
Abstract
Air pollution is a major environmental and health problem, especially in urban agglomerations. Estimating personal exposure to fine particulate matter (PM2.5) remains a great challenge because it requires numerous point measurements to explain the daily spatial variation in pollutant levels. Furthermore, meteorological variables have considerable effects on the dispersion and distribution of pollutants, which also depends on spatio-temporal emission patterns. In this study we developed a hybrid interpolation technique that combined the inverse distance-weighted (IDW) method with Kriging with external drift (KED), and applied it to daily PM2.5 levels observed at 10 monitoring stations. This provided us with downscaled high-resolution maps of PM2.5 for the Island of Montreal. For the KED interpolation, we used spatio-temporal daily meteorological estimates and spatial covariates as land use and vegetation density. Different KED and IDW daily estimation models for the year 2010 were developed for each of the six synoptic weather classes. These clusters were developed using principal component analysis and unsupervised hierarchical classification. The results of the interpolation models were assessed with a leave-one-station-out cross-validation. The performance of the hybrid model was better than that of the KED or the IDW alone for all six synoptic weather classes (the daily estimate for R2 was 0.66–0.93 and for root mean square error (RMSE) 2.54–1.89 μg/m3).
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.INTRODUCTION
Fine particulate matter (PM) with a median diameter of 2.5 μm or less (PM2.5) is a main component of smog.1 PM2.5 can be emitted directly in the atmosphere or generated through the gas-to-particle process (secondary) from sulfur oxides, nitrogen oxides, ammonia and volatile organic compounds.2 Many studies have shown associations between daily PM2.5 levels and respiratory or cardiovascular morbidity and mortality.2, 3, 4, 5 One major limitation of many studies on the health effects of short term air pollutant exposures is that they fail to consider spatial variation in pollutant levels.6, 7 This may introduce uncertainty in the estimation of the exposure of individuals in epidemiologic studies.
The spatial variation of pollutant levels such as PM2.5 is influenced by the location of the emission sources, meteorological conditions and site topography.8 Meteorological conditions such as precipitation, wind speed, temperature, humidity and atmospheric pressure determine the diffusion and transport of PM2.5. For example, an increase in the precipitation rate has a negative effect on the levels of PM2.5,9 local air circulation controls the dispersion and transport in the region,10 high winds disperse and transport pollutants over larger areas,9, 11 whereas temperature inversion (increases of temperature with height) traps pollutants close to the ground, thereby increasing their levels.12
To estimate the spatial variation in pollutant levels over extensive urban environments, a number of methods have been commonly used, among them univariate models such as the inverse distance-weighted (IDW)13 model and multivariate models such as land use regression (LUR)14, 15 and Bayesian Maximum Entropy models.16, 17 The multivariate models rely on some form of spatial dependence between covariates to create a continuous surface of exposure over time for a given area of interest.18 Nevertheless, such multivariate models are typically based on regressing annual averages of pollutant concentrations using geographic covariate invariants in time.19
The main objective of this work was to develop and compare interpolation models aimed at mapping daily ground-level PM2.5 concentrations at high resolution on the Island of Montreal. To pursue this objective, we explored the use of KED in combination with IDW to predict daily PM2.5 concentrations. The approach developed takes into account both broad spatial trends and local variations.20 To account for spatial dependence on meteorological variables, these models were calibrated separately for each synoptic weather class.
METHODS
Study Area
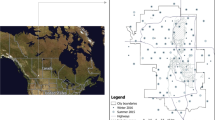
The study area is the Island of Montreal, which is mainly occupied by the City of Montreal (the second largest city in Canada) with a population of 1.89 million people. The city is bordered by the Rivière des Prairies and the Saint Lawrence River and is situated between 45.40°–45.72°N and 73.98°–73.45°W (Figure 1). The island is mostly flat, with the exception of a moderate hill, the Mount Royal, culminating at 234 m above sea level. The climate is classified as humid continental that, with severe winters and hot, humid summers, is subject to tremendous meteorological variations. The predominant wind direction is south–west, followed by north–east winds along the Saint Lawrence River. Poor air quality days on the Island of Montreal are associated with high concentrations of PM2.5, which are attributed to residential wood burning, road traffic, industrial activities, fireworks, forest fires occurring hundreds of kilometers north of the island,21 and long-range transport from industrial regions south of the border and around the Great Lakes. Also, meteorological conditions have an important role in determining pollution levels at proximity to sources. The study period for which interpolation models were developed spans from January to December 2010.

Geographical location of PM2.5 stations and meteorological stations in the study region.
PM2.5 and Meteorological Data
For each day of the study period, hourly data of PM2.5 concentrations were obtained from the National Air Pollution Surveillance (NAPS) network of Environment Canada.22 The NAPS network uses different equipment to measure ambient PM2.5 concentration. Currently, the most widely used methods in Canada are the Tapered Element Oscillating Microbalance (TEOM) method, which is based on inertial properties, and the BAM-1020 beta attenuation monitor.23 On the Island of Montreal, fine PM is measured with 10 NAPS monitors using TEOM technology with a Filter Dynamic Measurement System (Figure 1). PM2.5 monitoring stations provide a spatially sparse sample of particulate data with a good continuity in time. Meteorological measurements were obtained from the National Climatic Data and Information Archive of Environment Canada.24 There are eight meteorological monitoring stations across the Montreal Census Metropolitan Area (Figure 1). We calculated daily averages of PM2.5 levels, whereby wind speed, temperature, relative humidity and precipitation for all available monitoring data had no more than 2 h of missing values on any given day. In addition, extreme PM2.5 levels (outliers) that occurred during major forest fire events were excluded in the preprocessing stage. To identify these outliers, we used a list of major smog episodes from Environment Canada.25
Synoptic Weather Analysis
Although weather conditions in the study area are very variable, some general patterns were observed over the year.26 Assuming that the temporal variation and spatial distribution of PM2.5 concentrations are correlated with meteorological conditions, we used data from 2008–2010 to identify clusters of days having similar meteorological patterns, in other words, synoptic groups. A time period longer than the study period (i.e., beyond 2010) was used to classify days into synoptic groups, allowing for a robust classification based on a larger number of observations. To identify the synoptic groups, we proceeded in two stages. First we used principal component analysis (PCA) to reduce the existing correlation between the mean daily values of four meteorological variables (wind speed, temperature, relative humidity and precipitation) (949 observations) while retaining most of the information contained in the data. Then, to identify groups that contain similar meteorological patterns, we applied a hierarchical cluster analysis (HCA) to the variables resulting from the PCA. HCA is a method based on a hierarchical divisive and agglomerative approach where each data subset is associated to levels of the tree diagram (dendrogram).
External Variables for KED
The following were considered as potential external (independent) variables for the KED: spatio-temporal daily meteorological estimates, land use, population density, proximity to industry (weighted emissions), weighted road density (WRD) and greenness tasseled-cap.
Spatio-temporal Meteorological Variables
We performed an IDW interpolation to estimate meteorological surfaces (with cells sizes of 100 m) of all meteorological variables (wind speed, temperature, relative humidity and precipitation) for all days of the study period (2010). This operation was carried out using the R software version 3.1.1 (R Project for Statistical Computing; http://www.r-project.org).
Geographic Variables
WRD, industrial emission-weighted proximity, land use (urban, industrial and commercial area), population density and the greenness component of the tasseled-cap image transformation were calculated using circular buffers of different radii around the geographical features using the procedures described below. Throughout the design of geographical layers, the radii were selected based on a priori knowledge of the range of influence of each variable represented in the layer. A compromise was made between investigating several possible ranges of influences by using different radii and by limiting the total number of layers to be generated and analyzed. All output variables were created in raster format (uniform grids) with cells of 100 × 100 m using ArcGIS v.10.2 (ESRI).
WRD
Road traffic is a source of particles and their precursors. We obtained road network data from the 2010 Road Layer Dataset (CanMap RouteLogistics version 2010.3) compiled by Digital Mapping Technology (DMTI). We extracted the classes “highway” (expressway, principal and secondary highway), “major road” and “local road” from the complete road dataset and arbitrarily assigned weight value 3 to “highway”, 2 to “major road” and 1 to “local road” to represent their relative contribution to local concentrations of particles. Weights based on the hierarchical level of roads showed a similar accuracy as the density of traffic counts, as showed in previous studies.27, 28 The weighted road density (WRD)27 variable is used as a proxy for exposure to traffic-related pollution. A maximum distance of influence related to the traffic of 1500 m has been reported.29 Here we calculated the total kilometers of weighted road within 100, 150, 250 and 1000-m buffers around each cell (100 × 100 m), representing a measurement site. WRD was expressed in meters per square kilometer and is based on the following equation:

where Li is the length of roads within the buffer, Vi the arbitrary weights applied to each road class, and r the radial size of the buffer.
PM2.5 industrial emission-weighted proximity
Industries are important emitters of PM2.5. PM2.5 industrial emission data for the year 2010 were obtained from the National Pollutant Release Inventory of Environment Canada. They consist of point locations of the annual emissions volume of each industrial source. The exposure risk is defined as a ratio of the exposure risk value for the receptor to the average exposure risk value for all the receptors present within the study area.30 The proximity model used (the emission-weighted proximity model, EWPM) assumes that exposure decreases with distance and increases with emissions.30 EWPM is a simple approach used to estimate spatially the PM2.5 industrial emissions to facilitate the implementation of the proposed method. The calculation of EWPM is based on the followings: first, to simulate exposure at given points in space, we converted a uniform grid with a cell size of 100 m to points (centroids of each cell to represent the receptors). Second, the calculation of exposure intensity value (REWPM) at each point was based on the following EWPM equation:

where Ei,j and Ti,j are the emission rate and emission year of jth emission source, i the index of receptors; Di,j the distance separating i and j; and n and m the number of exposure points and the number of emission sources respectively.
Land use data
The land use types (residential, commercial and industrial) were extracted from DMTI Spatial data for the year 2010. These classes are used as surrogate measures for residential, commercial and industrial emissions related to fine PM. The original land use polygons were converted to a raster grid to allow aggregating the area of each land use class within search radii of 300, 500 and 750 m. We used these buffer sizes because these scales showed associations with PM2.5 in many studies.14, 31, 32 We used neighborhood statistics (a function of the ArcGIS Spatial Analyst extension) to compute the sum of the area of each land use type within circular buffers. This calculation resulted in three layers (one for each land use type) for each circle’s radius.
Population density
Households may emit PM2.5 from heating activities, proportionally to population density. To model this, we used data of population per dissemination area from the 2006 census from Statistics Canada. A dissemination area is a small census unit with a population of 400–700 persons.33 The dissemination area polygons were converted to centroids and the population count of each polygon was assigned to its centroid. We used kernel density to estimate the values within radii of 1000 and 2500 m.14 Again, these buffer sizes were used because these sizes showed correlations with PM2.5 in similar studies7, 14, 34 and because they better reflected the population distribution of larger dissemination areas that also include low population land uses, such as of commercial and industrial zones.
Remote sensing greenness tasseled-cap transformation
Vegetation can reduce levels of ambient PM2.5 and improve air quality.35 We extracted the greenness component from a tasseled-cap transformation of a Landsat Thematic Mapper (TM) image. The selected TM scene (path/row 014/028) for Montreal was captured on 27 July 27 2010. This image was orthorectified and provided by the US Geological Survey. The tasseled-cap is an orthogonal transformation of reflective bands, which isolates greenness, wetness and soil brightness.36 The greenness component exhibits high values for surfaces with high-vegetation density and low values for soil surfaces. For each grid of 100 m, the mean of the greenness component was calculated in a 500-m buffer, whereby this size was used because other studies demonstrated an association with PM2.5 and other related pollutants in that buffer.37, 38
Spatio-temporal Modeling
To map spatial and temporal variation of PM2.5 levels, we developed interpolation models based on mathematical and geostatistical approaches to interpolate values using the R software version 3.1.1 (R Project for Statistical Computing; http://www.r-project.org). The mathematical interpolation approach does not incorporate a statistical probability theory but uses mathematic formulas to interpolate values (e.g., IDW). The geostatistical approach uses statistical probability (randomness concept) within the interpolation process (e.g., KED). In this study, three approaches were used to estimate PM2.5 concentrations in the City of Montreal for each day of the study period: kriging with external drift (KED), a simple IDW interpolation and a hybridization of those two models (KED–IDW). To demonstrate the gain brought about by the three spatial interpolation models, we compared their results to the simple daily mean of PM2.5 concentrations at the 10 monitoring stations.
KED is a non-stationary geostatistical method also referred to as universal kriging by some authors.39, 40 The term “universal kriging” is reserved for the case where the trend is modeled as a function of coordinates41 and the expression “kriging with external drift”42 is employed for the specific case where the trend is modeled as a linear function of independent external variables. This linear function is used to derive the local mean (trend) of the dependent variable. Besides, this method requires relevant independent variables (in a physical sense).43 The independent variable that is physically related to the dependent variable and measured at a high spatial density improves the estimation to create maps at the resolution of the independent variable.
KED uses a first- (broad spatial trends) and second-order effect (local variation) of spatial dependence,20 in this case the spatial dependence between the independent variables and PM2.5 concentrations. Differing from a regression model where the model errors are assumed to be independent, KED uses variogram models under a dependence assumption of model errors. Assuming that the expected value of the dependent variable Z(u) (PM2.5 concentrations) is a linear function of another regionalized variable Y(u) (independent meteorological and geographical variables), the random function of Z(u) can be expressed as follows:

where c1 and c2 are constants, Y(u) is known everywhere and represents the value of the independent variable at location u, and YR(u) is the residual. Because of the limited number of ground stations available (n=10), we selected only two covariates to develop KED models in the present study. Independent variables Y(u) were selected based on the size of the Pearson correlation and their potential for reflecting the spatial variations of PM2.5 concentrations. More precisely, we first selected the meteorological variable presenting the greatest correlation and coefficient of variation with daily PM2.5 measures. We then selected the geographical variable that showed the greatest correlation with PM2.5.
In the KED model, the spatial dependence is computed using an empirical semi-variogram XXXXX, a function calculated using the variability between data pairs of various distances and defined as:

where N(h) is the number of pairs of sampling locations at distance h from one another, and Z(uα) is the observed value at the sampling site.
The concentration of PM2.5 at a given point of interest u is estimated according to:

where, λα(u) are the weights corresponding to the n samples at location u and obtained by solving a system of linear equations developed by Goovaerts (1997)43 involving knowledge of the variogram. PM2.5 predictions are generated for time slices and based on the daily estimated variograms. Temporal interactions were not incorporated in this study.
The second model, IDW, is a simple spatial interpolation approach commonly used in air pollution epidemiology.13, 44 IDW calculates the values as a distance-weighted average of the observation values without any dependence on external variables. It can be expressed as:

where dλ are the IDW weight distances and Z(uα) the observed values at the n measured sites. We integrated the KED and IDW models by selecting for each day the estimate that provided the best performance, namely by performing cross-validations.
Cross-validation
A leave-one-out cross-validation approach was used for assessing the performance of each model and to find the best predictive model. In this approach, each station observation on a given day is removed from the data one at a time and the remaining data is used to predict the PM2.5 concentration at the location of the excluded station. The observations and predictions at the excluded stations are then compared. To compare interpolation models to simple daily mean PM2.5 concentrations, the same form of cross-validation was also applied to the daily mean. In other words, the performance of this approach was evaluated by calculating the difference between the PM2.5 concentration at a given station on a given day and the mean of the remaining ones.
We computed PM2.5 estimation errors as predicted values minus observed values across interpolation methods. The root mean square error (RMSE) was used to estimate the total magnitude of errors for each day, across monitoring stations and for all station-days. Finally, to further evaluate the performance of the hybrid model prediction, we used cross-validation results to create scatter plots of predicted versus observed values and to evaluate the proportion of the variance explained by the model as well as the consistency and the model bias.
RESULTS
Four factors were derived from the PCA, whereby the three first explained 87% of the total variance. We therefore performed the HCA using the first three principal components to classify each day of the study period into groups with similar meteorological conditions. Six synoptic weather classes with similar patterns were obtained.
Descriptive statistics of PM2.5 concentrations and meteorological variables by synoptic weather classes are shown in Table 1. The results for all synoptic classes show that PM2.5 concentrations decrease when wind speed increases. Days of the synoptic class 1 are spread over the year and correspond to conditions of high relative humidity and high precipitation; days of class 2 and 3 are spread over the winter season; days of class 4 and 6 are spread over the summer and fall seasons; and days of class 5 are found mostly in the spring season. As shown in Table 1, the synoptic class 3 has the typical characteristics of temperature inversion: low winter temperatures, high atmospheric pressure and low wind speed, to which are associated high levels of PM2.5.
The Pearson correlation coefficients for geographic variables and coefficients of variation for the spatio-temporal meteorological variables that were used to select the KED covariables are presented in Tables 2 and 3. The wind speed variable shows high correlations and explains the spatial variability of PM2.5 concentrations for all synoptic classes (Table 3).
The following geographic predictors were selected for the KED model: greenness for synoptic class 1–4 and industrial area for synoptic class 5 and 6; wind speed was the meteorological variable selected for all synoptic classes.
Table 4 describes the cross-validation results for the three models for the days of the year 2010 at the 10 stations (n=3344). Overall, the hybrid model KED–IDW performed better for all synoptic classes compared with the IDW and KED models taken separately, although only marginally compared with IDW. The two performance metrics, R2 and RMSE, show different behaviors when comparing the models. The proportion of explained variance is almost always the lowest in the case of the mean of the stations, making it the worst approach. However, the highest RMSEs were in all cases but one observed for KED. The improvements brought about by a spatial interpolation approach are very significant for some synoptic classes (2, 4, 5), but rather small for other classes (3 and 6).
The distribution of daily PM2.5 errors also shows that the IDW and KED–IDW models overestimate PM2.5 levels, whereas KED underestimates them (errors, respectively of 0.42, 0.24 and −0.22 μg/m3) (Figure 2).

PM2.5 mapping error estimates from cross-validation (where error=predicted−observed PM2.5 concentration (in μg/m3) at each monitoring station] based in KED (mean±SD; −0.22±2.78 μg/m3), IDW (mean±SD; 0.42±2.21 μg/m3) and KED–IDW (mean±SD; 0.24±2.13 μg/m3) for days of the year 2010.
Figure 3 shows the individual prediction RMSEs of the IDW and KED models (Figure 3a), and of the hybrid KED–IDW model (Figure 3b). For the two individual models, the error is quite variable, oscillating mostly between 1 and 4 μg/m3, with a few large spikes. The RMSEs of the KED–IDW model show much less variation, being generally confined between 1 and 3 μg/m3, with only one spike. In the majority of cases, the RMSE of IDW is lower than that of KED (Figure 3a), but KED outperformed IDW for several days, featuring an RMSE, that is, sometimes 1 μg/m3 lower than IDW and being often in the same range of error. Figure 4 presents the scatter plots of predicted values modeled with KED–IDW versus monitoring site values (PM2.5 daily levels observed) for the six synoptic classes. Scatter around the 1:1 line is rather moderate and quite similar between one class and the next. Lower R2 values occurred when the range of observed values was itself smaller. Figure 5 shows that the RMSE of the hybrid model in space (at all stations) was closest to zero in comparison with the KED and IDW models and more uniform in space.

Daily temporal PM2.5 error estimates (RMSE) based on leave-one-station cross-validation for KED, IDW (a) and KED–IDW models (b).

PM2.5 daily levels predicted with the hybrid model KED–IDW vs PM2.5 concentrations measured at NAPS stations for the year 2010 by synoptic weather class.

Spatial distribution of mean PM2.5 error estimates (RMSE) of the year 2010 based on cross-validation for KED (a), IDW (b) and KED–IDW (c).
It also reveals that errors of the KED–IDW model are higher when stations are scarce (e.g., southwest of the Island of Montreal). In Figure 6, we present two examples of 100-m PM2.5 resolution maps for a spring day (22 April 2010) and a summer day (16 July 2010) generated with the KED and IDW models. In these examples, for the selected spring day, IDW produced better accuracy (RMSE=1.32 and R2 =0.60) than KED (RMSE=1.53 and R2 =0.47); and for the selected summer day, KED produced better accuracy (RMSE=1.26 and R2 =0.72) than IDW (RMSE=1.74 and R2 =0.46), likely due to correlations with covariates. However, it is clear that KED produces a higher resolution map of PM2.5 level variations, as evidenced by the more complex patterns visible on the KED maps.

Predicted PM2.5 concentrations for 22 April 2010: (a) KED (covariates: wind speed and greenness) and (b) IDW. Predicted PM2.5 concentrations for 16 July 2010: (c) KED (covariates: wind speed and industrial area) and (d) IDW.
DISCUSSION
In this paper, we show that it is possible to reduce the interpolation errors in estimating PM2.5 levels with the combination of the commonly used IDW approach and the KED model. Our results show that the estimates of PM2.5 across monitoring sites with the hybrid model were on average 11% higher in R2 and on average 0.60 μg/m3 lower in RMSE compared with KED. Compared with the IDW model, the hybrid model was only slightly higher, on average 3% in R2 and slightly lower, on average 0.22 μg/m3, in RMSE. IDW also performed better than KED, but the hybrid model was best. Nonetheless, the KED model produced better accuracy for specific days when PM2.5 observations showed strong associations and spatial dependency upon certain environmental and meteorological conditions.
We also found that the decomposition of the temporal distribution of meteorological factors in synoptic groups using principal components and hierarchical cluster analyses demonstrated an effective classification showing an important relationship between fine PM and meteorological conditions. This approach allowed us to classify the temporal variation in PM2.5 due to meteorological effects while selecting covariates according their effect level. As a result, for all models, the accuracy (R2 and RMSE) varies with the meteorological conditions captured by each synoptic class.
Univariate approaches such as IDW45 or ordinary kriging19, 20 and multivariate approaches such as KED20 and LUR19, 20, 45 have been used to estimate ambient particulate levels. The errors of these approaches vary widely from one study to another. For example, using KED to estimate PM2.5 daily levels, Pearce et al.20 reported RMSE values of 0.49 μg/m3, whereas Beelen et al.46 reported RMSE of 5.19 μg/m3 for particulate levels with a median diameter of 10 μg/m3. This probably depends on the density of stations (number of stations per km2) and on the scale of the study (regional, rural or urban). It is therefore difficult to compare our findings to other studies.
Like others have also observed (Yu et al.)47 we found that the error estimates from the models were higher in areas where the monitoring stations were sparse, such as in the South-West of the study area (Figure 5).
To our knowledge, KED and IDW have not been compared before. Although the results of this research show an overall better performance for IDW compared with KED, further investigation is needed to confirm this performance. This stems from the very concept of KED, in which an association between the dependent variable and external variables is expected. If, however, the correlation between these variables and the PM2.5 levels is low, noise is introduced in the interpolation, thus creating inaccurate predictions. It is therefore important to seek the best-correlated external variables, and to evaluate their usefulness for each synoptic weather class.
The approach that we used to spatialize the meteorological observations from the stations over the study area is too simple to capture the full complexity of the phenomena. We recognize that parameters such as wind speed do not necessarily vary linearly between stations. The 3D configuration of built areas, for example, has an important influence on the spatial behavior of this parameter. Again, we have chosen methods that allow a rather straightforward implementation and focused on studying the benefits of KED.
As mentioned previously, our model was based on only 10 monitoring sites and a limited number of covariates (the selection of predictors is limited to two). The small number of monitoring stations may have produced instability in the variogram estimation for the KED model. Another constraint in applying the proposed hybrid model approach is the substantial computational time required to create daily maps at a 100-m resolution.
Regardless of the limitations mentioned above, the hybrid KED–IDW model may improve the estimation of exposure of populations to estimate acute effects of PM2.5 because it generates higher resolution maps with smaller errors in space and time than other approaches often used in the field (e.g., closest monitor or only IDW). The predictive power of the hybrid model thus could reduce the exposure misclassification in epidemiological studies.
For implementation in future health studies, the hybrid interpolation model might be improved by expanding the number of monitoring sites and the inclusion of additional covariates. Furthermore, the choice of variables for a daily prediction could be improved by an automatic procedure depending of the degree of fit with daily PM2.5 measures.
Ambient levels of PM2.5 as interpolated in the present study provide imperfect estimates of true exposure, as individuals are exposed to different levels of pollution depending on their locations across time. As suggested by others48, 49, results from intra-urban interpolation models could be combined in future work, with information on time-activity patterns, to estimate individual exposure in future health studies.
CONCLUSIONS
The main objective of this study was to map the spatial and temporal variation of fine PM to improve PM2.5 exposure predictions within an urban environment. The hybrid KED–IDW model was more effective for exposure prediction and outperformed the KED and IDW models. This study demonstrated the improvements brought about by a hybrid KED–IDW model for mapping PM2.5 concentrations over time and space in the Montreal area.
Our study also shows that it is possible to develop high-resolution maps with a limited number of PM2.5 monitors under specific environmental and meteorological conditions. The integration of covariates in KED intends to allow capturing the intra-urban variation of PM2.5 levels; however, the model could perform better if there were more monitoring stations on the Island of Montreal.
References
Goverment of Canada Canadian Smog Science Assessment 2012, ISBN 978-1-100-19064-8: 64.
U.S. EPA. 2009 Final Report: Integrated Science Assessment for Particulate Matter. U.S. Environmental Protection Agency, Washington, DC, EPA/600/R-08/139F, 2009.
Zanobetti A, Schwartz J . The effect of fine and coarse particulate air pollution on mortality: a national analysis. Environ Health Perspect 2009; 117: 898–903.
Ito K, Mathes R, Ross Z, Nádas A, Thurston G, Matte T . Fine particulate matter constituents associated with cardiovascular hospitalizations and mortality in New York City. Environ Health Perspect 2011; 19: 467–473.
Bell M, Ebisu K, Peng R, Walker J, Samet J, Zeger S et al. Seasonal and regional short-term effects of fine particles on hospital admissions in 202 US counties, 1999–2005. Am J Epidemiol 2008; 168: 1301–1310.
Goldman G, Mulholland J, Russell A, Gass K, Strickland M, Tolbert P . Characterization of ambient air pollution measurement error in a time-series health study using a geostatistical simulation approach. Atmos Environ 2012; 57: 101–108.
Brauer M, Hoek G, van Vliet P, Meliefste K, Fischer P, Gehring U et al. Estimating long-term average particulate air pollution concentrations: application of traffic indicators and geographic information systems. Epidemiology 2003; 14: 228–239.
Pinto J, Lefohn A, Shadwick D . Spatial variability of PM2.5 in urban areas in the United States. J Air Waste Manag Assoc 2012; 54: 440–449.
Dawson JP, Adams PJ, Pandis SN . Sensitivity of PM2.5 to climate in the Eastern US: a modeling case study. Atmos Chem Phys 2007; 7: 4295–4309.
Munoz-Alpizar R, Blanchet J . Application of the NARCM model to high-resolution aerosol simulations: case study of Mexico City basin during the Investigacion sobre Materia Particulada y Atmosférico-Aerosol and Visibility Research measurements campaign. J Geophys Res 2003; 108: 14.
Tai APK, Mickley LJ, Jacob DJ . Correlations between fine particulate matter (PM2.5) and meteorological variables in the United States: implications for the sensitivity of PM2.5 to climate change. Atmos Environ 2010; 44: 3976–3984.
Malek E, Davis T, Martin R, Silva P . Meteorological and environmental aspects of one of the worst national air pollution episodes (January, 2004) in Logan, Cache Valley, Utah, USA. Atmos Res 2006; 79: 108–112.
Lipsett MJ, Ostro BD, Reynolds P, Goldberg D, Hertz A, Jerrett M et al. Long-term exposure to air pollution and cardiorespiratory disease in the California teachers study Cohort. Am J Respir Crit Care Med 2011; 184: 828–835.
Henderson S, Beckerman B, Jerrett M, Brauer M . Application of land use regression to estimate long-term concentrations of traffic-related nitrogen oxides and fine particulate matter. Environ Sci Technol 2007; 41: 2422–2428.
Briggs DJ, Collins S, Elliott P, Fischer P, Kingham S, Lebret E et al. Mapping urban air pollution using GIS: a regression-based approach. Int J Geogr Inf Sci Total Environ 1997; 11: 699–718.
Adam-Poupart A, Brand A, Fournier M, Jerrett M, Smargiassi A . Spatiotemporal modeling of ozone levels in Quebec (Canada): a comparison of kriging, land-use regression (LUR), and combined bayesian maximum entropy–LUR approaches. Environ Health Perspect 2014; 122: 970–976.
Beckerman B, Jerrett M, Serre M, Martin R, Lee S, Van Donkelaar A et al. A hybrid approach to estimating national scale spatiotemporal variability of PM2.5 in the contiguous United States. Environ Sci Technol 2013; 47: 7233–7241.
Jerrett M, Burnett R, Goldberg M, Sears M, Krewski D, Catalan R et al. Spatial analysis for environmental health research: concepts, methods, and examples. J Toxicol Environ Health 2003; 66: 1783–1810.
Chen C, Wu C, Yu H, Chan C, Cheng T . Spatiotemporal modeling with temporal-invariant variogram subgroups to estimate fine particulate matter PM2.5 concentrations. Atmos Environ 2012; 54: 1–8.
Pearce JL, Rathbuna SL, Aguilar-Villalobos M, Naeher LP . Characterizing the spatiotemporal variability of PM2.5 in Cusco, Peru using kriging with external drift. Atmos Environ 2009; 43: 2060–2069.
RSQA. Environmental Assessment Report–Air Quality of Montreal. Ville de Montréal–Direction de l'environnement et du Développement Durable, 2010.
Environment Canada. National Air Pollution Surveillance Network (NAPS) Data Products, 2013. Available at http://maps-cartes.ec.gc.ca/rnspa-naps/data.aspx. Accessed 10 March 2013.
Canadian Council of Ministers of the Environment Ambient air monitoring protocol for PM2.5 and ozone | Canada-wide standards for particulate matter and ozone. 2011; 978-1-896997-99-5 PDF: 61.
Environment Canada. Canada National Climate Data and Information Archive, 2013. Available at http://climate.weather.gc.ca/index_e.html. Accessed 5 March 2013.
Environment Canada. Major smog episodes, 2014. Available at http://www.ec.gc.ca/info-smog/default.asp?lang=En&n=669E620B-1. Accessed 20 January 2014.
Hufty A . Analyse en composants principales des situations synoptiques au Québec. Géographie physique et Quaternaire 1982; XXXVI: 307–314.
Rose N, Cowie C, Gillett R, Marks G . Weighted road density: a simple way of assigning traffic-related air pollution exposure. Atmos Environ 2009; 43: 5009–5014.
Hansell AL, Rose N, Cowie CT, Belousova EG, Bakolis I, Ng K et al. Weighted road density and allergic disease in children at high risk of developing asthma. PLoS One 2014; 9: 9.
Su J, Jerrett M, Beckerman B . A distance-decay variable selection strategy for land use regression modeling of ambient air pollution exposures. Sci Total Environ 2009; 407: 3890–3898.
Zou B, Wilson JG, Zhan FB, Zeng Y . An emission-weighted proximity model for air pollution exposure assessment. Sci Total Environ 2009; 407: 4939–4945.
Ross Z, Jerrett M, Ito K, Tempalski B, Thurston G . A land use regression for predicting fine particulate matter concentrations in the New York City region. Atmos Environ 2007; 41: 2255–2269.
Brauer M, Lencar C, Tamburic L, Koehoorn M, Demers P, Karr C . A cohort study of traffic-related air pollution impacts on birth outcomes. Environ Health Perspect 2008; 116: 680–686.
Statistics Canada. Dissemination Area (DA), 2009. Available at http://www12.statcan.ca/census-recensement/2006/ref/dict/geo021-eng.cfm. Accessed 10 April 2012.
Hoek G, Beelen R, De Hoogh K, Vienneau D, Gulliver J, Fischer P et al. A review of land-use regression models to assess spatial variation of outdoor air pollution. Atmos Environ 2008; 42: 7561–7578.
Nowak D, Hirabayashi S, Bodine A, Hoehn R . Modeled PM2.5 removal by trees in ten U.S. cities and associated health effects. Environ Poll 2013; 178: 395–402.
The tasseled Cap - A graphic description of the spectral-temporal development of agricultural crops as seen by LANDSAT. Symposium on Machine Processing of Remote Sensed Data; West Lafayette, Indiana. Institute of Electrical and Electronics Engineers, Inc. (IEEE), 1976.
Su J, Jerrett M, Beckerman B, Verma D, Arain MA, Kanaroglou P et al. A land use regression model for predicting ambient volatile organic compound concentrations in Toronto, Canada. Atmos Environ 2010; 44: 3529–3537.
Markevych I, Fuertes E, Tiesler C, Birk M, Bauer C, Koletzko S et al. Surrounding greenness and birth weight: results from the GINIplus and LISAplus birth cohorts in Munich. Health Place 2014; 26: 39–46.
Wackernagel H . Multivariate Geostatistics: an Introduction with Applications. Springer: Berlin, Heidelberg. 2003.
Stein A, Van der Meer F, Gorte B . Spatial statistic for remote sensing. Kluwer Academic Publishers: Dordrecht, The Netherlands, 1999, pp 284.
Matheron G. . Le krigeage universel. In: ENSMP (ed). Les Cahiers du Centre de Morphologie Mathématique de Fontainebleau. École Nationale Supérieure des Mines de Paris: France, 1969, pp 1-83.
Chiles JP . Application du krigeage avec dérive externe à l'implantation d'un réseau de surveillance piézométrique. Sciences de la Terre 1991; 30: 131–147.
Goovaerts P . Geostatistics for Natural Resources Evaluation. Oxford University Press: New York, USA. 1997.
Al-Hamdan MZ, Crosson WL, Limaye AS, Rickman DL, Quattrochi DA, Estes MG et al. Methods for characterizing fine particulate matter using ground observations and remotely sensed data: potential use for environmental public health surveillance. J Air Waste Manag Assoc 2009; 59: 865–881.
Hystad P, Demers P, Johnson K, Brook J, Van Donkelaar A, Lamsal L et al. Spatiotemporal air pollution exposure assessment for a Canadian population-based lung cancer case-control study. Environ Health 2012; 11: 1–13.
Beelen R, Hoek G, Pebesma E, Vienneau D, De Hooghd K, Briggs DJ . Mapping of background air pollution at a fine spatial scale across the European Union. Sci Total Environ 2009; 407: 1852–1867.
Yu H, Chen J, Christakos G, Jerrett M . BME estimation of residential exposure to ambient PM10 and ozone at multiple time scales. Environ Health Perspect 2009; 110: 537–544.
Kwan M-P . From place-based to people-based exposure measures. Soc Sci Med 2009; 69: 1311–1313.
Kwan M-P . The uncertain geographic context problem. Ann Assoc Am Geogr 2012; 102: 958–968.
Acknowledgements
The authors would like to acknowledge Allan Brand for providing a compilation of meteorological and ground-level PM2.5 data for this study. We also thank Éric de Montigny for comments on an earlier version of this paper. This project was financially supported by the Quebec Institute of Public Health.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no conflict of interest.
Rights and permissions
About this article

Cite this article
Ramos, Y., St-Onge, B., Blanchet, JP. et al. Spatio-temporal models to estimate daily concentrations of fine particulate matter in Montreal: Kriging with external drift and inverse distance-weighted approaches. J Expo Sci Environ Epidemiol 26, 405–414 (2016). https://doi.org/10.1038/jes.2015.79
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/jes.2015.79
- Springer Nature America, Inc.
Keywords
This article is cited by
-
A Review of Air Quality Modeling
MAPAN (2020)