

Abstract
Protein expression and turnover are controlled through a complex interplay of transcriptional, post-transcriptional and post-translational mechanisms to enable spatial and temporal regulation of cellular processes. To systematically elucidate such gene regulatory networks, we developed a CRISPR screening assay based on time-controlled Cas9 mutagenesis, intracellular immunostaining and fluorescence-activated cell sorting that enables the identification of regulatory factors independent of their effects on cellular fitness. We pioneered this approach by systematically probing the regulation of the transcription factor MYC, a master regulator of cell growth1,2,3. Our screens uncover a highly conserved protein, AKIRIN2, that is essentially required for nuclear protein degradation. We found that AKIRIN2 forms homodimers that directly bind to fully assembled 20S proteasomes to mediate their nuclear import. During mitosis, proteasomes are excluded from condensing chromatin and re-imported into newly formed daughter nuclei in a highly dynamic, AKIRIN2-dependent process. Cells undergoing mitosis in the absence of AKIRIN2 become devoid of nuclear proteasomes, rapidly causing accumulation of MYC and other nuclear proteins. Collectively, our study reveals a dedicated pathway controlling the nuclear import of proteasomes in vertebrates and establishes a scalable approach to decipher regulators in essential cellular processes.
Similar content being viewed by others


Main
To study mechanisms controlling protein expression and turnover, we developed a time-controlled CRISPR screening assay that enables the systematic identification of regulatory factors independent of their effects on viability (Fig. 1a). We applied this approach to study the regulation of MYC4, a proto-oncogenic transcription factor that is transcriptionally controlled by mitogenic signalling pathways and complex enhancer landscapes5,6, highly regulated at the mRNA level7 and rapidly degraded by the ubiquitin–proteasome system (UPS)8. As one of the most short-lived mammalian mRNAs and proteins3,9, MYC also provides an ideal reporter for studying general factors in nuclear protein regulation.

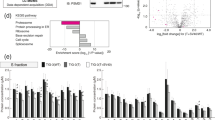
a, Schematic of iCas9 cell engineering and FACS-based screens. b, Competitive proliferation assays of sgMYC or sgAAVS1 control iCas9-RKO cells in the presence or absence of DOX (n = 3 biological replicates). Data are normalized to Day 0 and presented as mean ± s.d. c, Flow cytometry quantification of intracellular MYC protein 24 h after inducible MYC or AAVS1 knockout. Data are representative of three independent experiments. d, FACS-based CRISPR screens for positive MYC regulators. Gene-level enrichment of sgRNAs in MYClo cells (x axis) and one-sided MAGeCK P values (y axis). For each gene, the time point with the more significant P value is plotted. Dashed lines indicate significance (P < 0.01) and 95th percentile of enrichment. Significantly enriched genes involved in transcription, mRNA processing or translation are highlighted. Gating strategy shown in Supplementary Fig. 2. e, Heat map of selected MYC regulators as in d.
Temporal CRISPR screens for MYC regulators
Because MYC is broadly essential10,11, we reasoned that single guide RNAs (sgRNAs) targeting MYC or its regulators would rapidly deplete in a screen, thereby limiting observable effects on MYC protein abundance to a narrow time window after CRISPR–Cas9 editing. To gain temporal control, we engineered an optimized doxycycline (DOX)-inducible Cas9 (iCas9) system (Extended Data Fig. 1a, b) in three human cancer cell lines (RKO, MIA-PaCa-2 and K562), which we functionally characterized using sgRNAs targeting essential genes and surface markers (Fig. 1b, Extended Data Fig. 1c, d). For all cell lines, we isolated single-cell-derived clones that showed no Cas9 activity in the absence of DOX, whereas DOX addition rapidly triggered efficient CRISPR editing.
Next, we established an intracellular staining assay enabling robust and specific quantification of endogenous MYC levels by flow cytometry (Fig. 1c, Extended Data Fig. 1e). To systematically identify MYC regulators in diverse cancer contexts, we transduced all three iCas9 lines with the Vienna sgRNA library12, expanded library-transduced cells and induced Cas9 expression. Cells displaying decreased (MYClo) or elevated (MYChi) MYC levels were isolated by fluorescence-activated cell sorting (FACS) at two time points (2.5 d and 4–5 d after DOX induction) to account for different mRNA or protein half-lives, and sgRNAs were quantified by deep sequencing (Supplementary Table 1). Integrating effects from both time points identified MYC as a top hit in all three screens (Fig. 1d, e, Extended Data Fig. 2, Supplementary Table 2). Other prominent hits in MYClo cells included driving oncogenes (that is, BRAF in RKO cells, KRAS in MIA-PaCa-2 cells and ABL1 in K562 cells) and context-specific transcriptional regulators (Fig. 1d, e), confirming that MYC expression is controlled by Ras-signalling pathways13 and tissue-specific transcriptional machinery5. All three screens also identified core components of Pol-II-dependent transcription, mRNA splicing and protein translation, indicating that our iCas9 system captured general gene expression machinery despite its essential functions (Extended Data Fig. 2).
Consistent with the rapid turnover of MYC8, MYChi cells displayed strong enrichment of sgRNAs targeting components of the UPS (Fig. 2a, b), including all subunits of the 20S core proteasome (20S-CP), the 19S-ATPase and non-ATPase proteasome subunits, as well as E3 ubiquitin ligases previously implicated in MYC protein turnover14,15,16. Unexpectedly, all three screens also identified the transcriptional co-factor AKIRIN2 as a major negative regulator of MYC, with effect sizes matching those of essential UPS components.

a, FACS-based CRISPR screens for negative MYC regulators as in Fig. 1d. One-sided P values were calculated using MAGeCK. Significantly enriched proteasome subunits and UPS-related genes are highlighted. b, Heat map of selected UPS-associated genes as in a. c, d, Flow cytometric analysis (c) and quantification (d) of endogenous MYC protein levels in iCas9-RKO cells after inducible knockout of indicated hits. Data are normalized to Day 0. In c, the time point with maximal effects on MYC is shown. e, f, Representative confocal images (e; scale bar, 50 µm) and flow cytometric quantification (f) of relative mCherry–MYC/BFP ratios in mCherry–MYC-P2A–BFP reporter cells after induced knockout of selected hits (time points as in c). Data in c and e are representative of three independent experiments, respectively. Data in d and f are shown as mean ± s.d. (n = 3 independent experiments). FC, fold change.
AKIRIN2 is required for nuclear protein turnover
To investigate the role of AKIRIN2 in MYC regulation, we first validated our screen results using time-controlled AKIRIN2 knockout, which triggered a strong increase in MYC protein abundance in all three cell lines (Fig. 2c, Extended Data Fig. 3a–c). Consistent with our screening data, these effects peaked by 2 d after DOX treatment, preceding the effects of established UPS components (Fig. 2d, Extended Data Fig. 3a), and were followed by a marked increase in cleaved-caspase-3+ cells, indicating that loss of AKIRIN2 induces apoptosis (Extended Data Fig. 3d, e). Accordingly, sgAKIRIN2-expressing cells were rapidly depleted in primary screens and validation studies (Extended Data Figs. 2d, 3f). Together with fitness defects in proliferation-based CRISPR screens10,11 and early embryonic lethality reported in mice17, this indicates that AKIRIN2 is generally essential for cell survival.
AKIRIN2 has been implicated as a transcriptional regulator17,18,19. To probe putative transcriptional functions, we performed RNA sequencing (RNA-seq) in sgAKIRIN2-expressing iCas9-RKO cells 2 d after DOX induction. Acute loss of AKIRIN2 did not alter MYC transcript levels and resulted in few transcriptional changes (22 genes upregulated and 62 genes downregulated more than twofold) that included many TP53 targets20, potentially reflecting an indirect stress response (Extended Data Fig. 4a–c). At the same time, loss of AKIRIN2 resulted in a more than sixfold gain in MYC protein half-life (Extended Data Fig. 4d, e) and strongly increased the abundance of an ectopically expressed mCherryMYC fusion protein (Fig. 2e, f, Supplementary Video 1). Thus, AKIRIN2 controls MYC through a post-translational mechanism.
To investigate whether the regulatory functions of AKIRIN2 are MYC-specific, we performed tandem mass-tag labelling and quantitative mass spectrometry (MS) after temporally controlled knockout of AKIRIN2. Besides strong accumulation of MYC, we identified 120 proteins that were similarly enriched without deregulation of the associated transcripts (Fig. 3a, Extended Data Fig. 4f–h, Supplementary Table 3), suggesting that AKIRIN2 has a broader role in protein turnover. We, therefore, compared these effects to those observed after induced knockout of the 20S-CP subunit PSMA3, which led to upregulation of 289 proteins. Unexpectedly, AKIRIN2 scored among the ten most enriched proteins upon PSMA3 knockout (Fig. 3b, c), which, together with its short half-life of ~45 min (Extended Data Fig. 4d, e), indicated that AKIRIN2 itself is rapidly turned over by the proteasome. When comparing proteins enriched after PSMA3 knockout (proteasome targets) to those stabilized upon loss of AKIRIN2 (AKIRIN2 targets), we found that almost all AKIRIN2 targets were also controlled by the proteasome (Fig. 3b, Extended Data Fig. 4i). Conversely, only about 55% of proteasome targets were also enriched upon AKIRIN2 knockout (Fig. 3a). In Gene Ontology (GO) analyses, proteasome targets that were also upregulated upon loss of AKIRIN2 were highly enriched for nuclear localization and transcriptional functions, whereas proteasome targets that were not affected by AKIRIN2 knockout were mainly localized to the cytoplasm (Fig. 3d, Supplementary Table 4). Together, these findings suggested that AKIRIN2 is broadly required for the proteasomal degradation of nuclear proteins.

a, b, Whole proteome changes after induced AKIRIN2 (a) or PSMA3 (b) knockout. Quantitative mass spectrometry was performed 2 d (sgAKIRIN2 and sgAAVS1) or 3 d (sgPSMA3) after Cas9 induction. Genes with significant upregulation of protein (adjusted P ≤ 0.01 and FC ≥ 1.5, limma-moderated Benjamini–Hochberg-corrected two-sided t-test, n = 2 biological replicates) but not mRNA levels were classified as AKIRIN2 targets (n = 124, red box in a, highlighted red in b) or proteasome targets (n = 289, blue box and dots), respectively. c, Immunoblot of MYC and AKIRIN2 after acute AKIRIN2 or PSMA3 knockout. Data are representative of two independent experiments. Time points as in a and b. Uncropped scans are provided in Supplementary Fig. 1. d, Top differentially enriched GO terms (ΔFDR, Benjamini–Hochberg-corrected two-tailed Fisher’s exact test) between AKIRIN2-responsive (n = 89) and AKIRIN2-independent proteasome targets (n = 153). Complete results are shown in Supplementary Table 4. BP, biological process; CC, cellular component; FC, fold change; MF, molecular function.
AKIRIN2 interacts with the 20S proteasome
To understand the function of AKIRIN2 in nuclear protein turnover, we analysed its predicted secondary structure and evolutionary conservation (Fig. 4a, Extended Data Fig. 5a, Supplementary Table 5). Orthologues of human AKIRIN2 and its paralogue AKIRIN1 were found in more than 95% of analysed metazoans and several unicellular ancestors, but not in plants, fungi or prokaryotes. Throughout metazoan evolution, Akirin sequences are highly conserved, particularly within an N-terminal bipartite nuclear localization signal (NLS) and a C-terminal coiled-coil region, whereas an alanine-rich region is found only in higher vertebrates. The highest degree of conservation lies in a serine-tyrosine-valine-serine (SYVS) motif at the very C-terminus of AKIRIN2 (Fig. 4a, b).

a, AKIRIN2 protein features and conservation across 100 Akirin sequences from 77 species. b, C-terminal logo (left) and sequences from selected species (right). c, d, AKIRIN2 knockout-rescue. AKIRIN2 cDNA variants (c) and flow cytometric quantification of knockout-rescue iCas9-RKO cells (d) at indicated time points after Cas9 induction. Data are shown as mean ± s.d. (n = 3 independent experiments). e, f, Co-IP/MS of V5-AKIRIN2 (e) or ΔYVS mutant (f). Enrichment was calculated over V5-NLS-GFP (Benjamini–Hochberg-corrected limma-moderated two-sided t-test, n = 6 biological replicates). g, h, Cryo-EM reconstruction of human AKIRIN2 homodimers bound to the 20S-CP. De-noised density map at 3.2 Å (left) and atomic model (right). Detail views (h) show the interaction with the α3/α4 pocket (left) and the proteasome gate (right). FC, fold change.
To probe the functional relevance of these features, we performed a series of knockout–rescue experiments. We lentivirally delivered an AKIRIN2-specific sgRNA and sgRNA-resistant AKIRIN2 cDNAs (Fig. 4c, d, Extended Data Fig. 5b–d) and monitored the survival of sgRNA/cDNA double-positive cells after knockout of endogenous AKIRIN2 using flow cytometry. Although ectopic expression of full-length AKIRIN2 or a variant harbouring an N-terminal V5 tag fully compensated for the loss of endogenous AKIRIN2 (Fig. 4d), its essential functions could not be rescued by expressing just the N- or C-terminal half of the protein (Extended Data Fig. 5c). Consistent with the nuclear localization of AKIRIN2 (Extended Data Fig. 5e), a variant lacking the N-terminal NLS also failed to rescue loss of AKIRIN2, whereas deleting its alanine-rich region had little effect (Extended Data Fig. 5c). Remarkably, variants lacking only the last three amino acids (ΔYVS mutant) or harbouring a C-terminal V5 tag (V5–AKIRIN2) failed to rescue the knockout (Fig. 4d), indicating that the C-terminal SYVS motif is essential for the function of AKIRIN2.
To systematically identify AKIRIN2 interaction partners, we ectopically expressed N-terminally V5-tagged versions of full-length AKIRIN2, the ΔYVS mutant, AKIRIN1 or a nuclear GFP control and performed co-immunoprecipitation mass spectrometry (co-IP/MS). In both V5–AKIRIN2 and V5–AKIRIN1 pulldowns, we reciprocally identified an interaction between the two paralogues (Fig. 4e, Extended Data Fig. 5f, Supplementary Table 6). In addition, pulldown of V5–AKIRIN2 co-purified all subunits of the 20S-CP and the 19S regulatory particle (RP) as well as components of the nuclear transport machinery, including the small GTPase RAN and the nuclear import receptor IPO9 (Fig. 4e), which are also identified in the BioGRID repository21. By contrast, pulldown of V5–AKIRIN1 co-purified only AKIRIN2 and nuclear transport factors, without enrichment of proteasome subunits (Extended Data Fig. 5f). Similarly, the AKIRIN2ΔYVS mutant retained binding to AKIRIN1 and nuclear transport factors, whereas the proteasome interaction was lost (Fig. 4f). Thus, AKIRIN2, but not AKIRIN1, directly binds to fully assembled proteasomes via its C-terminal SYVS motif.
To further characterize the interaction between AKIRIN2 and the proteasome, we purified recombinant GST–AKIRIN2 (Extended Data Fig. 6a, b) and used it to co-purify interactors from HeLa cell extracts. Sucrose gradient fractionation followed by MS validated that AKIRIN2 binds both 20S and fully assembled 26S proteasomes (Extended Data Fig. 6c, d). We also identified IPO9 in AKIRIN2–proteasome fractions, suggesting the formation of a ternary protein complex. To visualize the AKIRIN2–proteasome interaction, we performed negative staining electron microscopy (EM) of proteasomes purified with GST–AKIRIN2 or the ubiquitin-like domain of RAD23B (GST–UBL; Extended Data Fig. 6e, f), which revealed AKIRIN2 as an additional density bound to the flat surface of the 26S proteasome (Extended Data Fig. 6g, h).
To gain more detailed structural insight, we analysed AKIRIN2–proteasome particles using cryo-EM and obtained a reconstruction of the AKIRIN2 C-terminus (amino acids 140–203) bound to the 20S proteasome at 3.2 Å resolution (Fig. 4g, Extended Data Fig. 7a–d, Supplementary Tables 7, 8). The cryo-EM map revealed that the C-terminal coiled-coil domains of AKIRIN2 form a homodimer that binds to the flat surface of the proteasome barrel by several specific interactions (Fig. 4h, Extended Data Fig. 7d, e). The C-terminal SYVS motifs of AKIRIN2 homodimers reach into distinct pockets formed between the α2/α3 (PSMA2/PSMA4) and the α3/α4 (PSMA4/PSMA7) subunits. In active 26S and 30S proteasomes, these pockets are occupied by the C-termini of the 19S subunits Rpt6 (PSMC5) and Rpt2 (PSMC1), which controls gate opening22 (Extended Data Fig. 7f). Moreover, the AKIRIN2 coiled-coil extends over the proteasome gate by direct interactions with the gate-forming N-termini of the α1, α5 and α6 proteasome subunits (PSMA6, PSMA5 and PSMA1, respectively; Fig. 4h) and further to the edge of the proteasome surface, where it interacts with the α7 subunit (PSMA3; Extended Data Fig. 7d). These results suggest that efficient binding of AKIRIN2 to the proteasome requires multiple specific interactions that position AKIRIN2 across the proteasome gate.
AKIRIN2 controls nuclear proteasome import
Given its broad effects on nuclear protein turnover and its interaction with nuclear import factors, we hypothesized that AKIRIN2 could mediate nuclear proteasome import. To test this, we constructed a fluorescent proteasome reporter by co-delivering an sgRNA targeting the 20S-CP subunit PSMB4 and an sgRNA-resistant PSMB4–mCherry fusion protein. Ectopic expression of PSMB4–mCherry fully rescued the lethal effects of endogenous PSMB4 knockout (Extended Data Fig. 8a), and single-cell-derived clones lacking endogenous PSMB4 grew normally and incorporated PSMB4–mCherry into assembled proteasomes (Extended Data Fig. 8b, c). AKIRIN2 knockout resulted in a strong reduction in nuclear PSMB4–mCherry signal (Fig. 5a, b), which was confirmed by immunofluorescence microscopy of the 20S-CP subunit PSMA5 (Extended Data Fig. 8d, e). The loss of nuclear proteasomes was accompanied by an increase in cytosolic PSMB4 signal (Fig. 5a, b), indicating a redistribution of nuclear proteasomes to the cytoplasm. Similar effects were observed when monitoring the subcellular localization of 19S-RPs using an mCherry–PSMD3 reporter (Extended Data Fig. 8f-j) or after IPO9 knockout (Extended Data Fig. 8k–n). Thus, AKIRIN2 regulates the nuclear import of fully assembled 20S and 26S proteasomes through an IPO9-dependent mechanism.

a, b, Representative confocal images (a) and quantification (b) of mCherry signal in sgAKIRIN2 (n = 4,772 cells) or sgAAVS1 (n = 4,925 cells) PSMB4mCherry reporter cells 36–48 h after Cas9 induction. Data are shown as mean ± s.d. (n = 7 biological replicates from three independent experiments; two-sided Welch’s t-test). c, d, Representative time-lapse images (c) and quantification (d) of nuclear PSMB4–mCherry signal in dividing PSMB4 reporter cells 15–32 h after inducible AKIRIN2 (n = 38 cells) or AAVS1 (n = 27 cells) knockout. Dashed lines indicate nuclei. e, f, Representative time-lapse images (e) and quantification (f) of nuclear mCherry–MYC signal in dividing MYC-reporter cells 15–32 h after inducible AKIRIN2 (n = 40 cells) or AAVS1 (n = 38 cells) knockout. Red, mCherry–MYC signal; grey, DNA visualized with SiR-Hoechst. Signals in b, d and f were normalized to mean nuclear signal of sgAAVS1 cells. Lines and areas in d and f represent mean ± 95% confidence interval of one of two independent experiments. Scale bars in a, 15 µm; scale bars in c and e, 10 µm.
To study the dynamics of AKIRIN2-dependent proteasome import, we performed time-lapse microscopy of PSMB4–mCherry reporter cells. Upon mitotic entry and nuclear membrane breakdown, proteasomes are excluded from compacted chromosomes and evenly distributed throughout the cytosol, as previously described for other macromolecular complexes23 (Fig. 5c, d, Extended Data Fig. 9a, Supplementary Video 2). After completion of mitosis, PSMB4–mCherry levels rapidly increase in daughter cell nuclei and reach pre-mitotic levels within less than 1 h (Fig. 5d). The reemergence of nuclear proteasomes was preceded by nuclear accumulation of a GFP-labelled importin-β binding domain (IBB) reporter that is known to be rapidly imported into the nucleus upon reformation of the nuclear envelope24 (Extended Data Fig. 9b–d). Thus, the nuclear proteasome compartment must be restored after each cell division through re-import across the reassembled nuclear envelope.
To determine the function of AKIRIN2 in this process, we performed time-lapse microscopy in sgAKIRIN2-expressing reporter cells 15–24 h after Cas9 induction, thereby ensuring efficient AKIRIN2 protein depletion. Although nuclear PSMB4 levels were moderately decreased at the start of imaging, a severe phenotype emerged when cells divided in the absence of AKIRIN2. During mitosis, AKIRIN2 knockout cells completely failed to re-import proteasomes into newly formed nuclei, resulting in a near-complete loss of nuclear proteasomes in both daughter cells (Fig. 5c, d, Extended Data Fig. 9a). This post-mitotic loss of nuclear proteasomes was associated with a rapid increase in MYC levels (Fig. 5e, f, Extended Data Fig. 9e, Supplementary Video 2). Collectively, these findings establish AKIRIN2 as a critical mediator of nuclear proteasome import (Extended Data Fig. 9f), thereby providing a mechanistic explanation for the essential function of AKIRIN2 in the dynamic turnover of MYC and other nuclear proteins.
Discussion
The dynamic turnover of nuclear proteins is orchestrated by the nuclear UPS, which requires localization of proteasomes to the nucleus25,26,27. Although several mechanisms mediating nuclear proteasome import have been described in yeast28, such pathways have remained elusive in animals. In this study, we uncovered AKIRIN2 as the central mediator of nuclear proteasome import in vertebrates. AKIRIN2 directly binds to 20S and 26S proteasomes, and to IPO9, which has recently been implicated in nuclear proteasome import in Drosophila29. This suggests that AKIRIN2 cooperates with the nuclear transport machinery to mediate the import of pre-assembled proteasome complexes through the nuclear pore. This role of AKIRIN2 mirrors the function of Sts-1 (Cut-8), an otherwise unrelated protein that mediates nuclear proteasome import in yeast30. The parallel evolution of distinct import mechanisms suggests a broader requirement for specialized adapters to control the nuclear localization of large protein complexes.
AKIRIN2 covers the proteasome gate and occupies binding sites for the gate-opening 19S-ATPases. This suggests that AKIRIN2 binding prevents substrate access and locks the proteasome gate in a closed conformation, presumably to prevent non-selective degradation during nuclear import. Such activities of AKRIN2 require precise regulation. AKIRIN2 itself is rapidly degraded, presumably upon completion of the import process and dissociation from the proteasome through a yet unknown trigger. At the transcriptional level, AKIRIN2 shows strong cell-cycle-dependent fluctuations and peaks shortly before mitosis31, consistent with its role in post-mitotic proteasome import. This implies that rapidly proliferating cells will be most vulnerable to AKIRIN2 inhibition. While general proteasome inhibitors are already being used for cancer therapy32, AKIRIN2 might provide a pharmacological access point to selectively inhibit the nuclear UPS.
Large-scale genetic screens coupled to FACS-based readouts provide a transformative approach for deciphering regulatory pathways33,34. However, by using constitutive gene knockout approaches, such screens have been largely limited to the non-essential genome. Our study overcomes this limitation by developing a tightly regulatable CRISPR–Cas9 system, which we used for a systematic analysis of MYC regulators in diverse cancer cell lines. We provide a survey of context-specific and general cellular machinery required for MYC expression and turnover, among which we identify AKIRIN2 as a central mediator of nuclear proteasome import in vertebrates. Although future work will be needed to further elucidate this pathway, our findings shed light on the longstanding question of how cells maintain and regulate their nuclear proteasome content and, thereby, dynamically control the function of short-lived nuclear proteins, such as MYC.
Methods
A glossary of abbreviations used in this study and their definitions is provided in Supplementary Table 9.
Antibodies
The following antibodies were used for immunoblot analyses: c-MYC (D84C12, no. 5605, Cell Signaling Technology, RRID:AB_1903938, 1:1,000); AKIRIN2 (HPA064239, Atlas Antibodies, RRID:AB_2685222, 1:1,000); PSMA3 (12446, Cell Signaling Technology, RRID:AB_2797918, 1:1,000); PSMB4 (sc-390878, Santa Cruz Biotechnology, 1:500); PSMD3 (sc-393588, Santa Cruz Biotechnology, 1:100); V5 tag (R960-25, Thermo Fisher Scientific, RRID:AB_2556564, 1:1,000); FLAG tag (14793, Cell Signaling Technology, RRID:AB_2572291, 1:1,000); vinculin (V9131, Sigma-Aldrich, RRID:AB_477629, 1:500); and β-actin (A3854, Sigma-Aldrich, RRID:AB_262011, 1:50,000–1:100,000). Secondary antibodies included: HRP anti‐rabbit IgG (7074, Cell Signaling Technology, RRID:AB_2099233, 1:2,500); HRP anti-mouse IgG (7076, Cell Signaling Technology, RRID:AB_330924, 1:2,500); and HRP anti-rabbit IgG light chain (93702, Cell Signaling Technology, RRID:AB_2800208, 1:2,500). Antibodies used for FACS included: PE anti-c-MYC (D3N8F, no. 35876, Cell Signaling Technology, RRID:AB_2799087, 1:50); PE anti-cleaved-caspase-3 (12768, Cell Signaling Technology, RRID:AB_2798021, 1:50); APC anti-CD46 (TRA-2-10, no. 352405, BioLegend, 1:500); APC anti-CD151 (50-6, no. 350406, BioLegend, RRID:AB_2564356, 1:500); APC anti-CD90.1/Thy1.1 (202526, BioLegend, RRID:AB_1595470, 1:500); BV421 anti-CD2 (no. 562667, BD Biosciences, RRID:AB_2737695, 1:500); PE rabbit (DA1E) IgG Isotype Control (5742, Cell Signaling Technology, RRID:AB_10694219, 1:416); and human Fc Receptor Blocking Solution (422302, BioLegend, RRID:AB_2818986, 1:100–1:1,000). Immunofluorescence stainings were done using the following antibodies: PSMA5 (2457, Cell Signaling Technology, RRID:AB_823611, 1:50); V5 tag (13202, Cell Signaling Technology, RRID:AB_2687461, 1:500); rabbit (DA1E) mAb IgG isotype control (3900S, Cell Signaling Technology, RRID:AB_1550038, 1:2,400); and AF647 anti-rabbit IgG (H+L), F(ab′)2 fragment (4414S, Cell Signaling Technology, RRID:AB_10693544, 1:1,000). V5 tag antibody (R960-25, Thermo Fisher Scientific, RRID:AB_2556564, 0.44 μg μl−1 beads) was used for immunoprecipitation followed by MS.
Viral vectors and oligonucleotides
The design and construction of the human genome-wide Vienna sgRNA library in the sgETN lentiviral vector have been described previously12. Lentiviral single sgRNA expression vectors were generated based on pLentiCRISPRv1 (Addgene plasmid no. 49535) or pLentiCRISPRv2 (Addgene plasmid no. 52961). iCas9 expression vectors were modified from pLentiCRISPRv2. Dual sgRNA expression vectors were modified from Dual-sgRNA_hU6-mU6 (ref. 35) (Addgene plasmid no. 154194). rtTA3 expression vectors were based on pWPXLd (Addgene plasmid no. 12258) or a modified pRRL backbone36. TetR-KRAB and cDNA expression plasmids were modified from pRRL. For ectopic expression of proteins in human cell lines, human AKIRIN2 (NM_018064), PSMB4 (NM_002796.3) and PSMD3 (NM_002809.4) open reading frame (ORF) cDNAs were purchased from GenScript or Twist Bioscience, cloned into pRRL lentiviral vectors and synonymously mutated to remove the proto-spacer adjacent motif and sgRNA seed sequences. All AKIRIN2 cDNA variants were coupled to mCherry by an internal ribosome entry site (IRES) to monitor cDNA expression. PSMB4 and PSMD3 cDNAs were fused to mCherry C-terminally and N-terminally, respectively, to obtain PSMB4–mCherry or mCherry–PSMD3 fusion proteins. Human MYC ORF was cloned into a modified pLX303 vector (Addgene plasmid no. 25897) to obtain MYC C-terminally fused to mCherry. For protein purification, Escherichia coli codon-optimized human AKIRIN2 ORF was obtained from GeneArt and cloned into pETM-33 (Geerlof laboratory), encoding a 3C protease-cleavable His and GST tag at the 5′ end of the insert. pLentiv2-EF1αs-IBB.GFP-IVS-IRES-BlastR23 was a kind gift from the Daniel Gerlich laboratory. All plasmids and sgRNAs used in this study are shown in Extended Data Table 1, and the genome-wide Vienna sgRNA library is shown in Supplementary Table 1.
Cell culture
Human RKO (sex unspecified; American Type Culture Collection (ATCC) cat. no. CRL-2577, RRID:CVCL_0504) and K562 (female; ATCC cat. no. CCL-243, RRID:CVCL_0004) cells were cultured in RPMI 1640 (Gibco) supplemented with 10% FBS (Sigma-Aldrich), l-glutamine (4 mM, Gibco), sodium pyruvate (1 mM, Sigma-Aldrich) and penicillin/streptomycin (100 U ml−1/100 μg ml−1, Sigma-Aldrich). MIA-PaCa-2 cells (male; ATCC cat. no. CRL-1420, RRID:CVCL_0428), Lenti-293T lentiviral packaging cells (female, Clontech, cat. no. 632180) and HeLa cells (female; ATCC cat. no. CCL-2, RRID:CVCL_0030) were cultured in Dulbecco’s modified Eagle’s medium (DMEM; Sigma-Aldrich) supplemented with 10% FBS, l-glutamine (4 mM, Gibco), sodium pyruvate (1 mM, Sigma-Aldrich) and penicillin/streptomycin (Sigma-Aldrich). All cell lines were maintained at 37 ºC with 5% CO2, routinely tested for mycoplasma contamination and authenticated by short tandem repeat analysis.
Lentivirus production and infections
Semiconfluent Lenti-X cells were co-transfected with lentiviral plasmids, pCMVR8.74 helper (Addgene plasmid no. 22036) and pCMV-VSV-G (Addgene plasmid no. 8454) or pCMV-Eco (Cell Biolabs) envelope plasmids using polyethylenimine (PEI) transfection (MW 25,000, Polysciences) as previously described12. Virus containing supernatant was clarified by centrifugation. Target cells were infected at limiting dilutions in the presence of 4 μg ml−1 of polybrene (Sigma-Aldrich).
Generation of clonal iCas9 cell lines
RKO cells were sequentially transduced with pWPXLd-EF1αs-rtTA3-IRES-EcoR-PGK-PuroR and pLentiv2-TRE3G-Cas9-P2A-GFP-PGK-BlastR or with pRRL-SFFV-rtTA3-IRES-EcoR-PGK-HygroR and pLentiv2-TRE3G-Cas9-P2A-BFP; MIA-PaCa-2 cells with pRRL-SFFV-rtTA3-IRES-EcoR-PGK-HygroR and pLentiv2-TRE3G-Cas9-P2A-BFP; and K562 cells with pWPXLd-EF1αs-rtTA3-IRES-EcoR-PGK-PuroR and pLentiv2-TRE3G-Cas9-P2A-GFP, selected for hygromycin B or puromycin resistance, and single cells were sorted by FACS into 96-well plates using a FACSAria III cell sorter (BD Biosciences) to obtain single-cell-derived clones. K562 cells were subsequently transduced with pRRL-SFFV-tetR-KRAB-P2A-HygroR, selected for hygromycin B resistance and sub-cloned by FACS. Cas9 expression in selected clones was induced with 0.2 µg ml−1 to 0.4 µg ml−1 of DOX (Sigma-Aldrich) and evaluated by flow cytometry on an LSRFortessa (BD Biosciences) or iQue Screener PLUS (Intellicyt), followed by testing of Cas9 function and tightness of the TRE3G promoter in competitive proliferation assays and by immunostaining after knockout of the surface markers CD151 or CD46.
Gene essentiality analyses
Essential genes in each cell line were defined based on gene-level log2 fold depletion less than or equal to −2 in published CRISPR gene essentiality screens12,37,38.
For competitive proliferation assays, cells were lentivirally transduced with sgRNA expression vectors at 20–70% infection efficiency. Infection levels were determined using flow cytometry based on fluorescent marker expression 3–4 d after transduction (Day 0). Gene editing was induced by induction of Cas9 expression with 0.2 µg ml−1 of DOX, and the percentage of sgRNA+ cells was monitored by flow cytometry in regular intervals.
For knockout-rescue experiments, cells were simultaneously transduced with a lentiviral vector expressing sgRNAs targeting AKIRIN2, PSMB4 or PSMD3 and a lentiviral vector encoding the respective sgRNA-resistant cDNAs coupled to distinct fluorescent markers. To evaluate the rescue of sgRNA-infected cells by cDNA expression constructs, double-positive cells were monitored by flow cytometry after induction of Cas9 with DOX. All measured time points are shown relative to Day 0.
Immunostaining after inducible gene knockout
To assess the effects of CRISPR-mediated genetic perturbations on surface marker expression or intracellular MYC levels, cells were transduced with lentiviral sgRNA expression vectors at 20–60% transduction efficiency. In regular intervals after Cas9 induction, cells were collected and stained with indicated antibodies in FACS buffer (PBS, 5% FBS) for 10 min at 4 ºC and washed 1× with FACS buffer before flow cytometric analysis.
For staining of intracellular MYC, cells were collected and stained with Zombie Aqua viability dye (1:1,000 dilution in PBS, BioLegend), washed twice with PBS and fixed and permeabilized using paraformaldehyde (PFA) and methanol (MeOH). Cell pellets were fixed with 2% PFA for 15 min at room temperature (RT) and washed twice with PBS, followed by dropwise addition of ice-cold MeOH for permeabilization. Fixed cells were stored in MeOH at −20 ºC overnight. On the next day, cells were washed and incubated for 30 min at RT in FACS buffer before intracellular staining with PE-conjugated anti-MYC (1:50) or concentration-matched isotype control antibody for 1 h at RT. Cells were washed three times and resuspended in FACS buffer for flow cytometric analysis on an LSRFortessa (BD Biosciences) or iQue Screener PLUS operated by BD FACSDiva software (v8.0) or ForeCyt (v6.2.6752), respectively, and FACS data were analysed in FlowJo (v10.6). Mean MYC fluorescence intensities of sgRNA+ cells were normalized to sgRNA− cells within the same sample to correct for well-to-well variation.
For the analysis of cleaved-caspase-3 expression, iCas9-RKO cells were lentivirally transduced with sgRNA expression plasmids (pRRL-U6-sgRNA-EF1αs-Thy1-P2A-NeoR) and selected for sgRNA expression with G418 (1 mg ml−1, Gibco). After Cas9 induction, cells were collected, washed 1× with PBS and stained with Zombie Aqua viability dye (1:1,000 dilution in PBS, BioLegend). Cells were washed twice with PBS and fixed and permeabilized using the eBioscience Foxp3/Transcription Factor Staining Buffer Set (00-5523-00, Thermo Fisher Scientific) according to the manufacturer’s instructions. After permeabilization, cells were blocked in permeabilization buffer containing 5% FBS for 40 min at RT and subsequently stained for 1 h at RT with PE-conjugated anti-cleaved-caspase-3 antibody (1 μg ml−1) or concentration-matched isotype control in 50 μl of permeabilization buffer containing 5% FBS. Cells were washed three times with FACS buffer and analysed on an LSRFortessa (BD Biosciences).
FACS-based CRISPR–Cas9 screens
For pooled genome-wide CRISPR–Cas9 screens, the genome-wide Vienna sgRNA library12 was lentivirally packaged using PEI transfection of Lenti-X cells. The virus containing supernatant was cleared of cellular debris by filtration through a 0.45-µm PES filter and used to transduce RKO, MIA-PaCa-2 or K562 cells at a multiplicity of infection (MOI) of less than 0.2 and 300- to 1,000-fold library representation. Transduction levels were assessed 4 d after transduction by immunostaining of Thy1 and flow cytometric analysis, followed by selection of library-transduced cells with G418 (1 mg ml−1, Gibco). Selected cells were expanded, and Cas9 expression was induced with DOX (0.2 µg ml−1 to 0.4 µg ml−1, Sigma-Aldrich).
Immediately before DOX induction (Day 0), as well as before each FACS sort, unsorted control samples were harvested. For this, cells corresponding to at least 1,000-fold library representation were pelleted, snap-frozen and stored at −80 ºC until further processing. Cells were harvested for intracellular MYC staining and FACS 2.5 d and 4 d (K562) or 2.5 d and 5 d (RKO and MIA-PaCa-2) after Cas9 induction.
For RKO and K562 screens, library-transduced cells were harvested, washed with PBS and stained with Zombie Aqua viability dye (1:1,000). Cells were washed thoroughly and fixed using the eBioscience Foxp3/Transcription Factor Staining Buffer Set (00-5523-00, Thermo Fisher Scientific). Batches of 50 × 106 cells were incubated in 2–5 ml of freshly prepared fixation buffer for 30 min at 4 ºC, washed with FACS buffer and stored at 4 ºC in FACS buffer overnight. On the following day, cell pellets were resuspended in 5 ml of permeabilization buffer containing 5% FBS for 30 min at RT. Cells were subsequently stained with PE-conjugated anti-MYC antibody (1:50) in 0.5 ml of permeabilization buffer containing 5% FBS and Fc blocking solution (1:100) for 1 h at RT, while protected from light. Cells were washed 3× with FACS buffer, strained through a 40-µM mesh and sorted in PBS containing 1% FBS, 1 mM EDTA and 25 mM HEPES on FACSAria II or FACSAria III cell sorters operated by BD FACSDiva software (v8.0). Aggregates, dead (Zombie Aqua positive), Cas9-negative (GFP) and sgRNA library-negative (Thy1-APC) cells were excluded, and the 5% of cells with the lowest and 1% of cells with the highest MYC-PE signal were sorted into PBS containing 5% BSA. At least 5 × 106 (MYClo) and 350,000 (MYChi) cells were collected for each cell line at each time point. For K562 cells, two independent sorts were performed for the early time point. Additionally, populations centred around the median MYC-PE signal were collected to obtain a neutral control population (MYCmid). All collected fractions were re-analysed for purity, and fractions with more than 5% cross-contamination were discarded before further processing.
For the MIA-PaCa-2 screen, cells were split into two technical replicates before intracellular staining and sorting by FACS. For intracellular MYC stainings, library-transduced cells were fixed with 2% PFA and permeabilized with MeOH as described above, and volumes were adjusted as for RKO and K562 screens. Cells with the 1% highest and 1% lowest MYC-PE signal were sorted, and, for each gate and replicate, at least 500,000 cells were collected. The gating strategy for flow cytometric cell sorting is shown in Supplementary Fig. 2.
Generation of next-generation sequencing libraries
Next-generation sequencing (NGS) libraries of sorted cell fractions and unsorted control populations were prepared as previously described12. In brief, genomic DNA was isolated by cell lysis (10 mM Tris-HCl, 150 mM NaCl, 10 mM EDTA, 0.1% SDS), proteinase K treatment and DNAse-free RNAse digest (10977035, Thermo Fisher Scientific), followed by two rounds of phenol extraction and 2-propanol precipitation. Isolated genomic DNA was subjected to several freeze–thaw cycles before nested polymerase chain reaction (PCR) amplification of the sgRNA cassette.
Barcoded NGS libraries for each sorted population were generated using a two-step PCR protocol. The first PCR was performed using 0.2 μl of AmpliTaq Gold (4311820, Invitrogen) in 50-μl reactions containing 1 μg of genomic DNA. For each sample, the resulting PCR products were pooled and purified using MBSpure magnetic PCR purification beads (in-house) and used as input for a second PCR introducing the standard Illumina adapters using 10 ng of DNA template. The final Illumina libraries were pooled and sequenced on a HiSeq 2500 platform (Illumina). Primers used for library amplification are listed in Extended Data Table 1.
Analysis of pooled CRISPR screens
To quantify raw sequencing reads, we developed the crispr-process-nf Nextflow workflow, available at https://github.com/ZuberLab/crispr-process-nf. In brief, all guides in the sgRNA library were padded with Cs to equal length before creating an index for Bowtie 2 (v2.3.0)39. Random 6mer nucleotides were trimmed using the fastx_trimmer from the fastx-toolkit (v0.0.14) (http://hannonlab.cshl.edu/fastx_toolkit/) before demultiplexing by 4mer sample barcodes with fastx_barcode_splitter (--mismatches 1 --bol). Next, barcodes and 20mer spacers were trimmed using fastx_trimmer, and reads were aligned with Bowtie 2 (-L 18 --score-min ‘C,0,−1’ -N 0 --seed 42) and quantified with featureCounts (v1.6.1)40.
To calculate enrichment or depletion of sgRNAs, we implemented the crispr-mageck-nf Nextflow workflow, available at https://github.com/ZuberLab/crispr-mageck-nf. First, count tables were filtered to exclude sgRNAs with fewer than 50 counts in control and sorted samples before further downstream analyses. Read counts were median normalized, and average log2 fold changes (LFCs), P values and false discovery rates (FDRs) were calculated using MAGeCK (0.5.9)41. If sorted samples had a median of 0, +1 pseudocount was added to each sgRNA for each sample included in the analysis. To calculate enrichment of sgRNAs in sorted populations, sgRNA counts within the sorted populations were compared to sorted MYCmid populations. For MIA-PaCa-2 cells, sgRNA enrichments were calculated against unsorted populations harvested on the day of sorting. Variance modelling within MAGeCK was set to estimate sgRNA variances based on MYCmid populations (RKO and K562) or unsorted populations (MIA-PaCa-2) from two different time points. To calculate enrichment or dropout of sgRNAs in unsorted populations over time, sgRNAs within unsorted populations were compared to initial Day 0 populations.
For each cell line, the gene-level sgRNA enrichments in the MYChi or MYClo populations for the two sorted time points were merged into one dataset representing the maximum effect of the two time points for each gene. Specifically, the gene-level LFCs of each dataset were median-normalized, and, for each gene, the time point with the more significant P value was included in the merged dataset. If the P values of the two time points were equal, the time point with maximum gene-level LFCs was chosen. GO terms were annotated using the GO.db and org.Hs.eg.db (both v3.11.4) Bioconductor packages in R.
Gene expression analysis
To evaluate MYC and MYCN expression in different cell lines, RPKM-normalized gene expression data were obtained from Klijn et al.42.
To assess transcriptional functions of AKIRIN2, iCas9-RKO cells were transduced with AKIRIN2-, PSMA3- or AAVS1-targeting sgRNAs (pLentiv2-U6-sgRNA-PGK-GFP-P2A-NeoR), and sgRNA+ cells were selected with G418. For each sgRNA, Cas9 expression was induced with DOX, and, 2 d (sgAKIRIN2 and sgAAVS1) or 3 d (sgPSMA3) after Cas9 induction, cells were washed, pelleted and snap-frozen. RNA was isolated using the NEBNext Poly(A) mRNA Magnetic Isolation Module (New England Biolabs). NGS libraries were prepared using the NEBNext Ultra RNA Kit (New England Biolabs) according to the manufacturer’s instructions and sequenced on a HiSeq 2500 platform (Illumina).
Before alignment, 3′-adaptors were removed using cutadapt (v1.4.2)43, and trimmed reads with a length shorter than 18 base pairs were discarded. Contaminating rDNA sequences (KY962518.1, NR_023363.1 and ERCC.fa) were filtered out using Bowtie 2 (v2.1.0)39, and the remaining reads were aligned to the human genome (GRCh38; GCA_000001405.15) and transcriptome (ENSEMBL build 78) using STAR-align (v2.4.2a)44. For differential gene expression analysis, read counts for genes were quantified using featureCounts (v1.6.4)40, with all human hg38 refSeq45 genes (accessed 2 May 2016) as reference. Differential gene expression analysis was performed using DESeq2 (v1.22.2)46 (Benjamini–Hochberg-corrected Wald test) and LFC shrinking with apeglm (v1.4.2)47. For downstream analysis, only genes with 5 or more transcripts per million (TPM) in sgAAVS1control samples were considered. Direct TP53 target genes were obtained from ref. 20. Principal component analysis was performed with the factoextra R package on the 1,000 most highly expressed genes.
Quantitative proteomics
To systematically assess protein changes after AKIRIN2 or proteasome knockout, iCas9-RKO cells were prepared as described for gene expression analysis, and, 2 d (sgAKIRIN2 and sgAAVS1) or 3 d (sgPSMA3) after Cas9 induction, 3–5 × 106 cells were washed, pelleted and snap-frozen for each condition.
Samples were prepared and analysed by liquid chromatography–tandem mass spectrometry (LC–MS/MS), as previously described3. In brief, cell pellets were resuspended in lysis buffer (10 M urea, 50 mM HCl) for 10 min at RT and adjusted to pH 8 using 1 M triethylammonium bicarbonate buffer (TEAB). Samples were treated with 10 mM dithiothreitol (DTT) and benzonase (37 ºC, 1 h, Merck), before iodoacetamide (IAA) was added for alkylation (15 mM, 30 min, RT), followed by quenching with DTT (15 mM, 30 min, 37 ºC). Next, 300 µg of protein per sample was diluted with 100 mM TEAB to a final urea concentration of 6 M and subjected to proteolysis with lysyl endopeptidase (Lys-C, Fujifilm Wako Chemicals, 3 h, 37 ºC), followed by dilution to 2 M urea and overnight digestion with trypsin (1:50, enzyme:protein, 37 ºC, Trypsin Gold, Promega). Samples were de-salted using SEP-PAK C18 solid phase extraction cartridges (WAT054960, Waters) after adjusting the pH to 2. Peptides were eluted with 80% acetonitrile (ACN, Chromasolv, gradient grade, Sigma-Aldrich) and 0.1% formic acid (FA, Suprapur, Merck), followed by freeze-drying. Isobaric labelling was performed using the tandem mass tag (TMT) 11-plex reagents (90110 and A34808, Thermo Fisher Scientific) according to the manufacturer’s instructions, followed by equimolar pooling of samples and de-salting by a C18 column. Samples were fractionated into 140 fractions by strong cation exchange (SCX) chromatography using 250 µg of peptide and an UltiMate 3000 Rapid Separation system (Thermo Fisher Scientific) at a flow rate of 35 µl min−1 and a TSK SP-2SW SCX column (1 mm ID × 300 mm, 5-µm particle size, Tosoh Bioscience). Fractions along the gradient were collected every minute for 140 min; the flow-through was collected as a single fraction; and all fractions were stored at −80 ºC until MS analysis.
LC–MS was performed using an UltiMate 3000 HPLC RSLC nano system (Thermo Fisher Scientific) coupled to a Q Exactive HF-X mass spectrometer (Thermo Fisher Scientific) equipped with a Proxeon nanospray source (Thermo Fisher Scientific). The Q Exactive HF-X mass spectrometer was operated in data-dependent mode, using a full scan (m/z range of 375–1,650, nominal resolution of 120,000, target value of 3 × 106), followed by MS/MS scans of the ten most abundant ions using normalized collision energy of 35, isolation width of 0.7 m/z, resolution of 45,000, a target value of 105 and a maximum fill time of 250 ms. For the detection of the TMT reporter ions, a fixed first mass of 110 m/z was set for the MS/MS scans. Precursor ions selected for fragmentation (exclude charge states 1, 7, 8 and >8) were dynamically excluded for 60 s; the minimum AGC target was set to 104; and the intensity threshold was set to 4 × 104.
For peptide identification, the RAW files were loaded into Proteome Discoverer (v2.3.0.523, Thermo Fisher Scientific), and the MS/MS spectra were searched using MS Amanda (v2.3.0.12368)48 against the Swiss-Prot Homo sapiens database (20,339 sequences and 11,360,750 residues) with IAA derivative on cysteine and 11-plex TMT on lysine as fixed modifications and deamidation on asparagine and glutamine; oxidation on methionine; phosphorylation on serine, threonine and tyrosine; and carbamylation and 11-plex TMT on peptide-N-terminus as variable modifications. Peptide mass tolerance was set to ±5 p.p.m. and fragment mass tolerance to ±15 p.p.m. The result was filtered to 1% FDR on protein level using the Percolator algorithm, and peptides were quantified based on reporter ion intensities extracted by the ‘Reporter Ions Quantifier’ node in Proteome Discoverer. Proteins were quantified by summing unique peptides, and protein-abundance normalization was done using sum normalization. The statistical significance of differentially expressed proteins was determined in limma (PD-Node v1.18.7822.12969)49 using a two-sided moderated limma t-test with Benjamini–Hochberg correction. A manually curated list based on the CRAPome50 and MaxQuant51 databases was used to call contaminants. Proteins with three or more unique identified peptides detected in quantitative proteomics are shown in Fig. 3.
Next, 7,332 proteins with three or more unique peptides and baseline mRNA expression of 5 or more TPM in RNA-seq were considered for further analyses. Of these, genes showing a significant upregulation of protein levels (FC ≥ 1.5 and adjusted P ≤ 0.01) after knockout of AKIRIN2 or PSMA3 compared to sgAAVS1 control, but no strong or significant upregulation of transcript levels (LFC ≤ 1 or adjusted P ≥ 0.01), were classified as ‘AKIRIN2 targets’ (124 genes) or ‘proteasome targets’ (289 genes), respectively. Genes passing these filters in both conditions were defined as ‘AKIRIN2-responsive proteasome targets’ (89 genes), whereas proteasome targets that showed no significant accumulation after AKIRIN2 knockout (FC ≤ 1.3 or adjusted P ≥ 0.01) were classified as ‘AKIRIN2-independent proteasome targets’ (153 genes). GO term enrichment analyses were performed for these two gene sets independently using PANTHER52 two-tailed Fisher’s exact test (release 20200407) with Benjamini–Hochberg multiple testing correction on the GO database (release 2020-06-01), and, for each GO term, the FDR ratio of AKIRIN2-responsive and AKIRIN2-independent gene sets was calculated (ΔFDR).
Protein half-life quantification
To estimate AKIRIN2 and MYC protein half-lives, iCas9-RKO cells expressing sgAKIRIN2 or sgAAVS1 control were treated with DOX for 2 d before translational elongation was inhibited using 10 μg ml−1 of cycloheximide (CHX). Cells were harvested at regular intervals between 30 min and 4 h after CHX addition, and AKIRIN2 and MYC protein levels were evaluated by immunoblot on a ChemiDoc Touch imaging system (Bio-Rad) operated by Image Lab (v2.2.0.08) and quantified using Image Studio Lite (v5.2). Background-subtracted signal was normalized to time point 0 and to vinculin or β-actin loading control, and half-lives were calculated in GraphPad Prism (v8.1.1) using non-linear fit (exponential one-phase decay with plateau constraint > 0). Uncropped and unprocessed immunoblot scans are provided in Supplementary Fig. 1.
AKIRIN2 sequence and motif analysis
Akirin orthologs were determined using NCBI BLAST53 searches of human AKIRIN2 (UniProt: Q53H80) or AKIRIN1 (UniProt: Q9H9L7) against UniProt reference proteomes (release 2020_02) or the NCBI non-redundant protein database (status, 20 July 2020), and the relatedness of sequences from selected model organisms was compared to both human AKIRIN paralogues based on BLASTP (v2.8.1) E values. To calculate the prevalence of Akirin proteins in metazoans, a species set including 53 UniProt metazoan reference proteomes was used, and orthogroups were assigned using OrthoFinder (v2.4.0)54. Akirin2 and Akirin1 were combined into one orthogroup that was found in 51 of 53 metazoan species (96%).
Of a manually curated set of 77 organisms that were selected for high taxonomic diversity, all 107 Akirin orthologues with a significant hit in the UniProt reference proteomes were selected. These sequences were aligned, and seven sequences with no alignment in the C-terminal motif were excluded from further analyses. From the remaining 100 sequences, a conservation score was calculated using aacon (1.1) and mapped on human AKIRIN2. The last eight residues of the C-terminus were extracted, and the sequence logo was created using WebLogo 3 (ref. 55). A selection of 15 full-length sequences from 11 taxa, including the Akirin1 and Akirin2 paralogues from widely used model organisms, were aligned with MAFFT (v7.427)56 and visualized in Jalview (v2.11)57. To illustrate the C-terminal conservation, the same sequence set was used, but Akirin1 paralogues were omitted owing to space constraints. The disorder score was calculated using PrDOS58. The bipartite nuclear localization signal (amino acids 6–27) was called using cNLS Mapper (version 2012/11/7)59; the alanine-rich region (amino acids 28–56) was annotated based on UniProt; and the α-helix (amino acids 78–92) was identified using Jnet v2.3.1 (ref. 60) via the JPred4 server61. The coiled-coil region (amino acids 157–177) was predicted using NCOILS (v2.2)62.
Generation of reporter cell lines
For MYC reporter cells, pLX303-SFFV-mCherry.MYC-P2A-BFP was transduced into iCas9-RKO cells, and single cells co-expressing mCherry and BFP were FACS-purified into 96-well plates to obtain single-cell-derived clones.
For the engineering of fluorescent 20S and 19S proteasome reporter cell lines, cDNAs encoding sgRNA-resistant, C-terminally FLAG–mCherry-tagged human PSMB4 (pRRL-SFFV-PSMB4.FLAG.mCherry) or N-terminally mCherry–FLAG-tagged PSMD3 (pRRL-SFFV-mCherry.FLAG.PSMD3) were lentivirally delivered into iCas9-RKO cells expressing PSMB4- or PSMD3-targeting sgRNAs (pRRL-U6-sgRNA-EF1αs-Thy1-P2A-NeoR). To assess the ability of fluorescently tagged proteasome subunits to rescue the knockout of the corresponding endogenous gene, Cas9 expression was induced, and survival of sgRNA and cDNA double-positive cells was monitored in competitive proliferation assays. At least 7 d after Cas9 induction, cDNA and sgRNA double-positive cells were sorted into 96-well plates to obtain single-cell-derived clones. Loss of endogenous PSMB4 or PSMD3 and ectopic expression of PSMB4–mCherry or mCherry–PSMD3, respectively, were verified in selected clones by immunoblot using anti-PSMB4, anti-PSMD3 and anti-FLAG antibodies. Incorporation of fluorescently labelled proteasome subunits into fully assembled proteasome particles was evaluated by 10–30% (w/v) sucrose gradient centrifugation of whole cell lysates followed by SDS–PAGE, fluorescent detection of mCherry (550/605 nm) and immunoblotting.
To generate IBB–GFP reporter cells, single-cell-derived PSMB4–mCherry reporter cells were lentivirally transduced with the C-terminally GFP-tagged importin-β binding domain of importin-α (pLentiv2-EF1αs-IBB.GFP-IVS-IRES-BlastR) and sorted for GFP expression on a FACSAria III cell sorter (BD Biosciences).
V5 co-IP/MS
For co-IP/MS studies, RKO cells were lentivirally transduced with SFFV-3xV5.AKIRIN2-IRES-mCherry, SFFV-3xV5.AKIRIN2ΔYVS-IRES-mCherry, SFFV-3xV5.AKIRIN1-IRES-mCherry or SFFV.3xV5-GFP-IRES-mCherry at high MOI and treated with 10 μM MG132 (MedChemExpress) for 2 h before harvest. Cells were washed 2× with ice-cold PBS, collected from plates using a cell scraper and snap-frozen for later processing. Cell pellets were lysed with NP-40 lysis buffer (50 mM HEPES pH 7.3, 120 mM NaCl, 10 mM MgCl2, 0.1 mM EDTA, 0.5% NP-40, 1 mM NaF, 2 mM Na3VO4) supplemented with 1× cOmplete, EDTA-free Protease Inhibitor Cocktail (Roche) on ice for 30 min in low-retention tubes, and lysates were cleared by centrifugation for 15 min at 14,000g at 4 ºC.
V5 tag antibody was coupled to Protein G Mag Sepharose Beads (GE Healthcare) for 2 h at 4 ºC in NP-40 buffer with rotation (2.2 µg of antibody per 5 µl of bead slurry). Antibody-coupled beads were washed 2× with NP-40 buffer, and 850 µg of protein lysate was incubated with 3 µl of bead slurry for 3 h at 4 ºC with rotation. Beads were transferred to fresh tubes and washed 4× with ice-cold lysis buffer for 20 min at 4 ºC and 6× with ice-cold wash buffer (20 mM HEPES pH 7.3, 120 mM NaCl). Pelleted beads were covered with 15 µl of 100 mM ammonium bicarbonate or wash buffer and stored at 4 ºC until processing for MS the following day.
Beads were resuspended in 50 μl of 100 mM ammonium bicarbonate buffer supplemented with 400 ng of Lys-C and incubated for 4 h at 37 ºC while shaking. The supernatant was transferred to a fresh tube and reduced with 0.5 mM Tris 2-carboxyethyl phosphine hydrochloride (TCEP, Sigma-Aldrich) for 30 min at 60 ºC and alkylated in 3 mM methyl methanethiosulfonate (Fluka) for 30 min at RT protected from light before digest with 400 ng of trypsin (Trypsin Gold, Promega) at 37 ºC overnight. The digest was acidified by the addition of trifluoroacetic acid (TFA, Pierce) to 1%. A similar aliquot of each sample was analysed by LC–MS/MS.
The eluted peptides were analysed using an UltiMate 3000 RSLC nano HPLC system coupled to an Orbitrap Fusion Lumos, a Q Exactive HF-X or an Orbitrap Exploris 480 mass spectrometer. Peptides were loaded onto a trap column (Thermo Fisher Scientific, PepMap C18, 5 mm × 300 μm ID, 5-μm particles, 100-Å pore size) at a flow rate of 25 μl min−1 using 0.1% TFA as mobile phase. After 10 min, the trap column was switched in line with the analytical column (Thermo Fisher Scientific, PepMap C18, 500 mm × 75 μm ID, 2-μm particles, 100-Å pore size) and eluted using a flow rate of 230 nl min−1 and a binary 3-h gradient ramping from 1.6% to 28% ACN in 0.1% FA.
For data acquisition, the Orbitrap Fusion Lumos mass spectrometer (Thermo Fisher Scientific), equipped with an EASY-spray ion source (Thermo Fisher Scientific) and JailBreak 1.0 adaptor insert for a spray emitter (Phoenix S&T) was operated in data-dependent mode, using a full scan (m/z range of 380–1,500, Orbitrap resolution of 120,000 and target value of 4 × 105) followed by MS/MS scans for a cycle time of 3 s, applying an isolation width of 1.0 m/z, HCD fragmentation with collision energy of 30, resolution of 30,000, target value of 2 × 105, maximum fill time of 150 ms and intensity threshold of 2.5 × 104. Precursor ions, including charges 2–6, were selected for fragmentation before being excluded for 60 s.
The Q Exactive HF-X mass spectrometer, equipped with a Nanospray Flex ion source (both Thermo Fisher Scientific), was operated in data-dependent mode, using a full scan (m/z range of 380–1,500, resolution of 60,000, target value of 1 × 106) followed by MS/MS scans of the ten most abundant ions. MS/MS spectra were acquired using normalized collision energy of 28, isolation width of 1.0 m/z, resolution of 30,000, target value of 1 × 105 and maximum fill time of 105 ms. Precursor ions, including charges 2–6, were selected for fragmentation before being excluded for 60 s. Additionally, the minimum AGC target was set to 5 × 103, and the intensity threshold was calculated to be 4.8 × 104. The peptide match feature was set to preferred, and the exclude isotopes feature was enabled.
The Orbitrap Exploris 480 mass spectrometer, equipped with a FAIMS pro interface and a Nanospray Flex ion source (all parts Thermo Fisher Scientific), was operated in data-dependent mode, performing a full scan (m/z range of 350–1,200, resolution of 60,000 and target value of 1 × 106) at two different compensation voltages (CVs) (−45 and −60), each followed by MS/MS scans of the most abundant ions for a cycle time of 1 s per CV. MS/MS spectra were acquired using a collision energy of 30, an isolation width of 1.0 m/z, a resolution of 45,000, a target value of 2 × 105 and an intensity threshold of 1 × 104. Precursor ions selected for fragmentation (including charge states 2–6) were excluded for 45 s. The peptide match feature was set to preferred, and the exclude isotopes feature was enabled.
For peptide identification, the RAW files were loaded into Proteome Discoverer (v2.3.0.523 and v2.5.0.400), and the created MS/MS spectra were searched using MS Amanda (v2.3.0.14114 and v2.5.0.16129)48 against the Swiss-Prot (20,593 sequences and 11,422,650 residues) or the UniProt H. sapiens reference proteome database (release 2021_01) supplemented with common contaminants, with mass tolerance ±5 p.p.m, fragment mass tolerance ±15 p.p.m. and number of missed trypsin cleavages ≤ 2. Results were filtered with a 1% FDR cutoff to generate a sub-database that was searched by setting Cys β-methylthiolation as fixed and oxidation on Met; deamidation on Asn and Gln; acetylation on Lys; phosphorylation on Ser, Thr and Tyr; methylation and di-methylation on Lys and Arg; tri-methylation on Lys; ubiquitination on Lys; carbamylation on Lys; and biotinylation on Lys as variable modifications. Peptide areas and proteins were quantified using the in-house-developed tool apQuant (v3.2.12.17949)63 by intensity-based absolute quantification (iBAQ) of unique peptides and sum normalization. Average enrichment between bait and control immunoprecipitation experiments was plotted against P values calculated using a limma two-sided moderated t-test in the limma R package.
Expression and purification of recombinant AKIRIN2
Rosetta 2 E. coli cells (71402, Novagen) were transformed with pETM33-T7-His.GST.3C.AKIRIN2 expression plasmid, and overnight cultures were grown at 37 ºC in liquid LB medium at 180 r.p.m. in the presence of appropriate antibiotics. Large-scale expression was performed in auto-induction (ZY) medium64. The cells were grown for 5 h at 37 ºC followed by 40-h growth at 18 ºC, harvested by centrifugation (4,000g, 15 min) and stored at −80 ºC. For protein purification, the cells were resuspended in lysis buffer (20 mM Tris-HCl pH 8.0, 500 mM NaCl, 0.5 mM TCEP) containing cOmplete Protease Inhibitor Cocktail (Roche) and benzonase. Cells were lysed in a cell disruptor (Constant Systems) at 1.34 kbar for one cycle. Lysates were clarified by centrifugation (42,000g, 45 min, 4 ºC), and recombinant protein was obtained using a four-step purification protocol based on an ÄKTA Protein Purification System (GE Healthcare Life Sciences). In brief, the supernatant was applied to a His-Trap Excel 5-ml column (GE Healthcare Life Sciences) equilibrated with equilibration buffer (20 mM Tris-HCl pH 8.0, 500 mM NaCl, 0.5 mM TCEP), and the protein was eluted using a step gradient of imidazole (250−500 mM in equilibration buffer). Fractions were examined by SDS-PAGE for protein content and purity and pooled according to the presence of His-GST-AKIRIN2. Pooled protein fractions were dialysed overnight against buffer ResQA (20 mM Tris-HCl pH 8.0, 50 mM NaCl, 0.5 mM TCEP) and applied to a Resource Q 6-ml ion exchange column (GE Healthcare Life Sciences). The protein was then eluted using a linear gradient of NaCl from 0.05 M to 0.74 M in ResQA buffer. Next, the protein was applied to a GST Trap 5-ml column (GE Healthcare Life Sciences) equilibrated with buffer (40 mM Tris-HCl pH 8.0, 100 mM NaCl, 1 mM DTT) and eluted in a step gradient with the same buffer containing 15 mM reduced l-glutathione. Finally, the protein was applied to a HiLoad 16/600 Superdex 200 prep-grade column (GE Healthcare Life Sciences) equilibrated with proteasome buffer (25 mM Bis-Tris pH 6.5, 50 mM KCl, 5 mM MgCl2, 10% glycerol, 1 mM DTT). Eluted fractions were analysed by SDS-PAGE, pooled according to protein purity, concentrated and stored at −80 ºC until use. The identity of protein samples was confirmed by MS analysis as described above.
GST-AKIRIN2 co-IP/MS
For mass spectrometric analysis of GST-AKIRIN2 protein complexes, 2.5 nmol of purified bait protein was incubated with 7 ml of HeLa cell extract supplemented with 0.1 mg ml−1 of BSA, 4 mM ATP, 1 mM DTT, 0.1 mM phenylmethylsulfonylfluoride (PMSF) and cleared of cellular aggregates by centrifugation at 39,000g for 30 min at 4 ºC. MagneGST Glutathione Particles (Promega) were pre-incubated for 30 min with 2 mg ml−1 of BSA in buffer A (25 mM BisTris pH 6.5, 50 mM KCl, 5 mM MgCl2, 1 mM DTT, 4 mM ATP). Next, 200 µl of the slurry was added to each replicate and incubated overnight at 4 ºC on a rotating shaker. Beads were washed 5× with 2 ml of wash buffer. Proteins were eluted twice for 30 min at 4 ºC with 300 µl of buffer A supplemented with 25 mM GSH, 50 mM NaCl and 0.02% NP-40, and both elution samples were combined. Then, 200 µl of eluate was loaded on a 10–30% (w/v) sucrose density gradient prepared in buffer A. Gradients were run in an Optima XE-90 ultracentrifuge with a SW60Ti rotor (Beckman Coulter) for 16 h at 121,300g at 4 ºC, manually fractionated into 200-µl fractions and examined by SDS-PAGE.
Individual fractions were precipitated with 80% acetone, resuspended in 100 mM Tris pH 7.5 and reduced with 10 mM DTT at 95 ºC for 10 min. Samples were alkylated with 20 mM IAA for 30 min at RT, protected from light, before quenching with 5 mM DTT for 30 min at RT and digested with 400 ng of trypsin at 37 ºC overnight. The digest was acidified by the addition of TFA acid to 1%, and a similar aliquot of each sample was supplemented with 10-fmol of Pierce Retention Time Calibration (PRTC) peptide standard (Thermo Fisher Scientific) and analysed by LC–MS/MS on an UltiMate 3000 RSLC nano HPLC system coupled to an Orbitrap Exploris 480 mass spectrometer equipped with a Nanospray Flex ion source as described above, with the following modified parameters: elution gradient 1-h ramping from 1.6% to 28% ACN in 0.1% FA, m/z range of 380–1,200, collision energy of 28, resolution of 30,000, target value of 2 × 105, included charge states of 2–5, exclusion time of 30 s and peptide mass tolerance of ±10 p.p.m. Peptides were identified as described above, setting carbamidomethylation of Cys as fixed and oxidation of Met; phosphorylation on Ser, Thr and Tyr; deamidation on Asn and Gln; 13C6 15N4 SILAC label on arginine; and 13C6 15N2 SILAC label on lysine as variable modifications. Proteins were quantified as described above using iBAQ on unique and razor peptides and normalized to the sum of PRTC peptide standard areas.
Negative staining electron microscopy
For EM analysis, proteasomes were purified from HeLa cell lysates as described previously65,66. In brief, cell pellets were homogenized in purification buffer (25 mM Bis-Tris pH 6.5, 50 mM KCl, 5 mM MgCl2, 10% glycerol, 4 mM ATP, 1 mM DTT) supplemented with 0.1% Triton and 0.1 mM PMSF and clarified by centrifugation using an Optima XE-90 ultracentrifuge with a Ti45 rotor (Beckman Coulter) for 1 h at 120,000g and 4 ºC. Proteasomes were enriched using a two-step precipitation protocol with 4% and 20% PEG 8000. Precipitated proteins were dissolved in purification buffer.
The dissolved pellet was mixed either with purified His–GST–AKIRIN2 or with a GST-tagged ubiquitin-like domain of the known proteasome interactor RAD23B67 (UBL). Bound proteasomes were affinity-purified using magnetic beads (MagneGST Glutathione Particles, Promega). Proteasomes were eluted from the beads with purification buffer containing 25 mM reduced l-glutathione, concentrated and prepared for negative staining electron microscopy by fractionation on a 10–30% (w/v) sucrose gradient prepared in purification buffer. Gradients were run in an Optima XE-90 ultracentrifuge with a SW60Ti rotor (Beckman Coulter) for 16 h at 120,000g at 4 ºC, manually fractionated into 200-µl fractions and examined by SDS-PAGE.
Carbon-coated grids were produced using an Auto 306 high vacuum evaporator (Edwards) and glow-discharged in an SCD005 sputter coater (Bal-Tec) for 1 min at ~20 mA. Next, 4 µl of selected sucrose gradient fractions was applied to the grid and incubated for 30 s. Excess liquid was removed, and the grid was washed three times with water. Samples were stained in 4 µl of uranyl acetate solution (2% (w/v) in water and filtered through a 0.22-μm filter) for 1 min. The excess dye was removed, and the grids were air-dried and imaged. Then, 1,500 micrographs were recorded on a Tecnai G2 20 (FEI) transmission electron microscope operating at 200 keV at a magnification of ×62,000 (1.85 Å per pixel) using SerialEM (v3.8)68.
Data were processed using RELION (v3.0)69. Particles from ten micrographs were manually picked and used for initial two-dimensional (2D) classification. Class averages that showed clear particles were used for automated template picking on all 1,500 micrographs, and the resulting particles were classified in two dimensions. Class averages that showed clear proteasome densities were selected for ab initio reconstruction followed by three-dimensional (3D) refinement. The resulting maps were segmented and illustrated with ChimeraX (v1.1.1)70.
Cryo-EM image acquisition and processing
For cryo grid preparation, 4 µl of sample was applied to a Quantifoil R3.5/1 grid also containing a freshly glow-discharged continuous carbon film. The grids were blotted for 2 s at 4 ºC and 75% humidity in a Leica EMGP and subsequently plunge-frozen.
Cryo-EM data were collected at the Electron Bio-Imaging Centre, Diamond Light Source, UK, using Titan Krios (Thermo Fisher Scientific) operating at 300 kV equipped with an energy-filtered K3 detector (Gatan) at ×81,000 magnification and slit width of 20 eV. A total of 4,595 electron micrograph movies was obtained using EPU (v2.6), with three images per hole. Each movie contained 50 frames recorded over 2 s with a pixel size of 1.06 Å per pixel and total dose of ~33 e−/Å2. Global motion correction and dose weighting were performed in Cryosparc (v3.2)71 using patch motion correction. The power spectrum of aligned frames was used for contrast transfer function (CTF) estimation by CTFFIND (v4.1.13)72. Particles were picked using 2D templates in Cryosparc, and 1,427,356 particles were extracted with a pixel size of 4.24 Å per pixel and 150 × 150 pixel box. One round of reference-free 2D classification was performed to remove false-positive particle images. The resulting 287,009 particles were then used for ab initio reconstruction in Cryosparc using five classes, and 239,335 particles that belonged to 3D classes resembling 20S or 26S proteasomes were selected for further analysis in Relion (v3.1)73. Particles were re-extracted with a pixel size of 1.59 Å per pixel and 400 × 400 pixel box. 3D refinement while imposing C2 symmetry was then performed using a 20S proteasome structure (from ab initio reconstruction) filtered to 30 Å as the 3D reference. To select for proteasomes bound to AKIRIN2, the particles were symmetry expanded using the relion_particle_symmetry_expand function in Relion followed by signal subtraction using a mask around one RP of the proteasome and its adjacent half of the 20S-CP. Upon 3D classification, an AKIRIN2 density was detected in 261,980 of 487,710 half-particles (= 54.6%). These particles were re-extracted with a pixel size of 1.06 Å per pixel and 560 × 560 pixel box, resulting in 165,181 AKIRIN2-bound full particles (69% of initially 2D classified proteasome particles), which were further 3D refined while imposing C2 symmetry, resulting in a 3 Å structure (Fourier shell correlation (FSC) criterion = 0.143). CTF refinement was performed on the refined particles to correct for per-micrograph defocus, astigmatism and coma due to beam tilt. This was followed by symmetry expansion and particle subtraction as before, yielding 330,362 half-particles. After 3D classification, these AKIRIN2-density-containing half-particles were selected and used for the further 3D refinement. A mask was applied on the AKIRIN2 region, and focused 3D classification without alignment using shift and rotations parameters of the previous alignment was performed. A subset of 37,443 (~20%) half-particles with strong AKIRIN2 density was identified and further refined. Finally, the structure of AKIRIN2 bound to the 20S-CP was solved at 3.2 Å according to the 0.143 FSC criterion with local resolution of the AKIRIN2 C-terminus of ~3–5 Å. The final map was de-noised using deepEMhancer (20210511)74.
The crystallographic 20S proteasome structure (PDB-5LE5)75 was used as the initial model for the 20S-CP and docked into the EM densities as a rigid body using UCSF Chimera (1.13.1)76. An additional round of rigid body refinement was then performed in Refmac (v5.8.0091)77. AKIRIN2 was modelled manually into the cryo-EM map while taking guidance from structures predicted using the Robetta server78 and information from secondary structure prediction61. Two copies of AKIRIN2 were modelled, comprising residues 156–203 and 160–203. The model underwent several rounds of manual modelling in Coot (v0.8.8)79, Isolde (v1.2)80 and refinement in Phenix (v1.19.1-4122)81. The data processing and model building workflow is illustrated in Supplementary Fig. 3. The model chain ID and proteasome subunit nomenclature are shown in Supplementary Table 7. Data collection and model building statistics are shown in Supplementary Table 8.
Immunofluorescence microscopy
For immunofluorescence stainings of PSMA5 after inducible gene knockout, clonal iCas9-RKO mCherry–MYC reporter cells were lentivirally transduced with dual sgRNA expression plasmids (Dual-hU6-sgRNA-mU6-sgRNA-EF1αs-Thy1-P2A-NeoR) and selected for sgRNA expression with G418. Two sgRNAs targeting the same gene were used to increase editing efficiency in microscopy experiments. Before fixation, cells were treated with 0.2 μg ml−1 of DOX for 1–2 d to induce Cas9 expression, seeded onto µ-Slide eight-well ibiTreat pre-coated coverslips (Ibidi) or 12-mm round coverslips (Menzel) coated with poly-l-lysine and left to attach for 24–48 h. Cells were washed once with PBS and fixed on coverslips with 4% PFA for 15 min at RT. Residual PFA was quenched with 10 mM Tris-HCl, and cells were washed twice with PBS for 5 min. Cells were permeabilized with ice-cold MeOH, incubated at −20 ºC for 15–20 min and washed twice again with PBS before blocking for 1 h in blocking solution (PBS, 5% FBS). Cells were stained with anti-PSMA5 antibody (1:50, 1 μg ml−1) or concentration-matched isotype control for 3 h at RT, protected from light, washed three times with PBS for more than 5 min and subsequently stained with AF647 anti-rabbit secondary antibody (1:1,000) for 1 h at RT, protected from light. Cells were washed once with PBS and incubated with Hoechst 33342 (1 μg ml−1 in PBS, Invitrogen) for 5 min before washing twice with PBS. Coverslips were covered with PBS or liquid mounting medium (Ibidi) before imaging or mounted onto microscopy slides (Menzel) using one drop of ProLong Diamond Antifade Mountant (Thermo Fisher Scientific).
For V5-AKIRIN2 stainings, iCas9-RKO cells were lentivirally transduced with SFFV-V5.AKIRIN2-IRES-mCherry, bulk sorted for mCherry expression and subsequently transduced with an sgRNA expression vector (pRRL-U6-sgAKIRIN2-EF1αs-Thy1-P2A-NeoR). G418-selected cells were induced with 0.2 μg ml−1 of DOX to knock out endogenous AKIRIN2, cultured for more than 1 week and subsequently seeded onto µ-Slide eight-well ibiTreat pre-coated coverslips (Ibidi). Cells were fixed with 4% PFA as described above and permeabilized with PBS containing 5% FBS and 0.2% Triton X-100 for 1 h at RT. Cells were stained with anti-V5 antibody (1:500) in antibody dilution buffer (PBS, 1% BSA, 0.2% Triton X-100) for 3 h at RT, washed three times with antibody dilution buffer and stained with anti-rabbit AF647 (1:1,000) for 1 h at RT, protected from light. Cells were washed with PBS, counterstained with Hoechst as described above and covered with liquid mounting medium (Ibidi) before imaging.
All immunofluorescence stainings were imaged with a Zeiss LSM880 or Zeiss LSM980 confocal microscope operated by ZEN Black (v2.3) or ZEN Blue (v3.1, Zeiss) software, respectively, and a ×40, 1.4 NA oil DIC plan-apochromat objective (Zeiss). Tile regions were stitched using ZEN Blue (v3.1). Representative images presented in the manuscript were adjusted for colour balance without changing luminescence in Adobe Photoshop 2020.
Confocal microscopy of reporter cell lines
PSMB4–mCherry, mCherry–PSMD3 and mCherry–MYC reporter cells were transduced with dual sgRNA expression plasmids (Dual-hU6-sgRNA-mU6-sgRNA-EF1αs-CD2 or Dual-hU6-sgRNA-mU6-sgRNA-EF1αs-Thy1-P2A-NeoR) and subsequently sorted for CD2 expression on a FACSAria III cell sorter or selected using G418, respectively.
For confocal imaging of reporter cells upon time-controlled knockout, Cas9 expression was induced with DOX for 36–48 h (sgAKIRIN2 and sgAAVS1 control) or 7 d (sgIPO9 and sgAAVS1 control). Before imaging, cells were seeded onto µ-Slide eight-well ibiTreat pre-coated coverslips (Ibidi) and stained with 200 nM SiR-Hoechst82 (Spirochrome) for 1–2 h to visualize DNA. Two to three 2 × 2 tile regions were imaged per well on a Zeiss LSM980 or LSM880 confocal microscope and a ×40, 1.4 NA oil DIC plan-apochromat objective (Zeiss). Tile regions were stitched using ZEN Blue (v3.1).
Live cell microscopy
For time-lapse imaging of iCas9-RKO mCherry–MYC reporter cells after inducible AKIRIN2 knockout, cells were transduced with sgRNA expression vectors (pLentiV2-U6-sgRNA-PGK-iRFP720) and sorted for iRFP expression on a FACSAria III cell sorter operated by BD FACSDiva (v8.0). Cells were seeded onto µ-Plate 24-well black polymer coverslips (TC treated, Ibidi), induced with DOX and imaged for 96 h using a Celldiscoverer 7 microscopy system (Zeiss) operated by Zen Blue Celldiscoverer (v3.1, Zeiss) and a ×20 plan-apochromat objective (Zeiss) with one image every 2 h.
For confocal time-lapse imaging of PSMB4–mCherry and mCherry–MYC reporter cells after inducible AKIRIN2 or AAVS1 knockout, dual-sgRNA-expressing reporter cells were seeded onto chambered µ-Slide eight-well ibiTreat pre-coated coverslips (Ibidi) and induced with DOX for 15–22 h before imaging. To visualize DNA, cells were stained with 200 nM SiR-Hoechst 1–2 h before imaging. One 2 × 2 tile region was imaged on a Zeiss LSM980 confocal microscope and a ×40, 1.4 NA oil DIC plan-apochromat objective (Zeiss) for 10 h every 10 min. For representative single-cell time-lapse images of PSMB4–mCherry reporter cells, prophase cells were manually selected and imaged on a Zeiss LSM880 confocal microscope and a ×63, 1.4 NA oil DIC plan-apochromat objective (Zeiss) for 1–2 h every 5 min. To maintain cells in focus during mitosis, five z slices with 2.5-μm spacing were acquired for all time-lapse recordings. All microscopes were equipped with an incubator chamber to maintain a humidified atmosphere at 37 ºC with 5% CO2. Imaged tile regions were stitched using ZEN Blue (v3.1).
To assess the timing of nuclear proteasome import, PSMB4–mCherry reporter cells co-expressing IBB–GFP were imaged on a Zeiss LSM980 confocal microscope and a ×40, 1.4 NA oil DIC plan-apochromat objective (Zeiss) for 10 h every 10 min, as described above.
Quantification of microscopy images
A custom script was used in ImageJ/Fiji (v1.52p) to quantify nuclear and cytoplasmic signal intensities for microscopy data. The nucleus was segmented as follows. In the DNA channel, borders and internal structures were enhanced using a variance filter (radius = 4) and converted to a binary using a fixed threshold. A closing operation was applied, small holes were filled and nucleus objects were separated by a binary watershed. The mask was used to define regions of interest (ROIs; ‘nucleus’) using Fiji’s ‘Analyze Particles’ function. Cell borders were defined by segmentation of the proteasome channel after applying a Gaussian blur filter (sigma = 5) and a fixed threshold that was defined by auto-thresholding (‘Huang’ method) of one of the images. From this cell mask, the nuclear ROIs were subtracted to create a cytoplasmic mask. A Marker-controlled Watershed algorithm (MorpholibJ plugin, https://imagej.net/MorphoLibJ) was used to separate neighbouring cells. Mean intensities of the proteasome channel in the defined nuclear and cytoplasmic areas were measured after setting outside values to NaN (not a number). Debris and fragmented nuclei with a nucleus size less than 30% of the mean nucleus size per well or a cell size smaller than 10 µm2 were excluded from further analysis, and each experiment was normalized to the mean nuclear sgAAVS1 signal.
Quantification of time-lapse imaging experiments
For quantification of nuclear mCherry or IBB–GFP reporter proteins in dividing cells during time-lapse imaging, three custom ImageJ macros were used to track dividing cells, extract central z slices and quantify nuclear mCherry, GFP and SiR-Hoechst signal. First, cells undergoing a cell division within the analysed tile region were selected and tracked manually using the ‘Manual Tracking’ plugin (https://imagej.nih.gov/ij/plugins/track/track.html). At anaphase onset, one of the two chromosome ensembles was randomly chosen for quantification, and the manually selected centre points were used to export cropped movies of the individual cells in three dimensions. For time-lapse imaging of mCherry-reporter cells upon AAVS1 or AKIRIN2 knockout, all mitotic cells within the analysed tile regions were tracked. For PSMB4–mCherry reporter cells co-expressing IBB–GFP, a subset (n = 15, N = 2) of mitotic cells present in the analysed tile region was manually tracked. In a second step, the central z section of the nuclei was defined separately for each frame by selecting for slices with the largest chromatin area in x–y and exported to a 2D time course. Nucleus segmentation was performed by auto-thresholding (‘Triangle’ method) a Laplacian of Gaussian filtered image of the SiR-Hoechst signal. To avoid fragmentation of the nuclei, holes in the mask were segmented separately, modified by erosion and median filtering and then added to the original mask to connect structures while maintaining clearly defined object borders. During mitosis and upon nuclear disassembly, only the chromosomal object closest to the image centre was used for measurement. All scripts are available upon reasonable request.
Frames containing cells out of focus or ROIs that extended to neighbouring cells or debris were manually excluded, and data were plotted in R. To normalize single-cell time-lapse movies to cell division, the frame with the highest mean chromatin channel intensity over time (corresponding to the time point of maximum mitotic chromatin condensation) was set to time point 0 (t0), and frames were plotted relative to t0 for each cell. The mean mCherry or GFP signal of all quantified cells and 95% confidence intervals were plotted for each sgRNA.
Statistical analysis
For all experiments, the sample number and the number of biological replicates are provided in the figure legends. Microsoft Excel 2016 (v16.0.11601.20130) was used to organize data into tables. Statistical analyses were performed with the R (v4.0.2) programming environment using RStudio (v1.3.1073 and v1.1.456). For statistical analyses of CRISPR screens, RNA-seq, quantitative proteomics, co-IP/MS and GO term enrichment, published statistics packages were used as stated in the respective Methods sections. For microscopy image analysis, the mean signal was normalized to control (sgAAVS1). Normal distribution of replicate values was tested using a Shapiro–Wilk test in R, and the significance of normally distributed data was tested using an unpaired two-sided Welch’s t-test in R.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this paper.
Data availability
Source data for Figs. 1d, e, 2a, b, 3a, b, d, 4e, f and Extended Data Figs. 2, 4a, b, g, i, 5f, 6d are included in the Supplementary Information files of the manuscript. Raw FASTQ files for RNA-seq analyses are available through the Gene Expression Omnibus (accession code GSE157663). Negative staining and cryo-EM density maps are deposited in the Electron Microscopy Data Bank with the accession codes EMD-11649 and EMD-12341, respectively. The atomic model is deposited under Protein Data Bank ID 7NHT. Raw micrographs and particle stacks are available in the EMPIAR database (EMPIAR-10752). TMT quantitative proteomics, V5 and GST co-IP/MS data have been deposited to the ProteomeXchange Consortium PRIDE repository with the accession codes PXD021898, PXD027184 and PXD027343, respectively. Human cancer cell line RNA-seq data were obtained from the ArrayExpress repository (https://www.ebi.ac.uk/arrayexpress/experiments/E-MTAB-2706). AKIRIN2 interactors identified in this study were cross-compared to the BioGRID database (https://thebiogrid.org/120430/summary/homo-sapiens/akirin2.html). The crystallographic native human 20S proteasome structure used for model building and the cryo-EM structure of the substrate-engaged human 26S proteasome shown for comparison in Extended Data Fig. 7f were obtained from the RCSB protein database (https://www.rcsb.org/structure/5LE5 and https://www.rcsb.org/structure/6MSJ, respectively).
Code availability
Custom code for screen analysis is available on GitHub (https://github.com/ZuberLab/crispr-process-nf, https://github.com/ZuberLab/crispr-mageck-nf). Custom ImageJ scripts applied for image analysis (see Methods for details) are available upon reasonable request.
References
Johnston, L. A., Prober, D. A., Edgar, B. A., Eisenman, R. N. & Gallant, P. Drosophila myc regulates cellular growth during development. Cell 98, 779–790 (1999).
Sabo, A. et al. Selective transcriptional regulation by Myc in cellular growth control and lymphomagenesis. Nature 511, 488–492 (2014).
Muhar, M. et al. SLAM-seq defines direct gene-regulatory functions of the BRD4–MYC axis. Science 360, 800–805 (2018).
Dang, C. V. MYC on the path to cancer. Cell 149, 22–35 (2012).
Hnisz, D. et al. Super-enhancers in the control of cell identity and disease. Cell 155, 934–947 (2013).
He, T. C. et al. Identification of c-MYC as a target of the APC pathway. Science 281, 1509–1512 (1998).
Dani, C. et al. Extreme instability of myc mRNA in normal and transformed human cells. Proc. Natl Acad. Sci. USA 81, 7046-7050 (1984).
Gregory, M. A. & Hann, S. R. c-Myc proteolysis by the ubiquitin-proteasome pathway: stabilization of c-Myc in Burkitt’s lymphoma cells. Mol. Cell. Biol. 20, 2423–2435 (2000).
Schwanhausser, B. et al. Global quantification of mammalian gene expression control. Nature 473, 337–342 (2011).
Meyers, R. M. et al. Computational correction of copy number effect improves specificity of CRISPR–Cas9 essentiality screens in cancer cells. Nat. Genet. 49, 1779–1784 (2017).
Dempster, J. M. et al. Extracting biological insights from the Project Achilles genome-scale CRISPR screens in cancer cell lines. Preprint at https://doi.org/10.1101/720243 (2019).
Michlits, G. et al. Multilayered VBC score predicts sgRNAs that efficiently generate loss-of-function alleles. Nat. Methods 17, 708–716 (2020).
Sears, R., Leone, G., DeGregori, J. & Nevins, J. R. Ras enhances Myc protein stability. Mol. Cell 3, 169–179 (1999).
Welcker, M. et al. The Fbw7 tumor suppressor regulates glycogen synthase kinase 3 phosphorylation-dependent c-Myc protein degradation. Proc. Natl Acad. Sci. USA 101, 9085–9090 (2004).
Inoue, S. et al. Mule/Huwe1/Arf-BP1 suppresses Ras-driven tumorigenesis by preventing c-Myc/Miz1-mediated down-regulation of p21 and p15. Genes Dev 27, 1101–1114 (2013).
Qiao, X. et al. UBR5 is coamplified with MYC in breast tumors and encodes an ubiquitin ligase that limits MYC-dependent apoptosis. Cancer Res. 80, 1414–1427 (2020).
Goto, A. et al. Akirins are highly conserved nuclear proteins required for NF-κB-dependent gene expression in Drosophila and mice. Nat. Immunol. 9, 97–104 (2008).
Tartey, S. et al. Akirin2 is critical for inducing inflammatory genes by bridging IκB-ζ and the SWI/SNF complex. EMBO J. 33, 2332–2348 (2014).
Bonnay, F. et al. Akirin specifies NF-κB selectivity of Drosophila innate immune response via chromatin remodeling. EMBO J. 33, 2349–2362 (2014).
Fischer, M. Census and evaluation of p53 target genes. Oncogene 36, 3943–3956 (2017).
Stark, C. et al. BioGRID: a general repository for interaction datasets. Nucleic Acids Res. 34, D535–D539 (2006).
Smith, D. M. et al. Docking of the proteasomal ATPases’ carboxyl termini in the 20S proteasome’s α ring opens the gate for substrate entry. Mol. Cell 27, 731–744 (2007).
Cuylen-Haering, S. et al. Chromosome clustering by Ki-67 excludes cytoplasm during nuclear assembly. Nature 587, 285–290 (2020).
Schmitz, M. H. et al. Live-cell imaging RNAi screen identifies PP2A-B55α and importin-β1 as key mitotic exit regulators in human cells. Nat. Cell Biol. 12, 886–893 (2010).
Reits, E. A., Benham, A. M., Plougastel, B., Neefjes, J. & Trowsdale, J. Dynamics of proteasome distribution in living cells. EMBO J. 16, 6087–6094 (1997).
Pack, C. G. et al. Quantitative live-cell imaging reveals spatio-temporal dynamics and cytoplasmic assembly of the 26S proteasome. Nat. Commun. 5, 3396 (2014).
Peters, J. M., Franke, W. W. & Kleinschmidt, J. A. Distinct 19 S and 20 S subcomplexes of the 26 S proteasome and their distribution in the nucleus and the cytoplasm. J. Biol. Chem. 269, 7709–7718 (1994).
Wendler, P. & Enenkel, C. Nuclear transport of yeast proteasomes. Front. Mol. Biosci. 6, 34 (2019).
Palacios, V., Kimble, G. C., Tootle, T. L. & Buszczak, M. Importin-9 regulates chromosome segregation and packaging in Drosophila germ cells. J. Cell Sci. 134, jcs258391 (2021).
Budenholzer, L., Breckel, C., Hickey, C. M. & Hochstrasser, M. The Sts1 nuclear import adapter uses a non-canonical bipartite nuclear localization signal and is directly degraded by the proteasome. J. Cell Sci. 133, jcs236158 (2020).
Dominguez, D. et al. A high-resolution transcriptome map of cell cycle reveals novel connections between periodic genes and cancer. Cell Res. 26, 946–962 (2016).
Manasanch, E. E. & Orlowski, R. Z. Proteasome inhibitors in cancer therapy. Nat. Rev. Clin. Oncol. 14, 417–433 (2017).
Parnas, O. et al. A genome-wide CRISPR screen in primary immune cells to dissect regulatory networks. Cell 162, 675–686 (2015).
Brockmann, M. et al. Genetic wiring maps of single-cell protein states reveal an off-switch for GPCR signalling. Nature 546, 307–311 (2017).
Umkehrer, C. et al. Isolating live cell clones from barcoded populations using CRISPRa-inducible reporters. Nat. Biotechnol. 39, 174–178 (2020).
Schambach, A. et al. Lentiviral vectors pseudotyped with murine ecotropic envelope: increased biosafety and convenience in preclinical research. Exp. Hematol. 34, 588–592 (2006).
Wang, T. et al. Identification and characterization of essential genes in the human genome. Science 350, 1096–1101 (2015).
Morgens, D. W. et al. Genome-scale measurement of off-target activity using Cas9 toxicity in high-throughput screens. Nat. Commun. 8, 15178 (2017).
Langmead, B. & Salzberg, S. L. Fast gapped-read alignment with Bowtie 2. Nat. Methods 9, 357–359 (2012).
Liao, Y., Smyth, G. K. & Shi, W. featureCounts: an efficient general purpose program for assigning sequence reads to genomic features. Bioinformatics 30, 923–930 (2014).
Li, W. et al. MAGeCK enables robust identification of essential genes from genome-scale CRISPR/Cas9 knockout screens. Genome Biol. 15, 554 (2014).
Klijn, C. et al. A comprehensive transcriptional portrait of human cancer cell lines. Nat. Biotechnol. 33, 306–312 (2015).
Martin, M. Cutadapt removes adapter sequences from high-throughput sequencing reads. EMBnet.journal 17, https://journal.embnet.org/index.php/embnetjournal/article/view/200 (2011).
Dobin, A. et al. STAR: ultrafast universal RNA-seq aligner. Bioinformatics 29, 15–21 (2013).
O’Leary, N. A. et al. Reference sequence (RefSeq) database at NCBI: current status, taxonomic expansion, and functional annotation. Nucleic Acids Res. 44, D733–D745 (2016).
Love, M. I., Huber, W. & Anders, S. Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2. Genome Biol. 15, 550 (2014).
Zhu, A., Ibrahim, J. G. & Love, M. I. Heavy-tailed prior distributions for sequence count data: removing the noise and preserving large differences. Bioinformatics 35, 2084–2092 (2019).
Dorfer, V. et al. MS Amanda, a universal identification algorithm optimized for high accuracy tandem mass spectra. J. Proteome Res. 13, 3679-3684 (2014).
Smyth, G. K. Linear models and empirical Bayes methods for assessing differential expression in microarray experiments. Stat. App. Gene. Mol. Biol. 3, Article3 (2004).
Mellacheruvu, D. et al. The CRAPome: a contaminant repository for affinity purification–mass spectrometry data. Nat. Methods 10, 730–736 (2013).
Schaab, C., Geiger, T., Stoehr, G., Cox, J. & Mann, M. Analysis of high accuracy, quantitative proteomics data in the MaxQB database. Mol. Cell Proteomics 11, M111. 014068 (2012).
Mi, H., Muruganujan, A., Ebert, D., Huang, X. & Thomas, P. D. PANTHER version 14: more genomes, a new PANTHER GO-slim and improvements in enrichment analysis tools. Nucleic Acids Res. 47, D419–D426 (2019).
Altschul, S. F. et al. Gapped BLAST and PSI-BLAST: a new generation of protein database search programs. Nucleic Acids Res. 25, 3389–3402 (1997).
Emms, D. M. & Kelly, S. OrthoFinder: solving fundamental biases in whole genome comparisons dramatically improves orthogroup inference accuracy. Genome Biol. 16, 157 (2015).
Crooks, G. E., Hon, G., Chandonia, J. M. & Brenner, S. E. WebLogo: a sequence logo generator. Genome Res. 14, 1188–1190 (2004).
Katoh, K., Rozewicki, J. & Yamada, K. D. MAFFT online service: multiple sequence alignment, interactive sequence choice and visualization. Briefings Bioinform. 20, 1160–1166 (2019).
Waterhouse, A. M., Procter, J. B., Martin, D. M., Clamp, M. & Barton, G. J. Jalview Version 2—a multiple sequence alignment editor and analysis workbench. Bioinformatics 25, 1189–1191 (2009).
Ishida, T. & Kinoshita, K. PrDOS: prediction of disordered protein regions from amino acid sequence. Nucleic Acids Res. 35, W460–W464 (2007).
Kosugi, S., Hasebe, M., Tomita, M. & Yanagawa, H. Systematic identification of cell cycle-dependent yeast nucleocytoplasmic shuttling proteins by prediction of composite motifs. Proc. Natl Acad. Sci. USA 106, 10171–10176 (2009).
Cuff, J. A. & Barton, G. J. Application of multiple sequence alignment profiles to improve protein secondary structure prediction. Proteins 40, 502–511 (2000).
Drozdetskiy, A., Cole, C., Procter, J. & Barton, G. J. JPred4: a protein secondary structure prediction server. Nucleic Acids Res. 43, W389–W394 (2015).
Lupas, A., Van Dyke, M. & Stock, J. Predicting coiled coils from protein sequences. Science 252, 1162–1164 (1991).
Doblmann, J. et al. apQuant: accurate label-free quantification by quality filtering. J. Proteome Res. 18, 535–541 (2019).
Studier, F. W. Protein production by auto-induction in high density shaking cultures. Protein Expr. Purif. 41, 207–234 (2005).
Sonn-Segev, A. et al. Quantifying the heterogeneity of macromolecular machines by mass photometry. Nat. Commun. 11, 1772 (2020).
Dohmen, R. J. & Scheffner, M. (eds) Ubiquitin Family Modifiers and the Proteasome (Springer, 2012).
Besche, H. C., Haas, W., Gygi, S. P. & Goldberg, A. L. Isolation of mammalian 26S proteasomes and p97/VCP complexes using the ubiquitin-like domain from HHR23B reveals novel proteasome-associated proteins. Biochemistry 48, 2538–2549 (2009).
Schorb, M., Haberbosch, I., Hagen, W. J. H., Schwab, Y. & Mastronarde, D. N. Software tools for automated transmission electron microscopy. Nat. Methods 16, 471–477 (2019).
Zivanov, J. et al. New tools for automated high-resolution cryo-EM structure determination in RELION-3. eLife 7, e42166 (2018).
Goddard, T. D. et al. UCSF ChimeraX: meeting modern challenges in visualization and analysis. Protein Sci. 27, 14–25 (2018).
Punjani, A., Rubinstein, J. L., Fleet, D. J. & Brubaker, M. A. cryoSPARC: algorithms for rapid unsupervised cryo-EM structure determination. Nat. Methods 14, 290–296 (2017).
Rohou, A. & Grigorieff, N. CTFFIND4: Fast and accurate defocus estimation from electron micrographs. J. Struct. Biol. 192, 216–221 (2015).
Zivanov, J., Nakane, T. & Scheres, S. H. W. Estimation of high-order aberrations and anisotropic magnification from cryo-EM data sets in RELION-3.1. IUCrJ 7, 253–267 (2020).
Sanchez-Garcia, R. et al. DeepEMhancer: a deep learning solution for cryo-EM volume post-processing. Commun. Biol. 4, 874 (2021).
Schrader, J. et al. The inhibition mechanism of human 20S proteasomes enables next-generation inhibitor design. Science 353, 594–598 (2016).
Pettersen, E. F. et al. UCSF Chimera—a visualization system for exploratory research and analysis. J. Comput. Chem. 25, 1605–1612 (2004).
Murshudov, G. N. et al. REFMAC5 for the refinement of macromolecular crystal structures. Acta Crystallogr. D Biol. Crystallogr. 67, 355–367 (2011).
Kim, D. E., Chivian, D. & Baker, D. Protein structure prediction and analysis using the Robetta server. Nucleic Acids Res. 32, W526–W531 (2004).
Emsley, P. & Cowtan, K. Coot: model-building tools for molecular graphics. Acta Crystallogr. D Biol. Crystallogr. 60, 2126–2132 (2004).
Croll, T. I. ISOLDE: a physically realistic environment for model building into low-resolution electron-density maps. Acta Crystallogr. D Struct. Biol. 74, 519–530 (2018).
Afonine, P. V. et al. Real-space refinement in PHENIX for cryo-EM and crystallography. Acta Crystallogr. D Struct. Biol. 74, 531–544 (2018).
Lukinavicius, G. et al. SiR-Hoechst is a far-red DNA stain for live-cell nanoscopy. Nat. Commun. 6, 8497 (2015).
Dong, Y. et al. Cryo-EM structures and dynamics of substrate-engaged human 26S proteasome. Nature 565, 49–55 (2019).
Acknowledgements
We are grateful to all members of the Zuber and Haselbach laboratories and to A. Pauli, C. Plaschka, T. Clausen, D. Gerlich, M. Petrovic, F. Grebien, N. Brown, G. Winter and M. Petronczki for experimental advice and helpful discussions. We thank members of the Obenauf, Gerlich, Clausen, Peters and Busslinger laboratories at IMP and IMBA for sharing reagents; K. Aumayr, P. Pasierbeck, the IMP BioOptics flow cytometry, microscopy and image analysis team and T. Kreslavskiy for cell sorting and imaging; G. Dürnberger and A. Lüttig at the IMP/IMBA Protein Biochemistry Core Facility for performing quantitative proteomics and immunoprecipitation mass spectrometry; A. Sommer and the VBCF-NGS team (https://www.vbcf.ac.at) for deep sequencing services; the Electron Microscopy Facility team at Vienna BioCenter Core Facilities for negative staining electron microscopy; A. Meinhart for model building advice; O. Kaya for experimental support; the IMP/IMBA Molecular Biology Service for continuous support; and G. Riddihough (Life Science Editors) for help with editing. We acknowledge Diamond Light Source for access and support of the cryo-EM facilities at the United Kingdom’s national Electron Bio-imaging Centre (under proposal EM BI25222), funded by the Wellcome Trust, the Medical Research Council and the Biotechnology and Biological Sciences Research Council. This work was funded by a Starting Grant from the European Research Council (ERC-StG-336860) to J.Z., the Austrian Science Fund (SFB grant F4710) to J.Z. and EPIC-XS (project number 823839), funded by the Horizon 2020 Programme of the European Union, to K.M. M.d.A. is the recipient of a DOC fellowship of the Austrian Academy of Sciences. Research at the IMP is generously supported by Boehringer Ingelheim and the Austrian Research Promotion Agency (Headquarter grant FFG-852936).
Author information
Authors and Affiliations
Contributions
M.d.A. and M.H. contributed equally and will be putting their name first on the citation in their CVs. M.d.A., M.H. and J.Z. conceived and planned this project. M.d.A., M.H., H.B. and I.G. designed and conducted experiments with help from M.S., S.K. and E.R. M.d.A., M.H., H.B., I.G., K.S., D.H. and J.Z. analysed and interpreted original data. A.S. performed phylogenetic analyses. T.L. established scripts for imaging analysis. D.H. and K.S. performed the 3D structure reconstruction. T.N. and R.I. performed deep sequencing and mass spectrometry data analyses, respectively. J.J., S.D., R.K. and M.V. established critical reagents and methodology. K.M. and G.V. provided critical input on experimental designs and data analyses. M.d.A., M.H., D.H. and J.Z. co-wrote the manuscript with input from all co-authors.
Corresponding authors
Ethics declarations
Competing interests
J.Z. is a founder, shareholder and scientific advisor of Quantro Therapeutics. J.Z., D.H. and the Zuber and Haselbach laboratories receive research support and funding from Boehringer Ingelheim. J.J. is now an employee of Twist Bioscience and T.N. is now an employee of Quantro Therapeutics. Other authors declare no competing interests.
Additional information
Peer review information Nature thanks Roderick Beijersbergen, Cordula Enenkel, Edmond Watson and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Engineering and validation of clonal iCas9 cell lines.
a, Schematic of clonal iCas9 cell line engineering and validation. Roman numbers indicate the vectors used for each cell line. In K562, generation of tightly regulatable iCas9 clones required additional suppression of leaky transcription from Tet-responsive promoters via a TetR-KRAB fusion protein. b–d, Evaluation of iCas9 function. b, Flow cytometric evaluation of inducible Cas9-P2A-GFP (RKO, K562) or -BFP (MIA-PaCa-2) expression in the presence or absence of DOX. c, Competitive proliferation assays in iCas9 cells transduced with sgRNAs targeting the core-essential genes PSMA3 (RKO), PLK1 (MIA-PaCa-2), or RPL23 (K562). Percentage of sgRNA+ cells was monitored by flow cytometry in the presence or absence of DOX for 10 days. Values are normalized to Day 0. d, Evaluation of surface marker editing in iCas9 cells transduced with sgRNAs targeting the surface markers CD151 (RKO, MIA-PaCa-2) or CD46 (K562). Editing was evaluated by immunostaining and flow cytometry 48 h after Cas9 induction. e, Analysis of MYC/MYCN mRNA levels based on42. A MYC/MYCN specific antibody was used for the detection of MYC. rtTA3, reverse tetracycline transactivator; DOX, doxycycline; PuroR, puromycin resistance gene; HygroR, hygromycin resistance gene; TRE3G, tetracycline response element; 2A, P2A self-cleaving peptide; GFP, green fluorescent protein; BFP, blue fluorescent protein; APC, allophycocyanin; RPKM, reads per kilo base per million mapped reads.
Extended Data Fig. 2 Identification of MYC regulators in iCas9 screens depends on their turnover and essentiality.
a–b, First timepoints of FACS-based CRISPR MYC-regulator (a) and dropout (b) screens. a, Gene-level sgRNA enrichment in MYClo (left panels) or MYChi cells (right panels) over MYCmid (RKO, K562) or unsorted (MIA-PaCa-2) cells and MAGeCK41 one-sided P values. Dashed lines indicate 95th percentile of enrichment and significance (P < 0.01). Essential genes based on12,37,38 within the scoring window are highlighted in red, 20S-CP subunits in blue. b, Gene-level sgRNA depletion in unsorted populations at the first screen timepoint compared to day 0. SgRNAs targeting highly turned-over essential proteins deplete already 2.5 days after Cas9-induction. c, d, Second screen timepoints as in a and b. The identification of MYC regulators at each timepoint depends on their turnover and essentiality. Short-lived essential proteins scored at the first timepoint in FACS-based (a) and dropout screens (b); however, due to rapid effects on cell viability (d), sgRNAs targeting these genes were undetectable at the second timepoint in FACS-based screens (c). Conversely, knockout of more stable proteins or protein complexes such as the 20S proteasome had only limited effects in MYC-regulation- (a) or dropout- screens after 2.5 days (b), while effects were readily detectable 4–5 days post Cas9 induction (c, d). The kinetics of gene editing, protein turnover and depletion of sgRNA-expressing cells are further determined by the cellular context, with rapid effects in diploid RKO cells, and delayed effects in hypertriploid K562 and tetraploid MIA-PaCa-2 cells.
Extended Data Fig. 3 AKIRIN2 is an essential regulator of MYC expression.
a–c, Flow cytometric quantification of endogenous MYC protein levels after inducible knockout of MYC regulators in RKO (a), MIA-PaCa2 (b), and K562 cells (c) 1-3 days after Cas9 induction. For MIA-PaCa2 and K562 the timepoint with the maximal effect on MYC protein abundance is shown. RKO maximal timepoints as in Fig. 2c. d–e, Percentage of cleaved-caspase-3+ (d) and dead cells (e) quantified by flow-cytometry before and 1-3 days after induction of AKIRIN2 knockout. f, Competitive proliferation assays. Percentage of sgRNA+ iCas9-RKO cells was monitored by flow cytometry in 24 h intervals after Cas9 induction. Values are normalized to Day 0. Data in a is representative of three, in b–c of two independent experiments. Data in d–f is shown as mean ± s.d. (n = 3 biological replicates). PE, phycoerythrin.
Extended Data Fig. 4 AKIRIN2 regulates nuclear protein turnover.
a–c, Transcriptional changes after acute knockout of AKIRIN2 (a) or PSMA3 (b). RNA-seq of iCas9-RKO cells was performed 2 (sgAKIRIN2, sgAAVS1) or 3 days (sgPSMA3) after Cas9 induction (n = 3 biological replicates). Genes significantly up- or downregulated (P ≤ 0.01; Benjamini-Hochberg corrected two-sided Wald-test) at least two-fold are highlighted in orange, TP53 target genes according to20 in red. c, Principal component (PC) analysis of the 1000 most highly expressed genes. d, e, AKIRIN2 and MYC protein half-life quantification. Immunoblot time-series of iCas9-RKO cells treated with cycloheximide (CHX) 2 days after Cas9 induction (d) and half-life quantification (e) of AKIRIN2 (half-life = 46 min, 95% CI = 37–58 min) and MYC (half-life = 25 and 178 min with 95% CI = 21–31 and 51–238 min in sgAAVS1 control and sgAKIRIN2 cells, respectively). Data is shown as mean ± s.d. (n ≥ 3 independent experiments). Dashed lines indicate halflives. f, g, Quantitative proteomics following induced AKIRIN2 or PSMA3 knockout. Samples were obtained as described for a-c (n = 2 biological replicates). f, Principal component analysis of the 1000 most highly expressed proteins. g, Scatter plot of transcriptome- versus proteome-changes upon acute AKIRIN2 knockout compared to sgAAVS1 control. AKIRIN2 targets as in Fig. 3a, b (orange; n = 124) are upregulated only on protein-, but not on mRNA-level. TP53 target genes as in a, b are shown in red. h, Western blot of selected AKIRIN2 targets after AKIRIN2 or proteasome knockout. iCas9-RKO cells expressing the indicated sgRNAs were harvested before, and 2 and 3 days after Cas9 induction. i, Euler diagram of proteasome targets and AKIRIN2 targets as defined in Fig. 3a, b. CI, confidence interval; FC, fold change.
Extended Data Fig. 5 AKIRIN2 is a highly conserved nuclear protein.
a, Alignment of Akirin orthologs from 11 representative model organisms. AKIRIN2 and AKIRIN1 are highly conserved in vertebrates. In invertebrate metazoans, only one Akirin ortholog per species was found, which is more closely related to AKIRIN2 than to AKIRIN1. Colors denote clustal amino acid identity. b–d, Knockout-rescue studies evaluating essentiality of AKIRIN2 protein features as in Fig. 4c, d. b, Schematic setup of knockout-rescue experiments and AKIRIN2 cDNA variants, in which sgAKIRIN2 seed and PAM sequences were removed through synonymous mutations. Roman numbers are continued from Fig. 4c. c, Competitive proliferation assays of iCas9-RKO cells co-expressing sgAKIRIN2 and the indicated AKIRIN2 cDNA variant. Cells were monitored using flow cytometry for 10 days after Cas9 induction. Values are normalized to Day 0. Data is shown as mean ± s.d. (n = 3 independent experiments). d, Immunoblotting of V5 and AKIRIN2 in iCas9-RKO cells expressing the indicated AKIRIN2 cDNA variants. e, Immunofluorescence localization of AKIRIN2. V5-AKIRIN2 knockout-rescue RKO cells were stained with α-V5 antibody. Images are representative of 3 independent experiments. Scale bar, 15 µm. f, Co-IP/MS of full-length V5-AKIRIN1 purified with α-V5 antibody. Enrichment was calculated over V5-NLS-GFP control (Benjamini-Hochberg corrected limma moderated two-sided t-test, n = 6 biological replicates from 2 independent experiments).
Extended Data Fig. 6 AKIRIN2 purification and negative staining EM.
a, Schematic four-step purification of recombinant His-GST-AKIRIN2 from E. coli (left) and size-exclusion chromatogram (right). Blue bars indicate GST-AKIRIN2 containing fractions analyzed by SDS-PAGE. b, SDS-PAGE of eluted fractions. Lower 26 kDa band corresponds to free GST. c, d, Co-IP/MS of sucrose fractionated proteins co-purified with GST-AKIRIN2 from cytosolic HeLa cell lysate. Experimental setup (c) and normalized protein abundance of selected AKIRIN2-interactors across sucrose fractions (d). 20S-CP and 19S-RP datapoints represent the mean of all 20S-CP and 19S-ATPase and non-ATPase subunits as defined in Fig. 2b, respectively. e–h, Negative staining electron microscopy of AKIRIN2-proteasome complexes. Experimental setup (e) and SDS-PAGE (f) of sucrose gradient fractionated proteins co-purified with GST-AKIRIN2 (left) or GST-UBL (right) from PEG-concentrated HeLa cell lysate. Red boxes indicate fractions used for negative staining electron microscopy (g, h). 3D reconstructions (g) and representative negative stain electron micrograph and 2D class averages (h) of 26S proteasome complexes co-purified with GST-AKIRIN2 (left) or GST-UBL (right). Arrows indicate AKIRIN2-specific densities. Data in a–b and f–h are representative of three independent experiments. Scale bar, 50 nm. SEC, size-exclusion chromatography; EM, electron microscopy; CP, core (proteasome) particle; RP, regulatory particle.
Extended Data Fig. 7 Cryo-EM data processing and analysis of the AKIRIN2-proteasome complex.
a, Representative micrograph and 2D class averages of proteasome complexes co-purified with AKIRIN2. Data is representative of three independent experiments. Scale bar, 50 nm. b, Angular distributions of individual particles. c, Fourier Shell Correlation (FSC) curve of the refined EM map at 3.2 Å resolution. d, Cryo-EM density map of AKIRIN2 bound to the 20S proteasome as in Fig. 4g, side view. e, f, Cryo-EM model of AKIRIN2 bound to the 20S proteasome (e) and the substrate-engaged 26S proteasome complex (f). Detail views show the binding sites of AKIRIN2. In the active proteasome conformation, the α3/α4 pocket (top) and α2/α3 pocket (bottom) are occupied by PSMC1 (Rpt2) and PSMC5 (Rpt6), respectively. At a low threshold, the α1/α2 pocket also contains a density that may be attributed to the AKIRIN2 C-terminal motif. 20S subunits are shown in blue, AKIRIN2 in red, PSMC1 and PSMC5 in orange, other 19S subunits in transparent white. 26S structure83 was accessed via PDB ID: 6MSJ. FSC, Fourier shell correlation.
Extended Data Fig. 8 AKIRIN2 is a critical mediator of nuclear proteasome import.
a–c, Engineering of 20S proteasome reporter cells. a, Schematic of vectors (left) used for PSMB4 knockout-rescue (right). iCas9-RKO cells were co-transduced with an sgRNA targeting PSMB4 and a cDNA encoding a FLAG-tagged sgRNA-resistant PSMB4-mCherry fusion protein. sgRNA and cDNA double positive cells were monitored by flow cytometry for 7 days after Cas9 induction. Percentage is normalized to Day 0. b, Immunoblot analysis of single cell-derived clonal PSMB4-mCherry reporter cells and WT iCas9-RKO cells. c, SDS-PAGE and immunoblot of PSMB4 in WT iCas9-RKO (top) and clonal PSMB4-mCherry reporter cells (bottom) after sucrose gradient fractionation. d, e, Representative IF images (d) and quantification (e) of endogenous PSMA5 (blue) levels in iCas9-RKO cells after induced knockout of AKIRIN2 (n = 2,729 cells) or AAVS1 (n = 3,625 cells). f–h, mCherry-PSMD3 19S proteasome reporter as in a–c. i–j, Representative confocal images (i) and quantification (j) of mCherry-PSMD3 signal after induced knockout of AKIRIN2 (n = 6,858 cells) or AAVS1 (n = 7,309 cells). k-n, Nuclear proteasome import (k, l) and MYC protein levels (m, n) after induced IPO9 knockout. Representative confocal images (k) and quantification (l) of PSMB4-mCherry signal 7 days after induced IPO9 (n = 8,055 cells) or AAVS1 (n = 8,336 cells) knockout. Representative flow cytometry histogram of endogenous MYC protein levels 7 days after induced IPO9 knockout (m) and fold change compared to sgRNA- cells (one-sided Welch’s t-test) (n). Bars and whiskers represent mean and standard deviation of 3 biological replicates. Nuclei in e, j, l were segmented based on DNA channel and signal was normalized to the mean nuclear signal in sgAAVS1 cells. Data in e, j, l is shown as mean ± s.d. (n = 9 biological replicates from 3 independent experiments; two-sided Welch’s -test). Data in c, h is representative of 2 independent experiments. Scale bars, 15 µm. FC, fold change.
Extended Data Fig. 9 AKIRIN2 controls the nuclear re-import of proteasomes following mitosis.
a, Quantification of nuclear PSMB4-mCherry signal in individual dividing iCas9-RKO reporter cells after AKIRIN2 (n = 38 cells) or AAVS1 knockout (n = 27 cells) as shown in Fig. 5d over time. b–d, Time-lapse imaging of mitotic PSMB4-mCherry RKO reporter cells co-expressing IBB-GFP. b, Quantification of nuclear PSMB4-mCherry and IBB-GFP signal in dividing reporter cells shown as averaged data (b, mean ± 95% CI, n = 27 cells from two independent experiments), individual cell-tracks (c), and representative time-lapse images (d). Dashed line indicates the onset of IBB-GFP import. DNA was visualized with SiR-Hoechst. Signal intensity is normalized to t = −100 min. Scale bar, 10 µm. e, Quantification of MYC-mCherry signal as in a after AKIRIN2 (n = 40 cells) or AAVS1 knockout (n = 38 cells) as shown in Fig. 5f. f, Model of post-mitotic nuclear proteasome import mediated by AKIRIN2. Cells undergoing mitotic cell division upon loss of AKIRIN2 give rise to daughter cells that are devoid of nuclear proteasomes. Signal in a, e is normalized to mean nuclear signal in sgAAVS1 cells. Pseudotime is normalized to the timepoint of maximal chromatin condensation (a, e) or to the onset of nuclear PSMB4-mCherry import (b, c).
Supplementary information
Supplementary Figs.
This file contains Supplementary Figs. 1–3. Supplementary Fig. 1 contains uncropped images of western blots and SDS gels. Supplementary Fig. 2 shows representative gating strategies for FACS-based MYC regulator screens and flow cytometric analyses. Supplementary Fig. 3 schematically shows cryo electron microscopy image processing and model building.
Supplementary Table 1
Raw sgRNA counts of MYC regulator screens. For each screen condition, raw sequencing reads for individual sgRNAs are provided. Reads are not normalized to sequencing depth. Column names are provided in the format cellline_FACSgate_timepoint_replicate.
Supplementary Table 2
MAGeCK analysis of MYC regulator screens. Gene-level average, median-normalized log2 fold changes, one-tailed logarithmized P values and FDRs calculated by MAGeCK v0.5.9. The table contains the merged dataset representing the minimum P value of both time points, as well as individual datasets for each time point. GO terms are annotated, and genes highlighted and categorized in Fig. 1 and Fig. 2 are indicated. Column names are provided in the format variable_cellline_FACSgate_timepoint.
Supplementary Table 3
Quantitative proteomics and RNA-seq results. Combined table of TMT mass spectrometry and RNA-seq results including normalized protein abundance and mRNA TPM averaged over two or three replicates, respectively, as well as log2 fold changes and logarithmized P values (Benjamini–Hochberg-corrected two-tailed limma moderated t-test and Wald test, respectively). Classification into AKIRIN2-responsive and -independent proteasome targets according to Fig. 3 is annotated.
Supplementary Table 4
GO term enrichment analysis of proteasome targets. Results of GO term enrichment analysis of AKIRIN2-reponsive and -independent proteasome targets using PANTHER two-tailed Fisher’s exact over-representation test with Benjamini–Hochberg multiple testing correction on GO database (release 2020-06-01). Ratio of FDRs (ΔFDR) for AKIRIN2-responsive and -independent genes for each GO term is provided.
Supplementary Table 5
Akirin orthologues. Gene name, species name, primary accession number and protein length in amino acids for 103 Akirin orthologues from 77 different species used for phylogenetic analyses. Consideration of individual orthologues for the different analyses and figures are annotated.
Supplementary Table 6
AKIRIN2 co-immunoprecipitation mass spectrometry results. Normalized, imputed protein abundances identified by co-immunoprecipitation mass spectrometry analysis of V5-AKIRIN2, V5-AKIRIN1, V5-AKIRIN2ΔYVS and V5-GFP in RKO cells averaged over six replicates, including log2 fold changes and logarithmized P values (Benjamini–Hochberg-corrected two-tailed limma moderated t-test) as well as mass spectrometric quantification of proteins co-purified with GSTAKIRIN2 from HeLa cell extract after fractionation on a 10–30% sucrose gradient.
Supplementary Table 7
Proteasome subunit nomenclature. Human gene name, common protein nomenclature and chain ID and protein nomenclature used in cryo-EM model of AKIRIN2 bound to the 20S proteasome.
Supplementary Table 8
EM model building statistics. EM data collection and processing statistics for negative stain EM structure of AKIRIN2 bound to the 26S proteasome and data collection, processing, refinement and validation statistics for cryo-EM structure of AKIRIN2 bound to the 20S proteasome.
Supplementary Table 9
Glossary. Abbreviations used in the manuscript and their definitions.
Supplementary Video 1
Live-cell imaging of mCherry–MYC reporter cells. Movie highlights kinetics of MYC stabilization after inducible knockout of AKIRIN2, FBXW7 or the 20S proteasome subunit PSMA1. Cells were imaged every 2 h for 96 h. Scale bar, 100 μm.
Supplementary Video 2
Confocal live-cell imaging of mitotic RKO reporter cells after inducible AKIRIN2/AAVS1 knockout. mCherryMYC or PSMB4mCherry reporter cells were imaged 15–24 h after induction of AKIRIN2/AAVS1 knockout and imaged at 5- or 10-min intervals as indicated. mCherry–MYC is shown in red, PSMB4mCherry in blue and DNA in grey. Scale bar, 10 μm (single cell) and 50 μm (overview, 10 h).
Rights and permissions
About this article

Cite this article
de Almeida, M., Hinterndorfer, M., Brunner, H. et al. AKIRIN2 controls the nuclear import of proteasomes in vertebrates. Nature 599, 491–496 (2021). https://doi.org/10.1038/s41586-021-04035-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41586-021-04035-8
- Springer Nature Limited
This article is cited by
-
CDK7/CDK9 mediates transcriptional activation to prime paraptosis in cancer cells
Cell & Bioscience (2024)
-
Nuclear proteasomes buffer cytoplasmic proteins during autophagy compromise
Nature Cell Biology (2024)
-
Orpinolide disrupts a leukemic dependency on cholesterol transport by inhibiting OSBP
Nature Chemical Biology (2024)
-
Alkylamine-tethered molecules recruit FBXO22 for targeted protein degradation
Nature Communications (2024)
-
Novel mechanisms of MITF regulation identified in a mouse suppressor screen
EMBO Reports (2024)