
Abstract
This paper proposes a new model to interpolate time series and forecast it effectively for the future. The important contribution of this study is the combination of optimal techniques for fuzzy clustering problem using genetic algorithm and forecasting model for fuzzy time series. Firstly, the proposed model finds the suitable number of clusters for a series and optimizes the clustering problem by the genetic algorithm using the improved Davies and Bouldin index as the objective function. Secondly, the study gives the method to establish the fuzzy relationship of each element to the established clusters. Finally, the developed model establishes the rule to forecast for the future. The steps of the proposed model are presented clearly and illustrated by the numerical example. Furthermore, it has been realized positively by the established MATLAB procedure. Performing for a lot of series (3007 series) with the differences about characteristics and areas, the new model has shown the significant performance in comparison with the existing models via some parameters to evaluate the built model. In addition, we also present an application of the proposed model in forecasting the COVID-19 victims in Vietnam that it can perform similarly for other countries. The numerical examples and application show potential in the forecasting area of this research.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
We all agree that forecasting is the scientific basis for the good plans required for many areas. Because of its important role in many fields, forecasting always gets the attention of managers and scientists. Despite several discussions in the literature, the problems of forecasting have not yet been completely solved [1, 21]. In statistics, time series and regression are popular models applied to forecast, but they have many disadvantages in practice. When building a regression model, we must constrain the data conditions that do not satisfy for real data. Therefore, it often receives the limited results in forecasting [2, 5, 22, 35].
In socioeconomic development, each field and country has stored a lot of data over time. Therefore, time series has become the most common data type. For these data, forecasting is the most attractive direction. There are two kinds in building the time series. They are non-fuzzy time series (NFS) and fuzzy time series (FS) models. Although NFS models often have more advantages than regression models in the real application, they have some limitations. For example, they only give the remarkable results if the series have normal changes or stationary [46]. Based on historical data, the NFS sets up a mathematical function to forecast, so it had not much flexibility. Non-reliance on the linguistic level to build the relationship of the elements in series is considered the main limitation of the NFS models. Because the FS models are built based on the fuzzy relations of the elements in series, they have overcome the weaknesses of NFS models.
The FS model is developed in two main directions. First, it builds the models from the original series and forecasts for the future from these models themselves. Abbasov and Manedova [1] and Tai et al. [46] have had the important contributions in this direction. Second, the original series are interpolated in order to obtain the new ones that are closely related to each other in the whole series. After that, this new series is used as the good input data to forecast. Compared to the first direction, the second one is getting more attention in our knowledge. Song et al. [42] were the pioneer in this direction with data on the enrollment of the University of Alabama (EnrollmentUA). Qiang et al. [43] used the triangular fuzzy relation for performing. Ming et al. [14] and Chen et al. [16] improved the result of [43] when taking notice of fuzzy level. Huarng [27] and Own [37] presented a heuristic model for FS using heuristic knowledge to improve the forecast for EnrollmentUA. Based on neural network, Alpaslan [7] gave the interesting results in some cases. Wu and Chau [50] constructed several soft computing approaches for rainfall prediction. Two aspects were considered improving the accuracy of rainfall prediction: carrying out a data preprocessing procedure and adopting a modular method. The proposed techniques included the moving average (MA) and singular spectrum analysis (SSA). The modular models were composed of local support vectors regression (SVR) model and local artificial neural networks (ANNs) model. Results showed that the MA was superior to the SSA when they were coupled with the ANN. Riccardo and Kwok [48] proposed the artificial neural networks-based interval forecasting of streamflow discharges using the lower and upper bounds and multi-objective fully informed particle swarm. Ghalandari et al. [24] introduced the aeromechanical optimization technique of first row compressor test stand blades using a hybrid machine learning model of genetic algorithm and artificial neural network. The authors used three-dimensional geometric parameters to conduct blade tuning. As a result, the reduced frequency increases by at least 5% in both stall and classical regions, and force response constraints are satisfied.
From the fuzzy model in accordance with different linguistic levels, many scientists such as [25, 34, 49] have proposed the new models. Moreover, Baghban et al. [10] used the adaptive network-based fuzzy inference system (ANFIS) which provided highly accurate predictions. The study was expanded based on the independent variables of temperature, nanoparticle diameter, nanofluid density, volumetric fraction, and viscosity of the base fluid. Prashant et al. [38] presented a fuzzy dominance-based analytical sorting method as advancement to the existing multi-objective evolutionary algorithm. The objective functions are defined as fuzzy objectives, and competing solutions are provided an overall activation score based on their respective fuzzy objective values. Recently, Tai [47] proposed a FS model from the results of the fuzzy clustering problem. Many applications have used the optimal techniques such as bat algorithm [51], genetic algorithm [38], and whale algorithm [36] in recent years. In this study, we consider the genetic algorithm to apply to FS model. Applying the genetic algorithm (GA) in clustering, Jain [30] proposed the FS for EnrollmentUA. Ali et al. [6] proposed a method based on a genetic algorithm (GA) for generation expansion planning (GEP) in the presence of wind power plants. A six-state model was used to obtain the wind farm output power model. The method of calculating the six-state wind farm output model with the turbine’s forced outage rate of wind farm units for use in long-term GEP calculations is described. Also, using GA, Aldouri et al. [3] introduced a model with two levels. The first level implements GA based on the autoregressive integrated moving average (ARIMA) model. The second level is utilized based on the forecasting error rate.
In time series, each value on time t is called the element, and the universal set is a set which contains all the elements as input data to forecast. For the second direction, a time series model is built to have three main phases. (1) Build the universal set and divide the suitable groups for it, (2) determine the elements for each group, and (3) establish the relationship between each element of the series to the groups found from (2) to build the rule for forecasting. For (1), many authors used the universal set to be the original series itself [13, 16, 23]. Some others used the maximum value and minimum value of original series to make the universal set [13, 16]. In addition, Huarng et al. [27, 28] proposed two new techniques for finding intervals based on the mean of the distributions. Abbasov et al. [1] and Tai [46] have built the universal set based on the change of data between consecutive periods of time or their percentage change. Dividing the universal set with appropriate number of groups is an important problem because it will influence the result of the model. Almost all of the existing models give the specific constant in performing. (It is often five or seven.) Others determine it based on the experiments from many data sets. However, the number of groups is only considered suitable if they depend on the similar level of elements in series. When the elements in a series have a lot of difference, the number of found groups will be large and vice versa. In this study, we use whole series as the universal set and determine the number of groups for it by the automatic clustering algorithm. Through this algorithm, in the series where the similarity of the elements is not the same, the number of clusters found will be different.
For (2), many authors divided the universal set to become the equal intervals. The elements in each cluster were also determined by the k-mean algorithm [9]. Tai [47] built groups for the elements based on the clustering algorithm. In this study, we proposed the cluster analysis method using genetic algorithm to find the specific elements in each group. For (iii), several important studies have been performed. For instance, Song et al. [42] used the matrix operations and Chen et al. [13] took the fuzzy logic relations. Moreover, many authors [4, 19, 20, 28] used artificial neural networks to determine fuzzy relations.
In addition, the fuzzy relationship based on the triangle and trapezoid fuzzy numbers was also considered in [25]. The relationship based on clustering algorithm is also established by Tai and Nghiep [47]. Many researchers had also used either the centroid method such as [13, 27, 28] or the adaptive expectation method [5, 16, 47] to perform. This article contributes to three stages (1), (2), and (3) for FS model:
For (1), we proposed a new algorithm for finding the appropriate number of groups divided for each series. This value depends on the similar level of objects in series. This method has outstanding advantages in comparison with the existing ones that were presented as linguistic values with levels being constant. (It is usually five or seven in applications.)
For (2), we propose the improved fuzzy genetic algorithm. It can find the specific elements for each group and the probability to belong to the established groups of the element in series.
For (3), based on the principle for normalizing series and the result from (2), a new interpolating method is also proposed.
Incorporating all these improvements, we propose the best model for series time. This model is better than the existing ones through many well- known data sets. We also establish the MATLAB procedure for the proposed model. This procedure can perform effectively for real data. In addition, we also apply the proposed model to forecast the number of COVID-19 victims in Vietnam.
The next section of the paper is structured as follows. Section 2 presents some definitions related to fuzzy time series and proposes a new model. This section also proves the convergence of the proposed model. Section 3 gives the specific steps of the new model and compares it with existing ones over many data sets. An application in Vietnam of the proposed model is presented in Sect. 4. The final section is conclusion.
2 The proposed algorithm
2.1 The parameters to evaluate the established model
Given a series of historical data \(\left\{ {{X_i}} \right\}\) and predictive value \(\left\{ {\widehat{{X_i}}} \right\} ,\,\,i = 1,2, \ldots ,N,\), respectively, we have the popular parameters to evaluate the built FTS models as follows:
Mean squared error:
Mean absolute error:
Mean absolute percentage error:
Symmetric mean absolute percentage error:
Mean absolute scaled error:
For the built models, the smaller these parameters are, the better the models are.
2.2 The proposed algorithm
A cluster with m elements is given. If these elements converge to the same one v by any algorithm, then v is called as the prototype element of the cluster. Let \({{T}} = \left\{ {{T_1},{T_2}, \ldots ,{T_N}} \right\}\) be the time series, and the \(V^{(t)}\) be set of prototype elements for clusters built at time t. We propose the forecasting model based on the genetic algorithm and clustering technique as follows:
Step 1 Initialize \(t=0\) and \({{{V}}^{({{0}})}} = \left\{ {v_1^{(0)},v_2^{(0)}, \ldots ,v_N^{(0)}} \right\} = \left\{ {{X_1}, {X_2}, \ldots ,{X_N}} \right\} .\) where \({X_c} = 10{T_c}/\max \left\{ {{T}} \right\} , 1\le c \le N.\)
Step 2 Update the prototype elements using Formula (1):
where
where \(\alpha _{ij}\left( t\right) =\alpha _{ij}\left( t-1\right) /\left[ 1+\alpha _{ij}\left( t-1\right) f\left( v_i^{(t-1)},v_j^{(t-1)} \right) \right]\) is the balance factor, and \(\alpha _{ij}\left( 0\right) =1.\) \(\mu =\sum \nolimits _{i<j}{d_E\left( v_i^{(t)},v_j^{(t)} \right) }/{{N}\atopwithdelims (){2}}\) is the average of Euclidean distance \(d_E\left( v_i^{(t)},v_j^{(t)} \right)\), \(\lambda =\sigma /r\), \(\sigma =\sqrt{\sum \nolimits _{i<j}{\left[ d_E\left( v_i^{(t)},v_j^{(t)} \right) -\mu \right] ^2}/{{N}\atopwithdelims (){2}}}\) is the standard deviation, and r is a constant.
Step 3 Repeat Step 2 until \(\left\| {{V^{(t + 1)}} - {V^{(t)}}} \right\| = {\max _i}\left\{ {\left| {v_i^{(t + 1)} - v_i^{(t)}} \right| } \right\} < \varepsilon .\)
\(v^{(t+1)}\) determined by (1) is expansion or narrowing of \(v^{(t)}\), such that the elements in the same group will be changed to become a prototype element. It means that after an iteration of Step 2, each element in X will converge to the prototype element of group containing it. Step 3 ends when the difference of all elements between two successive iterations is less than \(\varepsilon\). This value can affect the number of divided groups as well as the computational cost. The iterations of algorithm will increase if the value of \(\varepsilon\) decreases. In this study, we have taken \(\varepsilon =10^{-4}\) for all numerical examples.
Step 4 Encode the clustering solutions. In general genetic algorithm, each variable is represented by a gene, and the chromosome is the set of those genes, which represents a solution to the problem. In the proposed algorithm, the chromosome M is formed by kp genes representing for k clusters.
Step 5 Initialize N chromosomes and evaluate their Improved Davies and Bouldin index [18] by (3).
where,
-
\({{\bar{X}}_i}\) and \({{\bar{X}}_j}\) are the centroid of \(C_i\) and \(C_j\).
-
\(d_E (.)\) is the Euclidean distance.
-
\(\left| {{C_i}} \right|\) is the number of elements in cluster \(C_i\).
Step 6 Utilize the selection, crossover, and mutation operators:
-
Crossover Perform the crossover operator to chromosomes by the probability 0.85. Let \(L_1\) and \(L_2\) be the two parent chromosomes; then, the child chromosome is created as follows:
$$\begin{aligned}Child=L_1 + 0.85.(L_2 - L_1).\end{aligned}$$In a similar way for all chromosomes in population, we have a new population.
-
Mutation Let h be the previous value of the mutated gene, the new value \(h'\) of h is computed as follows:
$$ h^{\prime} = \begin{array}{*{20}l} {\left( {1 \pm 2\delta } \right)h} & {{\text{if}}\quad{\mkern 1mu} h \ne 0,} \\ { \pm 2\delta } & {~{\text{if}}\quad{\mkern 1mu} h = 0,} \\ \end{array}$$where \(\delta\) is a random number belonging to the interval \(\left[ 0,1\right]\), and the \(+\) or − sign occurs with equal probability.
-
Selection The Roulette wheel strategy [33] is used to implement the selection operation. Probability of choosing the ith element is determined by (4).
$$\begin{aligned} {p_i} = \frac{{{IDB_i}}}{{\sum \nolimits _{j = 1}^N {{IDB_j}} }}, \end{aligned}$$(4)where \(IDB_i\) is the fitness function of i and N is the size of the current population.
Step 7 Calculate the IDB index of the chromosomes obtained in Step 6.
Step 8 Replace the current clustering solution by the new ones having the smaller IDB index.
Repeat Step 5 to Step 7 until \(iter>maxiter\), where iter and maxiter are the number of current iterations and the required one of the proposed algorithm, respectively.
The parameters of the genetic algorithm used in the proposed model are summed by Table 1.
Step 9 Let \({\mu _{ic}} \in U^{(0)}\) be the result of fuzzy clustering at the first time \(t=0\), and \(M=(M_i), 1\le i \le k\) be the optimal central cluster. Establish the first partition matrix with the elements computed by (5).
Find the prototype element of clusters by (6).
where \({\mu _{ic}} \in {U^{(t)}},1 \le i \le k\) is fuzzy probability of k clusters, and \(w_i\) is the element official centroid of k clusters.
The value of m in (6) is the fuzziness degree. When \(m = 1\), the fuzzy clustering becomes the non-fuzzy clustering. When \(m \rightarrow \infty\), the partition becomes completely fuzzy with \(\mu _{ic}=1/k\). Although [11, 12, 39] had proposed the rules to find the supreme of m, the best value of m has not still been determined. Performing a lot of series, we take \(m =2\) for applications.
Step 10 Update the new partition matrix \({U^{\left( {t + 1} \right) }},\) where each element of \({U^{\left( {t + 1} \right) }}\) is determined by (7):
with \({d_E}\left( {{w_i},{X_c}} \right)\) being the Euclidean distance of cluster central \(w_i\) and original data \(X_c\).
Step 11 Repeat Step 9 and Step 10 until
Step 12 Calculate the center \((M_i)\) of each cluster and forecast \(Y_c\) according to the following rule:
where \({M^T} = {\left( {{M_i} \times \max \left\{ {{T}} \right\} /10} \right) ^T}\).
The proposed model includes three phases with 12 steps. Phase 1 has three steps (Step 1 to Step 3) that are used to determine the suitable number of groups to divide the series. In this phase, at the first time, each element is considered to be a cluster. After many iterations, the elements in the same group will converge to the prototype element. It can run many iterations depending on the similar level of elements in series. The result of this phase is the number of groups k that the series is divided. In many existing models, k is often chosen as constant \((k = 5\) or \(k = 7).\) In the proposed model, k is determined by the automatic algorithm.
Phase 2 has five steps (Step 4 to Step 8) that it finds the elements for k groups by the improved genetic algorithm. It builds the operators such as selection, crossover, and mutation with the objective function as IDB. First, the algorithm encodes the clustering solutions. Each variable is represented by a gene, and the chromosome is the set of those genes, which represents a solution to the problem. Initialize N chromosomes and evaluate their IDB; after that, perform the selection, crossover, mutation operators, and compute again IDB. These processes are repeated until the IDB index is almost unchanged. In our experiment, this phase often converges with the number of iterations less than 50.
Phase 3 includes three steps (Step 9 to Step 12). It builds the fuzzy relationship of each element in series to the established groups from Phase 2 and proposes the rule to interpolate data. In this phase, Step 9 initializes the initial fuzzy relationship by (5). After that, the elements in this matrix will be updated until all the values of two consecutive iterations are almost unchanged. From the result of this matrix, we give the rule to forecast.
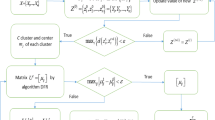
To sum up, the proposed model has to perform three phases, and each phase includes many steps and runs many iterations. Therefore, the computation of the proposed algorithm is complex compared to others. The flowchart of the proposed model is shown in Fig. 1.

Flowchart of the proposed model
We have established the complete MATLAB procedure for the proposed model. It can perform quickly and effectively for real data.
2.3 The convergence of the proposed model
The convergence of the proposed model is shown by three phases. Phase 2 will stop when the number of iterations is maxiter. (We chose maxiter = 1000.) The convergence of Phase 3 is similar as the fuzzy cluster analysis algorithm for the discrete elements (FCM) that it has been proven in many documents [31]. Therefore, we only consider the convergence of the Phase 1 which is proved by Theorem 1.
Theorem 1
If the function f(u, v) in (2) satisfies:
- (i):
-
\(0 \le f\left( {u,v} \right) \le 1\) and \(f\left( {u,v} \right) = 1\) when \(u=v.\)
- (ii):
-
f(u, v) depends only on \(\left\| {u - v} \right\|\); the distance from u to v.
- (iii):
-
f(u, v) is decreasing for \(\left\| {u - v} \right\| .\)
Then, there exist t and \(\varepsilon\) such that \(V^{(t)}\) whose elements are determined by (1) satisfies:
Proof
Let \(C_1^{(t)}\) be the convex hull of \(\left\{ {v_1^{(t)},...,v_N^{(t)}} \right\} .\) Then, \(v_i^{(t + 1)} \in C_1^{(t)}\) is a weighted average of \(v_j^{(t)},j = 1,...,N.\) Therefore, \(C_1^{(t)} \supseteq C\left( {\left\{ {v_1^{(t + 1)},...,v_N^{(t + 1)}} \right\} } \right) = C_1^{(t + 1)}.\) Since
there exist i such that \(\mathop {\lim }\nolimits _{t \rightarrow \infty } u_{1,i}^{(t)} = {u_{1,i}}\) where \(u_{1,i}^{(t)}\) is a vertex of \(C_1^{(t)}\). For each t and i, \(u_{1,i}^{(t)} = v_k^{(t)}\) for at least one k; there exists j such that \(v_j^{(t)} = u_{1,i}^{(t)}\) for infinite many t’s. Therefore, there exists \(t \rightarrow \infty\) such that \(v_j^{({t_n})} = u_{1,i}^{({t_n})},\) which leads to \(\mathop {\lim }\nolimits _{n \rightarrow \infty } v_j^{({t_n})} = {u_{1,i}}.\) We consider two possible cases as follows:
-
Case 1:
If \(v_j^{({t_n})} = {u_{1,i}}\) except for any finite t, then \(\mathop {\lim }\nolimits _{t \rightarrow \infty } v_j^{(t)} = {u_{1,i}}.\)
-
Case 2:
If there exists \(j' \ne j\) and \({s_n} \rightarrow \infty\) such that \(\forall n,\) \(v_{j'}^{({s_n})} = u_j^{({s_n})}.\) Assume that \(u_{1,i}^{(t)} = v_j^{(t)}\) or \(v_{j'}^{(t)}\) for all \(t>T.\) From equation (2), if \(v_j^{(s)} = v_{j'}^{(s)}\) for some s, \(v_j^{(t)} = v_{j'}^{(t)}\) for all \(t>s\) . Therefore, for any \(s > 0,\) there exists \(t > s\) such that \(u_{1,i}^{(t)} = v_j^{(t)}\) and \(u_{1,i}^{(t + 1)} = v_{j'}^{(t + 1)}.\) We claim that this case, however, can never happen with t being large enough.
Without loss of generality, assume that \({u_{1,i}} = 0,v_j^{(t)} \le 0,\) and \(v_k^{(t)} > 0\) for \(k \ne j\) or \(k \ne j'.\) If \(v_{j'}^{(t + 1)}\) later becomes the new vertex, then \(v_{j'}^{(t + 1)} < v_j^{(t + 1)}.\)
Moreover, since \(v_{j'}^{(t + 1)}\) is the new vertex we have
Since \(v_j^{(t)}\) is the current vertex, \(\left\| {v_j^{(t)} - v_k^{(t)}} \right\| > \left\| {v_{j'}^{(t)} - v_k^{(t)}} \right\|\) for all k. Then,
and
and we have
which is a contradiction to (2). Therefore, \(u_{1,i}^{(t)} = v_j^{(t)}\) for some j and for all t large enough. Then, \(\mathop {\lim }\nolimits _{t \rightarrow \infty } v_j^{(t)} = {u_{1,i}}.\)
We can apply a similar result for \(C_2\) as \(C_1^{(t)}\); at least one subject converges to each vertex of \(C_2.\) Then, we can run similar steps again for \(C_3,C_4,...\) until all subjects converge. This completes the proof of Theorem 1. \(\square\)
2.4 The computational complexity of the proposed algorithm
Let N be the number of elements in series, k be the number of clusters, p be the number of dimensions, \(t_\mathrm{max}\) be the number of iterations of algorithm, and P be the size of population in the genetic algorithm. Based on the research of Hongchun et al. [26] and Xu et al. [51], the computational complexity of the proposed model is explained as follows:
-
*Phase 1 (Step 1 to Step 3). Because the number of simulation replications is \(t_{max}\), the computational complexity of this phase is \(O(t_{max}N^2k)\), where
standardizing time series needs O(N); updating the value of prototypes needs \(O(N^2k)\), and comparing two prototypes in each iteration needs \(O(t_\mathrm{max}N).\)
-
*Phase 2 (Step 4 to Step 8). This phase uses the genetic algorithm with some improvements. The computational complexity of genetic algorithm is \(O(t_\mathrm{max}. NPkp)\) because of the following reasons:
The number of genes in a chromosome is kp. If there exists variable one in each gene, we need O(kp) to initialize one gene. P chromosomes need to be initialized, so the initialization of the whole population needs O(Pkp).
In one iteration, O(Pkp) is required for chromosome crossing. In one chromosome, gene rearrangement requires \(O(N^2kp).\)
Each iteration of mutation step is run O(Pkp) times, and O(NPkp) is required to select the best chromosomes in each iteration.
The IDB index is used as objective functions and required O(Nkp) to calculate individual fitness.
-
*Phase 3 (remaining steps): It is used to find the fuzzy relationship of elements in clusters, so it has the same construction with fuzzy c-mean algorithm. The computational complexity of this phase is \(O(t_\mathrm{max}Nkp)\) based on the research of Sreenivasarao and Vidyavathi [45].
In short, the total computational complexity of the proposed algorithm is
On comparing this result with other ones, we have Table 2.
Almost all of the popular fuzzy time series models have the computational complexity as the same as the model of Tai (2019) [46]. Table 2 shows that the computational complexity of the proposed model is more complicated than other models.
3 Numerical example and comparisons
3.1 Numerical example
We use the EnrollmentAU series performed in many studies [13, 46, 47] to illustrate the developed algorithm. The value of the EnrollmentAU series is given by Column \(T_i\) of Table 3.
- Step 1:
-
Initialize \(t=0\); because of \(\mathrm{max}\{T\}=19337,\) \(V^{(0)}\) is computed by the third column of Table 3.
- Step 2:
-
Calculating the prototype elements by Formula (1), we obtained \(V^{(1)}\) in Table 3.
- Step 3:
-
Because \(\mathrm{max}_i \{ |v^{(1)}_i-v^{(0)}_i|\} = 0.223 > \varepsilon ,\) the iterations of Phase 1 will continue. After 6 iterations of the above steps, Phase 1 stops. The result of these iterations is given in Table 3 and is shown in Fig. 2.

The convergence of EnrollmentUA data to 10 clusters
From Table 3 as well as Fig. 2, we see that the elements of series converge to 10 elements. Therefore, we divide the given series to \(k = 10\) groups.
Step 4 From the result of Phase 1, we encode the first chromosome as follows:
Step 5 Initialize 100 chromosomes and calculate the objective function (IDB) for each chromosome in population. The values of 100 chromosomes and IDB are shown in Table 10 (see Appendix A). Then, selecting the best chromosome with the smallest IDB, we have the chromosome 1 \((IDB=0.85).\) This result is used to create the new population for Step 6 and Step 7. Continue to run the steps of Phase 2 until IBD unchanged as shown in Fig. 3.

The convergence of the proposed method in Phase 2 after 300 iterations
Step 8 When Step 8 ends, we have the outcomes as follows:
-
The value of the best objective function: \(IDB =0.1534.\)
-
The optimal clusters:
$$\begin{aligned}\begin{array}{*{20}{l}} \begin{array}{l} {C_1} = \{ {X_5},{X_6},{X_{12}},{X_{13}}\} ;{C_2} = \{ {X_{11}}\} ;{C_3} = \{ {X_9},{X_{10}},{X_{17}}\} ;\\ {C_4} = \{ {X_4}\} ;{C_5} = \{ {X_{18}}\} ;{C_6} = \{ {X_{14}},{a_{15}}\} ;{C_7} = \{ {X_1},{X_2},{X_3}\} ; \end{array}\\ {{C_8} = \{ {X_{19}},{X_{20}},{X_{21}};{X_{22}}\} ;{C_9} = \{ {X_8}\} ;{C_{10}} = \{ {X_{16}}\} .} \end{array} \end{aligned}$$ -
The optimal centroid of clusters:
$$\begin{aligned}M^{300} = \{7.995; 8.266; 8.719; 7.171; 7.600; 7.014; 6.751; 8.475; 9.810; 7.832\}.\end{aligned}$$
Step 9 Performing Phase 3, we have the first partition matrix with \(t=0\) as follows:
Calculating the representative element of clusters, we have:
Step 10 Updating the new partition matrix, we obtain \(U^{(1)}:\)
Step 11 Repeating Step 9 and Step 10 for \(t=300\) iterations, Phase 3 stops. At that time, we obtain the matrix \(\mu _{ic}^{(300)}\) as shown in Fig. 4.

Bar graph showing the relation between each element with 10 clusters
Step 12 Applying the formula
where
we obtain Table 4 and is illustrated in Fig. 5.

Line graph of original and forecasting data
Computing the parameters to evaluate the model, we have
Figure 5 shows that the actual values are almost identical with the forecasted ones. It means that the proposed model is very suitable to forecast this series time.
3.2 Comparison with the popular models
This section compares the new model with the existing ones by the well-known data sets. The considered series are EnrrollmentUA [13], Taifex (Taiwan Stock Exchange) [15], Outpatient [23], and Foodgrain [25], and the compared models are Abbasov–Manedova [1] (AM), [34] (L-C), [27] (Hua), [23] (B-R), [41] (Si), [52] (Y-H), [25] (Gh), [13] (Chen), [15] (C-K), [16] (C-H), [32] (Kha), [53] (Yus), [21] (Egr), and Tai [46]. In each datum, we consider two cases:
- Case 1:
-
All of the series are used to build the models and to evaluate them by the parameters MAE, MAPE, and MSE.
- Case 2:
-
Eighty percent of each series is taken as the training set to build the ARIMA (autoregressive integrated and moving average), AM (Abbasov–Manedova), and IFTS [46] models (the others only interpolate) and about 20% of the remaining series is used as the test set. The effectiveness of the model is also evaluated by the MAE, MAPE, and MSE.
-
For Case 1, we obtain the results in Table 5:
Table 5 Parameters of models for the training sets Table 5 shows that the MAE, MAPE, and MSE parameters of the new model are always smaller than the compared existing models for all data sets. The parameters have shown the outstanding advantages in comparing the proposed model to others. For example, the value of MAPE of the proposed model for EnrollmentUA, Taifex, Outpatient, and Foodgrain data sets is 0.57, 0.1, 0.47, and 2.06, respectively, while the others have MAPE \(\in [1.02; 3.08]\) for EnrollmentUA, MAPE \(\in [0.16, 1.42]\) for Taifex, MAPE \(\in [1.09, 24.45]\) for Outpatient, and MAPE \(\in [4.53, 10.13]\) for Foodgrain. We also obtain the similar results for the MSE and MAE parameters.
-
For Case 2, their results are given in Table 6 (ARIMAR, AMR, and IFTSR are the ARIMA, IFTS, and Abassov models with the original data set. ARIMAP, IFTSP, and AMP are the ARIMA, IFTS, and Abassov models with a training set from the proposed algorithm).
Table 6 Parameters of models for the test sets
From Table 6, we also obtain the smallest value of the MAE, MAPE, and MSE for the proposed model on comparing with other ones.
To sum up, Tables 5 and 6 show that the proposed model has the best result in both interpolating and forecasting for all considered data sets. This shows the stability and the advantages of the new model. With a lot of considered models, this comparison is very meaningful in evaluating the advantages of the proposed model. In our opinion, the following are the reasons for this result. First, Phase 1 of the proposed model is an automatic algorithm that divides the series into groups with the appropriate numbers based on how similar they are in the series, while the other algorithms give the number of groups according to the experience or by language level. Second, Phase 2 only stops until the IDB index is optimized, while others base on distance criterion and do not consider parameters to evaluate the built algorithm. Finally, the relationship between each element in series and the divided groups is established appropriately. This relationship is built based on the fuzzy clustering algorithm, while others are often established by a specific expression.
3.3 Comparison with M3-Competition data
The third competition data called the M3-Competition were expanded from the M1-Competition data and M2-Competition data. It was built by [44]. This is very well known in series time which is often used to compare the efficiency of models together. Data set has 3003 series with many different kinds, including yearly, quarterly, monthly, daily, and others. They also belong to the different areas such as micro, industry, macro, finance, demographics, and other. The specificity about this set is presented in a lot of documents such as [44, 46, 47].
For these data, according to [44], the important models need to compare are ForecastPro, ForecastX, Bj automatic, Autobox1, Autobox2, Autobox3, Hybrid, ETS, and AutoARIMA (https: robjhyndman.com/m3comparisons.R). In the two recent studies, the authors Tai [46], Tai and Nghiep [47] have shown their outstanding advantages in comparison with all the above models. Therefore, we only compare the proposed result with that in [46, 47]. Let E(MAPE), E(MASE), and E(SMAPE) be the average of MAPE, MASE, and SMAPE, respectively. The result is presented in Table 7.
Table 7 shows that the new model is more advantages than the compared existing models. With the large number of considered series and the different features for the M3-competition data set, this comparison has shown the outstanding advantages of the new model in the existing ones.
4 A real application for COVID-19 victims in Vietnam
The COVID-19 pandemic is a global problem that most countries in the world are preventing. In the prevention of this pandemic, forecasting the number of victims is one of the important information because it is the base for preventable strategy of the governments. In this section, we use the proposed model to predict the number of COVID-19 victims in Vietnam. It is performed with the following steps:
-
The data are divided into two parts: 80% for the training set (97 dates) and 20% remaining for the test set (24 dates). Interpolating the training set by the proposed model, we have the results shown in Fig. 6. The proposed model has parameters MAE = 1.691; MAPE = 7.169; MSE = 6.288; SMAPE =0.483; and MASE = 0.475.
Figure 6 shows that the forecasting and actual values are almost identical.
Using the original and interpolated data from the training set to forecast for 24 dates by ARIMA, AM, SEDMFOA [17], and IFTS models, we obtain Table 8 and Fig. 7.
Figure 7 and Table 8 show that the models built from the interpolated data by the proposed model are better than the models built from the original data. Among them, ARIMAP gives the best result with 3.54% of MAPE, 11.1% of MAE, and 182.92% of MSE. These results have outstanding advantages compared to other models. Therefore, we use this model to forecast for the future.
-
Interpolating all data by the proposed model, we have Fig. 8, with MAE = 1.89; MAPE = 2.38; MSE = 11.10; SMAPE =0.87; and MASE = 0.55.
Using the data from Fig. 8, forecasting for the next several years by ARIMP model, we obtain Table 9.

Actual and forecasting values for the training set

Forecasting values for test set of models

Interpolating all data by the proposed model
Table 9 shows that in the next days, the number of COVID-19 victims in Vietnam is barely increased. This is suitable in reality in Vietnam.
5 Conclusion
This research has significant contributions for application of unsupervised learning in building the forecasting model for time series. From the automatic fuzzy genetic algorithm in clustering, we have some important improvements for the new model. They are the method to find the number of groups to divide the universal set, the algorithm to determine the probability to belong to the divided groups of each element in series, and the principle to interpolate the series from the above result. Implementing for 3007 series with very different numbers and characteristics, the proposed model has shown the stability and has given advantages in comparison with the existing ones via the parameters such as MAPE, MASE, and SMAPE.
A significant contribution of this study is the prediction of COVID-19 victims in Vietnam. Performance results show that the proposed model is good forecasts on this data set. By developing a predictive model that is entirely based on the relationship among the data in the series, we think that the proposed model can get relevant results in predicting COVID-19 victims in other countries. This research can contribute to the early warning of COVID-19 infection risk. This is also our next application direction in the near future.
For this study, we have also faced the problem of computing. Compared with other popular models, the calculation in the proposed model is more complicated. The proposed model has 12 steps that are divided into three phases and are set up in a model. As a result, the time cost of the proposed model is often more than others. In addition, in this study, we are only interested in the optimization of algorithm.
References
Abbasov A, Mamedova M (2003) Application of fuzzy time series to population forecasting. Vienna Univ Technol 12:545–552
Abreu PH, Silva DC, Mendes-Moreira J, Reis LP, Garganta J (2013) Using multivariate adaptive regression splines in the construction of simulated soccer teams behavior models. Int J Comput Intell Syst 6(5):893–910
Al-Douri Y, Hamodi H, Lundberg J (2018) Time series forecasting using a two-level multi-objective genetic algorithm: a case study of maintenance cost data for tunnel fans. Algorithms 11(8):123
Aladag CH, Basaran MA, Egrioglu E, Yolcu U, Uslu VR (2009) Forecasting in high order fuzzy times series by using neural networks to define fuzzy relations. Exp Syst Appl 36(3):4228–4231
Aladag S, Aladag CH, Mentes T, Egrioglu E (2012) A new seasonal fuzzy time series method based on the multiplicative neuron model and sarima. Hacettepe J Math Stat 41(3):337–345
Ali S, Hamid F, Mahdi F, Amir M, Abouzar E (2020) Generation expansion planning in the presence of wind power plants using a genetic algorithm model. Electronics. https://doi.org/10.3390/electronics9071143
Alpaslan F, Cagcag O, Aladag C, Yolcu U, Egrioglu E (2012) A novel seasonal fuzzy time series method. Hacettepe J Math Stat 41(3):375–385
Alireza B, Ali J, Mojtaba S, Mohammad H, Kwok W (2019) Developing an ANFIS-based swarm concept model for estimating the relative viscosity of nanofluids. Eng Appl Comput Fluid Mech 13(1):26–39
Bas E, Uslu VR, Yolcu U, Egrioglu E (2014) A modified genetic algorithm for forecasting fuzzy time series. Appl Intell 41(2):453–463
Baghban A, Jalali A, Shafiee M, Ahmadi MH, Chau KW (2019) Developing an ANFIS-based swarm concept model for estimating the relative viscosity of nanofluids. Eng Appl Comput Fluid Mech 13(1):26–39
Bora DJ, Gupta AK (2014) Impact of exponent parameter value for the partition matrix on the performance of fuzzy C means Algorithm. arXiv preprint arXiv:1406.4007
Cannon RL, Dave JV, Bezdek JC (1986) Efficient implementation of the fuzzy c-means clustering algorithms. IEEE Trans Pattern Anal Mach Intell 2:248–255
Chen SM (1996) Forecasting enrollments based on fuzzy time series. Fuzzy Sets Syst 81(3):311–319
Chen SM (2002) Forecasting enrollments based on high-order fuzzy time series. Cybern Syst 33(1):1–16
Chen SM, Kao PY (2013) Taiffex forecasting based on fuzzy time series, particle swarm optimization techniques and support vector machines. Inf Sci 247:62–71
Chen SM, Hsu CC et al (2004) A new method to forecast enrollments using fuzzy time series. Int J Appl Sci Eng 2(3):234–244
Chen Y, Pi D (2019) Novel fruit fly algorithm for global optimisation and its application to short-term wind forecasting. Connect Sci 31(3):244–266
Davies DL, Bouldin DW (1979) A cluster separation measure. https://doi.org/10.1109/TPAMI.%201979.4766909
Egrioglu E, Aladag CH, Yolcu U, Basaran MA, Uslu VR (2009) A new hybrid approach based on sarima and partial high order bivariate fuzzy time series forecasting model. Exp Syst Appl 36(4):7424–7434
Egrioglu E, Aladag CH, Yolcu U, Uslu VR, Basaran MA (2009) A new approach based on artificial neural networks for high order multivariate fuzzy time series. Exp Syst Appl 36(7):10589–10594
Egrioglu E, Bas E, Aladag C, Yolcu U (2016) Probabilistic fuzzy time series method based on artificial neural network. Am J Intell Syst 6(2):42–47
Friedman JH et al (1991) Multivariate adaptive regression splines. Ann Stat 19(1):1–67
Garg B, Garg R (2016) Enhanced accuracy of fuzzy time series model using ordered weighted aggregation. Appl Soft Comput 48:265–280
Ghalandari M, Ziamolki A, Mosavi A, Shamshirband S, Chau KW, Bornassi S (2019) Aeromechanical optimization of first row compressor test stand blades using a hybrid machine learning model of genetic algorithm, artificial neural networks and design of experiments. Eng Appl Comput Fluid Mech 13(1):892–904
Ghosh H, Chowdhury SP, (2016) An improved fuzzy time-series method of forecasting based on l-r fuzzy sets and its application. J Appl Stat 43(6):1128–1139
Hongchun Q, Li Y, Xiaoming T (2020) An automatic clustering method using multi-objective genetic algorithm with gene rearrangement and cluster merging. Appl Soft Comput J. https://doi.org/10.1016/j.asoc.2020.106929
Huarng K (2001) Heuristic models of fuzzy time series for forecasting. Fuzzy Sets Syst 123(3):369–386
Huarng K, Yu THK (2006) Ratio-based lengths of intervals to improve fuzzy time series forecasting. IEEE Trans Syst Man Cybern Part B Cybern 36(2):328–340
Jamwal PK, Abdikenov B, Hussain S (2019) Evolutionary optimization using equitable fuzzy sorting genetic algorithm. IEEE Access 7:8111–8126
Jain S, Bisht DC, Singh P, Mathpal PC (2017) Real coded genetic algorithm for fuzzy time series prediction 1897(1):020–021
Kamel MS, Selim SZ (1994) New algorithms for solving the fuzzy clustering problem. Pattern Recognit 27(3):421–428
Khashei M, Bijari M, Hejazi SR (2011) An extended fuzzy artificial neural networks model for time series forecasting 8(3):45–66
Lai CC (2005) A novel clustering approach using hierarchical genetic algorithms. Intell Autom Soft Comput 11(3):143–153
Lee HS, Chou MT (2004) Fuzzy forecasting based on fuzzy time series. Int J Comput Math 81(7):781–789
Lewis PA, Stevens JG (1991) Nonlinear modeling of time series using multivariate adaptive regression splines (mars). J Am Stat Assoc 86(416):864–877
Mirjalili S, Lewis A (2016) The whale optimization algorithm. Adv Eng Softw 95:51–67
Own CM, Yu PT (2005) Forecasting fuzzy time series on a heuristic high-order model. Cybern Syst Int J 36(7):705–717
Prashant KJ, Beibit A, Shahid H (2018) Evolutionary optimization using equitable fuzzy sorting genetic algorithm. IEEE Access. https://doi.org/10.1109/ACCESS.2018.2890274
Pal NR, Bezdek JC (1995) On cluster validity for the fuzzy c-means model. IEEE Trans Fuzzy Syst 3(3):370–379
Sahragard A, Falaghi H, Farhadi M, Mosavi A, Estebsari A (2020) Generation expansion planning in the presence of wind power plants using a genetic algorithm model. Electronics 9(7):1143
Singh SR (2007) A simple method of forecasting based on fuzzy time series. Appl Math Comput 186(1):330–339
Song Q, Chissom BS (1993) Forecasting enrollments with fuzzy time series-Part I. Fuzzy Sets Syst 54(1):1–9
Song Q, Chissom BS (1994) Forecasting enrollments with fuzzy time series-part II. Fuzzy Sets Syst 62(1):1–8
Spyros M, Michle H (2000) The M3-competition: results, conclusions and implications. Int J Forecast 16:451–476
Sreenivasarao V, Vidyavathi S (2010) Comparative analysis of fuzzy C-mean and modified fuzzy possibilistic C-mean algorithms in data mining. Ijcst 1(1):104–106
Tai VV (2019) An improved fuzzy time series forecasting model using variations of data. Fuzzy Optim Decis Making 18(2):151–173
Tai VV, Nghiep LN (2019) A new fuzzy time series model based on cluster analysis problem. Int J Fuzzy Syst 21(3):852–864
Taormina R, Chau KW (2015) ANN-based interval forecasting of streamflow discharges using the LUBE method and MOFIPS. Eng Appl Artif Intell 45:429–440
Teoh HJ, Cheng CH, Chu HH, Chen JS (2008) Fuzzy time series model based on probabilistic approach and rough set rule induction for empirical research in stock markets. Data Knowl Eng 67(1):103–117
Wu CL, Chau KW (2013) Prediction of rainfall time series using modular soft computing methods. Eng Appl Artif Intell 26(3):997–1007
Xu Y, Pi D, Yang S, Chen Y (2021) A novel discrete bat algorithm for heterogeneous redundancy allocation of multi-state systems subject to probabilistic common-cause failure. Reliab Eng Syst Safety. https://doi.org/10.1016/j.ress.2020.107338
Yu THK, Huarng KH (2010) A neural network-based fuzzy time series model to improve forecasting. Exp Syst Appl 37(4):3366–3372
Yusuf S, Mohammad A, Hamisu A (2017) A novel two-factor high order fuzzy time series with applications to temperature and futures exchange forecasting. Nigerian J Technol 36(4):1124–1134
Acknowledgements
For Tai Vovan, this research is funded by Ministry of Education and Training in Viet Nam under grant number B2022–TCT–03.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Phamtoan, D., Vovan, T. Building fuzzy time series model from unsupervised learning technique and genetic algorithm. Neural Comput & Applic 35, 7235–7252 (2023). https://doi.org/10.1007/s00521-021-06485-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-021-06485-7