
Abstract
Background/Objectives:
PGC-1α is an important regulatory factor for energy and glucose metabolism. Therefore, we investigated whether the PGC-1α genotype (rs10517030 and rs10212638) affects the incidence of type 2 diabetes mellitus (T2DM) and sought to explain the interactions between their variants and nutrient intake on the development of T2DM.
Subjects/Methods:
Subjects aged 40–65 years of both genders were from the Ansung/Ansan cohorts (8842 adults) in Korea. Associations of PGC-1α variants rs10517030 and rs10212638 with T2DM were analyzed in a dominant genetic model, and were tested for interactions of genotypes and nutrients with T2DM risk. It was adjusted for covariates related to glucose metabolism.
Results:
Three variants, rs10517030, rs10517032 and rs10212638, were positively associated with T2DM prevalence. Single-nucleotide polymorphisms, rs10517030 and rs10517032, had strong association (r2=0.963). In the glucose tolerance tests, odds ratios (ORs) for serum glucose levels at 120 min were higher for subjects who were in the minor-allele group (minor allele homozygotes and heterozygotes) than for the major-allele group (major allele homozygotes) for rs10517030 variants. Serum insulin levels at 60 min had a lower ORs in the minor-allele group of rs10517030 variants. The interaction between energy intake and PGC-1α rs10517030 variants also affected T2DM risk. PGC-1α minor alleles were linked to T2DM prevalence and homeostasis model assessment estimate of insulin resistance (HOMA-IR) only in the low-energy groups, and HOMA-B was significantly negatively associated with the minor-allele group of PGC-1α rs10517030 variants, only in the low-energy-intake groups.
Conclusions:
These data suggest that Koreans with the minor alleles of PGC-1α rs10517030, rs10517032 and rs10212638 are at greater risk of T2DM, and that a low-energy diet is more protective against the development of T2DM in subjects with the major alleles of rs10517030 and rs10517032.
Similar content being viewed by others


Introduction
The etiology of type 2 diabetes begins with progressive insulin resistance (IR) that is overcome by greater insulin secretion to maintain glucose homeostasis. However, eventually the capacity of the β-cells to produce adequate compensatory insulin fails, and type 2 diabetes results. Because Asians have inadequate β-cell response to increased IR,1 they progress to type 2 diabetes very rapidly and usually without the characteristic obesity of Caucasians.2 Indeed, Asians are particularly susceptible to type 2 diabetes, and most Asians with type 2 diabetes are non-obese.
The peroxisome proliferator-activated receptor-r coactivators-1α (PPARGC1A or PGC-1α) acts as a transcriptional coactivator of peroxisome proliferator-activated receptors-γ and -α.3 PGC-1α controls the transcription of genes coding key enzymes involved whereby β-oxidation and regulation of cellular energy metabolism.4 In addition to energy metabolism, PGC-1α is involved in various aspects of glucose metabolism, such as glucose production and utilization, hepatic gluconeogenesis and glucose uptake in skeletal muscles.4, 5 The expression of hepatic PGC-1α is increased during starvation, and PGC-1α stimulates gluconeogenesis in the liver by upregulating expressions of phosphoenol pyruvate carboxykinase and glucose-6-phosphatase.5 However, lower PGC-1α mRNA levels in liver, adipose tissue and skeletal muscles is associated with IR and glucose intolerance.3, 4 Interestingly, it was recently reported that PGC-1α is intimately involved with β-cell function.6 PGC-1α expression is suppressed in the islets of type 2 diabetic people who have a decreased insulin secretory capacity.6 Human pancreatic islets with knockdowned expression of PGC-1α also exhibit impaired glucose-stimulated insulin secretion.7 PGC-1α expression is lower in islets or cultured β-cells exposed to high glucose concentrations. However, excessively expressed PGC-1α in primary rat islets also impairs insulin secretion.8 Decreased PGC-1α expression in adult β-cells leads to decreased mitochondrial oxidative capacity and impaired glucose-stimulated insulin secretion.9 The mechanism underlying the effect of PGC-1α on β-cell function is unclear, but it may be related to mitochondrial capacity. Therefore, these observations provides compelling evidence that PGC-1α is involved with both insulin release by β cells and IR in insulin sensitive tissues and organs.
PGC-1α is mapped on chromosome 4p15.1, and in Pima Indians it is associated with elevated fasting insulin and with high body mass index (BMI) in the American Hispanic population.10, 11, 12, 13 The PGC-1α Gly482Ser polymorphism (rs8192678) has been published to be associated with type 2 diabetes mellitus and IR in various ethnic groups.11, 12, 14, 15 By contrast, the PGC-1α Gly482Ser polymorphism is not linked to type 2 diabetes in French Caucasians.16, 17 In the Korean population PGC-1α genotypes have not been shown to be associated with type 2 diabetes as a crucial gene in genome-wide association studies.18 PGC-1α Gly482Ser (g.75919G>A) was not significantly associated with the risk of type 2 diabetes in 1065 Korean adults, but PGC-1α c.−1789G>A and c.−1437C>T exhibit an association with diagnostic age of type 2 diabetes (P=0.042 and 0.032, respectively).19 The interaction effect of PGC-1α genotypes and nutrient intake on the occurrence of type 2 diabetes remains to be studied. In our preliminary study, the PGC-1α genotypes (Gly482Ser) were not included but 114 variants of PGC-1α were present in the subjects of the Korea Association Resource (KARE) Consortium in the Korean Genome Epidemiology Study. We identified three variants (rs10517030, rs10517032 and rs10212638) among 114 PGC-1α variants had a significant association with the prevalence of type 2 diabetes in the KARE study of Koreans.
We hypothesized that PGC-1α variants (rs10517030, rs10517032 and rs10212638) would be important risk factors for type 2 diabetes and that there would be an interaction effect of the relationship between their variants and nutrient intake on the development of type 2 diabetes. The hypothesis was tested in 8842 Korean adults in the Ansan/Ansung cohort in the KARE consortium.
Subjects and methods
Subjects
In 2001, samples and information were obtained from the KARE group’s Ansung and Ansan cohorts of the Korean Genome Epidemiology Study.20 The 4183 men and 4659 women aged 40–69 years resided in the, respectively, rural and urban areas of Ansung City and Ansan City. The Korean Genome Epidemiology Study protocols were approved by the Institutional Review Board of the Korean National Institute of Health. Informed consent was obtained in writing from each subject.
Basic characteristics of subjects
All participants had lived in the area for at 6 months and were free of any serious disease. Interviews were conducted to determine age, education, income, smoking history and alcohol consumption, and physical activity of subjects.
Anthropometric data were collected by measuring height, weight and circumferences of waist and hip in subjects wearing light clothes with bare feet. BMI was calculated by dividing body weight by height squared (kg/m2). Subjects were considered obese with BMI ⩾25. Body fat (%) was measured by Inbody analyzer 3.0 (Biospace, Seoul, Korea) using bioelectrical impedance analysis.21 Education of the subjects was categorized into less than high school, high school and college or more. Household income (USD/month) was categorized as very low (<1000), low (1000–2000), intermediate (2000–4000) and high (>4000). Subjects were separated according to smoking habits as current, past or never-smokers. Smoking status were defined as current smoker: smoked more than 100 cigarettes in past 6 months; past smoker: previous smoker who had not smoked during past 6 months. Alcoholic beverage consumption was assessed from subject responses to questions about the frequency of drinking and amount of drinking at one time during the month before the interview. Subjects were assigned to one of four groups according to g/day of alcohol consumed. Definitions of drinking status were as follows: non (0 g); light (1–15 g); drinker (16–30 g); and heavy (>30 g) of alcohol consumed per month.
Biochemical parameters and definition of type 2 diabetes
Morning fasting blood samples following were used to determine serum levels of glucose, hemoglobin A1c and triglycerides using an auto-analyzer (ZEUS 9.9; Takeda, Tokyo, Japan). A radioimmunoassay method was used for serum insulin determinations with a gamma counter (Perkin-Elmer, San Jose, CA, USA) and commercial kit (DiaSorin, Stillwater, MN, USA). Subjects with fasted glucose ⩾126 mg/dl, blood glucose concentration ⩾200 mg/dl 120 min following an oral glucose challenge, or who were currently using antidiabetic medications were considered type 2 diabetic.22 Subjects were identified as glucose intolerant when 100 mg/dl<fasting serum glucose<126 mg/dl or 140 mg/dl<serum glucose level<200 mg/dl 120 min following oral glucose challenge. IR was assessed using homeostasis model assessment estimates (HOMA) and beta (B)-cell capacity was assessed using HOMA-B. HOMA assessments were calculated as follows: (HOMA-IR=fasting insulin levels (μIU/ml) × fasting glucose levels (mM)/22.5) and (HOMA-B=20 × fasting insulin levels)/(fasting glucose levels–3.5).23
Assessment of nutrient intake
Estimates of usual food consumption were determined using a ‘semi-quantitative food frequency questionnaire’ (SQFFQ). The validity and reproducibility of the SQFFQ for estimating the mean annual consumption of specific foods was determined to be acceptable.23 The SQFFQ included 103 foods, and food frequencies were divided into 9 categories: never or seldom, once a month, 2–3 times per month, 1–2 times per week, 3–4 times per week, 5–6 times per week, once a day, twice a day and three or more times per day. The amount of food consumed in one sitting was scored as more than, equal to or less than the standard portion size, which was estimated by comparing to photographs of the foods, and subjects reported the frequencies based on visual assessments of portion sizes. Daily intakes were calculated using the midpoint of the frequency reported for each food category. The food consumption estimate was calculated by multiplying the weekly number of midpoints by the portion size of each food category. Macronutrient consumption was calculated from the SQFFQ data using Can-Pro 2.0 (Korean Nutrition Society, Seoul, Korea).
Genotyping and quality control
Genotyping and quality control processes were previously described in detail.20, 23 Briefly, peripheral blood DNA isolated from blood samples of subjects were subjected to genotyping by the Affymetrix Genome-Wide Human SNP array 5.0 (Affymetrix, Santa Clara, CA, USA). Genotyping accuracy was checked using Bayesian Robust Linear Modeling with the Mahalanobis Distance genotyping algorithm.20 Exclusion criteria for genotyping were as follows: low accuracy of genotyping (<98%), excessive call rates for missing genotype (⩾4%), excessive heterozygosity (>30%) and indication of bias for gender.
The PGC-1α gene contained 114 single-nucleotide polymorphisms (SNPs) in the zones encompassing the gene boundary (5 kb upstream and 5 kb downstream from the first and last exons) based on National Center for Biotechnology Information human genome build 36.1 (hg18).24, 25 Three SNPs (rs10517030, rs10517032 and rs10212638) were significantly associated with type 2 diabetes in the KARE data. All three SNPs were located in the PGC-1α intron that was found in the NCBI SNP website (https://www.ncbi.nlm.nih.gov/snp). For both variants, subjects who carried either one or two copies of the minor alleles (heterozygotes or homozygotes for minor alleles) were placed in the minor-allele group, and were compared with major-allele-homozygous subjects (major-allele group).
Statistical analysis
GPLINK version 2.0 (http://pngu.mgh.harvard.edu/~purcell/plink) and SAS (version 9.3; SAS Institute, Cary, NC, USA) were applied for statistical analysis. We used the G power calculator determine sample size for the study, and a sample size of 8842 was sufficient to attain significance at α=0.05 and β=0.96 at an odds ratio (OR) of 1.1 in the logistic analysis. Thus, the sample size is sufficient to obtain significance. Hardy–Weinberg equilibrium was evaluated using GPLINK. The descriptive statistics for categorical variables (age, gender and so on) were derived from frequency distributions. The statistical analysis of frequency distributions was analyzed with χ2-tests. The data were checked and they were found to be normally distributed by Proc univariate. We reported descriptive statistics of continuous variables as arithmetic means±s.d. ORs and 95% confidence intervals (CIs) for risk of type 2 diabetes were calculated for PGC-1α minor alleles in the dominant genetic model after adjusting for the covariates of age, gender, residence area, BMI, total energy intake, physical activity and smoking status. Multivariate adjustments for continuous variables comparisons used the generalized linear models after adjusting for potential confounders. Interactions between PGC-1α variants and dietary nutrients were evaluated using separate multivariate regression models to ensure inclusion of the corresponding main effects and interaction terms as well as potential confounders. Next, multivariate logistic regression was utilized for calculating ORs and 95% CIs for type 2 diabetes risk associated with PGC-1α genotypes while controlling for covariates.
Results
PGC-1α genotype
In all, 3 of 114 SNPs in the PGC-1α gene—rs10517030, rs10517032 and rs10212638—were associated with the prevalence of type 2 diabetes in a dominant genetic model that did not adjust for confounding factors (Table 1). The three SNPs were located in the introns of PGC-1α on chromosome 4 (Table 1). The minor allele frequency values of rs10517030, rs10517032 and rs10212638 were 0.172, 0.166, and 0.074, respectively. The Hardy–Weinberg equilibrium of these SNPs did not differ significantly. As there was a strong correlation between rs10517030 and rs10517032 (r2=0.963, P<0.0001), and rs10517030 was most closely associate with type 2 diabetes risk, rs10517032 was eliminated from the association study. Thus, the minor alleles, PGC-1α rs10517030 and rs10212638 variants, were assessed further for their association with the prevalence of type 2 diabetes.
Baseline characteristics of subjects according to PGC-1α variants
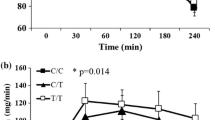
According to a dominant genetic model, subjects in the minor-allele group were younger than those in the major-allele group of rs10212638 (Table 2). Waist circumferences were higher in the minor-allele group than in the major-allele group of rs10517030. The gender, BMI and body fat of the rs10517030 and rs10212638 groups did not differ significantly (Table 2). Neither the serum glucose levels at 0, 60 and 120 min nor the hemoglobin A1c levels were higher in the minor-allele group than in the major-allele group of both rs10517030 and rs10212638; however, the serum glucose and hemoglobin A1c levels did differ significantly at 0 min. The serum insulin levels at 0, 60 and 120 min and the HOMA-B values of the subjects with minor allele were lower in those with major alleles for each of the two variants at all three time points, but the serum insulin levels and HOMA-B values differed significantly only in rs10517030 at 60 min (Table 2).
Association of PGC-1α variants with glucose metabolism in a dominant genetic model
The rs10517030 and rs10212638 PGC-1α variants were positively associated with the prevalence of type 2 diabetes (Table 3). Subjects with minor alleles of PGC-1α variants (rs10517030) exhibited higher ORs for type 2 diabetes compared with those with only major alleles (reference group). In addition, subjects with minor alleles of PGC-1α variants (rs10517030 and rs10212638) had higher ORs for hemoglobin A1c levels. However, the ORs for serum glucose after fasting and at 60 min post glucose challenge did not significantly differ in the minor-allele group compared with the major-allele group. The ORs for elevated serum glucose concentrations at 120 min were elevated in subjects with minor alleles compared to those with the major alleles for rs10517030. The fasted insulin levels and those during the oral glucose tolerance test at 120 min, of subjects with all PGC-1α genotypes did not differ. However, the serum insulin levels at 60 min showed lower ORs in subjects with minor alleles in the rs10517030 gene. The ORs for HOMA-IR did not significantly differ between PGC-1α genotypes (Table 3). The ORs for HOMA-B, an indicator of insulin secretion capacity, were significantly lower in carriers of the minor allele of the rs10517030 gene. Thus, the minor allele of the PGC-1α rs10517030 and rs10212638 variants exhibited a positive association with the prevalence of type 2 diabetes. This association of PGC-1α rs10517030 and type 2 diabetes risk is likely related impaired insulin secretion capacity, but also to suppressed insulin sensitivity.
PGC-1α variants and daily nutrient intake
The means and standard deviations of the intakes of several daily nutrients according to PGC-1α variant are presented in Table 2. The daily intake of energy and carbohydrates of those with different PGC-1α rs10517030 variants did not differ significantly, whereas the intake levels for fat and protein were significantly higher in those with minor alleles of PGC-1α rs10212638 (Table 2).
Interaction effect of PGC-1α rs10517030 and rs10212638 variants and macronutrient and energy intake on the prevalence of type 2 diabetes mellitus
There was an interaction effect of the relationship between energy intake and PGC-1α rs10517030 variants on the prevalence of type 2 diabetes (interaction P-value=0.0089; Table 4). Thus, in comparison with its major allele, PGC-1α rs10517030 minor alleles exhibited an association with type 2 diabetes risk, but only in the low-energy-intake group. However, other macronutrient intakes had no interaction with PGC-1α rs10517030 genotypes. In addition, PGC-1α rs10212638 variants had no association with the intake of any nutrient (Table 4).
Interaction effect of PGC-1α rs10517030 and rs10212638 genotypes and energy intake on glucose metabolism
The interaction of energy intake and PGC-1α genetic variants for outcomes related to type 2 diabetes were analyzed, and associations between PGC-1α genotypes and these levels were calculated according to level of energy intake (Table 5). Overnight-fasting serum glucose levels showed a significant interaction effect with energy intake on PGC-1α rs10517030 only in the low-energy-intake group, and the minor alleles of PGC-1α rs10517030 were positively associated only in this group (Table 5). However, the relationship between PGC-1α genotypes and energy intake did not show an interaction effect on fasting serum insulin levels.
PGC-1α variants exhibited no interaction effect with energy intake levels on HOMA-IR and HOMA-B results. However, minor alleles of PGC-1α rs10517030 and rs10212638 were positively associated with HOMA-IR only in the low-energy-intake group (Table 5). Moreover, HOMA-B was significantly negatively associated with the minor alleles of PGC-1α rs10517030 only in the low-energy-intake group. Thus, subjects with PGC-1α minor alleles of rs10517030 had a greater capacity not only to modulate IR but also to increase insulin secretion to maintain normoglycemia during periods of low energy intake (Table 5). However, having the major allele of PGC-1α genotypes cannot protect against the risks associated with high energy intake.
Discussion
PGC-1α is a coactivator of regulatory enzymes linked to energy and glucose metabolisms.3, 26 PGC-1α polymorphisms affect insulin sensitivity, hepatic glucose production and glucose-stimulated insulin secretion.3, 7 PGC-1α variants may be associated with altered glucose metabolism and the prevalence of type 2 diabetes. Previous studies in people of various ethnicities, such as Native Americans, Danish and Japanese populations, have demonstrated that the Gly482Ser (rs2970847) and Thr394Thr (rs8192673) variants of PGC-1α are modestly, but significantly, associated with the risk of type 2 diabetes.12, 27, 28, 29 According to the KARE data,20 114 SNPs were identified as PGC-1α variants, but rs2970847 and rs8192673 were not included. The association between these rs10212638 and rs10517030 alleles of PGC-1α and the prevalence of type 2 diabetes has not been previously reported. For the first time, the present study demonstrated that the minor alleles of rs10212638, rs10517030 and rs10517032 exhibited a positive association with type 2 diabetes in a dominant genetic model after adjusting for covariates. One study reported that the major allele frequency of PGC-1α rs10212638 was slightly higher in athletes than in controls in a Chinese cohort (P=0.053).30 However, rs10212638, rs10517030 and rs10517032 have not been a focus of research in Koreans. According to a hospital-based study in Korea (762 type 2 diabetic patients and 303 normoglycemic patients), SNPs of c.−1789G>A (rs2970867) and c.−1437C>T (rs2970870) in the PGC-1α promotor region were associated with resistance to early-onset type 2 diabetes (P=0.002 and 0.001, respectively).19 However, in a city–rural cohort of the Korean population, PGC-1α rs10517030 (OR=1.303, CI: 1.090–1.558, P<0.01), but not rs10212638 (OR=0.876, CI: 0.550–1.396), was significantly associated with the risk of type 2 diabetes in a dominant genetic model after adjusting for covariates in our preliminary study. Thus, in comparison with its major allele, PGC-1α rs10517030 minor alleles had a relation to an increased incidence of type 2 diabetes.
PGC-1α is a coactivator of peroxisome proliferator-activated receptor-γ and a multifunctional transcriptional regulator of mitochondrial biogenesis and energy and glucose metabolism.31 It is closely related to insulin sensitivity, and PGC-1α polymorphisms are associated with various diseases linked to glucose intolerance, such as obesity, type 2 diabetes and hypertension.29, 32 The PGC-1α variants exhibited positive or no association with the risk of type 2 diabetes in previous studies. The PGC-1α Gly482Ser polymorphism (rs8192687) has been reported to be modestly associated with type 2 diabetes in meta-analyses (95% CI: 1.00–1.15, P=0.044), mostly with Caucasians29 and Europeans.33 The Gly482Ser polymorphism is associated with IR in obese Caucasians12, 32 and with insulin secretion dysfunction in Pima Indians.13 In Koreans PGC-1α c.−1789G>A and c.−1437C>T are associated with the age when type 2 diabetes is first diagnosed19 but PGC-1α Gly482Ser (g.75919G>A) did not exhibit a significant association. In the present study, PGC-1α rs10517030 minor alleles were not significantly associated with IR. However, interestingly, PGC-1α rs10517030 minor alleles were negatively associated with insulin secretion capacity and serum insulin levels 60 min after oral glucose challenge, which is similar to the findings in Pima Indians. Interestingly, it was recently shown that PGC-1α is involved in β-cell function in animals and humans.7, 8, 34 The islets of type 2 diabetic patients exhibit significantly decreased expression of PGC-1α,7 which attenuates glucose-stimulated insulin secretion.8, 30 PGC-1α gene in β-cells part of the regulation of glucose-mediated insulin secretion by modulating mitochondrial oxidative capacity.7 Therefore, PGC-1α is associated not only with IR in the liver, skeletal muscles and adipose tissues but also with the insulin secretion capacity of β-cells.
Type 2 diabetes occurs when IR exceeds the capacity of insulin secretion to maintain normoglycemia.35 In the present study, the PGC-1α genotype was associated with insulin secretory capacity but was not closely related to IR. This finding may be related to low insulin capacity, which is a primary cause of type 2 diabetes in Koreans.36 The rapid increase in the prevalence of type 2 diabetes among Asians is likely due to the increasing prevalence of IR due to the westernization of lifestyles and because Asians have a lower insulin secretion capacity than Caucasians.36 In this study, there was an interaction effect between energy consumption and PGC-1α rs10517030 variants on the prevalence of type 2 diabetes. Interestingly, the PGC-1α minor alleles had a positive association with the prevalence of type 2 diabetes and HOMA-IR, and a negative association with HOMA-B only in the low-energy-intake group. To our knowledge, no study has evaluated the interaction effect between nutrient intake and PGC-1α rs10517030 variants on the prevalence of type 2 diabetes.
Many gene variants affect the risk of metabolic disease, including those associated with mitochondrial function, which were shown to have weak individual links to obesity, but stronger links in subjects with multiple variants.37 Knoll et al.37 reported that PGC-1α rs10517032 is a nuclear regulator of mitochondrial genes that enhance glycemic regulation, which is consistent with the present study as rs10517032 had a similarly strong correlation with rs10517030. It has been reported that low-calorie diets reduce body weight and IR, but scant research has focused on the interaction between a low-calorie diet and genotype. Goyenechea et al.38 reported an improved insulin response in obese PGC-1α Ser/Ser homozygote subjects who consumed a low-calorie diet. This indicates that being Ser/Ser homozygotes predisposes individuals to a more favorable response to low-calorie dietary treatment and that the PGC-1α polymorphism may have a gene–nutrient interaction. The present study also showed that the gene—nutrient interaction of PGC-1α rs10517030 was similar to that of PGC-1α Gly482Ser. Thus, low energy intake may be an effective preventive or therapeutic measure for managing type 2 diabetes in Koreans with PGC-1α rs10517030 major alleles. The results for rs10517030 was considered as those for rs10517032.
This work has the following strengths: it is the first report of the association of PGC-1α rs10517030 with the risk of type 2 diabetes and the gene–energy intake interaction in a large cohort (Ansung/Ansan cohort). Participants from an ethnically homogenous population were enrolled. However, the study also had several limitations. First, the results could not be used to determine causality because the study used a cross-sectional design. Second, PGC-1α Gly482Ser and Thr394Thr (missense mutation), the most intensively investigated SNPs linked to the development of type 2 diabetes, were not assessed, as they are not included in the KARE data. Third, no study has investigated the association between PGC-1α SNPs (rs10212638 and rs10517030). Finally, as too few subjects were homozygous for the minor alleles, all subjects carrying minor alleles were combined as one group and there was no determination of a gene dose effect.
In conclusion, subjects who were carriers of the PGC-1α minor allele for rs10517030 and rs10517032 and to a lesser extent rs10212638, had a high likelihood of developing type 2 diabetes. The increased risk was closely related to an inability to benefit as much from a low-energy-intake diet. When consuming a low-energy diet, the minor-allele group was more insulin resistant and had a lower capacity secrete insulin to compensate for the IR than the major-allele group. However, there were no significant differences between subjects with major or minor alleles when they consumed high-energy diets. Therefore, subjects with the minor alleles partially lose the natural protection of low-energy diets against type 2 diabetes and must be extra cautious to avoid other risk factors for diabetes.
References
Chan JC, Malik V, Jia W, Kadowaki T, Yajnik CS, Yoon KH et al. Diabetes in Asia: epidemiology, risk factors, and pathophysiology. JAMA 2009; 301: 2129–2140.
Coope A, Torsoni AS, Velloso LA . Mechanisms in endocrinology: metabolic and inflammatory pathways on the pathogenesis of type 2 diabetes. Eur J Endocrinol 2016; 174: R175–R187.
Wu H, Deng X, Shi Y, Su Y, Wei J, Duan H . PGC-1alpha, glucose metabolism and type 2 diabetes mellitus. J Endocrinol 2016; 229: R99–R115.
Puigserver P . Tissue-specific regulation of metabolic pathways through the transcriptional coactivator PGC1-alpha. Int J Obes (Lond) 2005; 29 (Suppl 1), S5–S9.
Nakamura MT, Yudell BE, Loor JJ . Regulation of energy metabolism by long-chain fatty acids. Prog Lipid Res 2014; 53: 124–144.
Ling C, Del Guerra S, Lupi R, Rönn T, Granhall C, Luthman H et al. Epigenetic regulation of PPARGC1A in human type 2 diabetic islets and effect on insulin secretion. Diabetologia 2008; 51: 615–622.
Oropeza D, Jouvet N, Bouyakdan K, Perron G, Ringuette LJ, Philipson LH et al. PGC-1 coactivators in beta-cells regulate lipid metabolism and are essential for insulin secretion coupled to fatty acids. Mol Metab 2015; 4: 811–822.
Valtat B, Riveline JP, Zhang P, Singh-Estivalet A, Armanet M, Venteclef N et al. Fetal PGC-1alpha overexpression programs adult pancreatic beta-cell dysfunction. Diabetes 2013; 62: 1206–1216.
Oberkofler H, Hafner M, Felder T, Krempler F, Patsch W . Transcriptional co-activator peroxisome proliferator-activated receptor (PPAR)gamma co-activator-1beta is involved in the regulation of glucose-stimulated insulin secretion in INS-1E cells. J Mol Med (Berl) 2009; 87: 299–306.
Kaul N, Singh YP, Bhanwer AJ . The influence of ethnicity in the association of WC, WHR, hypertension and PGC-1alpha (Gly482Ser), UCP2 -866 G/A and SIRT1 -1400 T/C polymorphisms with T2D in the population of Punjab. Gene 2015; 563: 150–154.
Ek J, Andersen G, Urhammer SA, Gaede PH, Drivsholm T, Borch-Johnsen K et al. Mutation analysis of peroxisome proliferator-activated receptor-gamma coactivator-1 (PGC-1) and relationships of identified amino acid polymorphisms to type II diabetes mellitus. Diabetologia 2001; 44: 2220–2226.
Hara K, Tobe K, Okada T, Kadowaki H, Akanuma Y, Ito C et al. A genetic variation in the PGC-1 gene could confer insulin resistance and susceptibility to type II diabetes. Diabetologia 2002; 45: 740–743.
Muller YL, Bogardus C, Pedersen O, Baier L . A Gly482Ser missense mutation in the peroxisome proliferator-activated receptor gamma coactivator-1 is associated with altered lipid oxidation and early insulin secretion in Pima Indians. Diabetes 2003; 52: 895–898.
Ha CD, Cho JK, Han T, Lee SH, Kang HS . Relationship of PGC-1alpha gene polymorphism with insulin resistance syndrome in Korean children. Asia Pac J Public Health 2015; 27: 544–551.
Kunej T, Globocnik Petrovic M, Dovc P, Peterlin B, Petrovic D . A Gly482Ser polymorphism of the peroxisome proliferator-activated receptor-gamma coactivator-1 (PGC-1) gene is associated with type 2 diabetes in Caucasians. Folia Biol (Praha) 2004; 50: 157–158.
Lacquemant C, Chikri M, Boutin P, Samson C, Froguel P . No association between the G482S polymorphism of the proliferator-activated receptor-gamma coactivator-1 (PGC-1) gene and type II diabetes in French Caucasians. Diabetologia 2002; 45: 602–603.
Leick L, Fentz J, Bienso RS, Knudsen JG, Jeppesen J, Kiens B et al. PGC-1{alpha} is required for AICAR-induced expression of GLUT4 and mitochondrial proteins in mouse skeletal muscle. Am J Physiol Endocrinol Metab 2010; 299: E456–E465.
Lee YH, Kang ES, Kim SH, Han SJ, Kim CH, Kim HJ et al. Association between polymorphisms in SLC30A8, HHEX, CDKN2A/B, IGF2BP2, FTO, WFS1, CDKAL1, KCNQ1 and type 2 diabetes in the Korean population. J Hum Genet 2008; 53: 991–998.
Kim JH, Shin HD, Park BL, Cho YM, Kim SY, Lee HK et al. Peroxisome proliferator-activated receptor gamma coactivator 1 alpha promoter polymorphisms are associated with early-onset type 2 diabetes mellitus in the Korean population. Diabetologia 2005; 48: 1323–1330.
Park S, Daily JW, Zhang X, Jin HS, Lee HJ, Lee YH . Interactions with the MC4R rs17782313 variant, mental stress and energy intake and the risk of obesity in Genome Epidemiology Study. Nutr Metab (Lond) 2016; 13: 38.
Bedogni G, Malavolti M, Severi S, Poli M, Mussi C, Fantuzzi AL et al. Accuracy of an eight-point tactile-electrode impedance method in the assessment of total body water. Eur J Clin Nutr 2002; 56: 1143–1148.
Association: AD. 2. Classification and Diagnosis of Diabetes. Diabetes Care 2016; 39 (Suppl 1), S13–S22.
Park S, Zhang X, Lee NR, Jin HS . TRPV1 gene polymorphisms are associated with type 2 diabetes by their interaction with fat consumption in the Korean Genome Epidemiology Study. J Nutrigenet Nutrigenomics 2016; 9: 47–61.
Brown TA . Genomes. 2nd edn. Wiley-Liss: Oxford, 2002.
Karolchik D, Hinrichs AS, Kent WJ . The UCSC Genome Browser. Curr Protoc Bioinformatics 2012; Chapter 1: Unit 1.4.
Liu C, Lin JD . PGC-1 coactivators in the control of energy metabolism. Acta Biochim Biophys Sin (Shanghai) 2011; 43: 248–257.
Bhat A, Koul A, Rai E, Sharma S, Dhar MK, Bamezai RN . PGC-1alpha Thr394Thr and Gly482Ser variants are significantly associated with T2DM in two North Indian populations: a replicate case-control study. Hum Genet 2007; 121: 609–614.
Fanelli M, Filippi E, Sentinelli F, Romeo S, Fallarino M, Buzzetti R et al. The Gly482Ser missense mutation of the peroxisome proliferator-activated receptor gamma coactivator-1 alpha (PGC-1 alpha) gene associates with reduced insulin sensitivity in normal and glucose-intolerant obese subjects. Dis Markers 2005; 21: 175–180.
Barroso I, Luan J, Sandhu MS, Franks PW, Crowley V, Schafer AJ et al. Meta-analysis of the Gly482Ser variant in PPARGC1A in type 2 diabetes and related phenotypes. Diabetologia 2006; 49: 501–505.
He ZH, Hu Y, Li YC, Gong LJ, Cieszczyk P, Maciejewska-Karlowska A et al. PGC-related gene variants and elite endurance athletic status in a Chinese cohort: a functional study. Scand J Med Sci Sports 2015; 25: 184–195.
Handschin C, Spiegelman BM . Peroxisome proliferator-activated receptor gamma coactivator 1 coactivators, energy homeostasis, and metabolism. Endocr Rev 2006; 27: 728–735.
Esterbauer H, Oberkofler H, Linnemayr V, Iglseder B, Hedegger M, Wolfsgruber P et al. Peroxisome proliferator-activated receptor-gamma coactivator-1 gene locus: associations with obesity indices in middle-aged women. Diabetes 2002; 51: 1281–1286.
Andrulionyte L, Peltola P, Chiasson JL, Laakso M . Single nucleotide polymorphisms of PPARD in combination with the Gly482Ser substitution of PGC-1A and the Pro12Ala substitution of PPARG2 predict the conversion from impaired glucose tolerance to type 2 diabetes: the STOP-NIDDM trial. Diabetes 2006; 55: 2148–2152.
Oberkofler H, Hafner M, Felder T, Krempler F, Patsch W . Transcriptional co-activator peroxisome proliferator-activated receptor (PPAR)gamma co-activator-1beta is involved in the regulation of glucose-stimulated insulin secretion in INS-1E cells. J Mol Med 2009; 87: 299–306.
Ferrannini E, Mari A . beta-Cell function in type 2 diabetes. Metabolism 2014; 63: 1217–1227.
Ma RC, Chan JC . Type 2 diabetes in East Asians: similarities and differences with populations in Europe and the United States. Ann N Y Acad Sci 2013; 1281: 64–91.
Knoll N, Jarick I, Volckmar AL, Klingenspor M, Illig T, Grallert H et al. Gene set of nuclear-encoded mitochondrial regulators is enriched for common inherited variation in obesity. PLoS One 2013; 8: e55884.
Goyenechea E, Crujeiras AB, Abete I, Parra D, Martinez JA . Enhanced short-term improvement of insulin response to a low-caloric diet in obese carriers the Gly482Ser variant of the PGC-1alpha gene. Diabetes Res Clin Pract 2008; 82: 190–196.
Acknowledgements
Funding for this study was provided by the Academic Research Fund of Hoseo University in 2016 (2016-0088). SP participated in the experimental design, data analysis and writing of the manuscript; BCK analyzed the data; and SK participated in discussing the results and writing the manuscript. All authors contributed substantially to the work and have read and approved the submitted version. The English in this document has been checked by at least two professional editors, both native speakers of English. For a certificate, please see: http://www.textcheck.com/certificate/vOLrKX.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no conflict of interest.
Rights and permissions
About this article

Cite this article
Park, S., Kim, B. & Kang, S. Interaction effect of PGC-1α rs10517030 variants and energy intake in the risk of type 2 diabetes in middle-aged adults. Eur J Clin Nutr 71, 1442–1448 (2017). https://doi.org/10.1038/ejcn.2017.68
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/ejcn.2017.68
- Springer Nature Limited