
Abstract
In this present work, a new technique for content-based image retrieval is introduced using local tetra-directional pattern. In conventional local binary pattern (LBP), each pixel of an image is changed into a specific binary pattern in accordance with their relationship with neighbouring pixels. Texture feature descriptor introduced in this work differs from local binary pattern as it exploits local intensity of pixels in four directions in the neighbourhood. Also, colour feature and gray level co-occurrence matrix have been applied in this work. Median of images have also been taken under consideration to keep the edge information preserved. The proposed technique has been validated experimentally by conducting experiments on two different sets of data, viz., Corel-1K and AT&T. Performance was measured using two well-known parameters, precision and recall, and further comparison was carried with some state-of-the-art local patterns. Comparison of results show substantial improvement in the proposed technique over existing methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 INTRODUCTION
With the fast development in technology, there is an expansive availability of online and offline images in several fields. Coping with such vast databases by human annotation requires large amount of efforts. This creates a demand for developing an effective technique in order to assist in searching for a desired image automatically from ever increasing databases. Image retrieval is an active research area in the field of image processing, which is used to retrieve images similar to a particular image, known as query, from a large dataset. The process of image retrieval can be executed in two ways: text-based image retrieval and content-based image retrieval (CBIR). In order to retrieve images using text, features like keywords, text and metadata are used. Since text-based image retrieval demands manual indexing of images, hence it becomes time exhausting. Thus, this traditional method becomes inefficient and incomplete in case of larger database. CBIR was initially introduced by Kato in 1992 [1]. CBIR extracts low-level visual features for indexing images for retrieval. These extracted features are further evaluated for similarity with the query in order to retrieve relevant images [2]. Being closer to human perception of visual data, CBIR is considered to be more advantageous than the earlier text-based retrieval techniques. Also, it performs more efficiently and at a faster rate.
Various CBIR techniques have been formulated so far. Some of these include NeTra [3], QBIC [4], SIMPLIcity [5], MetaSEEK [6], VisualSeek [7], and DRAWSEARCH [8]. A descriptive survey of several content based image retrieval techniques has been provided in [2, 9, 10]. Several low-level primitive features are used in CBIR techniques. These include color, shape, texture, spatial relationship etc. [10, 11]. Color is considered as one of the most significantly used feature descriptor. It can be treated as distribution of intensity in distinct color channels. Taking human perception into consideration, the color spaces that are much in use include RGB, LAB, HSV, and YCrCb. HSV color space is closer to human perception of color and is also invariant to illumination. Thus, it is preferable over other color spaces. Color features can be extracted using various statistical measures like color histograms, color moments, color moments, color-covariance matrix, color correlograms etc. [12, 13]. The most commonly used color feature is histogram, presented by Swain and Ballard [14]. Color histogram generates a feature vector by estimating the count of occurrence of each intensity in distinct channels. The spatial relationship among image intensities is represented by color correlogram [15]. Another feature, known as color coherence vector [16], uses the coherence and incoherence properties of image pixel color in order to create a feature vector. Motif co-occurrence matrix was further proposed in which, a 3D matrix was constructed corresponding to the local statistics of image [17].
Texture is another widely used feature for retrieval of images. Texture is well able to distinguish images from one another [18]. It varies with local intensities of image, thus providing with its surface characteristics. Various properties like coarseness, smoothness and regularity are used to identify these characteristics. Texture feature extraction is carried out extensively using the signal processing methods. These methods make use of mathematical transformations in the image, thus resulting in image features in the form of coefficients. Gabor filters [19], discrete wavelet transform [20], etc. are some of the important transforms used for extraction of texture features. Another way to extract texture feature involves model-based methods. In these methods, an assumption model for an image is initially designed. Estimation of the model parameters is carried out, which are used as texture descriptor features. One such popularly used method is Markov random field [21]. Structural analysis is another method for texture feature extraction. It is performed in the case where texture primitives consist of regular patterns and are large enough to be described and segmented on individual basis [22].
In this method, texture features are extracted using primitives and placement rules. The analysis of spatial distribution of gray levels is performed using statistical methods. Some of the widely used methods include co-occurrence matrix, Tamura feature extraction [23], Wold features [24], etc. Haralick et al. introduced the concept of gray-level co-occurrence matrix (GLCM) [25] in order to extract statistical features of an image. GLCM matrix extracts texture features by identifying spatial correlation of image pixels. In another work, Zhang et al. [26] estimated the GLCM of edge images which were formed using Prewitt edge detector in four directions, thus extracting statistical features to form co-occurrence matrices for retrieval purposes. Partio et al. used GLCM with statistical features for the retrieval of rock texture images [27].
An efficient method for the purpose of feature extraction for CBIR includes local binary pattern (LBP), introduced by Ojala et al. [28]. LBP is a fast, simple and robust texture descriptor which can capture local texture features unaffected by illumination. LBP was further modified into a uniform and rotation invariant LBP in order to limit the number of patterns. A number of LBP variants have been developed for different applications. Murala et al. [29] introduced local tetra pattern (LTrP) that retrieves images by tapping first order derivatives in both horizontal and vertical directions. Further, local ternary co-occurrence pattern was developed for retrieval of biomedical images [30]. In this pattern, co-occurrence of similar ternary edges was encoded based on gray level intensities in the pixel window. A robust center symmetric local binary co-occurrence pattern was introduced by Verma et al. [31] in which local information was attained by extracting center symmetric LBP. Later, Verma et al. [32] proposed local extrema co-occurrence pattern (LECoP). In this, local directional information was extracted for retrieval of images. Dubey et al. developed an efficient Local diagonal extrema pattern (LDEP) which described relationship among the diagonal neighbors of center pixel of the image [33]. Further, a novel texture feature, known as local tri-directional pattern (LTriDP) was proposed, which exploits the local intensities of neighborhood pixels in three directions [34]. Subsequently, Verma et al. proposed local neighborhood difference pattern (LNDP) [35], which creates a pattern by estimating differences between two immediate neighborhood pixels in horizontal or vertical directions. Recently, local neighborhood intensity pattern (LNIP) for image retrieval was introduced by Banerjee et al. [36] which is more advantageous in terms of resistance to illumination.
It is observed that there is no single optimal representation of an image for retrieval purposes. This is on account of the variant conditions in which photographs might be captured, viz. view angle, illumination changes, etc. In this paper, the authors have presented a novel pattern for the purpose of image retrieval based on color and texture. The method makes use of HSV color space for calculation of hue, saturation and intensity of the color image. Herein, the pattern establishes a relationship of the pixel under observation with its surrounding pixels by exploiting their mutual relationships based on four significant directions. A magnitude pattern is also taken into consideration using the same four directions, and both their histograms are combined to form a feature vector. The performance of the proposed method is validated using two databases. The remaining paper is organized as follows: Section 2 gives an introduction to color space, GLCM and local patterns. Framework of the proposed method, algorithm and similarity measure is explained in Section 3. Section 4 presents the experimental results and discussions. Finally, the conclusion of the work is achieved in Section 5.
2 COLOR AND TEXTURE DESCRIPTORS
Color Space
Broadly, images are classified into three categories–binary, gray scale and color image. Binary images comprise of only two intensity levels, viz. black and white. Gray scale images consist of a set of gray tone intensity measures in one band, whereas, color images compose of multiple bands, each band comprising of a range of intensities. The most commonly used color space is RGB color space. In this, the images consist of three bands labelled as red, green, and blue. Another color space that is in wide use is HSV, which has three constituents known as hue, saturation and value.
Hue component is related to color, by referring to which pure color it belongs to. It is defined as an angle and ranges from 0° to 360°, with each degree occupying different colors. Saturation describes the level of brightness and lightness of color component. Its value ranges between 0 and 1, with the color intensity increasing simultaneously with saturation value. The last component, i.e., value defines the intensity of the color that can be extracted from the color information obtained from the image. The range of value component varies from 0 to 1, where 0 refers to completely dark and 1 to completely bright intensity level. HSV color space is mostly preferred by researchers because of its close proximity to human perception of color and invariance [37]. In this present work, images have been transformed from RGB to HSV color space for feature extraction.
Gray Level Co-occurrence Matrix
One of the popular statistical approaches for extraction of image features include gray level co-occurrence matrix (GLCM) [25]. The matrix relates to the spatial arrangement of co-occurring gray valued pairs of pixels located at a certain distance in a particular direction. The matrix elements consist of the number of times a pixel pair occurs, and its size depends upon the maximum intensity value available in the image.
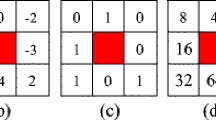
An illustration of GLCM computation is shown in Fig. 1. Figure 1a shows an original matrix and its calculated GLCM is depicted in Fig. 1b. First row and first column of the GLCM matrix indicate pixel values that are present in the original matrix. Co-occurrence for each pair of intensity values, for example, (0, 0), (0, 1), …, (3, 3) is calculated. As indicated in Fig. 1a, pair (3, 0) indicating occurrence of value “3” with “0” at a distance of one in horizontal direction occurs twice. Thus, 2 is entered in GLCM matrix at position (3, 0). Rest of the elements are computed in the similar ways in order to create the matrix.

Example of gray level co-occurrence matrix: (a) original matrix, (b) GLCM matrix.
Local Binary Patterns
Local binary pattern (LBP), proposed by Ojala et al. [28], draws out local information from an image by using neighbourhood pixel block, while considering center pixel intensity as the threshold value. The neighborhood pixels are compared to the center pixel. If the neighborhood pixel intensity is greater than that of the center pixel, the value is set to binary one, else zero. The resulting zeros and ones are then put together to create a binary number in order to generate an LBP code for the center pixel. Mathematically, the LBP operator for p surrounding pixels and radius r can be expressed as:
Here, Ii and Ic refer to the intensity values of the neighbourhood and the center pixel, respectively. The LBP map so created is thereafter converted into histogram with the help of following equations:
where M × N define the image size. An example of LBP is illustrated in Fig. 2.

Example of basic LBP.
Local Tetra-Directional Pattern
Local tetra-directional pattern is a variant of LBP. Instead of taking uniform relationship with all neighborhood pixels into consideration, LTrDP considers relationship based on different directions. Each center pixel consists of neighboring pixels in a certain radius. Closest neighbor consists of 8 pixels distributed all around the center pixel. Since closest neighbouring pixels are less in count and results in more related information, hence we consider 8-neighborhood pixels for pattern creation. Each neighborhood pixel is considered, one at a time, and compared with four most adjacent pixels. These four pixels are located at 0°, 45°, 90°, and 135°. An example for creating LTrDP is illustrated in Fig. 3 and explained as follows.

An illustrated example for local tera-directional pattern.
Consider a center pixel Ic. The window chosen consists of closest 8 neighborhood pixels. Firstly, we compute the difference between the neighborhood pixel and its four adjacent neighbouring pixels in four directions, viz., 0°, 45°, 90°, and 135°. Thus, for each neighborhood pixel, we have
where (i, j) denote the location of the neighborhood pixel in question. We thus have four differences, D1, D2, D3, and D4 for each neighborhood pixel. Further, a pattern is configured based on all the four differences.
where \(\# ({{D}_{k}} < 0)\) represents total count of \({{D}_{k}}\) with negative values, for all k = 1, 2, 3, 4. \(\# ({{D}_{k}} < 0)\) results in values ranging from 0 to 4. In order to calculate value of each pattern, a mod of \(\# ({{D}_{k}} < 0)\) is calculated with 4. The values are calculated according to \(\# ({{D}_{k}} < 0)\), e.g., if all \({{D}_{k}}\) are negative for k = 1, 2, 3, 4, then \(\# ({{D}_{k}} < 0)\) is 4 and \(\# \left( {{{D}_{k}} < 0} \right)\bmod 4\) results in zero. In this manner, \(\# \left( {{{D}_{k}} < 0} \right)\bmod 4\) is assigned values 0, 1, 2, and 3. For every neighborhood pixel i = 1, 2, 3, …, 8, pattern values \({{f}_{i}}\left( {{{D}_{1}},{{D}_{2}},{{D}_{3}},{{D}_{4}}} \right)\) is computed resulting in tetra-directional pattern
In this manner, we achieve a quaternary pattern for each center pixel, which are further converted into three binary patterns
These three patterns so obtained are further converted into pattern map using the following equation:
After attaining the pattern map, feature is extracted by computing histograms for all three binary patterns using Eqs. (3) and (4).
The tetra-directional pattern extracts most of the local information around the center pixel, but it has been observed that magnitude pattern can also be helpful in creating more illustrative feature vector [29]. Thus, we exploit magnitude information in order to create a magnitude pattern. It makes use of the magnitude values of each pixel present in the window and its neighborhood pixels in four directions, viz., 0°, 45°, 90°, and 135°. Magnitude pattern is created as follows:
where i = 0, 1, 2, …, 8 denotes each pixel located at location (a, b) in the window, with M0 referring to the value calculated for the center pixel. Binary value is further assigned to each neighborhood pixel based on comparison as shown:
Further, the histogram for this magnitude pattern is obtained using Eqs. (3), (4). All the four histograms obtained are then concatenated and a joint histogram is obtained as the final feature vector
Figure 3 illustrates the creation of LTrDP with the help of an example. Figure 3a describes the window chosen for creating the pattern. The center pixel is described by Ic and the neighborhood pixels are described by the shaded region, denoted from I1 to I8. An example window is taken in Fig. 3b. Magnitude term M0 for the center pixel is calculated in Fig. 3c using Eq. (15). In Fig. 3d, pixel I1 is compared with its neighborhood pixels located at 0°, 45°, 90°, and 135°, i.e., I9, I10, I2, and I3, respectively and “0” and “1” is assigned for all four comparisons. Since I1 > I9, I1 = I10, I1 < I2 and I1 > I3, hence the pattern for I1 is 1001. Thus, according to Eq. (6), the pattern value for I1 is 2. Further, magnitude value M1 for the pixel is calculated using Eq. (15) and compared with that of the center pixel. Since M1 < M0, hence, “0” pattern value is assigned for this. In the similar manner, pattern values for rest of the neighborhood pixels is calculated from Figs. 3e–3k, and one quaternary pattern and one magnitude pattern is formed. The quaternary pattern is further divided into three patterns based on Eqs. (8)–(13). All the four binary patterns are further converted into histograms and are concatenated together to result in a feature vector.
3 PROPOSED SYSTEM FRAMEWORK
Figure 4 presents the flowchart of the proposed method. The algorithm for the same is also explained further. The algorithm is outlined in two parts. First division of the algorithm explains the steps for construction of feature vector for the image database. The second division describes the retrieval process for the system.

Proposed system framework.
Algorithm
Part 1. Feature vector formation.
Input: image; output: feature vector.
1. Upload the image and transform it from RGB into HSV color space.
2. Quantize the hue (H) and saturation (S) components into 72 and 20 bins, respectively. Create the histograms for both.
3. Calculate the local median values for every pixel of the value (V) component.
4. Apply the proposed pattern on the median image obtained in step 3.
5. Construct GLCM of the pattern map obtained in step 4 and change it into vector form.
6. Combine the value of the center pixel, histograms from step 2 and GLCM vector obtained from step 5 in order to achieve the final histogram as the feature vector.
Part 2. Image retrieval.
Input: query image; output: retrieved similar images.
1. Enter the query image.
2. Construct its feature vector in the manner depicted in Section 1.
3. Calculate the similarity distance measure, and hence the similarity indices, in order to compare the feature vector of the query image with that of each image available in the database.
4. Sort the similarity indices and extract images corresponding to least similarity indices as the best match vectors as final results.
Similarity Measure
Similarity measure is considered as a significant element of content-based image retrieval systems. The function of similarity measurement is to compute the level of similarity between the query image and the images from the database. Similarity measure computes the amount of differences between the query image and other images using a distance metric. The proposed method makes use of d1 distance measure since it gives the best results for similarity matching [29, 31, 32, 38].
For a query image Q, its extracted feature vector can be represented as \({{f}_{Q}} = \left( {{{f}_{{{{Q}_{1}}}}},{{f}_{{{{Q}_{2}}}}}, \ldots ,{{f}_{{{{Q}_{L}}}}}} \right)\), where L is defined as the length of the feature vector. In a similar manner, each image from the given database |DB| can be represented by its feature vector as \({{f}_{{{\text{D}}{{{\text{B}}}_{j}}}}}\) = \(\left( {{{f}_{{{\text{D}}{{{\text{B}}}_{{j1}}}}}},{{f}_{{{\text{D}}{{{\text{B}}}_{{j2}}}}}}, \ldots ,{{f}_{{{\text{D}}{{{\text{B}}}_{{jL}}}}}}} \right)\), j = 1, 2, …, |DB|. The distance measure d1 can be calculated using the following formula:
where \({{f}_{{{\text{D}}{{{\text{B}}}_{{ji}}}}}}\) refers to the ith feature of the jth image from the database |DB|.
4 EXPERIMENTAL RESULTS AND ANALYSIS
To affirm the quality of the proposed method, it has been examined on two benchmark databases. The performance is graded on the basis of two measures, viz., precision and recall [39]. These parameters are computed based on the count of relevant images that are retrieved from the given database. Relevant images are those images that belong to the category similar to that of the query image. The remaining images are regarded as non-relevant. Precision and recall are effective evaluation parameters for CBIR. High values of precision and recall suggest better results. Precision is described as the ratio of total count of relevant images retrieved to the total number of images retrieved from the database. Recall is defined as the ratio of the total count of relevant images to the total number of images that are present in the database.
Given a query image Q, total number of images being retrieved be n, precision and recall values can be calculated from the following equations:
where \({{N}_{{qc}}}\) defines the total count of relevant images available in the dataset which is defined by the number of images present in each category of the database. For each category, we can calculate average precision and recall using the following equations:
where b refers to the category number in the database. Further, we compute total precision and total recall for the whole dataset using the following two equations:
where Nc denotes the total number of categories that exist in the dataset. Total recall is also referred to as average recall rate (ARR). The performance of the proposed method is validated by comparing it with recent methods listed in Table 1. In each experiment, retrieval is performed taking into consideration every image from the database as the query image. Specific number of images is retrieved for every query image. Precision and recall are computed and final results are then analyzed. The results evaluated on two datasets are explained below.
Database-1 (Corel-1K)
The first database considered for experimentation is Corel-1K [40]. This dataset comprises of 1000 natural images that are divided into ten distinct categories, viz., Africans, Beaches, Buildings, Buses, Dinosaurs, Elephants, Flowers, Horses, Mountains, and Food. Each category comprises of 100 images in it. Each image is either of size 256 × 384 or 384 × 256. Some of the images form the dataset are shown in Fig. 5.

Sample images from Corel-1K dataset.
For this database, 10 images were retrieved initially and the count is increased by 10 in every experiment. Maximum of 100 images were retrieved and henceforth, results were analyzed. The experimentation was carried out on each image of the dataset. Figure 6 shows one query image from each category along with some of its retrieved images. From the retrieval results, it was observed that similar images have been retrieved for each category. Precision and recall values for every experiment were calculated and analyzed. Average precision and recall percentage for different number of retrieved images have been described in Tables 2 and 3, respectively. Average precision rate decreases whereas average recall rate increases with the increase in the number of images that are to be retrieved. It can be observed from the table that the proposed method is more benevolent than the other existing methods in terms of both precision and recall. Figures 7a, 7b depict the graphical results for precision and recall for Corel-1K database. It can be observed that the proposed method outperforms the other methods. For retrieval of 10 images, the average retrieval rate for the proposed method is improved by 0.805% in case of LeCoP, 7.92% for LNIP, 12.13% for Tri-Directional Pattern, and 16.20% in case of LNDP. While retrieving 100 images, the proposed method shows an improvement of 10.48% for LeCoP, 16.90% for LNIP, 21.21% for Tri-Directional Pattern, and 19.31% in case of LNDP. Thus, it can be seen that the proposed method performs well for retrieving natural images from a huge database.

Query image and retrieved images from Corel-1K dataset.

(a) Precision (%) and (b) recall (%) for Corel-1K dataset.
Database-2 (AT&T)
Another experimentation for CBIR is carried out using AT&T face database [41]. The database comprises of 400 facial images of size 92 × 112. These 400 images are further divided into 40 categories with each category consisting of ten images. Figure 8 shows a few sample images from the AT&T dataset.

Sample images for AT&T.
In this experiment, initially, a single image was retrieved and the count of retrieval was increased by 1. Ten images were retrieved maximum for each category and results obtained were analysed. The experiment was carried out for every image present in the database. Some of the query images and their corresponding retrieved images are represented in Fig. 9. Precision and recall values were evaluated for each experiment. Tables 4 and 5 depict the average precision and recall percentage for different number of retrieved images for all the techniques. From the results, it was observed that the proposed method results in the better precision and retrieval rates in comparison to other methods. Graphs for precision and recall are shown in Figs. 10a, 10b. From the graphs, the performance of the proposed method can be compared with the other existing methods. For each method, the results show 100% in the case of retrieving only one image, thus indicating that every query image is retrieved successfully for each of the methods. Further, when 2 images are being retrieved, the proposed method shows an improvement in the average retrieval rate by 23.437% for LeCoP, 8.715% for LNIP, 4.558% for Tri-directional method, and 0.99% in case of retrieval by LNDP. While retrieving 10 images, the proposed method is improved by 39.634% in case of LeCoP and 10.96% for LNIP pattern. In case of Tri-directional pattern, the proposed method shows an improvement by 6.45% and for LNDP, it shows an improvement of 1.048%. This indicates the method is good for detection and identification of faces in comparison to the existing methods.

Query image and retrieved images from AT&T dataset.

(a) Precision (%) and (b) recall (%) for AT&T dataset.
Feature Vector Length
Table 4 calculates and describes the feature vector lengths for every method. It can be seen that the proposed method has the highest feature vector length out of all the methods. Further, the computational time for each method depends on its corresponding feature vector length. Higher length of feature vector corresponds to higher amount of time taken for retrieving a single image. Hence, compared to other existing methods, the proposed method results in highest computational time on account of highest feature vector length.
5 CONCLUSIONS
In the present paper, a new feature descriptor, known as local tetra-directional pattern, is proposed for CBIR. The descriptor combines the properties of basic LBP and its directional measures to create a pattern. It is further combined with color features and co-occurrence matrix in order to create the final feature vector for retrieval process.
The execution of the proposed method has been compared with the existing methods, viz., LeCOP, tri-driectional, LNDP, and LNIP and has been detailed below.
1. The average precision/average recall have significantly improved from 42.913, 39.116, 39.736, and 40.557–47.412% when compared with LeCOP, Tri-Directional, LNDP, and LNIP, respectively on Database 1.
2. The average precision/average recall have significantly improved from 32.8, 43.025, 45.325, and 41.275–45.8% when compared with LeCOP, tri-directional, LNDP, and LNIP, respectively on Database 2.
3. From the above analysis, it can be concluded that the proposed method is able to retrieve coloured natural images in a better way than the rest of the methods. Also, the method is good for retrieving faces irrespective of change in emotions or angles.
In this paper, directional patterns have been taken into consideration and weightage has also been given to the center pixel. Median has also been taken into account because of its robustness and preservation of edges. The proposed method can be used in various applications like face detection, fingerprint recognition, etc.
REFERENCES
T. Kato, “Database architecture for content-based image retrieval,” in Image Storage and Retrieval Systems (SPIE, San Jose, 1992).
R. Datta, D. Joshi, J. Li, and J. Z. Wang, “Image retrieval: Ideas, influences, and trends of the new age,” ACM Comput. Surv. 40 (2), 5:1–5:60 (2008).
B. S. Manjunath and W. Y. Ma, “Netra: A toolbox for navigating large image databases,” Multimedia Syst. 7 (3), 184–198 (1999).
C. W. Niblack, R. Barber, W. Equitz, M. D. Flickner, E. H. Glasman, D. Petkovic, P. Yanker, C. Faloutsos, and G. Taubin, “QBIC project: Querying images by content, using color, texture, and shape,” in Storage and Retrieval for Image and Video Databases, SPIE (San Jose, 1993).
J. Z. Wang, J. Li, and G. Wiederhold, “SIMPLIcity: Semantics-sensitive integrated matching for picture libraries,” IEEE Trans. Pattern Anal. Mach. Intell. 23 (9), 947–963 (2001).
M. Beigi, A. B. Benitez, and S. F. Chang, “MetaSEEK: A content-based metasearch engine for images,” in Storage and Retrieval for Image and Video Databases VI (SPIE, San Jose, 1997).
J. R. Smith and S. F. Chang, “Querying by color regions using the VisualSEEk content-based visual query system,” Intell. Multimedia Inf. Retr. 7 (3), 23–41 (1997).
E. D. Sciascio and M. Mongiello, “DrawSearch: A tool for interactive content-based image retrieval over the Internet,” in Storage and Retrieval for Image and Video Databases VII (SPIE, San Jose, 1998).
P. Aigrain, H. Zhang, and D. Petkovic, “Content-based representation and retrieval of visual media: A state-of-the-art review,” Multimedia Tools Appl. 3 (3), 179–202 (1996).
Y. Liu, D. Zhang, G. Lu, and W. Y. Ma, “A survey of content-based image retrieval with high-level semantics,” Pattern Recognit. 40 (1), 262–282 (2007).
B. S. Manjunath, J. R. Ohm, V. V. Vasudevan, and A. Yamada, “Color and texture descriptors,” IEEE Trans. Circuits Syst. Video Technol. 11 (6), 703–715 (2001).
G. Pass and R. Zabih, “Comparing images using joint histograms,” J. Multimedia Syst. 7 (3), 234–240 (1999).
G. Pass and R. Zabih, “Histogram refinement for content-based image retrieval,” in Proceedings Third IEEE Workshop on Applications of Computer Vision (Sarasota, 1996).
M. J. Swain and D. H. Ballard, “Color indexing,” Int. J. Comput. Vision 7 (1), 11–32 (1991).
J. Huang, S. R. Kumar, M. Mitra, W. J. Zhu, and R. Zabih, “Image indexing using color correlograms,” in Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (San Juan, 1997).
G. Pass, R. Zabih, and J. Miller, “Comparing images using color coherence vectors,” in Proceedings of the Fourth ACM International Conference on Multimedia (Boston, 1997).
N. Jhanwar, S. Chaudhuri, G. S. Seetharaman, and B. Zavidovique, “Content based image retrieval using motif cooccurrence matrix,” Image Vision Comput. 22 (14), 1211–1220 (2004).
Z. He, X. You, and Y. Yuan, “Texture image retrieval based on non-tensor product wavelet filter banks,” Signal Process. 89 (8), 1501–1510 (2009).
A. Ahmadian and A. Mostafa, “An efficient texture classification algorithm using Gabor wavelet,” in 25th Annual International Conference of Engineering in Medicine and Biology Society (Cancun, 2003).
H. Farsi and S. Mohamadzadeh, “Colour and texture feature-based image retrieval by using Hadamard matrix in discrete wavelet transform,” IET Image Process. 7 (3), 212–218 (2013).
L. Ainhoa, R. Manmatha, and S. Rüger, “Image retrieval using markov random fields and global image features,” in ACM International Conference on Image and Video Retrieval (New York, 2010).
R. Jain, R. Kasturi, and B. G. Schunck, Texture, in Machine Vision (McGraw-Hill, New York, 1995), pp. 234–248.
H. Tamura, S. Mori, and T. Yamawaki, “Textural features corresponding to visual perception,” IEEE Trans. Syst. Man Cybern. 8 (6), 460–473 (1978).
F. Liu and R. W. Picard, “Periodicity, directionality, and randomness: Wold features for image modeling and retrieval,” IEEE Trans. Pattern Anal. Mach. Intell. 18 (7), 722–733 (1996).
R. M. Haralick, K. Shanmugam, and I. Dinstein, “Textural features for image classification,” IEEE Trans. Syst. Man. Cybern. 6, 610–621 (1973).
J. Zhang, G.-l. Li, and S.-W. He, “Texture-based image retrieval by edge detection matching GLCM,” in 2008 10th IEEE International Conference on High Performance Computing and Communications (Dalian, 2008).
M. Partio, B. Cramariuc, M. Gabbouj, and A. Visa, “Rock texture retrieval using gray level co-occurrence matrix,” in Proc. of 5th Nordic Signal Processing Symposium (2002).
T. Ojala, M. Pieti, and T. Maenpaa, “Multiresolution gray-scale and rotation invariant texture classification with local binary patterns,” IEEE Trans. Pattern Anal. Mach. Intell. 24 (7), 971–987 (2002).
M. Subrahmanyam, R. P. Maheshwari, and R. Balasubramanian, “Local tetra patterns: A new feature descriptor for content-based image retrieval,” IEEE Trans. Image Process. 21 (5), 2874–2886 (2012).
M. Subrahmanyam and Q. J. Wu, “Local ternary co-occurrence patterns: A new feature descriptor for MRI and CT image retrieval,” Neurocomputing 119, 399–412 (2013).
M. Verma and B. Raman, “Center symmetric local binary co-occurrence pattern for texture, face and bio-medical image retrieval,” J. Visual Commun. Image Representation 32, 224–236 (2015).
M. Verma, B. Raman, and S. Murala, “Local extrema co-occurrence pattern for color and texture image retrieval,” Neurocomputing 165, 255–269 (2015).
S. R. Dubey, S. K. Singh, and R. K. Singh, “Local diagonal extrema pattern: A new and efficient feature descriptor for CT image retrieval,” IEEE Signal Process. Lett. 22 (9), 1215–1219 (2015).
M. Verma and B. Raman, “Local tri-directional patterns: A new texture feature descriptor for image retrieval,” Digital Signal Process. 51, 62–72 (2016).
M. Verma and B. Raman, “Local neighborhood difference pattern: A new feature descriptor for natural and texture image retrieval,” Multimedia Tools Appl. 77 (10), 11843–11866 (2018).
P. Banerjee, A. K. Bhunia, A. Bhattacharyya, P. P. Roy, and S. Murala, “Local neighborhood intensity pattern—a new texture feature descriptor for image retrieval,” Expert Syst. Appl. 113, 100–115 (2018).
A. Vadivel, S. Sural, and A. K. Majumdar, “An integrated color and intensity co-occurrence matrix,” Pattern Recognit. Lett. 28 (8), 974–983 (2007).
S. Murala, R. P. Maheshwari, and R. Balasubramanian, “Directional local extrema patterns: A new descriptor for content based image retrieval,” Int. J. Multimedia Inf. Retr. 1 (3), 191–203 (2012).
H. Müller, W. Müller, D. M. Squire, S. Marchand-Maillet, and T. Pun, “Performance evaluation in content-based image retrieval: Overview and proposals,” Pattern Recognit. Lett. 22 (5), 593–601 (2001).
The Corel-1K Database. http://wang.ist.psu.edu/docs/related/
The AT&T Database of Faces (2002). http://www.uk.research.att.com/facedatabase.html
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
The authors declare no conflict of interest neither in financial nor in any other area.
Additional information

Anterpreet Kaur Bedi was born in Pathankot, Punjab, on July 7, 1992. She received B.E. degree and M.E. degree (Gold Medalist) in Electronics from Department of Electronics and Communication Engineering, Dr. B. R. Ambedkar National Institute of Technology, Jalandhar, India in 2014 and 2017, respectively. Currently, she is pursuing her Ph.D. degree in Electronics and Communication Engineering Department, Dr. B. R. Ambedkar National Institute of Technology, Jalandhar, Punjab, India. Her major fields of interest are content-based image retrieval and biomedical imaging.

Ramesh Kumar Sunkaria was born in Kot Khalsa, (Amritsar), on February 20, 1967. He received B.Tech. degree in Electronics Engg. from Department of Electronics Technology, Guru Nanak Dev University Amritsar, and M.Tech. (Hons.) Degree in Electronics Engg. from Guru Nanak Dev Engineering College, Ludhiana (Punjab Technical University, Jalandhar) in 1990 and 2004, respectively. He did his Ph.D. degree from Electrical Engineering Department, Indian Institute of Technology Roorkee, Roorkee in June 2010.
He worked as Engineer in Bharat Heavy Electricals Limited, Haridwar upto June 2004. Thereafter he joined Indian Broadcasting (Engineers) Service, Govt. of India and worked as Assistant Director (Engineering) until August 1996. He directed the installation of numerous radio and TV projects all-over India, namely, VLPT Joginder Nagar, VLPT Ahjufort, VLPT Kalakot etc. Afterwards he joined academics and at present he is Associate Professor in Department of Electronics & Communication Engineering, Dr. B. R. Ambedkar National Institute of Technology, where he has been teaching UG/PG courses related to signal processing and communication engineering. Presently, he is also serving as Head in the Department of Electronics and Communication Engineering in the institute. His current research interests are in bio-electric signal and image processing, filter banks and non-linear heart variability studies. He has 57 publications in reputed international journals and 45 publications in conference proceedings. At present, seven PhD thesis have been guided and six PhD thesis are in progress under his guidance, 34 M.Tech thesis have already been completed and more than 44 B.Tech projects have been completed. Also, there are two ongoing projects under his supervision, funded by DST SERB and AICTE. He is member of IEEE Engineering in Medicine and Biology Society and IEEE Computer society.
Rights and permissions
About this article

Cite this article
Bedi, A.K., Sunkaria, R.K. Local Tetra-Directional Pattern–A New Texture Descriptor for Content-Based Image Retrieval. Pattern Recognit. Image Anal. 30, 578–592 (2020). https://doi.org/10.1134/S1054661820040057
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1134/S1054661820040057