
Abstract
In the video compression industry, video compression tailored to machine vision tasks has recently emerged as a critical area of focus. Given the unique characteristics of machine vision, the current practice of directly employing conventional codecs reveals inefficiency, which requires compressing unnecessary regions. In this paper, we propose a framework that more aptly encodes video regions distinguished by machine vision to enhance coding efficiency. For that, the proposed framework consists of deep learning-based adaptive switch networks that guide the efficient coding tool for video encoding. Through the experiments, it is demonstrated that the proposed framework has superiority over the latest standardization project, video coding for machine benchmark, which achieves a Bjontegaard delta (BD)-rate gain of 5.91% on average and reaches up to a 19.51% BD-rate gain.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.1 Introduction
As the volume of video data requiring processing, transmitting, and storing continues to rise, efficient video compression is indispensable. The influence of standardization in this realm is profound. The versatile video coding (VVC) standard [1], representing the forefront of compression technology, stands out due to its remarkable efficiency. Designed to address the escalating demands of video compression, VVC demonstrates substantial bitrate reductions—achieving up to 40% over the high-efficiency video coding (HEVC) standard [2].
The VVC standard represents the current state-of-the-art (SOTA) in video compression models, achieving substantially better coding efficiency than its predecessor in view of compressing general video data. However, directly applying such VVC that is optimized for human vision is not always suitable for video data for machine vision tasks. Recognizing this gap, standardization groups, particularly the moving picture experts group (MPEG), have launched the video coding for machines (VCM) project [3]. This initiative proposes techniques that enhance compression efficiency specifically for machine applications, employing strategies that maintain a higher quality of pixels within regions of interest (ROIs) identified by machine detection than in other regions, using VVC as the underlying codec. By adopting the VCM framework, compression efficiency has improved by 12.73% on the SFU-HW-Objects-v1 [4] and 39.73% on the Tencent Video dataset (TVD) [5] for random access (RA), compared to using VVC alone, demonstrating the effectiveness of tailoring compression techniques to the specific needs of machine vision tasks [6].
MPEG experts and academic researchers have made significant strides in exploring methods to enhance video compression performance for machine vision tasks, primarily through preprocessing steps that consider ROIs identified by machine vision, and temporal and spatial resampling [7,8,9,10,11,12,13]. While much of this work has adopted the VVC test model (VTM) as the encoder that uses standard VTM encoding options, it is essential to note that VVC is optimized for human vision tasks, which means its default settings may not be consistently ideal for machine vision applications. In the MPEG VCM, there is a specific approach that converts areas outside of the machine’s ROIs to grayscale to increase the coding efficiency of VVC [14]. This approach highlights a gap in research concerning the inefficiency of directly applying standard video compression techniques to machine vision contexts. Given that areas outside the ROI are uniformly processed into a single color, creating a clear boundary between these areas and the main object. Adhering strictly to the traditional use of individual encoding options, for frames comprising a machine-determined ROI and its distinctly colored surroundings, might be inefficient. In addition, the unique characteristics of each input sequence are crucial for machine vision tasks, requiring adaptive encoding strategies. Uniformly applying the same encoding options across all sequences could be problematic, highlighting the necessity for more customized video compression approaches in machine-focused applications.
This paper systematically investigates the effect of encoding options for VCM by toggling it on and off. Building upon these elements, we develop a novel framework, called the deep learning-based adaptive switch networks for machines (DASM). DASM is designed to autonomously select more appropriate encoding tools for each specific video sequence with a deep learning-based selector. The implementation of the proposed encoding framework yields a 5.91% gain in terms of Bjontegaard delta rate (BD-rate), on average, and reaches up to a 19.51% gain compared to the VCM reference software 0.6.0 (VCM-RS 0.6.0) that employs VVC test model software version 12 (VTM 12.0).

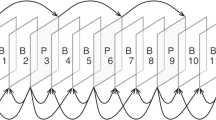
The overview of VCM framework [3]
2 Related works
2.1 Neural network-based VCM
Recently, the field of image compression has made significant advancements with neural-based approaches [15,16,17,18,19,20,21], especially in terms of bitrate savings. These approaches have reached or surpassed the performance of traditional codecs for human’s perspective. On the contrary, for machine vision applications, a few studies have explored neural network (NN) methods. Le et al. [22] introduced an end-to-end learned system for image compression designed for machine vision, using a convolutional NN (CNN) with residual blocks for the encoder and decoder components, demonstrating efficient bitrate savings. In contrast, our work focuses on compressing videos. Image codecs primarily handle the compression of spatial information within individual images, lacking the need or capability to address temporal redundancy. Consequently, when addressing video codecs, applying image codecs directly to video codec tasks presents challenges due to these fundamental differences. Kim et al. [23] proposed a multiscale feature compression method that encodes larger scale features followed by smaller scale features in sequence, using an end-to-end trainable model comprising CNN layers. While this method is primarily focused on enhancing feature quality, it does not focus on compressing and evaluating the entirety of preprocessed frames.
2.2 Traditional codec-based VCM
In the VCM project conducted by MPEG, based on the VTM, encoding is performed by reducing the quality in areas outside the ROI detected through machine vision [3]. The current framework for VCM provided by MPEG, VCM-RS 0.6.0, proceeds as illustrated in Fig. 1. Prior to compression, a preprocessing stage is conducted to enhance compression efficiency, emphasizing objects of interest for machine vision tasks.
The preprocessing stage typically includes temporal resampling, spatial resampling, and ROI-based processing. In temporal resampling, video frames are resampled at uniform intervals, effectively reducing the input video frame rate in the temporal domain [12, 13]. This process involves downsampling the original video sequence, which is restored to its original frame rate during the post-processing stage following decoding. Spatial resampling involves downsampling the video in the spatial domain. In the latest version of the MPEG VCM, spatial resampling is set to bypass by default, not engaging in this process. The ROI-based processing operates by employing an object recognition model, processing areas outside the recognized regions at different quality levels to achieve bitrate savings. Background masking is conducted by leveraging object recognition technology based on Faster R-CNN [39]. This technique removes unnecessary background information relevant to machine vision tasks, enhancing coding efficiency. Following the preprocessing phase, the video is compressed using the VTM.
In addition to the efforts in the MPEG VCM, significant research has also leveraged traditional video codecs, such as HEVC and VVC, focusing on applications in machine vision. Building on HEVC, Suzuki et al. [24] introduced a proposed image pre-transforming method that employs NNs to improve image recognition accuracy and lower bitrate. For machine visual analysis, Huang et al. [7] evaluated the degree of importance of each coding tree unit (CTU). By identifying the overlap between the machine ROI and the CTUs within images in the context of VVC, the method allocates bits accordingly. Similarly, Fischer et al. [11] built on VVC to determine salient CTUs based on the overlap between detected objects and CTUs. The model adjusts the quantization parameter (QP) values according to whether a CTU is deemed salient, achieving bitrate savings in object detection performance. Likewise, Lee et al. [8] focused on extracting attention regions of machines, allocating bits differently based on these attention regions. The mentioned studies predominantly focus on varying the quality of regions detected by machines, aiming to enhance the efficiency of machine analysis with bitrate savings. This approach is centered on manipulating the output quality for better analytical results rather than exploring the foundational aspects of the codecs themselves.
A few studies have investigated the encoding options of foundational codecs in video compression models designed for machine vision. Fischer et al. [25] explored the influence of three VVC in-loop filters—the deblocking filter, sample adaptive offset filter, and adaptive loop filter—by toggling these options on and off for object detection tasks. Similarly, Lee et al. [9] examined the influence of VVC-based feature coding for machines and its applicability to video captioning, proposing a combination of options for enhanced performance. However, these studies only investigate the effects of encoding options on the specific dataset, reporting the outcomes accordingly. Consequently, they do not provide insight into how these options perform on other input sequences, leaving their efficacy on varied content unexplored.
In the standardization process of the VCM currently at the working draft stage within MPEG [3], several proposals have recently been put forward. Yu et al. [26] suggested a new single layer that applies an NN image codec as an alternative to the conventional VVC intracoding modes for key frame encoding, avoiding the complexities associated with lossless encoding and decoding. Ding et al. [10] proposed truncating the bit depth to enhance the rate–distortion (RD) performance under the VCM common test conditions (CTCs). Lee et al. [27] highlighted the necessity of altering QP selection for encoding video sequences under the CTCs [28], recommending a fixed, constant interval between rate points. Ding et al. [29] introduced a constrained cubic curve-fitting method that achieves a lower fitting error compared to the current approach. However, these submissions are all set against the backdrop of the basic VTM configuration for compression, with no research on the influence of the encoding options on compression for machine tasks.
The VTM provides a range of prediction strategies and coding options. Among these, we investigated the effects of toggling key features, including the deblocking filter, dual I tree, luma mapping and chroma scaling (LMCS), intra-block copy (IBC), and early skip decisions (ESDs), on the encoding process for each input sequence. In VCM, non-ROI regions are converted to grayscale, creating distinct boundaries and sharp contrasts between the objects and the grayscale background. We assumed that since each sequence has varying characteristics and the proportion of the object differs, the adaptive use of these tools based on the frames would impact the compression performance.
First, the deblocking filter is used to smooth the edges of discontinuous blocks, enhancing the quality of the decoded video, particularly when differences in the quantization parameter (QP) across blocks lead to visible discontinuities at block boundaries [30]. In the context of VCM preprocessing, if an object occupies a significant portion of the frame or if there are many objects, it might be more efficient to avoid using the deblocking filter. This can maintain clear boundaries between the object and the grayscale background for better detection while also reducing complexity, thereby improving compression performance. Second, intra-coded I-slices can display distinct spatial characteristics for luma and chroma components. Thus, the dual tree coding structure can be employed to address luma and chroma coding separately, leading to more efficient encoding [31]. This functionality can be managed in the VTM by enabling or disabling the dual I tree option. The dual I tree option could be an efficient choice for camera-captured videos. However, for screen content videos, its effectiveness may vary [32]. In VCM, we assume that the dual I tree is unnecessary when the object is small and the background region is relatively large. This is because introducing a separate tree for chroma can be syntactically inefficient when the simple grayscale occupies a significant portion of the frame. Third, the LMCS is a tool designed to improve encoding performance and subjective image quality [30] by mapping the codewords of the input luma signal to those of the transmitted dynamic range and scaling the chroma signal accordingly. However, in machine vision applications, for frames where grayscale occupies a large portion of the background, encoding luma and chroma separately can introduce inefficiencies and unnecessary syntax. Fourth, the IBC is a technique in which the currently encoded block is predicted from the most similar block within the restored area of the same frame. This approach is anticipated to yield significant BD-rate improvements, particularly in images characterized by repetitive patterns, such as screen video content [33]. In VCM, where non-ROI regions are grayscale and have repetitive patterns, IBC can effectively compress these areas without losing critical information, thereby improving the overall encoding efficiency. Lastly, the ESD is a method that improves performance in terms of speed by determining the inter-frame prediction mode at an early stage. Traditionally, the inter-frame prediction mode was determined by calculating the RD cost for all modes to determine the optimal mode. Each RD cost calculation involves high complexity, leading to the possibility of improving efficiency by determining the mode at an early stage without performing all calculations. In the case of the ESD, after searching for the optimal 2N \(\times\) 2N mode, if the differential motion vector and coded block flag are zero in the selected optimal mode, no further search is conducted, and it is determined early on to be a skip mode [34]. In the context of VCM, especially for the frames where preprocessing introduced distinct regions, ESD can help quickly identify and skip non-critical regions, thus focusing resources on the ROI. When there is a large grayscale region that is simple, it is likely that the largest block will be selected, making it unnecessary to partition the tree into smaller blocks. Therefore, making early skip decisions can be considered more efficient. This selective processing aligns with the goals of machine vision, where attention needs to be directed primarily at areas of interest.
In Table 1, each encoding option is represented by i. In the VTM 12.0, the default configuration activates the LMCS, deblocking filter, and dual I tree, while disabling the IBC and ESD, as listed in Table 1. The recent VCM-RS 0.6.0 adheres to the default settings of the VTM 12.0 without modifications to specific filters or options. These settings, though primarily tailored to human visual perception, may not align with the objectives of enhancing machine vision performance. Moreover, for every frame processed by the encoder, alternative encoding options might better optimize the balance between the detection accuracy and bitrate efficiency for VCM tasks. There is scant research on the specific effects of each option within the VCM context. This research distinctively proposes a novel framework, DASM, aimed at determining the most suitable combination of encoding options for each input video. We tailored the encoding process to individual video characteristics, achieving bitrate savings, and advancing encoding technology for machine vision applications.
3 Proposed method
This section details the development process of the DASM framework. This process involves a thorough examination of the encoding options of the VCM-RS. Based on this analysis, we constructed selectors for encoding options. Finally, the approach includes video compression for machines with the optimized options selected. Figure 2 illustrates an overview of the proposed method. The details regarding DASM are described in the following sections.

Detailed architecture of the DASM framework
3.1 Coding options test
The encoding tools in VCM-RS, based on the VTM, include the deblocking filters and LMCS for in-loop filters, dual I tree, and IBC for screen content coding tools, along with adjustments for the ESD. As noted in Section 2.2, VCM-RS follows the default settings of the VTM encoding options for the use of each option. However, the experimental analysis revealed that deviating from the default options of the VTM can result in better compression performance in terms of BD-rate, BD mean average precision (BD-mAP), and BD multiple object tracking accuracy (BD-MOTA). To demonstrate this, we compressed the video datasets from the CTC [28] provided by the MPEG VCM, including the SFU-HW-Objects-v1 [4], TVD [5], and Multiple Object Tracking datasets (i.e., MOT15 [35], MOT17 [36], MOT20 [37]), using the VCM-RS. The VCM-RS 0.6.0 employed for encoding that uses the VTM 12.0, serves as the anchor for the results comparison. We employed TVD, MOT15, MOT17, and MOT20 as the training datasets, and the SFU-HW-Objects-v1 dataset was applied as the testing dataset. The TVD has a resolution of 1920 × 1080. The resolution of MOT15 is \(640 \times 480\), and the resolution of both MOT17 and MOT20 is \(1920 \times 1080\). Unlike traditional codecs, such as HEVC and VVC, which measure the BD-rate and BD peak signal-to-noise ratio (PSNR) based on the bitrate and PSNR graph, the VCM-RS compares the compression performance using the mAP and MOTA instead of the PSNR to suit machine vision tasks better. For training data, we measured MOTA using the JDE-1088 × 608 [38] model. Based on this, we calculated the BD-rate and BD-MOTA. The Faster R-CNN X101-FPN [39] was employed to measure the mAP of the test data.
When encoding the training and testing sets, we labeled the data based on whether changing the default options for the deblocking filter, LMCS, dual I tree, IBC, and ESD led to improved or degraded results for the BD-rate, BD-mAP, or BD-MOTA compared to the anchor. For example, Table 2 shows the results of encoding the test dataset with the opposite options to the anchor. During BD-rate calculation, errors can occur when the mAP value is nonmonotonic relative to the bitrate. To address this, we also presented Pareto mAP, a metric that selects only the points where the mAP increases monotonically relative to the bitrate for each sequence, ensuring that the BD-rate is calculated without errors. In addition, we encoded the test dataset with LMCS, IBC, and ESD options opposite to the anchor simultaneously, which individually showed better performance over the anchor in Table 2. Table 3 presents the results, showing improved compression performance. These experiments demonstrate that following the anchor option may not be optimal for VCM. Thus, we identified sets of option combinations for each video sequence and QP that yielded improved outcomes, detailed in subsection 3.2.1. In sum, we created ground truth labels for each video sequence depending on the QP. The labels were applied as ground truth to train the encoding option selectors of DASM, as detailed in the following section. Following the CTC [28], encoding was performed in an RA environment, ensuring the broad applicability of the framework across various encoding scenarios. The hardware used for this process includes an Intel core i7-10700 CPU at 2.90 GHz and an Nvidia GeForce RTX 3080 (10 GB) GPU.
3.2 Encoding option selector
The DASM framework, as shown in Fig. 2, comprises encoding option selectors, with each selector designed and trained for individual encoding options. Inputs for these selectors are the QP information and frames in YUV format. In the video sequence, each frame is extracted at a rate of one per second to serve as input. The Y (luminance) and UV (chrominance) components of the frames are separated and input individually, allowing for tailored processing that acknowledges the distinct characteristics and significance of each component in the encoding process. The optimal set of encoding options could vary depending on the QP, even for the same video. To learn and distinguish these variations specific to the QP for the same video, we chose to explicitly input the QP values into the classifier. The QP map generator transforms the QP values, which range from 20 to 58, into a tensor with values ranging from 0 to 1. This tensor was resized to a height and width of 224 before inputting it into each selector. This approach enables each selector to make decisions based on the content of the video frames and QP values, optimizing the encoding process.
The Y and UV information and the QP data initially pass through a convolutional (conv) layer designed to output a single channel, resulting in a total of three channels. However, for the LMCS and dual I tree options, which are significantly influenced by the relationship between the Y and UV components, the relationship was emphasized by processing Y through a 32-channel convolutional layer, UV through a 16-channel layer, and QP through a 16-channel layer, resulting in a total of 64 channels. After the Y, UV, and QP data are processed through these convolutional layers, they are concatenated and input into a classifying network, based on ResNet34 architecture [40]. This ResNet structure is trained from scratch, without using any pre-trained models. Following this, the network employs a global average pooling layer to output 512 nodes, which pass through two fully connected (FC) layers, one with 512 nodes and another with 128 nodes. Finally, a softmax function is applied to output the activation probabilities. The activation probabilities are input through an encoding option switch (EOS) described in the following subsection, which regulates the switching of encoding options.
3.2.1 Training process of encoding option selector
For data generation, we employed TVD, MOT15, MOT17, and MOT20 as training datasets and SFU as test dataset. To label the datasets, we encoded each dataset by independently changing only one coding tool option from its default or anchor state. This process generated results for the six QPs of all datasets by encoding them oppositely to the default anchor state. For each sequence and each QP, we replaced the results with those encoded oppositely to the anchor and examined the changes in BD-Rate and BD-mAP or BD-MOTA. If the results showed improvements over the anchor for all metrics, we labeled the dataset as 1; otherwise, we labeled it as 0. We repeated this labeling process for all five coding tools across the datasets.
For the training procedure, we trained the Encoding Option Selectors using the aforementioned labeled datasets. The input consisted of frames sampled at one frame per second from each video sequence. The output was the prediction of 0 or 1, with the labeled 0 and 1 serving as the ground truth for training, applying a binary cross-entropy loss function. The training was conducted with a batch size of 64 over 300,000 iterations, employing the Adam optimizer. The learning schedule was cosine annealing warm restarts, with the learning rate starting at 0.001 and decreasing to a minimum of 0.000001, according to the scheduler.
3.3 Encoding option switch (EOS)
Within the DASM framework, the EOS determines whether to activate or deactivate encoding options by comparing the probabilities output from softmax, ranging between 0 and 1, with the predefined threshold values:
In Eq. 1, the EOS corresponds to the function \(\phi ()\), where \(\alpha _{i}\) represents the probability values obtained from the softmax, and \(\tau _{i}\) represents the threshold value for each encoding option.
For a video sequence extracted at one frame per second, if the probability exceeds the threshold, as defined in Eq. 1, in more than half of the frames, the EOS triggers a switch to turn on the VTM options. Conversely, if the probability is below the threshold in more than half of the frames of the video sequence, the switch turns off the option. These settings are relayed to the VTM encoder of VCM-RS, dictating the encoding configuration within the VCM-RS framework. This mechanism ensures that encoding options are dynamically adjusted based on the evaluated probabilities, optimizing the encoding process for enhanced performance and efficiency.
While traditional rounding functions typically round these softmax output probabilities based on a 0.5 threshold, the EOS employs specific threshold values for each encoding option to determine on their activation status. This approach tailors the activation process to the unique requirements and performance sensitivities of each option. In the confusion matrix, considering the default options of the VTM as “true”, the labels for each video sequence and QP can either be true or false. A true negative occurs when both the label and prediction represent the reverse of the default option. A false positive arises when the label is the reverse of the default option, but the prediction favors the default option. A false negative is identified when the label supports the default option, but the prediction opts for the reverse. A true positive is noted when both the label and prediction align with the default option. A false negative represents a scenario in which the system incorrectly chooses the reverse of the default or anchor option (a considerable error). Thus, we meticulously adjusted the threshold for each classifier from 0.1 to 0.9, calculating the recall value to minimize the false negatives and selecting the most effective threshold accordingly. Table 4 displays the thresholds set as a result. In addition, experiments regarding the threshold in relation to the F1-score were conducted, with detailed outcomes of these analyses available in the ablation study.
4 Experimental results
4.1 Experimental setup
The SFU-HW-Objects-v1 video dataset was employed to test video compression using the DASM framework. This dataset was accepted as a testing dataset by the MPEG VCM group, comprising four classes with 13 sequences. Specifically, Class A includes Traffic, Class B consists of ParkScene, Cactus, BasketballDrive, BQTerrace, Class C comprises BasketballDrill, BQMall, PartyScene, RaceHorses, and Class D includes BasketballPass, BQSquare, BlowingBubbles, RaceHorses. These classes have resolutions of \(2560 \times 1600\), \(1920 \times 1080\), \(832 \times 480\), and \(416 \times 240\), respectively. Each sequence was compressed at six QP points, as specified in the CTC [28]. The metric mAP@[0.5:0.95], as described in the previous section, was selected to assess the machine vision performance. All experiments were conducted in an RA configuration based on the VTM 12.0, adhering to the VCM CTC [28].

Rate–distortion curve for the proposed method, compared with the VCM-RS Anchor on SFU-HW-Objects-v1 Class A (Traffic) on object detection tasks

Rate–distortion curves for the proposed method, compared with the VCM-RS Anchor on SFU-HW-Objects-v1 Class B (ParkScene, Cactus, BasketballDrive, BQTerrace) on object detection tasks

Rate–distortion curves for the proposed method, compared with the VCM-RS Anchor on SFU-HW-Objects-v1 Class C (BasketballDrill, BQMall, PartyScene, RaceHorses) on object detection tasks

Rate–distortion curves for the proposed method, compared with the VCM-RS Anchor on SFU-HW-Objects-v1 Class D (BasketballPass, BQSquare, BlowingBubbles, RaceHorses) on object detection tasks
4.2 Compression results on the video dataset
The DASM framework, proposed for video compression with machine vision considerations, was compared using the VCM-RS 0.6.0, based on the current SOTA video compression model VTM. Table 5 and Figs. 3, 4, 5, and 6 present the results for video resolution-specific BD-rate and BD-mAP, alongside the graphical data obtained using the proposed method. In Table 5, BD-rate values accompanied by asterisks indicate instances when the mAP was nonmonotonic with respect to the QP, preventing the accurate calculation of BD-rate across all six points. Consequently, these values were substituted with figures that did not cause calculation errors and were excluded from the average value computations. Compression via DASM resulted in an average BD-rate improvement of \(-\)5.91%, indicating a high level of compression efficiency. Furthermore, the BD-mAP increased by an average of 0.51, demonstrating improved compression efficiency and enhanced detection performance for machine vision tasks. An improvement in compression efficiency was observed across all resolutions, with notably exceptional efficiency for BQSquare, where the BD-Rate reached \(-\)19.51%. In addition, the operation of the encoding option selectors within the DASM framework took an average of only 0.84296 s, exerting a minimal influence on the overall video compression timeline as shown in Table 6.
5 Ablation study
5.1 Compression results from thresholds based on F1 score
This subsection presents the video compression results for DASM using the encoding options selectors trained with threshold values determined by the F1-score, as described in Section 3.3. Table 7 displays the thresholds for the encoding options learned for the selectors. The compression results, in Table 8, indicate an average BD-rate reduction of 2.47. In addition, there was a gain of 0.39 in BD-mAP. In cases where the BD-rate results include asterisks indicate that the mAP is nonmonotonic with respect to the QP, and a non-error-inducing value was substituted when all six points could not be used to determine the BD-rate due to errors. These values were not included in the average calculations. Figures 7, 8, 9, and 10 compare the performance of the proposed method and the anchor across various video resolutions.
5.2 Compression results measured with YOLOv8
In this subsection, we present the compression results obtained using labels derived from thresholds based on recall, evaluated with YOLOv8 [41] instead of the previously used object detection model, Faster R-CNN from CTC. Class D, which contains annotation errors with YOLOv8, was excluded. As shown in Table 9, in Classes A, B, and C, the proposed method demonstrates improvements over the anchor in both BD-Rate and BD-mAP.

Rate-distortion curve for the proposed method from the F1-score, compared with the VCM-RS Anchor on SFU-HW-Objects-v1 Class A (Traffic) on object detection tasks

Rate-distortion curves for the proposed method, compared with the VCM-RS Anchor on SFU-HW-Objects-v1 Class B (ParkScene, Cactus, BasketballDrive, BQTerrace) on object detection tasks

Rate-distortion curves for the proposed method, compared with the VCM-RS Anchor on SFU-HW-Objects-v1 Class C (BasketballDrill, BQMall, PartyScene, RaceHorses) on object detection tasks

Rate-distortion curves for the proposed method, compared with the VCM-RS Anchor on SFU-HW-Objects-v1 Class D (BasketballPass, BQSquare, BlowingBubbles, RaceHorses) on object detection tasks
6 Conclusion
This paper tackles the limitation of VVC coding efficiency, particularly core encoding tools in VVC per video sequence for machine vision tasks, where the video for the machine has very different characteristics from natural video. For that, we propose a novel framework, DASM, for better video compression tailored to machine vision tasks. The proposed approach demonstrates a significant BD-rate reduction of up to 19.51% on the SFU-HW-Objects-v1 dataset. Importantly, this work represents the first endeavor in the research that configures encoding tools to be adaptive to video sequences based on their suitability for machine vision tasks. Thorough experiments show that DASM on top of VCM could enhance compression efficiency across various machine-oriented video sequences without appreciably extending the encoding time.
Availability of data and materials
TVD is available at the public repository [https://multimedia.tencent.com/resources/tvd, accessed in April 2024] while SFU dataset can be accessed as shown in CTC [28] but restrictions apply to the SFU dataset.
Abbreviations
- BD:
-
Bjontegaard delta
- CNN:
-
Convolutional neural network
- CTC:
-
Common test conditions
- CTU:
-
Coding tree unit
- DASM:
-
Deep learning-based adaptive switch networks for machines
- EOS:
-
Encoding options switch
- ESD:
-
Early skip decisions
- HEVC:
-
High-efficiency video coding
- IBC:
-
Intra-block copy
- LMCS:
-
Luma mapping and chroma scaling
- mAP:
-
Mean average precision
- MOTA:
-
Multiple object tracking accuracy
- MPEG:
-
Moving picture experts group
- QP:
-
Quantization parameter
- RA:
-
Random access
- R-CNN:
-
Regions with convolutional neural network
- RD:
-
Rate–distortion
- ROI:
-
Region of interests
- TVD:
-
Tencent video dataset
- VCM:
-
Video coding for machines
- VCM-RS:
-
VCM reference software
- VTM:
-
Versatile video coding test model
- VVC:
-
Versatile video coding
References
B. Bross, Y.-K. Wang, Y. Ye, S. Liu, J. Chen, G.J. Sullivan, J.-R. Ohm, Overview of the versatile video coding (VVC) standard and its applications. IEEE Trans. Circuits Syst. Video Technol. 31(10), 3736–3764 (2021)
G.J. Sullivan, J.R. Ohm, W.J. Han, T. Wiegand, Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 22(12), 1649–1668 (2012)
S. Liu, C. Rosewarne, Working draft 2 of video coding for machines, document ISO/IEC JTC1/SC29/WG 04, N00465, (2024)
SFU-HW-Object-v1, ftp://hevc@mpeg.tnt.uni-hannover.de/testsequences/. Accessed July 2024
Tencent video dataset, https://multimedia.tencent.com/resources/tvd. Accessed July 2024
S. Różek, O. Stankiewicz, S. Maćkowiak, M. Domański, Video coding for machines using object analysis and standard video codecs, in Proceedings 2023 IEEE International Conference on Visual Communications and Image Processing (VCIP), (Jeju, Korea, 2023), pp. 1–5
Z. Huang, C. Jia, S. Wang, S. Ma, Visual analysis motivated rate-distortion model for image coding, in Proceedings 2021 IEEE International Conference on Multimedia and Expo (ICME), (2021), pp. 1–6
Y. Lee, S. Kim, K. Yoon, H. Lim, S. Kwak, H.-G. Choo, Machine-Attention-based Video Coding for Machines, in Proceedings 2023 IEEE International Conference on Image Processing (ICIP), (Kuala Lumpur, Malalysia, 2023), pp. 2700–2704
J.Y. Lee, Y. Choi, T. Van Le, K. Choi, Efficient feature coding based on performance analysis of Versatile Video Coding (VVC) in Video Coding for Machines (VCM). Multimed. Tools Appl. 82(27), 42803–42816 (2023)
D. Ding, Z. Xin, L. Zizheng, L. Shan, [VCM] Bitwise efficiency: truncating bit depth for machine video coding, document ISO/IEC JTC1/SC29/WG 04, m65525 (Hannover, Germany, 2023)
K. Fischer, F. Fleckenstein, C. Herglotz, A. Kaup, Saliency-driven versatile video coding for neural object detection, in Proceedings 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), (Toronto, Canada, 2021), pp. 1505–1509
Z. Lui, Y. Zhang, R. Chernyak, H. Zhu, X. Xu, S. Liu, J. Jia, Z. Chen, M. W. Park, [VCM] Response to VCM call for proposals—an EVC based solution, document ISO/IEC JTC1/SC29/WG 04, m61452 (Mainz, Germany, 2022)
L. Yu, VCM-CE 4: temporal resampling, document ISO/IEC JTC1/SC29/WG 04, N00383 (Switzerland, Geneva, 2023)
S. Kim, M. Jeong, J. Lee, H. Lee, S. Jung, [VCM] Proposed text of RoI based coding, document ISO/IEC JTC1/SC29/WG 04, m64627 (Switzerland, Geneva, 2023)
J. Lee, S. Cho, S.-K. Beack, Context-adaptive entropy model for end-to-end optimized image compression, in Proceedings 2019 International Conference on Learning Representations (ICLR), (New Orleans, USA, 2019), pp. 1–20
D. Minnen, S. Singh, Channel-wise autoregressive entropy models for learned image compression”, in Proceedings 2020 IEEE International Conference on Image Processing (ICIP) (Abu Dhabi, United Arab Emirates, 2020), pp. 3339–3343
J. Lin, D. Liu, H. Li, F. Wu, M-LVC: multiple frames prediction for learned video compression, in Proceedings 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (Seattle, USA, 2020), pp. 3546–3554
Z. Cheng, H. Sun, M. Takeuchi, J. Katto, Learned image compression with discretized gaussian mixture likelihoods and attention modules, in Proceedings 2020 IEEE/CVF conference on computer vision and pattern recognition (CVPR), (Seattle, USA, 2020), pp. 7939–7948
D. He, Y. Zheng, B. Sun, Y. Wang, H. Qin, Checkerboard context model for efficient learned image compression, in Proceedings 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (Nashville, USA, 2021), pp. 14771–14780
Y. Qian, M. Lin, X. Sun, Z. Tan, R. Jin, Entroformer: a transformer-based entropy model for learned image compression, in Proceedings 2022 International Conference on Learning Representations (ICLR), (Virtual, 2022), pp. 1–15
J. Li, B. Li, Y. Lu, Neural video compression with diverse contexts, in Proceedings 2023 IEEE/CVF conference on computer vision and pattern recognition (CVPR), (Vancouver, Canada, 2023), pp. 22616–22626
N. Le, H. Zhang, F. Cricri, R. Ghaznavi-Youvalari, E. Rahtu, Image coding for machines: an end-to-end learned approach, in Proceedings 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), (Toronto, Canada, 2021), pp. 1590–1594
Y. Kim, H. Jeong, J. Yu, Y. Kim, J. Lee, S. Y. Jeong, H. Y. Kim, End-to-end learnable multi-scale feature compression for VCM. IEEE Trans. Circuits Syst. Video Technol. (2023), p. 1
S. Suzuki, M. Takagi, K. Hayase, T. Onishi, A. Shimizu, Image pre-transformation for recognition-aware image compression, in Proceedings 2019 IEEE International Conference on Image Processing (ICIP), (Taipei, Taiwan, 2019), pp. 2686–2690
K. Fischer, C. Herglotz, A. Kaup, On intra video coding and in-loop filtering for neural object detection networks, in Proceedings 2020 IEEE International Conference on Image Processing (ICIP), (Abu Dhabi, United Arab Emirates, 2020), pp. 1147–1151
H. Yu, A. Liu, K. Jia, L, Yu, [VCM] CE2-related: single layer framework with NNIC and VVC for video coding for machines, document ISO/IEC JTC1/SC29/WG 04, m64253, (Geneva, Switzerland, 2023)
Y. Lee, K. Yoon, H. Lim, S. Kwak, S. Jung, W, Cheong, H. -G. Choo, [VCM] comments on VCM anchor, document ISO/IEC JTC1/SC29/WG 04, m64809, (Hannover, Germany, 2023)
S. Liu, H. Zhang, [VCM] Common test conditions for video coding for machines, document ISO/IEC JTC1/SC29/WG 04, m62002, (2023)
D. Ding, H. Wang, X. Zhao, X. Pan, Z. Lui, X. Xu, S. Lui, [VCM] A curve fitting approach to transform nonmonotonic test data for BD-rate calculation, document ISO/IEC JTC1/SC29/WG 04, m65531 (Hannover, Germany, 2023)
M. Karczewicz et al., VVC in-loop filters. IEEE Trans. Circuits Syst. Video Technol. 31(10), 3907–3925 (2021)
Y.-W. Huang, J. An, H. Huang, X. Li, S.-T. Hsiang, K. Zhang, H. Gao, J. Ma, O. Chubach, Block partitioning structure in the VVC standard. IEEE Trans. Circuits Syst. Video Technol. 31(10), 3818–3833 (2021)
W. Zhu, J. Xu, L. Zhang, Y. Wang, Adaptive dual tree structure for screen content coding, in Proceedings 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), (Toronto, Canada, 2021), pp. 1550–1554
X. Xu et al., Intra block copy in HEVC screen content coding extensions. IEEE J. Emerg. Sel. Top. Circuits Syst. 6(4), 409–419 (2016)
J. Kim, J. Yang, K. Won, B. Jeon, Early determination of mode decision for HEVC, in Proceedings 2012 Picture Coding Symposium (Krakow, Poland, 2012), pp. 449–452
L. Leal-Taixé, A. Milan, I. Reid, S. Roth, K. Schindler, Motchallenge 2015: towards a benchmark for multi-target tracking, arXiv preprint arXiv:1504.01942, (2015)
A. Milan, L. Leal-Taixé, I. Reid, S. Roth, K. Schindler, MOT16: a benchmark for multi-object tracking, arXiv preprint arXiv:1603.00831, (2016)
P. Dendorfer, H. Rezatofighi, A. Milan, J. Shi, D. Cremers, I. Reid, S. Roth, K. Schindler, L. Leal-Taixé, Mot20: a benchmark for multi object tracking in crowded scenes, arXiv preprint arXiv:2003.09003, (2020)
Z. Wang, L. Zheng, Y. Liu, Y. Li, S. Wang, Towards real-time multi-object tracking, in Proceedings 2020 European conference on computer vision (ECCV), (2020), pp. 107–122
S. Ren, K. He, R. Girshick, J. Sun, Faster R-CNN: towards real-time object object detection with region proposal networks. Adv. Neural Inform. Process. Syst. 28, 91–99 (2015)
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in Proceedings 2016 IEEE conference on computer vision and pattern recognition (CVPR), (Las Vegas, USA, 2016), pp. 770–778
D. Reis, J. Kupec, J. Hong, A. Daoudi, Real-time flying object detection with YOLOv8, arXiv preprint arXiv:2305.09972, (2023)
Acknowledgements
The authors would like to thank the experts of ISO/IEC MPEG video for their contributions to VCM.
Funding
This work was supported in part by Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (2020-0-00011, Video Coding for Machine) and in part by BK21 FOUR project (AI-driven Convergence Software Education Research Program) funded by the Ministry of Education, School of Computer Science and Engineering, Kyungpook National University, Korea (4120240214871)
Author information
Authors and Affiliations
Contributions
Conceptualization, S.P.; methodology, S.P. and A.K.; software, S.W.; validation, D.K., M.P., H.L., S.J., and S.K.; investigation, M.P., S.W., A.K., and D.K.; funding acquisition, H.L., S.J., S.K., and S.P.; writing—original draft, A.K., M.P. and S.W.; writing-review and editing, D.K., A.K., and S.W.; supervision, S.P. All the authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Kim, A., Woo, St., Park, M. et al. Deep learning-guided video compression for machine vision tasks. J Image Video Proc. 2024, 32 (2024). https://doi.org/10.1186/s13640-024-00649-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13640-024-00649-w