

Abstract
RNA editing generates post-transcriptional sequence changes that can be deduced from RNA-seq data, but detection typically requires matched genomic sequence or multiple related expression data sets. We developed the GIREMI tool (genome-independent identification of RNA editing by mutual information; https://www.ibp.ucla.edu/research/xiao/GIREMI.html) to predict adenosine-to-inosine editing accurately and sensitively from a single RNA-seq data set of modest sequencing depth. Using GIREMI on existing data, we observed tissue-specific and evolutionary patterns in editing sites in the human population.


Similar content being viewed by others


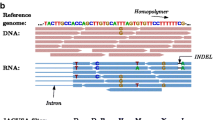
References
Bass, B.L. Annu. Rev. Biochem. 71, 817–846 (2002).
Nishikura, K. Annu. Rev. Biochem. 79, 321–349 (2010).
Farajollahi, S. & Maas, S. Trends Genet. 26, 221–230 (2010).
Lee, J.H., Ang, J.K. & Xiao, X. RNA 19, 725–732 (2013).
Ramaswami, G. et al. Nat. Methods 10, 128–132 (2013).
Ensterö, M., Daniel, C., Wahlstedt, H., Major, F. & Ohman, M. Nucleic Acids Res. 37, 6916–6926 (2009).
Djebali, S. et al. Nature 489, 101–108 (2012).
Chen, L. Proc. Natl. Acad. Sci. USA 110, E2741–E2747 (2013).
Bahn, J.H. et al. Genome Res. 22, 142–150 (2012).
Bazak, L. et al. Genome Res. 24, 365–376 (2014).
Bazak, L., Levanon, E.Y. & Eisenberg, E. Nucleic Acids Res. 42, 6876–6884 (2014).
Pinto, Y., Cohen, H.Y. & Levanon, E.Y. Genome Biol. 15, R5 (2014).
The GTEx Consortium. Nat. Genet. 45, 580–585 (2013).
Chen, J.Y. et al. PLoS Genet. 10, e1004274 (2014).
Abecasis, G.R. et al. Nature 491, 56–65 (2012).
Li, G. et al. Nucleic Acids Res. 40, e104 (2012).
Langmead, B., Trapnell, C., Pop, M. & Salzberg, S.L. Genome Biol. 10, R25 (2009).
Kent, W.J. Genome Res. 12, 656–664 (2002).
Peng, Z. et al. Nat. Biotechnol. 30, 253–260 (2012).
Ramaswami, G. et al. Nat. Methods 9, 579–581 (2012).
Kleinman, C.L. & Majewski, J. Science 335, 1302 (2012).
Lin, W., Piskol, R., Tan, M.H. & Li, J.B. Science 335, 1302 (2012).
Pickrell, J.K., Gilad, Y. & Pritchard, J.K. Science 335, 1302 (2012).
Clark, M.J. et al. PLoS Genet. 6, e1000832 (2010).
Smyth, G.K. in Bioinformatics and Computational Biology Solutions Using R and Bioconductor (eds. Gentleman, R., Carey, V., Dudoit, S., Irizarry, R. & Huber, W.) 397–420 (Springer, 2005).
Dreszer, T.R. et al. Nucleic Acids Res. 40, D918–D923 (2012).
Lee, J.H. et al. Circ. Res. 109, 1332–1341 (2011).
Huelga, S.C. et al. Cell Rep. 1, 167–178 (2012).
Katz, Y., Wang, E.T., Airoldi, E.M. & Burge, C.B. Nat. Methods 7, 1009–1015 (2010).
König, J. et al. Nat. Struct. Mol. Biol. 17, 909–915 (2010).
Hafner, M. et al. Cell 141, 129–141 (2010).
Macias, S. et al. Nat. Struct. Mol. Biol. 19, 760–766 (2012).
Mukherjee, N. et al. Mol. Cell 43, 327–339 (2011).
Hoell, J.I. et al. Nat. Struct. Mol. Biol. 18, 1428–1431 (2011).
Wilbert, M.L. et al. Mol. Cell 48, 195–206 (2012).
Sievers, C., Schlumpf, T., Sawarkar, R., Comoglio, F. & Paro, R. Nucleic Acids Res. 40, e160 (2012).
Xue, Y. et al. Mol. Cell 36, 996–1006 (2009).
Sanford, J.R. et al. Genome Res. 19, 381–394 (2009).
Tollervey, J.R. et al. Nat. Neurosci. 14, 452–458 (2011).
Wang, Z. et al. PLoS Biol. 8, e1000530 (2010).
Acknowledgements
We thank members of the Xiao laboratory for comments on this work and for helping with RNA-seq read mapping. We thank the ENCODE, GTEx and the 1000 Genomes Project for generating the data and making their data available to the public. This work was supported in part by US National Institutes of Health grants R01HG006264 and U01HG007013 and by US National Science Foundation grant 1262134.
Author information
Authors and Affiliations
Contributions
Q.Z. implemented and developed the GIREMI method and conducted bioinformatic analyses; X.X. conceived the idea, designed and conducted bioinformatic analyses, and wrote the paper with input from Q.Z.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Integrated supplementary information
Supplementary Figure 1 The GIREMI method.
(a) Distribution of mutual information for editing sites and SNPs relative to any other types of mismatches. Upper: all editing sites or SNPs; lower: separated according to the type of regions harboring editing sites or SNPs (rep.: repetitive). The table (right) shows the number of sites involved in each category for the lower panel. (see details in Supplementary Note 1) (b) Flowchart of GIREMI, see Online Methods for details. (c) Distribution of the absolute difference between allelic ratios of the mismatches corresponding to RNA editing sites or known SNPs and the estimated allelic ratio of the gene by maximum likelihood. The data were derived using predicted editing sites by the mutual information test in GM12878 data. (d) Pictograms of the -1 and +1 nucleotides flanking an RNA editing site compared to those of a SNP, derived using the predicted editing sites by the mutual information test in the GM12878 data. (e) Types of sites that are harbored in the same pair of reads as known recoding sites identified by the mutual information step alone. These sites are separated into different types (SNPs, RNA editing sites or un-determined SNVs (see Supplementary Note 1)). All the RNA editing sites shown here were located in non-repetitive regions.
Supplementary Figure 2 GIREMI performance using a different read-mapping and variant-calling method (BWA mapping and GATK variant calling; see Supplementary Note 2).
(a) GIREMI results using reads processed by BWA and GATK. Numbers of predicted RNA editing sites by GIREMI in the GM12878 lymphoblastoid cells (ENCODE, cytosolic, polyA+ RNA-seq) are shown. Different fractions of genetic SNPs of GM12878 were assumed as unknown by excluding them from dbSNP. For each fraction, the SNPs were selected randomly. The percentage of GM12878 SNPs (based on genome sequencing data) among all single-nucleotide mismatches identified in the mapped RNA-seq reads after filtering for artifacts is shown (input data, gray bars, see Methods). The percentage of false positives (GM12878 SNPs) among all predicted editing sites is shown as orange bars. The total number of predicted editing sites and percentage of A-to-G editing are shown (numbers in orange). (b) GIREMI results using reads processed by the stringent mapping pipeline (Online Methods), shown for comparison purpose. The results are the same as in Fig. 1c.
Supplementary Figure 3 Performance of the GIREMI method.
(a) Predicted RNA editing sites in ENCODE data sets (cytosolic, polyA+ RNA-seq). The numbers of editing sites resulted from the mutual information calculation and the GLM step are shown separately. The total number of predicted editing sites and percentage of A-to-G editing (%AG) are shown above the bars. The number of editing sites and %AG values are both higher than those in a previous study for most data sets (Chen L, PNAS, 110(29): E2741-7. Table S2, total editing sites (%AG): HeLa: 18,335 (96.6%), H1: 17,700 (97.3%), K562: 10,860 (95.8), NHEK: 8,681 (94.6%), HepG2: 8,209 (93.8%), HUVEC: 7,553 (94.3%)). (b) Predicted RNA editing sites in U87MG cells. Control: cells transfected with scrambled siRNA, ADAR1 KD: knockdown with siRNA targeting ADAR1. RNA-seq data were obtained from our previous work (Bahn, et al, Genome Research, 2012). A-to-G sites accounted for 90% of all predicted editing sites in control cells. A-to-G sites and U-to-C sites together accounted for 97% of all predicted editing sites in control cells. The number of editing sites and %AG (or %AG+UC) values are both higher than those in a previous study (Chen L, PNAS, 110(29): E2741-7. Table S1: total editing sites (%AG) = 2,965 (86.2%), %AG+UC = 94.3%). Note that since the RNA-seq data were not strand-specific, U-to-C sites could possibly be A-to-G editing sites in an antisense transcript. If all editing sites predicted in the KD data were assumed to be false positives (which may be an overestimate), then the FDR of our method is 5.2% (322/6182). Alternatively, using the U87MG-specific genome data, 431 of the 6182 predicted editing sites in control U87MG cells were indeed SNPs, yielding an estimated FDR of 7.0%. (c) & (d). The GM12878 RNA-seq data were down-sampled to reach different sequencing depth. Number of mapped reads (singletons) is shown along the x-axis. The percentage of GM12878 SNPs (based on genome sequencing data) among all single-nucleotide mismatches identified in the mapped RNA-seq reads after filtering for artifacts is shown (input data, gray bars). The percentage of false positives (GM12878 SNPs) among all predicted editing sites is shown as orange bars. The total number of predicted editing sites and percentage of A-to-G editing are shown (numbers in orange). (c) (d): 30%, 70% of the GM12878 SNPs were assumed to be unknown, respectively.
Supplementary Figure 4 Performance of GIREMI for single-end data.
The same GM12878 RNA-seq data were used as in Figure 1. However, the paired-end reads were used as if they were single-end. That is, pairing information between reads was discarded in the mapping step and all following analysis steps. (a) Different % of SNPs was assumed to be unknown, similarly as in Fig. 1c. (b) Different sequencing depth, similarly as in Fig. 1d.
Supplementary Figure 5 Predicted RNA editing sites in GTEx human tissues.
Left panel: Number of raw reads and final mapped read pairs in each sample. Right panel: Number of predicted editing sites and percentage of A-to-G type (orange bars). The % of A/G mismatches among all single-nucleotide mismatches identified in the mapped RNA-seq reads after filtering for artifacts is also shown (input data, gray bars). Sample names in GTEx database are shown. Samples with * were excluded from downstream editing analysis due to low sequencing depth.
Supplementary Figure 6 The RNA editing ratios do not correlate with expression levels of genes.
The same RNA editing sites used for Fig. 2a were analyzed here, together with the expression levels of the corresponding genes.
Supplementary Figure 7 Editing analysis of GTEx tissues.
(a) Tissue-specific editing (TSE) comparing pairs of tissues. Left panel: bar height corresponds to the percentage of editing sites that are tissue-specific among all testable sites of the associated tissue pair. Orange: editing sites specific to the first tissue shown in the y-axis label; blue: editing sites specific to the second tissue. The number of editing sites that are tissue-specific is also shown within the bars. Right panel: ADAR1 and ADAR2 expression levels in each pair of tissues (averaged across individuals). FC: frontal cortex; Cbm: cerebellum; HC: hippocampus; SM: skeletal muscle. (b) Editing ratios of tissue-specific editing sites in the GTEx data. All editing sites significantly specific to the tissue compared to any other tissues were included for each tissue.
Supplementary Figure 8 Expression of ADAR1 and ADAR2 and their correlation with TSE.
(a) The correlation between ADAR1 expression levels and RNA editing ratios. Expression level of ADAR1 in each sample was calculated as RPKM. Average editing ratios of all tissue-specific editing (TSE) in one sample was calculated and shown as one data point (blue). Similar data are shown for Non-TSE sites in the human tissue editome of each sample (gray). Pearson correlation was calculated. (b) Same as (a), but for ADAR2 expression level.
Supplementary Figure 9 Characteristics of TSE sites compared to non-TSE sites.
(a) Distribution of TSE in different types of intragenic regions. TSE sites that were significantly specific to at least one tissue were included. Similar distribution of Non-TSE sites is shown for comparison purpose. "Noncoding" refers to noncoding genes or noncoding transcripts of coding genes. (b) Empirical cumulative distributions of 3’ UTR length for genes harboring TSE or Non-TSE sites. The longest 3’ UTR span was used if alternative 3’ UTRs exist for a gene overlapping the editing sites. (c) Empirical cumulative distributions of distance between RNA editing sites and the AAUAAA poly A signal. All alternative distances were included in case of alternative 3’ UTRs. (d) Similar as (c), for AUUAAA poly A signal. All p values were calculated using the Kolmogorov–Smirnov test. (e) Percentage of RNA editing sites that overlap existing CLIP-seq binding sites of RNA binding proteins (collected from public CLIP-seq data, see Online Methods). TSEs were more often located in CLIP sites than Non-TSEs (p = 8.1x10-7, Fisher's Exact Test). The error bars show the 95% confidence intervals.
Supplementary Figure 10 Editing sites and their prevalence in the 1000 Genomes data set.
(a) Distribution of prevalence of editing sites identified in the 1000 Genomes data set. Prevalence was defined as the fraction of individuals expressing the edited nucleotide among those with at least 10 reads covering this position. Only editing sites with a minimum read coverage of 10 in at least 50% of individuals were included. (b) Editing ratios of sites associated with different values of prevalence. The first prevalence range was set to be between 0 and 0.3 due to the small number of editing sites within the first three deciles.
Supplementary Figure 11 Conservation of the immediate neighborhood of editing sites in 3' UTRs for all groups of editing sites with prevalence values in the indicated range.
Sequence conservation (percentage of identity) of each position flanking editing sites (position 0) was calculated using the UCSC multiz46way alignments of primate genomes (Online Methods). Dashed lines correspond to the sequence identity if Gs in other genomes were assumed as a conserved base given a reference nucleotide A in human. For a number of prevalence groups, the DNA sequences of common editing sites themselves were less conserved compared to their flanking regions and that this difference diminished if the edited G nucleotide were fixed into the human DNA. A likely explanation is that commonly edited positions in human are more tolerable for G, which is consistent with the frequent presence of genomic Gs in the other genomes.
Supplementary information
Supplementary Text and Figures
Supplementary Figures 1–11, Supplementary Tables 1–7 and Supplementary Notes 1–6 (PDF 1312 kb)
Supplementary Software
GIREMI software (ZIP 83 kb)
Rights and permissions
About this article

Cite this article
Zhang, Q., Xiao, X. Genome sequence–independent identification of RNA editing sites. Nat Methods 12, 347–350 (2015). https://doi.org/10.1038/nmeth.3314
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/nmeth.3314
- Springer Nature America, Inc.
This article is cited by
-
Host-mediated RNA editing in viruses
Biology Direct (2023)
-
L-GIREMI uncovers RNA editing sites in long-read RNA-seq
Genome Biology (2023)
-
A novel computational method enables RNA editome profiling during human hematopoiesis from scRNA-seq data
Scientific Reports (2023)
-
Retrospect of the Two-Year Debate: What Fuels the Evolution of SARS-CoV-2: RNA Editing or Replication Error?
Current Microbiology (2023)
-
RNA editing detection in SARS-CoV-2 transcriptome should be different from traditional SNV identification
Journal of Applied Genetics (2022)