
Abstract
Based on the three-parametric Lorenz curve proposed by Kakwani (1980), this paper builds a multiple linear regression model to estimate the parameters by the weighted least square method named the regression method. Using the Lorenz curve, the Gini index and its variance are then calculated. Compared to the error minimization technique, the regression method has a better performance in estimating the Gini index using Kakwani (1980)’s Lorenz curve and a dataset of sixteen economies from the United Nation University-World Income Inequality Database (UNU-WIID). The results also suggest that the regression method has an advantage when estimating the Gini index and fitting the income shares by decile for the medium and higher inequality economies. We find that the three-parametric Lorenz curve has a better performance than the double-parametric Lorenz curve, and the double-parametric Lorenz curve is superior to the single-parametric Lorenz curve, judged by the RMSE of the actual Gini index and the estimated ones.
Similar content being viewed by others
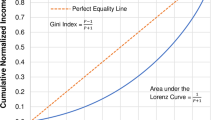
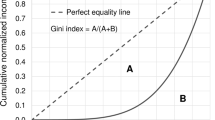

Introduction
Recently, periodic reports of certain summary statistics on income or wealth distribution have become quite common (Sitthiyot and Holasut, 2021). International Labor Organization’s ILOSTAT, United Nations Development Programme’s Human Development Report (UNDP-HDR), the United Nations University-World Income Inequality Database (UNU-WIID), the World Bank’s Poverty and Inequality Platform (PIP), and the World Income Database (WID) are the largest cross-country databases that provide grouped data. By using the grouped data on income or wealth, Gini index could be estimated (1) by assuming a statistic distribution of income, such as lognormal, Beta-II, Generalized Pareto, or mixture distribution (McDonald, 1984; Chotikapanich et al., 1997, 2007; Blanchet et al., 2022) and (2) by specifying a parametric function form for Lorenz curve (Paul and Shanker, 2020; Sitthiyot and Holasut, 2021).
Fitting Lorenz curve is more convenient than fitting income distribution because the cumulative population share and the corresponding cumulative income share form the points of the Lorenz curve. Numerous studies have suggested a variety of parametric functional forms to estimate directly the Lorenz curve. There are single-parametric Lorenz curve (Kakwani and Podder, 1973; Aggarwal, 1984; Chotikapanich, 1993; Paul and Shankar, 2020), double-parametric Lorenz curve (Rasche et al., 1980; Ortega et al., 1991; Sitthiyot and Holasut, 2021), three-parametric Lorenz curve (Kakwani, 1980; Sarabia et al., 1999). Chotikapanich and Griffiths (2002) have suggested estimating parameter(s) of the Lorenz curve using the Maximum Likelihood (ML) method assuming that each income share is subject to the joint Dirichlet distribution, while Jorda et al., (2021) have proposed estimating parameter(s) of the Lorenz curve utilizing the error minimization technique. Sitthiyot and Holasut (2021) introduce a simple and straightforward method for estimating the Lorenz curve using three indicators, namely, the Gini index, the income share of the bottom, and that of the top, which is associated with a specific functional form based on the weighted average of the exponential function and the functional form implied by Pareto distribution.
This study proposes a new approach named the regression method for estimating the Gini index by decile based on a specified functional form suggested by Kakwani (1980). The new approach builds a linear regression model to estimate three parameters, and can get better estimates of Gini index compared to the ML method and the error minimization technique for the same Lorenz curve. The new approach can easily obtain an estimation of the Lorenz curve and corresponding Gini index, and get an estimation of the variance of the Gini index utilizing popular computer programs such as EVIEWS and STATA. In addition to, the new approach allows negative income or wealth share values, which are not allowed in the Beta-II density functionFootnote 1 of Chotikapanich et al. (2007) and the Gamma functionFootnote 2 in the maximum likelihood of Chotikapanich and Griffiths (2002).
We demonstrate how to estimate the Gini index by using the new approach based on a dataset of the income shares of sixteen economies, which differ in the level of income inequality, economic, sociological, and regional backgrounds. We also compare the performance of our new method to that of the methods suggested by Sitthiyot and Holasut, 2021 and Sarabia et al. (1999), which aim to estimate the Gini index and fit the income shares by using the error minimization technique and decile data.
Methods
Kakwani (1980) suggests a functional form for fitting the Lorenz curve as follows:
where, x is the cumulative population share, 0 ≤ x ≤ 1. When fitting function of the Lorenz curve, the functional form in model (1) is more consistent with the actual data (Cheong, 2002; Tanak et al., 2018; Sitthiyot and Holasut, 2021).
The advantage of the function L(x) is that it is applicable to negative income or wealth share. This can deal with the Sarabia et al. (1999)’s criticism that Eq.⑴ violates L′ (0+) ≥ 0. Actually, the wealth share of the poorest 10% is often negative in many economies; in this case, we only request that the function L(x) meets the conditions: L(x) ≥ 0, L′(x) ≥ 0 and L″(x) ≥ 0 in the right-handed area within the interval [0,1].
The derivation process of its second-order derivative is as follows:
Let f(x) = xp(1-x)q namely L(x) = x-f(x), so that
Then
Let \(g(x)=(p+q)(p+q-1){x}^{2}-2p(p+q-1)x+{p}^{2}-p\). We can obtain the discriminant of the root nature of \(g(x)\) as follows
When p + q ≤ 1, p > 0, q > 0, then \(\varDelta \,<\, 0\), indicating g(x) ≤ 0, which means f″(x) ≤ 0,so that L″(x) ≥ 0 (a > 0). That is, the curve is convex.When p + q > 1, p > 0, q > 0, then \(\varDelta \,>\, 0\), thus we can obtain two roots of g(x), x1 and x2 as follows
So that
⑴ when p + q ≤ 1, p > 0, q > 0, we have L″(x) ≥ 0, x \(\in\) [0,1].
⑵ when p + q > 1, 0 < p ≤ 1, 0 < q ≤ 1, we have L″(x) ≥ 0, x \(\in\) [0,1].
⑶ when p > 1, 0 < q ≤ 1, we have x1 < 1, x2 > 1, we have L″(x) ≥ 0, x \(\in\) [x1,1].
Furthermore, L′(x) = 1-af′(x), when \(x\to {1}^{-}\), we have L′(x) > 0, because
It means L(x) is convex, increasing in the right-handed area within the interval [0, 1].
When analyzing the condition L″(x) ≥ 0, we find that under p + q > 1, the condition p > 0 must hold. So Eq. (1) can be expressed as follow:
Then, the L(x) satisfies with L(x) ≥ 0, L′(x) ≥ 0 and L″(x) ≥ 0 in the right-handed area within the interval [0,1]. For example, in Fig. 1, the Lorenz curve passes through the point (0.53, −0.0021), which is formed from fitting the generalized Pareto curves for the United States (Blanchet et al., 2022). Although model (2) cannot meet the properties of the classic Lorenz curve, i.e. L(x) ≥ 0, L′(x) ≥ 0, and L″(x) ≥ 0 in the interval [0, 1], we would like to call model (2) a Lorenz curve, more precisely, a fitting function of a Lorenz curve.

https://wid.world/gpinter/ (file2).
Then rearranging Eq. ⑴ and taking the natural logarithm, we can get the following equation:
where y = L(x), ε is an error term with zero mean value.
Let β0 = log (a), the model (3) can be expressed as the following matrix form:
we can obtain the parameters estimates of the model using the least square method:
where Var(ε) = σ2. Therefore, we estimate not only the parameters of the Lorenz curve, but also the covariance matrix of the parameters. Using the estimated parameters, we calculate the Gini coefficient and its variance according to the following formulas:
According to Kakwani and Podder (1976), we can obtain the following partial derivatives:
Because both x and y are increasing, this can lead to heteroscedasticity of ε. To avoid the problem, we can exploit the weighted least square method to estimate the parameters of Eq.⑶ using 1/xi (i = 1, 2,…, n) as the weights:
where Λ = diag(1/x1,1/x2,…,1/xn), Var(εε′) = \(\Lambda^{-1}\sigma^{2}\) .
The total income or wealth is usually greater than 0, and the average income or wealth is also required to be greater than 0. The income Gini coefficient is equal to the Gini mean difference divided by the mean income, the Gini mean difference is non-negative, so the Gini coefficient is always non-negative.
The UNU-WIID database has data on the income shares by decile and the Gini index for the economies in the world. These economies differ significantly in the degree of income inequality according to the UNU-WIID database. For example, Belgium (BEL), Czechia (CZE), Slovakia (SVK), and Iceland (ISL) have a lower Gini index ranging from 0.2 to 0.3; while Panama (PAN), Brazil (BRA), South Africa (ZAF), and Hong Kong (HKG) have higher Gini indices greater than 0.5. We classify the economies in the UNU-WIID database into four groups according to these economies’ Gini index. The economies in the first group has a Gini index less than 0.3, the economies in the second group with a Gini index ranging from 0.3 to 0.4, the economies in the third group with a Gini index ranging from 0.4 to 0.5, and the economies in the last group with a Gini index greater than 0.5.
To demonstrate the regression method for estimating Gini index by decile, we choose sixteen economies (see Table 1) from the above four groups and utilize the data on the income shares of these sixteen economies during the period of 2016 to 2020.
As suggested by Dagum (1977), a good parametric functional form for the Lorenz curve should be able to characterize income distributions of different countries, regions, socioeconomic groups in different periods. We can use some goodness-of-fit statistics, such as coefficient of determination (R2), mean square error (MSE), and mean absolute error (MAE), to gauge how close the estimated income shares are to the actual observations (Chotikapanich, 1993; Cheong, 2002; Tanak et al., 2018; Paul and Shankar, 2020; Sitthiyot and Holasut, 2021).
Fitting Lorenz curves using income shares by decile, we can estimate parameter(s) of the Lorenz curve based on the curve fitting technique and the method of minimizing the sum of squared errors:
From the view of fitting the Lorenz curve, though the goodness-of-fit of our regression method in most cases is smaller than that of the minimization technique of Eq.⑸, it has better performance in estimating Gini index. We introduce the root mean squared error (RMSE) in Eq. (6) to measure the difference between the estimated and the actual Gini indices.
Results and discussion
Table 1 reports the estimated parameters a, p and q for the Lorenz curve of Eq.⑵ for the sixteen economies using the error minimization technique and the regression method. We can substitute the estimated values of parameters a, p, and q into Eq. (4) to obtain the estimated Gini index. The ΔG1 and ΔG2 in Table 1 are the differences between the estimated and the actual Gini indices based on the two estimation methods, respectively. It can be seen that mostly the ΔG2 is smaller than the ΔG1 for the sixteen economies, indicating a better performance of the regression method. Furthermore, we can see that the regression method has a lower RMSE compared to the minimization technique for the full sample estimation. This conclusion also holds for the estimations for the medium, higher, and high groups. This also conveys that the regression method is superior to the minimization technique. We also note that in some cases the estimated value of parameter p is greater than one under both methods, this provides the justification of our adjustment of the range of parameter p in Eq. (2). Table 1 also gives the standard deviation of the estimated Gini index employing the regression method.
Comparison of goodness-of-fit by two methods
We then use the fitted Lorenz curves to calculate the values of the (cumulative) income shares by decile for the sixteen economies under the two methods, and compare the estimated income shares with the observed income shares. Table 2 reports the values of goodness-of-fit statistics, i.e., information inaccuracy measure (IIM), R2, MSE, MAE, and maximum absolute error (MAS). All the values of goodness-of-fit measures suggest that there is no significant difference between the estimated (cumulative) income shares and the observed income shares for each economy. We find that the MSE of the fitted Lorenz curve by the error minimization technique is less than the MSE by the regression method for all the sampled economies. In most cases, this conclusion holds in terms of the statistics MAS, MAE, and IIM. Therefore, the error minimization technique has a better performance than the regression method.
Comparison of the estimated Gini index using different Lorenz curves
There are many different functional forms of Lorenz curve, of which the most common forms are as the following:
The first five specifications of the above Lorenz curve are single-parametric, the last one is three-parametric, and the rest are double-parametric.
The minimization technique are applicable to all the above specifications of Lorenz curve, while the regression method can only be applied to the Kakwani’s Lorenz curve (1980). We fit the above-mentioned nine specifications using the error minimization technique, and fit the specification of the Kakwani’s Lorenz curve using the regression method based on the dataset of the sampled economies. Table 3 reports the estimated results. Column (4) presents the estimated result of the Kakwani’s Lorenz curve using the regression method, and columns (5)-(13) present the estimated results of the above nine specifications using the error minimization technique, respectively.
We find that the performance of the regression method is better than that of the error minimization technique under the single-parametric and the double-parametric specifications, while it is poorer than the error minimization method under the three-parametric specification presented in column (13). In addition, we find the regression method is always better than the error minimization technique under any specifications for the medium and the higher groups, since the RMSE of the regression method is smaller than the RMSE of the error minimization method under any specifications.
We also find that the three-parametric Lorenz curve has a better performance than the double-parametric one when the error minimization technique is used to fit Lorenz curve, since the RMSE under the three-parametric specification is smaller than the RMSE of the double-parametric one. Similarly, the double-parametric specification is better than the single-parametric one. The results from Table 3 also suggest that the L8 proposed by Sitthiyot and Holasut (2021) has the best performance in the three double-parametric Lorenz curves, and the L2 proposed by Aggarwal (1984) has the best performance in the five single-parametric Lorenz curves. Sitthiyot and Holasut (2023) find that the estimated Gini index has a lower bound of 0.4180 for the Lorenz curve L1 under the condition r > 0. In order to better fit the above-mentioned nine Lorenz curves, we relax the constraints on the parameters of those Lorenz curves when we fit them using the error minimization technique. For example, for the Lorenz curve L1, we allow the parameter r to vary between negative infinity and positive infinity, i.e. -∞ < r < ∞, and for the Lorenz curve L9, we allow the following looser parameter constaints: -∞ < q < ∞, 0 < r ≤ 1, and s > 0.
Comparison of the estimated income shares between LSH and KRE
Given the poorer performance of the regression method that fits the Lorenz curve in Table 2, we examine the relative performance of the regression method to the error minimization technique in fitting the income shares by decile. We compare the estimated income shares of the regression method under Kakwani’s Lorenz curve to those of the error minimization technique under the Lorenz curve L8, since the specification L8 has the best performance in all the single-parametric and the double parametric specifications. When estimating the income shares, we choose four countries from the sixteen economies, namely, Belgium, Albania (ALB), the United States (USA), and South Africa, which have significant differences in the level of inequality. For instance, the Gini index of Belgium is 0.2540 in 2019, Albania 0.343 in 2019, the USA 0.4709 in 2018, and South Africa 0.6170 in 2017.
Table 4 reports the estimated income shares for these four countries. Panel A in Table 4 presents the actual income shares and the estimated income shares using two methods for Belgium. Panel B, Panel C, and Panel D display the actual and the estimated income shares of Albania, the USA, and South Africa, respectively. The lower half of Table 4 reports the K-S test and the goodness-of-fit statistics such as IIM, MSE, MAE, and MAS.
The results of the K-S test suggest that there is no significant differences between the actual income shares and the estimated income shares for each country. Furthermore, judged by the MSE, MAE, MAS, and IIM, the regression method has a better performance than the error minimization technique in estimating income shares for Albania and the USA. In contrast, the error minimization technique has a better performance than the regression method for Belgium and South Africa.
Conclusions
Estimating Gini index with the income shares by decile attracts considerable attentions of researchers. Because the cumulative population shares and the corresponding cumulative income shares by decile form the points of Lorenz curve, fitting Lorenz curve is more convenient than fitting income distribution function. Based on the Lorenz curve suggested by Kakwani (1980), we propose a new approach named the regression method to estimate parameters of this Lorenz curve and calculate the Gini index for the sample economies.
We build a linear multiple regression equation and obtain the estimated values of three parameters of the Kakwani (1980)’s Lorenz curve using the latest data on the income shares by decile from the UNU-WIID database. We then calculate Gini index based on the Beta function, which is easily calculated utilizing some popular computer programs such as EWIEWS, STATA, MATHLAB, and R. We also provide a method to estimate the variance of Gini index.
The results suggest that the regression method has a better performance than the error minimization technique when fitting the Lorenz curve proposed by Kakwani (1980). We extend the range of the parameter p in Eq. ⑵ by replacing 0 < p ≤ 1 with p > 0. In the same time, the Lorenz curve proposed by Kakwani (1980) allows for negative income and wealth values. This is very useful for research using survey data with negative values.
We also analyze the effects of the different forms of Lorenz curves on the estimated Gini index. Using nine popular Lorenz curves, we find that the three-parametric Lorenz curves have a better performance than the double-parametric curves judged by the RMSE, and the double-parametric specifications are better than the single-parametric. Furthermore, we find that the three-parametric Lorenz curve proposed by Sarabia et al. (1999) has the best performance among the nine Lorenz curves. In addition, we find the regression method has the best performance for the economies with medium and higher levels of inequality, while the error minimization technique is the best for the economies with low and high levels of inequality under the Lorenz curve proposed by Sarabia et al. (1999).
Among the double-parametric Lorenz curves, the Lorenz curve suggested by Sitthiyot and Holasut (2021) has the best performance in terms of the estimated Gini index. Therefore, we compare the performance of the regression method to that of the error minimization technique in estimating the income shares by decile. The results show that the regression method is better than the error minimization technique for the economies with medium and higher inequality, while the minimization technique is better than the regression method for the economies with low and high inequality.
Data availability
The datasets generated and/or analyzed during the current study can be accessed from the United Nations University World Institute for Development Economics Research (UNU-WIDER) website (http://www4.wider.unu.edu/).
Notes
The density function of Beta-II distribution in Chotikapanich et al. (2007) is as following:
\(f(x)=\frac{{x}^{p-1}}{{b}^{p}B(p,q){(1\,+\,x/b)}^{p+q}}\begin{array}{cc}, & x \,>\, 0\end{array}\) where, B(·) is the Beta function, b, p, and q are all positive parameters.
The dirichlet distribution function in Chotikapanich and Griffiths (2002) is as following:
\(f(q|\alpha )=\frac{\varGamma ({\alpha }_{1}\,+\,{\alpha }_{2}\,+\,\cdots \,+\,{\alpha }_{M})}{\varGamma ({\alpha }_{1})\varGamma ({\alpha }_{2})\cdots \varGamma ({\alpha }_{M})}{q}_{1}^{{\alpha }_{1}-1}{q}_{2}^{{\alpha }_{2}-1}\cdots {q}_{M}^{{\alpha }_{M}-1}\begin{array}{cc}, & {\alpha }_{i}=\lambda [L({p}_{i};\theta )-L({p}_{i-1};\theta )]\end{array}\)
here, \(\varGamma (x)={\int }_{0}^{\infty }{t}^{x-1}{e}^{-t}dt\) is the Gamma function, λ is an additional unknown parameter. Correspondingly, the likelihood function of the above distribution function is as following:
\(\log [f(q|\theta )]=\,\log \varGamma (\lambda )+\mathop{\sum }\limits_{i=1}^{M}\{\lambda [L({p}_{i},\theta )-L({p}_{i-1},\theta )]-1\}\times \,\log {q}_{i}-\mathop{\sum }\limits_{i=1}^{M}\log \varGamma \{\lambda [L({p}_{i},\theta )-L({p}_{i-1},\theta )]\}\).
References
Aggarwal V (1984) On optimum aggregation of income distribution data. Sankhya B 46:343–355
Blanchet T, Piketty T, Fournier J (2022) Generalized Pareto curves: theory and applications. Rev Income Wealth 1:263–288
Chotikapanich D, Valenzuela MR, Prasada Rao DS (1997) Global and regional inequality in the distribution of income: Estimation with limited/incomplete data. Empir Econ 20:533–546
Chotikapanich D, Griffiths WE, Rao DSP (2007) Estimating and combining national income distributions using limited data. J Bus Econ Stat 25:97–109
Chotikapanich D (1993) A comparison of alternative functional forms for the Lorenz curve. Econ Lett 41:21–29
Chotikapanich D, Griffiths WE (2002) Estimating Lorenz curves using a dirichlet distribution. J Bus Econ Stat 20:290–295
Cheong KS (2002) An empirical comparison of alternative functional forms for the Lorenz curve. Appl Econ Lett 9:171–176
Dagum C (1977) A new model of personal income distribution: Specification and estimation. In: Chotikapanich D (Ed) Modeling income distributions and Lorenz curves. Economic studies in equality, social exclusion and well-being, vol 5. Springer, New York, pp. 3–25
Jorda V, Sarabia JM, Jantti M (2021) Inequality measurement with grouped data: parametric and non-parametric methods. J R Stat Soc Ser A 184:964–984
Kakwani NC (1980) On a class of poverty measures. Econometrica 48:437–446
Kakwani NC, Podder N (1973) On the estimation of Lorenz curves from grouped observations. Int Econ Rev 14:278–292
Kakwani NC, Podder N (1976) Efficient estimation of the Lorenz curve and associated inequality measures from grouped observations. Econometrica 44:137–148
McDonald JB (1984) Some generalized functions for the size distribution of income. Econometrica 52:647–663
Ortega P, Martn G, Fernndez A, Ladoux M, Garca A (1991) A new functional form for estimating Lorenz curves. Rev Income Wealth 37:447–452
Paul S, Shankar S (2020) An alternative single parameter functional form for Lorenz curve. Empir Econ 59:1393–1402
Rasche RH, Gaffney J, Koo A, Obst N (1980) Function forms for estimating the Lorenz curve. Econometrica 48:1061–1062
Sarabia JM, Castillo E, Slottje D (1999) An ordered family of Lorenz curves. J Econ 91:43–60
Sitthiyot T, Holasut K (2021) A simple method for estimating the Lorenz curve. Hum Soc Sci Commun. 8:268
Sitthiyot T, Holasut K (2023) An investigation of the performance of parametric functional forms for the Lorenz curve. PLoS ONE 18(6):e0287546
Tanak AK, Mohtashami Borzadaran GR, Ahmadi J (2018) New functional forms of Lorenz curves by maximizing Tsallis entropy of income share function under the constraint on generalized Gini index. Phys A 511:280–288
Author information
Authors and Affiliations
Contributions
Conceptualization: Pingsheng Dai. Formal analysis: Xiaobo Shen, Pingsheng Dai. Methodology: Pingsheng Dai. Validation: Xiaobo Shen. Writing - original draft: Pingsheng Dai. Writing - review & editing: Pingsheng Dai, Xiaobo Shen.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
Ethical approval was not required as the study did not involve human participants.
Informed consent
This article does not contain any studies with human participants performed by any of the authors.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Shen, X., Dai, P. A regression method for estimating Gini index by decile. Humanit Soc Sci Commun 11, 1235 (2024). https://doi.org/10.1057/s41599-024-03701-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1057/s41599-024-03701-2
- Springer Nature Limited