
Abstract
Paenirhodobacter enshiensis is a non-photosynthetic species that belongs to family Rhodobacteraceae. Here we report the draft genome sequence of Paenirhodobacter enshiensis DW2-9T and comparison results to the available related genomes. The strain has a 3.4 Mbp genome sequence with G + C content of 66.82 % and 2781 protein-coding genes. It lacks photosynthetic gene clusters and putative proteins necessary in Embden-Meyerhof-Parnas (EMP) pathway, but contains proteins in Entner-Doudoroff (ED) pathway instead. It shares 699 common genes with nine related Rhodobacteraceae genomes, and possesses 315 specific genes.
Similar content being viewed by others


Introduction
Family Rhodobacteraceae belongs to Proteobacteria which was established by Garrity et al. [1] and contains 105 genera including both chemoorganotrophic and photoheterotrophic bacteria. The type genus was Rhodobacter which was first proposed by Imhoff et al. in 1984 [2] and comprised of only photosynthetic species [3–8]. In 2013, we proposed Paenirhodobacter enshiensis DW2-9T to represent one of the non-photosynthetic genera of Rhodobacteraceae [9]. The main differences between Paenirhodobacter and its closest relative Rhodobacter are their photosynthetic characteristics and major polar lipid types [9]. Haematobacter is another non-photosynthetic genus of Rhodobacteraceae [10] and the main difference between Haematobacter and Paenirhodobacter is the cultivation condition [9–11].
So far, the genus Paenirhodobacter contains only one species, Paenirhodobacter enshiensis . The main characters of P. enshiensis DW2-9T are non-photosynthetic and possessing phosphatidylglycerol, phosphatidylethanolamine and aminophospholipid as the major polar lipids [9]. In addition, we found that strain P. enshiensis DW2-9T was able to reduce soluble selenite (Se4+) into insoluble elemental selenium nanoparticle (Se0). Since Se0 is less bioavailable, this strain could potentially been used in bioremediation of soil or water with selenite-contamination.
In order to provide genomic information for elucidating the mechanism of bacterial selenite reduction, as well as the taxonomic study, we performed genome sequencing of strain P. enshiensis DW2-9T, together with its close relatives Haematobacter missouriensis CCUG 52307T [10] and Haematobacter massiliensis CCUG 47968T [11]. In this study, we report the genomic features of P. enshiensis DW2-9T and the comparison results to the close relatives. This microorganism is not belonged to a larger genomic survey project.
Organism information
Classification and features
Strain P. enshiensis DW2-9T was isolated from soil near a sewage outlet of the Bafeng pharmaceutical factory, Enshi city, Hubei province, PR China. The general features of P. enshiensis DW2-9T are shown in Table 1. The 16S rRNA gene based phylogenetic tree showing the phylogenetic relationships of P. enshiensis DW2-9T to other taxonomically classified type strains of the family Rhodobacteraceae could be found in our previous study [9].
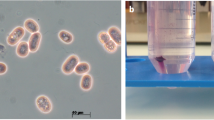
Strain DW2-9T is Gram-negative, facultatively anaerobic, non-motile, non-photosynthetic, and rod-shaped (Fig. 1). Cells are 0.9-1.2 μm long and 0.3-0.6 μm wide. Colonies are convex, circular, smooth and white after 2 days of incubation on modified Biebl & Pfennig’s agar at 30 °C [9]. The strain was able to reduce 0.2 mmol/L of sodium selenite (Na2SeO3) into Se0 within 2 days when grown in Luria-Bertani medium.

A TEM image of ultrathin sections for P. enshiensis DW2-9T cells. The scale bar represents 200 nm
The chemotaxonomic features include phosphatidylglycerol, phosphatidylethanolamine and aminophospholipid as the major polar lipids, ubiquinone-10 as the major quinone and C16:0, C18:1 ω7c, C19:0 cyclo ω8c and summed feature 3 (one or more of iso-C15:0 2-OH, C16:1 ω6c and C16:1 ω7c) as the major cellular fatty acids of [9].
Genome sequencing information
Genome project history
Strain P. enshiensis DW2-9T was sequenced by Majorbio Bio-pharm Technology Co., Ltd, Shanghai, China. The draft genome sequence of strain P. enshiensis DW2-9T has been deposited at DDBJ/EMBL/GenBank under accession number JFZB00000000. The version described in this study is the first version JFZB01000000 and consists of sequences JFZB01000001-JFZB01000112. The project information are summarized in Table 2
.
Growth conditions and genomic DNA preparation
Strain P. enshiensis DW2-9T was grown aerobically in LB medium at 28°C for 36 h. The DNA was extracted, concentrated and purified using the QiAamp kit according to the manufacturer’s instruction (Qiagen, Germany).
Genome sequencing and assembly
The genome of P. enshiensis DW2-9T was sequenced by Illumina technology [19]. An Illumina standard shotgun library was constructed and sequenced using the Illumina MiSeq 2000 platform, which generated 3,128,974 reads totaling 941.8 Mbp.
All original sequence data can be found at the NCBI Sequence Read Archive [20]. The following steps were performed for removing low quality reads: (1) removed the adapter in the reads, (2) cut the 5’ end bases which were not A, T, G, C, (3) filtered the reads which have a quality score lower than 20, (4) filtered the reads which contained N more than 10 percent, (5) removed the reads which have the length less than 25 bp after processed by the previous four steps. The processed reads were assembled by SOAPdenovo v1.05 [21].
The final draft assembly contained 153 contigs in 85 scaffolds. The total size of the genome is 3.4 Mbp and the final assembly is based on 764.6 Mbp of Illumina data, which provides an average 222× coverage of the genome. The simulated genome of P. enshiensis DW2-9T is a set of contigs ordered against the complete genome of Rhodobacter capsulatus SB1003 (NC_013034) using Mauve software [22].
Genome annotation
The draft genome of P. enshiensis DW2-9T was annotated through the RAST server version 2.0 [23] and the National Center for Biotechnology Information Prokaryotic Genome Annotation Pipeline, which combines the gene caller GeneMarkS+ [18] with the similarity-based gene detection approach.
Protein function classification was performed by WebMGA [24] with E-value cutoff 1-e10. The transmembrane helices were predicted by TMHMM Server v. 2.0 [25]. Internal gene clustering was performed by OrthoMCL using Match cutoff of 50 % and E-value Exponent cutoff of 1-e5 [26, 27]. Signal peptides in the genome were predicted by SignalP 3.0 server [28]. The translation predicted CDSs were also used to search against the Pfam protein family database [29], KEGG [30] and the NCBI Conserved Domain Database through the Batch web CD-Search tool [31].
Genome properties
The whole genome of P. enshiensis DW2-9T is 3,439,591 bp in length, with an average GC content of 66.82 %, and is distributed in 112 contigs (>200 bp). The genome properties and statistics are summarized in Table 3 and Fig. 2. A total of 2781 protein-coding genes are identified and 78.99 % of them are distributed into COG functional categories (Table 4).

A graphical circular map of the genome performed with CGview comparison tool [32]. From outside to center, ring 1, 4 show protein-coding genes colored by COG categories on forward/reverse strand; ring 2, 3 denote genes on forward/reverse strand; ring 5 shows G + C% content plot, and the innermost ring shows GC skew

A phylogenetic tree highlighting the phylogenetic position of P. enshiensis DW2-9T. The conserved protein was analyzed by OrthoMCL with Match Cutoff 50 % and E-value Exponent Cutoff 1-e5 [26, 27]. The phylogenetic tree was constructed based on the 699 single-copy conserved proteins shared among the ten genomes. The phylogenies were inferred by MEGA 5.05 with NJ algorithm [38], and 1000 bootstrap repetitions were computed to estimate the reliability of the trees. The genome accession numbers of the strains are shown in parenthesis

Ortholog analysis of P. enshiensis DW2-9T and nine Rhodobacteraceae genomes conducted using OrthoMCL with Match cutoff of 50 % and E-value Exponent cutoff of 1-e5. The total numbers of shared proteins of the ten genomes were tabulated and presented as a Venn diagram. Abbreviations for strain names: DW, P. enshiensis DW2-9T; CCUG1, Haematobacter missouriensis CCUG 52307T; CCUG2, Haematobacter massiliensis CCUG 47968T; RC, Rhodobacter capsulatus SB1003; RS, Rhodobacter sphaeroides ATH 2.4.1T; PA, Paracoccus aminophilus JCM 7686T; PD, Paracoccus denitrificans PD1222T; RD, Roseobacter denitrificans OCh 114; RL, Roseobacter litoralis Och 149T; RP, Ruegeria pomeroyi DSS-3T

A graphical circular map of the comparison between reference strain Rhodobacter capsulatus SB 1003 and the three strains sequenced in this study. From outside to center, rings 1, 4 show protein-coding genes colored by COG categories on forward/reverse strand; rings 2, 3 denote genes on forward/reverse strand; rings 5, 6, 7 show the CDS vs CDS BLAST results of Rhodobacter capsulatus SB 1003 with P. enshiensis DW2-9T, H. massiliensis CCUG 47968T and H. missouriensis CCUG 52307T, respectively; ring 8 shows G + C% content plot, and the innermost ring shows GC skew
Insights from the genome sequence
Profiles of metabolic network and pathway
Strain DW2-9T is facultatively anaerobic and can utilize a variety of sole carbon substrates, including acetate, propionate, pyruvate, fumarate, malate, citrate, succinate, D-glucose, D-fructose and maltose [9]. Genome analysis showed that this strain has the corresponding enzymes to utilize these sole carbon sources and to catabolize them via different pathways (mainly by the TCA cycle and pentose phosphate). Especially in glycolysis, strain P. enshiensis DW2-9T lacks the key enzyme 6-phosphofructokinase that is essential in Embden-Meyerhof-Parnas (EMP) pathway. Instead, it contains 6-phosphogluconate dehydratase (KFI24690) and 2-keto-3-deoxyphosphogluconate aldolase (KFI24689) that were characterized in Entner-Doudoroff (ED) pathway.
All key genes necessary for fatty acid biosynthesis are present. All genes required for de novo synthesis of 15 common amino acids are present. Genes for biosynthesis of Ala, Asn, Met, Tyr and His are not present.
As a non-photosynthetic bacterium, the known photosynthetic gene clusters, including the bch genes, puf genes and crt genes were not found in the genome of P. enshiensis DW2-9T.
In this study, strain DW2-9T was found to be capable of reducing selenite into selenium nanoparticle. It has been reported that low-molecular weight thiols such as glutathione [33] and cysteine [34], nitrite reductase [35], fumarate reductase [36], glutathione reductase and thioredoxin reductase [37] could reduce selenite into elemental selenium. In the genome of strain DW2-9T, all the encoding genes of the respective enzymes mentioned above were found (e.g. KFI26491, KFI30857, KFI28250, KFI28810, KFI29698, KFI24274 and KFI29723).
Comparisons with other Rhodobacteraceae genomes
The genomic sequence of strain DW2-9T was compared to nine available Rhodobacteraceae strains ( Haematobacter missouriensis CCUG 52307T, Haematobacter massiliensis CCUG 47968T, Rhodobacter capsulatus SB1003, Rhodobacter sphaeroides ATH 2.4.1T, Paracoccus aminophilus JCM 7686T, Paracoccus denitrificans PD1222, Ruegeria pomeroyi DSS-3T, Roseobacter denitrificans OCh 114T and Roseobacter litoralis Och 149T). OrthoMCL was used again to perform ortholog clustering analysis with Match cutoff of 50% and E-value Exponent cutoff of 1-e5 [26, 27]. A total of 699 shared protein sequences were obtained and a neighbor-jointing (NJ) phylogenomic tree [38] was constructed (Fig. 3). The phylogenomic result based on the 699 proteins is generally consistent with the 16S rRNA gene tree [9]. The ortholog clustering analysis also revealed that strain P. enshiensis DW2-9T has 315 strain-specific genes, which potentially contributes to genus-specific features distinguishing Paenirhodobacter from other genera (Fig. 4).
In this study, we also sequenced the genomes of two members of Haematobacter genus, strain H. missouriensis CCUG 52307T [10] and H. massiliensis CCUG 47968T [11]. The draft genome sequences were 3.9 and 4.1 Mbp, the G+C contents were 64.31 % and 64.56 %, and the numbers of predicted protein-coding genes were 3,612 and 3,806, respectively. Figure 5 shows the genome comparison results of strain P. enshiensis DW2-9T, H. missouriensis CCUG 52307T and H. massiliensis CCUG 47968T using CGview comparison tool [32]. Table 5 presents the difference of the gene number (in percentage) in each COG category between strain P. enshiensis DW2-9T, H. missouriensis CCUG 52307T and H. massiliensis CCUG 47968T.
Conclusions
Genomic analysis of P. enshiensis DW2-9T revealed a high degree of consistency between genotypes and phenotypes, especially in sole carbon source utilization and non-photosynthetic nature. Genome sequencing of strain P. enshiensis DW2-9T provides extra supports for its taxonomic classification. The genome sequence of strain DW2-9T also provides insights to better understand the molecular mechanisms of selenite reduction. In addition, this strain could potentially been used for bioremediation of environmental selenite-contamination.
The associated MIGS records are shown in Additional file 1: Table S1.
Abbreviations
- RAST:
-
Rapid annotation using subsystem technology
- KEGG:
-
Kyoto encyclopedia of genes and genomes
References
Garrity GM, Bell JA, Lilburn T. Family I. Rhodobacteraceae fam. nov. In: Brenner DJ, Krieg NR, Staley JT, Garrity GM, editors. Bergey’s Manual of Systematic Bacteriology, vol. 2. secondth ed. New York: (The Proteobacteria), part C (The Alpha-, Beta-, Delta-, and Epsilonproteobacteria), Springer; 2005. p. 161.
Imhoff JF. Genus I. Rhodobacter. In: Brenner DJ, Krieg NR, Staley JT, Garrity GM, editors. Bergey’s Manual of Systematic Bacteriology, vol. 2. secondth ed. New York: (The Proteobacteria), part C (The Alpha-, Beta-, Delta-, and Epsilonproteobacteria), Springer; 2005. p. 161.
Hiraishi A, Ueda Y. Intrageneric structure of the genus Rhodobacter: transfer of Rhodobacter sulfidophilusand related marine species to the genus Rhodovulum gen. nov. Int J Syst Bacteriol. 1994;44:15–23.
Eckersley K, Dow CS. Rhodopseudomonas blastica sp. nov.: a Member of the Rhodospirillaceae. J Genl Microbiol. 1980;119:465–73.
Uchino Y, Hamada T, Yokota A. Proposal of Pseudorhodobacter ferrugineus gen. nov., comb. nov., for a non-photosynthetic marine bacterium, Agrobacterium ferrugineum, related to the genus Rhodobacter. J Gen Appl Microbiol. 2002;48:309–19.
Girija KR, Sasikala C, Ramana CV, Spröer C, Takaichi S, Thiel V, et al. Rhodobacter johrii sp. nov., an endospore-producing cryptic species isolated from semi-arid tropical soils. Int J Syst Evol Microbiol. 2010;60:2099–107.
Ramana VV, Anil Kumar P, Srinivas TN, Sasikala C, Ramana CV. Rhodobacter aestuarii sp. nov., a phototrophic alphaproteobacterium isolated from an estuarine environment. Int J Syst Evol Microbiol. 2009;59:1133–6.
Shalem Raj P, Ramaprasad EVV, Vaseef S, Sasikala C, Ramana CV. Rhodobacter viridis sp. nov., a phototrophic bacterium isolated from Western Ghats of India. Int J Syst Evol Microbiol. 2013;63:181–6.
Wang D, Liu HL, Zheng SX, Wang GJ. Paenirhodobacter enshiensis gen. nov., sp. nov., a non-photosynthetic bacterium isolated from soil, and emended descriptions of the genera Rhodobacter and Haematobacter. Int J Syst Evol Microbiol. 2014;64:551–8.
Helsel LO, Hollis D, Steigerwalt AG, Morey RE, Jordan J, Aye T, et al. Identification of “Haematobacter” a new genus of aerobic Gram-negative rods isolated from clinical specimens, and reclassification of Rhodobacter massiliensis as “Haematobacter massiliensis comb. nov.”. J Clin Microbiol. 2007;45:1238–43.
Greub G, Raoult D. Rhodobacter massiliensis sp. nov., a new amoebae-resistant species isolated from the nose of a patient. Res Microbiol. 2003;154:631–5.
Field D, Garrity GM, Gray T, Morrison N, Selengut J, Sterk P, et al. The minimum information about a genome sequence (MIGS) specification. Nat Biotechnol. 2008;26:541–7.
Woese CR, Kandler O, Weelis ML. Towards a natural system of organisms. Proposal for the domains Archaea, Bacteria and Eucarya. Proc Natl Acad Sci U S A. 1990;87:4576–9. doi:10.1073/pnas.87.12.4576. pmid:2112744.
Garrity GM, Bell JA, Lilburn T. Phylum XIV. Proteobacteria phyl nov. In: Brenner DJ, Krieg NR, Stanley JT, Garrity GM, editors. Bergey’s Manual of Sytematic Bacteriology, vol. 2. secondth ed. New York: (The Proteobacteria), part B (The Gammaproteobacteria), Springer; 2005. p. 1.
Garrity GM, Bell JA, Lilburn T. Class I. Alphaproteobacteria class. nov. In: Brenner DJ, Krieg NR, Stanley JT, Garrity GM, editors. Bergey’s Manual of Sytematic Bacteriology, vol. 2. secondth ed. New York: (The Proteobacteria), part C (The Alpha-, Beta-, Delta-, and Epsilonproteobacteria), Springer; 2005. p. 1.
Garrity GM, Bell JA, Order LT, III. Rhodobacterales ord. nov. In: Brenner DJ, Krieg NR, Staley JT, Garrity GM, editors. Bergey’s Manual of Systematic Bacteriology, second edition. vol. 2 (The Proteobacteria), part C (The Alpha-, Beta-, Delta-, and Epsilonproteobacteria). New York: Springer; 2005. p. 161.
Validation List No. 107. List of new names and new combinations previously effectively, but not validly, published. Int J Syst Evol Microbiol. 2006;56:1–6. doi:10.1099/ijs.0.64188-0. pmid:16403855.
Ashburner M, Ball CA, Blake JA, Botstein D, Butler H, Cherry JM, et al. Gene ontology: tool for the unification of biology. Gene Ontol Consortium Nat Genet. 2000;25:25–9.
Bennett S. Solexa Ltd. Pharmacogenomics. 2004;5:433–8.
The NCBI Sequence Read Archive (SRA) [http://www.ncbi.nlm.nih.gov/Traces/sra/]
Li R, Li Y, Kristiansen K, Wang J. SOAP: short oligonucleotide alignment program. Bioinformatics. 2008;24:713–4.
Darling AC, Mau B, Blattner FR, Perna NT. Mauve: multiple alignment of conserved genomic sequence with rearrangements. Genome Res. 2004;14:1394–403.
Overbeek R, Olson R, Pusch GD, Olsen GJ, Davis JJ, Disz T, et al. The SEED and the Rapid Annotation of microbial genomes using Subsystems Technology (RAST). Nucleic Acids Res. 2014;42:206–14.
Wu S, Zhu ZW, Fu L, Niu BF, Li WZ. WebMGA: a customizable web server for fast metagenomic sequence analysis. BMC Genomics. 2011;12:444.
Krogh A, Larsson BÈ, Von Heijne G, Sonnhammer EL. Predicting transmembrane protein topology with a hidden Markov model: application to complete genomes. J Mol Biol. 2001;305:567–80.
Li L, Stoeckert Jr CJ, Roos DS. OrthoMCL: identification of ortholog groups for eukaryotic genomes. Genome Res. 2003;13:2178–89.
Fischer S, Brunk B P, Chen F, Gao X, Harb OS, Iodice JB, Shanmugam D, Roos DS and Stoeckert DJ. Using OrthoMCL to Assign Proteins to OrthoMCL-DB Groups or to Cluster Proteomes Into New Ortholog Groups. Curr Protoc Bioinformatics. 2011, 6–12.
Dyrløv Bendtsen J, Nielsen H, von Heijne G, Brunak S. Improved prediction of signal peptides: SignalP 3.0. J Mol Biol. 2004;340:783–95.
Finn RD, Bateman A, Clements J, Coggill P, Eberhardt RY, Eddy SR, et al. The Pfam protein families database. Nucleic Acids Res. 2014;42:222–30.
Moriya Y, Itoh M, Okuda S, Yoshizawa A, Kanehisa M. KAAS: an automatic genome annotation and pathway reconstruction server. Nucleic Acids Res. 2007;35:182–5.
Marchler-Bauer A, Lu S, Anderson JB, Chitsaz F, Derbyshire MK, DeWeese-Scott C, et al. CDD: a Conserved Domain Database for the functional annotation of proteins. Nucleic Acids Res. 2011;39:225–9.
Grant JR, Arantes AS, Stothard P. Comparing thousands of circular genomes using the CGView Comparison Tool. BMC Genomics. 2012;13:202.
Kessi J, Hanselmann KW. Similarities between the abiotic reduction of selenite with glutathione and the dissimilatory reaction mediated by Rhodospirillum rubrum and Escherichia coli. J Bio Chem. 2004;279:50662–9.
Gennari F, Sharma VK, Pettine M, Campanella M, Millero MJ. Reduction of selenite by cysteine in ionic media. Geochim Cosmochim Ac. 2014;124:98–108.
DeMoll-Decker H, Macy JM. The periplasmic nitrite reductase of Thauera selenatis may catalyze the reduction of selenite to elemental selenium. Arch Microbiol. 1993;160:241–7.
Li DB, Cheng YY, Wu C, Li WW, Li N, Yang ZC, Tang ZH and Yu HQ. Selenite reduction by Shewanella oneidensis MR-1 is mediated by fumarate reductase in periplasm. Sci Rep-UK. 2014;4:1–7.
Hunter WJ. Pseudomonas seleniipraecipitans proteins potentially involved in selenite reduction. Curr Microbiol. 2014;69:69–74.
Tamura K, Peterson D, Peterson N, Stecher G, Nei M, Kumar S. MEGA5: molecular evolutionary genetics analysis using maximum likelihood, evolutionary distance, and maximum parsimony methods. Mol Biol Evol. 2011;28:2731–9.
Acknowledgment
This work was supported by Chinese National High Technology (863) Project (2012AA101402) and the National Natural Science Foundation of China (31470227).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
DW, FZ and XZ performed the genome data analysis; DW and SZ drafted the paper; GW and RW revised the manuscript and provided financial supports. All authors read and approved the final manuscript.
Additional file
Additional file 1: Table S1.
Associated MIGS record.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Wang, D., Zhu, F., Zhu, X. et al. Draft genomic sequence of a selenite-reducing bacterium, Paenirhodobacter enshiensis DW2-9T . Stand in Genomic Sci 10, 38 (2015). https://doi.org/10.1186/s40793-015-0026-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40793-015-0026-9