
Abstract
Sensorimotor brain areas have been implicated in the recognition of emotion expressed on the face and through nonverbal vocalizations. However, no previous study has assessed whether sensorimotor cortices are recruited during the perception of emotion in speech—a signal that includes both audio (speech sounds) and visual (facial speech movements) components. To address this gap in the literature, we recruited 24 participants to listen to speech clips produced in a way that was either happy, sad, or neutral in expression. These stimuli also were presented in one of three modalities: audio-only (hearing the voice but not seeing the face), video-only (seeing the face but not hearing the voice), or audiovisual. Brain activity was recorded using electroencephalography, subjected to independent component analysis, and source-localized. We found that the left presupplementary motor area was more active in response to happy and sad stimuli than neutral stimuli, as indexed by greater mu event-related desynchronization. This effect did not differ by the sensory modality of the stimuli. Activity levels in other sensorimotor brain areas did not differ by emotion, although they were greatest in response to visual-only and audiovisual stimuli. One possible explanation for the pre-SMA result is that this brain area may actively support speech emotion recognition by using our extensive experience expressing emotion to generate sensory predictions that in turn guide our perception.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Emotion is contagious, whether it be a smile, a laugh, or a song. When we see others expressing emotion, it inspires us to do the same, often without conscious thought. But how do we do this—what mechanisms allow us to understand and mimic the emotions of others? In the current study, we used electroencephalography (EEG) to investigate the neural basis of emotion recognition. In particular, the current study is the first to assess whether activity in sensorimotor cortices (i.e., engagement of the human mirror neuron system [hMNS]) may support the recognition of emotion that is expressed nonverbally through speech.
Speech is an audiovisual signal, including speech sounds and facial speech movements (Sumby & Pollack, 1954). Both of these sensory modalities are important to understanding the emotion of a speaker, which can be conveyed via auditory cues (i.e., their vocal expression) or visual cues (i.e., their facial expression). The overwhelming majority of research on emotion recognition has focused on visual cues that are revealed by facial expressions. One of the brain mechanisms thought to underpin facial emotion recognition involves activity in sensorimotor cortices. When we perceive facial expressions of emotions, we unconsciously mimic them (Dimberg, 1982; Dimberg et al., 2000; Larsen et al., 2003). Furthermore, when such facial mimicry is prevented (e.g., by holding a pen in the teeth) or otherwise impaired (e.g., Autism Spectrum Disorder), it reduces our ability to recognize facial expressions of emotion involving those same muscles (Borgomaneri et al., 2020; Oberman et al., 2007; Ponari et al., 2012). In some studies, the degree of mimicry also has been associated with our ability to recognize the expressed emotions (Ipser & Cook, 2016; Künecke et al., 2014; Livingstone et al., 2016). For instance, Livingstone et al. (2016) found that patients living with Parkinson’s Disease varied in the extent to which they mimicked faces producing emotional speech and song. In addition, the greater the response of a patient’s zygomaticus major muscle (required for smiling) to the perception of happy faces, the faster that patient identified the emotion.
Wood et al. (2016) offer a useful conceptual explanation for these phenomena. They argue that when perceiving facial emotions, the face regions of the somatosensory and motor cortices are activated in response. Wood et al. refer to this response as “sensorimotor simulation” (Gallese, 2007; Jeannerod, 2001), because the neural systems required for the production of emotional facial expressions also are activated during the perception of those same emotions. Peripheral facial mimicry also may emerge as a downstream consequence of this sensorimotor simulation (Oberman et al., 2009; Prochazkova & Kret, 2017; Russo, 2020; Shamay-Tsoory, 2011). This simulation (both neural and peripheral) leads to activation of brain areas associated with the experience of those specific emotions, which in turn allows the perceiver to recognize them. This embodied account of emotion perception harkens back to the James-Lange theory of emotion (James, 1884), which proposed that we understand our emotional states by interpreting our bodies’ responses to the environment. More recent formulations of embodied accounts would not suggest that simulation is necessary, nor that it is the sole mechanism of emotion perception (Goldman, 2006); however, it may be especially helpful when judgments are rushed or when emotions are challenging to recognize (Wood et al., 2016; Karakale et al., 2019).
As pointed out by Wood et al. (2016), the precise neural underpinnings of sensorimotor simulation are a matter of debate. However, a strong candidate is the hMNS, a collection of brain areas that responds to both the execution of an action (e.g., a facial expression) as well as the observation of that same action (Cross et al., 2009; Rizzolatti & Craighero, 2004). Although the precise nature of this network is debated (Cook et al., 2014; Hickok, 2009), the existence of a network with these properties is generally accepted (for meta-analyses, see Caspers et al., 2010; Molenberghs et al., 2009). Audio and visual information are proposed to enter the hMNS via the superior temporal sulcus (STS), which provides sensory input to the inferior parietal lobule (IPL) and in turn the premotor cortex (PMC) and inferior frontal gyrus (IFG; Chong et al., 2008; Press et al., 2012). In addition to these “classical” hMNS areas, there is an “extended” hMNS—including the somatosensory cortex (S1/S2), presupplementary motor area (pre-SMA), middle temporal gyrus (MTG), and insula—which supports the classical hMNS, despite perhaps not possessing the same mirror-like properties (Bonini, 2017; Pineda, 2008).
Brain areas in this network appear to work together to simulate perceived action, including emotions, although the precise roles of each area are not entirely clear. One account argues that the parietal node of the hMNS (IPL, S1/S2) simulates the afferent (somatosensory) aspects of an action, whereas the frontal node (PMC/IFG, pre-SMA) simulates the efferent (motor) aspects of an action (Avenanti et al., 2007; Bastiaansen et al., 2009; Russo, 2020). In the case of emotion perception, the parietal node may process the somatic sensations associated with the expression of an emotion, whereas the frontal node may process the associated motor plans. In addition, other areas of the extended hMNS involved in the processing of emotions, including the insula, may enable us to empathize with those emotions (Bastiaansen et al., 2009; Iacoboni, 2009). These three components of the hMNS (parietal, frontal, and insular) may serve the functions deemed necessary by Wood et al.’s (2016) model, particularly the somatosensory, motor, and affective aspects of simulation, respectively.
There is considerable neuroimaging evidence for the view that the hMNS is involved in the recognition of facial emotions (Oberman & Ramachandran, 2007; Wood et al., 2016). Functional magnetic resonance imaging (fMRI) studies have regularly found greater activation of the classical hMNS (i.e., IPL and PMC/IFG) and extended hMNS (e.g., insula) in response to facial emotion (or, more often, emotion-related judgements of faces) than their neutral counterparts (Carr et al., 2003; Van der Gaag et al., 2007; Sarkheil et al., 2013; Wicker et al., 2003; Zaki et al., 2009). For instance, Van der Gaag et al. (2007) found that viewing facial emotion (happy, fearful, and disgusted) led to greater activation of the STS, IFG, and pre-SMA than viewing neutral faces. In addition to fMRI, another method that has been widely used to study facial emotion processing in the hMNS, often with the same results (Moore & Franz, 2017), is EEG (see also Karakale et al., 2019; Moore et al., 2012; Perry et al., 2010; Pineda & Hecht, 2009). The signal of interest in these studies is generally the alpha frequency band (8-13 Hz) of the mu rhythm, generated over sensorimotor brain areas. Power reduction in the mu rhythm, also called mu event-related desynchronization (mu-ERD), may reflect decoupling of oscillations across the two nodes of the hMNS (frontal and parietal). Thus, mu-ERD often is considered a measure of activity in the hMNS, with greater mu-ERD indicating greater activity (Fox et al., 2016; Lepage & Théoret, 2006; Muthukumaraswamy et al., 2004).
Although the above studies support the role of the hMNS in the recognition of facial emotions, little research has assessed the involvement of the hMNS in the recognition of vocal emotion, particularly as expressed in speech sounds. This is despite some evidence that the hMNS is involved in the perception of speech sounds generally (Jenson et al., 2014; Wilson et al., 2004; but see Hickok, 2010). Nonetheless, a few studies have considered the hMNS in the context of vocal emotion outside of the speech domain. For example, Warren et al. (2006) found that the left pre-SMA had a greater response to higher-intensity nonverbal vocalizations (i.e., triumph vs. amusement) and that the left IFG had a greater response to more positively valanced nonverbal vocalizations (i.e., triumph vs. disgust). McGarry et al. (2015) found that audiovisual presentations of sung intervals led to greater activation of the extended hMNS than did nonbiological control stimuli matched for mean pitch and gross facial movement.
In sum, although a considerable body of evidence suggests that the hMNS plays a role in perceiving facial emotions, and perhaps also emotional nonverbal vocalizations, no study has considered whether the hMNS plays a role in the perception of emotion as it is expressed in speech. This unexplored topic is likely to be more ecologically valid than the use of static faces or nonverbal vocalizations as stimuli. After all, dynamic vocal-facial expression of emotions in speech are far more common in the real world than static displays of facial emotion captured at the apex of an expression, or nonverbal vocalizations such as a shout of triumph. To explore this topic, the current study asked 24 healthy adults to observe and classify emotional speech stimuli while brain activity was measured and source-localized using EEG. The stimuli were drawn from the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) and encompassed happy, sad, and neutral expressions of emotion. The stimuli were presented in each of three sensory modalities: audio-only, visual-only, and audiovisual.
Our primary prediction, based on the literature summarized above, was that the hMNS would show greater responsiveness to emotional speech (happy and sad) than to neutral speech. A strong candidate brain area for this effect would be the pre-SMA, which previous studies of facial and vocal speech emotion have found to be sensitive to emotional intensity (Van der Gaag et al., 2007; Warren et al., 2006). We also had two secondary predictions. First, we predicted that the hMNS would be activated most strongly in response to modalities containing visual information (i.e., visual-only and audiovisual). This was based on the findings of Crawcour et al. (2009), an EEG study that reported greater mu-ERD over motor areas in response to facial speech movements than to speech sounds. Second, we predicted that the hMNS response to emotion (e.g., in the pre-SMA) would be positively correlated with participants’ accuracy when classifying emotions. This result has been found in some prior fMRI studies of emotion processing in the hMNS (Bestelmeyer et al., 2014; McGettigan et al., 2013), and a similar result here would suggest that the hMNS confers an active benefit to emotion recognition.
Methods
Participants
Twenty-four healthy adults (20 females, 4 males) participated in the study, recruited from undergraduate psychology courses and from the community. Participants either received course credit for taking part or did so as volunteers. Ages ranged from 20 to 37 years old (M = 20.88, SD = 4.93). All participants reported having normal hearing, and all but three reported being right-handed. The sample size was chosen to resemble other EEG-hMNS studies that have considered the effect of emotion (McGarry et al., 2015; Moore et al., 2012). The R package “Superpower” (Lakens & Caldwell, 2021) calculated that this sample size allowed us to detect effects of emotion and modality on mu-ERD as small as d = 0.33 with 80% power, assuming that mu-ERD is moderately correlated across conditions (r = 0.50). The study was approved by the Research Ethics Board at Ryerson University (protocol number 2018-241).
Design
The study was based on a two-factor, within-subject design. The independent variables were the emotion (happy, sad, or neutral) and modality (audio-only, visual-only, or audiovisual) of the presented speech stimuli. The dependent variables were mu-ERD, emotion classification accuracy, and emotion classification reaction time. The study consisted of three blocks, each corresponding to one modality. These blocks were presented in a fully counterbalanced order. There were six counterbalancing orders, each completed by four participants.
Stimuli
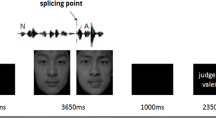
Stimuli were taken from the RAVDESS (Livingstone & Russo, 2018), particularly from actors 1, 4, 5, 8, 9, and 24 (3 males, 3 females). Stimuli ranged from 3.10 to 4.40 s in duration (M = 3.59, SD = 0.26). These durations did not differ between the three emotions (ps > 0.40). To minimize the possibility that differences in mu-ERD between conditions were due to low-level stimulus features, all stimuli were root-mean-square normalized in amplitude using Praat version 6.0.40. Based on the RAVDESS validation data, the specific actors and stimuli were chosen in such a way to ensure that there were no outlier stimuli with emotions that were especially difficult to identify or rated as being especially low in genuineness (more than two SD below the mean). For each participant, two actors (1 male, 1 female) were randomly assigned to each modality block. Within each modality block, each actor contributed 24 stimuli, 8 stimuli per emotion. For happy and sad stimuli, there were two neutral statements (“The kids are talking by the door” or “The dogs are sitting by the door”), two emotional intensities (low or high), and two repetitions of each stimulus. Neutral stimuli used the same two statements, two iterations (a second recording of the same stimulus), and two repetitions of each stimulus. For each participant, stimuli were randomized within each modality block.
EEG Recording
EEG data were collected using a 64-channel BioSemi ActiveTwo EEG system at a sampling rate of 1,024 Hz. Source localization of EEG signals was performed using independent component analysis (ICA; Delorme et al., 2007), a technique that identifies unique sources of spectrotemporal variability in each participant’s data. Our research group has previously used EEG and ICA to replicate hMNS results found using fMRI (McGarry et al., 2012). The number of channels (64), the sampling rate (1,024 Hz), and the total duration of stimulus presentation per participant (7.2 min) ensured that enough EEG data was collected to perform an ICA, for which at least (number of channels)2 × 30 data points are recommended.
Procedure
Participants entered the lab and gave informed, written consent. They were then fitted with a 64-electrode EEG electrode cap according to the international 10–20 system (Homan et al., 1987), with two electrodes attached to the mastoids (right and left). One horizontal eye electrode and one vertical eye electrode (both on the right) were used to facilitate measurement of eye blinks and eye movements. In addition, two electrodes were placed on the zygomaticus major (right), required for smiling, and two were placed on the corrugator supercilii (right), required for frowning. The results from the electrodes over facial muscles were not considered as the data quality was poor. Participants were then seated in a sound-attenuated chamber, approximately 60 cm in front of a Windows computer monitor (screen size 61-cm diagonally) on which the experiment was presented using Psychtoolbox-3 (Pelli, 1997) in MATLAB version 9.2. EEG data were monitored and saved on a separate Windows computer.
Participants were then taken through general task instructions. Once they understood the requirements of the task, they completed the first modality block. Specific task instructions and the visual components of stimuli (i.e., faces) were presented on the computer monitor, and audio components of stimuli (i.e., speech sounds) were presented via two speakers on either side of the computer monitor at a peak sound level of approximately 60 dB SPL (which is typical of everyday conversation). Within each trial, participants were presented with a fixation cross that randomly ranged from 4.00 s to 7.00 s, followed by a stimulus with an average duration of 3.59 s, and finally a blank screen that randomly ranged from 2.30 to 3.40 s. Using a keyboard, participants then classified the emotion that they perceived as quickly as they could while still being accurate. There were 48 stimuli presented per block. After the completion of the first block, participants were able to take a rest before completing the second one, and likewise for the third (final) block. At the break, participants were allowed to take as long as they wanted. After completing all blocks, participants completed a short demographic questionnaire before being debriefed.
Data Processing
The EEG data were processed in MATLAB R2019b using EEGLAB version 19.1 (Delorme & Makeig, 2004). The processing pipeline used was the same as Copelli et al. (in press). Raw EEG data were band-pass filtered from 1–60 Hz using “pop_eegfiltnew.” Next, noisy scalp electrodes were identified using “pop_rejchan” and interpolated on the basis of surrounding channels using “pop_interp,” while external electrodes were rejected. For each participant, between 0 and 8 of the 64 total scalp channels were interpolated (with an average of 2.83). Data were re-referenced to the average using “pop_reref” and epoched with a 4.00-s baseline and a 3.10-s stimulus, the duration of the shortest stimulus. For each trial, the average over its 4.00-s baseline was subtracted from the values from 0 to 3.10 s.
ICAs were then conducted using “runica” and the InfoMax algorithm. To avoid rank-deficient data, each participant’s ICA yielded n components, where n is the number of electrodes less all interpolated channels. An initial ICA was used to identify and reject noisy epochs using default EEGLAB epoch rejection parameters. For each condition averaged across participants, the percentage of noisy epochs rejected ranged from 0% to 8.16% (with an average of 4.46%). A second ICA captured stereotyped neuroelectric activity, including brain sources (Miyakoshi, 2020). This led to the final ICA weight matrixes for dipole fitting. Dipoles were located according to the boundary element model using “DIPFIT,” and automated independent component selection was done using “IClabel” (Pion-Tonachini et al., 2019). Automated selection of independent components (ICs) was done using a custom-written EEGLAB script (Miyakoshi, 2020). This script also rejected components with more than 15% residual variance, which represented an average of 18% of components per participant.
ICs were fit into clusters using the k-means algorithm (MacQueen, 1967), which amounted to one component per participant per cluster (EEGLAB Wiki: Chapter 05, 2014). As we were only interested in changes in spectral power that occur as a result of the mu rhythm in hMNS areas, clusters were formed using ERSPs and dipole location as our determining factors. Outlier components were classified as over 3 standard deviations from the mean and were separated out. The resulting data were fit into 18 source clusters (EEGLAB Wiki: Chapter 05, 2014). Data from all clusters within the hMNS were exported to Excel using a custom MATLAB script. For visualizations that considered the effect of time, the data were averaged across only the frequency band of interest (8–13 Hz). For analyses and visualizations that did not consider time, the data were also averaged across time (0–3.10 s) in addition to frequency.
Statistical Analyses
All statistical analyses used R version 4.0.3 (R Core Team, 2020). Analysis of variance (ANOVA), conducted using the “ez” package, was used to assess the effects of emotion and modality (and their interaction) on hMNS activity and the effect of modality on emotion classification accuracy and reaction time. Reaction time data were log-transformed due to being right-skewed (Whelan, 2008). Greenhouse-Geisser correction was applied to effects that failed Mauchly’s test of sphericity. In cases where main effects were significant, follow-up pairwise comparisons used Holm-Bonferroni correction (Holm, 1979). For all ANOVAs, the source of error was between components rather than between participants.
Correlational analyses were also used to assess the relationships between emotion classification accuracy, reaction time, and the hMNS response to emotion. For the latter, we isolated the hMNS response to emotion by subtracting mu-ERD in response to the neutral condition from mu-ERD in response to emotional conditions (happy and sad). For correlations, in cases where participants contributed more than one component to a cluster, only the component with the lowest residual variance was selected (Denis et al., 2017). Bivariate outliers were identified with a bagplot (Rousseeuw et al., 1999) using the “aplpack” package. A bagplot is a bivariate generalization of the one-dimensional boxplot, which draws a “bag” around 50% of all data points and draws a fence by inflating the bag by a factor of three. Data points outside of the fence were deemed bivariate outliers and excluded from the correlation.
Results
Neural Data
Of the 18 brain source clusters, we analyzed four in brain areas consistent with the hMNS: the left pre-SMA (Brodmann area [BA] 8), left posterior IFG (BA 44), and left and right PMC (BA 6). See Table 1 for all effects and interactions on mu-ERD in each cluster.
Left pre-SMA cluster
This cluster was located at Talairach coordinates (−3, 26, 38), which is within the boundaries of the left pre-SMA as described by Mayka et al. (2006). It was composed of 36 components contributed from 19 participants (Fig. 1). The timecourse of mu-ERD by emotion averaged across modalities shows that mu-ERD reached a peak approximately 0.70 s after stimulus onset (Fig. 2). At this point, mu-ERD became greater in the happy and sad conditions than in the neutral condition, with this difference persisting until the 2.00-s mark. Averaging across time revealed results consistent with these observations: there was a significant main effect of emotion on mu-ERD, which was significantly greater in the happy condition than in the sad condition (p = 0.037) and marginally greater in the sad condition than in the neutral condition (p = 0.071; Fig. 3). There was no effect of modality and no interaction between emotion and modality on mu-ERD. There also was no effect of participant sex on mean mu-ERD, although the small number of male participants (only three males contributed components to this cluster) resulted in low power for this analysis.

Components constituting the left pre-SMA cluster. This cluster is located at (TAL −3, 26, 38).

Effects of time and emotion on mu power in the left pre-SMA. Mu-ERD appeared greater in the happy and sad conditions than in the neutral condition over the period of approximately 0.70–2.00 s after stimulus onset.

Effect of emotion on mu power in the left pre-SMA. Mu-ERD was significantly greater in the happy condition, and marginally greater in the sad condition, than in the neutral condition. Lower mu power is synonymous with greater mu-ERD. Error bars represent the standard error of the mean.
Left posterior IFG cluster
The left posterior IFG cluster, located at Talairach coordinates (TAL −41, 16, 8), was composed of 26 components contributed from 18 participants (Hammers et al., 2006). There was a significant main effect of modality, with greater mu-ERD in the audiovisual condition than in the audio-only condition (p < 0.0001), as well as greater mu-ERD in the visual-only condition than in the audio-only (p < 0.0001) and audiovisual conditions (p = 0.022; Fig. 4A). Nonetheless, mu-ERD was still significantly greater than zero in the audio-only condition (p < 0.0001). There was no effect of emotion and no interaction between emotion and modality.

Effect of modality on mu power in all clusters responding to modality. A. Left posterior IFG. B. Left PMC. C. Right PMC. Across these three clusters, the most consistent trend is that conditions containing visual information (visual-only and audiovisual) always led to lower mu power (greater mu-ERD) than the audio-only condition. Error bars represent the standard error of the mean.
Bilateral PMC clusters
The left PMC cluster (TAL −35, −11, 37) was composed of 20 components contributed from 14 participants, and the right PMC cluster (TAL 34, 7, 46) was composed of 15 components contributed from 11 participants (Mayka et al., 2006). In both of these clusters, there was a significant main effect of modality on mu-ERD, although this differed slightly between hemispheres (Figs. 4B/C). In the left PMC, mu-ERD was greater in the visual-only condition than in the audio-only condition (p = 0.0006) and greater in the audiovisual condition than in the audio-only condition (p = 0.009); while in the right PMC, mu-ERD was greater in the visual-only condition than in the audio-only condition (p = 0.0007) and marginally greater in the visual-only condition than in the audiovisual condition (p = 0.051). In the left PMC, but not the right PMC, mu-ERD was significantly greater than zero in the audio-only condition (p < 0.0001). In both the left and right PMC, there was no effect of emotion and no interaction between emotion and modality.
Behavioural Data
There was a significant main effect of modality on emotion classification accuracy (F[2,46] = 24.9, p < 0.0001, ηG2 = 0.41; Fig. 5). Accuracy in the audio-only condition was significantly lower than in the visual-only (p = 0.0002) and audiovisual conditions (p < 0.0001), and accuracy in the visual-only condition was marginally lower than in the audiovisual condition (p = 0.064). Thus, recognizing emotions was most challenging in the audio-only condition, whereas in the other two modalities, accuracy was near ceiling and exhibited little variability across participants. There was no effect of modality on reaction time (F[2,46] = 0.42, p = 0.66, ηG2 = 0.004).

Effect of emotion-on-emotion classification accuracy. Note. Accuracy was higher in the visual-only and audiovisual conditions than in the audio-only condition, and it also was marginally higher in the audiovisual condition than the visual-only condition. Error bars represent the standard error of the mean.
Correlations
After removing one bivariate outlier, there was a significant negative correlation between emotion classification accuracy and reaction time in the audio-only condition (r[21] = −0.48, p = 0.021). This correlation may suggest that some participants were better at classifying emotions than others, with those who were more accurate also responding faster. This same correlation was not significant in the visual-only condition (two outliers) or audiovisual condition (no outliers), likely due to range restriction caused by a ceiling effect in the accuracy data.
We also analyzed the correlation between emotion classification accuracy and the mu-ERD response to emotion in the pre-SMA cluster. Our expectation was that participants with higher accuracy would have greater mu-ERD (i.e., lower mu power), which could help to explain why some participants are better at emotion identification than others. However, we found no evidence for such a relationship. In all three modalities, there was no significant correlation between accuracy and the pre-SMA response to happy (happy−neutral), sad (sad−neutral), or emotion overall (mean[happy, sad]−neutral). These correlations remained nonsignificant when considering emotion classification reaction time rather than accuracy. Across these correlations involving mu-ERD, the number of outliers removed ranged from zero to three.
Discussion
In the current study, 24 healthy adults listened to speech that was happy, sad, or neutral, as revealed nonverbally through facial and/or vocal expression rather than the semantic content of the speech (i.e., the words being used). At the same time, we measured participants’ brain activity with EEG and ultimately source-localized this activity using ICA. We predicted that the classical or extended hMNS would demonstrate more mu-ERD in response to emotional (happy and sad) speech than to neutral speech; that the hMNS response would be greater to visual-containing than audio-only stimuli; and that the hMNS response to emotion would be positively correlated with participants’ emotion classification accuracy.
We used ICA to identify four areas of the hMNS that were activated: the left pre-SMA, the left posterior IFG, and the right and left PMC. Interestingly, all of these areas were motor (frontal) components of the hMNS, and no somatosensory or affective sites were identified (e.g., IPL or insula). This has been found in other studies of emotion perception (e.g., vocal; Warren et al., 2006) and may suggest that motor aspects of simulation are more important than somatosensory or affective aspects of simulation, at least under the conditions of the current study. All four of the identified hMNS areas have previously been implicated in the perception of speech, particularly under challenging conditions (Du et al., 2014; Meister et al., 2007; Scott et al., 2004). It has been proposed that when speech is perceived under optimal conditions, the motor system is not needed, with the ventral stream of speech processing more than sufficient (Peelle, 2018). The dorsal stream and its motor termini are only recruited when the perception of speech—particularly speech sounds—is challenging (Hickok & Poeppel, 2000, 2004, 2007, 2012). This includes any conditions under which speech sounds are less stereotyped than usual, such as when it is distorted or vocal emotions are present (Russo, 2020).
Of the four areas mentioned above, activation of only one of them—the left pre-SMA—differed by emotion. In particular, the left pre-SMA was more active during the perception of happy and sad speech than neutral speech. Thus, our prediction that the hMNS would demonstrate more activation to emotional speech was supported. The pre-SMA is a frontal component of the extended hMNS that lies at the intersection of prefrontal and motor cortices and is associated with higher-order aspects of complex motor control (Bonini, 2017; Lima et al., 2016; Pineda, 2008; Rizzolatti & Luppino, 2001). While the IFG and SMA-proper are likely responsible for the sequencing and execution of specific actions, the pre-SMA may be involved in the preparation and selection of appropriate actions as well as the inhibition of inappropriate actions (Cunnington et al., 2005; Lima et al., 2016; Pineda, 2008; Rochas et al., 2012), including speech production (Alario et al., 2006). The pre-SMA also contributes to the perception of emotion (Zhang et al., 2019), and it may play a similar, regulatory role in that context, including by inhibiting inappropriate emotional responses (Etkin et al., 2015).
The current study is one of many to implicate the pre-SMA in emotion perception. For instance, Van der Gaag et al. (2007) found greater pre-SMA activation when viewing emotional faces—both positively and negatively valanced—than neutral faces, as have Carr et al. (2003) and Seitz et al. (2008). In the context of vocal emotion, Warren et al. (2006) found that pre-SMA activation was greater for emotions of higher intensity (e.g., triumph vs. amusement). More recently, Aziz-Zadeh et al. (2010) also reported pre-SMA activation in response to emotional prosody signals, whereas McGettigan et al. (2013) reported pre-SMA activation in response to both spontaneous and voluntary social-type laughter. Furthermore, Kreifelts et al. (2013) found that four weeks of nonverbal emotion communication training produced changes in a network that included the bilateral pre-SMA. The observed timecourse of pre-SMA activation in the current study also was consistent with this prior research, with peak activation reached approximately 0.70 s after stimulus onset (Rochas et al., 2012; Seitz et al., 2008).
We also found stronger evidence that the pre-SMA responded to happy speech, as opposed to sad speech, because mu-ERD to sad speech was only marginally greater than mu-ERD to neutral speech. Other studies have previously found a stronger association between the pre-SMA and happiness than other emotions. For instance, studies of patients with epilepsy have demonstrated that electrical stimulation of the left pre-SMA produces laughter and merriment (Fried et al., 1998; Krolak-Salmon et al., 2006) and that the pre-SMA is selectively activated during the observation and production of happy facial expressions rather than a range of other emotions or neutral expressions (Krolak-Salmon et al., 2006). More recently, in a healthy sample, it was found that TMS over the left pre-SMA impaired happy recognition, but not fear or anger recognition (Rochas et al., 2012). One possibility for the greater responsivity of the pre-SMA to expressions of happiness is that head movements tend to be greater for happy than for sad expressions (Livingstone & Palmer, 2016). Similarly, the frequency range and intensity of vocal emotions tend to be larger for happy expressions (Livingstone & Russo, 2018; Livingstone et al., 2013). Thus, while both happy and sad speech are more likely to recruit the pre-SMA than neutral speech, happy speech may be able to elicit a stronger response.
Why might the pre-SMA be recruited during emotion perception? A review by Lima et al. (2016) argues that it is an active contributor to emotion recognition rather than a mere by-product of action observation, as supported by several studies finding greater pre-SMA activation associated with more accurate emotional judgements (Bestelmeyer et al., 2014; McGettigan et al., 2013). The authors further proposed that the pre-SMA may generate sensory expectations about incoming stimuli, which in turn inform our perceptions and increase their accuracy under challenging conditions. This is consistent with two observations about the pre-SMA: it is more active when we have prior experience with the stimuli (e.g., biological vs. nonbiological action, or familiar vs. random music; Peretz et al., 2009) and when the stimuli are challenging to perceive accurately (e.g., speech emotion). For instance, Shahin et al. (2009) found that the pre-SMA is activated when gaps in speech—a stimulus that we have extensive experience producing—are “filled in” and perceived as continuous by the listener. This explanation by Lima et al. is consistent with the hypothesis that sensorimotor simulation in the hMNS provides a form of predictive coding. This account suggests that a more abstract, semantic pathway (which includes the MTG) makes predictions about the intentions of an observed action, and that the somatosensory and motor consequences of that action are then processed more concretely (i.e., simulated) in the parietal and frontal nodes (Kilner, 2011; Kilner et al., 2007). These consequences are then compared to the action being observed, and our perception and interpretation of that action are updated accordingly.
In addition to emotion, we also assessed whether activation of hMNS areas differed by modality. In the pre-SMA, modality did not affect activation, nor did the effect of emotion differ by modality. Thus, the pre-SMA may simulate speech emotion in a similar manner whether it is seen on the face or heard in the voice. In contrast, the left posterior IFG and bilateral PMC exhibited greater activation in response to stimuli that included visual information (visual-only and audiovisual) than those that did not (audio-only), although these areas nonetheless responded to audio-only stimuli. This suggests that while audio-only biological stimuli (i.e., speech sounds) may be simulated in the hMNS (Jenson et al., 2014; Wilson et al., 2004), visual biological stimuli (i.e., facial speech movements) are the dominant form of input. These results are generally consistent with our prediction, and also agree with Crawcour et al. (2009), who found greater mu-ERD over motor areas in response to facial speech movements than to speech sounds. Visual information also appears to drive hMNS simulation of other human actions, including a pair of hands ripping a piece of paper (Copelli et al., in press).
Emotion classification accuracy was lowest in the audio-only condition (82%), and much higher in the visual-only (93%) and audiovisual (96%) conditions. This suggests that visual information not only drives the hMNS but also is most important for the recognition of speech emotions, at least for the stimuli used in the current study. Previous research also has concluded that facial emotions are more easily recognized than vocal emotions (Elfenbein & Ambady, 2002; Scherer, 2003; see also Livingstone & Russo, 2018 for the RAVDESS validation). Accuracy in the audiovisual condition was marginally higher than in the visual-only condition, although it seems likely that the true advantage of the audiovisual condition was constrained by a ceiling effect. If audiovisual speech stimuli were more easily recognized than visual-only speech stimuli, it would suggest that speech sounds enhance our ability to recognize emotions, despite its smaller role than facial speech movements. Because the pre-SMA response did not differ between audiovisual and visual-only conditions, this result also serves as a reminder that the hMNS is not the only mechanism involved in emotion recognition (Yu & Chou, 2018).
We found that across participants, accuracy was negatively correlated with reaction time in the audio-only condition. This suggests that some participants were better at recognizing emotions than others, and that these participants had both faster reaction times and greater accuracy. (If, instead, these variables were positively correlated, it would suggest a speed-accuracy trade-off.) As a result, we opted to investigate whether accuracy also was correlated with the left pre-SMA response to emotion and thus whether this brain area actively supports emotion recognition. However, there was no evidence of a correlation between accuracy (or reaction time) and the pre-SMA response to emotion in any modality. This contrasts previous studies to find this relationship, including Bestelmeyer et al. (2014) and McGettigan et al. (2013; see also Lima et al., 2016; Rochas et al., 2012). Thus, although the pre-SMA appears to be recruited during the recognition of speech emotion in audio and visual modalities, we did not find any strong evidence that it plays an active role in this process. This may instead have had something to do with the emotion classification task used. The facial and vocal cues were not obscured in any way, and there were only three dissimilar emotions to choose from (happy, sad, and neutral). A more challenging task may well have led to greater variability in accuracy as well as greater pre-SMA activation, correlated with accuracy, to compensate for this.
The current study had a number of strengths. First, unlike most EEG studies of the hMNS, we used source-localization to ensure that differences in mu-ERD (particularly in response to emotion) were driven by frontal sensorimotor activity (i.e., in the pre-SMA) rather than attention-related alpha (Klimesch, 2012; Hobson & Bishop, 2017). Indeed, we found that in two occipital clusters (left cuneus and right middle occipital gyrus) as well as one temporal cluster involved in face perception (left fusiform gyrus), mu-ERD did not differ by emotion. Source-localization also allowed us to ensure that our left pre-SMA cluster did not fall within the frontal eye fields (Vernet et al., 2014), in which case eye movement may have confounded our measurement of mu-ERD. We also selected the task and stimuli carefully. Having participants classify emotions not only allowed us to measure their emotion classification accuracy, but also ensured that they stayed engaged with the task. In addition, to avoid semantic confounds, the stimuli were emotional only in their expression and not in their linguistic content (Warren et al., 2006); and to avoid low-level acoustic confounds, all stimuli across the three emotions were normalized to the same average amplitude (McGarry et al., 2015).
This study also had some limitations. One confound that we were unable to control for was the magnitude of facial motion in the visual and audiovisual conditions. To investigate this, we conducted an optical flow analysis (Horn & Schunck, 1981) of the first 3.10 s of the visual-only stimuli—the section during which mu-ERD was analyzed—using FlowAnalyzer (Barbosa et al., 2008). This revealed that there was more motion in the happy stimuli (M = 0.59, SD = 0.14) than the sad stimuli (M = 0.38, SD = 0.072), and more in the sad stimuli than the neutral stimuli (M = 0.26, SD = 0.054). Thus, one might argue that the effect of emotion on mu-ERD in the left pre-SMA was driven by differences in magnitude of motion (see Copelli et al., in press). However, at least two facts cast doubt on this explanation for our left pre-SMA findings. First, there was no interaction between emotion and modality on mu-ERD in this cluster. This suggests that the effect of emotion was similar in the audio-only condition, in which no facial motion was present, to the two visual-containing conditions. Second, we found greater mu-ERD in response to happy and sad stimuli than neutral stimuli, while for visual motion, happy had by far the most motion, followed by sad and then neutral. This suggests that visual motion does not entirely account for differences in mu-ERD by emotion, otherwise the mu-ERD differences would have mirrored the visual motion differences. The limited spatial resolution of EEG is also a limitation. Although ICA techniques can achieve a spatial resolution of 1 cm (Makeig et al., 2004a, b), this is inferior to many other neuroimaging methods, including fMRI.
In sum, the current study was the first to consider whether the hMNS is involved in the recognition of emotion expressed nonverbally through speech. We found that the left pre-SMA, a frontal component of the extended hMNS, was more active in response to happy and sad stimuli than to neutral stimuli. This was true whether emotions were perceived on the face, in speech sounds, or both. Activity levels in other areas of the hMNS (the left posterior IFG and bilateral PMC) did not differ by emotion, although they were driven by visual speech information. As proposed by others (Lima et al., 2016), the pre-SMA may actively support speech emotion recognition by using our extensive experience expressing emotion to generate sensory predictions that in turn guide our perception. However, the lack of a correlation between emotion classification accuracy (or reaction time) with the pre-SMA response to emotion leaves this possibility in need of more evidence. More research is needed to pinpoint the precise role of the pre-SMA in speech perception, particularly when speech is emotional.
References
Alario, F.-X., Chainay, H., Lehericy, S., & Cohen, L. (2006). The role of the supplementary motor area (SMA) in word production. Brain Research, 1076, 129–143.
Avenanti, A., Bolognini, N., Maravita, A., & Aglioti, S. M. (2007). Somatic and motor components of action simulation. Current Biology, 17, 2129–2135.
Aziz-Zadeh, L., Sheng, T., & Gheytanchi, A. (2010). Common premotor regions for the perception and production of prosody and correlations with empathy and prosodic ability. PLOS One, 5(1), 1–8.
Barbosa, A., Yehia, H., & Vatikiotis-Bateson, E. (2008). Linguistically valid movement behavior measured non-invasively. AVSP-2008, 173–177.
Bastiaansen, J. A. C. J., Thioux, M., & Keysers, C. (2009). Evidence for mirror systems in emotions. Philosophical Transactions of the Royal Society B: Biological Sciences, 364(1528), 2391–2404.
Bestelmeyer, P. E. G., Maurage, P., Rouger, J., Latinus, M., & Belin, P. (2014). Adaptation to vocal expressions reveals multistep perception of auditory emotion. Journal of Neuroscience, 34, 8098–8105.
Bonini, L. (2017). The extended mirror neuron network. The Neuroscientist, 23, 56–67.
Borgomaneri, S., Bolloni, C., Sessa, P., & Avenanti, A. (2020). Blocking facial mimicry affects recognition of facial and body expressions. PLOS One, 15(2), 1–21.
Carr, L., Iacoboni, M., Dubeau, M.-C., Mazziotta, J. C., & Lenzi, G. L. (2003). Neural mechanisms of empathy in humans: A relay from neural systems for imitation to limbic areas. Proceedings of the National Academy of Sciences, 100, 5497–5502.
Caspers, S., Zilles, K., Laird, A. R., & Eickhoff, S. B. (2010). ALE meta-analysis of action observation and imitation in the human brain. NeuroImage, 50, 1148–1167.
Chong, T. T.-J., Cunnington, R., Williams, M. A., Kanwisher, N., & Mattingley, J. B. (2008). fMRI adaptation reveals mirror neurons in human inferior parietal cortex. Current Biology, 18, 1576–1580.
Cook, R., Bird, G., Catmur, C., Press, C., & Heyes, C. (2014). Mirror neurons: From origin to function. Behavioral and Brain Sciences, 37, 177–192.
Copelli, F., Rovetti, J., Ammirante, P., & Russo, F.A. (in press). Temporal structure of visually observed biological movement is revealed in frontal areas of the human mirror neuron system. Experimental Brain Research.
Crawcour, S., Bowers, A., Harkrider, A., & Saltuklaroglu, T. (2009). Mu wave suppression during the perception of meaningless syllables: EEG evidence of motor recruitment. Neuropsychologia, 47, 2558–2563.
Cross, E. S., Kraemer, D. J. M., Hamilton, A. F. d. C., Kelley, W. M., & Grafton, S. T. (2009). Sensitivity of the action observation network to physical and observational learning. Cerebral Cortex, 19, 315–326.
Cunnington, R., Windischberger, C., & Moser, E. (2005). Premovement activity of the pre-supplementary motor area and the readiness for action: Studies of time-resolved event-related functional MRI. Human Movement Science, 24, 644–656.
Delorme, A., & Makeig, S. (2004). EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. Journal of Neuroscience Methods, 134, 9–21.
Delorme, A., Sejnowski, T., & Makeig, S. (2007). Enhanced detection of artifacts in EEG data using higher-order statistics and independent component analysis. NeuroImage, 34, 1443–1449.
Denis, D., Rowe, R., Williams, A. M., & Milne, E. (2017). The role of cortical sensorimotor oscillations in action anticipation. NeuroImage, 146, 1102–1114.
Dimberg, U. (1982). Facial reactions to facial expressions. Psychophysiology, 19, 643–647.
Dimberg, U., Thunberg, M., & Elmehed, K. (2000). Unconscious facial reactions to emotional facial expressions. Psychological Science, 11, 86–89.
Du, Y., Buchsbaum, B. R., Grady, C. L., & Alain, C. (2014). Noise differentially impacts phoneme representations in the auditory and speech motor systems. Proceedings of the National Academy of Sciences, 111, 7126–7131.
EEGLAB Wiki: Chapter 05: Component Clustering Tools (2014, July). Swartz Centre for Computational Neuroscience. Retrieved October 1, 2019, from https://sccn.ucsd.edu/wiki/Chapter_05:_Component_Clustering_Tools
Elfenbein, H. A., & Ambady, N. (2002). On the universality and cultural specificity of emotion recognition: A meta-analysis. Psychological Bulletin, 128, 203–235.
Etkin, A., Büchel, C., & Gross, J. J. (2015). The neural bases of emotion regulation. Nature Reviews Neuroscience, 16, 693–700.
Fox, N. A. et al. (2016). Assessing human mirror activity with EEG mu rhythm: A meta-analysis. Psychological Bulletin, 142, 291–313.
Fried, I., Wilson, C. L., MacDonald, K. A., & Behnke, E. J. (1998). Electric current stimulates laughter. Nature, 391, 650–650.
Gallese, V. (2007). Before and below ‘theory of mind’: Embodied simulation and the neural correlates of social cognition. Philosophical Transactions of the Royal Society B: Biological Sciences, 362, 659–669.
Goldman, A. I. (2006). Simulating minds. Oxford University Press.
Hammers, A. et al. (2007). Statistical neuroanatomy of the human inferior frontal gyrus and probabilistic atlas in a standard stereotaxic space. Human Brain Mapping, 28, 34–48.
Hickok, G. (2009). Eight problems for the mirror neuron theory of action understanding in monkeys and humans. Journal of Cognitive Neuroscience, 21, 1229–1243.
Hickok, G. (2010). The role of mirror neurons in speech perception and action word semantics. Language and Cognitive Processes, 25, 749–776.
Hickok, G., & Poeppel, D. (2000). Towards a functional neuroanatomy of speech perception. Trends in Cognitive Sciences, 4, 131–138.
Hickok, G., & Poeppel, D. (2004). Dorsal and ventral streams: A framework for understanding aspects of the functional anatomy of language. Cognition, 92(1-2), 67–99.
Hickok, G., & Poeppel, D. (2007). The cortical organization of speech processing. Nature Reviews Neuroscience, 8, 393–402.
Hickok, G., & Poeppel, D. (2012). The cortical organization of speech processing: Feedback control and predictive coding the context of a dual-stream model. Journal of Communication Disorders, 45, 393–402.
Hobson, H. M., & Bishop, D. V. M. (2017). The interpretation of mu-ERD as an index of mirror neuron activity: Past, present and future. Royal Society Open Science, 4(3), 1–22.
Holm, S. (1979). A simple sequentially rejective multiple test procedure. Scandinavian Journal of Statistics, 7, 65–70.
Homan, R. W., Herman, J., & Purdy, P. (1987). Cerebral location of international 10–20 system electrode placement. Electroencephalography and Clinical Neurophysiology, 66, 376–382.
Horn, B. K. P., & Schunck, B. G. (1981). Determining optical flow. Artificial Intelligence, 17, 185–203.
Iacoboni, M. (2009). Imitation, empathy, and mirror neurons. Annual Review of Psychology, 60, 653–670.
Ipser, A., & Cook, R. (2016). Inducing a concurrent motor load reduces categorization precision for facial expressions. Journal of Experimental Psychology: Human Perception and Performance, 42, 706–718.
James, W. (1884). What is an emotion? Mind, 9, 188–205.
Jeannerod, M. (2001). Neural simulation of action: A unifying mechanism for motor cognition. NeuroImage, 14, S103–S109.
Jenson, D., Bowers, A. L., Harkrider, A. W., Thornton, D., Cuellar, M., & Saltuklaroglu, T. (2014). Temporal dynamics of sensorimotor integration in speech perception and production: independent component analysis of EEG data. Frontiers in Psychology, 5, 1–17.
Karakale, O., Moore, M. R., & Kirk, I. J. (2019). Mental simulation of facial expressions: Mu suppression to the viewing of dynamic neutral face videos. Frontiers in Human Neuroscience, 13, 1–9.
Kilner, J. M. (2011). More than one pathway to action understanding. Trends in Cognitive Sciences, 15, 352–357.
Kilner, J. M., Friston, K. J., & Frith, C. D. (2007). Predictive coding: An account of the mirror neuron system. Cognitive Processing, 8, 159–166.
Klimesch, W. (2012). Alpha-band oscillations, attention, and controlled access to stored information. Trends in Cognitive Sciences, 16, 606–617.
Kreifelts, B., Jacob, H., Brück, C., Erb, M., Ethofer, T., & Wildgruber, D. (2013). Non-verbal emotion communication training induces specific changes in brain function and structure. Frontiers in Human Neuroscience, 7, 1–14.
Krolak-Salmon, P., Hénaff, M.-A., Vighetto, A., Bauchet, F., Bertrand, O., Mauguière, F., & Isnard, J. (2006). Experiencing and detecting happiness in humans: The role of the supplementary motor area. Annals of Neurology, 59, 196–199.
Künecke, J., Hildebrandt, A., Recio, G., Sommer, W., & Wilhelm, O. (2014). Facial EMG responses to emotional expressions are related to emotion perception ability. PLOS One, 9(1), 1–10.
Lakens, D., & Caldwell, A. R. (2021). Simulation-based power-analysis for factorial analysis of variance designs. Advances in Methods and Practices in Psychological Science, 4(1), 1–14.
Larsen, J. T., Norris, C. J., & Cacioppo, J. T. (2003). Effects of positive and negative affect on electromyographic activity over zygomaticus major and corrugator supercilii. Psychophysiology, 40, 776–785.
Lepage, J.-F., & Théoret, H. (2006). EEG evidence for the presence of an action observation-execution matching system in children. European Journal of Neuroscience, 23, 2505–2510.
Lima, C. F., Krishnan, S., & Scott, S. K. (2016). Roles of supplementary motor areas in auditory processing and auditory imagery. Trends in Neurosciences, 39, 527–542.
Livingstone, S. R., & Palmer, C. (2016). Head movements encode emotions during speech and song. Emotion, 16, 365–380.
Livingstone, S. R., & Russo, F. A. (2018). The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLOS ONE, 13, 1–35.
Livingstone, S. R., Peck, K., & Russo, F. A. (2013). Acoustic differences in the speaking and singing voice. Proceedings of Meetings on Acoustics, 19, 1–3.
Livingstone, S. R., Vezer, E., McGarry, L. M., Lang, A. E., & Russo, F. A. (2016). Deficits in the mimicry of facial expressions in Parkinson’s disease. Frontiers in Psychology, 7, 1–12.
MacQueen, J. B. (1967). Some methods for classification and analysis of multivariate observations (Vol. 1). University of California Press.
Makeig, S., Debener, S., Onton, J., & Delorme, A. (2004a). Mining event-related brain dynamics. Trends in Cognitive Sciences, 8, 204–210.
Makeig, S., Delorme, A., Westerfield, M., Jung, T.-P., Townsend, J., Courchesne, E., & Sejnowski, T. J. (2004b). Electroencephalographic brain dynamics following manually responded visual targets. PLOS Biology, 2, 1747–1762.
Mayka, M. A., Corcos, D. M., Leurgans, S. E., & Vaillancourt, D. E. (2006). Three-dimensional locations and boundaries of motor and premotor cortices as defined by functional brain imaging: A meta-analysis. NeuroImage, 31, 1453–1474.
McGarry, L. M., Pineda, J. A., & Russo, F. A. (2015). The role of the extended hMNS in emotional and nonemotional judgments of human song. Cognitive, Affective, & Behavioral Neuroscience, 15, 32–44.
McGarry, L. M., Russo, F. A., Schalles, M. D., & Pineda, J. A. (2012) Audio-visual facilitation of the mu rhythm. Experimental Brain Research, 218, 527–538.
McGettigan, C., Walsh, E., Jessop, R., Agnew, Z. K., Sauter, D. A., Warren, J. E., & Scott, S. K. (2013). Individual differences in laughter perception reveal roles for mentalizing and sensorimotor systems in the evaluation of emotional authenticity. Cerebral Cortex, 25, 246–257.
Meister, I. G., Wilson, S. M., Deblieck, C., Wu, A. D., & Iacoboni, M. (2007). The essential role of premotor cortex in speech perception. Current Biology, 17, 1692–1696.
Miyakoshi, M. (2020, January). Makoto's preprocessing pipeline. Swartz Centre for Computational Neuroscience. https://sccn.ucsd.edu/wiki/Makoto's_preprocessing_pipeline
Molenberghs, P., Cunnington, R., & Mattingley, J. B. (2009) Is the mirror neuron system involved in imitation? A short review and meta-analysis. Neuroscience & Biobehavioral Reviews, 33, 975–980.
Moore, M. R., & Franz, E. A. (2017). Mu rhythm suppression is associated with the classification of emotion in faces. Cognitive, Affective, & Behavioral Neuroscience, 17, 224–234.
Moore, A., Gorodnitsky, I., & Pineda, J. (2012). EEG mu component responses to viewing emotional faces. Behavioural Brain Research, 226, 309–316.
Muthukumaraswamy, S. D., Johnson, B. W., & McNair, N. A. (2004). Mu rhythm modulation during observation of an object-directed grasp. Cognitive Brain Research, 19, 195–201.
Oberman, L. M., & Ramachandran, V. S. (2007). The simulating social mind: the role of the mirror neuron system and simulation in the social and communicative deficits of autism spectrum disorders. Psychological bulletin, 133(2), 310.
Oberman, L. M., Winkielman, P., & Ramachandran, V. S. (2007). Face to face: Blocking facial mimicry can selectively impair recognition of emotional expressions. Social Neuroscience, 2, 167–178.
Oberman, L. M., Winkielman, P., & Ramachandran, V. S. (2009). Slow echo: facial EMG evidence for the delay of spontaneous, but not voluntary, emotional mimicry in children with autism spectrum disorders. Developmental Science, 12, 510–520.
Peelle, J. E. (2018). Listening effort: How the cognitive consequences of acoustic challenge are reflected in brain and behavior. Ear & Hearing, 39, 204–214.
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision, 10, 437–442.
Peretz, I., Gosselin, N., Belin, P., Zatorre, R. J., Plailly, J., & Tillmann, B. (2009). Music lexical networks. Annals of the New York Academy of Sciences, 1169, 256–265.
Perry, A., Troje, N. F., & Bentin, S. (2010). Exploring motor system contributions to the perception of social information: Evidence from EEG activity in the mu/alpha frequency range. Social Neuroscience, 5, 272–284.
Pineda, J. A. (2008). Sensorimotor cortex as a critical component of an “extended” mirror neuron system: Does it solve the development, correspondence, and control problems in mirroring? Behavioral and Brain Functions, 4, 1–16.
Pineda, J. A., & Hecht, E. (2009). Mirroring and mu rhythm involvement in social cognition: Are there dissociable subcomponents of theory of mind? Biological Psychology, 80, 306–314.
Pion-Tonachini, L., Kreutz-Delgado, K., & Makeig, S. (2019). ICLabel: An automated electroencephalographic independent component classifier, dataset, and website. NeuroImage, 198, 181–197.
Ponari, M., Conson, M., D’Amico, N. P., Grossi, D., & Trojano, L. (2012). Mapping correspondence between facial mimicry and emotion recognition in healthy subjects. Emotion, 12, 1398–1403.
Press, C., Weiskopf, N., & Kilner, J. M. (2012). Dissociable roles of human inferior frontal gyrus during action execution and observation. NeuroImage, 60, 1671–1677.
Prochazkova, E., & Kret, M. E. (2017). Connecting minds and sharing emotions through mimicry: A neurocognitive model of emotional contagion. Neuroscience & Biobehavioral Reviews, 80, 99–114.
R Core Team (2020). R: A language and environment for statistical computing. R Foundation for Statistical Computing. Retrieved from https://www.R-project.org/
Rizzolatti, G., & Craighero, L. (2004). The mirror-neuron system. Annual Review of Neuroscience, 27, 169–192.
Rizzolatti, G., & Luppino, G. (2001). The cortical motor system. Neuron, 31, 889–901.
Rochas, V., Gelmini, L., Krolak-Salmon, P., Poulet, E., Saoud, M., Brunelin, J., & Bediou, B. (2012). Disrupting pre-SMA activity impairs facial happiness recognition: An event-related TMS study. Cerebral Cortex, 23, 1517–1525.
Rousseeuw, P. J., Ruts, I., & Tukey, J. W. (1999). The bagplot: A bivariate boxplot. The American Statistician, 53, 382–387.
Russo, F. A. (2020). Motor system involvement in the perception of singing. In F. A. Russo, B. Ilari, & A. J. Cohen (Eds.), The Routledge companion to interdisciplinary studies in singing, volume I: Development (pp. 276–288). Routledge.
Sarkheil, P., Goebel, R., Schneider, F., & Mathiak, K. (2013). Emotion unfolded by motion: a role for parietal lobe in decoding dynamic facial expressions. Social Cognitive and Affective Neuroscience, 8, 950–957.
Scherer, K. (2003). Vocal communication of emotion: A review of research paradigms. Speech Communication, 40, 227–256.
Scott, S. K., Rosen, S., Wickham, L., & Wise, R. J. S. (2004). A positron emission tomography study of the neural basis of informational and energetic masking effects in speech perception. The Journal of the Acoustical Society of America, 115, 813–821.
Seitz, R. J., Schäfer, R., Scherfeld, D., Friederichs, S., Popp, K., Wittsack, H.-J., … Franz, M. (2008). Valuating other people’s emotional face expression: a combined functional magnetic resonance imaging and electroencephalography study. Neuroscience, 152, 713–722.
Shahin, A. J., Bishop, C. W., & Miller, L. M. (2009). Neural mechanisms for illusory filling-in of degraded speech. NeuroImage, 44, 1133–1143.
Shamay-Tsoory, S. G. (2011). The neural bases for empathy. The Neuroscientist, 17, 18–24.
Sumby, W. H., & Pollack, I. (1954). Visual contribution to speech intelligibility in noise. The Journal of the Acoustical Society of America, 26, 212–215.
Van der Gaag, C., Minderaa, R. B., & Keysers, C. (2007). Facial expressions: What the mirror neuron system can and cannot tell us. Social Neuroscience, 2, 179–222.
Vernet, M., Quentin, R., Chanes, L., Mitsumasu, A., & Valero-Cabré, A. (2014). Frontal eye field, where art thou? Anatomy, function, and non-invasive manipulation of frontal regions involved in eye movements and associated cognitive operations. Frontiers in Integrative Neuroscience, 8, 1–24.
Warren, J. E. et al. (2006). Positive emotions preferentially engage an auditory-motor “mirror” system. Journal of Neuroscience, 26, 13067–13075.
Whelan, R. (2008). Effective analysis of reaction time data. The Psychological Record, 58, 475–482.
Wicker, B., Keysers, C., Plailly, J., Royet, J.-P., Gallese, V., & Rizzolatti, G. (2003). Both of us disgusted in my insula. Neuron, 40, 655–664.
Wilson, S. M., Saygin, A. P., Sereno, M. I., & Iacoboni, M. (2004). Listening to speech activates motor areas involved in speech production. Nature Neuroscience, 7, 701–702.
Wood, A., Rychlowska, M., Korb, S., & Niedenthal, P. (2016). Fashioning the face: Sensorimotor simulation contributes to facial expression recognition. Trends in Cognitive Sciences, 20, 227–240.
Yu, C.-L., & Chou, T.-L. (2018). A dual route model of empathy: A neurobiological prospective. Frontiers in Psychology, 9, 1–5.
Zaki, J., Weber, J., Bolger, N., & Ochsner, K. (2009). The neural bases of empathic accuracy. Proceedings of the National Academy of Sciences, 106, 11382–11387.
Zhang, Y., Padmanabhan, A., Gross, J. J., & Menon, V. (2019). Development of human emotion circuits investigated using a Big-Data analytic approach: Stability, reliability, and robustness. The Journal of Neuroscience, 39, 7155–7172.
Acknowledgments
The authors thank Carson Pun for his help with technical aspects of the EEG equipment; Sean Gilmore and Emily Wood for their help coding the experiment; Makoto Miyakoshi for his help with EEGLAB; and Michael Zara for conducting the optical flow analysis.
Funding
This work was supported by a Discovery grant awarded from the Natural Sciences and Engineering Research Council of Canada [grant number RGPIN-2017-06969] to F.A.R.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
The authors have no conflicts of interest to report.
Open Practices
Data and statistical analysis code for all analyses reported in this study are available at https://osf.io/xb5h8/. The study was not preregistered.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Rovetti, J., Copelli, F. & Russo, F.A. Audio and visual speech emotion activate the left pre-supplementary motor area. Cogn Affect Behav Neurosci 22, 291–303 (2022). https://doi.org/10.3758/s13415-021-00961-2
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13415-021-00961-2