
Abstract
Natural language environments usually provide structured contexts for learning. This study examined the effects of semantically themed contexts—in both learning and retrieval phases—on statistical word learning. Results from 2 experiments consistently showed that participants had higher performance in semantically themed learning contexts. In contrast, themed retrieval contexts did not affect performance. Our work suggests that word learners are sensitive to statistical regularities not just at the level of individual word-object co-occurrences but also at another level containing a whole network of associations among objects and their properties.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
One of the most difficult tasks in language acquisition is to learn the meanings of novel words. Every time a language learner hears a novel label, there are usually multiple objects in view. The challenge is to figure out which object(s) the novel label refers to from potentially an infinite number of possible mappings, a phenomenon known as the indeterminacy of reference problem (Quine, 1960). Recently, an increasing number of studies have demonstrated that human learners are able to use co-occurrences between words and objects across different situations to learn novel word–object mappings (e.g., Smith, & Yu, 2008; Yu & Smith, 2007). The visual stimuli used in these studies are usually novel objects that have no apparent association with each other. This type of design allows researchers to examine the extent to which human learners are able to use cross-situational statistics alone to learn word–object mappings. In natural learning environments, however, virtually any learning moment happens in a context wherein related objects co-occur together (Sadeghi, McClelland, & Hoffman, 2015). For example, forks, spoons, and knives usually appear together in dining contexts. Moreover, our use of language reflects this pattern as words that are semantically or thematically related tend to co-occur in the same contexts. For example, when a child hears the word water, he also tends to hear the words milk, tea, and cup (Roy, Frank, & Roy, 2012). These examples show that in everyday life, words are presented in a structured way and tend to be contextually grounded.
The overarching goal of our current work was to investigate the effects of contextual information, in particular, semantic relationships among objects, on cross-situational word learning. One possible pathway that contextual information may influence learning is through memory processes (e.g., Kachergis, Yu, & Shiffrin, in press). Some studies show that it is easier to recall lists of words from the same semantic category than lists of unrelated words (e.g., Poirier & Saint-Aubin, 1995). Recently, Dautriche and Chemla (2014) conducted a statistical word learning study using a block design. They found that massed presentations of objects from the same semantic categories in the first block facilitated the learning of word–object pairs in the second block. This study provides initial evidence of the facilitative effect of semantic information in word learning. However, other studies show that after memorizing a list of semantically related words (e.g., table, seat, desk, sofa), adults tend to falsely recall or recognize semantically related words that are not in the list (e.g., chair; Payne, Elie, Blackwell, & Neuschatz, 1996). Another relevant line of research indicating negative semantic effects focuses on second language acquisition. It has been found that presenting novel vocabulary in semantically related word sets leads to slower recall and translation (e.g., Finkbeiner & Nicol, 2003; Tinkham, 1997).
Given the inconsistent evidence in literature, the first goal of this work was to examine the effect of semantically themed contexts on cross-situational word learning. There are many ways to create semantic themes (e.g., themes organized around activities or locations). In this work, we focused on semantic relations based on taxonomic categories and examined whether presenting taxonomically related objects in the same learning trials facilitated or hindered learning when compared to a situation in which taxonomically related objects occurred in different trials.
The second goal of this research was to investigate whether the match between learning and retrieval contexts affected adults’ cross-situational learning. In particular, we tested whether semantically themed learning and retrieval contexts affected performance. Prior research suggests that how contexts are structured at the time of encoding and retrieval can affect memory performance (e.g., Murnane, Phelps, & Malmberg, 1999). Importantly, retrieval performance is usually facilitated when the retrieval context matches with the encoding context. This effect is not restricted to contexts based on the relations between a memory cue and a target response. Environmental contexts unrelated to the task at hand, such as the natural environment or the room where information was encoded, can also affect retrieval accuracy (e.g., Godden & Baddeley, 1975; Smith, 1982). Similar effect has been found in word learning literature as well. For example, Vlach and Sandhofer (2011) found that 2- and 3-year-olds were more likely to generalize newly learned words to correct novel instances when the background table cloth during testing phase was the same as the one used during learning than when the background cloths mismatched.
Two experiments were designed to investigate the effects of semantically themed learning and retrieval contexts on cross-situational word learning. In Experiment 1, we compared adult participants’ word learning accuracy in either a semantically themed learning condition or a non-themed condition and examined the factors that affected errors. In Experiment 2, we further examined whether the match between learning and retrieval contexts affected performance.
Experiment 1
The goal of this experiment was to investigate whether contexts created based on the semantic relations among to-be-learned objects affected word learning, and whether participants encoded contextual information embedded in the input and used this information as a cue in test. Participants were trained in two conditions: (a) a themed learning condition, where objects from the same semantic category tended to co-occur in the same trials, and (b) a non-themed condition, where objects from different categories tended to co-occur in the same trials.
Participants
Participants were 68 undergraduate students (44 females, mean age: 18.80 years) at Indiana University who received course credits for volunteering.
Materials
The stimuli were 48 novel words and 48 pictures of real objects. The novel words consisted of one or two syllables and followed English phonotactic rules (e.g., dax, toma). The objects belonged to eight different categories (e.g., mammals, vegetables, vehicles), with six items in each category. Participants were exposed to four categories of objects (4 × 6 = 24 items) in each condition. For each participant, the words or objects did not repeat across conditions.
Design and Procedure
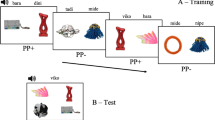
Each participant was trained in both themed learning and non-themed learning conditions. Half of the participants were randomly assigned to start with the themed condition while the other half started with the non-themed condition. As shown in Fig. 1, participants went through a learning session followed by a testing session in each condition. In each learning trial, participants saw four objects and heard four labels, each mapped to one object, presented in a random order. Even though word–object mappings were ambiguous within each trial, participants should still be able to find correct mappings by tracking word-object co-occurrences across trials.

A schematic of the learning and testing sessions in Experiment 1. Panel A represents the learning trials in the themed learning condition; Panel B represents the learning trials in the non-themed learning condition; Panel C represents the structure of the test trials in both conditions. Even though word–object mappings were ambiguous within each trial, correct word–object mappings could be learned by tracking word–object co-occurrences across trials. For example, in Trial 1 of the themed condition, participants saw a dog, a cow, a rabbit, and a pig and heard four novel words—vamy, kusk, toma, and dax—but were not given any information about which object was associated with which word. In Trial 3, participants saw the dog and heard the word toma again. If they remembered having heard the word toma while seeing the dog in the same trial previously, they should be able to infer that the word toma referred to the dog
Over the learning session, each word–object pair occurred nine times, yielding a total of 54 learning trials (24 objects × 9 repetitions/4 objects per trial). Each word co-occurred with other nontarget objects no more than four times during learning. In the themed condition, each target co-occurred with two members in the same category four times each, one to three objects from other categories three times each, and the rest of the objects no more than twice (the association matrices of the themed and non-themed conditions can be found at http://www.indiana.edu/~dll/PBR_association.pdf).
Based on the co-occurrence structure of the themed learning condition, we created the non-themed learning condition by consistently replacing a subset of objects (four out of six) in each category with objects from other categories. For example, in the themed learning trials where a rabbit occurred (e.g., Trials 1 and 54 in Fig. 1A), participants saw a tomato instead in the corresponding non-themed learning trials (e.g., Fig. 1B). Similarly, in themed trials where a horse occurred (e.g., Trials 3 and 54 in Fig. 1A), participants saw a shelf in the corresponding non-themed trials. Therefore, the themed and non-themed conditions had the same statistical structure, but a subset of the images were shuffled in the non-themed condition. Because of the consistent replacement, objects rarely co-occurred with members from the same category more than twice in the non-themed condition.
After the learning session, participants were tested on how well they learned. On each test trial, one word was played and participants selected its referent from an array of all 24 objects presented in the learning session (see Fig. 1C).Footnote 1 The locations of the objects changed trial to trial.
Results and Discussion
Each participant was trained in both themed and non-themed conditions, with the order counterbalanced across participants. We first tested whether the order of the training conditions affected performance. There was no significant order effect in either the themed condition, t(66) = .353, ns) or the non-themed condition, t(66) = .380, ns). All subsequent analyses were collapsed across training orders.
As Fig. 2 shows, participants learned more word–object pairs than expected by chance in both themed and non-themed conditions: themed: M = 0.670, t(67) = 15.842, p < .001, d = 1.92; non-themed: M = 0.581, t(67) = 14.013, p < .001, d =1.70. In addition, they had better performance in the themed condition, t(67) = 3.128, p < .01, d = .38. These results suggested that participants were able to track co-occurrences between words and objects across trials and that learners were able to use additional semantic information embedded in the themed learning context to facilitate word learning.

Word learning performance in the themed and non-themed conditions in Experiment 1. The dashed line indicates chance level (1/24). The * indicates performance significantly different from each other
The next set of analyses examined whether two factors influenced error patterns: (1) semantically relevant factor: the category membership of the target of a test trial and the 23 foil objects seen in the same trial, and (2) semantically irrelevant factor: how frequently a foil co-occurred with a word (and its target referent) during the learning phase. For each incorrect test trial, a foil object was coded as either a same- or different-category distractor based on its relationship with the target referent. Another factor that potentially influenced errors was how frequently a foil object co-occurred with the target word during the learning session. Roembke and McMurray (2016) suggested that high co-occurrence foils could compete with the target and impede learning. We used generalized estimating equations (GEEs) with the category membership of a foil object (same vs. different from the target) as a predictor and the co-occurrence frequency between the target word and the foil (0–4) as a covariate. Whether or not a foil object was mistakenly selected was used as the dependent measure. In the themed condition, category membership was a significant predictor of errors, Wald χ 2(1) = 8.857, p < .01. Participants were more likely to select a same-category distractor than a different-category distractor. There was no effect of co-occurrence frequency or interaction. In the non-themed condition, co-occurrence frequency predicted errors, Wald χ2(1) = 16.051, p < .001. Yet there was no category membership effect or interaction. Participants tended to mistakenly select a distractor that co-occurred with the target frequently, regardless of whether it came from the same category as the target.
This experiment showed that semantically themed contexts were beneficial for cross-situational word learning. Participants’ error patterns further suggested that they encoded contextual information and used it at test. However, the type of contextual information participants used were different in the two learning conditions. When participants made an error in the non-themed condition, they tended to select a high co-occurring object, regardless of the objects’ category membership. In contrast, they tended to select a same-category distractor in the themed condition, irrespective of how often the distractor co-occurred with the target during the learning phase. These results suggested that the semantic information was a salient cue in the themed condition but not in the non-themed condition.
Experiment 2
Experiment 1 showed that, given the same type of test trials, participants had better performance in the themed condition than the non-themed condition. Previous memory studies have shown that retrieval performance can be facilitated when the context at the time of retrieval matches with the context at encoding (e.g., Murnane et al., 1999). In Experiment 2, we investigated whether the match between the contexts in learning and testing sessions affected cross-situational learning performance.
Participants
Participants were 152 undergraduate students (96 females, mean age: 18.93 years) at Indiana University who received course credits for volunteering. They were randomly assigned to one of four different conditions (see below for more details).
Materials
The stimuli included the 48 words and 48 objects used Experiment 1. Each participant was exposed to 24 word–object pairs (six per category).
Design and Procedure
There were six conditions in this experiment: themed learning with themed retrieval (TL-TR), themed learning with non-themed retrieval (TL-NTR), non-themed learning with themed retrieval (NTL-TR), and non-themed learning with non-themed retrieval (NTL-NTR). The designs of the learning conditions were identical to the ones in Experiment 1 (see Panels A and B in Fig. 3).

A schematic of the learning and testing phase in Experiment 2. Panel A: learning trials in the themed learning session; Panel B: learning trials in the non-themed learning session, Panel C: test trial in the themed retrieval session; Panel D: test trial in the non-themed retrieval session
Following the learning session, participants were tested in either a themed retrieval or a non-themed retrieval session. In each test trial, participants heard one word and had to pick its referent from four objects. In the themed retrieval session, participants saw four items from the same category (Panel C of Fig. 3). In contrast, each object in a non-themed test trial came from a different category (Panel D of Fig. 3). The average foil strength (i.e., co-occurrence frequency between a test word and foil objects) was matched in three of the four conditions, the TL-TR, TL-NTR, and NTL-NTR conditions. On average, the target word co-occurred with the foil objects approximately 2.3 times during learning (TL-TR: 2.42 times, TL-NTR: 2.31 times, and NTL-NTR: 2.33 times). Because each target word rarely co-occurred with foil objects from the same semantic category more than twice during learning in the non-themed learning session, the average foil strength of the NTL-TR condition (mean = 1.21 times) was significantly lower than the other conditions, ts(46) >10, ps< .001. Using co-occurrences as the sole predictor, the test trials for the NTL-TR condition should be the easiest, because each test word co-occurred with its target referent 9 times during learning, but only co-occurred with the foils 1.21 times.
Results and Discussion
We first tested whether participants successfully learned correct word–object mappings. As Fig. 4 shows, participants in all four conditions learned more word–object pairs than expected by chance: TL-TR: M = 0.845, t(37) = 18.905, p < .001, d = 3.07; TL-NTR: M = 0.825, t(37) = 15.206, p < .001, d = 2.47; NTL-TR: M = 0.703, t(37) = 9.459, p < .001, d = 1.53; NTL-NTR: M = 0.695, t(37) = 10.149, p < .001, d = 1.65. These results again indicated that participants were able to use co-occurrences to learn word–object mappings.

Word learning performance in Experiment 2. The dashed line indicates chance level (1/4)
The next question was whether the learning and retrieval contexts affected performance. We conducted a 2 (learning context: themed vs. non-themed) × 2 (retrieval context: themed vs. non-themed) ANOVA with participants’ test scores as the dependent measure. Consistent with the findings in Experiment 1, participants trained in the themed learning conditions had better performance than their counterparts in the non-themed learning conditions, F(1, 148) = 11.227, p = .001, ηp 2 = .071. There was no effect of retrieval contexts or interaction, ps > .05. The lack of interaction suggested that the match between learning and retrieval contexts did not affect performance.
It is noteworthy that participants in the NTL-TR condition did not have better performance than their counterparts in other conditions, despite the fact that based on foil strength alone the test trials in this condition should be the easiest. Participants in this condition actually had significantly lower performance compared to learners in the two themed learning conditions: (compared to TL-TR: t(74) = 2.505, p < .05, d = 0.58; compared to TL-NTR: t(74) = 1.998, p < .05, d = 0.46. These results indicated that the facilitation effect resulted from the themed learning contexts could override the potential effect of foil strength at test.
In summary, Experiment 2 replicated the findings of Experiment 1, showing the facilitative effect of semantically themed learning contexts. However, the contextual structure in the retrieval phase did not affect performance. Unlike previous memory research (e.g., Murnane et al., 1999), we did not find a significant effect of contextual match. Interestingly, the facilitative effect of semantically themed learning contexts overshadowed potential benefits from learning-retrieval match and effects of foil strength. Together, these results suggested that the critical factor that affected cross-situational word learning performance was how the learning context was structured (see Axelsson &Horst, 2014, for additional evidence that learning contexts affect children’s cross-situational word learning).
General Discussion
Natural language environments provide structured contexts for learning. Our work suggested that structured learning contexts organized around semantic categories were beneficial for word learning. Participants were able to use the contextual structure presented in the input as a cue to help learn word–object mappings.
Even though the testing formats were different, Experiments 1 (24-AFC) and 2 (4-AFC) both demonstrated that adults had superior word learning performance in contexts where objects from the same category co-occurred frequently than in contexts where objects from different categories co-occurred frequently. Experiment 2 further showed that the facilitation effect of semantically themed contexts was strong enough to override the effect of foil strength. What is the mechanism underlying the semantic facilitation effect? One possibility is that the salient semantic information in the themed learning contexts offered learners a quick way to organize the objects they saw in different trials and helped them hold the information in memory during learning. For example, learners may notice that in trials where they heard the word toma, they tended to see multiple animals. This information may allow them to rule out objects other than animals as a potential referent of the word toma. Even though the non-themed contexts also offered co-occurrence structures that could potentially be used to organize objects across trials, it was more effortful to do so, because objects that co-occurred frequently did not have apparent relationship with each other.
This observed semantic facilitation effect is in line with the findings by Dautriche and Chemla (2014), who used a trial-by-trial test design in which learners heard one word per trial and picked its referent from four objects. In their study, semantically related objects were not only presented within the same trials but also in a massed sequence. Instead of using a block design with massed presentations to highlight the contextual structure, our study suggests that learners can extract the semantic structure across continuous learning trials, each having a much higher level of within-trial ambiguity (i.e., four words and four objects per trial). Furthermore, learners can make use of the semantic information to narrow down their search space in a following, separate, test phase. It has been argued that having trial-by-trial responses could sometimes encourage learners to adopt a single-referent tracking strategy and perform in a hypothesis-testing manner, whereas a design using continuous learning trials, each containing many words and many objects, tends to promote associative learning (Romberg & Yu, 2014). Despite significant design differences in Dautriche and Chemla’s (2014) and our current work, the facilitative semantic effects in both studies suggest that learners not only extract word–object co-occurrences from cross-situational learning contexts but also encode a whole network of information related to the objects and their properties. Learners also actively use the information to help learn novel words.
Previous memory research indicated that the match between encoding and retrieval contexts was usually beneficial for performance (e.g., Murnane et al., 1999). Experiment 2 of the current research suggests that the match between learning and retrieval contexts may not play an important role in the paradigm we used. There are two possible reasons for this finding. First, Nairne (2002) has argued that one critical factor that influences retrieval performance is whether retrieval contexts provide diagnostic cues about the target. In the test trials of Experiment 2, participants either saw all four objects from the same category or each from a different category. In conditions where the retrieval context matched with the learning context, the information in the test trials may not be useful enough to allow participants to pinpoint the target object. For example, in the TL-TR condition, simply knowing that toma co-occurred frequently with animals was not helpful during test, because all test items were animals. Second, and related to the first, the category information may be more useful in the TL-NTR condition, as only one of the four test objects came from the correct category. If a learner only remembers that the word toma goes with an animal, but does not know which particular animal it goes with, the category information should be sufficient for him to correctly pick the dog as the target object in Fig. 3D. The usefulness of semantic information in the TL-NTR condition may have offset the potential positive learning-retrieval match effect in the TL-TR condition. Much remains to be explored, as little is known about how retrieval contexts contribute to online referent selection in word learning (see McMurray, Horst, & Samuelson, 2012, for a discussion about the relationship between referent selection and word learning).
Another question is why are semantically themed contexts beneficial for cross-situational word learning, a phenomenon inconsistent with the hindrance effect (e.g., slower recall and translation) seen in second language learning studies (Finkbeiner & Nicol, 2003; Tinkham, 1997). One possibility concerns task differences. In second-language-learning studies, learners are usually given the meanings/referents of individual words “for free” and asked to memorize the word meaning or word-object pairings. In contrast, in our cross-situational learning design (as well as Dautriche & Chemla’s, 2014, design and in many real-world learning scenarios), learners had to track word–object co-occurrences across ambiguous learning situations to figure out correct mappings. The salient semantic information in the themed learning contexts likely offered participants a quick and easy way to organize and remember the objects they saw in learning trials. Indirect evidence of encoding and use of semantic information can be seen in participants’ errors. After trained in a themed learning condition, participants tended to falsely select same-category distractors as the target. The facilitative effects observed in cross-situational learning studies and the hindrance effects in previous second-language-learning studies suggest an interaction between task demands and contextual structures.
It is worth noting that the objects used in the current studies are all familiar to adult participants. One question to ask is whether the effects are the same in children, whose object and category concepts are still developing. Prior memory research suggests that children’s gist/theme extraction ability and/or knowledge base affect how likely they are to falsely recall or recognize semantically relevant items not in a memory list (e.g., Brainerd, Reyna, & Ceci, 2008; Howe, Wimmer, & Blease, 2009). It is possible that these factors also affect whether children can make use of semantic information when learning words grouped in semantically themed contexts. Future research investigating semantic context effects on children’s word learning is necessary.
In sum, our work points to the importance of grounding statistical learning in context. Our study contributes to the literature by showing that semantically themed learning contexts support and facilitate word learning. Statistical word learning is not one powerful mechanism that only exists in vacuum but disappears when other types of cues are available. Our findings demonstrate that learners encode a whole network of associations among individual word–object pairs and among object properties and actively use these associations to assist learning. Word acquisition is enhanced when learning is put in a more naturalistic and structured context. Learners can take advantage of structured input and use statistical information and semantic cues jointly in their acquisition of novel words.
Notes
Instead of using a four-alternative forced-choice (4-AFC) test, a design used in many previous cross-situational learning studies, we used a 24-AFC task. This is a more stringent test that can potentially produce more errors and provide us with the opportunity to analyze error patterns.
References
Axelsson, E. L., & Horst, J. S. (2014). Contextual repetition facilitates word learning via fast mapping. Acta Psychologica, 152, 95–99.
Brainerd, C. J., Reyna, V. F., & Ceci, S. J. (2008). Developmental reversals in false memory: A review of data and theory. Psychological Bulletin, 134(3), 343–382.
Dautriche, I., & Chemla, E. (2014). Cross-situational word learning in the right situations. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40(3), 892–903.
Finkbeiner, M., & Nicol, J. (2003). Semantic category effects in second language word learning. Applied PsychoLinguistics, 24(03), 369–383.
Godden, D. R., & Baddeley, A. D. (1975). Context‐dependent memory in two natural environments: On land and underwater. British Journal of Psychology, 66(3), 325–331.
Howe, M. L., Wimmer, M. C., & Blease, K. (2009). The role of associative strength in children’s false memory illusions. Memory, 17(1), 8–16.
Kachergis, G., Yu, C., & Shiffrin, R. M. (in press). A bootstrapping model of frequency and context effects in word learning. Cognitive Science. doi:10.1111/cogs.12353
McMurray, B., Horst, J. S., & Samuelson, L. K. (2012). Word learning emerges from the interaction of online referent selection and slow associative learning. Psychological Review, 119(4), 831.
Murnane, K., Phelps, M. P., & Malmberg, K. (1999). Context-dependent recognition memory: The ICE theory. Journal of Experimental Psychology: General, 128(4), 403–415.
Nairne, J. S. (2002). The myth of the encoding-retrieval match. Memory, 10(5/6), 389–395.
Payne, D. G., Elie, C. J., Blackwell, J. M., & Neuschatz, J. S. (1996). Memory illusions: Recalling, recognizing, and recollecting events that never occurred. Journal of Memory and Language, 35(2), 261–285.
Poirier, M., & Saint-Aubin, J. (1995). Memory for related and unrelated words: Further evidence on the influence of semantic factors in immediate serial recall. The Quarterly Journal of Experimental Psychology, 48(2), 384–404.
Quine, W. V. O. (1960). Word and object. Cambridge, MA: MIT Press.
Roembke, T. C., & McMurray, B. (2016). Observational word learning: Beyond propose-but-verify and associative bean counting. Journal of Memory and Language, 87, 105–127.
Romberg, A. R., & Yu, C. (2014). Interactions between statistical aggregation and hypothesis testing during word learning. In P. Bello, M. Guarini, M. McShane, & B. Scassellati (Eds.), Proceedings of the 36th annual conference of the cognitive science society (pp. 1311–1316). Austin, TX: Cognitive Science Society.
Roy, B. C., Frank, M. C., & Roy, D. (2012). Relating activity contexts to early word learning in dense longitudinal data. In Proceedings of the 34th Annual Meeting of the Cognitive Science Society (pp. 935–940). Austin, TX: Cognitive Science Society.
Sadeghi, Z., McClelland, J. L., & Hoffman, P. (2015). You shall know an object by the company it keeps: An investigation of semantic representations derived from object co-occurrence in visual scenes. Neuropsychologia, 76, 52–61.
Smith, S. M. (1982). Enhancement of recall using multiple environmental contexts during learning. Memory & Cognition, 10(5), 405–412.
Smith, L., & Yu, C. (2008). Infants rapidly learn word-referent mappings via cross-situational statistics. Cognition, 106(3), 1558–1568.
Tinkham, T. (1997). The effects of semantic and thematic clustering on the learning of second language vocabulary. Second Language Research, 13(2), 138–163.
Vlach, H. A., & Sandhofer, C. M. (2011). Developmental differences in children’s context-dependent word learning. Journal of Experimental Child Psychology, 108(2), 394–401.
Yu, C., & Smith, L. B. (2007). Rapid word learning under uncertainty via cross-situational statistics. Psychological Science, 18(5), 414–420.
Acknowledgements
The authors would like to thank Eric Timperman for assistance with data collection. This research was supported by NIH Grant R01HD074601.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Chen, Ch., Yu, C. Grounding statistical learning in context: The effects of learning and retrieval contexts on cross-situational word learning. Psychon Bull Rev 24, 920–926 (2017). https://doi.org/10.3758/s13423-016-1163-x
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-016-1163-x