
Abstract
We revisitself-adjustingexternal memory tree data structures, which combine the optimal (and practical) worst-case I/O performances of B-trees, while adapting to the online distribution of queries. Our approach is analogous to undergoing efforts in the BST model, where Tango Trees (Demaine et al., SIAM J. Comput. 37(1), 240–251, 2007) were shown to be \(O(\log \log N)\)-competitive with the runtime of the best offline binary search tree on every sequence of searches. Here we formalize the B-Tree model as a natural generalization of the BST model. We prove lower bounds for the B-Tree model, and introduce a B-Tree model data structure, the Belga B-tree, that executes any sequence of searches within a \(O(\log \log N)\) factor of the best offline B-tree model algorithm, provided \(B=\log ^{O(1)}N\). We also show how to transform any static BST into a static B-tree which is faster by a \({\varTheta }(\log B)\) factor; the transformation is randomized and we show that randomization is necessary to obtain any significant speedup.
Similar content being viewed by others



Avoid common mistakes on your manuscript.
1 Introduction
Worst-case analysis does not capture the fact that some sequences of operations on data structures, often typical ones, can be executed significantly faster than worst case ones. Methods of analyzing algorithms whose performance depends on more fine-grained characteristics of the input sequence other than the size N have been coined distribution sensitive data structures [7, 22]. Two general methods to bound the performance of such a data structure exist. The first is to explicitly bound the performance by some bound. For binary search trees (BSTs) there is a rich set of such bounds (see e.g. [9, 18]) like the sequential access bound [29], the working set bound [21, 28], the (weighted) dynamic finger bound [11, 12, 24], the unified bound [3, 21] and many others [6, 10, 20]. The other method is to compare the performance of the data structure on a sequence of operations to the performance of the best offline data structure in some model on the same sequence. Such an analysis uses the language of competitive analysis introduced in [27], where the competitive ratio of an algorithm is the supremum ratio of the performance of the given algorithm to the offline optimal over all sequences of operations over a given length. A data structure which is O(1)-competitive in a particular model is said to be dynamically optimal [28]. In the BST model, the best known competitive ratio is \(O(\log \log N)\), first achieved by Tango trees [14]. The existence of a dynamically optimal BST is one of the most intriguing and long-standing open problems in online algorithms and data structures (see [23] for a survey). The two prominent candidates to achieve dynamic optimality for BSTs are the splay tree of Sleator and Tarjan [28] and the greedy algorithm [15, 25], but they are only known to be \(O(\log N)\)-competitive.
Disk-Access Model (DAM)
The external memory model, or disk-access model (DAM) [2] is the leading way to theoretically model the performance of algorithms that can not fit all of their data in RAM, and thus must store it on a slower storage system historically known as disk. This model is parameterized by values M and B; the disk is partitioned into blocks of size B, of which M/B can be stored in memory at any given moment. The cost in the DAM is the number of transfers between memory and disk, called Input-Output operations (I/Os). The classic data structure for a comparison based dictionary in the DAM model, as well as in practice, is the B-Tree [4]. The B-Tree is a generalization of the BST, where each node stores up to B − 1 data items, for B ≥ 2, and the number of children is one more than the number of data items. The B-Tree supports searches in time \(O(\log _{B} N)\) in the DAM, a \(\log B\) factor faster than traditional BSTs such as red-black trees [19] or AVL trees [1].
Dynamic Dictionaries in the DAM
Here, our goal is to explore dynamic dictionaries in the DAM and to obtain results similar to those known for BSTs. Similarly to the classic dynamic optimality theory for BSTs, we focus on searching from a fixed universe of keys and assume that no insertions and deletions of keys occur.
Surprisingly, prior work in this direction is quite limited. One previous attempt was in the work of Sherk [26] where a generalization of splay trees to what we call the B-tree model was proposed, but without any strong results. Over ten years later, Bose et al. [5] studied a self-adjusting version of skip-lists and B-Trees, where nodes can be split and merged to adapt to the query distribution by moving elements closer or farther from the root of the tree (here we call this model classic self-adjusting B-trees, see Section 2). They showed that dynamic optimality in this model is closely related to the working set bound. This bound captures temporal locality: for an access sequence \(X = x_{1},\dotsc ,x_{m} \), it is defined as \(\text {WS}(X) = {\sum }_{i=1}^{m} \log w_{X}(i)\), where wX(i) is the number of distinct elements accessed since the last access to the element xi. In [5] the authors presented a data structure whose cost is upper bounded by \(O(\text {WS}(X)/\log B)\) and obtained a matching lower bound of \({\varOmega }(\text {WS}(X)/\log B)\) for this model, which implies that their structure is dynamically optimal.
Note that the lower bound of [5] shows a major limitation of B-trees with only split and merge operations: It implies there are sequences on which they are slower than BSTs. For example, repeatedly sequentially accessing all data items \(1,2,\dotsc ,N\) requires O(1) amortized time per search for BSTs like splay trees (this is the sequential access bound [29]) while the lower bound \({\varOmega }(\text {WS}(X)/\log B)\) implies an amortized cost \({\varOmega }(\log _{B} N)\) in the classic self-adjusting model. In this work, we show that by adding just one more operation, an analogue of the rotation for B-Trees, we can overcome this limitation and obtain significant speedups with respect to standard B-trees.
Our Contribution
In this work we initiate a systematic study of dynamic B-trees. First, we formally define the (dynamic) B-Tree model of computation (Section 2). Second, we show how to produce lower bounds in the B-Tree model (Section 3). Then, we introduce a data structure, which we call the Belga B-Tree,Footnote 1 which is \(O(\log \log N)\) competitive with any dictionary in the B-Tree model of computation, when \(B=O(\log ^{O(1)}N)\) (Section 4).
More generally, we conjecture the following in Section 6: any BST-model algorithm can be transformed into a (randomized) B-Tree model algorithm with a \({\varTheta }(\log B)\) factor cost savings. This would imply that BST model algorithms such as the splay tree [28] or greedy [15, 25] would have B-Tree model counterparts, and that a dynamically optimal BST-model algorithm would imply a dynamically optimal algorithm in the B-Tree model. We leave this conjecture open, but in Section 5 we do resolve the case of a static (no rotations allowed) BSTs by showing a randomized transformation from a static BST to a static B-Tree such that any algorithm in the static BST model would have factor \({\varTheta }(\log B)\) speedup in the B-Tree model. We also show that no ω(1)-factor speedup is possible for a deterministic transformation in general.
2 The B-Tree Model of Computation
In this section, we define the tree models discussed in this paper. In all cases, we consider data structures supporting searches over a universe of N elements \(\mathcal {U} = \lbrace 1,2,\dotsc ,N \rbrace \) which we refer to as keys. The input is a valid tree T0 storing all keys of \(\mathcal {U}\) and a request sequence of searches \(X = x_{1},x_{2} \dotsc , x_{m}\), where \(x_{i} \in \mathcal {U} \) is the i th item to be searched.
2.1 The BST Model
In a Binary Search Tree (BST) data structure, each node stores a single key and three pointers, indicating its parent and its (left and right) children. The key value of a node is larger than all keys in its left subtree and smaller than all keys in its right subtree. To execute a search for a key xi, a BST algorithm initializes a single pointer at the root (at unit cost) and then may perform any sequence of the following unit-cost operations:
-
Move the pointer to the parent or to a child of the current node the pointer points to (if such a destination node exists).
-
Perform a rotation of the edge between current node v and its parent (if v is not the root).
Whenever the pointer points to a node v, we say that node v is touched. A BST-model search algorithm is correct if during a search for a key xi, the node containing xi is touched. The cost of a BST algorithm on the search sequence X equals the total number of unit-cost operations performed to execute the searches in the sequence. This model was formally defined in [14] and it is known to be equivalent up to constant factors to several alternative models which have been considered (e.g. [15, 31]).
A BST data structure can be augmented such that each node stores \(O(\log N)\) additional bits of information. The running time of such BST data structures in the RAM model is dominated by the number of unit-cost operations.
A static BST is a restricted version of the BST model where rotations are not allowed and thus the shape of the tree never changes.
2.2 The B-Tree Model
We define the B-tree model to be a generalization of the BST model which allows more than one key to be stored in each node. The B-tree model is parameterized by a positive integer B ≥ 2 which represents the maximum number of children of each node;Footnote 2 in the case where B = 2 the B-tree model will be equivalent to the BST model. We denote by n(v) the number of keys stored in a node v. Every node v has n(v) ≤ B − 1 and n(v) + 1 child pointers (some of which could be null). A node v which stores exactly n(v) = B − 1 keys is called full.
Suppose \(x_{1},\dotsc ,x_{n(v)}\) are the keys stored at node v and c1,⋯ ,cn(v)+ 1 are the children of v. Keys satisfy the in-order condition, i.e. \(x_{1} < \dotsc < x_{n(v)}\) and for any key ki stored in the subtree \(T_{c_{i}}\) rooted at ci, we have that k1 < x1 < ⋅ < ki < xi < ki+ 1 < ⋯ < kn(v) < xn(v) < kn(v)+ 1.
Similar to the BST model, to execute each search there is a single pointer initialized to the root of the tree at unit cost. To execute a search for a key xi, a B-tree algorithm performs a sequence of the following unit-cost operations which are described formally later:
-
Move the pointer to a child or to the parent of the current node.
-
Split a node containing at least three keys.
-
Join two sibling nodes storing no more than B − 2 keys in total.
-
Rotate the edge between the current node and its parent.
B-tree model algorithms that only use the first type of operations are referred to as static as the shape of the B-tree does not change. Similarly to BST, a B-tree model algorithm is correct if during a search for a key xi, the node containing xi is touched. We now fully describe the unit-cost operations of rotating, splitting and joining:
- Rotations::
-
Consider a (non-root) node u and let p(u) be its parent. Let \(P =\lbrace p_{1}, \dotsc , p_{m} \rbrace \) be the union of all keys stored in u and p(u). The keys stored at u define an interval [pℓ,pr] in P. A rotation of the edge (p(u),u) essentially updates this interval to \([p_{\ell ^{\prime }},p_{r^{\prime }}]\), moving the keys as needed. Depending on the values of \(\ell , \ell ^{\prime }\) and \(r, r^{\prime }\) we characterize a rotation as a promote/demote left—promote/demote right rotation. For example, a rotation of the type promote left k—demote right \(k^{\prime }\) sets \(\ell ^{\prime } = \ell + k\) (i.e. the k leftmost keys of u are promoted to p(u)) and \(r^{\prime } = r + k^{\prime }\) (i.e. keys \(p_{r+1},\dotsc ,p_{r+k^{\prime }}\) are demoted to u). Values k and \(k^{\prime }\) should be non-negative and satisfy that after the rotation both u and p(u) have at most B − 1 keys. Rotations of the type demote left—promote right, promote left—promote right and demote left—demote right can be defined analogously. As an example, Fig. 1 shows a rotation of type demote left - promote right.
- Splitting a node::
-
Let u be a node (except the root) containing at least three keys and let p(u) be its non-full parent. Splitting node u at key um (which is not the smallest or the largest key stored at u) consists of promoting um to p(u) and replacing u by 2 nodes uL,uR such that keys smaller than um are contained in uL and keys larger than um are in uR. To split the root (given that it stores at least three keys), we create an empty B-tree node, make it the parent of the root (i.e. the new root) and then perform a split operation as defined above.
- Join::
-
This operation is the inverse of a split. Let u and v be two sibling nodes and let p be their parent, such that there exists a unique key pj in p such that pj is larger than all keys stored at u and smaller than all keys stored at v. Joining nodes u and v (given that they store no more than B − 2 keys in total) consists of demoting pj to u (and deleting it from p), adding all elements of v (including the pointers to children) to u and deleting v. Note that after a join operation p might become empty (in case pj was the unique key of p). In that case, we set the parent of u to be the parent of p (if it exists) and we delete p. If p is empty and it is the root, then we just delete p and u becomes the new root of the tree.
Fig. 1 
A rotation of a B-tree edge (u,v) of the type demote left ℓ—promote right k: From the left of v, the ℓ neighboring keys of \(u, u_{j-\ell +1},\dotsc ,u_{j} \) are getting demoted to v. From the right, the k last elements of \(v, v_{n-k+1},\dotsc ,v_{n}\) are getting promoted to u
Fig. 2 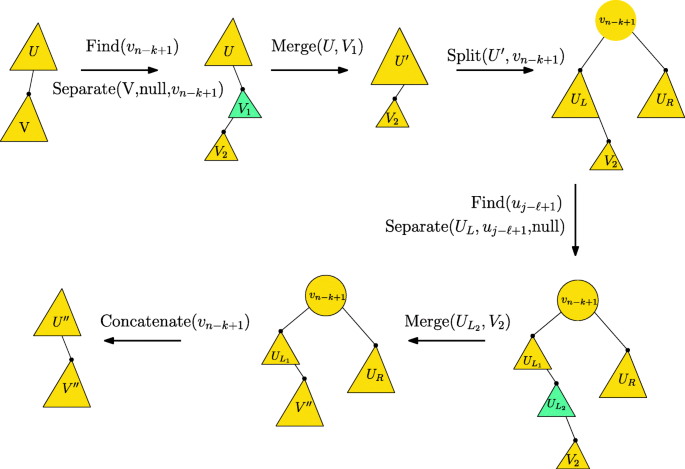
Simulating a rotation of a B-tree edge (u,v) of the type demote left ℓ - promote right k in the BST model using red-black tree operations of merge, separate, split, concatenate and find a key with a given rank


A B-tree can be augmented with additional \(O(B \log N)\) bits of information for each node. The performance of B-trees in the external memory model with blocks of size B, is within a constant factor of the sum of the unit-cost operations as we have defined them.
Relation with Other B-Tree Models
The classic structure of B-trees first appeared in [4]. In this framework, all leaves have the same depth and no join, split and rotate operations are performed during searches (to be precise, restricted versions of split and join were defined in order to support insertions and deletions and were not allowed for performing search operations, see [13] for an extensive treatment). We call this framework the classic B-tree model.
A more flexible model of B-trees was considered in [5]: We start with a classic B-tree and an algorithm is allowed to perform joins and splits, but not rotations. Note that by performing join and split operations, the property that all leaves of the tree have the same depth is maintained throughout the whole execution. This model was called “self-adjusting B-trees”. To avoid confusion with our dynamic B-tree model, we call this model classic self-adjusting B-trees, in order to emphasize that all leaves have the same depth, as in classic B-trees. The self-adjustment relies on the fact that using joins and splits the algorithm might choose to bring an item closer to the root or demote it farther from the root. Also, note that the number of nodes in a B-tree on N keys is not fixed (as opposed to BSTs where we always have exactly N nodes) and the split/join operations might increase/decrease the number of nodes of the tree, changing thus its shape.
For the rest of this paper, whenever we use the term B-tree we refer to our B-tree model, unless stated otherwise.
3 Lower Bounds: Simulating Dynamic B-Trees Using BSTs
In this section we show how to simulate a dynamic B-tree algorithm using a BST-model algorithm with an \(O(\log B)\) overhead in the cost. This will allow us to transform lower bounds from the BST model into lower bounds for the B-tree model.
Notation
For a search sequence X, we denote OPTBST(X) and OPTB-Tree(X) the optimal (offline) cost to serve X using a BST-model and a B-tree-model data structure respectively.
Theorem 1
For any search sequence X, \(\text {OPT}_{BST}(X) = O(\text {OPT}_{\text {B-Tree}}(X) \cdot \log B )\).
Proof
We simulate a B-tree execution of X using a BST in the following way: Each node of the B-tree is simulated by a red-black tree of depth \(O(\log B)\). Thus our BST is a tree of red-black trees. We also augment the red-black tree data structure such that each node stores a counter on the number of keys in its subtree. Note that in this tree-of-trees, leaves of a red-black tree might have children, which are the roots of other red-black trees. To distinguish the leaves of each tree, we mark the root of each red-black tree. We also use the parent-child terminology for those red-black trees, i.e., if U and V are red-black trees corresponding to B-tree nodes u and v respectively such that u is a child of v, we will say that “tree U is a child of tree V”.
It remains to show that each unit-cost B-tree operation can be simulated in time \(O(\log B)\) using our tree-of-trees BST data structure. Moving the pointer from a B-tree node to an adjacent node corresponds to moving the BST pointer from the root of one red-black tree to the root of its child/parent. This can be done in \(O(\log B)\) time, since the depth of our red-black trees is \(O(\log B)\). For the other unit-cost operations showing this is more complicated. In order to keep the presentation as simple as possible, we proceed as follows: we first describe some basic properties of red-black trees, we then use them to develop operations of merging and separating red-black trees which will be useful in our tree-of-trees construction and finally we show how to implement the B-tree unit-cost operations using all those tools. □
Background on Red-Black Trees
We note that red-black trees on k nodes support split and concatenate operations, as well as finding the ℓ th largest (or smallest key) in time \(O(\log k)\) [13]. We now describe those operations.
-
The split operation of a red-black tree T at a node x re-arranges the tree such that x is the root and the left and right subtrees are red-black trees including keys of smaller and larger values than x respectively.
-
Concatenating two red-black trees T1,T2 whose roots are children of a common node x, consists of re-arragning the subtree of x to form a red-black tree on all keys of T1 ∪ T2 ∪{x}. This operation is also referred as concatenating at x and it can be defined even if one of T1,T2 is empty. Particularly, in our tree of trees construction, if we concatenate at a node x whose left (right) child is marked, then we treat its left (right) subtree as empty.
-
Find the key with a given rank: Given an augmented red-black tree on k nodes, where each node stores the number of keys in its subtree and a value ℓ < k, we can find its ℓ th largest (or smallest) key in \(O(\log k)\) time (see e.g. [13, Chapter 14]).
Combining and Separating Red-Black Trees
We now develop two procedures that will be useful in our implementation of B-tree unit cost operations. In particular we show how to merge and separate red-black trees in \(O(\log k)\) time, where k is the total number of nodes in the trees involved.
-
(i)
Merge(S,T): Given two red-black trees S and T such that T is a child of S, merge them into one valid red-black tree. We describe an implementation of this operation in \(O(\log k)\) time, where k is the total number of nodes of S and T. Let yT be the root of T. We can find the predecessor ℓ and the successor r of yT in S in \(O(\log k)\) time, by searching for the key value of yT in S. Note that either ℓ or r might not exist. We split S at ℓ (if it exists) and then split the right subtree in r (if it exists). Now, T is the left subtree of r (if r does not exist, T is just the right subtree of ℓ). Unmark the root of T. Then, concatenate at r (skip this step if r does not exist) and finally concatenate at ℓ (if it exists). The result is a valid red-black tree containing all keys of S and T. We used a constant number of \(O(\log k)\)-time operations.
-
(ii)
Separate(T,ℓ,r): Given a red-black tree T, separate keys with values in the interval [ℓ,r], i.e. split T into two trees T1,T2 where T2 contains keys with values in the interval [ℓ,r] and T1 is a parent of T2. In case ℓ is not specified (ℓ = null), we think of ℓ as being the minimum key value in T and this operation separates all keys with value at most r. Symmetrically, if r is null, we think of r as being the maximum key value in T and this operation separates keys with value at least ℓ. We implement this as follows. Let \(\ell ^{\prime }\) be the predecessor of ℓ in T (if exists) and \(r^{\prime }\) the successor or r (if exists). Split T in \(\ell ^{\prime }\) (skip this step if \(\ell ^{\prime }\) does not exist) and then split the subtree with values larger than \(\ell ^{\prime }\) at \(r^{\prime }\) (skip this step if \(r^{\prime }\) does not exist). As a result the left subtree of \(r^{\prime }\) (or the right subtree of \(\ell ^{\prime }\) if \(r^{\prime }\) does not exists) is the tree T2 containing all keys in [ℓ,r]. Mark the root of T2. Then concatenate at \(r^{\prime }\) (if exists) and finally concatenate at \(\ell ^{\prime }\) (if exists). As a result we get a valid red-black tree T1 which is the parent of red-black tree T2 containing all keys of the interval [ℓ,r].
Simulating the Unit-Cost Operations
We now proceed on showing how to simulate B-tree rotations, splits and joins using our tree of red-black trees data structure with cost \(O(\log B)\). In all cases, the total number of keys in the trees involved is O(B) and we perform a constant number of operations which take time \(O(\log B)\).
-
Rotations. We show how to implement a rotation of the form demote left ℓ—promote right k (assuming valid values of ℓ and k). The other operations are defined analogously. Let (u,v) be the B-tree edge which is rotated, where node u is parent of v and let U and V be the augmented red-black trees corresponding to u and v. Let \(u_{1}, \dotsc , u_{j} , u_{j+1}, \dotsc , u_{m}\) and \( v_{1}, \dotsc , v_{n} \) be the key values stored in u and v respectively such that for all vi we have that uj < vi < uj+ 1, similar to the example in Fig. 1. The rotation corresponds to promoting to U the k largest keys of V, i.e. \(v_{n-k+1},\dotsc ,v_{n}\) and demoting to V the keys \(u_{j-\ell +1},\dotsc ,u_{j}\). We implement such a rotation as follows (see Fig. 2 for an illustration): We start by promoting the k elements to U. Find vn−k, i.e. the (k + 1)th largest key stored at V. Then, Separate(V,null,vn−k) to get a tree V1 containing keys \(v_{n-k+1},\dotsc ,v_{n}\) and a tree V2 with the rest keys of V. V2 is a child of V1 and V1 is a child of U. Now, we merge U and V1 to get a new tree \(U^{\prime }\), such that V2 is a child of \(U^{\prime }\). It remains to demote \(u_{j-\ell +1},\dotsc ,u_{j}\) to V2. To do that, we split \(U^{\prime }\) at vn−k+ 1. Let UL and UR be the two subtrees of vn−k+ 1 in \(U^{\prime }\). Note that \(u_{j-\ell +1},\dotsc ,u_{j}\) are the ℓ largest keys of UL. Find uj−ℓ+ 1, i.e., the ℓ th largest key of UL and Separate(UL,uj−ℓ+ 1,null). We get a separate tree \(U_{L_{2}}\) containing \(u_{j-\ell +1},\dotsc ,u_{j}\). Mark the root of \(U_{L_{2}}\). Now, V2 is a child of \(U_{L_{2}}\), so we can merge them to form \(V^{\prime \prime }\), the tree corresponding to B-tree node v. Finally we concatenate at the root vn−k+ 1, to form the final tree corresponding to u, denoted by \(U^{\prime \prime }\), where \(V^{\prime \prime }\) is a child of \(U^{\prime \prime }\).
-
Splitting a node of a B-tree. Let u be the node which we want to split and p(v) its parent. Let also U and P the corresponding red-black trees, where U is a child of P. Let um be the median key value of U. We split U at um, so that um is the root with subtrees UL and UR. Mark the roots of UL and UR and then merge um (which is a single-node red-black tree) with P. Clearly all those operations can be performing in \(O(\log B)\) time.
-
Joining two sibling nodes. This is the inverse operation of splitting so the sequence of operations can be seen as the symmetric of the ones performed in splitting. Let u and v be the sibling B-tree nodes that we want to join, and p their parent, with U,V and P the corresponding red-black trees in our binary search tree. U and V are children of P and there is a unique key pj in P such that keys stored at U are smaller than pj and keys stored at V are larger. Thus, pj is the successor of the root of U in P and we can find it in \(O(\log B)\) time. We then Separate(P,pj,pj). Now we get a new tree P1 containing all keys of P except from pj, and pj is a single-node red-black tree, child of P1. U and V are the left and right children of pj. We unmark the roots of U and V and concatenate at pj, to get a new tree \(U^{\prime }\) and mark its root. Now \(U^{\prime }\) corresponds to the join node of u and v, and it is a child of the red-black tree \(P^{\prime }\) which corresponds to the parent node in the B-tree. We performed a constant number of operations each of which takes time \(O(\log B)\).
Theorem 1 implies that we can transform any lower bound for binary search trees to a lower bound for dynamic B-trees, as shown in the following corollary.
Corollary 2
Let X be a search sequence and let LB(X) be any lower bound on the cost of executing X in the BST model. Then we have that \(\text {OPT}_{\text {B-Tree}}(X) = {\varOmega }\left (\frac {\text {LB}(X)}{\log B} \right )\).
Proof
Since LB(X) is a lower bound on OPTBST(X), we have that \( \text {LB}(X) \leq \text {OPT}_{BST}(X) = O(\log B) \cdot \text {OPT}_{\text {B-Tree}}(X)\), which implies \(\text {OPT}_{\text {B-Tree}}(X) = {\varOmega }\left (\frac {\text {LB}(X)}{\log B} \right )\). □
4 Belga B-Trees
In this section, we develop a dynamic B-tree data structure yclept Belga B-tree that achieves a competitive ratio of \(O(\log \log N)\), for search sequences of length Ω(N), provided that \(1 + \log _{B} \log N = O(\log _{B} \log N)\), i.e. \(B= (\log N)^{O(1)}\). Our construction is built upon the ideas used in [14] to get a similar competitive ratio for binary search trees. Particularly, we crucially connect the cost of our algorithm to the interleave lower bound. For completeness, we present here the setup and the necessary background regarding this lower bound.
Interleave Lower Bound and Preferred Paths (See Fig. 3)
Let {1,…,N} be the keys stored in our B-tree. Let P be a (fixed) complete binary search tree on those keys. For each internal node v in P, we define its left region to be v together with the subtree rooted at its left child and its right region to be the subtree rooted at its right child. Node v has a preferred child, which is left or right, depending on whether the last search for a node in its subtree was in its left or right region (if no node of the subtree rooted at v has been searched, then v has no preferred child).

Example of a reference tree P and the tree-of-trees representation of its preferred paths \(P_{1},\dotsc ,P_{8}\). Edges connecting different preferred paths are dashed gray
We define a preferred path in P as follows: Start from a node that is not the preferred child of its parent (including the root) and perform a walk by following the preferred child of the current node (if preferred child of a node is undefined, pick one arbitrary) until reaching a leaf. Clearly, a preferred path contains \(O(\log N)\) keys.
Note that during a search for a key, the preferred child of some nodes that are ancestors of the node with the key being searched might change. Each change of preferred child, changes also the preferred paths of P. For a search sequence X, the interleave lower bound IB(X) equals the total number of changes of preferred child from left to right or from right to left, over all nodes of P. We use the following lemma of [14], which is a slight variant of the first lower bound of [31]:
Lemma 1 (Lemma 3.2 in 14)
The cost to execute X in the BST model is Ω(IB(X)) if |X| = Ω(N).
High-Level Overview of Our Structure
We store each preferred path in a balanced classic B-tree. We call such classic B-trees auxiliary trees. Our dynamic B-tree will be a tree of classic B-trees. Recall that Lemma 1 essentially tells us that the number of preferred paths touched during a request sequence X is a lower bound on the value of OPTBST(X). The idea here is to show that for each preferred path touched, we can perform search and all update operations (cutting and merging preferred paths) with an overhead factor \(O(\log _{B} \log N ) = O(\frac {\log \log N}{\log B})\). This will imply that we have a dynamic B-tree with cost roughly \(O(\frac {\log \log N}{\log B} \cdot \text {OPT}_{BST}(X)) \). This combined with Theorem 1 implies that the cost of our dynamic B-tree data structure is \(O(\log \log N) \cdot \text {OPT}_{\text {B-Tree}}(X)\).
Auxiliary Trees
Our auxiliary trees are augmented classic B-trees. Each auxiliary tree stores a preferred path. With each key x we also store its depth in the reference tree P. We call this value depth of key x. Also, each node stores the minimum and maximum depth of a key in its subtree. Last, a node may be marked or unmarked, depending on whether it is the root of an auxiliary tree or not. Note that P is just a reference tree used for the analysis. We do not need to store P explicitly in order to implement our algorithm. All necessary information about P is stored in our dynamic B-tree data structure.
During an execution of a search sequence we need to perform the following operations on a preferred path:
-
(i)
Search for a key.
-
(ii)
Cut the preferred path into two paths, one consisting of keys of depth at most d and the other of keys of depth greater than d.
-
(iii)
Merge two preferred paths P1 and P2, where the bottom node of P1 is the parent of the top node of P2.
We will show that we can perform those operations using our auxiliary trees in time \(O(1 + \log _{B} k)\), where k is the number of keys in the involved preferred paths. We defer this proof to the end of this section and we now proceed to the description and analysis of Belga B-trees, assuming that those operations can be done in time \(O(1 +\log _{B} k)\). For the rest of this section, whenever we refer to cutting/merging operations on auxiliary trees, we mean the implementation of cutting/merging the corresponding preferred paths in our B-tree data structure.
Our Algorithm
A Belga B-tree is a tree of auxiliary classic B-trees, where each auxiliary tree stores a preferred path. Initially we transform the input tree T0 into a valid Belga B-tree. Upon a request for a key xi, we start from the root and search for xi. Whenever we reach a marked node v (i.e. a root of an auxiliary tree), we have to update the preferred paths. Let Q be the preferred path stored in the auxiliary tree of the parent of v and R the preferred path in the auxiliary tree rooted at v. We update the preferred paths using the cut and merge operations of auxiliary trees. Particularly, if d is the minimum depth of a key of R (this value is stored at node v of our B-tree), we cut the auxiliary tree storing Q at depth d − 1. This gives us two preferred paths Qd− and Qd+, where the first stores keys of Q of depth at most d − 1 and the second keys of Q of depth at least d. We mark the roots of the auxiliary trees corresponding Qd− and Qd+. We then merge the auxiliary tree storing Qd− with the auxiliary tree rooted at v (which stores R). We mark the root of the new tree and continue the search for xi.
Note that the only part where our algorithm needs to perform rotations is the initial step of transforming the input tree into a Belga B-tree.
Bounding the Cost
We now compare the cost of our Belga B-tree data structure to that of the optimal offline B-tree. The following lemma makes the essential connection between the number of preferred paths touched during a search and the cost of our algorithm.
Lemma 2
Let ℓ be the number of preferred child changes during a search for key xi. Then the cost of Belga B-tree for searching xi is \(O((\ell +1)(1+\log _{B} \log N))\).
Proof
To search for xi, we touch exactly ℓ + 1 preferred paths. We account separately for the search cost and the update cost.
For each preferred path touched, the search cost is \(O(\lceil \log _{B} \log N \rceil )\), since we are searching a balanced B-tree on \(O(\log N)\) keys. Thus the total search cost is clearly \(O((\ell +1)(1+\log _{B} \log N))\).
We now account for the update cost. Recall that we can cut and merge preferred paths on k keys in time \(O(1 +\log _{B} k)\). Since each preferred path has at most \(O(\log N)\) keys, we can perform those updates in time \(O(1 +\log _{B} \log N)\). There are ℓ preferred path changes, and for each change we perform one cut and and one merge operation, we get that the total time for merging and cutting is \(O(\ell \cdot (1 +\log _{B} \log N))\). The lemma follows. □
We now combine this lemma with Corollary 2 to get the competitive ratio of Belga B-trees.
Theorem 3
For any search sequence of length m = Ω(N), Belga B-trees are \(O(\log \log N)\)-competitive.
Proof
We account only for the cost occurred during searches, since the cost of transforming the input tree into a Belga B-tree is just a fixed additive term which does not depend on the input sequence.
The total number of preferred path changes is at most IB(X) + N. The additive N accounts for the fact that initially each node has no preferred child, so its first change from null to either left or right is not counted in IB(X). Using Lemma 2 and summing up over all search requests, we get that the cost of Belga B-trees is \(O((\text {IB}(X)+N+m)(1+\log _{B} \log N))\). By our assumption on the value of B, we have that \(1 + \log _{B} \log N = O(\log _{B} \log N)\), thus the cost is in \(O((\text {IB}(X)+N+m) \cdot \frac {\log \log N}{\log B})\). By Lemma 1 this is bounded by \((\text {OPT}_{BST}(X)+N+m) \cdot \frac {\log \log N}{\log B} \). Using Corollary 2 we get that cost of Belga B-tree is
Note that for any request sequence OPTB-Tree ≥ m. Since m = Ω(N), we have that \( \log B \cdot \text {OPT}_{\text {B-Tree}} + N +m = O(\log B \cdot \text {OPT}_{\text {B-Tree}})\). We get that the total cost is upper bounded by
□
Operations on Auxiliary Trees in Logarithmic Time
We now show that our auxiliary B-trees support search, cut and merge in time \(O(1 + \log _{B} k)\), where k is the total number of nodes in the trees which are involved.
Before proceeding to this proof we note that classic B-trees on k nodes support search, split and concatenate (similar to the ones we presented in previous section for red-black trees) operations in time \(O(1 +\log _{B} k)\) (see [13], Chapter 18). For completeness we describe here the split and concatenate operations:
-
Splitting a B-tree at a key value x consists of creating a tree where the root contains only x, its left subtree is a B-tree on keys with value smaller than x and the right subtree is a B-tree on keys greater than x.
-
Concatenating two classic B-trees T1,T2 with a key value k such that all keys in T1 are smaller than k and all keys in T2 are greater, consists of creating a new classic B-tree T which contains all key values contained in T1,T2 and k.
Search can be clearly performed in time \(O(1 + \log _{B} k)\). We now describe the cut and merge operations on preferred paths.
- Cut a preferred path at depth d::
-
Let R be the tree storing the preferred path. Let ℓ and r be the smallest and the largest key value respectively stored at depth greater than d in the path. We wish to find ℓ and r in the tree R. This can be easily done using the maximum depth value of subtree stored in the nodes. We show how to find ℓ and for r is symmetric. Start from the root and move to the leftmost child whose maximum depth is greater than d. When we reach a node v such that all its children have maximum depth smaller than d, then ℓ is the smallest key in v with depth greater than d. Let \(\ell ^{\prime }\) predecessor of ℓ in R (if it has one) and \(r^{\prime }\) the successor of r in R (if it has one). Split R at \(\ell ^{\prime }\) (skip this step if \(\ell ^{\prime }\) does not exist) and then split the right subtree at \(r^{\prime }\) (skip this step if \(r^{\prime }\) does not exist). Now, the left subtree of \(r^{\prime }\) contains all keys with depth greater than d. Let us call this tree D. Mark the root of D (and change values of depths, max depth, min depth in time \(O(1+ \log _{B} k)\)) and then use concatenate operations at the tree rooted at \(r^{\prime }\) (if it exists) and then at the tree rooted at \(\ell ^{\prime }\) (if it exists) to make the remaining of R a valid classic B-tree.
Merge two preferred paths: Let P1 and P2 be the preferred paths that we want to merge, where the bottom node of P1 is the parent of the top node of P2. Merging is the inverse operation of a cut. Let U and V be the auxiliary trees storing P1 and P2 respectively, i.e., U is a parent of V in our tree-of-trees construction and the keys stored at U are of smaller depth than the keys stored in V. Pick a key from the root of V and find its predecessor ℓ and its successor r in U. Split U in ℓ (skip this step if ℓ does not exist) and then split the right subtree at r (skip this step if r does not exist). Now the left subtree of r is V. Unmark the root of V. Then, concatenate at r to get a resulting tree R which is the right subtree of the root ℓ (skip this step if r does not exist). Then, concatenate at ℓ (if it exists), to get a valid B-tree which contains all keys of U and V. In each of the last two steps (if not skipped), updates of the values of depth, maximum depth, minimum depth take time \(O(1 +\log _{B} k)\).
5 Transforming Any Static BST into the B-Tree Model
In this section we focus on static trees, with the goal to simulate a static BST using a static B-tree and achieving a speedup by a factor of \({\varTheta }(\log B)\). In the static BST and B-Tree models, all that is allowed in each operation is to move a single pointer around the tree, starting at the root, each time moving to a neighboring node, at unit cost per move. We refer to a sequence of moves of a single pointer as a walk. In particular, given a BST we wish to convert it to a B-Tree so that if a walk in the BST costs k, a walk in the B-Tree TB that touches the same keys costs as little as possible in terms of k; k is clearly possible since a BST is a B-tree, but when can we achieve o(k)?
We note that the results of this section allow the pointer to move arbitrarily in a static BST/B-tree, i.e., it can visit nodes that are outside the path from the root to the searched node. In the case where only a search path of length D is considered, the worst-case cost has been completely characterized in [17] as \({\varTheta } \left (\frac {D}{\lg (1{+}B)} \right )\) when \(D = O(\lg N), {\varTheta }\left (\frac {\lg N}{\lg \left (1{+}\frac {B \lg N}{D}\right )} \right )\), when \(D = {\varOmega }(\lg N)\) and \(D = O(B \lg N)\), and \({\varTheta }\left (\frac {D}{B} \right )\) when \(D = {\varOmega }(B \lg N)\).
Block-Connected Mappings
The most natural approach to achieve our goal is to try to map a static BST T into a static B-tree TB such that each node of TB corresponds to a connected subtree of T. We call such a mapping \(f: T \rightarrow T_{B}\), block-connected. Observe that in order to achieve a \({\varOmega }(\log B)\) speedup for the B-tree model TB, it is necessary that a block-connected mapping f should satisfy that every node at depth d in T is at depth \(O(\frac {k}{\log B})\) in TB. However, as we will see, this is not sufficient.
The next theorem shows that, perhaps surprisingly, this approach fails to give any super-constant factor improvement, given that the mapping is deterministic. Afterwards, we show how to achieve an \({\varOmega }(\log B)\) factor speedup using randomization.
Theorem 4
For every T and B there does not exist a block-connected mapping \(f: T \rightarrow T_{B}\) such that every walk E on T of length k corresponds to a walk of length o(k) in TB.
Proof
Assume an f and N = 2i − 1 for some integer i > 2B, and let T be the perfectly balanced tree with N nodes and thus \(\ell =\frac {N+1}{2}\) leaves. Consider some BST model sequence of operations E which is an inorder traversal of T which does not recurse when it encounters a node in the same block as a leaf of T. The path E traces out in T is a tree with no degree-1 nodes, and where each leaf is in a different block due to the block-connected requirement. Thus, the number of blocks visited by E is at least a constant fraction of its operations. Furthermore, E is of size \(\sqrt {N}\), since the height of the tree is at least 2B, no node in the top half of the tree is in a leaf block and thus E contains the entire top half of the tree. □
Randomized Construction
Theorem 4 above is based on an adversarial argument and relies crucially on the knowledge of the layout of the B-tree. To overcome this issue, we use randomization.
Theorem 5
For any BST T, there is a randomized block-connected mapping which produces a static B-tree TR such that for any walk of length k in T, there exists a corresponding walk in TR with expected cost \(O\left ({\frac {k}{\log B}} \right )\).
Proof
We construct the B-tree TR as follows. We choose uniformly at random an integer h in \([0,\lfloor \log B \rfloor -1 ]\). The root node of TR contains the key values of the first h levels of T. Then, we build the rest of the tree in a deterministic way, by storing \(\lfloor \log B \rfloor - 1\) levels of each subtree in a B-tree node, recursively.
Consider any walk P of k operations on T that starts at the root. We assume that the block containing the root and the current location of the walk are stored in memory. Whenever P passes through an edge e of T, the probability that this move corresponds to a unit cost operation equals the probability that the endpoints of e belong to different B-tree nodes in TR and equals \( 1/\lfloor \log B \rfloor \).
We thus obtain that the expected cost of the corresponding sequence of operations in in TR is \( k / \lfloor \log B \rfloor \). Since \(\lfloor \log B \rfloor = {\varOmega }(\log B)\) for any B ≥ 3, we get that the expected cost is \(O(\frac {k}{\log B})\). □
6 Open Problems
We conclude with some open problems. The first is that our Belga B-trees are \(O(\log \log N)\)-competitive only when \(B=\log ^{O(1)} N\), and thus the case of large B where \(B=\log ^{\omega (1)} N\) remains open. The main impediment is to figure out how to fit multiple preferred paths into one block.
A more general open problem is to resolve the following conjecture: Is it possible to convert any BST-model algorithm into a B-Tree model algorithm such that if an algorithm costs O(k) in the BST model, it costs \(O(\frac {k}{\log B}+1)\) in the B-Tree model? Special cases of this theorem, when applied to, for example, splay trees and greedy future, would also be interesting.
A third open problem is whether, given two B-tree model algorithms, can you achieve the runtime that is the minimum of them; this would be the B-Tree model analogue of the BST result of [16]. It would also allow one to then combine Belga B-trees with other B-tree model algorithms to get stronger results, like, for example [5] to add the working-set bound; in the BST model [30] gave a \(O(\log \log N)\)-competitive BST with the working set bound.
Notes
The Tango tree was invented on an overnight flight from JFK airport en route to Buenos Aires, Argentina. The work on the Belga B-Tree has been substantially completed at Cafe Belga, Ixelles, Belgium.
Recall that in the external memory model (defined in Section 1) B denotes the block size. Each B-tree node has at most B children, contains O(B) words and thus it can be stored in O(1) blocks of size B.
References
Adelson-Velskiı̆, G.M., Landis, E.M.: An algorithm for organization of information. Dokl. Akad. Nauk SSSR 146, 263–266 (1962)
Aggarwal, A., Vitter, J.S.: The input/output complexity of sorting and related problems. Commun. ACM 31(9), 1116–1127 (1988). https://doi.org/10.1145/48529.48535
Badoiu, M., Cole, R., Demaine, E.D., Iacono, J.: A unified access bound on comparison-based dynamic dictionaries. Theor. Comput. Sci. 382(2), 86–96 (2007). https://doi.org/10.1016/j.tcs.2007.03.002
Bayer, R., McCreight, E.M.: Organization and maintenance of large ordered indices. Acta Inf. 1, 173–189 (1972). https://doi.org/10.1016/j.tcs.2007.03.002
Bose, P., Douïeb, K., Langerman, S.: Dynamic optimality for skip lists and b-trees. In: Symposium on Discrete Algorithms, SODA. http://dl.acm.org/citation.cfm?id=1347082.1347203, pp 1106–1114 (2008)
Bose, P., Douïeb, K., Iacono, J., Langerman, S.: The power and limitations of static binary search trees with lazy finger. Algorithmica 76(4), 1264–1275 (2016). https://doi.org/10.1007/s00453-016-0224-x
Bose, P., Howat, J., Morin, P.: A history of distribution-sensitive data structures. In: Brodnik et al. [8], 133–149. https://doi.org/10.1007/978-3-642-40273-9_10
Brodnik, A., López-Ortiz, A., Raman, V., Viola, A. (eds.): Space-Efficient Data Structures, Streams, and Algorithms - Papers in Honor of J. Ian Munro on the Occasion of His 66th Birthday, Lecture Notes in Computer Science, vol. 8066. Springer, Berlin (2013). https://doi.org/10.1007/978-3-642-40273-9
Chalermsook, P., Goswami, M., Kozma, L., Mehlhorn, K., Saranurak, T.: The landscape of bounds for binary search trees. CoRR arXiv:1603.04892 (2016)
Chalermsook, P., Goswami, M., Kozma, L., Mehlhorn, K., Saranurak, T.: Multi-finger binary search trees. In: 29th International Symposium on Algorithms and Computation, ISAAC. https://doi.org/10.4230/LIPIcs.ISAAC.2018.55, pp 55:1–55:26 (2018)
Cole, R.: On the dynamic finger conjecture for splay trees. Part II: the proof. SIAM J. Comput. 30(1), 44–85 (2000). https://doi.org/10.1137/S009753979732699X
Cole, R., Mishra, B., Schmidt, J.P., Siegel, A.: On the dynamic finger conjecture for splay trees. Part I: splay sorting log n-block sequences. SIAM J. Comput. 30(1), 1–43 (2000). https://doi.org/10.1137/S0097539797326988
Cormen, T.H., Leiserson, C.E., Rivest, R.L., Stein, C.: Introduction to Algorithms, 3rd edn. MIT Press, Cambridge (2009). http://mitpress.mit.edu/books/introduction-algorithms
Demaine, E.D., Harmon, D., Iacono, J., Patrascu, M.: Dynamic optimality—almost. SIAM J. Comput. 37(1), 240–251 (2007). https://doi.org/10.1137/S0097539705447347
Demaine, E.D., Harmon, D., Iacono, J., Kane, D.M., Patrascu, M.: The geometry of binary search trees. In: Symposium on Discrete Algorithms, SODA. http://dl.acm.org/citation.cfm?id=1496770.1496825, pp 496–505 (2009)
Demaine, E.D., Iacono, J., Langerman, S., Özkan, Ö.: Combining binary search trees. In: ICALP 2013, Part I. https://doi.org/10.1007/978-3-642-39206-1_33, pp 388–399 (2013)
Demaine, E.D., Iacono, J., Langerman, S.: Worst-case optimal tree layout in external memory. Algorithmica 72(2), 369–378 (2015). https://doi.org/10.1007/s00453-013-9856-2
Elmasry, A., Farzan, A., Iacono, J.: On the hierarchy of distribution-sensitive properties for data structures. Acta Inf. 50(4), 289–295 (2013). https://doi.org/10.1007/s00236-013-0180-8
Guibas, L.J., Sedgewick, R.: A dichromatic framework for balanced trees. In: Foundations of Computer Science (FOCS). https://doi.org/10.1109/SFCS.1978.3, pp 8–21 (1978)
Howat, J., Iacono, J., Morin, P.: The fresh-finger property. CoRR arXiv:1302.6914 (2013)
Iacono, J.: Alternatives to splay trees with o(log n) worst-case access times. In: Symposium on Discrete Algorithms (SODA). http://dl.acm.org/citation.cfm?id=365411.365522, pp 516–522 (2001)
Iacono, J.: Distribution sensitive data structures. Ph.D. thesis, Ph.D. Thesis. Rutgers The State University of New Jersey (2001)
Iacono, J.: In pursuit of the dynamic optimality conjecture. In: Brodnik et al. [8], 236–250. https://doi.org/10.1007/978-3-642-40273-9_16
Iacono, J., Langerman, S.: Weighted dynamic finger in binary search trees. In: Symposium on Discrete Algorithms, SODA. https://doi.org/10.1137/1.9781611974331.ch49, pp 672–691 (2016)
Lucas, J.M.: Canonical forms for competitive binary search tree algorithms. Tech. Rep. DCS-TR-250 Rutgers University (1988)
Sherk, M.: Self-adjusting k-ary search trees. J. Algorithms 19(1), 25–44 (1995). https://doi.org/10.1006/jagm.1995.1026
Sleator, D.D., Tarjan, R.E.: Amortized efficiency of list update and paging rules. Commun. ACM 28(2), 202–208 (1985). https://doi.org/10.1145/2786.2793
Sleator, D.D., Tarjan, R.E.: Self-adjusting binary search trees. J. ACM 32(3), 652–686 (1985). https://doi.org/10.1145/3828.3835
Tarjan, R.E.: Sequential access in play trees takes linear time. Combinatorica 5 (4), 367–378 (1985). https://doi.org/10.1007/BF02579253
Wang, C.C., Derryberry, J., Sleator, D.D.: O(log log n)-competitive dynamic binary search trees. In: Symposium on Discrete Algorithms, SODA. http://dl.acm.org/citation.cfm?id=1109557.1109600, pp 374–383 (2006)
Wilber, R.E.: Lower bounds for accessing binary search trees with rotations. SIAM J. Comput. 18(1), 56–67 (1989). https://doi.org/10.1137/0218004
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
SpringerNature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article belongs to the Topical Collection: Special Issue on Computer Science Symposium in Russia (2019)
Guest Editor: Gregory Kucherov
This work was supported by the Fonds de la Recherche Scientifique-FNRS under Grant no MISU F 6001 1 and by NSF Grant CCF-1533564.A preliminary version of this article appeared in the Proceedings of the 14th International Computer Science Symposium in Russia (CSR 2019).
Rights and permissions
About this article

Cite this article
Demaine, E.D., Iacono, J., Koumoutsos, G. et al. Belga B-Trees. Theory Comput Syst 65, 541–558 (2021). https://doi.org/10.1007/s00224-020-09991-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00224-020-09991-8