
Abstract
In this paper, we propose a self adaptive spectral conjugate gradient-based projection method for systems of nonlinear monotone equations. Based on its modest memory requirement and its efficiency, the method is suitable for solving large-scale equations. We show that the method satisfies the descent condition \(F_{k}^{T}d_{k}\leq -c\|F_{k}\|^{2}, c>0\), and also prove its global convergence. The method is compared to other existing methods on a set of benchmark test problems and results show that the method is very efficient and therefore promising.
Similar content being viewed by others


Introduction
In this paper, we focus on solving large-scale nonlinear system of equations
where \(F:\mathbb {R}^{n}\rightarrow \mathbb {R}^{n}\) is continuous and monotone. A function F is monotone if it satisfies the monotonicity condition
Nonlinear monotone equations arise in many practical applications, for example, chemical equilibrium systems [1], economic equilibrium problems [2], and some monotone variational inequality problems [3]. A number of computational methods have been proposed to solve nonlinear equations. Among them, Newton’s method, quasi-Newton method, Gauss-Newton method, and their variants are very popular due to their local superlinear convergence property (see, for example, [4–9]). However, they are not suitable for large-scale nonlinear monotone equations as they need to solve a linear system of equations using the second derivative information (Jacobian matrix or an approximation of it).
Due to their modest memory requirements, conjugate gradient-based projection methods are suitable for solving large-scale nonlinear monotone equations (1). Conjugate gradient-based projection methods generate a sequence {xk} by exploring the monotonicity of the function F. Let zk=xk+αkdk, where αk>0 is the step length that is determined by some line search and
Fk=F(xk) and βk is a parameter, is the search direction. Then by monotonicity of F, the hyperplane
strictly separates the current iterate xk from the solution set of (1). Projecting xk on this hyperplane generates the next iterate xk+1 as
This projection concept on the hyperplane Hk was first presented by Solodov and Svaiter [10].
Following Solodov and Svaiter [10], a lot of work has been done, and continues to be done, to come up with a number of conjugate gradient-based projection methods for nonlinear monotone equations. For example, Hu and Wei [11] proposed a conjugate gradient-based projection method for nonlinear monotone equations (1) where the search direction dk is given as
yk−1=Fk−Fk−1 and γ>0. This method was shown to perform well numerically and its global convergence was established using the line search
with σ>0 being a constant.
Recently, three term conjugate gradient-based projection methods have also been presented. One such method is that by Feng et al. [12] who presented their direction as
where \(|\beta _{k}|\leq t\frac {\|F_{k}\|}{\|d_{k-1}\|},\,\, \forall k\geq 1\), and t>0 is a constant. The global convergence of this method was also established using the line search (4). For other conjugate gradient-based projection methods, the reader is referred to [13–27].
In this paper, following the work of Abubakar and Kumam [21], Hu and Wei [11] and that of Liu and Li [22], we propose a self adaptive spectral conjugate gradient-based projection method for solving systems of nonlinear monotone Eq. (1). This method is presented in the next section and the rest of the paper is organized as follows. In “Convergence analysis” section, we show that the proposed method satisfies the descent property \(F_{k}^{T}d_{k}\leq -c\|F_{k}\|^{2}, c>0\), and also establish its global convergence. In “Numerical experiments” section, we present the numerical results and lastly, conclusion is presented in “Conclusion” section.
Algorithm
In this section, we give the details of the proposed method. We start by briefly reviewing the work of Abubakar and Kumam [21] and that of Liu and Li [22].
Most recently, Abubakar and Kumam [21] proposed the direction
where μ is a positive constant and
and sk−1=zk−1−xk−1=αk−1dk−1. This method was shown to perform well numerically and its global convergence was established using line search (4). In 2015, Liu and Li [22] proposed a spectral DY-type projection method for nonlinear monotone system of Eq. (1) with the search direction dk as
where\(\beta _{k}^{DY}=\frac {\|F_{k}\|^{2}}{d_{k-1}^{T}u_{k-1}}\), uk−1=yk−1+tdk−1, \(t=1+\max \left \{0,-\frac {d_{k-1}^{T}y_{k-1}}{d_{k-1}^{T}d_{k-1}}\right \}\), yk−1=Fk−Fk−1+rsk−1 with sk−1=xk−xk−1, r>0 being a constant and \(\lambda _{k}=\frac {s_{k-1}^{T}s_{k-1}}{s_{k-1}^{T}y_{k-1}}\). The global convergence of this method was established using the line search
Motivated by the work of Abubakar and Kumam [21], Hu and Wei [11] and that of Liu and Li [22], in this paper we present our direction as
where
and
with η>0 being a constant and the parameters \(\lambda _{k}^{*}=\frac {s_{k-1}^{T}y_{k-1}}{s_{k-1}^{T}s_{k-1}}\) and \(\mu _{k}>\frac {1}{\lambda _{k}^{*}}\) where sk−1=xk−xk−1 and yk−1=Fk−Fk−1+rsk−1, r∈(0,1). With dk defined by (6), (7), and (8), we now present our algorithm.

Throughout this paper, we assume that the following assumption holds.
Assumption 1
(i) The function F(·) is monotone on \(\mathbb {R}^{n}\), i.e. \((F(x)-F(y))^{T}(x-y) \geq 0, \forall x,y\in \mathbb {R}^{n}\). (ii) The solution set of (1) is nonempty. (iii) The function F(·) is Lipschitz continuous on \(\mathbb {R}^{n}\), i.e. there exists a positive constant L such that
Convergence analysis
In this section we present the descent property and global convergence of the proposed method.
Lemma 1
For all k≥0, we have
Proof
From the definition of yk−1, we get that
which using the monotonicity of F it follows that
Also, from the Lipschitz continuity we obtain that
Combining (11) and (12) we get the inequality (10). This, therefore, means that \(\lambda _{k}^{*}\) is well defined.
Lemma 2
Suppose that Assumption 1 holds. Let the sequence {xk} be generated by Algorithm 1. Then the search direction dk satisfies the descent condition
Proof
Since d0=−F0, we have \(F_{0}^{T}d_{0}=-\|F_{0}\|^{2}\), which satisfies (13). For k≥ 1, we have from (6) that
Lemma 3
For all k≥0, we have
Proof
From (13) and Cauchy-Schwarz inequality, we have
Also, we have that
It then follows from (6), (7), and (8) that
Lemma 4
Suppose Assumption 1 holds and let {xk} be generated by Algorithm 1. Then the steplength αk is well defined and satisfies the inequality
Proof
Suppose that, at kth iteration, xk is not a solution, that is, Fk≠0, and for all i=0,1,2,..., inequality (5) fails to hold, that is
Since F is continuous, taking limits as i→∞ on both sides of (18) yields
which contradicts Lemma 2. So, the steplength αk is well defined and can be determined within a finite number of trials. Now, we prove inequality (17). If αk≠κ, then \(\alpha '_{k}=\frac {\alpha _{k}}{\rho }\) does not satisfy (5), that is
Using (9), (13) and (15) we have that
Thus
The following lemma shows that if the sequence {xk} is generated by Algorithm 1, and x∗ is a solution of (1), i.e. F(x∗)=0, then the sequence {∥xk−x∗∥} is decreasing and convergent. Thus, the sequence {xk} is bounded.
Lemma 5
Suppose Assumption 1 holds and the sequence {xk} is generated by Algorithm 1. For any x∗ such that F(x∗)=0, we have that
and the sequence {xk} is bounded. Furthermore, either {xk} is finite and the last iterate is a solution of (1), or {xk} is infinite and
which means
Proof
The conclusion follows from Theorem 2.1 in [10].
Theorem 1
Let {xk} be the sequence generated by Algorithm 1. Then
Proof
Suppose that the inequality (22) is not true. Then there exists a constant ε1>0 such that
This together with (13) implies that
This and (21) gives that
On the other hand, Lemma 5 implies that
Numerical experiments
In this section, results of our proposed method SASCGM are presented together with those of improved three-term derivative-free method (ITDM) [21], the modified Liu-Storey conjugate gradient projection (MLS) method [11], and the spectral DY-type projection method (SDYP) [22]. All algorithms are coded in MATLAB R2016a. In our experiments, we set ε=10−4, i.e., the algorithms are stopped whenever the inequality ∥Fk∥≤10−4 is satisfied, or the total number of iterations exceeds 1000. The method SASCGM is implemented with the parameters σ=10−4, ρ=0.5, r=10−3, \(\mu _{k}=\frac {1}{\lambda _{k}^{*}}+0.1\) and κ=1, while parameters for algorithms ITDM, MLS, and SDYP are set as in respective papers.
The methods are compared using number of iterations, number of function evaluations and CPU time taken for each method to reach the optimal value or termination. We test the algorithms on ten (10) test problems with their dimensions varied from 5000 to 20000, and with four (4) different starting points \(x_{0}=\left (\frac {1}{n},\frac {1}{n},\ldots,\frac {1}{n}\right)^{T}\), x1=(−1,−1,…,−1)T, x2=(0.5,0.5,…,0.5)T and x3=(−0.5,−0.5,…,−0.5)T. The test functions are listed as follows:
Problem 1. Sun and Liu [19] The mapping F is given by
where
and \(\phantom {\dot {i}\!}g(x)=(2e^{x_{1}}-1, 3e^{x_{2}}-1,\ldots,3e^{x_{n-1}}-1, 2e^{x_{n}}-1)^{T}\).
Problem 2. Liu and Li [22] Let F be defined by
where \(\phantom {\dot {i}\!}g(x)=(e^{x_{1}}-1, e^{x_{2}}-1,\ldots,e^{x_{n}}-1)^{T}\) and
Problem 3. Liu and Feng [18] The mapping F is given by
Problem 4. Liu and Li [20] The mapping F is given by
Problem 5. Abubakar and Kumam [21] The mapping F is given by
Problem 6. Hu and Wei [11] The mapping F is given by
Problem 7. Hu and Wei [11] The mapping F is given by
where \(h=\frac {1}{n+1}\).
Problem 8. Wang and Guan [25] The mapping F is given by
Problem 9. Wang and Guan [25] The mapping F is given by
Problem 10. Gao and He [24] The mapping F is given by
The numerical results are reported in Tables 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10, where “SP” represents the starting point (initial point), “DIM” denotes the dimension of the problem, “NI” refers to the number of iterations, “NFE” stands for the number of function evaluations, and “CPU” is the CPU time in seconds. In Table 3, “*” indicates that the algorithm did not converge within the maximum number of iterations. From the tables, we observe that the proposed method performs better than the other methods in Problems 2, 3, 4, 6, 9, and 10. The proposed method performs slightly lower in Problems 1, 5, 7, and 8. However, overall, the proposed method shows that it is very competitive with the other methods and can be a good addition to the existing methods in the literature.
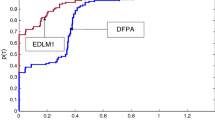
The performance of the three methods is further presented graphically in Figs. 1, 2, and 3 based on the number of iterations (NI), number of function evaluations (NFE), and the CPU time, respectively, using the performance profile of Dolan and Mor\(\acute {e}\) [28]. That is, we plot the probability ρS(τ) of the test problems for which each of the three methods was within a factor τ. Figures 1, 2, and 3 clearly show the efficiency of the proposed SASCGM method as compared to the other three methods.

Iterations performance profile

Function evaluations performance profile

Cpu time performance profile
Conclusion
In this paper, we proposed a self adaptive spectral conjugate gradient-based projection (SASCGM) method for solving systems of large-scale nonlinear monotone equations. The proposed method is free from derivative evaluations and also satisfies the descent condition \(F_{k}^{T}d_{k}\leq -c\|F_{k}\|^{2}, c>0\), independent of any line search. The global convergence of the proposed method was also established. The proposed algorithm was tested on some benchmark problems with different initial points and different dimensions and the numerical results show that the method is competitive.
Availability of data and materials
All data generated or analyzed during this study are included in this manuscript.
Abbreviations
- CPU:
-
CPU time is seconds
- DIM:
-
Dimension
- ITDM:
-
Improved three-term derivative-free method
- MLS:
-
Modified Liu-Storey method
- NFE:
-
Number of function evaluations
- NI:
-
Number of iterations
- SASCGM:
-
Self adaptive spectral conjugate gradient-based projection method
- SDYP:
-
Spectral DY-type projection method
- SP:
-
Starting (initial) point
References
Meintjes, K., Morgan, A. P.: A methodology for solving chemical equilibrium systems. Appl. Math. Comput. 22, 333–361 (1987).
Dirkse, S. P., Ferris, M. C.: A collection of nonlinear mixed complementarity problems. Optim. Methods Softw. 5, 319–345 (1995).
Zhao, Y. B., Li, D.: Monotonicity of fixed point and normal mapping associated with variational inequality and its applications. SIAM J. Optim. 11, 962–973 (2001).
Dehghan, M., Hajarian, M.: New iterative method for solving non-linear equations with fourth-order convergence. Int. J. Comput. Math. 87, 834–839 (2010).
Li, D., Fukushima, M.: A global and superlinear convergent Gauss-Newton-based BFGS method for symmetric nonlinear equations. SIAM J. Numer. Anal. 37, 152–172 (1999).
Dehghan, M., Hajarian, M.: On some cubic convergence iterative formulae without derivatives for solving nonlinear equations. Int. J. Numer. Methods Biomed. Eng. 27, 722–731 (2011).
Dehghan, M., Hajarian, M.: Some derivative free quadratic and cubic convergence iterative formulas for solving nonlinear equations. Comput. Appl. Math. 29, 19–30 (2010).
Zhou, G., Toh, K. C.: Superlinear convergence of a Newton-type algorithm for monotone equations. J. Optim. Theory Appl. 125, 205–221 (2005).
Zhou, W. J., Liu, D. H.: A globally convergent BFGS method for nonlinear monotone equations without any merit functions. Math. Comput. 77, 2231–2240 (2008).
Solodov, M. V., Svaiter, B. F.: A globally convergent inexact newton method for systems of monotone equations, Reformulation: Nonsmooth, Piecewise Smooth, Semismoothing methods. Springer US (1998). https://doi.org/10.1007/978-1-4757-6388-1_18.
Hu, Y., Wei, Z.: A modified Liu-Storey conjugate gradient projection algorithm for nonlinear monotone equations. Int. Math. Forum. 9, 1767–1777 (2014).
Feng, D., Sun, M., Wang, X.: A family of conjugate gradient methods for large scale nonlinear equations. J. Inqual. Appl. 2017, 236 (2017).
Ding, Y., Xiao, Y., Li, J.: A class of conjugate gradient methods for convex constrained monotone equations. Optim. 66(12), 2309–2328 (2017).
Koorapetse, M., Kaelo, P.: Globally convergent three-term conjugate gradient projection methods for solving nonlinear monotone equations. Arab. J. Math. 7, 289–301 (2018).
Liu, J., Li, S.: Multivariate spectral DY-type projection method for convex constrained nonlinear monotone equations. J. Ind. Manag. Optim. 13, 283–295 (2017).
Wang, X. Y., Li, S. J., Kou, X. P.: A self-adaptive three-term conjugate gradient method for monotone nonlinear equations with convex constraints. Calcolo. 53, 133–145 (2016).
Xiao, Y., Zhu, H.: A conjugate gradient method to solve convex constrained monotone equations with applications in compressive sensing. J. Math. Anal. Appl. 405, 310–319 (2013).
Liu, J., Feng, Y.: A derivative-free iterative method for nonlinear monotone equations with convex constraints. Numer. Algor. 82, 245–262 (2019).
Sun, M., Liu, J.: Three derivative-free projection methods for nonlinear equations with convex constraints. J. Appl. Math. Comput. 47, 265–276 (2015).
Liu, J., Li, S.: A three-term derivative-free projection method for nonlinear monotone system of equations. Calcolo. 53, 427–450 (2016).
Abubakar, A. B., Kumam, P.: An improved three-term derivative-free method for solving nonlinear equations. Comput. Appl. Math. 37(5), 6760–6773 (2018).
Liu, J., Li, S.: Spectral DY-type projection method for nonlinear monotone systems of equations. J. Comput. Math. 33, 341–354 (2015).
Abubakar, A. B., Kumam, P.: A descent Dai-Liao conjugate gradient method for nonlinear equations. Numer. Algor. 81, 197–210 (2019).
Gao, P., He, C.: An efficient three-term conjugate gradient method for nonlinear monotone equations with convex constraints. Calcolo. 55, 53 (2018). https://doi.org/10.1007/s10092-018-0291-2.
Wang, S, Guan, H: A scaled conjugate gradient method for solving monotone nonlinear equations with convex constraints. J. Appl. Math. 2013, 286486 (2013).
Ou, Y., Li, J.: A new derivative-free SCG-type projection method for nonlinear monotone equations with convex constraints. J. Appl. Math. Comput. 56, 195–216 (2018).
Yuan, G., Zhang, M.: A three-terms Polak-Ribiere-Polyak conjugate gradient algorithm for large-scale nonlinear equations. J. Comput. Appl. Math. 286, 186–195 (2015).
Dolan, E. D., More, J. J.: Benchmarking optimization software with performance profiles. Math. Program. 91, 201–213 (2002).
Acknowledgements
The authors appreciate the work of the referees, for their valuable comments and suggestions that led to the improvement of this paper. The authors would also like to thank Prof J. Liu who provided the MATLAB code for SDYP.
Funding
None.
Author information
Authors and Affiliations
Contributions
The authors jointly worked on the results, read, and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License(http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Koorapetse, M., Kaelo, P. Self adaptive spectral conjugate gradient method for solving nonlinear monotone equations. J Egypt Math Soc 28, 4 (2020). https://doi.org/10.1186/s42787-019-0066-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s42787-019-0066-1