
Abstract
The set covering problem is a fundamental model which comprises a wide range of important applications such as crew scheduling problems that need to cover a set of trips. It is one of the most common issues in the facility location problem, which requires further investigations, particularly in emergency and service facilities. As such, the objective of this study is to propose a new coefficient-based heuristic algorithm for the set covering problems. This paper has accordingly presented the algorithm that evaluates the qualification of subsets by directly applying a fitness function. This fitness function is formulated based on sets and subsets coefficients in a way that the subsets of selected sets have the lowest probability to be selected in the next iteration. The algorithm is not only capable of constructing an answer within polynomial time, but can solve complex set covering problems without conventional restrictions. The performance of this algorithm is evaluated on benchmark instances including a set of reproduced and selected OR-library problems within different sizes. Computational results indicate that the proposed heuristic algorithm produces better solutions, especially in large-scale problems comparing simulated annealing in terms of quality and time.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Location selection problem (LSP) is one of the branches of operations research that aims at reducing costs in industrial sectors. Center’s location selection problem (CLSP) involves selecting a location for one or more centers which needs to take into account the existing constraints and the location of other centers so that a specific goal is optimized. This goal can be transportation costs, covering a wider area of the market, and providing fair service to customers. As such, the facility location problem (FLP) is regarded as a critical issue for public and private companies which in turn, necessitate examining the cost and the distance of demand points in different fields [1].
Set covering problem (SCP) is one of the most common issues in FLP that requires further investigations, particularly in emergency and service facilities. In many coverage problems, customers receive services based on their distance from the service facility. Each customer is able to receive services from the provided facilities where the distance between them is less than a pre-determined value; the value which is called coverage distance [2]. Set covering problem has been applied to solve various problems including practical and non-practical applications such as airline staff scheduling, fire stations layout plan, radar layout plan, police stations layout plan, hospitals, libraries, post offices, delivery points, design and simplification of switch circuits, assembly line balance, vehicle routing, ship scheduling, defense and offensive networks, bus drivers scheduling, information retrieval, production, investment, project selection, traffic allocation in satellite communication systems, calculation of limits in integer programming, computer networks, transportation systems, bioinformatics, etc. [3,4,5,6,7]. Going through the literature indicates that SCP was first introduced by Jain et al. [8] to examine the minimum number of required police wearing the nodes of the highway network. They modeled the problem as a vertex coverage problem in a graph. Regarding studies of location problems, continuous location models, network location, mixed integer programming models and their applications are presented [9, 10]. This study was then proceeded to solve a discrete location problem when facilities are potentially prone to failure [10]. In another study, the location problem was defined regarding uncertainty. A multi-objective location problem solution was also developed based on a meta-heuristic algorithm constructed by tabu search [11]. Subsequently, a new model for locating hazardous waste [12] was proposed. The purpose of this model was to minimize the total cost and risk of transportation. Considering the problem of designing routes for hazardous materials transportation in a densely crowded area, the integer programming method with the function of minimizing transport risk was proposed [13]. Afterward, using a constructive heuristic algorithm, the solution to the tree design problem was developed. A probabilistic coverage location model for perishable and non-perishable items was also presented [14]. In this regard, the effect of goods’ spoilage cost on the issue of location has been also investigated.
From the above discussion, SCP is a NP-hard problem. Researchers have proposed various heuristic algorithms regarding this problem. Optimization models including combinational and multi-objective have been presented for this problem. Different algorithms of ant, tabu, pso, genetic and hybrid have been also applied to deal with the development of these models. Due to the nature of SCP, which is one of the NP-hard problems, this class of problems cannot be solved exactly in real dimensions. Hence, to overcome this issue, a new heuristic algorithm is proposed that can solve the real problem in polynomial time. Meanwhile, to evaluate the efficiency of the proposed algorithm, the simulated annealing (SA) algorithm has been applied to extend its application to the problems in larger dimensions, and the Taguchi method has been used to tune its parameters. Although there are very few polynomial time algorithms that can solve NP-hard problems in polynomial time; there is no polynomial time algorithm to deal with SCP. Hence, the presented algorithm's superiority to the other algorithms is its specified approach for SCP. In other words, the main contribution of this paper is to present a new heuristic algorithm that is not only capable of constructing an answer within polynomial time, but can solve complex SCPs without conventional restrictions that previous studies have applied.
To this end, in the following section, the research background is reviewed. In the third section, the mathematical model of the problem is stated. The fourth and fifth sections cover the SA algorithm and the new proposed heuristic algorithm, respectively. Computational results are accordingly discussed in the sixth section.
2 Literature
A considerable logistic problem appears when there is a set of demands which need to be satisfied with services to be located at many points to supply those demands. This is a renowned problem in operations research, entitled ‘set covering problem’ [15,16,17].
The set covering problem is a well-known optimization problem in the heuristics and mathematical programming literature [18, 19]. In this background, most studies in SCP considered the earlier SCP formulation presented by Lanza-Gutierrez et al. [20] and defined it as follows. If K is a set of n objects and L is a set of m subsets of k where subsets take non-negative cost, then the purpose of SCP is to minimize the cost group of subsets X ⊆ L, in a way that each agent of K belongs to at least one subset of the group X. In addition, early works proposed to solve it using exact methods, which typically count on the branch and bound [21, 22] and branch-and-cut algorithms [23, 24]. However, the main concern is the long time these algorithms take to deal with hard instances. To tackle this concern, recent studies have been mostly focused on the evolvement of new heuristics with the ability to find solutions in a logical time [25]. The greedy randomized adaptive search procedure (GRASP) is a technique that builds a solution through a specified number of steps applying a set of specific rules. Among recent studies pertaining to GRASP, the local search and rewarded procedures [25] has been proposed to improve the solutions discovered by GRASP. The approach had been tested by applying non-unicost SCP benchmark instances from the OR-library, indicating promising results. Traditional greedy algorithms are fast enough for implementation, despite their weakness in producing high-quality solutions due to their deterministic character. For instance, GRASP has been applied by [26] for the set covering problem. The objective of this study was to find a column subset from a zero–one matrix to cover all of the rows with the least possible cost.
Salehipour [27] developed an effective heuristic algorithm applying lower bounds to generate a feasible solution which was obtained through a local search. Nogueira et al. and Hashemi et al. [28, 29] also developed a heuristic local search algorithm for large SCP applying SA. This study used an improvement routine to generate near-optimal solutions within reasonable CPU time. In addition, Chiscop et al. [30] developed a hybrid algorithm for multi-service SCP. This algorithm applied a process that began from an initial seed solution to repetitively create sub-problems to be resolved more efficiently. A configuration checking-based algorithm for SCP [31] was developed to not only consider subset states but also take into account the element states, leading to cutting down the unnecessary search space. Sadeghi et al. [32] developed a simple Lagrangian heuristic algorithm for SCP. This algorithm had an application for low-density with the dimension of 1000 rows and 10,000 columns wherein the density is equal to the ratio of 1 s in the matrix of the coefficients of the model constraints. Later on, Mandal et al. [33] designed an algorithm to indicate the application of SCP in natural disaster management. This algorithm was proposed to find supply vertices for covering sets of fuzzy graphs. In a similar study, Alizadeh and Nishi [34] proposed an algorithm for dynamic modular SCP. In this study, the algorithm applied a fitness function to deal with locating first aid centers in logistic services in Japan. Lorena and de Souza Lopes, Aickelin and Idrees and Al-Yaseen [35,36,37] have applied a Genetic Algorithm (GA) to resolve SCP. Lorena and de Souza Lopes [35] presented a new GA for the SCP. This study applied GA to provide a decoder from which the actual solution was taken. Meanwhile, Aickelin [36] applied a GA-based heuristic for non-unicost SCP which led to a high-quality solution. This heuristic was built based on three developed operators which included a new fitness-based crossover, a variable mutation rate, and a feasibility operator. Idrees and Al-Yaseen [37] implemented a classical GA for computationally difficult SCP. The proposed algorithm tests finally showed an optimal solution for incidence matrices. Aourid and Kaminska and Yang and Rajgopal [38, 39] have developed meta-heuristic algorithms of neural networks to deal with SCP. Aourid and Kaminska [38] proposed a neural network for a large-scale SCP. The network applied connections between nonlinear and integer programming based on concavity and penalty functions. The simulation finally indicated that the system coverage ability was within a few neural times. Applying neural networks, the study of [39] developed a machine learning approach to deal with SCP. This study provided a condition to learn from recorded optimal solutions taken from Machine Learning Problem (MLP) formulation. Vasko and Wolf [40] applied a two-step meta-heuristic algorithm of heuristic concentration (HC). In the first step, various local optimal solutions are proposed, and in the second step, these solutions are used to determine the centralized problem so that this problem is small enough to be solved.
The first mathematical model on the coverage problem was developed by [5] in which the location of emergency service facilities was investigated aiming to minimize the number of laid out facilities [41]. Hwang [42] studied the issue of complementary connecting arcs, which is one of the issues of complementary edge covering problem. This paper presented a new linear integer programming model for the problem. They also suggested a number of reduction rules that increase the speed of achieving the optimal answer. Rajagopalan et al. [43] presented a model for the distribution of relief goods aiming to satisfy the demand in the shortest possible time. Finally, the proposed model in that research was solved with exact and heuristic methods. The results showed that the heuristic method is able to provide high-quality answers compared to exact methods.
Amoaning-Yankson [44] developed a multi-objective programming model in which it provided the possibility of locating temporary warehouse cycles and allocating them to affected areas for the distribution of relief goods. The two main goals of his model were to minimize set-up and relocation costs between supply centers, temporary warehouses, and affected areas; as well as, to maximize the sum of minimum demand ratios covered to ensure fair distribution of goods. In this research, two meta-heuristic algorithms of GA and SA were presented to solve the model which finally, the computational results showed the efficiency of the developed model for practical issues. Mandal et al. [45] presented an efficient algorithm for conditional covering problems. They also proposed the design of algorithms with polynomial time for more complex graphs of structures such as distance graphs and serial and parallel diagrams for future research.
Wang and Qin [46] proposed a new multi-objective imperialist competitive algorithm to solve the stochastic multi-state model. The problem model was the coverage of the hub network, which according to the location of the risk, minimizes the current investment costs and the transportation time between each pair of nodes in the hub network. Murray and Wei [47] also proposed a solution to ensure complete coverage of the area with a minimum number of facilities that eliminates the potential error. Also, to demonstrate the efficiency of the proposed solution, the method mentioned in this study has been developed for the application of emergency alarm sirens and fire station locations. Meanwhile, Hosseininezhad et al. [48] presented a location model of continuous coverage with the risk factor. In this model, the coverage radius and the degree of customer satisfaction with the coverage are defined using the fuzzy concept. This study introduced a method of risk analysis based on the level of response to deal with the model.
Bagherinejad et al. [49] presented a new method for solving the coverage problem. The proposed algorithm for solving the coverage problem was efficient using a reversal method to produce each partial coverage without any non-partial iteration. Meanwhile, Furini et al. [50] proposed several models of the knapsack problem, including the cover problem in which entities must be allocated and the multidimensional knapsack in which the constraint replacement strategy was also used. The proposed model was validated and verified as competitive with former ones. Regarding the issue of coverage aiming to develop the current state of hybrid intelligent technology and meta-heuristic combination with Lagrangian relaxation, Al-Shihabi [51] proposed Greedy Randomized Adaptive Search Procedures (GRASP) and adaptive Lagrangian relaxation heuristic based on sub-gradient optimization to escape local optimization to find better answers. The results indicated that the proposed algorithm on benchmark instances from the literature had the effectiveness of their approach in producing better quality solutions.
Dastmardi et al. [52] emphasized the time of the problem, the seller's coverage, and the positioning of the problem. Meanwhile, they developed an integer linear programming model as a method of improvement and tried to improve the quality of the solution. Bagheri et al. [53] developed a traditional coverage problem model that can disrupt service delivery facilities in disruption situations such as floods and earthquakes. Then, they used the Bee Colony Optimization (BCO) algorithm to solve the proposed problem and validated the algorithm by comparing the results with exact algorithms for small problems. Additionally, Shi et al. [54] proposed a new method for selecting a landmark point within the neighborhood for the weighted coverage problem. As a result of his research, it was shown that the set covering problem can be solved applying the heuristic method based on Lagrangian relaxation with sub-gradient optimization. Meanwhile, Khorsi et al. [55] presented a multi-objective mathematical model to minimize the total time to reach the affected areas. The model was to maximize the satisfaction of the affected areas with higher priority and minimize costs including set-up costs, relocation, and shortages. In this research, to solve this multi-objective model, the Weighted Comprehensive Criterion Method (WCCM) had been applied to the single-purpose model.
Mahrach et al. [56] presented a multi-objective mathematical model that was able to generate all Pareto solutions to multi-objective combination optimization problems including two well-known multi-objective vendor and coverage problems. In another study, Bogue et al. [57] proposed a hybrid algorithm based on the neighborhood search variable and integer programming to solve the vehicle routing problem with a time window. In the proposed algorithm, a combination of a meta-heuristic and exact method was applied. Moreover, among the studies applying integer programming for SCP, the study [58] developed a novel integer programming formulation for the first time wherein the demands and facility locations align with the edges. In order to build acceptable solutions in a logical time, a heuristic algorithm was constructed to add vertices along the edges iteratively and solve a non-complex problem that dismisses non-nodal facility locations. Finally, numerical results indicated that the meta-heuristic algorithm generates good quality solutions in a very short time.
These studies were the most significant research conducted so far on the major model of the SCP. A special case of the original model, considering the same layout cost for all facilities, is also widely applied. Some researchers like [59] who proposed a Surrogate Heuristic (SH) for SCP have focused only on this issue. The conducted investigations of SCP have taken into account the issues with different dimensions which either examined the major model of SCP or a specific mode of the model that considers the layout cost of all facilities. These two modes of the model have the ability to determine the optimal points for the facilities’ layout disregarding the points where the facility is located.
The set covering problem has an exponential complexity and is one of the NP-hard problems [60]. Hence, it is almost impossible to find an optimal solution in polynomial time [61]. Basically, since any formulation (mathematical modeling) of real-world problems is to control the behavior of occurring phenomena, it is necessary to formulate the problems in such a way that different aspects of the problem appear in the model. Therefore, modeling real-world problems and encountering their large dimensions or problems with several objective functions, in the form of behavioral simulation of phenomena, can increase problem solving time. The time required to solve large problems is one of the criteria for evaluating the problem solving technique.
The reviewed studies indicated that the research in this area can be classified into three divisions. The first division encompasses studies dealing with SCPs applying either meta-heuristic or new meta-heuristic-based algorithms. The proposed algorithms of this division lack the efficiency of polynomial time solutions for SCPs. Next, the second division of studies covers very little research that proposes heuristic algorithms for non-complex SCPs. These non-complex SCPs include those problems which add vertices along the edges dismissing non-nodal facility locations. Finally, the third division includes studies that do not propose a reasonable approach to tackle the infeasibility of large problems. Hence, the current study aims to propose a heuristic algorithm to tackle: (1) the issue of studies including algorithms inefficiency to deal with polynomial time solutions; and (2) the issue of studies pertaining to the restrictions of SCPs taken into account in constructing heuristic algorithms. Thus, the current study presents a heuristic algorithm that is not only capable of constructing an answer within polynomial time but also can solve complex SCPs without non-nodal restrictions and infeasibility of large problems. To this end, the most relevant articles have been systematically summarized in Table 1.
3 Coverage Problem
The weighted set covering problem (WSCP) is to select a number of subsets to cover all the members in a total set at the lowest cost. It is a well-studied conventional problem with applications in fields like machine learning, planning, facility allocation, etc. If the cost of all facilities layout is equal, the objective function of the model is to minimize the number of those laid out facilities, which is called the minimum cardinality set covering problem (MCSCP) [1].
3.1 Assumptions, Parameters, and Decision Variables
The current study took discrete WSCP into account. This means that the demand points are considered discontinuous. In the discrete model, the problem is defined in the form of a network of customers as a node wherein it is possible at the same time to establish a facility on each, for which all facilities are considered the same. There are no restrictions on the provision of services by facilities to customers and each customer can be covered by several facilities at the same time. Hence, the parameters and decision variables of the study are as follow:
\(i\) the index of demand points.
\(j\) the index of layout points.
\(m\) number of demand points.
\(n\) number of layout points.
\(f_{j}\) layout cost at point j
\( a_{{ij}} = \left\{ {\begin{array}{ll} 1 & {{\text{If }}\,{\text{layout}}\,{\text{ point }}\,{\text{of }}\,j\,{\text{ can }}\,{\text{cover }}\,i} \\ 0 & {{\text{otherwise}}} \\ \end{array} } \right. \)
\( y_{j} = \left\{ {\begin{array}{ll} 1 & {{\text{If}}\,{\text{ any}}\,{\text{ layout}}\,{\text{ at }}\,{\text{point}}\,{\text{ }}j\,{\text{ happen}}} \\ 0 & {{\text{otherwise}}} \\ \end{array} } \right. \)
3.2 The Model of Study
Regarding mentioned explanation, the study goes to cover all points of demand with the least possible cost with a mathematical model as follows [2]:
The objective function (1) minimizes the total cost of facilities layout and the constraint (2) ensures that all points of demand will be covered. It should be noted that the left side of the constraint (2) indicates the number of facilities that can cover demand i. In other words, constraint (2) states that for each point of demand i, we need to lay out a device in at least one of the places that can cover that point of demand.
According to the model, the goal is to calculate the values of \(y_{j}\) in such a way that constraint (2) is met and the value of the objective function is minimized. The current study, applies 20 problems with different sizes which 18 are reproduced by authors and 2 selected of OR-library to assess the performance of the proposed algorithm. Dealing with issues, the study solves these problems by the proposed algorithm along with a meta-heuristic algorithm of SA to highlight the efficiency of the proposed algorithm. Hence, the functionality of the algorithms is briefly described and then the calculations are presented subsequently.
4 Simulated Annealing (SA) Algorithm
Simulated Annealing is an approach based on the Monte Carlo model applied to study the relationship between atomic clusters, entropy, and temperature during the annealing of a material. This algorithm simulates the cooling process of materials by gradually decreasing the temperature to a point of temperature equilibrium. This method moves towards the optimal solution step by step through creating and evaluating consecutive answers. To do so, a new neighborhood is randomly created and evaluated. It examines the points close to the given point in the search space. If the new point is better (reduces the cost function), it would be selected as the new point in the search space, and if it is worse (increases the cost function), it would be selected based on a probabilistic function. In other words, to minimize the cost function, the search is always conducted to reduce the value of the cost function; however, it is possible that sometimes the move is to increase the cost function. Usually, a criterion called the metropolis criterion is used to accept the next point as following Eq. 4 [64]:
\(P\) is the probability of accepting the next point, \(C\) is the A control parameter, \(\Delta f\) is the cost change.
The optimization algorithm of SA starts from a random initial solution for decision variables so that the new solution is randomly generated in the suitable neighborhood of the previous solution. Therefore, neighborhood production is one of the important issues in SA. To implement the thermal simulation algorithm, the basic factors including starting point, generator of motion, neighborhood generation, acceptance criterion and stop condition are needed [62, 63].
4.1 Representation of Answer Structure
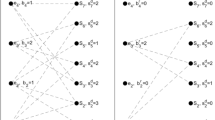
The answer structure expresses a point in the possible space of the problem, so the way it is represented in any heuristic approach is a matter of consideration. In SCP, an achievable answer should indicate whether the facility is laid out in any location. Therefore, the structure of the answer can be considered as a vector of zero and one, so that the presence of element one in the number i house indicates the layout of facility in place i. The notation i simply shows the number of nodes which based on fitness function value takes zero or one. This structure is shown in Fig. 1.

An instance of answer structure representation
According to Fig. 1, the nodes with higher fitness will take value 1 and the rest take 0. For example, if at the 1st iteration, the node (4) takes value 1, then due to the number of nodes covered by it (a), there will be a vector with i-a nodes at the next iteration. At the 2nd iteration, node (5) plays the same role, but it covers b number nodes. The iterations go on so that all nodes are covered which means all demand points are met. In fact, at the last iteration, node 6 covers the rest of nodes (c) which is equal to the difference between i and the existing nodes (i-a-b).
4.2 Tune of Parameters Applying Taguchi
The method of Taguchi experiment designs was first introduced in 1960 by Professor Taguchi [64]. This method can determine the optimal conditions with the least number of tests and significantly reduces the time and cost of performing the required tests. In the Taguchi method, according to the number of selected parameters and related surfaces, different orthogonal arrays are used as test matrices. In this method, changes are introduced with a factor called signal-to-noise ratio (S/N), and the experimental conditions with the highest signal-to-noise ratio are selected as the optimal conditions [64, 65]. Taguchi method has been used to adjust the factors of temperature decrement coefficient, iteration at each temperature, final temperature, initial temperature, and maximum iteration of the main loop.
Accordingly, 3 levels are defined for each factor as presented in Table 2. As a result, there are 27 scenarios for evaluating these factors, known as Taguchi tables. Since the purpose of the problem is to minimize the cost of allocating facilities to demand points, loss function and signal-to-noise (S/N) are calculated from Eqs. 5 and 6, respectively, and the final results are also submitted in Table 3. The desired values for tuning the parameters were calculated on a problem sample with 1000 nodes. In this study, S/N ratio with a smaller-the-better methodology was used for wear rate as follow:
where \(n\) and \(o_{i}\) are notating the number of experimental observation and experimental observations results, respectively.
Based on the general strategy for optimizing the levels of controlling parameters, the study evaluates the effects of controlling factors on the signal-to-noise (S/N) ratio and the mean (Fig. 2). It applies the appropriate factorial experimental design on the signal-to-noise ratio and the average of the desired feature. In this case, the experimental design method can be used.

The experimental design to compare levels of controlling parameters
For factors that have a significant effect on the signal-to-noise ratio (S/N), the levels that can maximize S/N are selected. Factors that do not have a significant effect on the signal-to-noise ratio (S/N) and have a significant effect on the mean, are considered as an adjusting factor and the levels are selected in a way that the mean is closer to the target. Factors that have neither an effect on the signal-to-noise ratio nor on mean are considered as economic factors and the levels are selected to improve performance.
The levels are now compared to determine which level should be used for each parameter; the results of which are determined using the diagrams in Fig. 2. The results in these graphs are obtained from the implementation of the Taguchi method in Matlab software to calculate S/N ratio in the case where the smaller is optimal. Accordingly, Alfa (\(\alpha\)) level 1 (0.999 in Table2) maximizes the S/N. Similarly, \(Tek\_Temp\) in Fig. 2 as iteration parameter at each temperature maximizes the S/N in its Level 1 (100 in Table2). Hence, these two parameters are tuned assigning values of 0.999 and 100, respectively. To tune initial temperature parameter \(T_{0}\), the value of Level 3, which is equal to 10, is assigned. As well as, the value of Level 1 (0.001 in Table 2) is assigned to tune final temperature parameter \(T_{f}\). Meanwhile, the value of level 1 (20,000 in Table2) is determined to tune \(Max\_iter\) as maximum iteration of the main loop.
4.3 The Simulated Annealing (SA) Flowchart
The general overview of how the SA algorithm works with the tuned parameters, using Taguchi method, is indicated in Fig. 3 and explained in the following section.

The tuned SA algorithm flowchart for the study problem
5 Proposed Algorithm
Unlike meta-heuristic algorithms that start from a random initial solution with a neighborhood construction mechanism in each step and calculate the value of the objective function for possible solutions and finally report the best answer, the current algorithm constructs directly an answer through the defined mechanism that logically tries to get the closest to the optimal state. In the existing meta-heuristic algorithms, during the defined iterations, the solution to the problem must be solved from \(2n\) possible modes by creating an initial solution and improving it during the solution process, while the proposed algorithm decides whether or not to establish a facility at one point (Node). In other words, the binary mode (one or zero) of each variable has a maximum of \(2n\) possibilities to check. This is the case in which the algorithm will encounter this number in the worst case. In other words, regarding that the number of steps to achieve the answer is equal to \(2n\), in some simultaneous steps, the certainty of determining the value of several variables is decided together, which in turn helps to improve the performance of this algorithm.
The above explanation refers to the polynomial growth of the proposed algorithm, which indicates desirability in this regard with respect to performance expectations. In cover problems where the coefficient of facility cost is equal for each variable in the objective function, it is obvious that the optimized answer is equal to the minimum number of possible facilities that meet all constraints requirements. By changing the coefficients in the objective function and assigning different values to them, it makes sense that the optimal answer of the minimum number of facilities will not be possible, and understanding the problem and finding the answer is no longer as simple as the previous circumstance.
In this case, there should be a balance between the two views of the objective function and the constraints. Hence, from the perspective of the objective function, it is more desirable to select variables whose coefficient value is lower in the objective function. On the other hand, from the point of view of constraints, it is more desirable to select variables that at the same time satisfy more constraints, which practically removes them from the analysis in the next steps, leading to sooner decision making. To make such a balance to select the best option for the layout, a mechanism is presented in the proposed algorithm in which a parameter attributed to the amount of improvement is calculated for each variable in each step; the steps for which the weight and importance of each variable in terms of desirability for the problem is calculated. Based on the above, the algorithm needs to be able to distinguish between two variables, one of which satisfies six constraints while the coefficient value in the objective function is 10 and the variable that satisfies five constraints while the coefficient in the objective function is 8. According to the applied logic, when the facility layout in location \(j\) can cover several other points at the same time, it practically exempts-from the layout of the new facility in those covered areas leading to exempting the equivalent of those in the objective function with coefficient value of \(f_{j}\); unless there are other points of demand which it is more cost-effective for us to cover, regarding the cost they have. Hence, there will be an exemption from the facilities layout in those places which will reduce the cost \(f_{j}\) subsequently. Thus, the fitness function \(b(y_{j} )\) can be defined as follow:
In Eq. (7), \(S_{j}\) is the indices set of variables covered by \(y_{j}\). As mentioned earlier, previously covered areas are exempt from layout; however, they will remain candidates for layout, as long as they do not cover anything other than the points covered. The algorithm works in such a way that in the first step, for all layout candidate points, the improvement parameter \(b(y_{j} )\) is calculated as a fitness function. Then the variable that has the maximum improvement is selected as the location of the facilitation in this step and takes the value of 1. In the next step, the fitness function values are updated; however, the coefficients of the variables previously covered by the facility are not included in \(\sum {f_{j} }\) to calculate the improvement values. In this step, if after the update, the covered variables by facilities do not cover anything other than the variables that are covered by this step; they take the value of zero. This process will be repeated until the decision on the layout of all variables is ended. In other words, the parameter \(b(y)\) indicates the fitness value of variable \(y\) for layout. As we know, with the layout of facilities at the desired point, three other variables (nodes) are also covered. As a result, it would be better not to have another facility layout in these three since at the same time the coverage of these areas is satisfied and there will be cost reduction by the coefficients of these three variables in the objective function. This cost reduction in the calculation of improvement is given as \(\sum {f_{j} }\). Meanwhile, due to the layout of facilities at the desired point, there will incur cost as the same as the value of its coefficient in the objective function and this cost will be also deducted in the calculation of improvement.
5.1 Algorithm Pseudo Code
According to the explanation, a set of variables whose value has not been assigned is initially formed, which in the first stage will be equal to the indices set of all variables. In the second step, sets consisting of the indices of variables covered by each of the variables in the first step are calculated. In the third step, the amount of improvement is calculated for the variables of the first step applying the fitness function. In the next step, the index of the variable that has the most improvement is determined. In the fifth step, the variable with the most improvement is assigned value 1, and to the variables covered by that variable with improvement value less than or equal to zero, the value of zero is assigned. Steps one to five will be repeated so that a value of 1 or 0 is assigned to all variables. In summary, the run steps of the proposed algorithm in the form of pseudo-code are as follow:

5.2 A Case Study Problem
To present the performance of the proposed algorithm, a case study problem will be solved step by step. For this purpose, the study assumes a set of variables \(\{ y_{1} ,y_{2} ,...,y_{7} \}\) with a coverage radius of \(D_{c}\) as follow:
Conceding in the first step, \(y_{1}\) assigns the value 1 to itself. In the second step, the improvement for the remaining variables is calculated based on the following order:
The values \(S_{j}\) are equal to the sum of the coefficients in the objective function of the variables that are covered and are not calculated in the improvement. For variables \(y_{3}\) and \(y_{2}\), since they are already covered by \(y_{1}\), their value is zero, unless they have an improvement at this stage, which is not the case in this example, and the decision will be made to assign zero to them. Variable \(y_{4}\) is examined as \(y_{3}\) and \(y_{1}\). Variable \(y_{4}\) takes the value of 1 whether it has a less-equal cost or even more than \(y_{7}\), \(y_{6}\) and \(y_{5}\) if it has a positive improvement.
Applying the same reasoning, for variables \(y_{6}\) and \(y_{5}\), since they are already covered by \(y_{4}\), their value is considered zero. Meanwhile, the variable \(y_{7}\) takes the value of 1 without a competitor.
5.3 The Proposed Algorithm Flowchart
To clarify how the proposed algorithm works, a general overview is represented in the following flowchart in Fig. 4.

The flowchart of the proposed algorithm
6 Computational Results
To evaluate the proposed algorithm performance, the report of MATLAB code of this algorithm is presented within 20 different sizes. Then, a comparison between this algorithm results and SA is conducted. In this comparison, the best results of the proposed algorithm are reported, as listed in Tables 4, 5, and 6.
The main issue taken into account in this study is to deal with full coverage of 1000 variables (\(y_{j}\)) and 200 applicable constraints that assure the coverage of all 1000 demand points. The coefficients of this problem are available in an online and pre-determined form on the website of OR-library, which is a set of coefficients of layout cost and indices number of variables presented over the sub-categories of the SCP like SCP41 and SCP51 and so on. Other issues used in this study have been randomly designed and tested. First, a small-scale problem is solved to understand the solution process of the proposed algorithm and compare it with the exact answer obtained from the Gams software. In this regard, the small-scale problem is considered according to Fig. 5 where the coverage distance is equal to 6 and its cost function is as follows:

A small-scale problem of set covering problem with 8 nodes and 11 connecting arcs
To solve the problem applying the proposed algorithm, at the first step regarding the improvement value of fitness function for each variable there will be:
In this step, value 1 is assigned to variable \(y_{5}\) and the improvement values of the fitness function are updated. As a result, the improvement values for the second step will be as follow:
At this stage, a value of 1 is assigned to variable \({\text{y}}_{j}\) and the algorithm ends by covering all points of demand. Finally, the value of the objective function for this problem will be equal to Z = 2 + 4 = 6 according to the proposed algorithm. Following the verification of the algorithm, the answer values for this problem are obtained from the exact solution methods in the Gams software, equal to 6, which confirms the good and acceptable performance of the proposed algorithm.
The strength of the algorithm is determined in high-dimensional problems, which is emphasized in Table 4. Due to this issue, in small-scale problems, the importance of the algorithm in terms of time is not understood; rather, it is a problem on a large scale that this heuristic algorithm can be applied for a very convenient time with desired quality of the answer.
To better compare the performance of the solution methods used for different problems in Table 4, the cost reduction percentage of the objective function by the proposed algorithm to cost reduction of the objective function using the SA algorithm is calculated and plotted in Fig. 6 for different problems. As can be seen in Fig. 6, the proposed algorithm in most cases has a better answer than the SA algorithm.

Reduction percentage of the objective function value by the proposed algorithm relative to SA
Thus, it can be said that according to Tables 4, 5 and 6 and Fig. 6, the proposed algorithm has a better answer quality compared to algorithm SA, wherein parameters are tuned by the Taguchi method. Meanwhile, the strength of the proposed algorithm is in high-dimensional problems with a number of polynomial iterations (NP-hard problems). Since the best answer obtained from algorithm SA is given after 10 times due to its random nature, the solution time of the algorithm will be 10 times the current value, which has been ignored for the pessimistic review of the algorithm. In other words, the best answer of the algorithm is given after running 10 times, while the time of algorithm’s first run is reported. Therefore, it can be concluded that in terms of quality, the proposed heuristic algorithm clearly performs better than algorithm SA and is competitive in terms of time.
7 Conclusion
In this study, a new heuristic algorithm for the set covering problems based on coefficient and fitness values was presented due to the complexity of the problems. However, heuristic algorithms are more likely to succeed in such cases where they start from a certain point. There is a characteristic of the presented algorithm which contributes to its superior performance. The proposed algorithm applies a mechanism that improves the set covering solution through a particular fitness function. In other words, it evaluates the qualification of subsets by directly applying a fitness function. This fitness function is formulated based on sets and subsets coefficients in a way that the subsets of selected sets have the lowest probability to be selected in the next iteration.
In addition, due to the exponential complexity of the coverage problem, the optimal solution cannot be achieved in a logical time. To solve the problems presented in this study via applying the exact method, the resource limitation error was observed. Hence, the study suffices to present a comparison of the results obtained from meta-heuristic methods for large problems. The experimental results indicated that the proposed algorithm has a relative improvement compared to other methods including SA algorithm wherein parameters were tuned using the Taguchi method. In other words, the proposed algorithm submits better results in terms of quality than the SA algorithm and in terms of time, the algorithm is quite competitive.
For future studies, it is suggested to develop the proposed algorithm for other problems, including stochastic problems. It is also recommended to use this method and its generalization for other NP-hard problems to examine whether this algorithm can be combined with other algorithms leading to a more efficient way to deal with SCP.
References
Wang, K.J., Lestari, Y.D., Tran, V.N.B.: Location selection of high-tech manufacturing firms by a fuzzy analytic network process: a case study of Taiwan high-tech industry. Int. J. Fuzzy Syst. 19(5), 1560–1584 (2017)
Farahani, R.Z., Hekmatfar, M.: Facility Location: Concepts, Models, Algorithms and Case Studies. Springer, Berlin (2009)
Beasley, J.E., Jörnsten, K.: Enhancing an algorithm for set covering problems. Eur. J. Oper. Res. 58(2), 293–300 (1992)
Liu, Z., Xu, H., Liu, P., Li, L., Zhao, X.: Interval-valued intuitionistic uncertain linguistic multi-attribute decision-making method for plant location selection with partitioned hamy mean. Int. J. Fuzzy Syst. 22(6), 1993–2010 (2020)
Solar, M., Parada, V., Urrutia, R.: A parallel genetic algorithm to solve the set-covering problem. Comput. Oper. Res. 29(9), 1221–1235 (2002)
Bahrami, I., Ahari, R.M., Asadpour, M.: A maximal covering facility location model for emergency services within an M (t)/M/m/m queuing system. J. Model. Manag. 16(3), 963–986 (2021)
Li, R., Hu, S., Cai, S., Gao, J., Wang, Y., Yin, M.: NuMWVC: a novel local search for minimum weighted vertex cover problem. J. Oper. Res. Soc. 71(9), 1498–1509 (2020)
Jain, A.K., Khare, V.K., Mishra, P.M.: Facility planning and associated problems: a survey. Innov. Syst. Des. Eng. 4(6), 1–8 (2013)
Berman, O., Kalcsics, J., Krass, D.: On covering location problems on networks with edge demand. Comput. Oper. Res. 74, 214–227 (2016)
Xiang, X., Qiu, J., Xiao, J., Zhang, X.: Demand coverage diversity based ant colony optimization for dynamic vehicle routing problems. Eng. Appl. Artif. Intell. 91, 103582 (2020)
Klose, A., Drexl, A.: Facility location models for distribution system design. Eur. J. Oper. Res. 162(1), 4–29 (2005)
Lee, S.D., Chang, W.T.: On solving the discrete location problems when the facilities are prone to failure. Appl. Math. Model. 31(5), 817–831 (2007)
Caballero, R., González, M., Guerrero, F.M., Molina, J., Paralera, C.: Solving a multi-objective location routing problem with a metaheuristic based on tabu search. Application to a real case in Andalusia. Eur. J. Oper. Res. 177(3), 1751–1763 (2007)
Alumur, S., Kara, B.Y.: A new model for the hazardous waste location-routing problem. Comput. Oper. Res. 34(5), 1406–1423 (2007)
Berge, C.: Two theorems in graph theory. Proc. Natl. Acad. Sci. USA 43(9), 842–844 (1957)
Gholami, H., Saman, M.Z.M., Sharif, S., Md Khudzari, J., Zakuan, N., Streimikiene, D., Streimikis, J.: A general framework for sustainability assessment of sheet metalworking processes. Sustainability. 12(12), 4957 (2020)
Toregas, C., Swain, R., ReVelle, C., Bergman, L.: The location of emergency service facilities. Oper. Res. 19(6), 1363–1373 (1971)
Crawford, B., Soto, R., Olivares, R., Embry, G., Flores, D., Palma, W., Castro, C., Paredes, F., Rubio, J.M.: A binary monkey search algorithm variation for solving the set covering problem. Nat. Comput. 19(4), 825–841 (2020)
Hashemi, A., Hadavand, S., Esrafilian, R.: An extended mathematical model for multi-floor facility layout problems. Spec. J. Eng. Appl. Sci. 4(1), 69–74 (2019)
Lanza-Gutierrez, J.M., Caballe, N.C., Crawford, B., Soto, R., Gomez-Pulido, J.A., Paredes, F.: Exploring further advantages in an alternative formulation for the set covering problem. Math. Probl. Eng. (2020). https://doi.org/10.1155/2020/5473501
Balas, E., Carrera, M.C.: A dynamic subgradient-based branch-and-bound procedure for set covering. Locat. Sci. 3(5), 203 (1997)
Beasley, J.E.: An algorithm for set covering problem. Eur. J. Oper. Res. 31(1), 85–93 (1987)
Fisher, M.L., Kedia, P.: Optimal solution of set covering/partitioning problems using dual heuristics. Manag. Sci. 36(6), 674–688 (1990)
Jamil, N., Gholami, H., Saman, M.Z.M., Streimikiene, D., Sharif, S., Zakuan, N.: DMAIC-based approach to sustainable value stream mapping: towards a sustainable manufacturing system. Econ. Res.-Ekonomska Istraživanja. 33(1), 331–360 (2020)
Reyes, V., Araya, I.: A GRASP-based scheme for the set covering problem. Oper. Res. (2019). https://doi.org/10.1007/s12351-019-00514-z
Chvatal, V.: A greedy heuristic for the set-covering problem. Math. Oper. Res. 4(3), 233–235 (1979)
Salehipour, A.: A heuristic algorithm for the set k-cover problem. In: International Conference on Optimization and Learning, pp. 98–112. Springer, Cham (2020)
Nogueira, B., Tavares, E., Maciel, P.: Iterated local search with tabu search for the weighted vertex coloring problem. Comput. Oper. Res. 125, 105087 (2021)
Hashemi, A., Esrafilian, R., Hadavand, S., Zeraatkar, M.: Application of fuzzy TOPSIS for evaluation of green supply chain management practices (case study: Zanjan Sepehr Khodro; Iran). Int. J. Eng. Technol. 11(6), 13–24 (2020)
Chiscop, I., Nauta, J., Veerman, B., Phillipson, F.: A hybrid solution method for the multi-service location set covering problem. In: International Conference on Computational Science, pp. 531–545. Springer, Cham (2020)
Wang, Y., Pan, S., Al-Shihabi, S., Zhou, J., Yang, N., Yin, M.: An improved configuration checking-based algorithm for the unicost set covering problem. Eur. J. Oper. Res. 294(2), 476–491 (2021)
Sadeghi, J., Niaki, S.T.A., Malekian, M.R., Wang, Y.: A lagrangian relaxation for a fuzzy random epq problem with shortages and redundancy allocation: two tuned meta-heuristics. Int. J. Fuzzy Syst. 20(2), 515–533 (2018)
Mandal, S., Patra, N., Pal, M.: Covering problem on fuzzy graphs and its application in disaster management system. Soft. Comput. 25(4), 2545–2557 (2021)
Alizadeh, R., Nishi, T.: Hybrid set covering and dynamic modular covering location problem: application to an emergency humanitarian logistics problem. Appl. Sci. 10(20), 7110 (2020)
Lorena, L.A., de Souza Lopes, L.: Genetic algorithms applied to computationally difficult set covering problems. J. Oper. Res. Soc. 48(4), 440–445 (1997)
Aickelin, U.: An indirect genetic algorithm for set covering problems. J. Oper. Res. Soc. 53(10), 1118–1126 (2002)
Idrees, A.K., Al-Yaseen, W.L.: Distributed genetic algorithm for lifetime coverage optimisation in wireless sensor networks. Int. J. Adv. Intell. Paradig. 18(1), 3–24 (2021)
Aourid, M., Kaminska, B.: Neural networks for the set covering problem: an application to the test vector compaction. In: Proceedings of 1994 IEEE International Conference on Neural Networks (ICNN'94), vol. 7, pp. 4645–4649. IEEE (1994)
Yang, Y., Rajgopal, J.: Learning Combined Set Covering and Traveling Salesman Problem. http://arxiv.org/abs/arXiv:2007.03203 (2020).
Vasko, F.J., Wolf, F.E.: A heuristic concentration approach for weighted set covering problems. Locator: ePubl. Locat. Anal. 2(1), 1–14 (2001)
Erkut, E., Alp, O.: Designing a road network for hazardous materials shipments. Comput. Oper. Res. 34(5), 1389–1405 (2007)
Hwang, H.S.: A stochastic set-covering location model for both ameliorating and deteriorating items. Comput. Ind. Eng. 46(2), 313–319 (2004)
Rajagopalan, H.K., Saydam, C., Xiao, J.: A multiperiod set covering location model for dynamic redeployment of ambulances. Comput. Oper. Res. 35(3), 814–826 (2008)
Amoaning-Yankson, S.: A conceptual framework for developing sociotechnical transportation system resilience. PhD diss., Georgia Institute of Technology (2017)
Mandal, S., Patra, N., Pal, M.: Covering problem on fuzzy graphs and its application in disaster management system. Soft Comput. 25(4), 2545–2557 (2020)
Wang, J., Qin, Z.: Chance constrained programming models for uncertain hub covering location problems. Soft. Comput. 24(4), 2781–2791 (2020)
Murray, A.T., Wei, R.: A computational approach for eliminating error in the solution of the location set covering problem. Eur. J. Oper. Res. 224, 52–64 (2013)
Hosseininezhad, S.J., Jabalameli, M.S., Pesaran Haji Abbas, M.: A cross entropy algorithm for continuous covering location problem. J. Ind. Syst. Eng. 11(3), 247–260 (2018)
Bagherinejad, J., Seifbarghy, M., Shoeib, M.: Developing dynamic maximal covering location problem considering capacitated facilities and solving it using hill climbing and genetic algorithm. Eng. Rev.: Međunarodni časopis namijenjen publiciranju originalnih istraživanja s aspekta analize konstrukcija, materijala i novih tehnologija u području strojarstva, brodogradnje, temeljnih tehničkih znanosti, elektrotehnike, računarstva i građevinarstva. 37(2), 178–193 (2017)
Furini, F., Ljubić, I., Sinnl, M.: An effective dynamic programming algorithm for the minimum-cost maximal knapsack packing problem. Eur. J. Oper. Res. 262(2), 438–448 (2017)
Al-Shihabi, S.: A hybrid of max–min ant system and linear programming for the k-covering problem. Comput. Oper. Res. 76, 1–11 (2016)
Dastmardi, M., Mohammadi, M., Naderi, B.: Maximal covering salesman problems with average travelling cost constrains. Int. J. Math. Oper. Res. 17(2), 153–169 (2020)
Bagheri, H., Babaei Morad, S.B.M., Behnamian, J.: Fuzzy multi-period mathematical programming model for maximal covering location problem. J. Ind. Syst. Eng. 11(1), 223–243 (2018)
Shi, H., Yin, B., Zhang, X., Kang, Y., Lei, Y.: A landmark selection method for L-Isomap based on greedy algorithm and its application. In: 2015 54th IEEE Conference on Decision and Control (CDC), pp. 7371–7376. IEEE (2015)
Khorsi, M., Chaharsooghi, S.K., Bozorgi-Amiri, A., Kashan, A.H.: A multi-objective multi-period model for humanitarian relief logistics with split delivery and multiple uses of vehicles. J. Syst. Sci. Syst. Eng. 29, 360–378 (2020)
Mahrach, M., Miranda, G., León, C., Segredo, E.: Comparison between single and multi-objective evolutionary algorithms to solve the knapsack problem and the travelling salesman problem. Mathematics (2018). https://doi.org/10.3390/math8112018
Bogue, E.T., Ferreira, H.S., Noronha, T.F., Prins, C.: A column generation and a post optimization VNS heuristic for the vehicle routing problem with multiple time windows. Optim. Lett. (2020). https://doi.org/10.1007/s11590-019-01530-w
Alamatsaz, K., Jolfaei, A., Iranpoor, M.: Edge covering with continuous location along the network. Int. J. Ind. Eng. Comput. 11(4), 627–642 (2020)
Kaur, C., Misra, N.: On the parameterized complexity of spanning trees with small vertex covers. In: Conference on Algorithms and Discrete Applied Mathematics, pp. 427–438. Springer, Cham (2020)
Klostermeyer, W.F., Messinger, M.E., Yeo, A.: Dominating vertex covers: the vertex-edge domination problem. Discussiones Mathematicae: Graph Theory 41(1), 123–132 (2021)
Fiorini, S., Joret, G., Schaudt, O.: Improved approximation algorithms for hitting 3-vertex paths. Math. Program 182(1), 355–367 (2020)
Redi, A.A.N.P., Maula, F.R., Kumari, F., Syaveyenda, N.U., Ruswandi, N., Khasanah, A.U., Kurniawan, A.C.: Simulated annealing algorithm for solving the capacitated vehicle routing problem: a case study of pharmaceutical distribution. Jurnal Sistem dan Manajemen Industri. 4(1), 41–49 (2020)
Kaur, M., Saini, S.: A review of metaheuristic techniques for solving university course timetabling problem. In: Goar V., Kuri M., Kumar R., Senjyu T. (eds) Advances in Information Communication Technology and Computing. Lecture Notes in Networks and Systems, vol. 135. Springer, Singapore (2021). https://doi.org/10.1007/978-981-15-5421-6_3
Mori, T.: The New Experimental Design: Taguchi’s Approach to Quality Engineering. ASI Press, Dearborn (1990)
Park, S.H.: Robust Design and Analysis for Quality Engineering, 1st edn. Chapman & Hall, London (1996)
Acknowledgements
The authors would like to thank the Research Management Centre at Universiti Teknologi Malaysia and the Ministry of Higher Education (Malaysia) for supporting and funding the Postdoctoral Fellowship scheme (PDRU Grant), Vot No. Q.J130000.21A2.05E33.
Author information
Authors and Affiliations
Corresponding authors
Rights and permissions
About this article

Cite this article
Hashemi, A., Gholami, H., Venkatadri, U. et al. A New Direct Coefficient-Based Heuristic Algorithm for Set Covering Problems. Int. J. Fuzzy Syst. 24, 1131–1147 (2022). https://doi.org/10.1007/s40815-021-01208-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40815-021-01208-5