clustering methods to benchmarking DMUs.
The key-route main paths highlight many highly recognized works in DEA development. No doubt, many important works are not revealed, but it does sketch the outlines of a grand DEA development especially in the early stage. The key-route main path approach expands the traditional method, thus providing us a richer view of the development trajectory. After SeifordZ1999a, the main paths include discussions on various subjects of DEA. Are these discussions truly representative of recent DEA research activities? The next section investigates further to answer the question.
18.5 DEA Research Fronts
The key-route main paths presented in the previous section highlight certain aspects of overall DEA development, but may not reveal enough detail of the research fronts. This section focuses on more recent articles and applies the edge-betweenness clustering method to Part II dataset (2000–2014) in order to discover active DEA research subareas in recent years. One issue needs to be addressed before clustering, and that is whether to include in the analysis survey type articles in which their discussions encompass the whole DEA field. Survey type articles impose a difficulty in clustering, because they logically do not belong to any of the subareas. There are four such articles (Cook and Seiford 2009; Cooper et al. 2007; Liu et al. 2013a, b) during the period 2000–2014. In order to know the difference these four articles can make, we conduct a pilot analysis that analyzes two datasets. One includes all articles in Part II dataset while the other has the four survey articles removed. The results show that the network modularity of the two analyses is 0.513 and 0.525, respectively, out of scale from 0 to 1. The one without the four review articles provides a better clustering result, as indicated by its higher network modularity, and thus we adopt it in this study.
Edge-betweenness clustering divides the DEA citation network into groups of various sizes. The largest group contains 156 articles, while the smallest includes only one article. Four groups have a size greater than 100, consisting of 156, 156, 152, and 147 articles, respectively. The total number of papers in the top four groups is 611, which amounts to 38.3 % of Part II data. The sizes of the groups ranked number 5th to 10th are 97, 55, 47, 47, 38, and 32. Taken together, the top 10 groups contain 927 (58.1 %) of Part II data. The remaining groups are of size 29 and smaller. Among them, 91 groups are of size less than 5. The majority of these small-size groups are either isolated nodes or ‘islands’ in the citation network. Reporting results with so many small size groups is actually one of the advantages of edge-betweenness clustering methods—it does not enforce an attachment of an entity to a seemingly irrelevant group, like what is done in the K-means method. It leaves remotely relevant entities alone as small groups .
Those groups of a larger size are the subareas that have a large amount of coherent research activities and can therefore be regarded as the research fronts in DEA. In the following discussions, we concentrate on the four largest groups and apply key-route main path analysis to each group in order to identify the essence of each research front. The key-route main paths are created from the top 10 key-routes. The groups ranked number 5th–10th, however, deserve brief notes. They are discussed together at the end of this section.
To comprehend the contents of each group, we count keywords in the titles and abstracts of the articles in each group. The keywords are selected from a list of terms used in all the articles excluding stop-wordsFootnote 5 and words that are too common in DEA such as ‘DEA’, ‘efficiency’, ‘model’, ‘measure’, etc. Variations of terms with identical or similar meanings are regarded as the same keywords—for example, ‘cross efficiencies’, ‘cross efficiency’, ‘cross-efficiencies’, and ‘cross-efficiency’ are all treated as the same keywords.
Table 18.3 presents the results of the keyword analysis. Keywords within each group are listed in the order of their appearance count. Only keywords with an average appearance count greater than 0.12 are listed. Except for the 1st and 4th groups, the focus for each group is identified from the keywords without much struggle. For example, the 2nd group includes mostly terms related to energy and environment and undesirable factors, while ‘cross-efficiency’ is the prevailing term in the 3rd group.
The 1st and 4th groups both have ‘stage’ as the top word and seem to contain several other irrelevant terms. The term ‘stage’ is used widely in the DEA literature, especially in network structure models and contextual analysis methodology. In the context of network structure models, a two-stage process model or two-stage network model refers to a special case of the general network DEA models where a DMU’s operation is divided into two processes and all outputs from the first stage become the only inputs to the second stage. In contextual analysis methodology, two-stage or multi-stage analysis indicates that additional regression analysis is applied to determine the exogenous factors that affect the efficiency. The 1st group includes the term ‘regression’, and so ‘stage’ has to be used in the context of two-stage contextual factor analysis. The 4th group contains terms on new methodologies such ‘slacks-based measure’ (SBM), ‘network DEA’ , and ‘dynamic ’. Thus, it is reasonable to assume that the term ‘stage’ in this group is related to a two-stage process model. The terms ‘banking’ and ‘financial’ in this group can be interpreted as these new methodologies using banking and financial data to test their new models.
Based on the observations and discussions above, we determine that the four research fronts are “bootstrapping and two-stage analysis”, “undesirable factors”, “cross-efficiency and ranking”, and “network DEA, dynamic DEA, and SBM”. All of them focus on methodologies and techniques. From methodological point of view, it may not be appropriate to group SBM with network and dynamic DEA. They are grouped together here because some of the network and dynamic DEA are based upon SBM.
These four subareas show, nevertheless, dissimilar paper growth trends. The last row in Table 18.3 presents the trend of the number of papers for each subarea. The first three subareas exhibit somewhat jagged growth while the 4th subarea “network DEA, dynamic DEA, and SBM” displays a surge in the period 2008–2012.
A previous study (Liu et al. 2013a) mentions five active subareas—“two-stage contextual factor evaluation framework”, “extending models”, “handling special data”, “examining the internal structure”, and “measuring environmental performance”—using a dataset for the period 1978–2010. In comparison, three of them continue as active subareas: “two-stage contextual factor evaluation framework” (now as “bootstrap and two-stage analysis”), “examining the internal structure” (now as “network DEA, dynamic DEA, and SBM”), as well as “measuring environmental performance” (now as “undesirable factors”). We elaborate on the contents of these four research fronts in the following subsections.
18.5.1 Bootstrapping and Two-Stage Analysis
DEA does not embed a statistical concept in its original methodology. This particular research stream integrates two statistical methodologies into DEA. The first one, bootstrapping, constructs a base for statistical inference in DEA. The second, two-stage analysis, establishes procedures for contextual factor analysis.
Bootstrapping refers to regenerating original input/output data repeatedly according to a specified statistical distribution. The purpose of the technique is to mimic the sampling distribution of the original data, thus allowing the estimation of data bias and the construction of confidence intervals for efficiency scores. The additional confidence interval information for efficiency scores can be useful for decision makers. The main paths for this research front, shown in Fig. 18.2, begin with SimarW2000 (Simar and Wilson 2000) which extends their earlier work (Simar and Wilson 1998) on bootstrapping in non-parametric frontier models and proposes a general methodology. SimarW2002 (Simar and Wilson 2002) presents another bootstrap procedure, this time for testing hypotheses regarding returns to scale in DEA models. Wilson2003 (Wilson 2003) discusses independence test methods under the premise that an independence condition can simplify the bootstrap procedure.

Key-route main path for “bootstrapping and two-stage analysis” research front (for top 8 key-routes)
Finding the contextual factors that affect the efficiency has a strong need for many DEA applications and is the emphasis of many studies. This is usually done through a two-stage procedure that typically begins by calculating DEA efficiency scores and then regressing these scores on contextual factors. As to which regression model is the most proper to use in the second stage is a subject of intense debates. The next study on the main paths, SimarW2007 (Simar and Wilson 2007), suggests that a maximum likelihood estimation of a truncated regression rather than tobit is the preferred approach. BankerN2008 (Banker and Natarajan 2008) indicates that ordinary least squares (OLS), maximum likelihood, and tobit regression are all appropriate. Mcdonald2009 (McDonald 2009) advocates using OLS and not using tobit. RamalhoRH2010 (Ramalho et al. 2010) proposes to use fractional regression models. SimarW2011a (Simar and Wilson 2011) compares the approaches in SimarW2007 and BankerN2008 in detail. BadinDS2012 (Badin et al. 2012) suggests a new two-stage type approach for detecting the impact of contextual factors by using a conditional efficiency measure. JohnsonK2012 (Johnson and Kuosmanen 2012) offers a method that directly integrates the regression model into the standard DEA formulation and develop a new one-stage semi-nonparametric estimator .
Two-stage analysis is a useful tool for decision makers who are looking for improving performance while coping with environmental factors. The development in this area in the last few years largely advances our understanding on the assumptions and constraints of the methodology. From a practical point of view, the current state of development, nevertheless, still leaves some confusion to practitioners whose true need is a clear guidance on what methodology to use.
18.5.2 Undesirable Factors
Applying DEA to measure energy and environmental performance faces a special situation where an increase in output level may not be desirable. This is particularly so for some output factors such as wastes, pollutants, and noise. Most of the studies in this subarea focus on the methods that deal with such undesirable outputs. These methods resort to extending into the area of reference technology and/or efficiency measure under the traditional DEA framework (Zhou et al. 2008).
SeifordZ2002 (Seiford and Zhu 2002) and HailuV2001 (Hailu and Veeman 2001) lead the main paths for this research front as shown in Fig. 18.3. HailuV2001 suggest a method equivalent to treating undesirable outputs as inputs. SeifordZ2002, on the other hand, propose to deal with undesirable outputs by applying a monotone decreasing transformation to them. FareG2004 (Fare and Grosskopf 2004) advocates the concept of weak disposability and suggests applying a directional distance function efficiency measure. Weak disposability of outputs means that the model mandates a proportional reduction of both desirable and undesirable outputs and that the reduction of only undesirable outputs is impossible. ZhouAP2006 (Zhou et al. 2006) and ZhouPA2007 (Zhou et al. 2007) adopt weak disposability reference technology, but use slacks-based and non-radial measures, respectively, to evaluate the environmental performance of OECD countries.

Key-route main path for “ undesirable factors” research front (for top 10 key-routes)
ZhouAP2008a, as mentioned i n Sect. 18.4.2, presents a review article. It is followed by a series of works by Sueyoshi and colleagues (SueyoshiGU2010 (Sueyoshi et al. 2010), SueyoshiG2010a (Sueyoshi and Goto 2010a), SueyoshiG2010b (Sueyoshi and Goto 2010b), SueyoshiG2011a (Sueyoshi and Goto 2011a), SueyoshiG2011b (Sueyoshi and Goto 2011b), and SueyoshiG2012 (Sueyoshi and Goto 2012)). Several of these works are also on the overall main path discussed in Sect. 18.4.2. The most recent study, ZhouAW2012 (Zhou et al. 2012), applies a directional distance function approach to measure energy and CO2 emission performance in electricity generation.
In summary, the core studies in this subarea evolve around approaches to deal with undesirable output and the attention on the performance of energy and environmental system remains strong as the challenges from energy and pollution have never been more demanding. To further extend the power of modern DEA, applying a network DEA concept to tap into the inner workings of energy and environment systems may be an interesting topic for future research.
18.5.3 Cross-Efficiency and Ranking
The cross-efficiency concept was first proposed by Sexton et al. (1986) in 1986, but did not emerge as a serious alternative DEA approach until Doyle and Green (1994) re-examine it in detail in 1994. The concept increases the discriminating power of DEA by conducting peer-evaluation as opposed to self-evaluation in the traditional DEA model. It is associated closely with the idea of ranking and is widely used in applications where the ranking of DMUs is needed. As shown in Fig. 18.4, the key-route main paths for this subarea begin with a review article on ranking methods. AdlerFS2002 (Adler et al. 2002) review six ranking methods, including cross-efficiency, under the DEA context.

Key-route main path for “cross-efficiency and ranking” research front (for top 10 key-routes)
Four studies following AdlerFS2002 all share an interest in ranking the performance of countries in the Olympics. LinsGDD2003 (Lins et al. 2003) proposes a zero-sum gains model. ChurilovF2006 (Churilov and Flitman 2006) integrates data mining techniques to DEA. WuLY2009 (Wu et al. 2009a) and WuLC2009 (Wu et al. 2009b) apply a cross-efficiency model, while the latter propose a DEA game cross-efficiency model where each DMU is viewed as a competitor via a non-cooperative game.
The remaining parts of the main paths are dominated by articles that propose alternative approaches to improve the cross-efficiency analysis. A core issue in cross-efficiency evaluation is that it may give multiple efficiency scores resulting from alternate optima in solving the linear programming model. Doyle and Green suggest solving this non-uniqueness problem with the use of secondary goals, which include two alternatives called benevolent and aggressive formulations. These secondary goals are related to weight determination. Different from benevolent and aggressive formulations, WangC2010a (Wang and Chin 2010) and WangCW2012 (Wang et al. 2012) propose formulations that determine the input and output weights in a neutral way. RamonRS2010b (Ramon et al. 2010) and RamonRS2011 (Ramon et al. 2011) move further along the idea of WangC2010a. WangC2011 (Wang and Chin 2011) offers a study on the aggregation process in calculating cross-efficiency. RuizS2012 (Ruiz and Sirvent 2012) suggest calculating the cross-efficiency scores using a weighted average rather than an arithmetic mean. AlcarazRRS2013 (Alcaraz et al. 2013) put forward a method that has no need to choose a weighting method and yield a range of possible rankings for each DMU.
As shown in Table 18.3, keywords in this subarea center on only three terms. In fact, it is a truly very focused subarea. Such a large coherent block of research studies indicates that many issues in cross-efficiency remain to be resolved and that there probably has not been a consensus on the method to address the issues in the original cross-efficiency concept. For example, a recent review on cross-efficiency (Cook and Zhu forthcoming) discusses two other alternative approaches including the game cross efficiency methodology of Liang et al. (2008) and the maximum cross efficiency concept of Cook and Zhu (2013).
18.5.4 Network DEA, Dynamic DEA, and SBM
Another chunk of coherent literature consists of several fast evolving DEA topics: SBM, network DEA, and dynamic DEA. There is no surprise that network DEA and dynamic DEA are assigned to the same group as they are conceptually associated with each other. Nevertheless, SBM is grouped with network and dynamic DEA for the reason that some of the network and dynamic DEA are based upon SBM.
The term ‘network DEA’ was first used in Färe and Grosskopf (2000) in 2000. This work is the most likely candidate for the leading articles on the main paths of this research front. Due to a limitationFootnote 6 of this current study, it is not shown on the main paths. In the summary section of the article, Färe and Grosskopf notes: “The basic idea of the network model is to ‘connect’ processes—providing a single model framework for multi-stage production (with intermediate products, for example) or multi-period production” (Färe and Grosskopf 2000) wherein ‘multi-stage production’ and ‘multi-period production’ can be regarded as the origin of network DEA and dynamic DEA concepts, respectively.
The main paths for this group, as shown in Fig. 18.5, begin with three research streams that eventually merge to Tone’s work on dynamic DEA, ToneT2010 (Tone and Tsutsui 2010), and then divide into two research activities. Tone2001 (Tone 2001) leads the first research stream, introducing SBM. SBM, as opposed to the radial measure used in the traditional CCR (Charnes et al. 1978) and BCC (Banker et al. 1984) models, measures efficiency based on the input excesses and output shortfalls. AvkiranR2008 (Avkiran and Rowlands 2008) and Avkiran2009a (Avkiran 2009b) extend a three-stage procedure proposed in Fried et al. (2002) by infusing SBM into the procedure. The procedure accounts for environmental effects and statistical noise in the efficiency measure. Avkiran2009b (Avkiran 2009a), in parallel with ToneT2009 (Tone and Tsutsui 2009), proposes a model for network SBM.

Key-route main paths for “network DEA, dynamic DEA, and SBM” research front (for top 10 key-routes)
The second stream begins with Zhu2000 (Zhu 2000) and ChenLYZ2006 (Chen et al. 2006). Zhu2000 suggests measuring bank performance in two process stages. ChenLYZ2006 proposes a two-stage process model that is an improvement over a model they propose earlier (Chen and Zhu 2004). The core of this stream, however, is a series of studies by Kao that propose several relational models (KaoH2008 (Kao and Hwang 2008), Kao2009a (Kao 2009a), and Kao2009b (Kao 2009b)). ToneT2009 (Tone and Tsutsui 2009) extends the network DEA model to the SBM framework.
In the third research stream, CastelliPU2001 (Castelli et al. 2001) presents a model that considers the case of specialized and interdependent subunits in a DMU. LewisS2004b (Lewis and Sexton 2004) proposes a network DEA model with a different reference set definition than that proposed in Färe and Grosskopf (2000). Chen2009 (Chen 2009) incorporates dynamic effects into a network DEA model.
The merging article, ToneT2010 (Tone and Tsutsui 2010), extends the dynamic DEA concept proposed by Färe et al. (1996) within the SBM framework. CookLZ2010 (Cook et al. 2010a) reviews the existing two-stage process models. The remaining studies on the main paths, except ZhongYLH2011 (Zhong et al. 2011), are all the latest studies on network DEA or dynamic DEA. LiCLX2012 (Li et al. 2012) extend the two-stage network structure by allowing inputs to the second stage to come from sources other than the outputs of the first stage. AktherFW2013 (Akther et al. 2013) applies two-stage process model to study bank efficiencies. Kao2014b (Kao 2014a) discusses a general multi-stage DEA model. The model defines efficiency in a different way than that defined by Cook et al. (2010b). ChenCKZ2013 (Chen et al. 2013b) discusses the differences between the multiplier and envelopment network DEA models and points out the functions of each. ToneT2014 (Tone and Tsutsui 2014) offers a model that combines the network DEA and dynamic DEA models under the SBM framework. KaoH2014 (Kao and Hwang 2014) proposes a multi-period two-stage DEA model.
The research activities in this subarea have moved at a very fast pace since 2008. One indication mentioned earlier is that the papers in this subarea have surged during the period 2008–2012. Another indication is the number of review articles. As of 2014, there are already three review papers for this subarea (Castelli et al. 2010; Cook et al. 2010a; Kao 2014b). The most recent review by Kao (2014b) indicates several future research directions for this subarea, including the type of data used, the Malmquist index for network systems, and dynamic analysis of network systems. Incorporating a time factor into the network structure is clearly the core research activity in this research front.
18.5.5 Other Coherent Subareas
In addition to the four research fronts, six smaller coherent research subareas deserve brief notes. Their group sizes are 97, 55, 47, 47, 38, and 32 respectively. For these groups, we list papers with relative high citation counts to highlight their subject of interests. We remind readers that the discussions herein include only papers in Part II data.
The 5th group focuses on banking application. Banking had been at the top of DEA applications over the period 1978–2010 as indicated in Liu et al. (2013b). In this current study, many of the papers examining bank data are clustered into other groups due to the fact that their emphases are on methods and techniques. Cook et al. (2000), Cook and Hababou (2001), Paradi and Schaffnit (2004), and Paradi et al. (2011) apply various techniques to examine the performance of bank branches. Asmild et al. (2004) evaluate Canadian bank performances over time by combining DEA window analysis with the Malmquist index. Two review articles (Fethi and Pasiouras 2010; Paradi and Zhu 2013) are good references on the progress of research in applying DEA to measure bank performances.
The 6th group emphasizes on fuzzy and imprecise DEA. Traditional DEA assumes that input and output data are crisp and precise, but the assumption may not always be true in the real world. Data can be fuzzy (vague, fluctuate), or it can be imprecise (bounded, ordinal, or ratio bounded). Kao and Liu (2000), Guo and Tanaka (2001), Lertworasirikul et al. (2003), and Wang et al. (2005) propose different approaches to handle fuzzy input and output data. Hatami-Marbini et al. (2011) survey and classify fuzzy DEA methods. Cooper et al. (2001) illustrate the use of imprecise DEA. Zhu (2003) reviews the methods to handle imprecise data.
The next group centers on profit and cost efficiency studies. Most of the studies in this group propose methods or models to deal with various profit and cost efficiency measurement situations, including price under the most and least favorable scenarios (Camanho and Dyson 2005), the law of one price (Kuosmanen et al. 2006), incomplete price information (Kuosmanen and Post 2001), and price depending on negotiation (Camanho and Dyson 2008).
Centralized resource allocation is the main subject of the 8th group. There can be situations where a centralized decision maker supervises all DMUs, such that maximizing overall efficiency across units becomes one of his objectives in addition to maximizing individual units. Beasley (2003), Lozano and Villa (2004), Asmild et al. (2009), and Lozano et al. (2004) propose models that cope with such situations.
The main theme of the 9th group is variable selection. DEA results are sensitive to the number of input/output variables. Several papers in this group propose methods and procedures to make the best selection of variables (Cinca and Molinero 2004; Jenkins and Anderson 2003; Pastor et al. 2002; Wagner and Shimshak 2007), or to cope with a large number of variables (Meng et al. 2008).
The 10th group is about models that handle stochastic data. Cooper et al. (2002) propose to apply chance constrained programming to deal with stochastic data. Ruggiero (2004) and Kao and Liu (2009) work on problems with stochastic data using a simulation technique. Dyson and Shale (2010) discuss approaches to handle uncertainty in DEA which includes bootstrapping, Monte Carlo simulation, and change constrained DEA.
18.6 DEA Applications
DEA started out as a theoretical method and found its way into a broad spectrum of applications. In terms of volume, the research papers that apply DEA are now well exceeding those developing theoretical models. In this section, we present several facts related to DEA applications in the light to familiar the readers with the buildup in applications and their association with theoretical models.
A clarification on the meaning of ‘application’ herein is nevertheless necessary before proceeding further. Many DEA papers touch on both methodologies and real world applications. There are basically three types of DEA papers: purely-methodological, application-centered, and theory-together-with-empirical-data (Liu et al. 2013b). The first type, purely-methodological , elaborates on mathematics and models, but does not relate to empirical data, although occasionally some simulated data are used to test the theory. Examples are Banker et al. (1984), who present only mathematics, and Tone (2001), who illustrates the proposed model with a set of artificial data. The second type, application-centered , applies an already developed approach to a real world problem. The focus is mainly on application. Examples are Karkazis and Thanassoulis (1998) and Ma et al. (2002), who apply existing DEA models to study the efficiencies of Greece’s public investment and China’s iron and steel industry, respectively. In-between the two extremes is the third type, theory-together-with-empirical-data . This type proposes a methodological innovation and then validates or tests the proposed method with a set of empirical data. It may put strong emphasis on the application or simply adopt a previous empirical data to test the model. Examples for the former case are Sahoo and Tone (2009) and Kao and Hwang (2008), whereas the latter include Cook and Zhu (2006) and Chen et al. (2006). The contribution to the theory also varies widely in these studies. Practically, it is not easy to differentiate between the second- and the third-type works as there is a wide spectrum on how the authors balance the weight between the models and applications. Herein, as in Liu et al. (2013b), both of the application-centered and theory-together-with-empirical-data are regarded as application-embedded papers, or simply application papers.
In the remaining part of this section, we begin with presenting the evolution of DEA applications. It is followed by a discussion of prevailing DEA applications. In the end, we discuss the association between DEA methods and applications.
18.6.1 Catching Up of DEA Applications
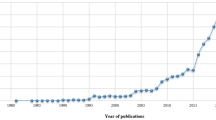
Liu et al. (2013b) analyze their data collected in August, 2010 and find that among all DEA papers, 36.5 % are purely-methodological and 63.5 % are application-embedded, or roughly one-third purely-methodological and two-third application-embedded. They also point out that this one-to-two ratio between types is not how it was during the early stage of the DEA evolution. In the first 20 years of DEA development, purely-methodological articles outnumbered application-embedded papers. It was not until 1999 that the accumulated number of application-embedded papers caught up to the number of purely-methodological papers. Figure 18.6 shows the growth trend of both categories.

Accumulated number of purely theoretical and application DEA papers (Source: Liu et al. 2013b)
18.6.2 Prevailing DEA Application
As regards to prevailing DEA applications, Liu et al. (2013b) suggest that as of 2010 the top five applications are banking, health care, agriculture and farm, transportation, and education. These five applications make up 41.0 % of all application-embedded papers.
It is interesting to know if the emphasis on applications changes with time. In contrast to manually classify the papers as did in Liu et al. (2013b), this study conducts an automatic keyword analysis, and on a fairly recent data—the Part II data. In these papers, only the titles and abstract are examined. We first identify 13 applicationsFootnote 7 and their associated terms. The associated terms are the words or phrases that hint the use of empirical data on certain application. For example, emission, pollution, energy efficiency, environmental performance, etc. are the terms related to energy and environment application whereas hospital, medical, pharmaceutical, etc. are related to health care application. Whenever a paper contain at least one application specific terms, it is labeled as an article for that application. Papers may be assigned two or more applications if they contains terms for more than one application. Finally, one counts the number of papers for each application.
The result is presented in Table 18.4, which shows scholar’s preference of applications in the period 2000–2014. The table is ordered according to the number of papers. The application that attracts the most attention is still banking, which is followed by energy and environment, education, health care, and transportation. The remaining five applications are finance, agriculture and farm, power, tourism, and manufacturing. Notably, the rank for energy and environment application has jumped sharply from number eight to the second.
18.6.3 Association Between Methodologies and Applications
Liu et al. (2013b) examine how methodological works were used in banking, health care, agriculture and farm, transportation, and education. It was done by counting the citations some major methodological papers received by these five application papers. No obvious preferences for each application were observed but there is a general trend of citing network DEA and two-stage analysis modeling articles. It should be noted that this results reflect the status in and before 2010. Fast development of new methodologies and some applications in recent years, may have changed the adoption of models in different applications.
This study re-examine the issue by applying keyword analysis to the recent data (Part II data). We check the usage of application terms in each of the four research fronts, noticing that all these four research fronts focus on methodologies and techniques. In other words, we compare the number of times certain applications are ascribed in each of the four recently popular methodologies. The results are presented in Fig. 18.7. In contrast to the previous results, the preferences of some of the applications on certain methodologies are obvious. Energy and environment as well as power applications largely apply undesirable factor models. Agriculture and farm as well as manufacturing applications are also dominated by undesirable factor model. The results make sense because all these four applications have bad outputs to deal with. Banking and financial applications are associated largely with network DEA and SBM models. Education and health care applications prefer to adopt two-stage analysis. Transportation application does not seem to have clear preference on models while tourism application is not much associated with the four research fronts.

Association between methodologies and applications
The results of this association analysis imply wide-open research opportunities. Certain preferences of methodologies are rooted in the characteristics of applications. For example, energy and environment applications contain bad outputs thus it is natural to adopt models that are able to handle undesirable factors. Yet many research front methodologies can be applied universally. For example, two-stage analysis is suitable for determining the contextual factors that affect efficiency in all types of application. Network DEA is quite appropriate for examining a process’s efficiency in more details. The new methodologies provide opportunities for deeper analyses but many applications have not taken full opportunities from these new methodologies. A caveat is that whether such opportunities really are able to provide meaningful results are up to the judgment of experts in t he field.
18.7 Conclusions
The large amount of DEA literature has made it difficult to conduct general surveys using qualitative approaches, thus increasing the need for applying quantitative and systematic approaches in surveying scientific and technological fields. Citation-based analysis, although widely accepted in the research community, has drawn some criticisms, including no discrimination on the level of citation relevancy, self-citation, remote citation, etc. Remote citation is the situation where an article references others in a very broad sense, such as the same application area, the same general method, or even just because of applying the same methodology. Researchers have proposed methods to address some of these shortcomings—for example, Liu et al. (2014) propose methods to handle citations with different levels of relevancy. In addition to issues in citation-based methodology, data in this study are taken only from WOS. Some DEA articles of certain importance may be ignored. Bearing these limitations in mind, we present the research fronts in DEA for the period 2000–2014.
We identifies four research fronts: “bootstrapping and two-stage analysis”, “undesirable factors”, “cross-efficiency and ranking”, and “network DEA, dynamic DEA, and SBM”. All of them focus on methodologies and techniques. From the science and technology evolution point of view, two of the research fronts seem to be at a stage that seeks a “dominant design” (Anderson and Tushman 1990; Utterback and Abernathy 1975). The intense debate in the two-stage analysis subarea, over which is the best regression model to adopt, seems to have not yet reached a conclusion. For the network DEA and dynamic DEA subareas, an intellectual exchange that looks for a simple universal model remains to be expected.
The top five applications in the period 2000–2014 are banking, energy and environment, education, health care, and transportation. Growth in energy and environment application is in particular high. Some applications have not incorporated methodologies introduced in recent years. Research opportunities are wide open considering that there are many such gaps to close.
This study contributes to both the DEA and the bibliometric fields. For the former, we present the most recent research fronts that help increase our understanding on those research activities that have continued to make this 35-year old methodology a solid scientific field. It should be noted that the main paths, similar to citation networks, are dynamic. New articles, along with the articles they reference, are changing the main paths day in and day out. What we have presented herein is only a snap shot at the current point in time. As for the contribution to the bibliometric field, the methodology in this study that combines the clustering method and key-route main path analysis turns out to be very effective in exploring research fronts and can be used as a model for future studies targeting research fronts, in DEA, or any other scientific and technology field.
Notes
- 1.
Part II data thus contain only articles in the first half of 2014.
- 2.
The two sources are the Harzing Journal Quality List (http://www.harzing.com/pop.htm) and The ABDC Journal Quality List (http://www.abdc.edu.au/pages/abdc-journal-quality-list-2013.html).
- 3.
In the same survey, several experts indicate that they do not feel comfortable with DEA papers published in some journals. Among them, African Journal of Business Management, Applied Mathematics and Computation, and Expert Systems with Applications are high on the list.
- 4.
The procedure preserves medium to high cited articles even though they are not in the 12 selected journals.
- 5.
Stop words include ‘about’, ‘become’, ‘could’, ‘give’, ‘please’, ‘seems’, ‘under’, ‘whereas’, etc., to name a few.
- 6.
The article is published in the Socio-economic Planning Sciences journal, which is not listed in the WOS database. Thus, no citation information is available for the article.
- 7.
These 13 applications are banking, health care, agriculture and farm, transportation, education, (electrical) power, manufacturing, energy and environment, communication, finance, insurance, tourism, and fishery.
References
Adler N, Friedman L, Sinuany-Stern Z (2002) Review of ranking methods in the data envelopment analysis context. Eur J Oper Res 140:249–265
Akther S, Fukuyama H, Weber WL (2013) Estimating two-stage network slacks-based inefficiency: an application to Bangladesh banking. OMEGA Int J Manag Sci 41:88–96
Alcaraz J, Ramon N, Ruiz J, Sirvent I (2013) Ranking ranges in cross-efficiency evaluations. Eur J Oper Res 226:516–521
Anderson P, Tushman ML (1990) Technological discontinuities and dominant designs: a cyclical model of technological change. Adm Sci Q 35:604–633
Angulo-Meza L, Lins MPE (2002) Review of methods for increasing discrimination in data envelopment analysis. Ann Oper Res 116:225–242
Asmild M, Paradi J, Aggarwall V, Schaffnit C (2004) Combining DEA window analysis with the Malmquist index approach in a study of the Canadian banking industry. J Prod Anal 21:67–89
Asmild M, Paradi JC, Pastor JT (2009) Centralized resource allocation bcc models. OMEGA Int J Manag Sci 37:40–49
Avkiran N (2009a) Opening the black box of efficiency analysis: an illustration with UAE banks. OMEGA Int J Manag Sci 37:930–941
Avkiran N (2009b) Removing the impact of environment with units-invariant efficient frontier analysis: an illustrative case study with intertemporal panel data. OMEGA Int J Manag Sci 37:535–544
Avkiran NK, Rowlands T (2008) How to better identify the true managerial performance: state of the art using DEA. OMEGA Int J Manag Sci 36:317–324
Badin L, Daraio C, Simar L (2012) How to measure the impact of environmental factors in a nonparametric production model. Eur J Oper Res 223:818–833
Banker R, Natarajan R (2008) Evaluating contextual variables affecting productivity using data envelopment analysis. Oper Res 56:48–58
Banker RD, Charnes A, Cooper WW (1984) Some models for estimating technical and scale inefficiencies in data envelopment analysis. Manag Sci 30:1078–1092
Batagelj V, Mrvar A (1998) Pajek-program for large network analysis. Connections 21:47–57
Beasley JE (2003) Allocating fixed costs and resources via data envelopment analysis. Eur J Oper Res 147:198–216
Berger AN, Humphrey DB (1997) Efficiency of financial institutions: international survey and directions for future research. Eur J Oper Res 98:175–212
Camanho AS, Dyson RG (2005) Cost efficiency measurement with price uncertainty: a DEA application to bank branch assessments. Eur J Oper Res 161:432–446
Camanho A, Dyson R (2008) A generalisation of the Farrell cost efficiency measure applicable to non-fully competitive settings. OMEGA Int J Manag Sci 36:147–162
Castelli L, Pesenti R, Ukovich W (2001) DEA-like models for efficiency evaluations of specialized and interdependent units. Eur J Oper Res 132:274–286
Castelli L, Pesenti R, Ukovich W (2010) A classification of DEA models when the internal structure of the decision making units is considered. Ann Oper Res 173:207–235
Charnes A, Cooper WW, Rhodes E (1978) Measuring the efficiency of decision making units. Eur J Oper Res 2:429–444
Chen C-M (2009) A network-DEA model with new efficiency measures to incorporate the dynamic effect in production networks. Eur J Oper Res 194:687–699
Chen Y, Zhu J (2004) Measuring information technology’s indirect impact on firm performance. Inf Technol Manag 5:9–22
Chen Y, Liang L, Yang F, Zhu J (2006) Evaluation of information technology investment: a data envelopment analysis approach. Comput Oper Res 33:1368–1379
Chen Y-B, Liu JS, Lin P (2013a) Recent trend in graphene for optoelectronics. J Nanopart Res 15:1–14
Chen Y, Cook WD, Kao C, Zhu J (2013b) Network DEA pitfalls: divisional efficiency and frontier projection under general network structures. Eur J Oper Res 226:507–515
Chen Y, Du J, Huo J (2013c) Super-efficiency based on a modified directional distance function. OMEGA Int J Manag Sci 41:621–625
Chuang TC, Liu JS, Lu LY, Lee Y (2014) The main paths of medical tourism: from transplantation to beautification. Tour Manage 45:49–58
Churilov L, Flitman A (2006) Towards fair ranking of Olympics achievements: the case of Sydney 2000. Comput Oper Res 33:2057–2082
Cinca CS, Molinero CM (2004) Selecting DEA specifications and ranking units via PCA. J Oper Res Soc 55:521–528
Cook W, Hababou M (2001) Sales performance measurement in bank branches. OMEGA Int J Manag Sci 29:299–307
Cook WD, Seiford LM (2009) Data envelopment analysis (DEA)–thirty years on. Eur J Oper Res 192:1–17
Cook WD, Zhu J (2006) Rank order data in DEA: a general framework. Eur J Oper Res 174:1021–1038
Cook W, Zhu J (2013) DEA Cobb-Douglas frontier and cross-efficiency. J Oper Res Soc 65:265–268
Cook W, Hababou M, Tuenter H (2000) Multicomponent efficiency measurement and shared inputs in data envelopment analysis: an application to sales and service performance in bank branches. J Prod Anal 14:209–224
Cook W, Liang L, Zhu J (2010a) Measuring performance of two-stage network structures by DEA: a review and future perspective. OMEGA Int J Manag Sci 38:423–430
Cook WD, Zhu J, Bi G, Yang F (2010b) Network DEA: additive efficiency decomposition. Eur J Oper Res 207:1122–1129
Cook WD, Tone K, Zhu J (2014) Data envelopment analysis: prior to choosing a model. OMEGA Int J Manag Sci 44:1–4
Cook WD, Zhu J (2015) DEA cross efficiency. In: Zhu Joe (ed) Data envelopment analysis: a handbook of models and methods. Springer US
Cooper WW, Park KS, Yu G (2001) An illustrative application of idea (imprecise data envelopment analysis) to a Korean mobile telecommunication company. Oper Res 49:807–820
Cooper WW, Deng H, Huang Z, Li SX (2002) Chance constrained programming approaches to technical efficiencies and inefficiencies in stochastic data envelopment analysis. J Oper Res Soc 53:1347–1356
Cooper W, Seiford LM, Tone K, Zhu J (2007) Some models and measures for evaluating performances with DEA: past accomplishments and future prospects. J Prod Anal 28:151–163
Csardi G, Nepusz T (2006) The igraph software package for complex network research. InterJournal, Complex Systems 1695
Dai X, Kuosmanen T (2014) Best-practice benchmarking using clustering methods: application to energy regulation. OMEGA Int J Manag Sci 42:179–188
Doyle J, Green R (1994) Efficiency and cross-efficiency in DEA: derivations, meanings and uses. J Oper Res Soc 567–578
Dyson R, Shale E (2010) Data envelopment analysis, operational research and uncertainty. J Oper Res Soc 61:25–34
Egghe L (2006) Theory and practise of the g-index. Scientometrics 69:131–152
Emrouznejad A, Parker BR, Tavares G (2008) Evaluation of research in efficiency and productivity: a survey and analysis of the first 30 years of scholarly literature in DEA. Socioecon Plann Sci 42:151–157
Fang H, Lee H, Hwang S, Chung C (2013) A slacks-based measure of super-efficiency in data envelopment analysis: an alternative approach. OMEGA Int J Manag Sci 41:731–734
Färe R, Grosskopf S (2000) Network DEA. Socioecon Plann Sci 34:35–49
Fare R, Grosskopf S (2004) Modeling undesirable factors in efficiency evaluation: comment. Eur J Oper Res 157:242–245
Färe R, Grosskopf S, Brännlund R (1996) Intertemporal production frontiers: with dynamic DEA. Kluwer, Boston
Fethi MD, Pasiouras F (2010) Assessing bank efficiency and performance with operational research and artificial intelligence techniques: a survey. Eur J Oper Res 204:189–198
Fried HO, Lovell CK, Schmidt SS, Yaisawarng S (2002) Accounting for environmental effects and statistical noise in data envelopment analysis. J Prod Anal 17:157–174
Gattoufi S, Oral M, Kumar A, Reisman A (2004a) Epistemology of data envelopment analysis and comparison with other fields of OR/MS for relevance to applications. Socioecon Plann Sci 38:123–140
Gattoufi S, Oral M, Reisman A (2004b) Data envelopment analysis literature: a bibliography update (1951–2001). J Socioecon Plann Sci 38:159–229
Girvan M, Newman ME (2002) Community structure in social and biological networks. Proc Natl Acad Sci U S A 99:7821–7826
Guo P, Tanaka H (2001) Fuzzy DEA: a perceptual evaluation method. Fuzzy Set Syst 119:149–160
Hailu A, Veeman T (2001) Non-parametric productivity analysis with undesirable outputs: an application to the Canadian pulp and paper industry. Am J Agric Econ 83:605–616
Hatami-Marbini A, Emrouznejad A, Tavana M (2011) A taxonomy and review of the fuzzy data envelopment analysis literature: two decades in the making. Eur J Oper Res 214:457–472
Hirsch JE (2005) An index to quantify an individual’s scientific research output. Proc Natl Acad Sci U S A 102:16569–16572
Hosseinzadeh Lotfi F, Jahanshahloo GR, Khodabakhshi M, Rostamy-Malkhlifeh M, Moghaddas Z, Vaez-Ghasemi M (2013) A review of ranking models in data envelopment analysis. J Appl Math 2013
Hummon NP, Dereian P (1989) Connectivity in a citation network: the development of DNA theory. Soc Networks 11:39–63
Hung S-C, Liu JS, Lu LY, Tseng Y-C (2014) Technological change in lithium iron phosphate battery: the key-route main path analysis. Scientometrics 1–24
Jenkins L, Anderson M (2003) A multivariate statistical approach to reducing the number of variables in data envelopment analysis. Eur J Oper Res 147:51–61
Johnson A, Kuosmanen T (2012) One-stage and two-stage DEA estimation of the effects of contextual variables. Eur J Oper Res 220:559–570
Kao C (2009a) Efficiency decomposition in network data envelopment analysis: a relational model. Eur J Oper Res 192:949–962
Kao C (2009b) Efficiency measurement for parallel production systems. Eur J Oper Res 196:1107–1112
Kao C (2014a) Efficiency decomposition for general multi-stage systems in data envelopment analysis. Eur J Oper Res 232:117–124
Kao C (2014b) Network data envelopment analysis: a review. Eur J Oper Res 239:1–16
Kao C, Hwang S (2008) Efficiency decomposition in two-stage data envelopment analysis: an application to non-life insurance companies in Taiwan. Eur J Oper Res 185:418–429
Kao C, Hwang S-N (2014) Multi-period efficiency and Malmquist productivity index in two-stage production systems. Eur J Oper Res 232:512–521
Kao C, Liu S-T (2000) Fuzzy efficiency measures in data envelopment analysis. Fuzzy Set Syst 113:427–437
Kao C, Liu S-T (2009) Stochastic data envelopment analysis in measuring the efficiency of Taiwan commercial banks. Eur J Oper Res 196:312–322
Karkazis J, Thanassoulis E (1998) Assessing the effectiveness of regional development policies in northern Greece using data envelopment analysis. Socioecon Plann Sci 32:123–137
Kuosmanen T, Post T (2001) Measuring economic efficiency with incomplete price information: with an application to European commercial banks. Eur J Oper Res 134:43–58
Kuosmanen T, Cherchye L, Sipiläinen T (2006) The law of one price in data envelopment analysis: restricting weight flexibility across firms. Eur J Oper Res 170:735–757
Lertworasirikul S, Fang S-C, Joines JA, Nuttle HL (2003) Fuzzy data envelopment analysis (DEA): a possibility approach. Fuzzy Set Syst 139:379–394
Lewis HF, Sexton TR (2004) Network DEA: efficiency analysis of organizations with complex internal structure. Comput Oper Res 31:1365–1410
Li Y, Chen Y, Liang L, Xie J (2012) DEA models for extended two-stage network structures. OMEGA Int J Manag Sci 40:611–618
Liang L, Wu J, Cook WD, Zhu J (2008) The DEA game cross-efficiency model and its Nash equilibrium. Oper Res 56:1278–1288
Lins MPE, Gomes EG, Soares de Mello JCC, Soares de Mello AJR (2003) Olympic ranking based on a zero sum gains DEA model. Eur J Oper Res 148:312–322
Liu JS, Lu LY (2012) An integrated approach for main path analysis: development of the Hirsch index as an example. J Am Soc Inf Sci Technol 63:528–542
Liu JS, Lu LYY, Lu WM, Lin BJY (2013a) Data envelopment analysis 1978–2010: a citation-based literature survey. OMEGA Int J Manag Sci 41:3–15
Liu JS, Lu LYY, Lu WM, Lin BJY (2013b) A survey of DEA applications. OMEGA Int J Manag Sci 41:893–902
Liu JS, Chen HH, Ho MHC, Li YC (2014) Citations with different levels of relevancy: tracing the main paths of legal opinions. J Assoc Inf Sci Technol 65:2479–2488
Lozano S, Villa G (2004) Centralized resource allocation using data envelopment analysis. J Prod Anal 22:143–161
Lozano S, Villa G, Adenso-Dıaz B (2004) Centralised target setting for regional recycling operations using DEA. OMEGA Int J Manag Sci 32:101–110
Lu LY, Liu JS (2013) An innovative approach to identify the knowledge diffusion path: the case of resource-based theory. Scientometrics 94:225–246
Lu LY, Liu JS (2014) The knowledge diffusion paths of corporate social responsibility–from 1970 to 2011. Corp Soc Responsib Environ Manag 21:113–128
Ma J, Evans DG, Fuller RJ, Stewart DF (2002) Technical efficiency and productivity change of china’s iron and steel industry. Int J Prod Econ 76:293–312
McDonald J (2009) Using least squares and tobit in second stage DEA efficiency analyses. Eur J Oper Res 197:792–798
Meng W, Zhang D, Qi L, Liu W (2008) Two-level DEA approaches in research evaluation. OMEGA Int J Manag Sci 36:950–957
Mukherjee A, Nath P, Pal M (2003) Resource, service quality and performance triad: a framework for measuring efficiency of banking services. J Oper Res Soc 54:723–735
Newman ME (2006) Modularity and community structure in networks. Proc Natl Acad Sci U S A 103:8577–8582
Paradi JC, Schaffnit C (2004) Commercial branch performance evaluation and results communication in a Canadian bank––a DEA application. Eur J Oper Res 156:719–735
Paradi J, Zhu H (2013) A survey on bank branch efficiency and performance research with data envelopment analysis. OMEGA Int J Manag Sci 41:61–79
Paradi J, Rouatt S, Zhu H (2011) Two-stage evaluation of bank branch efficiency using data envelopment analysis. OMEGA Int J Manag Sci 39:99–109
Pastor JT, Ruiz JL, Sirvent I (2002) A statistical test for nested radial DEA models. Oper Res 50:728–735
Ramalho E, Ramalho J, Henriques P (2010) Fractional regression models for second stage DEA efficiency analyses. J Prod Anal 34:239–255
Ramanathan R (2005) Estimating energy consumption of transport modes in India using DEA and application to energy and environmental policy. J Oper Res Soc 56:732–737
Ramon N, Ruiz J, Sirvent I (2010) On the choice of weights profiles in cross-efficiency evaluations. Eur J Oper Res 207:1564–1572
Ramon N, Ruiz J, Sirvent I (2011) Reducing differences between profiles of weights: a “peer-restricted” cross-efficiency evaluation. OMEGA Int J Manag Sci 39:634–641
Ruggiero J (2004) Data envelopment analysis with stochastic data. J Oper Res Soc 55:1008–1012
Ruiz J, Sirvent I (2012) On the DEA total weight flexibility and the aggregation in cross-efficiency evaluations. Eur J Oper Res 223:732–738
Sahoo BK, Tone K (2009) Decomposing capacity utilization in data envelopment analysis: an application to banks in India. Eur J Oper Res 195:575–594
Seiford LM (1996) Data envelopment analysis: the evolution of the state of the art (1978–1995). J Prod Anal 7:99–137
Seiford LM, Thrall RM (1990) Recent developments in DEA: the mathematical programming approach to frontier analysis. J Econ 46:7–38
Seiford LM, Zhu J (1998a) Sensitivity analysis of DEA models for simultaneous changes in all the data. J Oper Res Soc 49:1060–1071
Seiford LM, Zhu J (1998b) Stability regions for maintaining efficiency in data envelopment analysis. Eur J Oper Res 108:127–139
Seiford LM, Zhu J (1999a) Infeasibility of super-efficiency data envelopment analysis models. INFOR 37:174–187
Seiford LM, Zhu J (1999b) Profitability and marketability of the top 55 us commercial banks. Manag Sci 45:1270–1288
Seiford L, Zhu J (2002) Modeling undesirable factors in efficiency evaluation. Eur J Oper Res 142:16–20
Sexton TR, Silkman RH, Hogan AJ (1986) Data envelopment analysis: critique and extensions. In: Silkman Richard H (ed) Measuring efficiency: an assessment of data envelopment analysis. Jossey-Bass, San Francisco, pp 73–105
Sherman HD, Zhu J (2013) Analyzing performance in service organizations. Sloan Manage Rev 54:36–42
Simar L, Wilson PW (1998) Sensitivity analysis of efficiency scores: how to bootstrap in nonparametric frontier models. Manag Sci 44:49–61
Simar L, Wilson P (2000) A general methodology for bootstrapping in non-parametric frontier models. J Appl Stat 27:779–802
Simar L, Wilson P (2002) Non-parametric tests of returns to scale. Eur J Oper Res 139:115–132
Simar L, Wilson P (2007) Estimation and inference in two-stage, semi-parametric models of production processes. J Econ 136:31–64
Simar L, Wilson P (2011) Two-stage DEA: caveat emptor. J Prod Anal 36:205–218
Song M, An Q, Zhang W, Wang Z, Wu J (2012) Environmental efficiency evaluation based on data envelopment analysis: a review. Renew Sustain Energy Rev 16:4465–4469
Sueyoshi T, Goto M (2010a) Measurement of a linkage among environmental, operational, and financial performance in Japanese manufacturing firms: a use of data envelopment analysis with strong complementary slackness condition. Eur J Oper Res 207:1742–1753
Sueyoshi T, Goto M (2010b) Should the us clean air act include CO2 emission control?: examination by data envelopment analysis. Energy Policy 38:5902–5911
Sueyoshi T, Goto M (2011a) Measurement of returns to scale and damages to scale for DEA-based operational and environmental assessment: how to manage desirable (good) and undesirable (bad) outputs? Eur J Oper Res 211:76–89
Sueyoshi T, Goto M (2011b) Methodological comparison between two unified (operational and environmental) efficiency measurements for environmental assessment. Eur J Oper Res 210:684–693
Sueyoshi T, Goto M (2012) Data envelopment analysis for environmental assessment: comparison between public and private ownership in petroleum industry. Eur J Oper Res 216:668–678
Sueyoshi T, Goto M (2013) Returns to scale vs. damages to scale in data envelopment analysis: an impact of U.S. clean air act on coal-fired power plants. OMEGA Int J Manag Sci 41:164–175
Sueyoshi T, Goto M, Ueno T (2010) Performance analysis of us coal-fired power plants by measuring three DEA efficiencies. Energy Policy 38:1675–1688
Tone K (2001) A slacks-based measure of efficiency in data envelopment analysis. Eur J Oper Res 130:498–509
Tone K (2002) A slacks-based measure of super-efficiency in data envelopment analysis. Eur J Oper Res 143:32–41
Tone K, Tsutsui M (2009) Network DEA: a slacks-based measure approach. Eur J Oper Res 197:243–252
Tone K, Tsutsui M (2010) Dynamic DEA: a slacks-based measure approach. OMEGA Int J Manag Sci 38:145–156
Tone K, Tsutsui M (2014) Dynamic DEA with network structure: a slacks-based measure approach. OMEGA Int J Manag Sci 42:124–131
Utterback JM, Abernathy WJ (1975) A dynamic model of process and product innovation. OMEGA Int J Manag Sci 3:639–656
Wagner JM, Shimshak DG (2007) Stepwise selection of variables in data envelopment analysis: procedures and managerial perspectives. Eur J Oper Res 180:57–67
Wang Y, Chin K (2010) A neutral DEA model for cross-efficiency evaluation and its extension. Expert Syst Appl 37:3666–3675
Wang Y, Chin K (2011) The use of OWA operator weights for cross-efficiency aggregation. OMEGA Int J Manag Sci 39:493–503
Wang Y-M, Greatbanks R, Yang J-B (2005) Interval efficiency assessment using data envelopment analysis. Fuzzy Set Syst 153:347–370
Wang Y, Chin K, Wang S (2012) DEA models for minimizing weight disparity in cross-efficiency evaluation. J Oper Res Soc 63:1079–1088
Wilson P (2003) Testing independence in models of productive efficiency. J Prod Anal 20:361–390
Wu J, Liang L, Chen Y (2009a) DEA game cross-efficiency approach to Olympic rankings. OMEGA Int J Manag Sci 37:909–918
Wu J, Liang L, Yang F (2009b) Achievement and benchmarking of countries at the summer Olympics using cross efficiency evaluation method. Eur J Oper Res 197:722–730
Zhong W, Yuan W, Li S, Huang Z (2011) The performance evaluation of regional R&D investments in china: an application of DEA based on the first official china economic census data. OMEGA Int J Manag Sci 39:447–455
Zhou P, Ang B, Poh K (2006) Slacks-based efficiency measures for modeling environmental performance. Ecol Econ 60:111–118
Zhou P, Poh K, Ang B (2007) A non-radial DEA approach to measuring environmental performance. Eur J Oper Res 178:1–9
Zhou P, Ang B, Poh K (2008) A survey of data envelopment analysis in energy and environmental studies. Eur J Oper Res 189:1–18
Zhou P, Ang B, Wang H (2012) Energy and CO2 emission performance in electricity generation: a non-radial directional distance function approach. Eur J Oper Res 221:625–635
Zhu J (2000) Multi-factor performance measure model with an application to fortune 500 companies. Eur J Oper Res 123:105–124
Zhu J (2001) Super-efficiency and DEA sensitivity analysis. Eur J Oper Res 129:443–455
Zhu J (2003) Imprecise data envelopment analysis (idea): a review and improvement with an application. Eur J Oper Res 144:513–529
Acknowledgements
The authors would like to express their gratitude Professor Joe Zhu for providing guidance and critiques in several aspect of this research project. Our gratitude extends to several reviewers for their constructive comments, which have greatly improved the accuracy and readability of this article. This work is partially supported by Taiwan’s Ministry of Science and Technology grant NSC 102-2410-H-011-008-MY3, NSC 102-2410-H-155-021-MY3, and NSC 102-2632-H-155-001-MY3.
Part of this chapter is based upon “John S. Liu, Louis Y.Y. Lu, and Wen-Min Lu, “Research fronts in data envelopment analysis”, OMEGA, Vol. 51, (2016), 33–45.”, with permission from Elsevier.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer Science+Business Media New York
About this chapter
Cite this chapter
Liu, J.S., Lu, L.Y.Y., Lu, WM. (2016). Research Fronts and Prevailing Applications in Data Envelopment Analysis. In: Zhu, J. (eds) Data Envelopment Analysis. International Series in Operations Research & Management Science, vol 238. Springer, Boston, MA. https://doi.org/10.1007/978-1-4899-7684-0_18
Download citation
DOI: https://doi.org/10.1007/978-1-4899-7684-0_18
Published:
Publisher Name: Springer, Boston, MA
Print ISBN: 978-1-4899-7682-6
Online ISBN: 978-1-4899-7684-0
eBook Packages: Business and ManagementBusiness and Management (R0)