
Abstract
The paper describes the automated seismic monitoring system for the European Arctic based on an international seismic network located in the region. The core of the system is the NSDL software package developed by the authors for automated detection and location of seismic events. NSDL is designed to automatically monitor the seismic activity of a region using a seismic network, seismic arrays, or individual three-component seismic stations. The described system has two levels. The first level consists of single-station data-processing programs that implement algorithms for detecting and prelocating seismic events based on data from individual three-component seismic stations and arrays. The second level is a program for associating individual station data-processing results, which performs joint location over the network based on events and phases of seismic waves detected at the first processing level. NSDL makes it possible to use a set of 1D layered velocity models for locating remote events the wave propagation paths from which cross regions of the medium with different velocity properties. Decisions about the truth or falsity of the detected candidate events are made with a Bayesian classifier based on the evaluation of a number of amplitude, spectral, and polarization parameters both for single-station and joint (network) processing of seismic events. The use of the seismic monitoring system for the Arctic region showed high reliability of automatically obtained results, significantly sped up the compilation of the final analyst-verified catalogs, and significantly increased the representativeness of the resulting bulletin due to weak events. The level of detail achieved by the described system makes it possible to take a fresh look at the development and structure of the seismic process in the European Arctic and in particular to record seismic events associated not only with tectonic processes but also with cryospheric destruction processes.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
INTRODUCTION
Active development of automated seismic monitoring systems began simultaneously with the transition of global monitoring networks to digital data recording and processing. To date, such systems are being developed both by global consortia of scientific institutions, which then promote their products to regional monitoring centers (Olivieri and Clinton, 2012), and by local research groups for solving specific problems and for specific seismic networks (Lindblom, 2011; Kortström et al., 2012, 2016; Stepnov et al., 2017).
The use of automated approaches to detecting and locating seismic events can significantly increase the efficiency of obtaining information about earthquakes, lower the magnitude detection threshold, and thereby increase the integrity and representativeness of the resulting catalogs. In this paper, the authors present an automated seismic monitoring system based on an arbitrary seismic network or individual seismic stations called NSDL (Asming and Fedorov, 2015). Currently, NSDL is implemented for automatic processing of data from the international seismic network in the Arctic, where a seismic monitoring system is being created (Danilov et al., 2014; Rogozhin et al., 2015; Gibbons et al., 2015).
The network data collection and processing center was established at the Kola Branch of the Geophysical Survey of the Russian Academy of Sciences (KB GS RAS). As of the end of 2017, this network comprises 19 seismic stations of Russian and foreign organizations engaged in seismic monitoring of the western sector of the Arctic (Fig. 1). The KBS, FAUS, TRO, HAMF, VADS, and KTK1 stations are owned or serviced by the University of Bergen (Norway). The seismic arrays SPI and ARCESS belong to the Norwegian Seismic Array (NORSAR). The PAAN station was jointly created and serviced by the KB GS RAS and the Institute of Geology of the Karelian Research Centre of the Russian Academy of Sciences (IG KRC RAS). The HSPB station belongs to the Institute of Geophysics of the Polish Academy of Sciences (PAN). The remaining stations are serviced by KB GS RAS.

Network of seismic monitoring stations of western Arctic included in NSDL automated system deployed by KB GS RAS.
Data from all stations are transmitted via the Internet in close to real time to the data collection and processing center of KB GS RAS in Apatity, where they are automatically converted to the internal data format and processed by the NSDL software. The results of online processing are available on the KB GS RAS website.
NSDL ARCHITECTURE
The NSDL software is structurally divided into two large functional parts. The first includes a sensor and a locator of regional (the distance between the station and the source is no more than 3000 km) seismic events for individual stations, NSS, and some additional programs for data preparation (data conversion) and visualization of results. It can analyze data from single seismic stations (both in near real time and postevent), find seismic events in them, preliminarily determine the epicentral coordinates, and save records of these events as individual files, and the event parameters, into bulletins and a database.
An individual seismic station means an arbitrary set of seismic sensors (both three- and one-component) possibly at a distance from each other in a certain area that can be considered as a single point on a geographical scale. Thus, the concept of an individual seismic station includes both single three-component stations and seismic arrays of arbitrary configuration. The system can operate with almost any combination of sensors.
Messages that can be transmitted to warning programs are generated as events are detected and their locations determined. Auxiliary files with information about the detected events and about all seismic wave arrivals detected at the station are also generated. These files arrive in the program for association of detected waves (associator), called NAS, which is the second part of the system. The associator combines data from several seismic stations; more accurately locates the detected events, if possible; discards false activations of the single-station sensor; and stores the results in the form of a database and a bulletin.
Thus, the NSDL-based automated seismic monitoring system contains several copies of the NSS program, one copy per station, and one general associator.
The starting points for the association are seismic events detected by individual copies of the NSS program and strong seismic wave arrivals that are not associated with each other at the single-station processing stage.
As a result, the end user is presented with an automatic bulletin of detected seismic events from the network and a set of single-station bulletins.
NSS Single Station Processing Program
The NSS program (Asming and Fedorov, 2015) processes data from one individual seismic station. Detection and location algorithms incorporated in this program make it possible to process data from both individual three-component seismic stations and seismic arrays consisting of an arbitrary number of seismometers and with almost any combination of sensors.
The NSS program outputs files and lists of detected events and seismic waves, which are subsequently fed to the NAS program for association with data from other seismic stations. NSS also generates preliminary bulletins with the results of detecting and locating events by a single station and a database with fragments of waveforms. In addition, NSS can send messages to monitoring programs for prompt notification of observed seismic events. The ability to detect and locate a seismic event by only one station is an extremely important feature of the NSDL system. In the case of a widely spaced network, when large distances between seismic stations significantly reduce the likelihood that weak seismic events will be recorded by more than one station, the possibility of highly reliable detection and fairly accurate determination of the epicentral coordinates significantly increase the level of detail of seismic monitoring.
The general operating principle of the NSS program is as follows. The program analyzes a fragment of waveforms and filters it in the user-defined frequency range.
Filtered records are used to generate amplitude envelopes that are used to detect the so-called phases, i.e., possible arrivals of seismic waves to the station. To do this, the original filtered seismic record is averaged in a narrow moving time window. Windows with a width of 1 s and with an offset of 0.1 s are usually used. Thus, a set of nonnegative amplitudes with an offset of 0.1 s is obtained. Then the noise level is estimated by a statistical algorithm. Next, the noise is subtracted from the original average trace, and the result is divided by the noise. We will further call this trace the envelope.
The NSS program uses envelopes constructed in the manner described above or SNR (signal/noise) traces instead of the original records for detection. Therefore, the traditional algorithm for searching for the maxima of the STA/LTA ratio (Freiberger, 1963) becomes meaningless, because the noise in the SNR trace is already taken into account. The STA/LTA algorithm is used instead. It is implemented in the same way except that subtraction is used instead of division. The calculated difference means the change in the SNR over time. Next, local maxima that exceed a certain threshold are sought in the obtained STA/LTA trace. Each such maximum is considered the expected seismic wave arrival time.
Wave arrival times are determined by the STA/LTA algorithm with some inaccuracy due to both averaging and offset of the maxima of the STA/LTA trace with respect to the actual wave arrival. Therefore, the arrival times are set using an autoregressive algorithm.
When the phases are selected, the program begins to iterate over their pairs, such that the time difference between them is greater than some minimum and less than the maximum. The hypothesis is tested for each pair of phases that the first phase is the P- and the second is the S-wave generated by the same seismic event. To do this, a complex rating is calculated, which depends on the polarization estimates of the phases, the estimates of joint analysis of seismic array sensors, the geometrical parameters of the envelope corresponding to the phases, etc. A large number of parameters of the detected phases are estimated. At the last stage, these parameters reach the Bayesian classifier-based statistical analysis system, which decides if the probable seismic event is true. The experience of using Bayesian classifiers in seismology was described in (Asming et al., 2015).
The construction and application of the Bayesian classifier in the NSS program can be briefly described as follows. An experienced analyst processes a large sample of sensor results (from several hundred to several thousand) and marks the presented solutions as true or false to construct a classifier. At the same time, as mentioned earlier, the NSS program determines a set of parameters describing the amplitude, geometric, polarization, and some other signal characteristics for each candidate event. A special program for constructing the Bayesian classifier selects the threshold values of previously defined parameters so as to maximally separate true and false decisions after processing and classification of the original sample by a human analyst. This set of thresholds is called the Bayesian classifier or decision rule and is applied to all detected candidate seismic events.
When a pair of phases is associated, i.e., when they are attributed to the same event and classified by the Bayesian classifier as a true event, the location procedure is performed. The time difference between the detected primary (P) and secondary (S) waves with the regional velocity model is used to estimate the distance from the event to the station (epicentral distance), and the polarization and/or results of the beamforming algorithm (in the case of seismic array data processing) are used to estimate the back azimuth of wave arrivals (Ringdal and Kvaerna, 1989). Prelocation is carried out by epicentral distance and back azimuth to the source.
Program for Associating Data from Several NAS Seismic Stations
The purpose of the NAS program is to associate the results obtained by copies of the NSS program that process the data of individual seismic stations of the seismic network with each other. The program associates phases (arrivals of seismic waves) with seismic events, locates them, and compiles a bulletin and a database of seismic events.
The results of the NSS programs (lists of seismic events detected at one station, lists of all detected phases with their azimuthal estimates obtained either from polarization of the waves or from the beamforming method according to the seismic data) are fed to the program’s input.
The final association and location of hypocenters of seismic events in the NAS program is implemented by a method conceptually similar to the generalized beamforming method (Ringdal and Kvaerna, 1989).
Unlike the traditional application of this method, when seismic events are sought over a large time period in a large area of the Earth, the NAS follows the list of events detected by single stations and performs a grid search for each such event in the bounded spacetime region in the vicinity of the event. As a rule, in a circle with a radius of 250 km around the initial location of the event and for times in the source (t0 – 30 s, t0 + 30 s), where t0 is the time in the source of the prototype event.
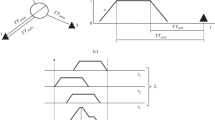
After selecting the next source (located by the NSS program by one station), the NAS generates a grid in the area (circle) surrounding the initial coordinates, which consists of circular cells that cover the entire area. An example of such a search grid for an earthquake in the Kandalaksha Gulf is shown in Fig. 2. The rating, an estimate that a seismic event occurred in this particular cell, is calculated for each grid cell.

Example of setting initial grid for location of seismic event. (1) Cell centers, (2) grid center, (3) cells, and (4) grid border.
Then the grid is reduced. Three-fourths of the cells with the lowest ratings are discarded, and each remaining cell is divided into four smaller ones. Ratings are calculated for them again. Moreover, the size of the new cells is selected so that the number of cells into which the grid is divided remains almost unchanged.
This procedure is performed several times (iterations). If, as a result, the highest rating of the remaining cell exceeds a certain threshold, we assume that a seismic event has occurred in it. The program takes phases (arrivals of waves) that were associated with a given cell (i.e., identified as arrivals of P- and S-waves from an event that occurred in this cell) and locates the event using a method that minimizes the time error at the source.
The result (coordinates, depths, and magnitudes of events) is recorded in seismic bulletins.
The selection of an adequate velocity model of the medium is extremely important for the ultimately locating the hypocenter of a seismic event. Unlike the NSS program, which uses only seismic wave travel time tables calculated with a horizontally layered model of the medium for a depth of 0, the NAS program uses a more complex scheme for specifying models of media and calculating the travel times.
Velocity Models
Velocity models are placed in special configuration files and consist of submodels, each of which is considered valid within a certain geographic contour. Submodels can be of two types.
The first type is velocity models given by an ordinary horizontal velocity profile of the medium. Each such model operates in its own contour, and the Bondár regionalization method (István Bondár) (Bondár and North, 1999) is used for calculating wave travel along paths that cross several contours (Bondár and North, 1999), which makes it possible to obtain a smooth high-speed trace. Regionalization will be described in more detail below. Recalculation from a horizontally layered profile to travel time tables occurs directly when the model is loaded, i.e., when the NAS program is launched.
The second type is high-velocity models for individual stations. These are tables of so-called pseudovelocities, which are precalculated by 3D-modeling programs (e.g., the Seismic Configurator program). These models have a higher priority than horizontally layered models. Bondár regionalization is not applied to them.
We mean the following value for the pseudodistance between two points with coordinates (φ1, λ1, h1) and (φ2, λ2, h2), respectively:
where A is the angular distance between points on the Earth’s surface, d is the distance corresponding to one angular degree on the surface of the Earth (111.2 km). The pseudovelocity is the pseudodistance between two points divided by the travel time between them. We denote it as pV.
Velocity models of the second type are pseudovelocity tables of P- and S-waves for a specific station, specific azimuth, and pseudodistance from source to station, i.e., functions like \(pV = pV(\alpha ,R,h)\), where α is the azimuth of the event, R is the distance to the event, and h is the depth.
Let us return to the horizontally layered models and Bondár regionalization. The essence of regionalization is shown in Fig. 3.

Bondár regionalization \(TT(d,h) = \frac{{{{d}_{1}}T{{T}_{1}}(d,h) + {{d}_{2}}T{{T}_{2}}(d,h) + {{d}_{3}}T{{T}_{3}}(d,h)}}{{{{d}_{1}} + {{d}_{2}} + {{d}_{3}}}},\)\(d = {{d}_{1}} + {{d}_{2}} + {{d}_{3}}\).
If the points between which the travel time is calculated lie in the contours where different velocity models operate (see Fig. 3), the program calculates the travel times individually for each model (but for the common path between the points). The resulting time is obtained as a weighted combination of these times, and the weights are parts of the path that the wave travels in the coverage zones of different models.
The calculation of weighted combinations is somewhat simplified in the NAS program. The program generates points on the surface of a sphere along the shortest path from the point (φ1, λ1) to the point (φ2, λ2) with a constant step of 0.1°. It is determined to the contour of the model in which the point fell for each point. The travel times corresponding to the contours to which these points fall are averaged. If the step tends to 0, this is completely equivalent to averaging by Bondár regionalization, but the computational resources are far fewer.
NSDL SYSTEM APPLICATION
As mentioned in the Introduction, the automated seismic monitoring system for the western sector of the European Arctic has now been developed using the NSDL system, which combines data from Russian, Norwegian, and Polish seismic stations located on the northern Baltic Shield and the Svalbard archipelago. This system has been operating in test mode since 2016. It was expanded in 2017 by adding new seismic stations located in northeastern Norway and in the northern Karelia.
The results of the NSDL complex automatically fill the corresponding database and are hosted on the KB GS RAS website (www.krsc.ru). A registered user can view a real-time map of seismic events as well as detailed information about the parameters of detected events and fragments of waveforms of records (Fig. 4).

Example of mapping of real-time results of NSDL system on KB GS RAS website (www.krsc.ru).
The results of the automated monitoring system in routine mode are viewed by a human analyst. False sensor activations are removed from the final catalog and, if necessary, the locations of the detected events are refined by the analyst. Analysis of the statistics of manual checks of operation of the NSDL automated system for 11 months of 2017 showed that only 18% of seismic events in the automatic catalog are false. At the same time, 55% of them fall on decisions obtained according to data from only one station. Such a percentage of false positives is more than sufficient for the operational control of such a vast territory taking into account the rather widely spaced seismic network.
The system detected and located more than 33 000 seismic events and ensured the representative magnitudes in the resulting catalog of M = 0.5 during the aforementioned time period in the area of the Svalbard archipelago alone. This level of detail of the regional seismic pattern of and the efficiency of its presentation to researchers was previously unattainable due to physical limitations and very high laboriousness in processing such a dataset. Regional catalogs, in particular, the NORSAR catalog, for the area of the Svalbard archipelago are limited to a magnitude of M = 2.
Lowering the magnitude threshold and significantly increasing the integrity of data provided by the described system allow a fundamentally different level of detail in the regional seismic pattern for an in-depth study of dynamic processes not only in the lithosphere but also in the Arctic cryosphere. Analysis of minor seismicity of the Svalbard archipelago shows that a significant number of events detected by the system are confined to glacier destruction zones and are characterized by specific attributes of icequake records.
CONCLUSIONS
Thus, implementation of the NSDL automated seismic monitoring system has significantly increased the efficiency of obtaining information about seismic events occurring in this region. The high reliability of the results achieved due to the use of intelligent decision-making methods can significantly reduce the labor costs in preparing a final, verified, and analyst-refined catalog of recorded seismic events. In addition, the integrity and representativeness of the final catalog are increased due to the use of highly sensitive methods for detecting seismic events.
The flexible structure of this automated seismic monitoring system makes it easy to scale by adding new seismic stations or use in any other world regions for both local and regional monitoring.
REFERENCES
Asming, V.E. and Fedorov, A.V., Possibility of using a single three-component station automatic detector–locator for detailed seismological observations, Seism. Instrum., 2015, vol. 51, no. 3, pp. 201–208. https://doi.org/10.3103/S0747923915030032
Asming, V.E., Kremenetskaya, E.O., Vinogradov, Yu.A., and Fedorov, A.V., Application of naïve Bayesian classifiers in seismology, Seism. Prib., 2015, vol. 51, no. 4, pp. 29–40.
Bondár, I. and North, R., Development of calibration techniques for the Comprehensive Nuclear-Test-Ban Treaty (CTBT) international monitoring system, Phys. Earth Planet. Inter., 1999, vol. 113, nos. 1–4, pp. 11–24. https://doi.org/10.1016/S0031-9201(99)00033-3
Danilov, A.V., Antonovskaya, G.N., and Konechnaya, Ya.V., Specific features of seismic stations installation in the Arctic Region of Russia, Seism. Instrum., 2014, vol. 50, no. 3, pp. 206–220.
Freiberger, W.F., An approximate method in signal detection, Q. Appl. Math., 1963, vol. 20, pp. 373–378.
Gibbons, S.J., Asming, V., Fedorov, A., Fyen, J., Kero, J., Kozlovskaya, E., Kværna, T., Liszka L., Näsholm, S.P., Raita, T., Roth, M., Tiira, T., and Vinogradov, Yu., The European Arctic: A laboratory for seismoacoustic studies, Seism. Res. Lett. 2015, vol. 86, no. 3, pp. 917–928. https://doi.org/10.1785/0220140230
Kortström, J., Uski, M., Tiira, T., and Korja, A., Data Processing and Analysis System for the Pyhäjoki Seismic Network, Report T-86, Helsinki: Univ. Helsinki, 2012.
Kortström, J., Tiira, T., and Kaisko, O., Automatic data processing and analysis system for monitoring region around a planned nuclear power plant, Adv. Geosci., 2016, vol. 41, pp. 73–81. https://doi.org/10.5194/adgeo-41-73-2016
Lindblom, E., Microearthquake study of end-glacial faults in Northern Sweden, Licentiate thesis, Uppsala Universitet, Uppsala, Sweden, 2011. http://uu.diva-portal.org/smash/get/diva2:456600/FULLTEXT01.pdf. Accessed October 31, 2018.
Olivieri, M. and Clinton, J., An almost fair comparison between Earthworm and SeisComp3, Seismol. Res. Lett., 2012, vol. 83, no. 4, pp. 720–727. https://doi.org/10.1785/0220110111
Ringdal, F. and Kvaerna, T., A multi-channel processing approach to real time network detection, phase association, and threshold monitoring, Bull. Seismol. Soc. Am., 1989, vol. 79, no. 6, pp. 1927–1940.
Rogozhin, E.A., Antonovskaya, G.N., and Kapustyan, N.K., Current state and prospects of the development of an Arctic seismic monitoring system, Seism. Instrum., 2015, vol. 52, no. 2, pp. 144–153.
Stepnov, A.A., Konovalov, A.V., Gavrilov, A.V., and Manaychev, K.A., Earthworm-based automatic system for real-time calculation of local earthquake source parameters, Seism. Instrum., 2017, vol. 53, no. 4, pp. 267–279. https://doi.org/10.3103/S0747923917040107
Author information
Authors and Affiliations
Corresponding author
Additional information
Translated by O. Pismenov
About this article

Cite this article
Fedorov, A.V., Asming, V.E., Jevtjugina, Z.A. et al. Automated Seismic Monitoring System for the European Arctic. Seism. Instr. 55, 17–23 (2019). https://doi.org/10.3103/S0747923919010067
Published:
Issue Date:
DOI: https://doi.org/10.3103/S0747923919010067