
Abstract
The introduction of COVID-19 lockdown measures and an outlook on return to normality are demanding societal changes. Among the most pressing questions is how individuals adjust to the pandemic. This paper examines the emotional responses to the pandemic in a repeated-measures design. Data (n = 1698) were collected in April 2020 (during strict lockdown measures) and in April 2021 (when vaccination programmes gained traction). We asked participants to report their emotions and express these in text data. Statistical tests revealed an average trend towards better adjustment to the pandemic. However, clustering analyses suggested a more complex heterogeneous pattern with a well-coping and a resigning subgroup of participants. Linguistic computational analyses uncovered that topics and n-gram frequencies shifted towards attention to the vaccination programme and away from general worrying. Implications for public mental health efforts in identifying people at heightened risk are discussed. The dataset is made publicly available.
Similar content being viewed by others

Introduction
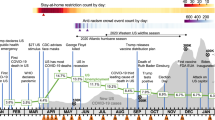
The COVID-19 pandemic has been dominating people’s lives for far more than a year now. Despite the success of ongoing vaccination programmes in various countries, lockdown and social distancing measures remain in place around the world. In the United Kingdom, however, at the time of writing this paper, society is increasingly opening up, and residents can visit shops, bars and restaurants and cultural and entertainment venues (e.g., museums, sports stadiums and cinemas) are welcoming visitors again1.
The impact of the pandemic on people’s lives has been studied widely by researchers in the last year, and the natural language processing (NLP) research community has focussed on linguistic phenomena related to the pandemic in a range of studies2,3,4. In April 2020, shortly after the start of the SARS-CoV-2 outbreak and the COVID-19 pandemic, the COVID-19 Real World Worry Dataset (RWWD; Kleinberg et al.5) was presented—a dataset of 5,000 long and short texts in which participants expressed their feelings about the pandemic. The text data were accompanied by 9-point-scale ratings for a set of nine emotional variables (e.g., anger, anxiety, happiness, sadness and worry) and aids in understanding the impact of the pandemic on people’s mental wellbeing and the nexus between emotion and text expression.
The study found that participants reported predominantly negative emotions such as anxiety, worry, sadness and fear. Furthermore, using the text data to understand the participants' concerns and emotional responses, topic modelling methods uncovered that people were mainly writing about worries related to family, friends, employment, and the economy. A different study further showed that the text data reveal gender differences in the concerns and worries of people6. The dataset has since been used to understand emotional responses to COVID-19 through the lens of text data (e.g., Çakar and Sengur7).
The original RWWD dataset was collected when the UK was hit hard by COVID-19, and residents were instructed to stay at home and leave their houses only for essential purposes. Large parts of the economy, including the hospitality and retail sectors, were completely locked down at that time8. In the current paper, we follow up on the work by Kleinberg et al.5, presenting a new corpus of text data related to the COVID-19 pandemic, written by the same participants one year after the original data collection. We asked the participants to again write about their feelings concerning the pandemic and provide the same emotional measures. Using this unique within-subjects corpus, we assess to what extent people's emotions changed as society is slowly opening up and ongoing vaccination programmes are paving the way to an eventual return to normality. Specifically, we conduct statistical comparisons between emotion scores from both phases and assess individual differences based on topic modelling approaches and word frequency comparisons between texts of both data collection phases. Using clustering analyses, we also test for potential subgroups of participants with respect to emotion change.
Our findings show that, compared to the first phase, the participants demonstrate stronger positive emotional responses in the second phase (e.g., happiness and relaxation) and score lower on negative ones (e.g., fear and anxiety). Data clustering algorithms, however, suggest that this pattern is far from homogenous. Two cluster groups are identified based on the emotion change scores, a well-coping and a resignation cluster. n-gram frequency analysis and topic modelling indicate that text data reveal a focus shift from the first to the second phase.
Text-based analyses around COVID-19
Since the emergence of COVID-19, numerous studies have examined the effect of the pandemic. Various behavioural research efforts have used text-based analyses concerning COVID-199,10,11. A large number of studies made use of Twitter data to perform textual analyses. Examples include the spread of misinformation on Twitter12,13, emotional consequences of lockdowns studied through Twitter and Weibo data14, as well as the association between US partisanship and sentiment towards COVID-19 measures15. Other text data sources include Reddit, which has, for example, been used to characterise the linguistic difference between posters on the r/Coronavirus and the r/China_flu page16. Based on word frequency measures, the language difference between the two subreddits was low in January and February of 2020, but diverged for the rest of the year, indicating the emergence of two distinct communities characterised by their attitude towards the virus. In another study of Reddit data, linguistic features including the Linguistic Inquiry and Word Count software (LIWC; Pennebaker et al.17), sentiment analysis, and word frequencies were used to study changes in mental health discourse across 15 subreddits18. All in all, the studies above demonstrate how the availability of text data on social media platforms enables researchers to study the effects of COVID-19 on a large scale.
Previous research has also specifically examined emotional responses to the COVID-19 crisis. Using 122M tweets posted throughout 2020,19 propose that the psycho-social response to the pandemic occurs in three phases. Following Strong’s 1990 model of the sociological reaction to fatal epidemics, refusal is followed by anger, which in turn is followed by acceptance. The authors made use of keywords from the original Strong (1990) paper, the LIWC, and lexicons for emotions, moral foundations, and pro-social behaviour to examine the occurrence of the three phases in the Twitter data. Aiello et al. (2021) note that refusal and acceptance decreased throughout 2020, whereas acceptance increased. When new waves of COVID-cases emerged, new waves of anger were observed in the language use on Twitter. In a similar endeavour,20 examined social discourse within tweets from Italy straight after the first lockdown in March 2020. Tweets were collected by searching three hashtags related to the lockdown, after which networks of hashtags were constructed by examining co-occurrences of hashtags in tweets. The tweets were subsequently analysed for their sentiment polarity using the NRC lexicon. By exploring the emotional valence in the identified hashtag networks, the authors note that they observed co-existence of anger and fear with trust, solidarity and hope in the corpus. Emotional responses to the pandemic have also been examined by other means than text data, for instance in an exploration of the emotional appreciation of humour (memes, jokes) related to COVID-1921. In an online survey in April 2020, different clusters of emotional responses were identified (e.g., optimists and pessimists) which were found to be related to several variables such as gender, pre-existing health conditions, and political orientation22. In related research using an online task, participants who scored high on COVID-19 fear and negative emotion also judged words relating to COVID-19 more negatively23.
These studies are united by using text data as a proxy for real-life behaviour or attitudes. Among the many potentials of text data is the possibility to use observational data—often produced as a by-product of human online behaviour (e.g., participation in online forums, see Salganik24)—as the lens through which we study human emotions, attitudes and behaviour. At the same time, pure observational text data often lack ground truth in the form of known emotional states, attitudes or even behaviours. The current study addresses the ground truth problem by collecting primary data in a one-year lagged within-subjects design, thereby extending the research questions.
Aims of this paper
This paper makes two key contributions. First, we present and make available a within-subjects follow-up dataset for the RWWD, comprising people's emotional responses to the COVID-19 pandemic and corresponding text data at two moments in time. Doing so helps us study the phenomenon in a longitudinal sense and may allow us to pose new research questions beyond observational snapshot studies. Second, this paper seeks to shed further light on the emotional responses to the Coronavirus pandemic. Specifically, we are interested in the change that happened and consequently may have led to different emotional responses between the onset of the pandemic and a year later when the UK was about to open up the country again. We aim to answer two questions: (1) How did people's emotional responses change one year after the pandemic? (2) How can text data help us understand the change in emotional responses?
By connecting textual responses to emotional states, we specifically aim to explore how emotions are reflected in human language use. Such an investigation might help us exploit potential relationships between these two modalities, and to obtain insights into emotional states solely based on human language data. Our findings could provide helpful insights for healthcare professionals and policy makers in tackling mental health issues as a consequence of the COVID-19 pandemic.
Method
Data availability statement
The data collected for and used in this paper are publicly available at https://osf.io/7hpjq/.
Ethics statement
The study has been reviewed and approved by the IRB of University College London. All participants were informed about the purpose and procedure of the study and provided informed consent and were over the age of 18. All methods were performed in accordance with the guidelines of the Declaration of Helsinki.
Data collection
Our data consisted of repeated measures of the same sample at two different points in time (phase 1 and phase 2, respectively). Data from phase 1 were collected in April 20205 and consisted of n1 = 2491 participants who each reported their emotions about the Coronavirus pandemic and expressed in text form how they felt. We contacted each participant who contributed to the first phase via the crowdsourcing platform Prolific Academic and notified them of a new data collection precisely one year after the original study. We used the identical questionnaire, task interface (with Qualtrics software), participant payment and exclusion criteria. The second phase of data collection ran from March to April 2021.
The initial sample of phase 2 consisted of n2 = 1839. After applying the following exclusion criteria, we retained n = 1716 participants: participants who did not write an English text (n = 67), wrote more than 20% punctuation (n = 6), did not input a valid Prolific id (n = 33, e.g., due to a typo) or were duplicates in the data (n = 17) were excluded. We then merged the two data collection phases: n = 18 participants who completed phase 2 were not in the final dataset from phase 1 (we reached out to all participants who participated in phase 1—but did not necessarily complete the task or end up in the final dataset, e.g. due to timing out in the data collection task of phase 1 or due to being excluded from the dataset in phase 1 due to more than 20% punctuation). The full final sample consisted of n = 1698 participants who provided complete data for both data collection phases. Of that sample, 67.37% were female, 31.33% male, and 1.30% did not provide gender information. The mean age was 36.22 years (SD = 11.66) with a range from 18 to 83 (an outlier with an age of 961 was excluded from the age calculation but retained for all other analyses). All participants were UK residents with 88.40% being born in the UK. The majority were in full-time (55.83%) or part-time employment (22.08%). 10.54% of the sample were not in paid work (e.g., retired or homemaker) and 7.53% were unemployed. Being an active student (regardless of employment) applied to 17.90% of the sample.
Context of data collection
Data for phase 1 of this study were collected during the beginning of lockdown in the UK (April 2020), where death tolls attributable to the virus were steadily increasing. At that time, Queen Elizabeth II has just addressed the nation via a television broadcast, and Prime Minister Boris Johnson was admitted to intensive care in a hospital for COVID-19 symptoms25. One year later, in phase 2 of this study (March–April 2021), many UK residents had been vaccinated, and schools, retail and the hospitality sectors were (partially) re-opened. Reports of the newly identified delta-variant of the Coronavirus just started to emerge at this time.
Emotion data
Each participant was asked how they felt about the Coronavirus pandemic at the moment of data collection for each of eight emotions and emotional states (anger, anxiety, desire, disgust, fear, happiness, relaxation, sadness; Harmon-Jones et al.26) and worry. They indicated their emotions for each on a 9-point Likert scale (1 = very low, 5 = moderate, 9 = very high). In addition, they were asked to pick which of the eight emotions best described their feeling if they had to choose just one.
Text data
After the participants self-reported their emotions, we asked them to express how they felt at that moment about the COVID-19 situation in text form. Their task was to write one long text of at least 500 characters and a shorter one that expresses their feeling in Tweet length (max. 280 characters). Table 1 shows verbatim excerpts of one participant for both phases and text lengths.
Additional variables
We also asked participants how well they thought they were able to express their feelings in text (in general, the short text and in the long text) and how often they use Twitter (specifically: being on Twitter, responding to Tweets and tweeting themselves). Each variable was measured on a 9-point Likert scale (these data are available in the full dataset and are not analysed here). A comprehensive range of sociodemographic variables is collected by default through the crowdsourcing platform Prolific but not further examined here, yet available in the shared dataset.
Analysis plan
We assess our key research questions as follows. To test how emotional responses changed, we conduct within-subjects t-tests and report the corresponding Cohen’s d effect size with confidence intervals and the Bayes Factor. The d effect size expresses the absolute magnitude of an effect with values of 0.2, 0.5 and 0.8 representing small, moderate and large effects, respectively27. The Bayes Factor (BF) is derived from the Bayesian within-subjects t-test28 by testing how likely the data are under two competing hypotheses (here: the null hypothesis of no difference vs. a two-sided alternative hypothesis). We used the bayesfactor R package29 with default, non-informative settings for the prior distribution (i.e., a Cauchy prior on the effect size with a scale parameter of \(\sqrt 2 /2\), for details see30. That prior was chosen because of its desirable properties for the current context (i.e., changes in emotional responses within-subjects after a year in a pandemic), which include a high prior probability density around zero, a symmetrical spread of the prior probability to positive and negative effect sizes (i.e., reflecting the two-sided alternative hypothesis), and its “small influence on the posterior distribution, such that most of the diagnosticity comes from the likelihood of the data”30. A BF = 1.00 implies that both are equally probable. BFs larger than 10 and 100 can be regarded as strong and extreme evidence in favour of the alternative hypothesis, respectively31. We also report the Pearson correlation between the two measurements.
In addition to the statistical comparisons, we furthermore examined whether the change in emotions is homogenous across the sample. We do this with k-means clustering.
The text data are analysed in three different ways, each allowing us to understand the content in a different manner. (1) We used the LIWC to measure differences between phase 1 and phase 2 in psycholinguistic categories (e.g., personal concerns, time references). The LIWC employs a dictionary-based approach that counts how many predefined words occur in each text. All LIWC categories were tested in a data-driven exploratory manner. (2) Structural topic modelling was used to identify co-occurrences of words that may form latent topics. We tested how topics changed between the two data collection moments. (3) We used n-gram frequency analysis to test which (sequences of) words differentiated the most between phase 1 and phase 2. That approach may inform us about how foci of the texts shifted.
Results
Change in emotions
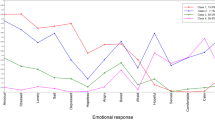
Table 2 shows that there is a substantial decrease in anxiety (d = 0.55 [0.48; 0.62]), fear (d = 0.75 [0.68; 0.82]) and worry (d = 0.86 [0.78; 0.93]). There were small-to-moderate increases in desire (d = 0.30 0.24; 0.36]), happiness (d = 0.32 [0.26; 0.38]) and relaxation (d = 0.26 [0.19; 0.32]). Marginal-to-small effects were observed for a decrease in anger (d = 0.10 [0.04; 0.17]) and disgust (d = 0.10 [0.04; 0.17]). Overall, these findings suggest that the participants experienced considerably fewer negative emotions and somewhat more positive emotions. Anger and disgust remained rather stable. The correlations between the phase 1 and phase 2 scores ranged from r = 0.34 to r = 0.50.
Clustering of emotion change
The findings from Table 2 show the aggregated mean change for the whole sample, but this may obscure individual differences. To examine whether potential subgroups exist within the sample, we applied k-means clustering on the nine emotion change scores (phase 2–phase 1).
The k-means method used Euclidean distance on the nine-dimensional vector representations corresponding to the emotion scores to find the optimal allocation of data points (here: participants) into k clusters32. To determine k for the final model, we ran the algorithm for \(k \in \left\{ {1, \ldots , 20} \right\}\) and used the within-cluster sum of squares (the "elbow" method) and the silhouette coefficients33. Both methods indicated that a cluster model with k = 2 cluster centres is most suitable to describe the data. The means of each of the emotion change variables per cluster (Table 3) show two distinct groups of participants. We tested for each cluster mean whether it deviated from zero (i.e., no change). All except for anxiety (cluster 2) differed significantly from 0 at p < 0.01.
Cluster 1 consisted of participants who reported marked decreases in anger, anxiety, disgust, fear, sadness and worry, and increases in desire, happiness and relaxation. In contrast, participants in cluster 2 reported higher anger, desire, disgust and sadness, and a decrease in fear, happiness, relaxation and worry.
These patterns lead us to interpret participants in cluster 1 (43.58% of the participants) as well-coping individuals who fared significantly better one year after the start of the pandemic: all negative emotional states (anger, anxiety, disgust, sadness and worry) decreased while all positive ones (desire, happiness, relaxation) increased. The second cluster (56.42% of the participants) showed a more complex pattern: participants were less afraid and less worried but also less happy and less relaxed. Instead, the increases in anger, disgust, sadness and desire, suggest some resignation after one year in the pandemic. Table 4 shows verbatim excerpts of texts of two participants representative for each cluster at the different data collection moments.
Participants in the resignation cluster were marginally younger than those in the well-coping cluster, d = 0.16 [99% CI: 0.04; 0.29]. There was no difference in gender between the two clusters, X2(1) = 1.86, p = 0.173 (we excluded participants from the gender analysis who did not provide gender information). Additional exploratory analyses on predicting cluster membership from the text data using machine learning can be found in the Appendix.
Linguistic analysis
Table 5 shows the corpus descriptive statistics for both phases. There were no marked changes between the corpora of the two phases. The linguistic analyses were conducted with the quanteda R package34. For the subsequent analyses, we use the long texts only. All results for the short texts are available in the Appendix.
Psycholinguistic variables
In order to capture possible psychological changes reflected in language use, we examined the change in LIWC2015 categories17 between phase 1 and phase 2. A large number of LIWC categories differed between the two phases for long texts. Table 6 lists the ten categories with the largest BF: the categories “time”, “focus on the past”, “Tone” (i.e., emotional tone, where a higher value represents more positive emotion), and “relativity” increased in phase two. References to anxiety, negative emotion, the home, as well as pronouns, social words, and interrogators decreased in phase 2.
Topic models
A structural topic modelling approach was used to examine possible changes in topics between phase 1 and 2. This analysis enables us to further examine the content of texts, for example the specific topics that participants worry about35. A topic model was constructed for the whole corpus (texts from phase 1 and 2 together), where data collection phase was included as a covariate to assess its effect on topic prevalence. Measures of semantic coherence and exclusivity of topic words36 were used to determine the ideal number of topics, resulting in a topic model of 15 topics for long texts.
The data collection phase (phase 1 vs. phase 2) had a significant effect (p < 0.001) on topic assignment for all topics with the exception of Topic 1 and 4. Table 7 denotes the effect size of the differences in topic proportion between phases. The topics’ content demonstrates the differences between the two data collection moments. Several topics contain the word 'vaccine' as a frequent term, all of which significantly increased in the second data collection phase (Topic 14, 7, and 3). Topic 14 and 7, which showed the largest increase in phase 2, seem to refer to hope and a return to normality. In contrast, Topic 8 and 11 largely discuss worries about loved ones—these were significantly more prevalent in the first phase. Negative emotions demonstrated in Topic 10 and 9 were also more prevalent in phase 1. This also holds for topics that seemingly relate to rule following (Topic 6) and panic buying (Topic 13) which were themes that were a lot more prevalent at the start of the pandemic. Interestingly, Topic 4, which appears to refer to a negative outlook on the government handling of the pandemic, did not significantly differ between phase 1 and 2.
n-gram differentiation analysis
Next, we investigated which terms shifted the most from the first to the second phase. Specifically, we tested whether the n-gram frequencies (unigrams, bigrams and trigrams) differed between the first and the second phase. Since each participant provided two texts, we used a within-subjects test on the n-gram frequencies. Since the parametric assumptions are not met for n-gram frequencies, we used the Wilcoxon signed rank sum test to test for each n-gram whether the frequency between the phases changed. A joint corpus of both phases was created, lower-cased, stemmed, stopwords were removed (using the default English stopword list from the quanteda package), and only n-grams with a document frequency of at least 5% were retained. The signed rank sum test results in a large proportion of ties with skewed data37, so we resolved the ties by assigning random ranks to tied cases and ran 500 iterations with random seeds. These were then averaged, and the findings below show the mean and standard error. We use the r effect size to show the top 20 most moved n-grams in Table 8. Values of r closer to + 1.00 indicate a higher n-gram frequency in phase 2 than in phase 1, and vice versa for values approaching -1.00.
The results suggest that the n-grams that increased the most were related to the prospect of the vaccine, the opening of the country and returning back to normal, while decreased terms were about worries, the NHS, staying home, stress, worker and worry—indicating a more worried look on the pandemic in phase 1 than in phase 2.
The effect of the term “vaccine”
Using the n-gram differentiation analysis revealed an important role for the term “vaccine” (or variations thereof such as “vaccinated”, “vaccination”). We explored whether references to the vaccine affected the emotion change from phase 1 to phase 2. We counted the occurrences of (versions of) the unigram “vaccine” and then separated the sample into those who did (n = 1010) and did not (n = 688) refer to it in the long text of phase 2. Table 9 shows the statistical findings when we assessed the emotion change scores between these two groups. Participants who mentioned the vaccine had a larger reduction in anxiety (d = 0.22) and sadness (d = 0.17) between the two phases than those who did not mention it. There were no changes for the other emotions.
Discussion
The COVID-19 pandemic is affecting the lives and mental health of millions. This paper examined how emotional responses to the pandemic changed within one year—from the early onset with severe lockdown measures until the prospect of a return to normal with ongoing vaccination programmes and decreasing incident rates. Using a within-subjects design with a one-year lag, we could assess the change in people’s emotional responses to the pandemic. Two core questions guided this paper: (1) How did emotional responses change from April 2020 to April 2021? (2) How can we use text data as a lens through which we can learn about emotional responses in more detail?
Change in emotions
The analyses suggest that, on average, the intensity of negative emotions decreased and that of positive emotions increased from the onset of the pandemic to the prospect of re-opening the country. These findings are not surprising: the first phase of data collection happened at a time where unequalled lockdown measures were in place, hence resulting in high scores for negative emotions and low scores for positive emotions. These then moved towards the positive in phase 2. The correlations between the two data collection points suggest that it is unlikely that the change towards less extreme scores in phase 2 is attributable to a regression to the mean. Instead, we found subgroups hinting at a more complex picture.
Two clusters of participants emerged: one group exhibited a pattern in emotion change that we identified as well-coping. Participants in that group showed a general increase in positive emotions and a decrease in worry-related emotions. In contrast, a second group appeared to be less well-adapted after one year in the pandemic, with a pattern that we interpret as resembling resignation. Importantly, we failed to find straightforward explanations for these cluster patterns. While participants in the well-coping cluster were marginally older than those in the resignation cluster, neither gender nor linguistic differences emerged. Previous work6 found gender differences in the topics of the first phase texts, but these patterns did not seem to be at play with the subgroups. Possibly, membership in either of the two clusters can be inferred from the texts that participants wrote. If that were the case, we would expect at least some predictive relationship between linguistic features of the text data and the participants’ cluster membership. We tested this with supervised machine learning but failed to find an above-guessing prediction performance (see Appendix).
Learning about emotions through text data
Linguistic analyses revealed marked differences between data collection phases. For instance, using LIWC variables, we found increased positive emotion and decreased negative emotion in phase 2 compared to phase 1. References to the home also decreased in phase 2, possibly reflecting the difference in social distancing rules between phase 1 (strict lockdown at home) and 2 (easing of social distancing rules).
When we applied structural topic modelling, we observed dominant themes for each phase (April 2020 vs. April 2021) in participants' writing. Similar to the LIWC analysis, we observed more reference to negative emotion about the pandemic in phase 1 than in phase 2. We also shed some light on the content of worries, which often related to family and friends. In the second phase, topics relating to (hope for) a return to normality often included references to the vaccine. One of the topics which discussed a negative outlook on the government’s handling of the pandemic did not differ between data collection phases. These results possibly suggest that UK residents were dissatisfied with government handling during both phases of data collection but had different concerns pertaining to their individual situation (worries in phase 1 and hope in phase 2). Although several topics showed overlap in most frequent terms and thus were not easily distinguishable, topic modelling enabled us to shed some further light on the content of worries and hope demonstrated by participants in the study.
Further trends were revealed in the n-gram differentiation analysis. The frequencies of n-grams related to the vaccine and an outlook on the future ("looking forward to") were markedly higher in the second phase than in the first phase. Conversely, the mentions of n-grams, including "worry", were more frequent in the first phase. These findings highlight that text data somewhat capture significant changes in society and that participants have them on their minds. The vaccine was the dominant word in phase 2, which mirrors the public discourse in the UK at the time of data collection. Interestingly, the notion of a vaccine was practically absent in the first phase. Follow-up analyses showed that individuals who mentioned the vaccine showed a more pronounced reduction in anxiety and sadness than those who did not refer to the vaccine.
So what? The bigger picture and an outlook
A key challenge for public health may lie in the mental health effects that the COVID-19 pandemic is having. With limited resources available, research such as the current study can help health care professionals identify individuals who may be at a heightened risk of more severe mental health problems. Related work, for example, has looked at changes in loneliness due to the various interventions introduced due to the pandemic38,39. Understanding the relationship between an emotional response such as loneliness and text data produced by people is a promising avenue for research but is still in an early stage40. Importantly, our analysis showed that it is oversimplified to assume that a population processes the pandemic in a homogenous manner. Two radically divergent subgroups were identified. This, again, may aid mental health professionals and policymakers in their approach to handling the (mental health) consequences of the pandemic. Future work could test (1) how subgroups can be identified and (2) whether membership in a subgroup also corresponds to differences in mental health and possibly even the effectiveness of different intervention strategies.
Our paper makes the connection between emotion data and text data. Although similar connections have been made in the past (e.g.,19,20), they lacked ground truth of the emotional states of text writers. By assessing ‘ground truth’ emotional states (albeit self-reported ones) and having participants write about them, we were able to examine linguistic correlates of emotions and worries. For clarification, the term ‘ground truth’ emotional states here denotes that the emotional states of individual participants were provided by the participants themselves rather than through an external annotation procedure. While we appreciate that emotional states are volatile, our dataset records the participants’ emotional wellbeing at the time of conducting the task, thus representing their ground truth mental states when writing the statements. All in all, this approach can help us as a research community to test and ultimately harness the simmering potential of observational text data. Future work could, for example, use the dataset to assess whether text data from one phase can be used to predict emotions in a subsequent phase. Ideally, social and behavioural science research continues to adopt methods from the computational sciences and builds on the current work to further our understanding of text data as a means to study behaviour and emotions.
Limitations
Our paper comes with a few limitations worth noting. First, we only captured the emotional responses of UK residents. While this was done to avoid the influence of potential confounds such as government responses, this somewhat limits the ecological validity of these findings. Whether our results are valid in other countries is an open question and hard to ascertain absent longitudinal data on emotion and text data from other countries. Second, as with all unsupervised techniques, the topic models and the clustering analysis contain subjectivity in the interpretation. Other researchers may have interpreted the clusters differently and hence yielded different conclusions. We acknowledge that subjectivity, and by making the raw data available, we encourage others to challenge our findings. Similarly, we have only focused on the core of the dataset but have not examined further variables such as socioeconomic status or self-assessed linguistic expression ability. All these data are now publicly available as part of this paper. Third, we have identified the two subgroups only through exploratory analyses and refrained from conducting further in-depth analyses on the properties of these groups. Ideally, similar studies could attempt to replicate the findings and solidify the evidence favouring heterogenous coping with the pandemic. Future work could then look at linguistic differences between these clusters (i.e., do the subgroups use different words and topics?).
Conclusion
The COVID-19 pandemic could have potentially long-lasting consequences on public mental health. Understanding the emotional responses to a “new normal” requires an analytical toolkit that allows for the complexity in how people (struggle to) cope. This paper identified a heterogeneous pattern in people (well-coping vs. resigned ones). Our method demonstrated how text data can help us understand the impact of the COVID-19 pandemic on people’s lives, and how individuals work through and adapt to drastically changing circumstances. We believe that our data collection efforts and subsequent analyses represent a valuable resource to better understand emotional standpoints of the public, and we encourage other researchers to further exploit the potential of our presented dataset.
References
Institute for Government Analysis. Timeline of UK coronavirus lockdowns, March 2020 to March 2021. https://www.instituteforgovernment.org.uk/sites/default/files/timeline-lockdown-web.pdf (2021).
Biester, L., Matton, K., Rajendran, J., Provost, E. M. & Mihalcea, R. Quantifying the effects of COVID-19 on mental health support forums. In Proceedings of the 1st Workshop on NLP for COVID-19 (Part 2) at EMNLP 2020 (2020).
Boon-Itt, S. & Skunkan, Y. Public perception of the COVID-19 pandemic on Twitter: Sentiment analysis and topic modeling study. JMIR Public Health Surveill. 6, e21978. https://doi.org/10.2196/21978 (2020).
Shuja, J., Alanazi, E., Alasmary, W. & Alashaikh, A. COVID-19 open source data sets: a comprehensive survey. Appl. Intell. 51, 1–30 (2020).
Kleinberg, B., van der Vegt, I. & Mozes, M. Measuring emotions in the COVID-19 real world worry dataset. In Proceedings of the 1st Workshop on NLP for COVID-19 at ACL 2020. Online: Association for Computational Linguistics. https://www.aclweb.org/anthology/2020.nlpcovid19-acl.11 (2020).
van der Vegt, I. & Kleinberg, B. Women worry about family, men about the economy: Gender differences in emotional responses to COVID-19. In Social Informatics (eds Aref, S. et al. et al.) 397–409 (Springer, 2020). https://doi.org/10.1007/978-3-030-60975-7_29.
Çakar, H. & Sengur, A. Machine learning based emotion classification in the COVID-19 real world worry dataset. Comput. Sci. 6, 24–31 (2021).
gov.uk. COVID-19 Response—Spring 2021 (Summary). In GOV.UK [Internet]. 2021 [cited 19 Jul 2021]. https://www.gov.uk/government/publications/covid-19-response-spring-2021/covid-19-response-spring-2021-summary (2021).
Imhoff, R. & Lamberty, P. A bioweapon or a hoax? The link between distinct conspiracy beliefs about the coronavirus disease (COVID-19) outbreak and pandemic behavior. Soc. Psychol. Pers. Sci. 11, 1110–1118. https://doi.org/10.1177/1948550620934692 (2020).
Nilima, N., Kaushik, S., Tiwary, B. & Pandey, P. K. Psycho-social factors associated with the nationwide lockdown in India during COVID-19 pandemic. Clin. Epidemiol. Glob. Health 9, 47–52. https://doi.org/10.1016/j.cegh.2020.06.010 (2021).
Pfattheicher, S., Nockur, L., Böhm, R., Sassenrath, C. & Petersen, M. B. The emotional path to action: Empathy promotes physical distancing and wearing of face masks during the COVID-19 pandemic. Psychol. Sci. 31, 1363–1373. https://doi.org/10.1177/0956797620964422 (2020).
Ferrara, E. What types of COVID-19 conspiracies are populated by Twitter bots? First Monday [cited 5 Jun 2021]. https://doi.org/10.5210/fm.v25i6.10633 (2020).
Shahi, G. K., Dirkson, A. & Majchrzak, T. A. An exploratory study of COVID-19 misinformation on Twitter. Online Soc. Netw. Med. 22, 100104. https://doi.org/10.1016/j.osnem.2020.100104 (2021).
Su, Y. et al. Examining the impact of COVID-19 lockdown in Wuhan and Lombardy: A psycholinguistic analysis on Weibo and Twitter. Int. J. Environ. Res. Public Health 17, 4552. https://doi.org/10.3390/ijerph17124552 (2020).
Jiang, J., Chen, E., Yan, S., Lerman, K. & Ferrara, E. Political polarization drives online conversations about COVID-19 in the United States. Hum. Behav. Emerg. Technol. 2, 200–211. https://doi.org/10.1002/hbe2.202 (2020).
Zhang, J. S., Keegan, B., Lv, Q. & Tan, C. Understanding the Diverging User Trajectories in Highly-Related Online Communities during the COVID-19 Pandemic 12 (2021).
Pennebaker, J. W., Boyd, R. L., Jordan, K. & Blackburn, K. The development and psychometric properties of LIWC2015. https://repositories.lib.utexas.edu/handle/2152/31333 (2015).
Low, D. M. et al. Natural language processing reveals vulnerable mental health support groups and heightened health anxiety on reddit during COVID-19: Observational study. J. Med. Internet Res. 22, e22635. https://doi.org/10.2196/22635 (2020).
Aiello, L. M. et al. How epidemic psychology works on Twitter: Evolution of responses to the COVID-19 pandemic in the U.S.. Humanit. Soc. Sci. Commun. 8, 1–15. https://doi.org/10.1057/s41599-021-00861-3 (2021).
Stella, M., Restocchi, V. & De Deyne, S. #lockdown: Network-enhanced emotional profiling in the time of COVID-19. Big Data Cogn. Comput. 4, 14. https://doi.org/10.3390/bdcc4020014 (2020).
Bischetti, L., Canal, P. & Bambini, V. Funny but aversive: A large-scale survey of the emotional response to Covid-19 humor in the Italian population during the lockdown. Lingua 249, 102963. https://doi.org/10.1016/j.lingua.2020.102963 (2021).
Dillard, J. P., Yang, C. & Huang, Y. Feeling COVID-19: Intensity, clusters, and correlates of emotional responses to the pandemic. J. Risk Res. https://doi.org/10.1080/13669877.2021.1958043 (2021).
Montefinese, M., Ambrosini, E. & Angrilli, A. Online search trends and word-related emotional response during COVID-19 lockdown in Italy: A cross-sectional online study. PeerJ 9, e11858. https://doi.org/10.7717/peerj.11858 (2021).
Salganik, M. J. Bit by Bit: Social Research in the Digital Age (Princeton University Press, 2019).
Lyons, K. Coronavirus Latest: At a Glance. The Guardian (accessed 7 April 2020); https://www.theguardian.com/world/2020/apr/07/coronavirus-latest-at-a-glance-7-april.
Harmon-Jones, C., Bastian, B. & Harmon-Jones, E. The discrete emotions questionnaire: A new tool for measuring state self-reported emotions. PLoS ONE 11, e0159915. https://doi.org/10.1371/journal.pone.0159915 (2016).
Cohen, J. Statistical Power Analysis for the Behavioral Sciences (Academic Press, 1988).
Rouder, J. N., Speckman, P. L., Sun, D., Morey, R. D. & Iverson, G. Bayesian t tests for accepting and rejecting the null hypothesis. Psychon. Bull. Rev. 16, 225–237. https://doi.org/10.3758/PBR.16.2.225 (2009).
Morey, R., Rouder, J., Love, J. & Marwick, B. Bayesfactor: 0.9.12-2 Cran. Zenodo. https://doi.org/10.5281/zenodo.31202 (2015).
van Ravenzwaaij, D. & Etz, A. Simulation studies as a tool to understand Bayes factors. Adv. Methods Pract. Psychol. Sci. 4, 251524592097262. https://doi.org/10.1177/2515245920972624 (2021).
Wagenmakers, E., Wetzels, R., Borsboom, D. & van der Maas, H. L. J. Why psychologists must change the way they analyze their data: The case of psi: Comment on Bem (2011). J. Pers. Soc. Psychol. 100, 426–432. https://doi.org/10.1037/a0022790 (2011).
Likas, A., Vlassis, N. & Verbeek, J. The global k-means clustering algorithm. Pattern Recognit. 36, 451–461. https://doi.org/10.1016/S0031-3203(02)00060-2 (2003).
de Amorim, R. C. & Hennig, C. Recovering the number of clusters in data sets with noise features using feature rescaling factors. Inf. Sci. 324, 126–145. https://doi.org/10.1016/j.ins.2015.06.039 (2015).
Benoit, K. et al. quanteda: An R package for the quantitative analysis of textual data. J. Open Source Softw. 3, 774. https://doi.org/10.21105/joss.00774 (2018).
Roberts, M. E. et al. Structural topic models for open-ended survey responses. Am. J. Polit. Sci. 58, 1064–1082. https://doi.org/10.1111/ajps.12103 (2014).
Mimno, D., Wallach, H., Talley, E., Leenders, M. & McCallum, A. Optimizing Semantic Coherence in Topic Models 11 (2011).
Lijffijt, J. et al. Significance testing of word frequencies in corpora. Digit. Scholarsh. Humanit. 31, 374–397. https://doi.org/10.1093/llc/fqu064 (2016).
Killgore, W. D. S., Cloonan, S. A., Taylor, E. C. & Dailey, N. S. Loneliness: A signature mental health concern in the era of COVID-19. Psychiatry Res. 290, 113117. https://doi.org/10.1016/j.psychres.2020.113117 (2020).
Tso, I. F. & Park, S. Alarming levels of psychiatric symptoms and the role of loneliness during the COVID-19 epidemic: A case study of Hong Kong. Psychiatry Res. 293, 113423. https://doi.org/10.1016/j.psychres.2020.113423 (2020).
Hipson, W. E., Kiritchenko, S., Mohammad, S. M. & Coplan, R. J. Examining the language of solitude versus loneliness in tweets. J. Soc. Pers. Relatsh. https://doi.org/10.1177/0265407521998460 (2021).
Acknowledgements
We thank two anonymous reviewers for suggestions that helped us improve the paper; in particular the exploration of the role of the term “vaccine” on emotion change scores.
Author information
Authors and Affiliations
Contributions
All authors contributed equally to this paper and were involved in all stages.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mozes, M., van der Vegt, I. & Kleinberg, B. A repeated-measures study on emotional responses after a year in the pandemic. Sci Rep 11, 23114 (2021). https://doi.org/10.1038/s41598-021-02414-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-02414-9
- Springer Nature Limited
This article is cited by
-
A multi-modal panel dataset to understand the psychological impact of the pandemic
Scientific Data (2023)