
Abstract
Non-participation can be a source of selection bias. We evaluated the effect of non-participation on food insecurity prevalence among 2942 young adults from the EPITeen cohort (Portugal), which we have followed since assembling the cohort in 2003–2004. We conducted a cross-sectional study when the cohort participants were 26 years old. To examine the effect of non-participation, we statistically imputed the missing data on food security status using multivariate imputation by chained equations based on characteristics associated with food insecurity, specifically household income perception, education and household structure from 21 or 24 years of age follow-ups. In our cohort, non-participation caused ~ 2% difference in the food insecurity prevalence: 11.0% (95% CI 9.0–13.0) for 954 participants and 12.6% (95% CI 11.1–14.1) after imputation. These estimates are close to evidence from other European countries and sustain the relevance of developing public health interventions to promote food security, especially considering the negative nutritional and health outcomes associated with food insecurity.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Key messages
-
We evaluated the effect of non-participation on the prevalence estimate of food insecurity among young adults from a longitudinal population-based cohort.
-
To estimate food security status among non-participants, we used data from previous evaluations of a longitudinal cohort to impute missing data using multivariate imputation by chained equations.
-
Non-participation accounted for a ~ 2% decrease in the estimated prevalence of food insecurity–after multiple imputations, from 11.0 to 12.6%.
Introduction
Food insecurity, defined as "limited or uncertain availability of nutritionally adequate and safe foods or limited or uncertain ability to acquire acceptable foods in socially acceptable ways" [1]—is an important public health problem and one attracting more attention. Although the research community observed considerable prevalence of food insecurity among young adults in Portugal during 2011 to 2013—a period of economic crisis (43.7% [2]), they reported lower estimates in this population group for 2015–2016 (8.6% [3]). Food insecurity constitutes an important concern, especially based on recent reports that 10.1% of Portuguese families experienced food insecurity in 2015–2016 [4].
Investigators have associated food insecurity with negative health outcomes [5,6,7,8] and young adults, mainly due to the economic vulnerability characteristic of this life period [9], are more likely to experience food insecurity than other age groups [10,11,12]. The vulnerability of young adults reinforces the importance of gathering evidence-based knowledge about them to inform development of appropriate public health policies.
Valid estimates of food insecurity are key features of that knowledge. In epidemiological research, non-participation may represent a source of selection bias, affect both the internal and external validity of the study, and could make difficult to understand its real effect [13]. Participants may differ from non-participants. Among the reasons for non-participation are time constraints and low rates of willingness to participate in studies [14, 15]. These factors have contributed also to a decrease in the retention of participants, mainly in longitudinal studies [16]. Research shows that individuals with low levels of education, and those of low socioeconomic status, are less likely to participate or more likely to drop out of a study [17, 18]. However, low rates of participation do not necessarily represent a loss of validity, but the potential risk of it [16]. In aiming to assess the prevalence of food insecurity, non-participation may have an important effect, especially because the factors noted above related to non-participation are also determinants of food insecurity [19,20,21].
Therefore, we used a population-based cohort, the EPITeen cohort study, to evaluate the effect of non-participation on the food insecurity prevalence estimate in young adults. We applied a statistical technique to replace missing values on food security status with values produced by imputation based on available information.
Methods
Study design and participants
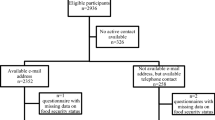
This is a cross-sectional study conducted as part of the Epidemiological Health Investigation of Teenagers (EPITeen) cohort in Porto, Portugal. The EPITeen is a population-based cohort assembled to study growth, development, and health in adolescents born in 1990 who attended public and private schools in Porto, Portugal, as described elsewhere [22]. At baseline (in the school year of 2003–2004), 2159 adolescents agreed to participate (77.5%) [22]. A second evaluation of the cohort took place when individuals reached 17 years of age, in school year 2007–2008, with 1716 participants (79.5%). The cohort also enrolled an additional 783 adolescents, also born in 1990, who had moved to Porto schools after the baseline evaluation. The cohort carried out additional follow-up evaluations at 21 (2011–2013) and 24 (2014–2015) years of age, evaluating 1764 and 1094 participants, respectively. For the present study, when the cohort was 26 years of age, in March and April 2016, we evaluated the cohort with the specific purpose of to assess food security status [23].
We obtained ethical approval for the EPITeen study from the Ethics Committee of the São João University Hospital, Porto, the Institute of Public Health of the University of Porto, and the Portuguese Data Protection Authority. We developed policies and procedures to guarantee data confidentiality and protection. We obtained written informed consent for participation in all evaluations from participants, and also from parents of the adolescents at 13 and 17 years of age. For the food security status assessment, and depending on the method of data collection, cohort participants provided consent online, after signing onto the web-based platform, or orally.
Data collection
At the time of the food security status evaluation, we collected information on sociodemographic characteristics: education (completed years of formal schooling), household structure, and household income perception. We classified household structure as follows: (1) parents-based nuclear family (participant and parent(s), or siblings, or all), (2) participant-based nuclear family (index young adult and that person’s partner, or children, or both), (3) extended family (comprising all family members beyond the nuclear family), and (4) others (comprising individuals who reported living alone and those who lived with other individuals–for instance, living only with non-family members or living with family and non-family members). We collected data on the household income perception using a four-option question with responses: ‘insufficient’, ‘need to be careful about expenses’, ‘enough to meet needs’ and ‘comfortable’. For statistical analysis, we created a binary variable by combining the categories ‘need to be careful about expenses’, ‘enough to meet needs’, and ‘comfortable’ into ‘sufficient’ category to adjust for household income perception.
We assessed food security status using the United States (US) Household Food Security Survey Module: Six-Item Short Form [24], translated into Portuguese by the research team (Cronbach’s alpha = 0.753). The US Household Food Security Survey Module: Six-Item Short Form comprises six questions related to the previous 12 months; we asked individuals whether they were able to afford the food they needed. The total raw score corresponded to the sum of affirmative responses for each of the six questions. We classified households as ‘food secure’ if the number of affirmative responses was equal to, or less than one; or as ‘food insecure’ if we obtained two to six affirmative responses [24].
Identification of participants and non-participants
Among the 2942 cohort participants, we registered six deaths. We found no active contact information for 326 participants. Of the remaining participants, 2352 had provided updated e-mail addresses and the study team sent each a link to the web-based questionnaire; for 258 participants for whom we had no e-mail address, the study team made telephone contact and invited those participants to answer a computer-assisted telephone interview (CATI). The proportion of cohort participants who answered through the web-based questionnaire was 37.1%, for CATI it was 31.4% (p = 0.070).
A sample of 957 individuals responded to the questionnaire. Of those, 3 people had missing data on food security status. In the final sample of 954 individuals, 873 (91.5%) answered using the web-based questionnaire, and 81 (8.5%) through CATI.
From the total of 2942, after excluding 6 deaths and the 954 participants, a sample of 1982 was considered as non-participants as they have missing data on food security status.
Considering the determinants of food insecurity identified in this population group, we used data on education, household structure, and household income perception from previous follow-up evaluations of the EPITeen cohort to impute food security status for non-participants.
Statistical analysis
We described continuous variables as mean and standard deviation (SD), and categorical variables as counts and proportions. We compared means using Student’s T-test, and for proportions, we used the Chi-square test. We assessed food insecurity determinants in the 954 participants of the 26-year-old evaluation. For that purpose, we applied logistic regression models (crude and adjusted for education, household structure and household income perception) and calculated odds ratios (ORs) and 95% confidence intervals (95% CIs).
To estimate the effect of non-participation on food insecurity prevalence, we took data on education (n = 948), household income perception (n = 920) and household structure (n = 938) from the 21- and 24-year-old evaluation and we used the most recent information for each variable to perform multiple imputations of missing values in the food security status. To impute missing data on food security status, we used multivariate imputation by chained equations (MICE). The MICE package [25] creates multiple imputations for multivariate missing data, based on Fully Conditional Specification [26]. In this study, we used MICE under the assumption that given variables used in the imputation procedure, missing data occur at random [27], or in other words assuming that the probability of having a missing value depends only on observed values and not on unobserved [27, 28].
We carried out the process of multiple imputation in three main steps: imputation, analysis, and pooling. In the first step, we replaced missing values with plausible values drawn from a distribution specially modelled for each missing value, based on the observed data, and different imputed datasets were obtained [26, 29]. In the second step, we estimated food security status from each imputed dataset. In the third step, we pooled results of the different imputed datasets [26, 30].
This process was repeated for the three tested models, considering the number of variables associated with food insecurity not missing for each non-participant; that is, with a guarantee that at least one, two, or three variables per non-participant were available for the analysis. In the end, we determined an overall food insecurity prevalence for each of the three tested models.
Finally, we performed a sensitivity analysis using the most recent data from the follow-up evaluation of the cohort at 24 years of age.
We performed statistical analysis using SPSS Statistics 25.0 and the software R 3.4.3, mice package 3.5. We adopted a significance level of 5%.
Results
In the sample of 954 participants, the prevalence (95% CI) of food insecurity was 11.0% (9.0–13.0). Cohort characteristics shown to be significantly associated with food insecurity were education, household income perception, and household structure (Table 1). The results were similar for both methods of data collection: CATI and web-based questionnaire.
In comparing 954 participants who have information on food security status with the 1982 non-participants for whom such information was missing, we observed that participants were more often women than men (58.3% vs. 47.9%; p < 0.001), and had more years of schooling [mean (SD) = 13.8 (1.7) vs. 12.8 (2.2); p < 0.001]. Participants were less likely to report an insufficient household income (5.6% vs. 9.6%; p = 0.011) and their parents had more years of schooling [11.6 (4.5) vs. 9.9 (4.6) years of schooling; p < 0.001] as compared to non-participants (Table 2). Based on sensitivity analyses, for non-participants we observed no differences as to household income perception and education (as a categorical variable: < 12, 12 or > 12 years of schooling) when comparing the cohort at 21 and at 24 years of age. The proportion of individuals living in a parents-based nuclear family at 26 years of age (55.6%) was lower for participants than their counterparts at 21 or 24 years of age (69.3%).
Characteristics of the cohort with which we performed imputations are shown in Table 3. After imputing missing data in the models with at least one, two or three variables used for multiple imputation not missing, the overall food insecurity prevalence estimates were 12.5% (95% CI 11.1–14.0), 12.5% (95% CI 11.0–14.0) and 12.6% (95% CI 11.1–14.1), respectively (Table 4). We considered as the most appropriate the model where at least three variables were available for the analysis. We performed a sensitivity analysis using data from the most recent follow-up evaluation (of 24 year olds), and obtained a similar prevalence of food insecurity of 11.1%, 10.8% and 11.8%, for the models guaranteed at least one, two or three variables are available, respectively.
Discussion
We observed a high proportion of non-participation (63%) in the EPITeen cohort. The differences between participants and non-participants, particularly in characteristics associated with food insecurity (such as education, household structure and household income perception), reinforced the need to evaluate the effect of non-participation on the food insecurity prevalence estimates. This is particularly important among young adults—a population group vulnerable to food insecurity, because of the economic vulnerability characteristic of this period of life [9].
A review of the literature pointed out that researchers should acknowledge non-participation in the studies, and if non-participation is caused by data missing at random, researchers may use multiple imputation to replace missing values [31]. In our study, those who participated and had data on food security status were more educated and from a higher socioeconomic status, while those non-participants (with missing data) were less educated and from a lower socioeconomic status (education and socioeconomic status are determinants of (non) participation). Thus, and in line previous evidence [27], we consider that missing were at random, as the possible differences between having missing and food security status values could be explained by the observed sociodemographic variables (in the case of our study, education, household income perception and household structure), which can be seen as a proxy of the individuals’ socioeconomic status. For public health professionals and policy implication, this is important because can be seen as a way to assess the validity of the food insecurity estimates.
We found the determinants of food insecurity (education, household structure and household income perception) to be similar using two methods of data collection. We recognize the need to compare the two methods of data collection, because some methods could lead to social desirability bias, especially for sensitive topics as food insecurity is.
Although some sociodemographic characteristics, namely education and household structure, were not significantly associated with food insecurity, in the CATI group, the direction of the associations remained and these results probably reflect the insufficient power to detect significant differences. Thus, we decided to use the information on education, household structure and household income perception from previous follow-up evaluations—derived by face-to-face interviews—to impute missing data on food security status.
We computed three models for imputation of the missing data on food security status. Despite seemingly similar results, we considered the model using at least three associated variables as not missing to be the most appropriate one. The justification is that all the available variables used for imputation could lead to a more reliable estimate of the food security status of the young adults’ household. Thus, after multiple imputations, the prevalence of food insecurity was 12.6%, and not considerably differ from the prevalence of food insecurity we evaluated (11.0%). So, non-participation introduced a near 2% difference in the prevalence of food insecurity; we believe that the generalizability of study results is not impaired [32], supporting the validity of the estimate.
We anticipated a huger impact of non-participation on the prevalence of food insecurity, as use of data from the 21 and 24 years of age follow-ups could not represent the real situation at 26 years. However, a sensitivity analysis suggested stability in these variables among non-participants, supporting its use for multiple imputation of the missing data on food security status.
The household structure variable showed differences throughout evaluations, as we expected in this period of the life span [33]. The potential protective effect of living with parents seems to reduce the risk of food insecurity for non-participants and contribute to the slight difference of the prevalence of food insecurity observed. Nevertheless, to assess the potential influence of using data from previous evaluations (at 21 and 24 years of age) for food security status imputation, we performed a sensitivity analysis using the most recent data; the results were similar.
To the best of our knowledge, there are no previous studies assessing the effect of non-participation on the prevalence of food insecurity, limiting further comparison. We examined research on other topics, such as on smoking trends or HIV prevalence [34, 35], showing that non-participation (or missing data) can be a source of bias. Hence, the use of data from a population-based cohort to explore the effect of non-participation on the food insecurity prevalence provides a unique opportunity to assess the effect of non-participation and the possibility of selection bias among this cohort of young adults. We believe this represents an important strength of this study. We also consider the use of MICE to assess the effect of non-participation in food insecurity prevalence as a strength. Contrary to other methods of imputation, this method can utilize different types of variables, continuous or categorical [25]. This method can create multiple imputations, rather than single one, accounting for the statistical uncertainty in the imputations [25], thus overcoming the limitations of other methods [29, 36]. Another strength is use of two methods for data collection (designed to reach more participants [37]) compared to use of a single method. Also important is the lack in differences in the proportion of participation in the two methods.
The present study also had limitations. After food security status imputation, data were still missing for between 35 and 37% (depending on the model that guarantees at least one, two or three associated variables as not missing). We believe we used the best possible approach, by using characteristics from previous evaluations of the cohort to perform the imputation of the missing data on food security status. Non-participants were more likely to be from low socioeconomic strata [17, 18], and, therefore, more likely to be vulnerable to food insecurity. Among young adults’ cohorts, it was already expected a low participation proportion, also common in other population-based cohorts with several evaluation throughout time.
Conclusion
We obtained a prevalence of food insecurity of 12.6%, according to the model that guaranteed at least three variables not missing. For our cohort, non-participation did little to impair the internal validity of the study. On food security status assessment, evaluation of the impact of non-participation is of utmost relevance as it may affect the validity of the food insecurity prevalence estimates, which ultimately might affect public health policy and practice.
References
Anderson SA. Core indicators of nutritional state for difficult-to-sample populations. J Nutr. 1990;120:1555–600.
Gregório MJ, Graça P, Nogueira PJ. Household food insecurity determinants in Portugal – Results from INFOFAMÍLIA National Survey (2011–2013). In: Gregório MJ. Social inequalities in the access to a healthy diet: a study in the Portuguese population PhD Thesis. Porto, Portugal: Faculty of Nutrition and Food Science of the University of Porto; 2014.
Gregório MJ, Rodrigues AM, Graça P, de Sousa RD, Dias SS, Branco JC, et al. Food insecurity is associated with low adherence to the Mediterranean diet and adverse health conditions in Portuguese adults. Front Public Health. 2018;6:38.
Lopes C, Torres D, Oliveira A, Severo M, Alarcão V, Guiomar S, et al. National Food, Nutrition, and Physical Activity Survey of the Portuguese General Population 2015–2016: Summary of Results. 2018. https://www.ian-af.up.pt/sites/default/files/IAN-AF/20Summary/20of/20Results_1.pdf. Accessed 26 May 2020.
Leung CW, Epel ES, Ritchie LD, Crawford PB, Laraia BA. Food insecurity is inversely associated with diet quality of lower-income adults. J Acad Nutr Diet. 2014;114(1943–1953): e2.
Pan L, Sherry B, Njai R, Blanck HM. Food insecurity is associated with obesity among US adults in 12 states. J Acad Nutr Diet. 2012;112:1403–9.
Pérez-Escamilla R, Villalpando S, Shamah-Levy T, Méndez-Gómez HI. Household food insecurity, diabetes and hypertension among Mexican adults: results from Ensanut 2012. Salud Publica Mex. 2014;56:s62–70.
Thomas MK, Lammert LJ, Beverly EA. Food insecurity and its impact on body weight, type 2 diabetes, cardiovascular disease, and mental health. Curr Cardiovasc Risk Rep. 2021;15:15.
Fiori F, Rinesi F, Spizzichino D, Di Giorgio G. Employment insecurity and mental health during the economic recession: an analysis of the young adult labour force in Italy. Soc Sci Med. 2016;153:90–8.
Krahn HJ, Howard AL, Galambos NL. Exploring or Floundering? The meaning of employment and educational fluctuations in emerging adulthood. Youth Soc. 2012;47:245–66.
Baer TE, Scherer EA, Fleegler EW, Hassan A. Food Insecurity and the Burden of Health-Related Social Problems in an Urban Youth Population. J Adolesc Health. 2015;57:601–7.
Bhawra J, Kirkpatrick SI, Hammond D. Food insecurity among Canadian youth and young adults: insights from the Canada Food Study. Can J Public Health. 2021;112:663–75.
Nohr EA, Liew Z. How to investigate and adjust for selection bias in cohort studies. Acta Obstet Gynecol Scand. 2018;97:407–16.
Markanday S, Brennan SL, Gould H, Pasco JA. Sex-differences in reasons for non-participation at recruitment: geelong osteoporosis study. BMC Res Notes. 2013;6:104.
Keusch F, Batinic B, Mayerhofer W. Motives for joining nonprobability online panels and their association with survey participation behavior. In: Callegaro M, Baker RP, Bethlehem J, Göritz AS, Krosnick JA, Lavrakas PJ, editors. Online panel research. Hoboken: Wiley; 2014. p. 171–91.
Morton SM, Bandara DK, Robinson EM, Carr PE. In the 21st Century, what is an acceptable response rate? Aust N Z J Public Health. 2012;36:106–8.
Canivet C, Nilsson A, Björk J, Moghaddassi M, Östergren P-O. Assessment of selection bias due to dropouts in the follow-up of the Scania Public Health Cohort. Scand J Public Health. 2021;49:457–64.
Ramos P, Santana R, Cima J, Marques P, Baptista A, Moreno L, et al. Participation rates in epidemiologic studies. Eur J Public Health. 2015;25:376.
Carter KN, Lanumata T, Kruse K, Gorton D. What are the determinants of food insecurity in New Zealand and does this differ for males and females? Aust N Z J Public Health. 2010;34:602–8.
Gundersen C. Food insecurity is an ongoing national concern. Adv Nutr. 2013;4:36–41.
Martin-Fernandez J, Grillo F, Parizot I, Caillavet F, Chauvin P. Prevalence and socioeconomic and geographical inequalities of household food insecurity in the Paris region, France, 2010. BMC Public Health. 2013;13:486.
Ramos E, Barros H. Family and school determinants of overweight in 13-year-old Portuguese adolescents. Acta Paediatr. 2007;96:281–6.
Maia I, Monjardino T, Lucas R, Ramos E, Santos AC. Household food insecurity and socio-demographic determinants in young adults: findings from a Portuguese population-based sample. Int J Public Health. 2019;64:887–95.
United States Department of Agriculture. U.S. Household Food Security Survey Module: Six-Item Short Form. 2012. https://www.ers.usda.gov/media/8282/short2012.pdf. Accessed 20 July 2015.
Azur MJ, Stuart EA, Frangakis C, Leaf PJ. Multiple imputation by chained equations: what is it and how does it work? Int J Methods Psychiatry Res. 2011;20:40–9.
van Buuren S, Groothuis-Oudshoorn K. mice: multivariate imputation by chained equations in R. J Stat Softw. 2011;45:67.
Bhaskaran K, Smeeth L. What is the difference between missing completely at random and missing at random? Int J Epidemiol. 2014;43:1336–9.
Schafer JL, Graham JW. Missing data: our view of the state of the art. Psychol Methods. 2002;7:147–77.
Sterne JA, White IR, Carlin JB, Spratt M, Royston P, Kenward MG, et al. Multiple imputation for missing data in epidemiological and clinical research: potential and pitfalls. BMJ. 2009;338: b2393.
van Buuren S. Flexible imputation of missing data. 2nd ed. Florida: CRC Press; 2018.
Keeble C, Baxter PD, Barber S. Participation rates in epidemiology studies and surveys: a review 2005–2007. Internet J Epidemiol. 2016;14:1–14.
Alkerwi AA, Sauvageot N, Couffignal S, Albert A, Lair M-L, Guillaume M. Comparison of participants and non-participants to the ORISCAV-LUX population-based study on cardiovascular risk factors in Luxembourg. BMC Med Res Methodol. 2010;10:80.
Corijn M, Klijzing E. Transitions to adulthood in Europe. 1st ed. Dordrecht: Springer; 2001.
Chinomona A, Mwambi H. Multiple imputation for non-response when estimating HIV prevalence using survey data. BMC Public Health. 2015;15:1059–1059.
Tolonen H, Kopra K, Vartiainen E. The effect of non-participation on the estimation of smoking trends: Hanna Tolonen. Eur J Public Health. 2015;25:292–3.
Salgado CM, Azevedo C, Proença H, Vieira SM. Missing Data. In: MIT critical data. Secondary analysis of electronic health records. Cambridge: Springer; 2016.
Dillman DA, Smyth JD, Christian LM. Internet, phone, mail, and mixed-mode surveys. 4th ed. Hoboken: Wiley; 2014.
Acknowledgements
The authors gratefully acknowledge the participants enrolled in EPITeen for their kindness and all members of the research team for their enthusiasm and perseverance.
Funding
This work was supported by FEDER through the Operational Programme Competitiveness and Internationalization and national funding from the Foundation for Science and Technology – FCT (Portuguese Ministry of Science, Technology and Higher Education) (POCI-01-0145-FEDER-016829), under the project “A longitudinal approach to metabolically healthy obesity: from inflammation to cardiovascular risk profile” PTDC/DTP-EPI/6506/2014. This research was also financed by Portuguese Funds through FCT—Foundation for Science and Technology, I.P., under the project UIDB/04750/2020 [Unidade de Investigação em Epidemiologia—Instituto de Saúde Pública da Universidade do Porto (EPIUnit)], and the project UID/MAT/00013/2013. This study is also supported by the PhD Grant SFRH/BD/117371/2016 (IM) co-funded by the FCT and the POCH/FSE Program, and the FCT Investigator contract IF/01060/2015 (ACS). This study is also a result of the project DOCnet (NORTE-01- 0145-FEDER- 000003), supported by Norte Portugal Regional Operational Programme (NORTE 2020), under the PORTUGAL 2020 Partnership Agreement, through the European Regional Development Fund (ERDF).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Maia, I., Moreira, C., Ramos, E. et al. The effect of non-participation on the prevalence of food insecurity in a population-based cohort in Portugal. J Public Health Pol 43, 391–402 (2022). https://doi.org/10.1057/s41271-022-00362-w
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1057/s41271-022-00362-w