
Abstract
Social media platforms significantly increase general information about disease severity and inform preventive measures among community members. To identify public opinion through tweets on the subject of Covid-19 and investigate public sentiment in the country over the period. This article proposed a novel method for sentiment analysis of coronavirus-related tweets using bidirectional encoder representations from transformers (BERT) bi-directional long short-term memory (Bi-LSTM) ensemble learning model. The proposed approach consists of two stages. In the first stage, the BERT model gains the domain knowledge with Covid-19 data and fine-tunes with sentiment word dictionary. The second stage is the Bi-LSTM model, which is used to process the data in a bi-directional way with context sequence dependency preserving to process the data and classify the sentiment. Finally, the ensemble technique combines both models to classify the sentiment into positive and negative categories. The result obtained by the proposed method is better than the state-of-the-art methods. Moreover, the proposed model efficiently understands the public opinion on the Twitter platform, which can aid in formulating, monitoring and regulating public health policies during a pandemic.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Introduction
With the emergence of Covid-19 globally massive number of people affected have suffered health issues, making the epidemic the most significant public health event of the twenty-first century. The impact of the disease has been a life-threatening a health condition that cannot be disregarded throughout previous years in history, and it has impacted people physiology and psychology. The Wuhan health commission in china recorded 27 instances of pneumonia with no known cause in December 2019. Covid-19, which is generated from SARS-CoV-2, is spreading rapidly worldwide, causing millions of infections and deaths among humans. SARS-CoV-2 was discovered in a seafood marketplace in China in December 2019 and infected millions of people. The World Health Organization (WHO) (https://www.who.int) formally named the novel coronavirus Covid-19 on 11 Feb 2020 in Geneva. Since the outbreak of Covid-19, the disease has sparked widespread panic worldwide.
The Covid-19 epidemic had a profound effect on social communities and people’s daily life throughout the world. Countries globally employed various containment guidelines in response to local pandemic conditions to safeguard their populations and restrict the spread of Covid-19. To enforce lockdown and suspend domestic and international flights to routine methods such as making it mandatory to wear masks and maintain social distancing in public. Countries have used various methods to control the spread of covid-19. While people in most countries have adapted to covid appropriate safety guidelines such as masks and social distancing, a complete restriction on movement enforced through a lockdown has often met with resistance in different parts of the world. The public perception of a lockdown is crucial since it determines public opinion. Real-time analysis of posts on social media has proven to be a valuable resource for understanding public sentiment. The method of identifying community opinion is known as “sentiment analysis”. It is a subset of text mining that entails automating emotions from textual content through natural language processing (NLP). Textual analytics is concerned with evocating and analyzing characters. Also, as the semantics, syntax, and associated endogenous aspects. This method aids in defining user opinion toward any entity, issue, or product, among other things 1,2.
Social media platforms facilitate information among human societies and assist them in exchanging ideas, information, knowledge, and other facts. It generates a massive volume of data on various platforms like Facebook, Twitter, and Instagram. Social and statistical research has revealed that regular usage of these applications affects human behavior, both positively and negatively. Twitter has approximately 400 million registered users sharing their thought and generates a massive data volume every day. Twitter users share news, information, and opinions through “ tweets,” short messages. Twitter users can also like, comment, “retweet” (reposting a tweet), and share tweets. This provides an excellent platform for opinion-based textual data analytics in various real-world applications. According to WHO guidelines, awareness and social isolation are the most effective methods of staying safe during a pandemic. Social distancing is an effective strategy to control the spread of the Covid-19 pandemic. People are encouraged to remain at home and maintain social distance. To ensure social separation in public spaces, practically all governments imposed lockdowns. There has never been a time when the entire planet was under lockdown in the history of human civilization. Lockdown is an emergency technique that prevents individuals from freely moving about public areas. People must stay there and not even venture outside their building during a total lockdown. Consider lockdown as a curfew with certain exceptions for vital services. For the duration of the closure, all non-essential services are disabled. Over 200 countries, regions, and territories have already been affected by the Covid-19 outbreak. The Covid-19 situation has had severe consequences in terms of health, financial crises, and education.
Merchant and Lurie3 conducted study in which they examined the importance of social media as a critical tool in managing the ongoing epidemic and the evolving characteristics of disaster preparedness and response. Doulamis et al.4 categorized Twitter data as per the tasks, event kinds, and the content orientation of tweets. Farzindar and Khreich5 conducted a similar study in which they examined event detection in Twitter data in terms of event types, characteristics, detection methods. Saeed et al.6 categorized existing methods for detecting Twitter events, highlighted their shortcomings, and rectified the deficiencies of existing approaches. Machine learning and hybrid method have been used to evaluate the implications of Covid-19 on socioeconomic condition using Twitter data. The previous work contribution shows in Table 1.
Twitter platform for collecting community opinion during the current Covid-19 outbreak. Twitter has an advantage over specific other social media platforms in that it provides immediate access to concise, real-time information and networks of comparable topics via #hashtags. Analyzing public responses and sentiment during the early stages of a pandemic in places with social inequalities might help inform future public health guidelines in similar conditions. We have collected the Covid-19-related data from the Twitter platform in our work. We extract Twitter data related to current challenges and discuss the prevalent public opinion around Covid-19. The findings of this research could help governments around the world design effective public health responses. Depending on local health infrastructure, economic position, demography, and varied regional circumstances, people expressed a range of perspectives, opinions, and feelings towards identical Covid-19 guidelines. During the various stages of covid-19 wave of the Coronavirus pandemic in 2021, the Indian government emphasized different public health guidelines, including “wash your hands,” “stay home,” “maintain a safe distance from other people,” “use the mask,” and “avoid coughing or sneezing in a public place.” Given the severity of the virus and the high mortality rate observed during the second wave in India, it was critical to stress the need of covid-19 appropriate behavior.
Research motivation
People are being pushed out of public situations, and most of the coronavirus discussions take place on social media platforms like Twitter. So we can use Twitter data to mitigate and control the Covid-19 pandemic. The study aims to monitor public opinion to determine how their prospects, view, and opinions change with time in the country during a crisis. Analyzing a tremendous amount of community information can assist governments in analyzing public opinion over a period for making public health policy or applying safety guidelines. Opinion analysis finds out what the community is thinking about a subject. With the rise of coronavirus in late 2019 and its spread in early 2020, we will analyze how people think Covid-19 will affect over a period that has been a difficult situation by this disease.
Problem statement
Social media platforms contain a tremendous amount of public opinion information to analyze and a decision-making system. So we need to examine public opinions around the Covid-19 situation, which helps us to analyze individual perceptions and make future policies. Previously, many countries have imposed lockdown as a solution to the covid-19.
The purpose of this work is to determine the Covid-19-related subjects and public opinion over the period of time stated on Twitter.
Research questions covered in this article are:
-
How to automatically determine public perceptions stated on Twitter as a result of Covid-19?
-
What are the most common challenges discussed while expressing their opinions about Covid-19 on Twitter?
-
How to determine the Covid-19-related subjects and public opinion over the period of time stated on Twitter?
Research contribution
The paper presents Twitter data as a source for opinion analysis. It is used to gauge public opinion and, more specifically, to track the subject associated with Covid-19. Also offers a systematic technique for analyzing sentiment classification for related variations in crisis scenarios, and association concerning Twitter data analysis. In this study, we proposed a deep transformer learning intelligence model to determine the social community opinion about Covid-19 in situations across the country. The proposed novel model would combine a transformer-based deep learning ensemble approach.
The contribution of this research work as follows :
-
Sentiment analysis is used to examine public opinion toward Covid-19 related subject using Twitter data.
-
The proposed method identifies public opinion in real-time and discusses the prevalent public dialogue around Covid-19.
-
The proposed work classifies sentiments about Covid-19 related subjects over a period of time.
-
The findings of this research could help governments around the world design effective public health decisions.
The remaining paper is organized as follows: Section “Related work”, discuss the related work. Section “Proposed method”, Proposed method. Section “Results analysis”, Results analysis. Section “Conclusion”, Conclusion.
Related work
The scientific community interest in sentiment analysis is increasing because it facilitates decision-making for a variety of applications that rely on community opinion. As a result, previous studies various automated techniques for sentiment analysis 7. In investigated customized methods to identify constructs such as dominant behavior in electronic chats have and have demonstrated the potential to enhance analysis by expediting automated sentiment categorization utilizing NLP techniques 8. Covid-19 microblog texts can be analyzed in many ways, such as topics, market liquidity, events, and terms. Basiri et al.9 study investigated how Twitter users in eight countries felt about Covid-19. This work also has a new Covid-19 Twitter dataset that has taken over four months. Chakraborty et al.10 suggested a connection between people infected with Covid-19 and how many people died from Covid-19.
Recent research on Covid-19 has concentrated on the automatic recognition of tweets. Prabhakar et al.21 conducted a Covid-19 feature selection study that generated the frequently used tag used in Covid-19 tweets. Additionally also used the sentiment lexicon to determine the sentiments. In the work of22 ascertain the social and economic patterns associated with the Covid-19 outbreak in Pakistan. Huang et al.23 studied a total of 53k tweets from Saudi residents about Covid-19 and discovered that positive tweets outnumber negative tweets for nearly all of the metrics. They discovered that the processes associated with religious activity elicited the highest positive sentiment. They discovered that Saudi Twitter users support infection control efforts in the fight against Covid-19, and that this positive attitude among Saudi people contributes to the Saudi government overall trust. According to them, religious beliefs may be critical in preparing believers for pandemics. They gathered several tweets about the Saudi government various actions. After the news of the Grand Mosque’s closure, they analyzed 9924 tweets and discovered that 76.72% of them were positive. They also gathered tweets for the university closures, shopping mall, park, and restaurant closures, sports competition suspension hashtags, congregational and lastly, nationwide curfew restrictions. Depoux et al. 24 has shown that panic caused by people posting on social media spreads quicker than Covid-19. As a result, specialists and relevant authorities must notice and act to such rumors, attitudes, and public conduct as quickly as feasible25.
Users recalling side effects and starting to recollecting their previous infection with Covid-19 have been classified into various categories. The users could not be tested to confirm their concerns26. Because previous epidemics have been more modest, a recent investigation discovered a few studies that employed sentiment analysis to detect the presence of pandemics. Studies that assist authorities in appreciating human behavior may aid authorities in managing a crisis. Nowadays, social media is a primary source of news, and study that helps us understand human behavior may aid authorities in resolving a crisis Covid-19 27. Rao et al.28 developed a method for doing efficient personnel screening, traveling history and general manifestations. The data acquired thus far may aid in initial screening and early detection of people who are Covid-19 positive. Data sets can be collected and enhanced using an artificial intelligence model, which can then be used to assess and categorize individuals who may be coronavirus positive 29.
Text categorization is a prominent field of research in NLP since it involves associating a given text sequence with predetermined categories. Numerous prior research has used government neural network models, and convolution neural network (CNN) model, to learn text presentation for categorization30. Recurrent neural network (RNN) and attention models outperform alternative statistical methods. Pre-trained word vectors across an extensive unsupervised document collection are frequently used as features of sequences in these studies, which are frequently trained using the word2vec 31 or the GloVe technique 32, which is based on the idea that words with similar meanings appear in similar contexts. So classifying the collection twitter data as per literature and statistics abound, and maintaining data up to date is challenging. In the work of33 integrates active learning into a system for sentiment analysis that also combines the most popular collectable methodologies. Souri et al.34,35 examined a user relationship management strategy in terms of the relationship between human behavior and social systems. The presented work in a formal framework that integrates the behavioral demonstrating method. Pashazadeh et al.36 systematic examined of the state-of-the-art mechanisms behind big data in healthcare applications.
Deep learning algorithms play an essential role in analyzing and predicting large epidemic data patterns and the early detection and exploitation of coronavirus outbreaks37. To evaluate the predictions with a positive, and negative opinion, the gated RNN and LSTM have presented the gated recurrent neural network 38. Deep learning has improved the performance of neural network architectures such as RNN, LSTM, and CNN 39 in solving a variety of NLP tasks such as text categorization, language processing, and machine translation 40. Text categorization, language modeling, machine translation, and other NLP activities are all sequence modeling challenges. Traditional machine learning methods and neural networks cannot grasp the text’s sequential information. A researcher began to employ RNN and LSTM due to their ability to model sequential data present in the text. In41 contributed attempting to address this issue by developing a sentiment-aware lexicon using data from many domains.
The lack of large labeled text datasets could be one of the fundamental causes for this poor progress. The majority of labeled text datasets are insufficient for training deep neural networks, as these networks contain many parameters, and training them on short datasets will result in overfitting 42. A deep learning model like this is referred to as a pre-trained model 43. As a result, rather than constructing a model from scratch, it is preferable to use a pre-trained model as a starting point to address a problem 44. One significant issue is that RNN cannot be parallelized because they only accept one input at a time. In the instance of a text sequence, an RNN or LSTM would take one token at a time as input.
Recently, despite the fact that BERT has produced some incredible results in various NLP applications and clearly surpasses most feature-based representation approaches 45, such as word2vec, GloVe full potential has yet to be realized 46. Additionally, the most common and best-performing solutions are more complicated language models. The Spatio-temporal model 47 is used to illustrate the dengue survival mechanism. The model is based on linear regression and is used to make predictions using tweet datasets. In the work 48 of provides a concise overview of how NLP is beneficial for Twitter data analytics, used in research and public health analysis. Additionally, it has aided in deciphering social networks, public health messages, and the propagation of forecasts 49. Previous studies have demonstrated that pandemics and disease outbreaks can be contained if relevant experts consider publicly available data 50. Additionally, tracking twitter data has been used to study prior epidemics, do crisis situational analysis, and conduct tracking 51.
The strength of BERT is that the same pretrained model can be utilized in a variety of applications with excellent outcomes by simply adding one additional output layer. This means that it is capable of extracting critical information from input text that can be used to address a range of problems. Given that the model architecture is identical to that of the transformer encoder, we will concentrate on how it is trained and used for various purposes. BERT corpus is built of the Books Corpus(800 million words) and the English Wikipedia(2,500 M words). BERT comes in various flavors, including BioBERT 52, sciBERT 53, and others trained on domain-specific corpora. Pretraining model with such a large volume of material, it may learn the English language and develop the ability to extract meaningful information from the text to handle a variety of problems.
Proposed method
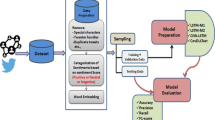
The proposed Bi-LSTM-BERT Ensemble approach consists of two stages. In the first stage, the BERT model gains the domain knowledge with Covid-19 data and fine-tunes Sentiment140 dataset. The second stage is the Bi-LSTM model, which is used to process the data in a bi-directional way to process the data to classify the sentiment. Finally, the ensemble model combines both models to classify the sentiment category into positive and negative categories. The goal of the approach is to categorize user opinions of tweets into two categories: positive sentiment or negative sentiment. It also analyzes opinions expressed in terms of various aspects at different times. The proposed method workflow is shown in Fig. 1.

The architecture of BERT-Bi-LSTM Ensemble model for opinion analysis.
Task definition
Suppose Tweet contain sentence S and sequence of word w in sentence such as \(S = [w_1, w_2,\dots ,w_n ]\) having ’n’ words and several aspect as mentioned in Table 3. The objective of the proposed work is to classify sentiment into positive and negative categories. For example, “Together, we can win the battle against COVID-19.” which is supposed to produce positive outputs. In the second case “Bullshit !! Our country is the worst in the world for the pandemic because of you, not China. Stop blaming everyone else & trying to defect blame. The state of our country is your fault & yours alone. RESIGN” which shows negative intent. In third case “maybe being stupid is a pre-existing condition that makes you susceptible to the corona virus?” which shows negative intent. In the fourth case “Covid-19 is everyone’s fight. I have covered major disasters, but nothing like this before” which shows negative intent. For better understanding, we have given some examples in Table 2.
Data collection
The data collection stage consists of English-language Twitter post (tweets) shared by users between 1st March, 2021 to 1st January, 2022. We used the keyword (top frequent hashtag) search tagging word, phrase mentioned in Table 3. The Twitter standard search API returns specific tweet properties for each tweet, including the tweet unique identified user ID, the tweet time and content, and geo-graphic coordinates location (including latitude and longitude) denoting the tweet’s boundary ( https://developer.twitter.com/en/docs/twitter-api/v1/tweets/filter-realtime). Twitter does not identify the precise location from which tweets were sent in-country for privacy concerns. In our data, all the tweets are collected in India (https://twitter.com). We crawled tweets from the Twitter platform, including Covid-19 related top frequent associated tags with tweets. Our study covered several issues, including covid-19, lockdown, vaccination, health, quarantine, safety, policy, and guidelines. Finally, we have combined all the datasets to analyze the public perception corresponding to associated tags to classify them into positive and negative category. The data set (tweets) has been obtained using Tweepy, an official Python Twitter API library, and the data set (tweets) has been obtained (https://github.com/MayurWankhade/Sentiment-Classification-Task). The selection criteria are based on the tweet are based on the associated tag as mentioned in Table 3.
Data preprocessing
Data preprocessing is one of the most effective ways to extract stated emotions from unstructured texts by converting the information into a structured manner. We performed the data preprocessing task to remove irrelevant data in tweets required for effective categorization; it is necessary to remove unnecessary data to reduce the dimension of data which is helpful to improve the model performance. The Python library package has been used to collect geographic location tweets for the key tagging phrases and timing period. Only English tweets are considered for further data analysis. The data collected from tweets are cleaned, removing the unnecessary symbols commonly included in tweets. The “re” python package cleans symbols like # , @, URL, RT, number values, and punctuation marks. Finally, data is stored in a structured format and removes irrelevant and duplicate rows of similar tweets. The preprocessing stage includes remove the stop-words, URL, # and number also consider replacing negation mentioned and repeated character removal, which effectively improves sentiment classification accuracy. The statistics of collected data are shown in Table 4.
BERT-Bi-LSTM ensemble model
The proposed approach consists of two stages. In the first stage, the BERT model which is used to gains the domain knowledge of Covid-19 data and fine-tunes with Sentiment140 dataset. Because Covid-19 dataset most of the words are new to understands for machine so to gain the domain specific knowledge BERT model used in approach. The second stage is the Bi-LSTM model, which is used to process the data in a bi-directional way to process the data to classify the sentiment.
The proposed BERT-Bi-LSTM Ensemble model has used to classify the public opinion into positive and negative category. Sentiment analysis is one of the most effective ways to analyze user opinion. To make opinion sense of the massive tweets shared on Twitter platforms at various times. The sentiment characteristics of text are determined by the sentiment polarities of its many aspects, such as positive and negative intent words and emoticons. Sentiment features consist of positive and negative intent words or phrases. Additionally, we consulted sentiment strength when developing our vocabulary of emotional terms, but we are currently extending our own (https://github.com/MayurWankhade/Sentiment-Classification-Task). The emoticons features are positive, negative, and neutral. Features relating to hashtags include the total number of positive and negative hashtags. The number of positive and negative slang terms is one of the characteristics of slang words.
BERT domain knowledge adoption
We present the BERT attention mechanism contains two essential modules: the Covid-19 domain attention and sentiment modules. The domain attention mechanism module gains the domain representation invokes an domain-related features. BERT is intended to pre-train deep bidirectional representations from an unlabeled text by simultaneously conditioning both the left and right contexts. As a result, by adding a single additional output layer to the pre-trained BERT model, for a wide variety of NLP applications can be generated 54. Bidirectional means that the NLP BERT framework acquires knowledge about a word’s in bi-directional way. After pre-processing data training step, acquiring data train from the BERT model and output of BERT passes to Bi-LSTM model. To simulate the logarithm of probabilities, we employ a fully connected linear layer.
The ith element of \(L_p\) is the log-likelihood of the ith tag, indicate the word embedding. Input of sequence taken as \(X = (x_1,x_2,\ldots ,x_n)\) and the output label obtained with fine tune BERT as \(Y = (y_1,y_2,\ldots ,y_n)\). We obtain the predicated tags by selecting the tag with the highest probability from a sequence of word embedding.
A softmax all-inclusive conceivable tag sequence produces the following probability for the sequence y:
We enhanced the log-probability of the proper tag sequence during training:
where \(Y_X\) denotes all possible unique tag sequences for phrase X. During decoding, we forecast the output sequence with the highest score given by
Twitter data does not include a sentiment label, so it is challenging to train the model. In the proposed model for data training and fine-tuning performed with Stanford Sentiment140 dataset 55 to solve the unlabeled data issue, sentiment140 data consist of 1600 million tweets with positive and negative sentiment labels. We randomly picked 75% of the tweets used for training the models and 25% for validation during the testing process.
Reason for selecting BERT model: BERT can produce multiple words embedding for a single word, each of which reflects the context of the word as it appears in a sentence. Transformer fundamental idea has been to integrate the benefits of CNN and RNN in a unique design based on the attention mechanism. Transformer architecture provides parallelism by paying attention to the recurrence sequence and simultaneously encoding the position of each item in the sequence. As a result, a compatible model with a significantly reduced training time is obtained.
Bi-LSTM attention mechanism
LSTM 56, has been utilized as a more advanced form to overcome RNN limitations by introducing hidden layer units known as memory cells. Memory cells are self-contained units that store the temporal network state and are controlled by input, output and forget gates. The input gate function regulates the flow of memory cell input and output gate into the remainder of the network. The activation level determines the information stored in memory. If the input unit has a high activation level, the information is stored in a memory cell. Additionally, if the output unit has a high activation level, it will transmit information to the next neuron. Else, high-weighted input data is stored in a memory cell. Bi-LSTM attention mechanism consists of forward and backward steps which used to identify the true meaning of the sentence. The forward step notations are the activation vectors of \(i_t\) denote input gate as per Eq. (6), \(f_t\) denote forget gate as per Eq. (7), \(c_t\) denote output gate as per Eq. (8), and \(c_t\) denote cell gate as per Eq. (9), and \(\sigma\) is the sigmoid function. We use LSTM networks layers, which are utilized in sequence labeling tasks and produce significant results. We use the following method of implementation:
The backward step notations are the activation vectors of \(\tilde{i_t}\) denote input gate as per Eq. (11), \(\tilde{f_t}\) denote forget gate as per Eq. (12), \(\tilde{o_t}\) denote output gate as per Eq. (13), and \(\tilde{c_t}\) denote cell gate as per Eq. (14), and \(\sigma\) is the sigmoid function.
Where, W indicate the weight matrices, b indicate bias vector parameters, \(x_t\) indicate the input variable at time t, \(h_{t-1}\) is the hidden state of the layer at time \(t-1\), \(h_t\) is the hidden state at time t, \(c_t\) is the cell state at time t. We have adopted Bi-LSTM attention mechanism from57 and ensemble model construct the domain representation using a Bi-LSTM network in the domain attention mechanism module. The \(f_{Bi-LSTM}(\dot{)}\) used to represent the word embedding process, we can formulate this process as
Where, \(wv_i\) represents the word vector for the \(i{th}\) word in the sentence. Specifically, \(h_d\) is the sum of the outputs of a forward LSTM network as per Eq. (10) and a backward LSTM network as per Eq. (15) as follows
Where as \(\oplus\) indicate the concatenation and function \(f_{Bi-LSTM}()\) transform the text embedding. The domain knowledge representation is fed into softmax classifier to gain the domain information.
Where \(W^{attention}\) and \(b^{attention}\) are parameters for attention. Then, all attention weights are fed into a softmax layer to generate probabilistic attention weights. The last stage representation for classification tasks \(h^{s}\) is the weighted combination of all memory formation which is,
The weighted vector \(h_{s}\) can be viewed as a hidden layer of a text for sentiment classification and fully-connected layer and a softmax layer in predicting the sentiment labels of texts. As per Eqs. (21) and (19) mapping between the acquired hidden layer and its sentiment label and s is the predicted sentiment label.
Result analysis
The experiments are executed using NVIDIA Tesla V100 SXM3 32 GB GPU. The hyper-parameter setting as follows dimensions of hidden size BiLSTM is = 300, dropout rate = 0.2, learning parameter = 0.001, regularization weight = 0.001, activation function as sigmoid, BERT model parameter are consists of: number of layers = 12, hidden size h = 768, self-attention heads A = 12, total parameters= 110M. We have validated the model by modifying several hyper parameters and provided the optimal result. We have manually checked parameters that are perfectly suited to the proposed method. We have performed the ten cross-validation (CV) and average accuracy results considered in the proposed work.
The proposed BERT-Bi-LSTM ensemble method analyzes public opinion and categorizes it into positive and negative categories to find out the overall sentiment. We examined how country-specific(India) community opinions around the Covid-19 epidemic are evolving. A massive amount of public opinion analysis plays an essential role in measuring sentiment for government to make specific decisions. We extracted public opinion from Twitter posts at the country level(India) at different times in order to analyze how public opinion of the pandemic has evolved. The proposed method classified each tweet’s valence (positive or negative) based on its textual information emotion intensity. Additionally, a key aspect related to the Covid-19 is classified as aggregated sentiment across tweets. The distribution of opinions is found in Fig. 2 shows inconsistency across period (1st March, 2021 to 1st January, 2022) in the country (Fig. 3).
This paper presents a novel BERT-Bi-LSTM ensemble approach for sentiment analysis. In our work, we have used the CuDNN package to accelerate GPU computation. The computational time for the proposed BERT-BiLSTM ensemble approach for training the data has taken 11.73 s, whereas testing the data has taken 03.77 s. At the same time, to fine-tune domain knowledge, BERT has taken 6.07 s to gain sentiment domain information. The proposed method result analysis compare with baseline machine learning and deep learning method in Table 5.
In the proposed model, several variations of the result shown in Table 6 indicate the impact of each stage on classifying the sentiment. Since the Covid-19 dataset, most words are unique, and it is not used to classify sentiment. To solve these challenges in the proposed work, we have used the sentiment140 dataset to gain domain knowledge for finding categories. Also, we found that the result obtained after adding sentiment dictionary positive and negative features to the sentiment fine-tune (SFT) BERT model improved the classification accuracy. Table 5 experiment results show the impact of dictionaries in classification; the F1 score rises to 86.13% (compared to 73.48%). Adding sentiment features can also significantly boost performance. When the Bi-LSTM model with hidden layer attention embedding is used for sentiment features, the F1 score can rise to 86.13%, respectively (compared to 75.14% ). Furthermore, when dictionary and emotion characteristics are combined, the model yields an F1 score of 86.13% and 85.78% for positive and negative categories. Also, the most common aspects discussed during the pandemic and overall public opinion are shown in Table 7.

The overall public opinion discussed during Covid-19 pandemic condition month-wise result analysis.

Graphical visualization of Covid-19 cases, the report contains a record of new case, new taste case, positive rate, reproduction rate, and over the period.
The results indicate in Fig. 6 shows the average strength of negative feelings reduced, and the intensity of positive sentiments grew between the beginning of the pandemic and the prospect of the country’s reopening. The various phase of data collecting occurred during an era of unequal lockdown measures, resulting in high scores for negative emotions and low values for pleasant emotions. The most challenging aspect discussed during the pandemic period, and the sentiment classification performance of various aspects are shown in Table 5.
Figure 3 shows the Covid-19 cases, the report contains a record of a new case, new taste case, positive rate, reproduction rate, and over the period. The proposed method result comparison shown in Fig. 4 indicate that result obtained are consistent for real-time public opinion analysis over a period. Depending on Covid-19 cases over the period and public opinion impact based on that time, Fig. 7 shows that public opinions are getting changed as per the covid-19 situation in the country (https://ourworldindata.org/covid-cases). It depends on the Covid-19 situation in the country. How the people lockdown aspect gets change over time are shown in Fig. 5. The people get affected due to Covid-19, new confirmed Covid-19 cases reported, and death cases reported over the period in India are shown in Fig. 9, whereas 1M indicates per million.

The proposed method comparative result analysis monthly reported during pandemic a period.

Overall public sentiment classification on various aspects discussed during the pandemic period.
The public opinion on Covid-19 as per the vaccination-related tag mentioned in Table 3 over Twitter indicates most users positive opinions and graphical visualization over the period shown in Fig. 6. The impact of vaccination indicates positive things towards public safety (Fig. 7). Figure 8 shows the number of people vaccinated reported over the period in India (https://www.mohfw.gov.in). The number of new cases reported and death cases reported over time in India is shown in Fig. 9.

Public opinion analysis on vaccination discussed during the pandemic period.

Public opinion analysis on lowdown discussed during the pandemic period.

The number of people vaccinated reported over the period of time.

The ratio of new confirmed Covid-19 cases reported and death cases reported over the period.
For comparison, we employed the Bag of Words (BoW)58 and N-gram models59 Word2Vec and GloVe with various classifiers Naive bayes, Support vector machine, Random forest, and Logistic regression. Also, we have used a deep learning approach as LSTM and Bi-LSTM. Compared to the traditional machine learning approach, the deep learning approach demonstrated superior performance for the Covid-19 dataset; compared to baseline methods the proposed approach showed significantly superior performance due to its ability to capture out-of-vocabulary words effectively. The comparative result analysis shown in Table 5.
Additionally, we perform in-depth social sentiment research via public opinion to ascertain the general population’s feelings. The most emerging topic identified by the top frequently mentioned in Fig. 10 is most commonly discussed during the pandemic. Also, most aspects discussed during the pandemic and overall public opinion are shown in Fig. 5. We found that negative opinion dominates public sentiment regarding these critical Covid-19 occurrences, a consistent pattern across countries. This can help governments and organizations learn more about their involvement with this disease to develop a better decision-making policy to help their citizens.

Top frequently used words which are most commonly discussed during the pandemic period.
Discussion
The proposed work classifies the sentiment into positive and negative categories, which is helpful for the decision-making system. Our findings are based on the opinions or feelings of people in India discussed on Twitter social media platform about Covid-19 related subjects. Twitter is an incredibly powerful and efficient platform for communicating the efficacy of the public is shown. Real-time epidemiological data is necessary for self-reporting capabilities and rapid assessment of pandemic scenarios. The Covid-19 dataset has vast scales of unavailable training data are due to the time and human resources required for manual labeling of training data. It is not possible to label such tremendous data. In the proposed approach data training and fine-tuning performed with stanford sentiment140 dataset to solve the unlabeled data issue.
The proposed approach to investigating content related to Covid-19 reveals that Twitter may be efficiently used to identify individual-level responses to infectious disease outbreaks. At the same time, it considers the effects of local socioeconomic resources and illness prevalence. Additionally, it established a socioeconomic difference and reactions to the current Covid-19 outbreak even in the country where disease cases are the most severe. Also, it provides a comprehensive study of public sentiment, including the overall state of public emotions, the change in public sentiment over time, and the emotions expressed in response to specific occurs. The COVID-19 pandemic threatens the physical and mental health of millions. This article evaluated how feelings and emotions about the pandemic evolved over the period of time. The empowered ct of lockdown Stanford ination measures the hope of a return to normal with an effective vaccination effort and a decline in incidence.We analyze the variations in opinion under lockdown regulations. When comparing impact of lockdown measures with respective synthetic control, we find some evidence to support the widespread belief that lockdown policies have high emotional consequences. Also, some significant point are discuss below
-
Since the Covid-19 dataset, most of the words are unique does not include any sentiment label. To gain the domain knowledge and sentiment knowledge with sentiment140 corpus, which has extensive volume label data used to assign the label in our work. Sentiment fine-tuned BERT training on the Twitter Covid-19 dataset improves the performance of the proposed model.
-
Adding Bi-LSTM hidden attention layers on top of the BERT model improves the performance of the proposed method.
-
We use tweet locations to investigate the county-specific(data explicitly collected in India) geographic distributions of Covid-19 tweets.
-
We summarize and reveal the aspect addressed on Twitter by tagging based attention with proposed models.
Conclusion
We demonstrated the performance of the proposed model by comparing it with various versions of the BERT methods. We analyze social media, i.e., Twitter discourse regarding COVID-19, by utilizing information from tweets tagged with Covid-19 related topics and various challenges discussed during the pandemic, such as feelings, subjects, and emerging issues. We perform a real-time analysis of public opinion changes related to Covid-19. The proposed approach comprehension the changing nature of people’s opinions about the pandemic duration to be helpful for the government in making decisions. This study analysis of community-based pandemic reactions might reveal disparate discourses about social life such as mental health, daily routine, socio-economic disparity, and education. Such information can assist in initiatives such as public health crisis messaging and prioritizing the interests of the disproportionately affected people geographic.
Data availability
The datasets used analyzed during the current study are available from the corresponding author on reasonable request. The codes that were made or used in this study are eligible for inclusion author on reasonable request. Details information is available through requests from the authors.
References
Wankhade, M., Rao, A. C. S. & Kulkarni, C. A survey on sentiment analysis methods, applications, and challenges. Artif. Intell. Rev. 55, 1–50 (2022).
Esrock, S. L. & Leichty, G. B. Social responsibility and corporate web pages: Self-presentation or agenda-setting?. Public Relat. Rev. 24, 305–319 (1998).
Merchant, R. M. & Lurie, N. Social media and emergency preparedness in response to novel coronavirus. JAMA 323, 2011–2012 (2020).
Doulamis, N. D., Doulamis, A. D., Kokkinos, P. & Varvarigos, E. M. Event detection in twitter microblogging. IEEE Trans. Cybernet. 46, 2810–2824 (2015).
Atefeh, F. & Khreich, W. A survey of techniques for event detection in twitter. Comput. Intell. 31, 132–164 (2015).
Saeed, Z. et al. What’s happening around the world? a survey and framework on event detection techniques on twitter. J. Grid Comput. 17, 279–312 (2019).
Wankhade, M., Annavarapu, C. S. R. & Verma, M. K. CBVoSD: Context based vectors over sentiment domain ensemble model for review classification. J. Supercomput. 78, 1–37 (2021).
Feldman, R. Techniques and applications for sentiment analysis. Commun. ACM 56, 82–89 (2013).
Basiri, M. E., Nemati, S., Abdar, M., Asadi, S. & Acharrya, U. R. A novel fusion-based deep learning model for sentiment analysis of covid-19 tweets. Knowl. Based Syst. 228, 107242 (2021).
Chakraborty, K. et al. Sentiment analysis of covid-19 tweets by deep learning classifiers-a study to show how popularity is affecting accuracy in social media. Appl. Soft Comput. 97, 106754 (2020).
Barkur, G. & Vibha, G. B. K. Sentiment analysis of nationwide lockdown due to covid 19 outbreak: Evidence from india. Asian J. Psychiatry 51, 102089 (2020).
Samuel, J. et al. Covid-19 public sentiment insights and machine learning for tweets classification. Information 11, 314 (2020).
Hamzah, F.B. et al. Coronatracker: Worldwide covid-19 outbreak data analysis and prediction. Bull World Health Organ 1 (2020).
Abd-Alrazaq, A., Alhuwail, D., Househ, M., Hamdi, M. & Shah, Z. Top concerns of tweeters during the covid-19 pandemic: Infoveillance study. J. Med. Internet Res. 22, e19016 (2020).
Lwin, M. O. et al. Global sentiments surrounding the covid-19 pandemic on twitter: Analysis of twitter trends. JMIR Public Health Surveill. 6, e19447 (2020).
Raamkumar, A. S., Tan, S. G. & Wee, H. L. Measuring the outreach efforts of public health authorities and the public response on facebook during the covid-19 pandemic in early 2020: Cross-country comparison. J. Med. Internet Res. 22, e19334 (2020).
Liu, R. et al. Positive rate of RT-PCR detection of SARS-COV-2 infection in 4880 cases from one hospital in Wuhan, China, from Jan to Feb 2020. Clin. Chim. Acta 505, 172–175 (2020).
Satu, M. S. et al. TClustVID: A novel machine learning classification model to investigate topics and sentiment in covid-19 tweets. Knowledge-Based Syst. 226, 107126 (2021).
Wang, Y., Hao, H. & Platt, L. S. Examining risk and crisis communications of government agencies and stakeholders during early-stages of covid-19 on twitter. Comput. Hum. Behav. 114, 106568 (2021).
Su, Y., Venkat, A., Yadav, Y., Puglisi, L. B. & Fodeh, S. J. Twitter-based analysis reveals differential covid-19 concerns across areas with socioeconomic disparities. Comput. Biol. Med. 132, 104336 (2021).
Prabhakar Kaila, D., Prasad, D. A. et al. Informational flow on twitter–corona virus outbreak–topic modelling approach. Int. J. Adv. Res. Eng. Technol. (IJARET) 11 (2020).
Nasir, A., Shah, M. A., Ashraf, U., Khan, A. & Jeon, G. An intelligent framework to predict socioeconomic impacts of covid-19 and public sentiments. Comput. Electr. Eng. 96, 107526 (2021).
Huang, X., Li, Z., Jiang, Y., Li, X. & Porter, D. Twitter reveals human mobility dynamics during the covid-19 pandemic. PLoS ONE 15, e0241957 (2020).
Depoux, A. et al. The pandemic of social media panic travels faster than the covid-19 outbreak (2020).
Kumar, V. Spatiotemporal sentiment variation analysis of geotagged covid-19 tweets from India using a hybrid deep learning model. Sci. Rep. 12, 1–14 (2022).
Nguyen, D. N., Phan, T. T. & Do, P. Embedding knowledge on ontology into the corpus by topic to improve the performance of deep learning methods in sentiment analysis. Sci. Rep. 11, 1–18 (2021).
Alamoodi, A. et al. Sentiment analysis and its applications in fighting covid-19 and infectious diseases: A systematic review. Expert Syst. Appl. 167, 114155 (2020).
Rao, A. S. S. & Vazquez, J. A. Identification of covid-19 can be quicker through artificial intelligence framework using a mobile phone-based survey when cities and towns are under quarantine. Infect. Control Hosp. Epidemiol. 41, 826–830 (2020).
Lopez, C. E., Vasu, M. & Gallemore, C. Understanding the perception of covid-19 policies by mining a multilanguage twitter dataset. arXiv preprint arXiv:2003.10359 (2020).
Jain, P. K., Pamula, R. & Srivastava, G. A systematic literature review on machine learning applications for consumer sentiment analysis using online reviews. Comput. Sci. Rev. 41, 100413 (2021).
Goldberg, Y. & Levy, O. word2vec explained: Deriving mikolov et al.’s negative-sampling word-embedding method. arXiv preprint arXiv:1402.3722 (2014).
Pennington, J., Socher, R. & Manning, C. D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1532–1543 (2014).
Aldoğan, D. & Yaslan, Y. A comparison study on active learning integrated ensemble approaches in sentiment analysis. Comput. Electr. Eng. 57, 311–323 (2017).
Souri, A., Nourozi, M., Rahmani, A. M. & Navimipour, N. J. A model checking approach for user relationship management in the social network. Kybernetes 48, 407–423 (2019).
Souri, A. & Norouzi, M. A new probable decision making approach for verification of probabilistic real-time systems. In 2015 6th IEEE International Conference on Software Engineering and Service Science (ICSESS), 44–47 (IEEE, 2015).
Pashazadeh, A. & Navimipour, N. J. Big data handling mechanisms in the healthcare applications: A comprehensive and systematic literature review. J. Biomed. Inform. 82, 47–62 (2018).
Bandyopadhyay, S. K. & Dutta, S. Machine learning approach for confirmation of covid-19 cases: Positive, negative, death and release. medRxiv (2020).
Chimmula, V. K. R. & Zhang, L. Time series forecasting of Covid-19 transmission in Canada using LSTM networks. Chaos Solitons Fract. 135, 109864 (2020).
Zhou, J. & Xu, W. End-to-end learning of semantic role labeling using recurrent neural networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 1127–1137 (2015).
Giménez, M., Palanca, J. & Botti, V. Semantic-based padding in convolutional neural networks for improving the performance in natural language processing. A case of study in sentiment analysis. Neurocomputing 378, 315–323 (2020).
Jha, V., Savitha, R., Shenoy, P. D., Venugopal, K. & Sangaiah, A. K. A novel sentiment aware dictionary for multi-domain sentiment classification. Comput. Electr. Eng. 69, 585–597 (2018).
Gu, J. et al. Recent advances in convolutional neural networks. Pattern Recogn. 77, 354–377 (2018).
Beck, B. R., Shin, B., Choi, Y., Park, S. & Kang, K. Predicting commercially available antiviral drugs that may act on the novel coronavirus (SARS-COV-2) through a drug-target interaction deep learning model. Comput. Struct. Biotechnol. J. 18, 784–790 (2020).
Huh, M., Agrawal, P. & Efros, A. A. What makes imagenet good for transfer learning? arXiv preprint arXiv:1608.08614 (2016).
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
Zhang, T., Wu, F., Katiyar, A., Weinberger, K. Q. & Artzi, Y. Revisiting few-sample bert fine-tuning. arXiv preprint arXiv:2006.05987 (2020).
Gomide, J. et al. Dengue surveillance based on a computational model of spatio-temporal locality of twitter. In Proceedings of the 3rd International Web Science Conference, 1–8 (2011).
Kashyap, R. & Nahapetian, A. Tweet analysis for user health monitoring. In 2014 4th International Conference on Wireless Mobile Communication and Healthcare-Transforming Healthcare Through Innovations in Mobile and Wireless Technologies (MOBIHEALTH), 348–351 (IEEE, 2014).
Odlum, M. & Yoon, S. What can we learn about the Ebola outbreak from tweets?. Am. J. Infect. Control 43, 563–571 (2015).
Kim, E.H.-J., Jeong, Y. K., Kim, Y., Kang, K. Y. & Song, M. Topic-based content and sentiment analysis of Ebola virus on twitter and in the news. J. Inf. Sci. 42, 763–781 (2016).
Fung, I.C.-H. et al. Pedagogical demonstration of twitter data analysis: A case study of world aids day, 2014. Data 4, 84 (2019).
Lee, J. et al. Biobert: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 36, 1234–1240 (2020).
Beltagy, I., Lo, K. & Cohan, A. Scibert: A pretrained language model for scientific text. arXiv preprint arXiv:1903.10676 (2019).
Gao, Z., Feng, A., Song, X. & Wu, X. Target-dependent sentiment classification with Bert. IEEE Access 7, 154290–154299 (2019).
Friedrich, N., Bowman, T. D., Stock, W. G. & Haustein, S. Adapting sentiment analysis for tweets linking to scientific papers. arXiv preprint arXiv:1507.01967 (2015).
Greff, K., Srivastava, R. K., Koutník, J., Steunebrink, B. R. & Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 28, 2222–2232 (2016).
Li, W., Qi, F., Tang, M. & Yu, Z. Bidirectional LSTM with self-attention mechanism and multi-channel features for sentiment classification. Neurocomputing 387, 63–77 (2020).
HaCohen-Kerner, Y., Miller, D. & Yigal, Y. The influence of preprocessing on text classification using a bag-of-words representation. PLoS ONE 15, e0232525 (2020).
Bespalov, D., Bai, B., Qi, Y. & Shokoufandeh, A. Sentiment classification based on supervised latent n-gram analysis. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, 375–382 (2011).
Author information
Authors and Affiliations
Contributions
M.W.: Data curtion, Implementation, Conceptualization, Validation, Writing—original draft. A.C.S.R.: Review, Validation, Editing, Methodology, Conceptualization.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wankhade, M., Rao, A.C.S. Opinion analysis and aspect understanding during covid-19 pandemic using BERT-Bi-LSTM ensemble method. Sci Rep 12, 17095 (2022). https://doi.org/10.1038/s41598-022-21604-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-21604-7
- Springer Nature Limited
This article is cited by
-
CBMAFM: CNN-BiLSTM Multi-Attention Fusion Mechanism for sentiment classification
Multimedia Tools and Applications (2023)
-
MAPA BiLSTM-BERT: multi-aspects position aware attention for aspect level sentiment analysis
The Journal of Supercomputing (2023)
-
Sentiment analysis using deep learning techniques: a comprehensive review
International Journal of Multimedia Information Retrieval (2023)