
Abstract
Human information processing is incredibly fast and flexible. In order to survive, the human brain has to integrate information from various sources and to derive a coherent interpretation, ideally leading to adequate behavior. In experimental setups, such integration phenomena are often investigated in terms of cross-modal association effects. Interestingly, to date, most of these cross-modal association effects using linguistic stimuli have shown that single words can influence the processing of non-linguistic stimuli, and vice versa. In the present study, we were particularly interested in how far linguistic input beyond single words influences the processing of non-linguistic stimuli; in our case, environmental sounds. Participants read sentences either in an affirmative or negated version: for example: “The dog does (not) bark”. Subsequently, participants listened to a sound either matching or mismatching the affirmative version of the sentence (‘woof’ vs. ‘meow’, respectively). In line with previous studies, we found a clear N400-like effect during sound perception following affirmative sentences. Interestingly, this effect was identically present following negated sentences, and the negation operator did not modulate the cross-modal association effect observed between the content words of the sentence and the sound. In summary, these results suggest that negation is not incorporated during information processing in a manner that word–sound association effects would be influenced.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The human brain is the most flexible information processing system we know. In order to survive, the human brain is incredible fast in integrating information from various sources and in deriving a coherent interpretation of the meaning of a given situation (Mesulam, 1998). A key challenge therefore is that identical input can have various interpretations across different contexts. Therefore, humans are able to interpret incoming information more flexibly than basic reflexive systems, leading to adequate behavior, which in critical situations can result in crucial survival benefits.
In experimental setups, such integration phenomena are often investigated in terms of cross-modal association effects. How does a stimulus from the visual domain influence the processing of an auditory stimulus (e.g., Schneider, Debener, Oostenveld, & Engel, 2008)? How does a linguistic stimulus influence the processing of a visual stimulus, etc. (e.g., Sperber, McCauley, Ragain, & Weil, 1979)? Interestingly, up to now, most of these cross-modal association effects using linguistic stimuli have shown that single words can influence the processing of non-linguistic stimuli and vice versa. In the present study, we are particularly interested in how far linguistic input beyond single words influences the processing of non-linguistic stimuli; in our case, environmental sounds.
Environmental sounds are generated by real events in our everyday life; this could be, for example, the sound of a cat meowing or a train leaving a railway station (Ballas & Howard, 1987). Researchers have argued that environmental sounds share various features with human language. On a basic level, just like speech, the stream of incoming environmental sounds needs to be segregated in order to recover its individual components and their sources. Some authors even propose a language-like “parsing” mechanism to be at work which follows learned rules in order to achieve this goal of segregation (Bregman, 1981). Additionally, sound processing is not only driven by bottom–up processes but is also subject to top–down influences, such as expectations in specific contexts (Gygi & Shafiro, 2011). Most importantly, it has been suggested that environmental sound perception is guided by the sub-ordinate aim to interpret the semantics of the sounds, which would typically be the identification of a sound’s source (Ballas & Howard, 1987). In addition, several studies have suggested that auditory events—such as environmental sounds but also music—influence the neurophysiological markers of semantic processing in a similar way to language (e.g., Koelsch et al., 2004; Schirmer et al., 2011).
In recent years, various influences on environmental sound processing have been investigated. Specifically, manifold cross-modal priming effects have been demonstrated both from linguistic stimuli and from pictorial stimuli on environmental sound processing (e.g., Cummings et al., 2006), and vice versa. In line with the assumption that environmental sounds are processed in a language-like manner, it has been shown that mismatches between word–sound pairs influence both behavioral and electrophysiological markers. With regard to electroencephalogram (EEG) studies, it has been shown that mismatching stimulus pairs result in larger N400-like effects, an event-related potential (ERP) component that is typically taken to reflect semantic association and word expectancy (Kutas & Hillyard, 1984). Interestingly, these N400-like effects are usually bi-directional, from environmental sound primes to words, but also when using words as primes and measuring EEG activity during environmental sound processing. Such ERP-effects were first demonstrated by Van Petten and Rheinfelder (1995). In either case—sounds following words and words following sounds—there was an enlarged N400-like effect if the two stimuli did not match. Orgs, Lange, Dombrowski, and Heil (2006, 2007, 2008) replicated these findings and also showed enlarged N400-like effects in the case of a mismatch between a word and a subsequent sound. In addition, Orgs et al. (2007, 2008) manipulated the task condition from a low-level detection task (on which ear was a sound played?) to a task that required semantic processing of the two stimuli (did the word and the sound match?). Interestingly, the results showed compatibility effects across all task levels, suggesting that environmental sounds are conceptually processed irrespective of the specific task conditions, and that sound meaning is accessed automatically. In the studies described so far, however, it cannot be excluded that the effects of words on sound processing are linguistically mediated, meaning that participants internally label the environmental sounds early on during sound processing. Therefore, the above reported N400-like effects during sound processing might be attributed to labeling processes. Schön, Ystad, Kronland-Martinet, and Besson (2010) aimed at ruling out this explanation and used specially created acousmatic sounds. Despite these sounds being created in way that reduced the possibility of labeling the sounds according to their sources, the authors reported N400-like conceptual priming effects in both directions. Therefore, it seems unlikely that N400-like effects produced by environmental sounds are merely due to linguistic labeling processes.
Despite various similarities in the processing of language and environmental sounds, there are also clear dissociations between linguistically-driven N400 effects and sound-driven N400 effects. For example, Hendrickson, Walenski, Friend, and Love (2015) investigated the N400 effect elicited by picture–word and picture–sound pairs. Both combinations showed larger N400 amplitudes in the mismatch than match conditions; however, it was only for the picture–word pairs that N400 effects were incrementally enlarged by the semantic distance between the picture and the word. The absence of such a semantic distance effect in N400 amplitude for picture–sound pairs might suggests that environmental sound representations are less fine-grained. Various studies have also investigated whether there are differences regarding the topographic distribution of linguistic and non-linguistic N400 components, a debate that is still ongoing. For example, Gallagher et al. (2014) showed a topographic dissociation between the linguistic and the non-linguistic N400 effects. Specifically, linguistic N400 effects are typically associated with generators in the left superior temporal gyrus. In contrast, non-linguistic N400 effects were associated with right middle and superior temporal gyri. The authors concluded that similar processes are involved in detecting matches or mismatches in linguistic and non-linguistic processes. However, they also suggested that these processes take place in different brain areas. Frey, Aramaki, and Besson (2014) were also interested in a topographic comparison and investigated conceptual priming effects for sounds and words. They compared sound–sound, word–sound, word–word, and sound–word conditions. All conditions showed significant priming effects both in RTs (faster for conceptually related targets) and the N400 (smaller for conceptually related targets), both in explicit and implicit tasks. However, there were differences in scalp topography between the linguistic and the sound condition—with the N400 to auditory events being more frontally distributed compared to the centro-parietal N400 during linguistic processing—suggesting that there are slight differences in the integration process. Cummings et al. (2006) also investigated the differences between lexical processing in the brain and the processing of meaningful environmental sounds. They used pictures to prime words, environmental sounds, and non-meaningful sounds. The results showed clear N400 effects for both words and meaningful environmental sounds as targets, while there were only slight topographic and timing differences, suggesting that largely overlapping neural networks underlie the processing of verbal and non-verbal semantic information. The authors also found slightly earlier N400 mismatch peaks in the environmental sound condition, suggesting that semantic processing of environmental sounds might proceed faster as compared to words.
Most studies have so far focused on priming effects by single words on environmental sounds. Hence, little is known about the processing of environmental sounds following linguistic input in terms of sentences. When using pictures instead of sounds as targets, Nigam, Hoffman, and Simons (1992) showed that sentences influence subsequent picture processing in a similar manner as words (see also Ganis, Kutas, & Sereno, 1996). Specifically, the authors compared “normal sentences” and “anomalous sentences”. The normal sentences ended with a matching word or a matching picture (e.g., ‘socks’ or a picture of socks after ‘I can never find a pair of matching’). The “anomalous sentences” ended with a mismatching word or a mismatching picture (e.g., ‘sock’ or a picture of a sock after ‘I ate an apple and a’). Both endings produced comparable N400 effects, suggesting that the N400 is an electrophysiological marker of conceptual processing of both pictures and words. In the auditory domain, Brunyé, Ditman, Mahoney, Walters, and Taylor (2010) to our knowledge were the first to investigate the influence of sentences on sound processing. Participants had to determine whether sounds were real sounds (i.e. occurring in a natural environment) or fake sounds (i.e. computer-generated). Before each sound, participants read either a matching or a mismatching sentence. The sentences were for example ‘The campfire crackled as the kids prepared for storytime’ or ‘The waves crashed against the beach as the tide began to rise’. Participants were faster to categorize sounds as real sounds if the sounds were preceded by a matching sentence. The authors concluded that participants perform mental simulations of the linguistically described situation, which subsequently supports sound identification. Despite the use of sentential materials, it remains an open issue whether the observed priming effects occur on a sentential level or are rather driven by single words, since this study did not control for possible influences from single words (e.g., the single word ‘waves’ might already prime the sound of waves). A similar limitation applies to a recent study in which we investigated whether effects from sentences on sound processing are comparable to sensory priming between physical sounds—as suggested by the mental simulation account— or are mediated on a conceptual level (Dudschig, Mackenzie, Strozyk, Kaup, & Leuthold, 2016a). In that study, we used simple sentences (e.g., ‘The dog barks’) and investigated the effects on the processing of subsequent environmental sounds. Indeed, as in previous studies, we found N400-like priming effects, and dipole source localization of the match–mismatch N400 effect pointed to its origin in the inferior temporal cortex, clearly dissociated from auditory N400 priming effects originating in the superior temporal cortex. Thus, we concluded that the priming effect of the sentences on environmental sounds is driven rather by conceptual than sensory processes. However, this study was not designed to investigate sentence versus word-based effects, and leaves open in how far the reported effects indeed reflect sentence-level effects or are rather word-based, with the latter reflecting for instance that the word ‘bark’ or the word ‘dog’ activates aspects of a barking sound, independent of sentence meaning. Why would it be of interest to find out whether the reported priming effects are word- or sentence-based? Most importantly, different conclusions would have to be drawn with respect to the question as to which kind of linguistic representations are involved in the associations underlying the priming effect. Word-based effects could reflect associations between particular words in the mental lexicon and particular aspects of auditory experiences. These associations potentially arise from Hebbian learning (Hebb, 1949) via repeated experiences of processing the word and the sound at the same time (e.g., Öttl, Dudschig, & Kaup, 2017). In contrast, true sentence-based effects cannot be explained in this way. Sentence-based priming effects, reflecting meaning aspects that cannot be attributed to individual words in the sentence, must involve linguistic representations in working memory that result from meaning composition processes that take into account the meanings of the words in the sentence as well as their syntactic relation, computing meaning at the sentence level (Frege, 1892). Thus, whereas word-based effects might be based on stored word–sound associations in long-term memory, true sentence-based effects must reflect more flexible working memory processes. These considerations directly lead to the aim of the current study. Here, we implement sentential negation in order to investigate whether priming effects measured on environmental sounds are mediated by high-level sentence processing. For this purpose, we introduced clear sentence meaning differences by using a negation operator. Interestingly, negation is a linguistic operator that allows the changing of the meaning of the sentences without changing any of the content words in the sentences. Therefore, using sentences in the negated and the affirmative version allows directly disentangling word-based from sentence-based effects. If the effects are based on the content words of the sentence, a sentence such as ‘The dog does not bark’ should yield the same results as ‘The dog barks’. However, if the effects are sentence-based then the two sentences should differ with respect to the priming of a barking sound. In the affirmative version, the meaning of the sentence is compatible with a barking sound and should therefore prime it whereas in the negative version, the meaning of the sentence is not compatible with a barking sound and should therefore not prime it. Please note, that this the case even if the word ‘dog’ is associated with a barking sound.
In studies investigating negation integration during sentence comprehension, it has been suggested that negation is typically rather hard to integrate in the comprehension process (e.g., Fischler et al., 1983). Thus, affirmative false sentence endings elicited a larger N400 than affirmative true sentence endings (e.g., ‘A bee is a tree vs. insect’). However, this N400 effect was reversed in negative sentences, resulting in a larger N400 in the true than the false condition (e.g., ‘A bee is not a tree vs. insect’). These findings suggest that a word-based semantic mismatch between the relevant terms rather than high-level sentence processing influence the size of the N400 measured on the last word of the sentence. Recently, a prediction-based N400 model has been proposed. According to this model, under conditions of high predictability, the N400 is reduced—almost independent of whether or not the sentence contains a negation operator (e.g., Nieuwland, 2016; Nieuwland & Kuperberg, 2008; Nieuwland & Martin, 2012). Additionally, other negation comprehension models suggested that negation integration does take place and is only fully integrated after sentence completion (e.g., Kaup, Lüdtke, & Zwaan, 2006). Interestingly, to our knowledge, to date, no study has directly investigated whether cross-model association effects are influenced by linguistic negation. Here we use the sentences from Dudschig et al. (2016a) but this time in an affirmative [e.g., Der Hund bellt jetzt (the dog barks now)] and negated version [e.g., Der Hund bellt nicht (the dog does not bark)]. If the cross-modal priming effect is modulated by sentential meaning differences, we expect the N400 match–mismatch effect to be modified by the negation operator. In contrast, if language-sound priming takes place on the word-level, we again expect to observe the word-sound priming effect as previously reported on the N400 (e.g., Dudschig et al., 2016a), but no modification of this N400 priming effect by the negation operator.
Methods
Participants
Eighteen German native, right-handed participants took part (M age = 22.67, SD age = 3.34, 10 female). Participants gave informed consent and were reimbursed (credit points or money, €8/h).
Stimuli
We used the original 80 German sentences from Dudschig et al. (2016a) in an affirmative and a negated version [e.g., Die Katze miaut jetzt/nicht (the cat meows now/not), Die Tür quietscht jetzt/nicht (The door squeals now/not)], resulting in a total of 160 sentences. We also used the original 80 sounds and a conceptually identical set of 80 sounds in order to avoid target repetitions (sampled rate 44.1 kHz, 16-bit mono wav files, 500 ms length; see also Shafiro & Gygi, 2004). Additional processing steps were the normalization (maximum amplitude 1.0 dB), DC offset removal and the application of a 5-ms fading-in and fading-out interval.
Procedure
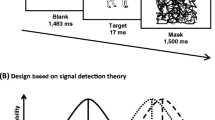
The experiment was programmed using MATLAB/Psychtoolbox 3.0.10. The stimuli were displayed in black on a white background [21in. (c.53.3-cm) CRT-monitor, 1280 × 960, 60 Hz]. Each trial started with a 750-ms fixation cross. Sentences were presented centrally word by word. Words were displayed for 300 ms separated by a 200-ms blank screenFootnote 1. After the last word, a 700-ms blank interval was followed by the sound presentation via headphones (Sennheisser-PX-100-ii). Following sound offset, there was a 2000-ms blank interval after which the response screen was displayed. The response screen indicated which key to press in the case of a match or mismatch between the sound and the previous sentence. Participants responded using left (x) and right (n) keys of a German qwertz keyboard. The key-to-response assignment (x → fit and n → no-fit versus vice versa) was random in each trial to avoid anticipatory response preparation. The task was chosen to maximize the potential influence of the negation operator on the N400 effects. That is, in order to perform the task correctly, participants had to take into account both the sentence and the sound information. Specifically, for affirmative sentences (e.g. ‘The dog barks now’) in a match condition a WOOF sound was played (response: fit), and, for example, a MEOW sound for the mismatch (response: no-fit). In the negated condition, participants were instructed to respond by pressing the fit and no-fit button in the following manner: ‘The dog does not bark’ followed by WOOF → no-fit; ‘The dog does not bark’ followed by MEOW → fit. This procedure first ensured that the two responses occurred equally often and second that the negation operator itself had to be processed in order to perform the task correctly. Participants could not perform the task correctly merely on the basis of word-level associations (e.g., only processing the information provided by the content noun of the sentence—for example ‘dog’—and the subsequent sound—for example, WOOF—was not sufficient to perform the task correctly). The experimental conditions resulting from the combination of affirmative and negated sentences and the sounds are summarized in Table 1. Participants performed four experimental blocks of 80 trials and saw each sentence in a match and mismatch assignment, with the restriction that sentences did not repeat within a block and that identical sentences only re-occurred after an intermediating block. Across participants, each tone was presented equally often in an affirmative and in a negated match and mismatch condition, ensuring that differences between conditions cannot be explained by low-level sound differences.
Electrophysiological recording and analysis
Electrophysiological recording
Electroencephalographic (EEG) activity was sampled at 512 Hz from 72 Ag/AgCl electrodes. EEG/ERP analysis was performed using MATLAB toolboxes (Delorme & Makeig, 2004; Oostenveld et al., 2011) and custom MATLAB scripts (see Dudschig et al., 2016a). The analysis epoch started 1 s prior to sound onset lasting 2.5 s.
Statistical analysis
The ERPs in a posterior (P1, Pz, P2, CP1, CPz, CP2) and anterior (C1, Cz, C2, FC1, FCz, FC2) region of interest (ROI) were calculated in the N1 (80–110 ms), the P2 (180–220 ms), the N400 (300–500 ms) and two late time windows (600–800 ms and 800–1000 ms) and aligned to a 100-ms baseline prior to sound onset. A repeated measures ANOVA with the factors sentence type (affirmative vs. negated), compatibility (match vs. mismatch) and ROI (anterior vs. posterior) was conducted. As we were interested in the modulation of the N400 match–mismatch effect by the sentence type, the factor compatibility was determined by the match between the sentences’ noun/verb information and the sound.
Results
Behavioral results
Participants responded correctly in 93.37% of the trials. An ANOVA with the factor sentence type (affirmative vs. negated) and compatibility (match vs. mismatch) of error rates showed a main effect of sentences type, F(1,17) = 19.52, p < .001, ηp 2 = .53, due to more correct responses for affirmative than negated sentences (M aff = 95.03%, M neg = 91.70%). Additionally, there was a main effect of compatibility, F(1,17) = 11.41, p < .01, ηp 2 = .40, participants responded more accurately in the mismatch than in the match condition (M m = 91.46%, M mm = 95.28%). This seems surprising, but is probably due to a conservative strategy by the participants regarding the sounds that they classified as match. There was no interaction between sentence type and compatibility, F < 1.
Electrophysiological results
The sound elicited ERP waveforms are displayed in Fig. 1, and the ANOVA results are summarized in Table 2. Here, we will summarize the significant results. There were no significant effects in the N1 analysis window. In line with previous studies, the compatibility effect was significant in the P2 time window (180–220 ms), F(1,17) = 9.75, p < .01, ηp 2 = .36 (M m = 3.43 μV, M mm = 2.94 μV). Additionally, there was an effect of ROI, F(1,17) = 9.50, p < .01, ηp 2 = .36 (M a = 3.88 μV, M p = 2.49 μV). The compatibility effect persisted in the N400 time window, F(1,17) = 14.44, p < .01, ηp 2 = .46 (M m = 0.76 μV, M mm = –0.28 μV). Again there was an effect of ROI, F(1,17) = 29.44, p < .001, ηp 2 = .63 (M a = –0.63 μV, M p = 1.1 μV). The compatibility effect interacted with ROI, F(1,17) = 11.41, p < .01, ηp 2 = .40, due to a larger compatibility effect over posterior electrodes (M pDIFF = 1.40 μV, M aDIFF = 0.69 μV). Additionally, there was an effect of sentence type, F(1,17) = 4.75, p < .05, ηp 2 = .22, due to more positive ERP deflection in the affirmative cases (M aff = 0.39 μV, M neg = 0.09 μV). In the 600–800 ms time window, there was still a compatibility effect, F(1,17) = 4.80, p < .05, ηp 2 = .22 (M m = 1.37 μV, M mm = 0.90 μV), as well as an effect of ROI, F(1,17) = 78.11, p < .001, ηp 2 = .82 (M a = -0.82 μV, M p = 3.09 μV). Interestingly, the compatibility effect now interacted with sentence type and ROI, F(1,17) = 4.71, p < .05, ηp 2 = .22, due to an increased compatibility effect in the affirmative condition for the anterior ROI (M aDIFF = 0.97 μV) compared to the posterior ROI (M pDIFF = 0.46 μV) but no such topographic modulation in the negated condition (M aDIFF = 0.10 μV , M pDIFF = 0.34 μV). In the latest time window (800–1000 ms), there was still a small compatibility effect, F(1,17) = 4.70, p < .05, ηp 2 = .22 (M m = 0.49 μV, M mm = 0.15 μV), and again a significant effect of ROI, F(1,17) = 68.46, p < .001, ηp 2 = .80 (M a = -1.42 μV, M p = 2.06 μV).

Upper Grand mean ERP waveforms at electrodes FC1, FCz, FC2, CP1, CPz, CP2, P1, Pz, P2. Lower Topographic distribution of the mismatch minus match ERP activity across the different analysis time windows for the affirmative (upper row) and the negated (lower row) sentences
Discussion
Cross-modal priming has been investigated across various modalities. Here, we investigated whether linguistic stimuli prime auditory sounds beyond the single word level. Specifically, we were interested whether priming of environmental sounds is purely driven by semantic associations between the sound and the previous content words in the sentence or whether higher-level sentence meaning modifications—introduced by a negation operator—are reflected in the match–mismatch effect. In line with previous studies (e.g., Orgs et al., 2006; Van Petten & Rheinfelder, 1995), we found significant N400-like effects with more negative amplitudes in the case of mismatches between the content words of the sentences and the sounds. This match–mismatch effect started to develop in the P2 time interval and persisted until 1000 ms after sound onset.
With regard to our main research question, this match–mismatch effect was not modulated by the use of a negation operator, neither in the early nor in the critical time intervals of interest (P2, N400), which are typically regarded to measure semantic fit. This is quite surprising given the fact that the sentence meaning in the negated version expresses the opposite of the sentence in the affirmative condition. Behavioral studies have shown that sounds embedded in incoherent contexts (e.g., rooster crowing in a hospital) are often processed faster than in coherent contexts (Gygi & Shafiro, 2011), a finding that has been attributed to the sensitivity of the auditory system to unexpected events. Therefore, one could have assumed that the negation operator changes sound processing towards the processing of a more unexpected event. However, the results do not provide any evidence for early changes in sound processing. On the other hand, our findings are fully in line with findings regarding purely linguistic N400 effects, showing that, within sentences, negation does not influence these effects (Fischler et al., 1983) unless the critical word is highly predictable (e.g., Nieuwland, 2016).
Interestingly, our study also showed that, at the later time interval, ranging from 600 ms to 800 ms, the compatibility effect started to interact with sentence type and ROI. Here, the compatibility effect clearly dissociated between the negated and the affirmative condition. Specifically in the affirmative condition, the compatibility effect was more pronounced for the anterior ROI, whereas, in the negation condition, the compatibility effect was about to slowly decay. This rather late influence of negation on the compatibility effect might be due to various causes which would need to be disentangled in further studies. One of the simplest explanations might be that this is a basic task-driven effect, as participants start to prepare for the upcoming classification of the sound as a match versus mismatch, and this task might be more demanding in the case of the negation condition. Another possibility is that the late dissociation between the affirmative and the negation condition results from differences regarding the ease of the anticipation of the upcoming response signal (Van Boxtel & Böckler, 2004). Finally, one might speculate that the anterior N400 in the affirmative condition relates to the N700 concreteness effect previously reported by West and Holcomb (2000). According to this idea, and in line with the simulation view of language comprehension, participants might engage in a mental simulation process that ultimately contributes to comprehension. As the simulation involved in the affirmative condition is presumably more concrete or less complex than in the negated condition, this would also accord with the present differential anterior N400 effect.
In summary, our study clearly shows that a negation operator in a priming sentence does not influence the processing of a subsequent environmental sound. Therefore, we can conclude that language–sound priming effects observed on sounds are typically driven by semantic associations between the content words in the sentence (e.g., ‘dog’ or ‘bark’) rather than changes in higher-level sentence meaning introduced by the negation. It is important to note that these findings might be specific to changes in sentence-level meaning introduced by negation and do not generalize to other ways of changing sentence meaning. Indeed, it is well known that negation is an effortful and resource-demanding cognitive process and therefore typically is found to be rather hard to integrate instantly during comprehension (e.g., Dudschig & Kaup, 2017). Future studies will be needed in order to address the question whether other types of linguistic expressions that change meaning at the sentence-level, as for instance quantifiers, impact cross-modal priming effects more directly.
Notes
We chose word-by-word presentation in order to avoid artefacts resulting from head or eye movements. As a reviewer pointed out to us, word-by-word presentation might emphasize word-level processing over holistic sentence-level processing. Indeed, there are studies pointing towards different types of reading strategies involved depending on word-by-word versus more natural sentence presentation (e.g., Metzner et al. 2017). However, to our knowledge, word- versus sentence-level N400 effects have not yet been shown to be qualitatively influenced by presentation type (i.e. similar N400 effects despite different presentation types: Dudschig, Maienborn, & Kaup, 2016b ; Hagoort et al. 2004; Metzner et al. 2015). Still, future studies would be needed to address whether, in the paradigm used in the current study, presentation type impacts on word-level and sentence-level processing.
References
Ballas, J. A., & Howard Jr, J. H. (1987). Interpreting the language of environmental sounds. Environment and Behavior, 19(1), 91-114.
Bregman, A. S. (1981). Chomsky without language. Cognition, 10(1), 33-38.
Brunyé, T. T., Ditman, T., Mahoney, C. R., Walters, E. K., & Taylor, H. A. (2010). You heard it here first: Readers mentally simulate described sounds. Acta Psychologica, 135(2), 209-215.
Cummings, A., Čeponienė, R., Koyama, A., Saygin, A. P., Townsend, J., & Dick, F. (2006). Auditory semantic networks for words and natural sounds. Brain Research, 1115(1), 92-107.
Delorme, A., & Makeig, S. (2004). EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. Journal of Neuroscience Methods, 134(1), 9–21.
Dudschig, C., & Kaup, B. (2017). How does “not left” become “right”? Electrophysiological evidence for a dynamic conflict-bound negation processing account. Journal of Experimental Psychology: Human Perception and Performance. https://doi.org/10.1037/xhp0000481.
Dudschig, C., Mackenzie, I. G., Strozyk, J., Kaup, B., & Leuthold, H. (2016a). The sounds of sentences: Differentiating the influence of physical sound, sound imagery, and linguistically implied sounds on physical sound processing. Cognitive, Affective, & Behavioral Neuroscience, 16(5), 940-961.
Dudschig, C., Maienborn, C., & Kaup, B. (2016b). Is there a difference between stripy journeys and stripy ladybirds? The N400 response to semantic and world-knowledge violations during sentence processing. Brain and Cognition, 103, 38-49.
Fischler, I., Bloom, P. A., Childers, D. G., Roucos, S. E., & Perry, N. W. (1983). Brain potentials related to stages of sentence verification. Psychophysiology, 20(4), 400-409.
Frege, G. (1892). Über Sinn und Bedeutung. Zeitschrift fÜr Philosophie und philosophische Kritik, 100, 25–50.
Frey, A., Aramaki, M., & Besson, M. (2014). Conceptual priming for realistic auditory scenes and for auditory words. Brain and Cognition, 84(1), 141-152.
Gallagher, A., Béland, R., Vannasing, P., Bringas, M. L., Sosa, P. V., Trujillo-Barreto, N. J., …, Lassonde, M. (2014). Dissociation of the N400 component between linguistic and non-linguistic processing: A source analysis study. World Journal of Neuroscience, 4(01), 25–39.
Ganis, G., Kutas, M., & Sereno, M. I. (1996). The search for “common sense”: An electrophysiological study of the comprehension of words and pictures in reading. Journal of Cognitive Neuroscience, 8(2), 89-106.
Gygi, B., & Shafiro, V. (2011). The incongruency advantage for environmental sounds presented in natural auditory scenes. Journal of Experimental Psychology: Human Perception and Performance, 37(2), 551-565.
Hagoort, P., Hald, L., Bastiaansen, M., & Petersson, K. M. (2004). Integration of word meaning and world knowledge in language comprehension. Science, 304(5669), 438-441.
Hebb, D. O. (1949). The Organization of Behavior. A neuropsychological theory. New York: John Wiley & Sons.
Hendrickson, K., Walenski, M., Friend, M., & Love, T. (2015). The organization of words and environmental sounds in memory. Neuropsychologia, 69, 67-76.
Kaup, B., Lüdtke, J., & Zwaan, R. A. (2006). Processing negated sentences with contradictory predicates: Is a door that is not open mentally closed?. Journal of Pragmatics, 38(7), 1033-1050.
Koelsch, S., Kasper, E., Sammler, D., Schulze, K., Gunter, T., & Friederici, A. D. (2004). Music, language and meaning: Brain signatures of semantic processing. Nature Neuroscience, 7(3), 302-307.
Kutas, M., & Hillyard, S. A. (1984). Brain potentials during reading reflect word expectancy and semantic association. Nature, 307, 161 – 163.
Mesulam, M. M. (1998). From sensation to cognition. Brain, 121(6), 1013-1052.
Metzner, P., von der Malsburg, T., Vasishth, S., & Rösler, F. (2015). Brain responses to world knowledge violations: A comparison of stimulus-and fixation-triggered event-related potentials and neural oscillations. Journal of Cognitive Neuroscience, 27, 1017-1028.
Metzner, P., Malsburg, T., Vasishth, S., & Rösler, F. (2017). The importance of reading naturally: Evidence from combined recordings of eye movements and electric brain potentials. Cognitive Science, 41(S6), 1232-1263.
Nieuwland, M. S. (2016). Quantification, prediction, and the online impact of sentence truth-value: Evidence from event-related potentials. Journal of Experimental Psychology: Learning, Memory, and Cognition, 42(2), 316-334.
Nieuwland, M. S., & Kuperberg, G. R. (2008). When the truth is not too hard to handle an event-related potential study on the pragmatics of negation. Psychological Science, 19(12), 1213-1218.
Nieuwland, M. S., & Martin, A. E. (2012). If the real world were irrelevant, so to speak: The role of propositional truth-value in counterfactual sentence comprehension. Cognition, 122(1), 102-109.
Nigam, A., Hoffman, J. E., & Simons, R. F. (1992). N400 to semantically anomalous pictures and words. Journal of Cognitive Neuroscience, 4(1), 15-22.
Oostenveld, R., Fries, P., Maris, E., & Schoffelen, J. M. (2011). FieldTrip: Open source software for advanced analysis of MEG, EEG, and invasive electrophysiological data. Computational Intelligence and Neuroscience, 2011. https://doi.org/10.1155/2011/156869.
Orgs, G., Lange, K., Dombrowski, J. H., & Heil, M. (2006). Conceptual priming for environmental sounds and words: An ERP study. Brain and Cognition, 62(3), 267-272.
Orgs, G., Lange, K., Dombrowski, J. H., & Heil, M. (2007). Is conceptual priming for environmental sounds obligatory?. International Journal of Psychophysiology, 65(2), 162-166.
Orgs, G., Lange, K., Dombrowski, J. H., & Heil, M. (2008). N400-effects to task-irrelevant environmental sounds: Further evidence for obligatory conceptual processing. Neuroscience Letters, 436(2), 133-137.
Öttl, B., Dudschig, C., & Kaup, B. (2017). Forming associations between language and sensorimotor traces during novel word learning. Language and Cognition, 9(1), 156-171.
Schirmer, A., Soh, Y. H., Penney, T. B., & Wyse, L. (2011). Perceptual and conceptual priming of environmental sounds. Journal of Cognitive Neuroscience, 23(11), 3241-3253.
Schneider, T. R., Debener, S., Oostenveld, R., & Engel, A. K. (2008). Enhanced EEG gamma-band activity reflects multisensory semantic matching in visual-to-auditory object priming. NeuroImage, 42(3), 1244-1254.
Schön, D., Ystad, S., Kronland-Martinet, R., & Besson, M. (2010). The evocative power of sounds: Conceptual priming between words and nonverbal sounds. Journal of Cognitive Neuroscience, 22(5), 1026-1035.
Shafiro, V., & Gygi, B. (2004). How to select stimuli for environmental sound research and where to find them. Behavior Research Methods, Instruments, & Computers, 36(4), 590-598.
Sperber, R. D., McCauley, C., Ragain, R. D., & Weil, C. M. (1979). Semantic priming effects on picture and word processing. Memory & Cognition, 7(5), 339-345.
Van Boxtel, G. J., & Böcker, K. B. (2004). Cortical measures of anticipation. Journal of Psychophysiology, 18, 61-76.
Van Petten, C., Rheinfelder, H. (1995). Conceptual relationships between spoken words and environmental sounds: Event-related brain potential measures. Neuropsychologia, 33(4), 485-508.
West, W. C., & Holcomb, P. J. (2000). Imaginal, semantic, and surface-level processing of concrete and abstract words: An electrophysiological investigation. Journal of Cognitive Neuroscience, 12, 1024-1037.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Dudschig, C., Mackenzie, I.G., Leuthold, H. et al. Environmental sound priming: Does negation modify N400 cross-modal priming effects?. Psychon Bull Rev 25, 1441–1448 (2018). https://doi.org/10.3758/s13423-017-1388-3
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-017-1388-3