
Abstract
We investigated how becoming literate in Roman script affects the way we process letter-like objects and even faces, using a paired same-different task with nonwords, false fonts (letter-like symbols), and faces with monoliterate English and Thai readers. Roman script has mirror letter pairs whereas Thai script does not. Importantly, the Thais were literate in Thai but illiterate in Roman script. Participants were required to respond with a “same” response to both identical and mirror pairs of images. We predicted that the Thais would be more influenced by mirror invariance and so better able to recognise mirror-image pairs as being the same object than English readers. We found support for this prediction as the English readers showed a greater mirror cost for response times than the Thais. Thus, becoming literate in Roman script reduces the ability to judge two mirror images as the “same” in comparison to Thai script readers. These findings provide evidence that Thai readers who are illiterate in Roman script are more susceptible to mirror generalisation effects than Roman script readers.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Learning to read is a cognitively challenging task that varies dependent on the characteristics or features of the particular orthography to be learned. As reading is a relatively recent cultural invention, it does not have particular cortical networks of the brain associated with that function. Instead, it has been found to recycle pre-existing regions of the visual cortex that are typically used for recognising objects and faces (e.g., Dehaene 2005; Dehaene & Cohen 2007; Dehaene et al. 2005, 2010, 2015; Dehaene-Lambertz et al. 2018). From an evolutionary perspective, the visual system is programmed to recognise predators or objects regardless of their orientation. This is referred to as mirror invariance or generalisation and is defined as the ability to recognise objects as being the same regardless of their spatial orientation (in particular in relation to a left-to-right orientation).
Importantly, some scripts, such as Roman script, have mirror letters (b vs. d or p vs. q), which can pose significant challenges to children learning to read, in particular children with dyslexia (e.g., see Badian 2005; Fernandes & Leite 2017). When learning to read Roman script with its mirror letters, children need to fine-tune skills so that they can readily discriminate between mirror letter pairs and words containing those letters (e.g., bad vs. dad). Thus, the general mirror recognition ability must be inhibited or suppressed to some extent when learning to read scripts with mirror letters (e.g., Dehaene et al. 2005, 2010; Dehaene-Lambertz et al. 2018; Duñabeitia et al. 2011; Hervais-Adelman et al. 2019; Perea et al. 2011). However, many scripts, including Tamil, Devanagari, and Thai, do not have mirror letters. This raises the question as to whether readers of scripts without mirror letters or readers who are illiterate in Roman script retain their mirror invariance to a greater extent than English readers whose script has mirror letters.
The majority of research so far conducted on mirror invariance has predominantly focused on the Roman script. The relatively few studies that have been conducted on different writing systems suggests that learning to read scripts with and without mirror letters may lead to somewhat different brain changes and responses to mirror invariance. Previous research on Tamil (a script without mirror letters) indicates that readers remained poor at mirror discrimination of geometric figures and identified them as if they were the same stimulus (Danziger & Pederson 1998; Pederson 2003). In both studies, a “whole” card with a complex geometric figure was shown in conjunction with a “part” card that had a component from the complex figure (e.g., a triangle or arrow) that was either a mirror-image or not. Participants gave a speeded response as to whether the “part” occurred in the “whole”. They found that Tamil readers and illiterates tended to respond similarly to identical and mirror images. In Thai, another script without mirror letters, Winskel and Perea (2018) used a same-different masked priming task with mirror primes composed of Thai and English words with mirror-letters (the two middle letters were rotated on the vertical). The Thai participants were university students, who were also experienced and familiar with reading English and Roman script. They found that the mirror prime (e.g.,  ) had a similar facilitative effect as the identical prime (e.g., leaf) in Thai readers, whereas this was not apparent in the English readers. Thus, the Thais were more likely to perceive mirror letters and identical letters similarly in comparison to English readers. These results on Tamil and Thai suggest that readers of scripts without mirror letters are more susceptible to mirror generalisation effects when compared to readers of scripts that do have mirror letters (i.e., Roman script).
) had a similar facilitative effect as the identical prime (e.g., leaf) in Thai readers, whereas this was not apparent in the English readers. Thus, the Thais were more likely to perceive mirror letters and identical letters similarly in comparison to English readers. These results on Tamil and Thai suggest that readers of scripts without mirror letters are more susceptible to mirror generalisation effects when compared to readers of scripts that do have mirror letters (i.e., Roman script).
In a recent study, Fernandes et al. (2021) investigated mirror processing in illiterate, Tamil literate and Tamil-Latin-bi-literate adults. Importantly, they presented participants with two contrasting same-different tasks; one shape-based and the other orientation-based with Latin-alphabet letters. In the shape-based task, participants were asked to decide if the second stimulus had the same shape or not as the first stimulus, regardless of orientation. Thus, the task required them to respond same to identical, mirror-image, and plane-rotation trials. In this task, mirror invariance facilitates performance. In contrast, in the orientation-based task, participants were asked to decide if the two presented stimuli exactly match or not. Thus, in that task, they should respond different to mirror-image and plane-rotation trials. They found that Tamil monoliterates were significantly better at the orientation-based task than illiterates and showed good explicit mirror-image discrimination. However, only the biliterates fully broke mirror invariance as they showed slower shape-based judgments for mirrored than identical pairs and a reduced disadvantage in orientation-based over shape-based judgments of mirrored pairs. Thus, they found that learning to read a script with mirrored graphs was the primary factor in breaking mirror invariance.
Script-specific differences in mirror invariance processing have also been found in an fMRI study that investigated the brain mechanisms underlying mirror generalisation in French and Japanese readers using a same-different repetition priming task. Dehaene et al. (2010) found some intriguing differences in their study using French words, Japanese logographic Kanji characters, false fonts, pictures of tools, and faces and their corresponding left–right reversed mirror images. The participants had to give a “same” response to both pairs of identical and mirror images. Results revealed that mirror priming did not occur for alphabetic stimuli in the French participants (4 ms) but did for the Japanese Kanji characters in the Japanese participants (44 ms). Thus, mirror invariance processing differences occurred in the two contrasting scripts.
A related line of research has focused on comparing illiterate with literate Roman script participants and how that affects mirror invariance. Pegado et al. (2014), for example, compared mirror generalisation abilities in adult literates, illiterates, and ex-illiterates using a same-different task with Roman script nonwords, false fonts, and pictures (faces, houses and tools). Participants had to respond “same” to mirror pairs (e.g., iblo—oldi) as they did to identical pairs (e.g., iblo—iblo). In the illiterates, there was no response time difference between identical and mirror-images when responding “same” for any of the stimulus types. In contrast, literates were slower at responding “same” to mirror-images in comparison to the identical images with the largest difference occurring when responding to nonwords (e.g., iblo—oldi). Thus, illiterates were found to be better able to recognise mirror pairs as being the same object than people who were literate in Roman script, and this included ex-illiterates. This suggests that becoming literate in Roman script with its mirror letters impacts the visual system such that mirror invariance is reduced.
As previously stated, prior research on readers of scripts without mirror letters suggests that they are more susceptible to mirror generalisation effects in comparison to readers of scripts that do have mirror letters (i.e., Roman script). In order to further investigate how becoming literate in the Roman script affects the way we process letter-like objects and even faces, we conducted a paired same-different task with nonwords, false fonts, and faces with monoliterate English readers and monoliterate Thai readers. Roman script has mirror letter pairs whereas Thai script does not. We used similar materials as used by Dehaene et al. (2010) and Pegado et al. (2014); however, we only used faces and not houses or tools. The monoliterate Thais were illiterate in Roman script as they were not able to read that script. Of particular note in this task, participants were required to respond with a “same” response to both identical and mirror pairs of images (see Fig. 1); similar to the shape-based task used by Fernandes et al. (2021). We can make a number of predictions. We can expect the monoliterate Thai readers to be more influenced by mirror invariance and so better able to recognise mirror-image pairs as being the same object than English readers. Thus, it is expected that for Thai readers, there will be a smaller difference between the response times and accuracy for making “same” judgment responses to identical and mirror-image stimuli in comparison to English readers when making judgments about the Roman script nonwords or letters but also to false fonts and even to the faces, as occurred in the Pegado et al. (2014) study. Thus, we can expect differences in responses to identical and mirror-image Roman script nonwords and false font stimuli to be reduced in the Thai in comparison to the Roman script monoliterates.

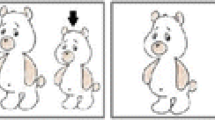
Examples of the stimuli used: faces, nonwords and false fonts showing “same’ responses to identical and mirror-images and “different” responses to non-matching stimuli. A single trial consisted of an initial stimulus with a duration of 200 ms that was replaced by a fixation point that occurred for 300 ms and subsequently the second stimulus was presented for 200 ms. The participant then had to decide whether the two stimuli were the same or different. The participant was required to make a same response to both identical and mirror-image stimuli
Method
Participants
Twenty-two monoliterate Thai readers (mean age 39.91, range 17–59 years) and 22 monoliterate English readers (mean age 42.82, range 20–62 years) participated in the experiment. The Thai and English participants were matched as closely as possible for age, gender, and educational background. None of the participants were tertiary educated and all had either no or limited secondary education, and none of the participants had completed senior high school. The Thai participants were recruited on the basis that they could not speak or read English but were native speakers of Thai as well as fluent readers of Thai. They were recruited through word of mouth. The Thai monoliterates had very limited knowledge of the Roman script. Prior to the experiment being conducted, they were assessed for their knowledge of Roman script using upper and lower-case letters of the Roman alphabet and some simple English words (e.g., man, cat, one). Thirteen of the Thai participants could identify some of the letters of the alphabet and only seven participants could recognise a few (two or three) simple English sight words. However, they were not able to read the word when the initial consonant was changed (e.g., cat to bat). The majority of the participants were also not familiar with using a computer. In order to address this, participants had a series of practice trials to ensure that they gained familiarity with responding using the keys on the keyboard. The Thai participants were recruited in Bangkok and the English participants were recruited in regional Australia. All participants had normal or corrected-to-normal vision.
Materials
Three categories of visual stimuli were presented to each participant: nonwords, false fonts, and faces. The materials were adopted from Pegado et al. (2014); however, in the current study only faces were used and not houses or tools. The stimuli from the three categories were presented sequentially as pairs in a random order for each participant. Each category consisted of three different conditions (20 identical, 20 mirror-images, 20 different). Thus, there were 60 trials per category and in total 180 trials. The nonwords were composed of four lowercase Roman letters. The false font stimuli were matched one-to-one with the nonwords by replacing each letter with a pseudoletter. The “different” pairs of stimuli were created by pairing each example with a substantially different stimulus (see Fig. 1 for an example of the stimuli used). Also see Pegado et al. (2014) and Dehaene et al. (2010) for a more detailed description of the materials used.
Procedure
A similar procedure was followed as in Pegado et al. (2014). Participants were tested individually in a quiet room. Presentation of the stimuli and recording of response times were controlled by a 17-inch Dell laptop computer running DMDX (Forster & Forster 2003). The testing procedure was explained verbally and demonstrated through visual and written instructions in the respective language to each participant. Subsequently, 12 practice trials were presented prior to the 180 experimental trials. Two pairs of stimuli were presented (i.e., two faces, two nonwords, two false fonts) and the participant was required to give a ‘same’ response if the pair of stimuli were identical or mirror images by pressing the ‘M’ key on the keyboard and a different response to a different pair of stimuli by pressing the ‘Z’ key on the keyboard. The first image was presented for 200 ms, a screen with a fixation point appeared for 300 ms, then the second image of the pair was displayed for 200 ms (see Fig. 1 for a graphic representation of a trial). The participant had up to 3 s to respond, before a new trial started. The experiment took approximately 15 min.
Results
Response times (RTs)
For comparison purposes, the inferential analyses on the RTs were parallel to those conducted by Pegado et al. (2014). First, we used natural logarithmic-transformed RTs as the dependent measure to reduce differences in variance across literacy groups (Thai monoliterates, English monoliterates) (see Table 1 with mean RTs). Second, we focused on the “same” versus “mirror” conditions only, as they both corresponded to “yes” responses. Third, we employed a 2(Group: English monoliterates, Thai monoliterates) × 3(Category: faces, false fonts, nonwords) × 2(Condition: same, mirror) ANOVA. The ANOVA showed a main effect of literacy group with Thai literates having faster response times than the English literates (467 vs. 617 ms, respectively), F(1, 43) = 10.94, p = 0.002. There was a main effect of category, F(2, 43) = 63.45, p < 0.001. Participants responded to faces faster than either false fonts or nonwords (440, 598 and 588 ms, respectively). There was a main effect of condition as same responses were faster than mirror responses (441 vs. 580 ms, respectively), F(1, 43) = 218.17, p < 0.001. More important, there was a significant interaction effect between literacy group and condition, F(1, 43) = 6.93, p = 0.01. This interaction effect was due to a smaller difference between response times for “same” and “mirror” items for Thais (382 vs. 475 ms, respectively), t(43) = 3.92, p < 0.001 than for the English participants (500 vs. 685 ms, respectively), t(43) = 2.62, p = 0.01. The 3-way interaction effect of group × category × condition was not significant (p > 0.3), thus, indicating that the interaction effect between group and condition occurred for all categories of faces, false fonts and nonwords (refer to Fig. 2). In order to verify this effect, we also tested directly for group differences in mirror cost for each category, using the normalized index: (logRTmirror − logRTsame)/(logRTmirror + logRTsame) (Pegado et al. 2014). We found a main effect of group, F(2, 43) = 4.99, p = 0.03, but not for category (p > 0.1). There was also no interaction effect for group by category (p > 0.4). In sum, the monoliterate English group showed a greater mirror cost index than the Thai monoliterates. In other words, becoming literate in Roman script reduces the efficiency with which one judges two mirror images as the “same” in comparison to Thai script readers, who do not have mirror letters in their script.

Log-transformed response times (logRTs). Response times were transformed according to a natural logarithm to correct for group differences in variance
We then analysed the “different” trials by performing an ANOVA with literacy group as the between-subjects factor and category as the within-subjects factor. The results showed a main effect of category, F(1, 43) = 112.53, p < 0.001. Response latencies to faces were faster than to false fonts and nonwords. There was a main effect of literacy group, F(1, 43) = 6.15, p = 0.02, as the Thais responded faster than the English participants. No other effects were significant.
Error rates
An ANOVA on error rates revealed main effects of category, F(2, 43) = 41.81, p < 0.001 and condition, F(2, 43) = 53.50, p < 0.001, but there was no main effect of literacy group (p > 0.7) (see Fig. 3). There was an interaction effect of category by condition, F(2, 43) = 26.18, p < 0.001. For faces, there was no significant difference between same and mirror conditions. However, there were less errors for ‘same’ than ‘mirror’ responses for false fonts, t(43) = 7.73, p < 0.001 and nonwords, t(43) = 6.08, p < 0.001. No other effects were significant (ps > 0.2).

Error rates for English monoliterates and Thai monoliterates in the different conditions
Speed-accuracy trade-off analysis
No speed-accuracy trade-off was found, that is, no negative correlation between RTs and error rates was found. In fact, there was a positive correlation, r = 0.32, p < 0.001.
Signal detection theory (SDT) analysis
In order to evaluate the sensitivity and possible bias in subjects’ responses, a signal detection theory (SDT) analysis was performed similar to Pegado et al. (2014). Because there were three conditions (same, different, and mirror), two of which (same and mirror) had to be responded with the “same” response, two successive SDT analyses were performed. The first focused on the ability of the subjects to distinguish “mirror” versus “different” trials; we therefore coded the data in the following manner: hits = different trials answered “different” and false alarms (FAs) = mirror trials answered “different”. The second SDT analysis examined the discrimination between same versus different trials, in which hits = different trials answered “different” and FAs = same trials answered “different.”
Sensitivity (d′)
We calculated d′ = (Z scores hits − Z scores FA) for each subject, category, and SDT matrix type to use them as the dependent variable in a 2 × 3 × 2 ANOVA for literacy group (Thai monoliterates, English monoliterates) as a between-subjects factor and visual category (faces, false fonts, nonwords) and d’ type (“same” vs. “different,” “mirror” vs. “different”) as within-subject factors. Refer to Table 1.
A main effect of category was found, F(2, 84) = 335.98, p < 0.001. Faces were found to be significantly easier than nonwords, which were significantly easier than false fonts. A main effect for d′ type was found, F(1, 43) = 81.49, p < 0.001. It was easier for subjects to discriminate between same vs. different than mirror vs. different trials. Literate type was only marginally significant, F(1, 43) = 3.27, p = 0.078. There was an interaction of category by condition, F(2, 84) = 28.68, p < 0.001. For false fonts and nonwords, it was easier for subjects to discriminate between same vs. different than mirror vs. different trials (p < 0.001), but there was no significant difference for faces. Noticeably, there were no significant interactions effects for literacy group by condition (p > 0.9) or literacy group by category (p > 0.2) or between literacy group, condition and category (p > 0.7). Thus, when considering accuracy in the form of signal-detection theory, the findings were similar for both the Thai and English monoliterates.
Discussion
In order to investigate how becoming literate in the Roman script affects the way we process letter-like objects and even faces, we conducted a paired same-different task with nonwords, false fonts, and faces with English monoliterate readers and Thai monoliterate readers. Importantly, the Thais were literate in Thai but illiterate in Roman script—note that Roman script has mirror letter pairs whereas Thai script does not. We employed similar materials as those used by Dehaene et al. (2010) and Pegado et al. (2014). We predicted that the monoliterate Thai readers would be more influenced by mirror invariance and so better able to recognise mirror-image pairs as being the same object than English readers. Thus, it was expected that there would be a smaller difference between the response times and accuracy for making “same” judgment responses to identical and mirror-image stimuli in Thai readers in comparison to English readers. This pattern occurred not only when making judgments about the Roman script nonwords but also to false fonts and even to the faces. Thus, we found support for this prediction as the monoliterate English group showed a greater mirror cost for response times than the Thai monoliterates. In other words, becoming literate in Roman script reduces the ability to judge two mirror images as the “same” in comparison to Thai script readers. This pattern occurred across all categories but in particular for false fonts and nonwords (strings of letters)—note, that matching pairs of faces was an easier task than matching either the false font or nonword pairs. Of note, while we tried to match the Thai and English participants as closely as possible for age, gender and education level, the English monoliterates had overall slower response times than the Thai monoliterates. The Thai readers were recruited in the fast-paced life of Bangkok whereas the English readers were recruited in regional Australia, and consequently, had different cultural and life experiences. The Bangkok Thais were employed in occupations associated with the university such as food sellers, janitors, motorbike taxi drivers and some regularly played video games.
Thus, the present findings have shown evidence that Thai readers who are illiterate in Roman script are more susceptible to mirror generalisation effects in comparison to Roman script readers, as deduced from the latency data. This is in line with Pegado et al.’s (2014) research on illiterates, as they were found to be better able to recognise mirror objects as being the same than literate participants. This supports the view that becoming literate in Roman script with its mirror letters impacts the visual system such that mirror invariance is reduced. Pegado et al. (2014) found the largest effect was for nonwords whereas in the current study we found the effect occurred for all categories but the effects were numerically larger for false fonts and nonwords. One noticeable difference between our study and the Pegado et al. (2014) study is that our Thai participants were illiterate in Roman script but literate in another script, Thai, which does not contain mirror letters. These findings are also compatible with the results from Fernandes et al. (2021) study that investigated mirror processing in illiterate, Tamil literate and Tamil-Latin-bi-literate adults with Roman script. They used a shape-based task similar to the current study but in addition an orientation-based task. Significantly, they found that learning to read a script with mirrored letters was the primary factor in breaking mirror invariance. In addition, they also found that mirror-image discrimination occurs from just learning to read a script (regardless of mirror letters), as they found that Tamil monoliterates were significantly better at the orientation-based task than the illiterates. Notably in both studies, ours and Fernandes et al. (2021), Roman script stimuli were used and not Thai or Tamil.
These results give empirical support to the neuronal recycling hypothesis, which proposes that reading piggybacks onto pre-existing regions of the visual cortex that are used for recognising objects and faces regardless of their spatial orientation (e.g., Dehaene et al. 2005; Dehaene et al. 2010; Dehaene-Lambertz et al. 2018; Duñabeitia et al. 2011; Hervais-Adelman et al. 2019; Perea et al. 2011). Thus, reading inherits mirror invariance or generalisation tendencies. However, when learning to read Roman script these inherited tendencies need to be inhibited or suppressed, so that mirror letters can be discriminated (e.g., bad vs. dad). In contrast, in scripts such as Thai that do not have mirror letters, mirror invariance does not need to be inhibited or suppressed to the same extent. As a side note on the neuronal recycling hypothesis, Van Paridon et al. (2021) recently showed that the recycling of evolutionarily older circuits (e.g., object recognition areas for processing letters and words) that occurs with literacy acquisition does not necessarily have a deleterious effect on general object recognition abilities, but rather a facilitative one.
The notion of suppression in relation to literacy development can also be applied more generally to other spatial operations besides mirror suppression. Lachmann and van Leeuwen (2014) argued that learning to read and write generally requires analytic processing, and thus, the holistic processing that is dominant in object recognition (e.g., in relation to symmetry, context and global processing) needs to be suppressed. However, this more general approach would not predict a different impact for learning Thai versus Roman script; instead, the current findings support a more specific mirror-image perspective.
We believe that the present study opens interesting opportunities for further research investigating mirror generalisation effects in bilinguals learning scripts with and without mirror letters or with letters occurring in different orientations. For example, Burmese has mirror letters on the horizontal axis (e.g.,  and
and  ) whereas Korean Hangul has both lateral and vertical perceptually similar mirror letter pairs apart from orientation (i.e., see Pae et al. (2020), for evidence of effects of writing direction in Korean Hangul and Winskel & Kim (2021), who used a negative priming paradigm to investigate mirror letter orientation).
) whereas Korean Hangul has both lateral and vertical perceptually similar mirror letter pairs apart from orientation (i.e., see Pae et al. (2020), for evidence of effects of writing direction in Korean Hangul and Winskel & Kim (2021), who used a negative priming paradigm to investigate mirror letter orientation).
References
Badian, N. A. (2005). Does a visual orthographic deficit contribute to reading disability? Annals of Dyslexia, 55, 28–52. https://doi.org/10.1007/s11881-005-0003-x
Danziger, E., & Pederson, E. (1998). Through the looking glass: Literacy, writing systems and mirror-image discrimination. Written Language & Literacy, 1, 153–169. https://doi.org/10.1075/wll.1.2.02dan
Dehaene, S. (2005). Evolution of human cortical circuits for reading and arithmetic: The neuronal recycling hypothesis. In S. Dehaene, J-R. Duhamel, M. D. Hauser, & G. Rizzolatti (Eds.), From monkey brain to human brain. A Fyssen Foundation Symposium (pp. 133–157). MIT Press.
Dehaene, S., & Cohen, L. (2007). Cultural recycling of cortical maps. Neuron, 56(2), 384–398. https://doi.org/10.1016/j.neuron.2007.10.004
Dehaene, S., Cohen, L., Morais, J., & Kolinsky, R. (2015). Illiterate to literate: Behavioural and cerebral changes induced by reading acquisition. Nat Rev Neurosci, 16(4), 234–244. https://doi.org/10.1038/nrn3924
Dehaene, S., Cohen, L., Sigman, M., & Vinckier, F. (2005). The neural code for written words: A proposal. Trends in Cognitive Sciences, 9, 335–341. https://doi.org/10.1016/j.tics.2005.05.004
Dehaene, S., Pegado, F., Braga, L. W., Ventura, P., Nunes Filho, G., Jobert, A., & Cohen, L. (2010). How learning to read changes the cortical networks for vision and language. Science, 330, 1359–1364. https://doi.org/10.1126/science.1194140
Dehaene-Lambertz, G., Monzalvo, K., & Dehaene, S. (2018). The emergence of the visual word form: Longitudinal evolution of category-specific ventral visual areas during reading acquisition. PLoS Biology, 16(3), e2004103. https://doi.org/10.1371/journal.pbio.2004103
Duñabeitia, J. A., Molinaro, N., & Carreiras, M. (2011). Through the looking-glass: Mirror reading. NeuroImage, 54, 3004–3009. https://doi.org/10.1016/j.neuroimage.2010.10.079
Fernandes, T., Arunkumar, M., & Huettig, F. (2021). The role of the written script in shaping mirror-image discrimination: Evidence from illiterate, Tamil literate, and Tamil-Latin-alphabet bi-literate adults. Cognition, 206, 104493. https://doi.org/10.1016/j.cognition.2020.104493
Fernandes, T., & Leite, I. (2017). Mirrors are hard to break: A critical review and behavioral evidence on mirror-image processing in developmental dyslexia. Journal of Experimental Child Psychology, 159, 66–82. https://doi.org/10.1016/j.jecp.2017.02.003
Hervais-Adelman, A., Kumar, U., Mishra, R. K., Tripathi, V. N., Guleria, A., Singh, J. P., & Huettig, F. (2019). Learning to read recycles visual cortical networks without destruction. Science Advances, 5(9), eaax0262. https://doi.org/10.1126/sciadv.aax0262
Pae, H. K., Bae, S., & Yi, K. (2020). Horizontal orthography versus vertical orthography: The effects of writing direction and syllabic format on visual word recognition in Korean Hangul. Quarterly Journal of Experimental Psychology, 74(3), 443–458. https://doi.org/10.1177/1747021820971503
Pederson, E. (2003). Mirror-image discrimination among nonliterate, monoliterate, and biliterate Tamil subjects. Written Language & Literacy, 6, 71–91. https://doi.org/10.1075/wll.6.1.04ped
Pegado, F., Nakamura, K., Braga, L. W., Ventura, P., Nunes Filho, G., Pallier, C., & Dehaene, S. (2014). Literacy breaks mirror invariance for visual stimuli: A behavioral study with adult illiterates. Journal of Experimental Psychology-General, 143(2), 887–894. https://doi.org/10.1037/a0033198
Perea, M., Moret-Tatay, C., & Panadero, V. (2011). Suppression of mirror generalization for reversible letters: Evidence from masked priming. Journal of Memory and Language, 65, 237–246. https://doi.org/10.1016/j.jml.2011.04.005
Van Paridon, J., Ostarek, M., Arunkumar, M., & Huettig, F. (2021). Does neuronal recycling result in destructive competition? The influence of learning to read on the recognition of faces. Psychological Science, 32, 459–465. https://doi.org/10.1177/0956797620971652
Winskel, H., & Perea, M. (2018). Do the characteristics of the script influence responses to mirror letters? In N. Mani, R. K. Mishra, & F. Huettig (Eds.) The interactive mind: Language, vision and attention (pp. 61–66). Macmillan.
Winskel, H., & Kim, T.-H. (2021). The mirror generalization process in reading: Evidence from Korean Hangul. Journal of Psycholinguistic Research, 50(2), 447–458. https://doi.org/10.1007/s10936-020-09736-1
Funding
No funding was received for conducting this study.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflicts of interest to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Winskel, H., Perea, M. Mirror-image discrimination in monoliterate English and Thai readers: reading with and without mirror letters. J Cult Cogn Sci 6, 169–177 (2022). https://doi.org/10.1007/s41809-021-00090-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41809-021-00090-9