

Abstract
The capture of transient scenes at high imaging speed has been long sought by photographers1,2,3,4, with early examples being the well known recording in 1878 of a horse in motion5 and the 1887 photograph of a supersonic bullet6. However, not until the late twentieth century were breakthroughs achieved in demonstrating ultrahigh-speed imaging (more than 105 frames per second)7. In particular, the introduction of electronic imaging sensors based on the charge-coupled device (CCD) or complementary metal–oxide–semiconductor (CMOS) technology revolutionized high-speed photography, enabling acquisition rates of up to 107 frames per second8. Despite these sensors’ widespread impact, further increasing frame rates using CCD or CMOS technology is fundamentally limited by their on-chip storage and electronic readout speed9. Here we demonstrate a two-dimensional dynamic imaging technique, compressed ultrafast photography (CUP), which can capture non-repetitive time-evolving events at up to 1011 frames per second. Compared with existing ultrafast imaging techniques, CUP has the prominent advantage of measuring an x–y–t (x, y, spatial coordinates; t, time) scene with a single camera snapshot, thereby allowing observation of transient events with temporal resolution as tens of picoseconds. Furthermore, akin to traditional photography, CUP is receive-only, and so does not need the specialized active illumination required by other single-shot ultrafast imagers2,3. As a result, CUP can image a variety of luminescent—such as fluorescent or bioluminescent—objects. Using CUP, we visualize four fundamental physical phenomena with single laser shots only: laser pulse reflection and refraction, photon racing in two media, and faster-than-light propagation of non-information (that is, motion that appears faster than the speed of light but cannot convey information). Given CUP’s capability, we expect it to find widespread applications in both fundamental and applied sciences, including biomedical research.
Similar content being viewed by others

Main
To record events occurring at subnanosecond scale, currently the most effective approach is to use a streak camera, that is, an ultrafast photodetection system that transforms the temporal profile of a light signal into a spatial profile by shearing photoelectrons perpendicularly to their direction of travel with a time-varying voltage10. However, a typical streak camera is a one-dimensional imaging device—a narrow entrance slit (10–50 μm wide) limits the imaging field of view (FOV) to a line. To achieve two-dimensional (2D) imaging, the system thus requires additional mechanical or optical scanning along the orthogonal spatial axis. Although this paradigm is capable of providing a frame rate fast enough to catch photons in motion11,12, the event itself must be repetitive—following exactly the same spatiotemporal pattern—while the entrance slit of a streak camera steps across the entire FOV. In cases where the physical phenomena are either difficult or impossible to repeat, such as optical rogue waves13, nuclear explosion, and gravitational collapse in a supernova, this 2D streak imaging method is inapplicable.
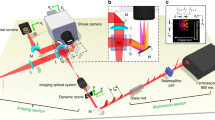
To overcome this limitation, here we present CUP (Fig. 1), which can provide 2D dynamic imaging using a streak camera without employing any mechanical or optical scanning mechanism with a single exposure. On the basis of compressed sensing14, CUP works by encoding the spatial domain with a pseudo-random binary pattern, followed by a shearing operation in the temporal domain, performed using a streak camera with a fully opened entrance slit. This encoded, sheared three-dimensional (3D) x, y, t scene is then measured by a 2D detector array, such as a CCD, with a single snapshot. The image reconstruction process follows a strategy similar to compressed-sensing-based image restoration15,16,17,18,19—iteratively estimating a solution that minimizes an objective function.

CCD, charge-coupled device; DMD, digital micromirror device; V, sweeping voltage; t, time. Since each micromirror (7.2 μm × 7.2 μm) of the DMD is much larger than the light wavelength, the diffraction angle is small (∼4°). With a collecting objective of numerical aperture NA = 0.16, the throughput loss caused by the DMD’s diffraction is negligible. See text for details of operation. Equipment details: camera lens, Fujinon CF75HA-1; DMD, Texas Instruments DLP LightCrafter; microscope objective, Olympus UPLSAPO 4×; tube lens, Thorlabs AC254-150-A; streak camera, Hamamatsu C7700; CCD, Hamamatsu ORCA-R2.
By adding a digital micromirror device as the spatial encoding module and applying the CUP reconstruction algorithm, we transformed a conventional one-dimensional streak camera into a 2D ultrafast imaging device. The resultant system can capture a single, non-repetitive event at up to 100 billion frames per second with appreciable sequence depths (up to 350 frames per acquisition). Moreover, by using a dichroic mirror to separate signals into two colour channels, we expand CUP’s functionality into the realm of four dimensional (4D) x, y, t, λ ultrafast imaging, maximizing the information content that we can simultaneously acquire from a single instrument (Methods).
CUP operates in two steps: image acquisition and image reconstruction. The image acquisition can be described by a forward model (Methods). The input image is encoded with a pseudo-random binary pattern and then temporally dispersed along a spatial axis using a streak camera. Mathematically, this process is equivalent to successively applying a spatial encoding operator, C, and a temporal shearing operator, S, to the intensity distribution from the input dynamic scene, I(x, y, t):

where Is(x″, y″, t) represents the resultant encoded, sheared scene. Next, Is is imaged by a CCD, a process that can be mathematically formulated as:

Here, T is a spatiotemporal integration operator (spatially integrating over each CCD pixel and temporally integrating over the exposure time). E(m, n) is the optical energy measured at pixel m, n on the CCD. Substituting equation (1) into equation (2) yields

where O represents a combined linear operator, that is, O = TSC.
The image reconstruction is solving the inverse problem of equation (3). Given the operator O and spatiotemporal sparsity of the event, we can reasonably estimate the input scene, I(x, y, t), from measurement, E(m, n), by adopting a compressed-sensing algorithm, such as two-step iterative shrinkage/thresholding (TwIST)16 (detailed in Methods). The reconstructed frame rate, r, is determined by:

Here v is the temporal shearing velocity of the operator S, that is, the shearing velocity of the streak camera, and Δy″ is the CCD’s binned pixel size along the temporal shearing direction of the operator S.
The configuration of the CUP is shown in Fig. 1. The object is first imaged by a camera lens with a focal length of 75 mm. The intermediate image is then passed to a DMD by a 4f imaging system consisting of a tube lens (focal length 150 mm) and a microscope objective (focal length 45 mm, numerical aperture 0.16). To encode the input image, a pseudo-random binary pattern is generated and displayed on the DMD, with a binned pixel size of 21.6 μm × 21.6 μm (3 × 3 binning).
The light reflected from the DMD is collected by the same microscope objective and tube lens, reflected by a beam splitter, and imaged onto the entrance slit of a streak camera. To allow 2D imaging, this entrance slit is opened to its maximal width (∼5 mm). Inside the streak camera, a sweeping voltage is applied along the y″ axis, deflecting the encoded image frames towards different y″ locations according to their times of arrival. The final temporally dispersed image is captured by a CCD (672 × 512 binned pixels (2 × 2 binning)) with a single exposure.
To characterize the system’s spatial frequency responses, we imaged a dynamic scene, namely, a laser pulse impinging upon a stripe pattern with varying periods as shown in Fig. 2a. The stripe frequency (in line pairs per mm) descends stepwise along the x axis from one edge to the other. We shone a collimated laser pulse (532 nm wavelength, 7 ps pulse duration) on the stripe pattern at an oblique angle of incidence α of ∼30° with respect to the normal of the pattern surface. The imaging system faced the pattern surface and collected the scattered photons from the scene. The impingement of the light wavefront upon the pattern surface was imaged by CUP at 100 billion frames per second with the streak camera’s shearing velocity set to 1.32 mm ns−1. The reconstructed 3D x, y, t image of the scene in intensity (W m−2) is shown in Fig. 2b, and the corresponding time-lapse 2D x, y images (50 mm × 50 mm FOV; 150 × 150 pixels as nominal resolution) are provided in Supplementary Video 1.

a, Experimental setup. A collimated laser pulse illuminates a stripe pattern obliquely. The CUP system faces the scene and collects the scattered photons. Laser is an Attodyne APL-4000. b, Left panel, reconstructed x, y, t datacube representing a laser pulse impinging upon the stripe pattern. Right panel, the representative frame for t = 60 ps, where the dashed line indicates the light wavefront, and the white arrow denotes the in-plane light propagation direction (kxy). The entire temporal evolution of this event is shown in Supplementary Video 1. c, Reference image captured without introducing temporal dispersion (see f for explanation of G4–G1). d, e, Projected vertical and horizontal stripe images calculated by summing over the x, y, t datacube voxels along the temporal axis. f, Comparison of average light fluence distributions along the x axis from c (labelled as Reference) and d (labelled as CUP (x axis)), as well as along the y axis from e (labelled as CUP (y axis)). G1, G2, G3 and G4 refer to the stripe groups with ascending spatial frequencies. g, Spatial frequency responses for five different orientations of the stripe pattern. The inner white dashed ellipse represents the CUP system’s band limit, and the outer yellow dashed-dotted circle represents the band limit of the optical modulation transfer function without temporal shearing. Scale bars: b, 10 mm; g, 0.1 mm–1.
Figure 2b also shows a representative temporal frame at t = 60 ps. Within a 10 ps exposure, the wavefront propagates 3 mm in space. Including the thickness of the wavefront itself, which is ∼2 mm, the wavefront image is approximately 5 mm thick along the wavefront propagation direction. The corresponding intersection with the x–y plane is 5 mm/sinα ≈ 10 mm thick, which agrees with the actual measurement (∼10 mm).
We repeated the light sweeping experiment at four additional orientations of the stripe pattern (22.5°, 45°, 67.5° and 90° with respect to the x axis) and also directly imaged the scene without temporal dispersion to acquire a reference (Fig. 2c). We projected the x, y, t datacubes onto the x–y plane by summing over the voxels along the temporal axis. The resultant images at two representative angles (0° and 90°) are shown in Fig. 2d and e, respectively. We compare in Fig. 2f the average light fluence (J m−2) distributions along the x axis from Fig. 2c and d as well as that along the y axis from Fig. 2e. The comparison indicates that CUP can recover spatial frequencies up to 0.3 line pairs per mm (groups G1, G2 and G3) along both x and y axes; however, the stripes in group G4—having a fundamental spatial frequency of 0.6 line pairs per mm—are beyond the resolution of the CUP system.
We further analysed the resolution by computing the spatial frequency spectra of the average light fluence distributions for all five orientations of the stripe pattern (Fig. 2g). Each angular branch appears continuous rather than discrete because the object has multiple stripe groups of varied frequencies and each has a limited number of periods. As a result, the spectra from the individual groups are broadened and overlapped. The CUP’s spatial frequency response band is delimited by the inner white dashed ellipse, whereas the band purely limited by the optical modulation transfer function of the system without temporal shearing—derived from the reference image (Fig. 2c)—is enclosed by the outer yellow dash-dotted circle. The CUP resolutions along the x and y axes are ∼0.43 and 0.36 line pairs per mm, respectively, whereas the unsheared-system resolution is ∼0.78 line pairs per mm. Here, resolution is defined as the noise-limited bandwidth at the 3σ threshold above the average background, where σ is the noise defined by the standard deviation of the background. The resolution anisotropy is attributed to the spatiotemporal mixing along the y axis only. Thus, CUP trades spatial resolution and resolution isotropy for temporal resolution.
To demonstrate CUP’s 2D ultrafast imaging capability, we imaged three fundamental physical phenomena with single laser shots: laser pulse reflection and refraction, and racing of two pulses in different media (air and resin). It is important to mention that, unlike a previous study11, here we truly recorded one-time events: only a single laser pulse was fired during image acquisition. In these experiments, to scatter light from the media to the CUP system, we evaporated dry ice into the light path in the air and added zinc oxide powder into the resin, respectively.
Figure 3a and b shows representative time-lapse frames of a single laser pulse reflected from a mirror in the scattering air and refracted at an air–resin interface, respectively. The corresponding movies are provided in Supplementary Videos 2 and 3. With a shearing velocity of 0.66 mm ns−1 in the streak camera, the reconstructed frame rate is 50 billion frames per second. Such a measurement allows the visualization of a single laser pulse’s compliance with the laws of light reflection and refraction, the underlying foundations of optical science. It is worth noting that the heterogeneities in the images are probably attributable to turbulence in the vapour and non-uniform scattering in the resin.

a, Representative temporal frames showing a laser pulse being reflected from a mirror in air. The bright spot behind the mirror is attributed to imperfect resolution. b, As a but showing a laser pulse being refracted at an air–resin interface. c, As a but showing two racing laser pulses; one propagates in air and the other in resin. d, Recovered light speeds in air and in resin. The corresponding movies of these three events (a, b, c) are shown in Supplementary Videos 2, 3 and 4. Scale bar (in top right subpanel), 10 mm.
To validate CUP’s ability to quantitatively measure the speed of light, we imaged photon racing in real time. We split the original laser pulse into two beams: one beam propagated in the air and the other in the resin. The representative time-lapse frames of this photon racing experiment are shown in Fig. 3c, and the corresponding movie is provided in Supplementary Video 4. As expected, owing to the different refractive indices (1.0 in air and 1.5 in resin), photons ran faster in the air than in the resin. By tracing the centroid from the time-lapse laser pulse images (Fig. 3d), the CUP-recovered light speeds in the air and in the resin were (3.1 ± 0.5) × 108 m s−1 and (2.0 ± 0.2) × 108 m s−1, respectively, consistent with the theoretical values (3.0 × 108 m s−1 and 2.0 × 108 m s−1). Here the standard errors are mainly attributed to the resolution limits.
By monitoring the time-lapse signals along the laser propagation path in the air, we quantified CUP’s temporal resolution. Because the 7 ps pulse duration is shorter than the frame exposure time (20 ps), the laser pulse was considered as an approximate impulse source in the time domain. We measured the temporal point-spread functions (PSFs) at different spatial locations along the light path imaged at 50 billion frames per second (20 ps exposure time), and their full widths at half maxima averaged 74 ps. Additionally, to study the dependence of CUP’s temporal resolution on the frame rate, we repeated this experiment at 100 billion frames per second (10 ps exposure time) and re-measured the temporal PSFs. The mean temporal resolution was improved from 74 ps to 31 ps at the expense of signal-to-noise ratio. At a higher frame rate (that is, higher shearing velocity in the streak camera), the light signals are spread over more pixels on the CCD camera, reducing the signal level per pixel and thereby causing more potential reconstruction artefacts.
To explore CUP’s potential application in modern physics, we imaged apparent faster-than-light phenomena in 2D movies. According to Einstein’s theory of relativity, the propagation speed of matter cannot surpass the speed of light in vacuum because it would need infinite energy to do so. Nonetheless, if the motion itself does not transmit information, its speed can be faster than light20. This phenomenon is referred to as faster-than-light propagation of non-information. To visualize this phenomenon with CUP, we designed an experiment using a setup similar to that shown in Fig. 2a. The pulsed laser illuminated the scene at an oblique angle of incidence of ∼30°, and CUP imaged the scene normally (0° angle). To facilitate the calculation of speed, we imaged a stripe pattern with a constant period of 12 mm (Fig. 4a).

a, Photograph of a stripe pattern with a constant period of 12 mm. b, Representative temporal CUP frames, showing the optical wavefront sweeping across the pattern. The corresponding movie is shown in Supplementary Video 5. The striped arrow indicates the motion direction. c, Illustration of the information transmission in this event. The intersected wavefront on the screen travels at a speed, vFTL, which is twice the speed of light in air, cair. However, because the light wavefront carries the actual information, the information transmission velocity from location A to B is still limited to cair. Scale bar, 5 mm.
The movement of a light wavefront intersecting this stripe pattern is captured at 100 billion frames per second with the streak camera’s shearing velocity set to 1.32 mm ns−1. Representative temporal frames and the corresponding movie are provided in Fig. 4b and Supplementary Video 5, respectively. As shown in Fig. 4b, the white stripes shown in Fig. 4a are illuminated sequentially by the sweeping wavefront. The speed of this motion, calculated by dividing the stripe period by their lit-up time interval, is vFTL = 12 mm/20 ps = 6 × 108 m s−1, twice the speed of light in the air due to the oblique incidence of the laser beam (FTL, faster than light). As shown in Fig. 4c, although the intersected wavefront—the only feature visible to the CUP system—travels from location A to B faster than the light wavefront, the actual information is carried by the wavefront itself, and therefore its transmission velocity is still limited by the speed of light in the air.
Secure communication using CUP is possible because the operator O is built upon a pseudo-randomly generated code matrix sheared at a preset velocity. The encrypted scene can therefore be decoded only by recipients who are granted access to the decryption key. Using a DMD (instead of a pre-made mask) as the field encoding unit in CUP facilitates pseudo-random key generation and potentially allows the encoding pattern to be varied for each exposure transmission, thereby minimizing the impact of theft with a single key decryption on the overall information security. Furthermore, compared with other compressed-sensing-based secure communication methods for either a 1D signal or a 2D image21,22,23, CUP operates on a 3D data set, allowing transient events to be captured and communicated at faster speed.
Although not demonstrated here, CUP can potentially be coupled to a variety of imaging modalities, such as microscopes and telescopes, allowing us to image transient events at scales from cellular organelles to galaxies. For example, in conventional fluorescence lifetime imaging microscopy (FLIM)24, point scanning or line scanning is typically employed to achieve 2D fluorescence lifetime mapping. However, these scanning instruments cannot collect light from all elements of a data set in parallel. As a result, when measuring an image of Nx × Ny pixels, there is a loss of throughput by a factor of Nx × Ny (point scanning) or Ny (line scanning). Additionally, scanning-based FLIM suffers from severe motion artefacts when imaging dynamic scenes, limiting its application to fixed or slowly varying samples. By integrating CUP with FLIM, we could accomplish parallel acquisition of a 2D fluorescence lifetime map within a single snapshot, thereby providing a simple solution to these long-standing problems in FLIM.
Methods
Forward model
We describe CUP’s image formation process using a forward model. The intensity distribution of the dynamic scene, I(x, y, t), is first imaged onto an intermediate plane by an optical imaging system. Under the assumption of unit magnification and ideal optical imaging—that is, the PSF approaches a delta function—the intensity distribution of the resultant intermediate image is identical to that of the original scene. To encode this image, a mask which contains pseudo-randomly distributed, squared and binary-valued (that is, either opaque or transparent) elements is placed at this intermediate image plane. The image immediately after this encoding mask has the following intensity distribution:

Here, Ci,j is an element of the matrix representing the coded mask, i, j are matrix element indices, and d′ is the mask pixel size. For each dimension, the rectangular function (rect) is defined as:

In this section, a mask or camera pixel is equivalent to a binned DMD or CCD pixel defined in the experiment.
This encoded image is then passed to the entrance port of a streak camera. By applying a voltage ramp, the streak camera acts as a shearing operator along the vertical axis (y″ axis in Extended Data Fig. 1) on the input image. If we again assume ideal optics with unit magnification, the sheared image can be expressed as

where v is the shearing velocity of the streak camera.
Is(x″, y″, t) is then spatially integrated over each camera pixel and temporally integrated over the exposure time. The optical energy, E(m, n), measured at pixel m, n, is:

Here, d″ is the camera pixel size. Accordingly, we can voxelize the input scene, I(x, y, t), into Ii,j,k as follows:

where  . If the mask elements are mapped 1:1 to the camera pixels (that is, d′ = d″) and perfectly registered, combining equations (5)–(8) yields:
. If the mask elements are mapped 1:1 to the camera pixels (that is, d′ = d″) and perfectly registered, combining equations (5)–(8) yields:

Here  represents a coded, sheared scene, and the inverse problem of equation (9) can be solved using existing compressed-sensing algorithms25,26,27,28,29.
represents a coded, sheared scene, and the inverse problem of equation (9) can be solved using existing compressed-sensing algorithms25,26,27,28,29.
It is worth noting that only those indices where n – k > 0 should be included in equation (9). Thus, to convert equation (9) into a matrix equation, we need to augment the matrices C and I with an array of zeros. For example, to estimate a dynamic scene with dimensions Nx × Ny × Nt (Nx, Ny and Nt are respectively the numbers of voxels along x, y and t), where the coded mask itself has dimensions Nx × Ny, the actual matrices I and C used in equation (9) will have dimensions Nx × (Ny + Nt − 1) × Nt and Nx × (Ny + Nt − 1), respectively, with zeros padded to the ends. After reconstruction, these extra voxels, containing non-zero values due to noise, are simply discarded.
CUP image reconstruction algorithm
Given prior knowledge of the coded mask matrix, to estimate the original scene from the CUP measurement, we need to solve the inverse problem of equation (9). This process can be formulated in a more general form as

where O is the linear operator, Φ(I) is the regularization function, and β is the regularization parameter. In CUP image reconstruction, we adopt an algorithm called two-step iterative shrinkage/thresholding (TwIST)25, with Φ(I) in the form of total variation (TV):

Here we assume that the discretized form of  has dimensions Nx × Ny × Nt, and m, n, k are the three indices. Im, In, Ik denote the 2D lattices along the dimensions m, n, k, respectively.
has dimensions Nx × Ny × Nt, and m, n, k are the three indices. Im, In, Ik denote the 2D lattices along the dimensions m, n, k, respectively.  and
and  are horizontal and vertical first-order local difference operators on a 2D lattice. In TwIST, the minimization of the first term,
are horizontal and vertical first-order local difference operators on a 2D lattice. In TwIST, the minimization of the first term,  , occurs when the actual measurement E closely matches the estimated measurement OI, while the minimization of the second term, βΦ(I), encourages I to be piecewise constant (that is, sparse in the gradient domain). The weighting of these two terms is empirically adjusted by the regularization parameter, β, to lead to the results that are most consistent with the physical reality. To reconstruct a datacube of size 150 × 150 × 350 (x, y, t), approximately ten minutes is required on a computer with Intel i5-2500 CPU (3.3 GHz) and 8 GB RAM. The reconstruction process can be further accelerated by using GPUs.
, occurs when the actual measurement E closely matches the estimated measurement OI, while the minimization of the second term, βΦ(I), encourages I to be piecewise constant (that is, sparse in the gradient domain). The weighting of these two terms is empirically adjusted by the regularization parameter, β, to lead to the results that are most consistent with the physical reality. To reconstruct a datacube of size 150 × 150 × 350 (x, y, t), approximately ten minutes is required on a computer with Intel i5-2500 CPU (3.3 GHz) and 8 GB RAM. The reconstruction process can be further accelerated by using GPUs.
Traditionally, the TwIST algorithm is initialized with a pseudo-random matrix as the discretized form of  and then converged to a solution by minimizing the objective function in equation (10). Thus no spatiotemporal information about the event is typically employed in the basic TwIST algorithm. However, it is important to remember that the solution of TwIST might not converge to a global minimum, and hence might not provide a physically reasonable estimate of the event. Therefore, the TwIST algorithm may include a supervision step that models the initial estimate of the event. For example, if the spatial or temporal range within which an event occurs is known a priori, one can assign non-zero values to only the corresponding voxels in the initial estimate of the discretized form of I and start optimization thereafter. Compared with the basic TwIST algorithm, the supervised-TwIST approach can substantially reduce reconstruction artefacts and therefore provide a more reliable solution.
and then converged to a solution by minimizing the objective function in equation (10). Thus no spatiotemporal information about the event is typically employed in the basic TwIST algorithm. However, it is important to remember that the solution of TwIST might not converge to a global minimum, and hence might not provide a physically reasonable estimate of the event. Therefore, the TwIST algorithm may include a supervision step that models the initial estimate of the event. For example, if the spatial or temporal range within which an event occurs is known a priori, one can assign non-zero values to only the corresponding voxels in the initial estimate of the discretized form of I and start optimization thereafter. Compared with the basic TwIST algorithm, the supervised-TwIST approach can substantially reduce reconstruction artefacts and therefore provide a more reliable solution.
Effective field-of-view measurement
In CUP, a streak camera (Hamamatsu C7700) temporally disperses the light. The streak camera’s entrance slit can be fully opened to a 17 mm × 5 mm rectangle (horizontal × vertical axes). Without temporal dispersion, the image of this entrance slit on the CCD has an approximate size of 510 × 150 pixels. However, because of a small angle between each individual micro-mirror’s on-state normal and the DMD’s surface normal, the DMD as a whole needs to be tilted horizontally so that the incident light can be exactly retroreflected. With an NA of 0.16, the collecting objective’s depth of focus thereby limits the horizontal encoding field of view (FOV) to approximately 150 pixels at the CCD. Extended Data Fig. 2 shows a temporally undispersed CCD image of the DMD mask. The effective encoded FOV is approximately 150 × 150 pixels. Note that with temporal dispersion, the image of this entrance slit on the CCD can be stretched along the y″ axis to approximately 150 × 500 pixels.
Calibration
To calibrate for operator matrix C, we use a uniform scene as the input image and apply zero sweeping voltage in the streak camera. The coded pattern on the DMD is therefore directly imaged onto the CCD without introducing temporal dispersion. A background image is also captured with all DMD pixels turned on. The illumination intensity non-uniformity is corrected for by dividing the coded pattern image by the background image pixel by pixel, yielding operator matrix C. Note that because CUP’s image reconstruction is sensitive to mask misalignment, we use a DMD for better stability rather than pre-made masks that would require mechanical swapping between system alignment and calibration or data acquisition.
Limitation on CUP’s frame rate and reconstructed datacube size
The CUP system’s frame rate and temporal resolution are determined by the shearing velocity of the streak camera: a faster shearing velocity results in a higher frame rate and temporal resolution. Unless the illumination is intensified, however, the shortened observation time window causes the signal-to-noise ratio to deteriorate, which reduces image reconstruction quality. The shearing velocity thus should be balanced to accommodate a specific imaging application at a given illumination intensity.
In CUP, the size of the reconstructed event datacube, Nx × Ny × Nt, is limited fundamentally by the acceptance NA of the collecting objective, photon shot noise, and sensitivity of the photocathode tube, as well as practically by the number of binned CCD pixels (NR × NC; NR, the number of rows; NC, the number of columns). Provided that the image formation closely follows the ideal forward model, the number of binned CCD pixels becomes the underlying limiting factor. Along the horizontal direction, the number of reconstructed voxels must be less than the number of detector columns, that is, Nx ≤ NC. In multicolour CUP, this requirement becomes Nx ≤ NC/NL, where NL is the number of spectral channels (that is, wavelengths). Along the vertical direction, to avoid field clipping, the sampling obeys Ny + Nt – 1 ≤ NR because the spatial information and temporal information overlap and occupy the same axis.
Multicolour CUP
To extend CUP’s functionality to reproducing colours, we added a spectral separation module in front of the streak camera. As shown in Extended Data Fig. 3a, a dichroic filter (≥98% reflective for 490–554 nm wavelength, 50% reflective and 50% transmissive at 562 nm, and ≥90% transmissive for 570–750 nm) is mounted on a mirror at a small tilt angle ( ). The light reflected from this module is divided into two beams according to the wavelength: green light (wavelength <562 nm) is directly reflected from the dichroic filter, while red light (wavelength >562 nm) passes through the dichroic filter and bounces from the mirror. Compared with the depth of field of the imaging system, the introduced optical path difference between these two spectral channels is negligible, therefore maintaining the images in focus for both colours.
). The light reflected from this module is divided into two beams according to the wavelength: green light (wavelength <562 nm) is directly reflected from the dichroic filter, while red light (wavelength >562 nm) passes through the dichroic filter and bounces from the mirror. Compared with the depth of field of the imaging system, the introduced optical path difference between these two spectral channels is negligible, therefore maintaining the images in focus for both colours.
Using the multicolour CUP system, we imaged a pulsed-laser-pumped fluorescence emission process. A fluorophore, Rhodamine 6G, in water solution was excited by a single 7 ps laser pulse at 532 nm. To capture the entire fluorescence decay, we used 50 billion frames per second by setting a shearing velocity of 0.66 mm ns−1 on the streak camera. The movie and some representative temporal frames are shown in Supplementary Video 6 and Extended Data Fig. 3b, respectively. In addition, we calculated the time-lapse mean signal intensities within the dashed box in Extended Data Fig. 3b for both the green and red channels (Extended Data Fig. 3c). Based on the measured fluorescence decay, the fluorescence lifetime was found to be 3.8 ns, closely matching a previously reported value30.
In theory, the time delay from the pump laser excitation to the fluorescence emission due to the molecular vibrational relaxation is ∼6 ps for Rhodamine 6G31. However, our results show that the fluorescence starts to decay ∼180 ps after the pump laser signal reaches its maximum. In the time domain, with 50 billion frames per second sampling, the laser pulse functions as an approximate impulse source while the onset of fluorescence acts as a decaying edge source. Blurring due to the temporal PSF stretches these two signals’ maxima apart.
We theoretically simulated this process by using the experimentally measured temporal PSF and the fitted fluorescence decay as the input in Matlab (R2011a). The arrival of the pump laser pulse and the subsequent fluorescence emission are described by a Kronecker delta function (Extended Data Fig. 3d) and an exponentially decaying edge function (Extended Data Fig. 3e), respectively. For the Rhodamine 6G fluorophore, we neglect the molecular vibrational relaxation time and consider the arrival of the pump laser pulse and the onset of fluorescence emission to be simultaneous. After pump laser excitation, the decay of the normalized fluorescence intensity,  , is modelled as
, is modelled as  , where τ = 3.8 ns. To simulate the temporal-PSF-induced blurring, we convolve an experimentally measured temporal PSF (Extended Data Fig. 3f) with these two event functions shown in Extended Data Fig. 3d and e. The results in Extended Data Fig. 3g indicate that this process introduces an approximate 200 ps time delay between the signal maxima of these two events, which is in good agreement with our experimental observation. Although the full width at half maximum of the main peak in the temporal PSF is only ∼80 ps, the reconstruction-induced side lobe and shoulder extend over a range of 280 ps, which temporally stretches the signal maxima of these two events apart.
, where τ = 3.8 ns. To simulate the temporal-PSF-induced blurring, we convolve an experimentally measured temporal PSF (Extended Data Fig. 3f) with these two event functions shown in Extended Data Fig. 3d and e. The results in Extended Data Fig. 3g indicate that this process introduces an approximate 200 ps time delay between the signal maxima of these two events, which is in good agreement with our experimental observation. Although the full width at half maximum of the main peak in the temporal PSF is only ∼80 ps, the reconstruction-induced side lobe and shoulder extend over a range of 280 ps, which temporally stretches the signal maxima of these two events apart.
References
Fuller, P. W. W. An introduction to high speed photography and photonics. Imaging Sci. J. 57, 293–302 (2009)
Li, Z., Zgadzaj, R., Wang, X., Chang, Y.-Y. & Downer, M. C. Single-shot tomographic movies of evolving light-velocity objects. Nature Commun. 5, 3085 (2014)
Nakagawa, K. et al. Sequentially timed all-optical mapping photography (STAMP). Nature Photon. 8, 695–700 (2014)
Heshmat, B., Satat, G., Barsi, C. & Raskar, R. Single-shot ultrafast imaging using parallax-free alignment with a tilted lenslet array. CLEO Sci. Innov. http://dx.doi.org/10.1364/CLEO_SI.2014.STu3E.7 (2014)
Munn, O. & Beach, A. A horse’s motion scientifically determined. Sci. Am. 39, 241 (1878)
Mach, E. & Salcher, P. Photographische Fixirung der durch Projectile in der Luft eingeleiteten Vorgänge. Ann. Phys. 268, 277–291 (1887)
Nebeker, S. Rotating mirror cameras. High Speed Photogr. Photon. Newsl. 3, 31–37 (1983)
Kondo, Y. et al. Development of “HyperVision HPV-X” high-speed video camera. Shimadzu Rev. 69, 285–291 (2012)
El-Desouki, M. et al. CMOS image sensors for high speed applications. Sensors 9, 430–444 (2009)
Guide. to Streak Camerashttp://www.hamamatsu.com/resources/pdf/sys/e_streakh.pdf (Hamamatsu Corp., Hamamatsu City, Japan, 2002)
Velten, A., Lawson, E., Bardagjy, A., Bawendi, M. & Raskar, R. Slow art with a trillion frames per second camera. Proc. SIGGRAPH 44 (2011)
Velten, A. et al. Recovering three-dimensional shape around a corner using ultrafast time-of-flight imaging. Nature Commun. 3, 745 (2012)
Solli, D. R., Ropers, C., Koonath, P. & Jalali, B. Optical rogue waves. Nature 450, 1054–1057 (2007)
Eldar, Y. C. & Kutyniok, G. Compressed Sensing: Theory and Applications (Cambridge Univ. Press, 2012)
Figueiredo, M. A. T., Nowak, R. D. & Wright, S. J. Gradient projection for sparse reconstruction: application to compressed sensing and other inverse problems. IEEE J. Sel. Top. Signal Process. 1, 586–597 (2007)
Bioucas-Dias, J. M. & Figueiredo, M. A. T. A new TwIST: two-step iterative shrinkage/thresholding algorithms for image restoration. IEEE Trans. Image Process. 16, 2992–3004 (2007)
Afonso, M. V., Bioucas-Dias, J. M. & Figueiredo, M. A. T. Fast image recovery using variable splitting and constrained optimization. IEEE Trans. Image Process. 19, 2345–2356 (2010)
Wright, S. J., Nowak, R. D. & Figueiredo, M. A. T. Sparse reconstruction by separable approximation. IEEE Trans. Signal Process. 57, 2479–2493 (2009)
Afonso, M. V., Bioucas-Dias, J. M. & Figueiredo, M. A. T. An augmented Lagrangian approach to the constrained optimization formulation of imaging inverse problems. IEEE Trans. Image Process. 20, 681–695 (2011)
Einstein, A. Relativity: The Special and General Theory (Penguin, 1920)
Agrawal, S. & Vishwanath, S. Secrecy using compressive sensing. Proc. Inform. Theory Workshop, IEEE, 563–567 (2011)
Orsdemir, A., Altun, H. O., Sharma, G. & Bocko, M. F. On the security and robustness of encryption via compressed sensing. Proc. Military Commun. Conf., IEEE, 1–7 (2008)
Davis, D. L. Secure compressed imaging. US patent 5,907. 619 (1999)
Borst, J. W. & Visser, A. J. W. G. Fluorescence lifetime imaging microscopy in life sciences. Meas. Sci. Technol. 21, 102002 (2010)
Figueiredo, M. A. T., Nowak, R. D. & Wright, S. J. Gradient projection for sparse reconstruction: application to compressed sensing and other inverse problems. IEEE Sel. Top. Signal Process. 1, 586–597 (2007)
Bioucas-Dias, J. M. & Figueiredo, M. A. T. A new TwIST: two-step iterative shrinkage/thresholding algorithms for image restoration. IEEE Trans. Image Process. 16, 2992–3004 (2007)
Afonso, M. V., Bioucas-Dias, J. M. & Figueiredo, M. A. T. Fast image recovery using variable splitting and constrained optimization. IEEE Trans. Image Process. 19, 2345–2356 (2010)
Wright, S. J., Nowak, R. D. & Figueiredo, M. A. T. Sparse reconstruction by separable approximation. IEEE Trans. Signal Process. 57, 2479–2493 (2009)
Afonso, M. V., Bioucas-Dias, J. M. & Figueiredo, M. A. T. An augmented Lagrangian approach to the constrained optimization formulation of imaging inverse problems. IEEE Trans. Image Process. 20, 681–695 (2011)
Selanger, K. A., Falnes, J. & Sikkeland, T. Fluorescence lifetime studies of rhodamine 6G in methanol. J. Phys. Chem. 81, 1960–1963 (1977)
Rentzepis, P. M., Topp, M. R., Jones, R. P. & Jortner, J. Picosecond emission spectroscopy of homogeneously broadened, electronically excited molecular states. Phys. Rev. Lett. 25, 1742–1745 (1970).
Acknowledgements
We thank N. Hagen for discussions and J. Ballard for a close reading of the manuscript. We also acknowledge Texas Instruments for providing the DLP device. This work was supported in part by National Institutes of Health grants DP1 EB016986 (NIH Director’s Pioneer Award) and R01 CA186567 (NIH Director’s Transformative Research Award).
Author information
Authors and Affiliations
Contributions
L.G. built the system, performed the experiments, analysed the data and prepared the manuscript. J.L. performed some of the experiments, analysed the data and prepared the manuscript. C.L. prepared the sample and performed some of the experiments. L.V.W. contributed to the conceptual system, experimental design and manuscript preparation.
Corresponding author
Ethics declarations
Competing interests
L.V.W. has a financial interest in Microphotoacoustics, Inc. and Endra, Inc., which, however, did not support this work.
Extended data figures and tables
Extended Data Figure 1 CUP image formation model.
x, y, spatial coordinates; t, time; m, n, k, matrix indices; Im,n,k, input dynamic scene element; Cm,n, coded mask matrix element; Cm,n−kIm,n−k,k, encoded and sheared scene element; Em,n, image element energy measured by a 2D detector array; tmax, maximum recording time. See Methods for details.
Extended Data Figure 2
A temporally undispersed CCD image of the coded mask, which encodes the uniformly illuminated field with a pseudo-random binary pattern. The position of the mask and definition of the x′–y′ plane are shown in Fig. 1.
Extended Data Figure 3 Multicolour CUP.
a, Custom-built spectral separation unit. b, Representative temporal frames of a pulsed-laser-pumped fluorescence emission process. The pulsed pump laser and fluorescence emission are pseudo-coloured based on their peak emission wavelengths. To explicitly indicate the spatiotemporal pattern of this event, the CUP-reconstructed frames are overlaid with a static background image captured by a monochromatic CCD camera. All temporal frames of this event are provided in Supplementary Video 6. c, Time-lapse pump laser and fluorescence emission intensities averaged within the dashed box in b. The temporal responses of pump laser excitation and fluorescence decay are fitted to a Gaussian function and an exponential function, respectively. The recovered fluorescence lifetime of Rhodamine 6G is 3.8 ns. d, Event function describing the pulsed laser fluorescence excitation. e, Event function describing the fluorescence emission. f, Measured temporal PSF, with a full width at half maximum (FWHM) of ∼80 ps. Owing to reconstruction artefacts, the PSF has a side lobe and a shoulder extending over a range of 280 ps. g, Simulated temporal responses of event functions d and e after being convolved with the temporal PSF. The maxima of these two time-lapse signals are stretched by 200 ps. Scale bar, 10 mm.
Supplementary information
Light sweeping across a stripe pattern with varied spatial frequencies
Light sweeping across a stripe pattern with varied spatial frequencies. (MOV 107 kb)
Laser pulse reflection from a mirror
Laser pulse reflection from a mirror. (MOV 22 kb)
Laser pulse refraction at an air-resin interface
Laser pulse refraction at an air-resin interface (MOV 17 kb)
Laser pulse racing in different media
Laser pulse racing in different media. (MOV 23 kb)
Apparent faster-than-light phenomenon
Apparent faster-than-light phenomenon. (MOV 107 kb)
Pulsed-laser-pumped fluorescence emission
Pulsed-laser-pumped fluorescence emission. (MOV 679 kb)
Rights and permissions
About this article

Cite this article
Gao, L., Liang, J., Li, C. et al. Single-shot compressed ultrafast photography at one hundred billion frames per second. Nature 516, 74–77 (2014). https://doi.org/10.1038/nature14005
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/nature14005
- Springer Nature Limited
This article is cited by
-
Swept coded aperture real-time femtophotography
Nature Communications (2024)
-
Fast topographic optical imaging using encoded search focal scan
Nature Communications (2024)
-
Single-pulse real-time billion-frames-per-second planar imaging of ultrafast nanoparticle-laser dynamics and temperature in flames
Light: Science & Applications (2023)
-
Real-time observation of optical rogue waves in spatiotemporally mode-locked fiber lasers
Communications Physics (2023)
-
Single-shot ultrafast terahertz photography
Nature Communications (2023)