
Abstract.
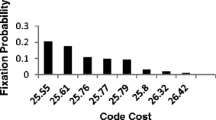
A paper (Amirnovin R, J Mol Evol 44:473–476, 1997) seems to undermine the validity of the coevolution theory of genetic code origin by shedding doubt on the connection between the biosynthetic relationships between amino acids and the organization of the genetic code, at a time when the literature on the topic takes this for granted. However, as a few papers cite this paper as evidence against the coevolution theory, and to cast aside all doubt on the subject, we have decided to reanalyze the statistical bases on which this theory is founded. We come to the following conclusions: (1) the methods used in the above referred paper contain certain mistakes, and (2) the statistical foundations on which the coevolution theory is based are extremely robust. We have done this by critically appraising Amirnovin's paper and suggesting an alternative method based on the generation of random codes which, along with the method reported in the literature, allows us to evaluate the significance, in the genetic code, of different sets of amino acid pairs in biosynthetic relationships. In particular, by using this method and after building up a certain set of amino acid pairs reflecting the expectations of the coevolution theory, we show that the presence of this set in the genetic code would be obtained, purely by chance, with a probability of 6 × 10−5. This observation seems to provide particularly strong support to the coevolution theory.
Article PDF
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Author information
Authors and Affiliations
Additional information
Received: 28 June 1999 / Accepted: 23 October 1999
Rights and permissions
About this article
Cite this article
Di Giulio, M., Medugno, M. The Robust Statistical Bases of the Coevolution Theory of Genetic Code Origin. J Mol Evol 50, 258–263 (2000). https://doi.org/10.1007/s002399910030
Issue Date:
DOI: https://doi.org/10.1007/s002399910030