
Abstract
Automatic modulation classification (AMC) is an important process for future communication systems with prominent applications from spectrum management, and secure communication, to cognitive radio. The requirement for an efficient AMC classifier is due to its capability in blind modulation recognition, which is a difficult task in real scenarios where the limitations of traditional hardware and the complexity of channel impairments are involved. Therefore, this paper proposes a complete real-time AMC system based on software-defined radio and deep learning architecture. The system demodulation performance is verified through simulations and real channel impairment conditions to ensure reliability. With at most 6 times reduced number of parameters, two proposed models convolutional long short-term memory deep neural network and residual long short-term memory neural network also show a general improvement in classification accuracy compared with reference studies. The performance of these models at real-time AMC is tested with suitable processing time for practical applications.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.1 Introduction
The concept of an automatic modulation classification (AMC) system relies on an intermediate process, which has the advantage of blindly recognizing input signal modulation to provide proper demodulation [1]. The applications of the AMC system are various through providing the fundamentals for cognitive radio (CR) [2], in which a CR system [3] has to consist of different capabilities, i.e., spectrum sensing, such as sensing for anomaly event [4], and high adaptation through learning. On the other hand, AMC can help to assure the security of the communications system [5] and prevent the degradation of the quality of service (QoS) [6].
Previous solutions for AMC revolve around applying probability theory and predicting based on the extracted statistical features of the input signal [1]. One of the most popular probability theories applied in AMC is the maximum likelihood-based classifier, which selects the most suitable modulation scheme that maximizes the likelihood of received signal through the evaluation of channel coefficients in an example of additive white Gaussian noise (AWGN) and fading channel [7]. When the problem comes to undefinable channel parameters, the theory of maximum likelihood is replaced by the average likelihood ratio test (AVRT) [8] or the general likelihood ratio test (GLRT) [9]; however, the tradeoff is the increasing complexity of the classifier. The prediction based on extracted features includes two phases: preprocessing signals for feature extraction and classifying using a machine learning (ML) classifier. Selected features have to ensure classification at low Signal-to-Noise Ratio (SNR) levels, be resilient to interference, and most importantly, characterize the signature of different modulations. Some effective and widely used features depend on the spectral [10], moment [11], and cyclo stationarity [12] characteristics of the observed signal. Regarding the classifier, machine learning methods are varied from evaluating a predefined number of relevant samples as in k-nearest neighbor (KNN) [13] to creating boundaries by hyperplanes to separate samples of same modulation type in support vector machine (SVM) [14]. The traditional approaches have limitations in significantly increasing the complexity of system design when expanding the number of modulation classes. Therefore, recent research has proposed different classifiers based on deep learning (DL), due to its versatile and flexible basics. Convolutional neural network (CNN) and the residual deep neural network (ResNet), widely used in computer vision and natural language processing, are also efficient when applied in AMC [15,16,17,18]. Other architectures based on the concept of recursive neural networks such as recurrent neural network (RNN) [19] and long short-term memory neural network (LSTM) [20] have also shown improvement in classification accuracy. By combining both CNN and LSTM, a hybrid model convolution long short-term memory deep neural network (CLDNN) can be obtained for AMC with significant results for further applications [21, 22].
The implementation of DL-based classifiers can be realized using software-defined radio (SDR) [23], which is a communication system that is configured and controlled by software through a platform like GNU radio [24]. SDR has been widely used for verifying the theory concept and algorithm and testing the reliability of cutting-edge communication systems before production. The applications of SDR are various, from verifying the theory of 5G communication system [25], to testing the performance of spectrum sensing [26]. The AMC-based system in [18] introduces the integration of DL classifiers into the SDR communication system, with real-time AMC at the from 2 to 20 m distance testing conditions between transmitter and receiver, with different modulations such as binary phase shift keying (BPSK), and quadrature phase shift keying (QPSK). On the other hand, the papers in [27, 28] only propose the DL models but do not include the AMC at real-time verification. The limitations of these works are insufficient testing scenarios for AMC, and therefore, they do not propose adequate approaches to validate the performance of AMC in real applications.
Thus, the contributions of this paper are summarized as follows:
-
Propose an AMC-decision-driven receiver architecture based on SDR. The system performance is verified through simulations and real scenario tests to validate the effect of DL-based AMC classifiers on the overall system. The experiment shows good results for effectively implementing a practical AMC communications system.
-
Propose two AMC classifiers CLDNN and RSTM models, with improved classification accuracy at the whole SNR range compared with reference architectures. For real-time classification, the proposed models have appropriate processing time to adapt to the operation of the AMC-based communication system.
The rest of this paper is constructed as follows. In Sect. 2, the related works of the SDR-based transceiver architecture and also the reference DL models are introduced. In Sect. 3, the proposed SDR-based receiver architecture for real-time AMC and the proposed CLDNN and RSTM are described and constructed. In Sect. 4, the training results of both CLDNN and RSTM models are compared with reference models on a public dataset, and they also be tested on a synthesized dataset on GNU radio. At the same time, the performance of the system is verified on the bit-error-rate (BER) simulations on GNU radio. Then, real scenario tests are carried out with classification accuracy and BER metrics to evaluate the performance of both the AMC classifier and demodulation system in real data transmission. Finally, in Sect. 5, the results of the paper are summarized with the main contributions.
2 Existing DL architecture and modulation classification system
2.1 DL architecture
Deep Learning has been researched to apply in communication systems and specifically has shown significant results in AMC tasks. Among previous architectures, CNN, CLDNN, and ResNet have shown potential in real applications due to their accuracy and reduced processing time.
2.1.1 CNN model
The authors in [15] propose a baseline CNN architecture, including two convolutional layers with a total number of parameters over 2 million. The architecture uses two consecutive CNN layers and the output is connected to fully connected layers. The authors use a large number of filters in two convolutional layers, specifically 256, and 80 filters in the first and second CNN layers. The overall accuracy performance of this model reaches 73% at SNR equal to 16 dB.
2.1.2 CLDNN model
In paper [21], the authors propose a hybrid model between CNN and LSTM to enhance classification performance. The model includes three consecutive CNN layers with numbers of filters being 256, 256, and 80 and the feature map is then mapped to an LSTM layer with 50 units. The output of this is sent to a dense layer for giving a prediction. The total parameters of the model are over 2.5 million parameters. The highest accuracy of this model is 91.5% at 14 dB. Although the mentioned CNN and CLDNN architectures achieve considerable results for AMC, their architecture could be further optimized to reduce the number of parameters to adapt to practical applications.
2.1.3 ResNet model
In paper [18], the authors introduce the multi-skip deep neural network based on the residual stack as shown in Fig. 1. The residual stack contains several one-dimensional convolutional layers, with the addition of three summing points and the final layer of maximum pooling. The multi-skip connections of the residual stack can help to avoid gradient vanishing when concatenating multi-convolutional layers. The architecture in [18] combines 6 consecutive residual stacks and three fully connected layers. The number of parameters used in the architecture is approximately 155,000 parameters, with the highest accuracy at 14 dB equals 96%.

Residual stack architecture
2.2 Transceiver
In this section, an overview of the transceiver in the AMC communication system is summarized, in addition to our illustration of the transmitter realization on GNU radio.
The principles of the transmitter in an SDR-based communications system are summarized in Fig. 2. The raw data stream is first encoded by specific modulation schemes to help the receiver side correct any errors due to channel impairments [23]. Then, the output data are mapped to the desired modulation scheme, i.e., BPSK, QPSK. The pulse-shaping filter is applied to the IQ signals to limit the output spectrum of the signals. Some pulse-shaping filters widely used are the root-raised cosine filter and the Gaussian filter. Finally, this signal is converted to a passband frequency by mixing the signal with the desired carrier frequency.

SDR-based transmitter
Phase shift keying (PSK) modulation-based transmitter, which is an example of SDR-based communications, is shown in Fig 3. First, the files of a transmitted message and a preamble are prepared. The use of a preamble file is to assist the receiver in recovering the original message. The prefix’s bits need to be chosen to avoid duplicating any of the transmitted file’s bit streams. For example, they could be generated as non-ASCII characters if the message originally contains ASCII characters. To prevent inter-symbol interference, the data stream is first mapped to the required modulation constellation and then filtered using a root-raised cosine filter. This baseband signal is sampled and transformed to a passband signal at a specific center frequency and delivered to an SDR device such as HackRF One for over-the-air transmission. The Constellation Modulator block can be altered by the GFSK Mod and GMSK Mod blocks, if we consider using Gaussian frequency shift keying (GFSK), or Gaussian minimum shift keying (GMSK), as in Figs. 4 and 5, respectively.

GNU radio realization of PSK transmitter

GNU radio realization of GFSK transmitter

GNU radio realization of GMSK transmitter
Regarding the receiver side of the AMC-based system, the general architecture contains three main blocks [2], shown in Fig. 6. The received signal is preprocessed to compensate for channel impairments, and then, the signal is passed through to the AMC classifier to generate a prediction, and upon the predicted information, a suitable demodulation process can proceed. However, the comprehensive realization of this general system in the SDR platform for real-time AMC has not received much attention.

AMC receiver
3 Proposed DL classifiers and receiver architecture
3.1 CLDNN architecture
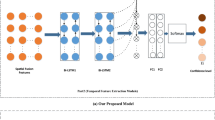
The first DL architecture proposed in this paper is the CLDNN architecture, which utilizes both the advantages of the convolutional layer and the long short-term memory layer, which is illustrated in Fig. 7. The total trainable parameters of this architecture are 309,450 parameters.

Proposed CLDNN architecture
The long time-series signals are first processed and represented by shorter high-level time-series signals with the use of a convolutional layer and max-pooling layer. The use of a one-dimensional (1D) convolutional layer is to adapt to the time-series characteristics of the input data. The output feature maps from this step are then passed through two consecutive LSTM layers. Two consecutive LSTM layers are used to utilize their coherent memory characteristics. This memory characteristic is very effective for processing the coherence of long-term temporal data as in different modulation schemes [29]. The introduction of two dropout layers is for limiting the overfitting phenomenon. Finally, the output feature map is passed through a fully connected layer with Softmax activation function to give a prediction.
The input samples are first passed through a 1D convolutional layer containing 64 filters with a kernel size of 7 and downsampled by a maximum pooling filter of size 2. Two consecutive LSTM layers contain 128 hidden units, with a dropout rate of 0.3 in both two dropout layers.
3.2 RSTM architecture
A residual long short-term memory neural network architecture is introduced in this section, with the detailed architecture shown in Fig. 8. The RSTM architecture has 428,234 total parameters. The proposed architecture is developed based on the residual stack with 5 consecutive one-dimensional CNN layers in Fig. 1.

Proposed RSTM architecture
In this architecture, we propose using only one residual stack and then passing the feature map into two LSTM layers with dropout layers in between. Adding the LSTM layers could increase the number of parameters in the architecture; however, passing the feature map to LSTM layers can help utilize the coherent memory characteristics of the LSTM layers when processing the extracted feature map of the residual stack. For the design of the residual stack, all five 1D convolutional layers use a kernel size of 7 with 64 output filters. For the first 1D convolutional layer, we use the linear activation function, and the rest of the convolutional layers are implemented with the ReLU activation function. The feature map output from the residual stack is processed by two LSTM layers with 128 hidden units. The dropout rate is also 0.3.
3.3 Receiver
The working principles of our receiver are illustrated in Fig. 9. Our receiver is developed based on the general processing of an SDR-based communications system [23]. Signals received at the SDR hardware are downconverted to baseband signals. At the same time, the receiver uses a phase lock loop to correct any frequency mismatch between the transmitter and receiver. Subsequently, the processed signal is passed through an automatic modulation classification block to predict the modulation scheme of this signal. Based on this information, the receiver can decide on suitable demodulating processes. Then, the signal is processed for optimal sampling with match filtering and equalizing channel impairments. Subsequently, the symbols from the signal can be mapped to its corresponding bit representation and finally decoded to obtain subtle information.

Receiver block diagram
The receiver system is illustrated in Fig. 10. The block osmocom Source which is the representation of the HackRF One receiver receives the communication signal and converts it to a baseband signal, shown in Fig. 10. After receiving the signal, the initial processing step is performed by the AGC (Adaptive Gain Control) and FLL (Frequency Locked Loop) Band-Edge blocks. The received baseband signal is under amplitude control by AGC block and then processed to compensate for any frequency offset which is affected by clock mismatch between the transmitter and the receiver by FLL Band-Edge block.
Our modified block, the AMC block, serves as the primary controller for the entire operation. It is in charge of providing an estimate for the input signal’s modulation scheme, with two inputs Frames and Modulation. The AMC block processes a multiplication of the input size corresponding to the models indicated by the Frames parameter and can calculate the classification accuracy based on a provided class in the Modulation parameter. The CLDNN or RSTM model integrated into the block input frames of samples and processes to give preliminary predictions. The process repeats for several iterations, and the class with the highest prediction accuracy will be determined, and its label and index will be produced. Based on the output modulation label, the Selector block can connect the input to its corresponding demodulation process. The parameter index indicates the demodulation process matching the output label from the AMC block, in which the Selector will stream the input signal through the in port to the demodulation process. After that, we continue to demodulate the signal and record the message in an output file.
With the support of the ONNX Runtime platform, the proposed models can be integrated into the GNU Radio flowgraph to give real-time classification [30], with reduced processing time compared with their original format. Table 1 gives the estimated time used for processing one single frame. It also gives the total time elapsed for predicting the most probable modulation scheme of streams of input signals at a specific time for BER calculation. Moreover, this time is not a reception and decoding communication messages time; this is a DL decision time and is acceptable compared to a normal DL model. For one single frame, the CLDNN model can give a prediction after every \(2 \times 10^{-4}\) seconds, and for the RSTM model, this is about \(4 \times 10^{-4}\) seconds, which is a significant processing time reduction from \(4 \times 10^{-3}\) seconds as in [18]. In addition, the total frames required for the AMC process depend on the user’s purpose. For instance, we propose to use 10,000 frames for calculating the BER of the demodulation process, which requires the total number of frames to be sufficiently large to ensure the output class of the AMC being of only the desired modulation, which leads to overall decision time for CLDNN and RSTM being 2s and 4s, as shown in Table 1.

GNU radio realization of classification system
4 Results
4.1 Dataset
In this paper, two datasets are used for training the models. The first dataset is RadioML-2016.10b, which comes from the Deepsig company [31]. The purpose of this dataset is to optimize the architecture of the proposed models. It includes 10 modulation classes under the SNR of range between \(-20\) dB and 18 dB, both analog and digital modulation, i.e., BPSK, QPSK, 8PSK, PAM4, QAM16, QAM64, CPFSK, GMSK, GFSK, and WBFM. This dataset has been widely used in many research papers due to its variability in modulation schemes and corresponding SNR levels. The dataset simulates real-world scenarios by imposing different impairments such as phase and frequency offset, fading channel, and additive white Gaussian noise by using GNU Radio software. It consists of 1,200,000 samples of size \(2\times 128\).
To validate the reliability of the proposed CLDNN and RSTM models in a real data transmission scenario, we propose the GRA dataset with SNR of 24 dB and 10 dB, which is generated by receiving signals under SDR-based data transmissions, including 8 modulation classes, i.e., 8PSK, BPSK, GFSK, GMSK, PAM4, PAM8, QAM16, and QPSK. The dataset contains in total 102,400,000 samples of size \(128\times 2\).
4.2 Training results
The training results of the proposed CLDNN, RSTM classifiers are shown and compared with the model CNN [15], CLDNN [21], ResNet [18]. The most complex model in these papers is CLDNN, with over 2,000,000 trainable parameters, in total.
As shown in Fig. 11, the proposed CLDNN and the RSTM models outperformed the CNN architecture in [15]. Our CLDNN model reaches 93% average accuracy at a high SNR range between 10 dB and 18 dB. On the other hand, our proposed RSTM model obtains an average accuracy of approximately 90% at high SNR levels. In comparison, at high SNR levels, our CLDNN model outperforms the CLDNN architecture in paper [21]. In addition, our proposed RSTM architecture achieves better performance compared to the ResNet architecture in paper [18] with 1–2% higher accuracy at high SNR levels.

Performance comparison—RadioML-2016.10b
4.3 Simulation results
First, we verify the demodulation performance of BPSK and QPSK of the system shown in Fig. 10 under the AWGN channel and frequency offset, which is shown in Fig. 12. Figure 12a shows the theoretical BER of BPSK under AWGN channel and the simulated BER under AWGN channel with additional frequency offset. The simulated results nearly approach the values of BER in theory. On the other hand, from the theory [32], both the BER of QPSK and BPSK have a similar performance. From Fig. 12b, the simulated results of QPSK also approach the theoretical values.
On the other hand, the performance of the proposed models needs to be evaluated on the SDR platform, which leads to our generated dataset on GNU Radio. These modulations are 8PSK, QPSK, BPSK, PAM4, PAM8, QAM16, GMSK, and GFSK, under the conditions of SNR between \(-20\) dB and 20 dB. Figure 13 compares the results of our proposed CLDNN and RSTM models in the new dataset, which exhibits similar trends as in the RadioML-2016.10b dataset. The performance of the CLDNN model outperforms that of RSTM model, despite with considerably smaller number of parameters. Their classification accuracy rapidly rises to more than 98% at high SNR levels; however, the CLDNN still outperforms the RSTM architecture by 1–2%.

Simulated BER in AWGN with frequency offset

Simulated results between proposed CLDNN and RSTM
4.4 Experimental results
Before integrating the CLDNN and RSTM models into the system, we train our proposed models by the GRA dataset with the same 8 modulation schemes as in the simulation results. The dataset is recorded through real data transmissions over two HackRF One devices. The first HackRF One device is considered as a transmitter to transmit modulated signals among 8 modulation schemes. The other device is utilized as a receiver for collecting the modulated signals and recording these to create the dataset. This dataset contains 102,400,000 samples in the SNR of 24 dB and 10 dB, with 50, 000 frames of size 128 for each modulation at a specific SNR level.
A real data transmission process is carried out to evaluate the classification performance of the proposed models with the transmitted signal in the SNR range of 0 dB to 16 dB. Furthermore, to verify the stability of this communication system integrated with the AMC classifiers, a BER measurement is carried out at the distance range between 10 and 70 m, in addition to the SNR range from 8 to 16 dB. The transmitter modulates and sends the contents of a 13-byte message. The receiver, on the other hand, repeatedly determines whether the first 100 consecutive messages have a BER that is less than 50%. It will classify the modulation scheme of the signal, demodulate it, and store the results in a temporary file. The file will be retained to determine the final BER measurement if the instantaneous BER is less than 50%; otherwise, the receiver will repeat the receiving process. If the received process succeeds, beginning from the first initial matching point, data of length \(5000 \times 13\)-byte messages will be collected. Then, a procedure of bit-by-bit comparison with the transmitted message will reveal the number of error bits presented in the file.
Table 2 compares the classification accuracy of 8 modulation schemes between CLDNN and RSTM models. The CLDNN and RSTM models have similar performance at high SNR levels, but the CLDNN model shows better performance at low SNR levels. CLDNN’s classification accuracy typically starts to decline to below 90% at 4 dB, whereas the RSTM model’s accuracy starts to decline at 6 dB. Throughout the results, PAM4, PAM8, QAM16, 8PSK, and BPSK are the modulation schemes that are not difficult to classify, in contrast with GFSK, GMSK, and QPSK.
In Table 3, we also compare the average classification accuracy with previous studies under different distances. The result in [18] was based on the multi-skip residual neural network (MRNN). On the other hand, an approach for AMC based on a modulation diagram constellation was proposed in [33]. The classification accuracy based on CLDNN proposed by this paper is comparatively greater than both of the results in [18, 33]. With the increasing number of modulation schemes from 6 to 8, the classification accuracy of the CLDNN model also increases to above \(96\%\) in general.
For modulation schemes not included in the dataset, the AMC may misclassify these modulation schemes into the existing classes. For example, suppose we aim to transmit a greater order phase shift keying (PSK) modulation scheme such as 16PSK. In that case, the system may misclassify the 16PSK scheme into 8PSK or QPSK classes due to high similarities in modulation constellation. However, the versatility of the deep learning approach can help to cope with the modulation changes with less effort and changes in system complexity by combining the information about the new classes in the training dataset. Although the total modulation classes are 8 modulation schemes, the system includes high-performance and widely used modulation schemes. In addition, the total number of classes is greater than that in [18, 33].
Since integrating both of CLDNN and RSTM models in the demodulation exhibits similar results, the results solely focus on the cases when integrating the CLDNN model. The overview of BER measurements using the proposed CLDNN classifier and six modulation schemes is shown in Table 4. The settings of the real scenario tests are carried out in indoor conditions with a line of sight (LoS) position between two HackRF One devices separated by 10 m to 70 m. To ensure reliability, for each distance setting, we additionally vary different SNR levels between 8 dB and 16 dB. Due to the complexity of the communication channels, the BER of the real demodulating process may differ from what is discussed in Fig. 12.
The BER result of BPSK begins at \(5.8\times {10}^{-4}\%\) at 10 m and 16 dB, which continues to rise to \(1.9\times {10}^{-2}\%\) at 70 m and 8 dB. Under all conditions, the BER of BPSK is maintained below \({10}^{-1}\%\) consistently. BPSK has a low BER since each symbol is only represented by one bit. In [34], the BPSK demodulation process was developed based on deep learning, in which the demodulation performance was measured in the real scenarios, with the BER between 8 dB and 10 dB, being approximately \(0.03\%\). On the other hand, our BER results between 8 dB and 10 dB are approximately \(0.003\%\), which shows a considerably improved demodulation performance.
Regarding the QPSK modulation, the BER results are comparable to that of BPSK modulation. The BER of QPSK starts at \(7.7 \times 10^{-4}\)%, and it continues to rise to \(2.7 \times 10^{-2}\)%. Similar to BPSK, QPSK modulation uses just one bit when we separately consider the in-phase or quadrature component, even though every symbol is represented by two bits; therefore, there is a similar BER result between QPSK and BPSK measurements. However, the results of 8PSK show a degradation in BER. The BER of 8PSK increases significantly from 5.3% to nearly 50% at the final condition. The reason for this phenomenon is due to the introduction of noise, and the complexity of the channel leads to the demodulation of 8PSK becoming difficult. At a smaller extent, the BER of PAM4 increases progressively from \(4.5 \times 10^{-2}\)% to 5.6%.
Concerning GMSK and GFSK modulation schemes, their BER both start at nearly 5% and increase gradually to over 50% by 70 m and 8 dB. The fading channel’s appearance may affect the demodulating process, which leads to low performance of the demodulator when processing timing synchronization.
5 Conclusion
This paper proposes a complete AMC-decision-driven architecture of the receiver developed in SDR. In addition, the two proposed CLDNN and RSTM architectures ensure the processing time for real-time AMC tasks and also have a general improvement in classification accuracy. The performance of the AMC communication system is verified in GNU Radio simulations with simulated BER approaching the theoretic curve. Regarding the real scenario testing, the demodulation performance of the system is affected by the complexity of real channel impairments, which leads to the degradation of BER results. However, the communication process of BPSK and QPSK shows positive results, in which the receiver can successfully demodulate the message with BER under \(10^{-1}\)% including the most severe conditions. Regarding the real-time AMC, the CLDNN model outperforms the proposed RSTM model at low SNR levels, and they both accurately classify with the SNR level of at least 4 dB.
Availibility of data and materials
Not applicable.
References
M. Abdel-Moneim, W. El-Shafai, N. Abdelsalam, E.S. El-Rabaie, F. Abd El-Samie, A survey of traditional and advanced automatic modulation classification techniques, challenges and some novel trends. Int. J. Commun. Syst. (2021). https://doi.org/10.1002/dac.4762
O.A. Dobre, A. Abdi, Y. Bar-Ness, W. Su, Survey of automatic modulation classification techniques: classical approaches and new trends. IET Commun. 1, 137–156 (2007)
X. Zhou, M. Sun, G.Y. Li, B.H.F. Juang, Intelligent wireless communications enabled by cognitive radio and machine learning. China Commun. 15(12), 16–48 (2018). https://doi.org/10.12676/j.cc.2018.12.002
A. Toma, A. Krayani, L. Marcenaro, Y. Gao, C.S. Regazzoni, Deep Learning, for Spectrum Anomaly Detection in Cognitive mmWave Radios, in IEEE 31st Annual International Symposium on Personal. Indoor and Mobile Radio Communications, pp. 1–7 (2020). https://doi.org/10.1109/PIMRC48278.2020.9217240
J. Bai, X. Wang, Z. Xiao, H. Zhou, T.A.A. Ali, Y. Li, L. Jiao, Achieving efficient feature representation for modulation signal: a cooperative contrast learning approach. IEEE Internet Things J. 11(9), 16196–16211 (2024). https://doi.org/10.1109/JIOT.2024.3350927
M. Goyal, S. Mittal, Review for prevention of botnet attack using various detection techniques in IoT and IIoT, in 2024 2nd International Conference on Disruptive Technologies (ICDT) (2024), pp. 259–264. https://doi.org/10.1109/ICDT61202.2024.10489168
W. Wei, J. Mendel, Maximum-likelihood classification for digital amplitude-phase modulations. IEEE Trans. Commun. 48(2), 189–193 (2000). https://doi.org/10.1109/26.823550
L. Hong, K. Ho, Classification of BPSK and QPSK signals with unknown signal level using the Bayes technique, in 2003 IEEE International Symposium on Circuits and Systems (ISCAS), vol. 4 (2003), pp. IV–IV. https://doi.org/10.1109/ISCAS.2003.1205758
P. Panagiotou, A. Anastasopoulos, A. Polydoros, Likelihood ratio tests for modulation classification, in MILCOM 2000 Proceedings. 21st Century Military Communications. Architectures and Technologies for Information Superiority (Cat. No.00CH37155), vol. 2 (2000), pp. 670–674 https://doi.org/10.1109/MILCOM.2000.904013
M. Li, X. Yin, W. Cao, M. Zhang, J. Tao, H. Zhang, Cloud platform protocol data graph structure modeling method based on spectral clustering, in, IEEE 7th Advanced Information Technology. Electronic and Automation Control Conference (IAEAC), vol. 7(2024), pp. 317–322 (2024). https://doi.org/10.1109/IAEAC59436.2024.10503987
V.D. Orlic, M.L. Dukic, Automatic modulation classification algorithm using higher-order cumulants under real-world channel conditions. IEEE Commun. Lett. 13(12), 917–919 (2009). https://doi.org/10.1109/LCOMM.2009.12.091711
B. Ramkumar, Automatic modulation classification for cognitive radios using cyclic feature detection. IEEE Circuits Syst. Mag. 9(2), 27–45 (2009). https://doi.org/10.1109/MCAS.2008.931739
P. Yang, Y. Xiao, M. Xiao, Y.L. Guan, S. Li, W. Xiang, Adaptive spatial modulation MIMO based on machine learning. IEEE J. Sel. Areas Commun. 37(9), 2117–2131 (2019). https://doi.org/10.1109/JSAC.2019.2929404
F.C.B.F. Muller, C. Cardoso, A. Klautau, A front end for discriminative learning in automatic modulation classification. IEEE Commun. Lett. 15(4), 443–445 (2011). https://doi.org/10.1109/LCOMM.2011.022411.101637
T.J. O’Shea, J. Corgan, T.C. Clancy. Convolutional radio modulation recognition networks (2016). https://doi.org/10.1007/978-3-319-44188-7_16
Y. Wang, M. Liu, J. Yang, G. Gui, Data-driven deep learning for automatic modulation recognition in cognitive radios. IEEE Trans. Veh. Technol. 68(4), 4074–4077 (2019). https://doi.org/10.1109/TVT.2019.2900460
R. Ding, F. Zhou, Q. Wu, C. Dong, Z. Han, O.A. Dobre, Data and knowledge dual-driven automatic modulation classification for 6g wireless communications. IEEE Trans. Wirel. Commun. 23(5), 4228–4242 (2024). https://doi.org/10.1109/TWC.2023.3316197
C. Lin, W. Yan, L. Zhang, W. Wang, A real-time modulation recognition system based on software-defined radio and multi-skip residual neural network. IEEE Access 8, 221235–221245 (2020). https://doi.org/10.1109/ACCESS.2020.3043588
D. Hong, Z. Zhang, X. Xu, Automatic modulation classification using recurrent neural networks, in 2017 3rd IEEE International Conference on Computer and Communications (ICCC) (2017), pp. 695–700. https://doi.org/10.1109/CompComm.2017.8322633
M. Zhang, Y. Zeng, Z. Han, Y. Gong, Automatic modulation recognition using deep learning architectures, in 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC) (2018), pp. 1–5. https://doi.org/10.1109/SPAWC.2018.8446021
A. Emam, M. Shalaby, M.A. Aboelazm, H.E.A. Bakr, H.A. Mansour, A comparative study between CNN, LSTM, and CLDNN models in the context of radio modulation classification, in 2020 12th International Conference on Electrical Engineering (ICEENG) (2020), pp. 190–195. https://doi.org/10.1109/ICEENG45378.2020.9171706
Y. Wu, X. Li, J. Fang, A deep learning approach for modulation recognition via exploiting temporal correlations, in 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC) (2018), pp. 1–5. https://doi.org/10.1109/SPAWC.2018.8445938
B. Farhang-Boroujeny, Signal Processing Techniques for Software Radios (University of Utah, 2008)
GNU Radio Website (2001). http://www.gnuradio.org
A. Xhafa, F. Fabra, J.A. López-Salcedo, G. Seco-Granados, I. Lapin, Pathway to coherent phase acquisition in multi-channel USRP SDRs for direction of arrival estimation, in 2023 Tenth International Conference on Software Defined Systems (SDS) (2023), pp. 1–8. https://doi.org/10.1109/SDS59856.2023.10329093
Y. Molina-Tenorio, A. Prieto-Guerrero, R. Aguilar-Gonzalez, Real-time implementation of multiband spectrum sensing using SDR technology. Sensors 21(10), 1–21 (2021)
H.B. Thameur, I. Dayoub, W. Hamouda, USRP RIO-based testbed for real-time blind digital modulation recognition in MIMO systems. IEEE Commun. Lett. 26(10), 2500–2504 (2022). https://doi.org/10.1109/LCOMM.2022.3191787
T.T. An, B.M. Lee, Robust automatic modulation classification in low signal to noise ratio. IEEE Access 11, 7860–7872 (2023). https://doi.org/10.1109/ACCESS.2023.3238995
F. Karim, S. Majumdar, H. Darabi, S. Chen, LSTM fully convolutional networks for time series classification. IEEE Access 6, 1662–1669 (2018). https://doi.org/10.1109/ACCESS.2017.2779939
Onnx Runtime Website (2019). https://onnxruntime.ai
T. O’Shea, N. West, Radio machine learning dataset generation with GNU radio, in Proceedings of the GNU Radio Conference, vol.1, no. (1) (2016)
M.S. John, G. Proakis, Digital Communications (McGraw-Hill Higher Education, New York, 2008)
S. Peng, H. Jiang, H. Wang, H. Alwageed, Y. Zhou, M.M. Sebdani, Y.D. Yao, Modulation classification based on signal constellation diagrams and deep learning. IEEE Trans. Neural Netw. Learn. Syst. 30(3), 718–727 (2019). https://doi.org/10.1109/TNNLS.2018.2850703
A. Ahmad, S. Agarwal, S. Darshi, S. Chakravarty, DeepDeMod: BPSK demodulation using deep learning over software-defined radio. IEEE Access 10, 115833–115848 (2022). https://doi.org/10.1109/ACCESS.2022.3219090
Acknowledgements
This research is funded by Vietnam National University HoChiMinh City (VNU-HCM) under grant number C2024-28-01.
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
These authors contributed equally to this work.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Le, Q.N., Huynh, T.Q., Ta, H.Q. et al. Modified receiver architecture in software-defined radio for real-time modulation classification. EURASIP J. Adv. Signal Process. 2024, 77 (2024). https://doi.org/10.1186/s13634-024-01176-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13634-024-01176-6