
Abstract
The effect of climate change on human life has led the scientific community to observe the behaviour of meteorological and climatic variables on various spatial and temporal scales. However, analysing precipitation trends is important for studying the impact of climate change on water resource planning and management. This study examines changes in rainfall data at-site location in Duhok city, Kurdistan Region, Iraq using rainfall data for 42 years covering the period of 1976–2017. The quality control test was performed for rainfall data series using Mandel’s k method. The non-parametric tests (Mann–Kendall and Modified Mann–Kendall) with the Innovative Trend Analysis method have been used to assess the change in monthly, seasonal, and annual rainfall series. Also, the homogeneity in rainfall data series has been investigated using Van Bell and Hughes homogeneity, Runs, Pettit, Standard Normal Homogeneity, Buishand Range, and Von Neumann Rate tests. The results of Mandel’s k method showed that no outlier was detected in the study area. The trend test results revealed an increasing trend in some rainfall data series and a decreasing trend in some other data series in the study area. The maximum increasing significant trend has been observed in January and Winter series at a 5% significance level. In addition, the set cases of monthly and seasonal data series were found to be nonhomogeneous, while according to each separate case of time series, it has been found that the most of data series appears to be homogeneous.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
In recent years, the effects of climate change and its effects have become increasingly prominent around the world, resulting in climate hazards, such as severe storms, floods, forest fires, heatwaves, droughts, and strong winds (Chibuike et al. 2014; Hajani and Rahman 2017; Hajani 2020). Unfortunately, the potential for extreme increases in rainfall intensity often leads to climatic and environmental hazards, increasing the risk of flooding in most parts of the world (Joshua and Ekwe 2013). To reduce the risk of climate change, it is necessary to understand the impact of climate change on the rainfall data of flood control measures (IPCC 2014). The relationship between rainfall and flood runoff probability is important from both practical and theoretical perspectives (Breinl et al. 2021). Floods usually occur when it rains for several days, when it rains for a short period, or when rivers and streams flood the area due to the accumulation of ice and debris (Packman and Kidd 1980). The most common cause of floods is stormwater. Stormwater collects faster than the soil absorbs, or the river carries it away (Pilgrim and Cordery 1975). About 75% of all presidential disaster statements are related to floods. The extreme rainfall distribution depends on the climatological conditions of each interesting location (Barbero et al. 2019).
According to the IPCC report, the frequency and depth of rainfall events will increase worldwide (IPCC 2014). In this regard, the assessment of changes in rainfall data series by applying various statistical tests is very important and has been studied by many researchers around the world (Yue et al. 2003; Chowdhury and Al-Zahrani 2013; Gao et al. 2016; Ongoma and Chen 2017; Hajani et al. 2017; Hajani and Rahman 2018; Nashwan et al. 2019; Tarekegn et al. 2021). For example, Mamoon and Rahman (2017) investigated the trends from 29 rainfall stations covering the period of 1962–2010 in Qatar. Two nonparametric trend tests [i.e. Mann–Kendall (MK) and Spearman’s Rho (SR) tests] were adopted to identify trends in the rainfall data series. Both increasing and decreasing were observed for most of the rainfall series. In another study, Nashwan et al. (2019) used seasonal and annual rainfall data over Egypt and the Nile river basin to estimate the statistical significance of trends throughout 1948–2010. The MK and Modified MK tests were used to find trends in rainfall data series. The results showed a significant difference between the trends obtained with both the modified MK test and the MK test. Meena (2020) detected a trend in rainfall in the Udaipur district of Rajasthan state, India between 1957 and 2016. The Modified MK test and Sen’s slope were used at a 5% significance level. The results showed that rainfall in the study area tended to increase over the study period.
Several studies in neighboring countries (e.g., Iran, Turkey, and Syria) have been conducted on the trend of rainfall on various time scales to evaluate the impacts of climatic changes. For example, Modarres and Sarhadi (2009) assessed trends in the total annual rainfall and 24-h maximum rainfall intensity data for the period of 1951–2000 at 145 rainfall stations in Iran. The MK test was used to assess trends in rainfall data. The study shows that the decreasing trends of annual rainfall are mostly observed in northern and north-western regions of Iran, while the increasing trends of 24-h maximum rainfall are mostly located in arid and semi-arid regions of Iran. In addition, Güçlü (2018) evaluated trends in annual rainfall data at 24 stations from 1931 to 2010 in different regions of Turkey. In this study, partial MK test and innovative trend analysis (ITA) method were adopted. It was found that about two-thirds of the stations in the study area showed an increasing trend. Furthermore, Güçlü (2020) used 50-year rainfall records in the Mediterranean, the Black Sea, and Continental climate regions in Turkey. It has been observed that Mediterranean stations are showing a complete upward trend. On the other hand, the stations in the Black Sea area are decreasing at low and high values, and the stations in the continental climate area are increasing.
The climate of the Kurdistan region has been identified according to the Koppen classification as a semi-arid climate. In this region, a comprehensive understanding of the rainfall pattern is greatly needed as it will significantly affect the balance among these natural features. Unfortunately, only very few studies have evaluated changes in rainfall data in the Kurdistan region. For example, Al Salihi et al. (2014) adopted the MK test to determine trends in rainfall data over 30 years from 36 stations in different parts of Iraq. The results show that rainfall levels in Iraq are declining on various time and spatial scales, especially in northern Iraq (i.e., the Kurdistan Region). It was also found that from 1989 to 1999, most of the changes were in the northern region. In another study, AL-Lami et al. (2014) investigated the homogeneity of 36 rainfall stations throughout Iraq between 1981 and 2010. The Pettit, Standard Normal Homogeneity, Buishand Range, and Von Neumann Rate tests were adopted at a significance level of 0.05. Based on the monthly and annual data series, the results of the above four homogeneity tests showed that most of the data series from 36 stations were found to be homogeneous. In addition, Agha et al. (2017) used the similar four homogeneity tests of AL-Lami et al. (2014) and investigated the homogeneity of 9 rainfall stations throughout northern Iraq. Based on the seasonal and annual series, the results show that most of the data series were found to be homogeneous.
Rainfall studies are very helpful in understanding the nature of climate change and, therefore, behaviour and impact. Rainfall time series is a series of rainfall observations recorded at specific times, usually at regular intervals. Therefore, time-dependent data sets are called time series (e.g., monthly, seasonal, and annual time series). In general, time series analysis is useful for comparing actual performance and analyzing the causes of variation (Maragatham 2012). In addition, Sen (2012) introduced an ITA method implemented on water resources. Many researchers used the ITA method to analyze time-series data along with the MK method. For example, monthly rainfall trends in different parts of the world were analyzed using the ITA method (Wang et al. 2020). Thus, the ITA method is widespread and is an applicable method compared to the MK method (Alashan 2020). No study has been done so far over any area in the Kurdistan Region using the Modified MK test and ITA method to analyze the trends of rainfall data, especially on monthly, seasonal, and annual rainfall variability. In this regard, the purpose of this study is devoted to examining the trends in rainfall time series at site locations in the Kurdistan region, Iraq for the period 1976–2017. Besides, this study is with five specific objectives: (1) to detect the outlier of rainfall data series to check the quality control of the rainfall data series. (2) to examine trends in rainfall data series in detail using the ITA method and comparing its results with the MK and modified MK tests.; (3) to quantify the significance of changes after removing the effects of serial correlation on the results of trend analysis from the time series; (4) to detect the occurrence of abrupt changes in rainfall; and (5) to explore homogeneity in rainfall time series. The results of the present study will help the researchers to understand the characteristics of rainfall data in Duhok city, also, it will be a reference for future studies on the water resources, hydrological processes, and climate change fields in Duhok city, Kurdistan region, north Iraq.
Study area and data
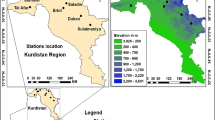
The study area of the current study is Duhok city in the Kurdistan Region, Iraq. Duhok city is the capital city of Duhok prefecture (governorate) and it is one of the main cities in the Kurdistan Region. The study area extends approximately between latitudes 36° 50′ 00″ and 36° 54′ 40″ N, and longitudes 42° 52′ 00″ and 43° 04′ 44″ E in the north–west of Iraq, as shown in Fig. 1, at 430–450 m above the sea level and it covers about 107 km2, near the Syrian–Turkish border (Othman 2008). Duhok city is located in a flat area between the two mountain ranges of Bekhair in the north and northeast and Zawa in the southeast (Othman 2008; Mustafa et al. 2012). A flat area with a tourist environment was seen on the west side (Duhok Province 2015).

Location of the selected Duhok station in Duhok city, Kurdistan Region, Iraq
Depending upon temperature variation in a whole year, there are four seasons, namely, Summer—June, July, and August (JJA); Autumn—September, October, and November (SON); Winter—December, January, and February (DJF); and Spring—March, April and May (MAM). It rains and is cold in winter, with temperatures ranging from 2 to 16 °C. While summers are dry and hot, with temperatures above 43 °C during July and August (WCG 2019). Rainfall is very seasonal, occurring in the winters of October–April (Othman 2008; AL-Lami et al. 2014). The average annual rainfall ranges from 236.5 to 909.7 mm, indicating a very seasonal runoff regime with runoff peaking mainly in early spring (April) due to snowmelt (Abbasa et al. 2016). In the current study, the historical monthly rainfall data series of 43 years (1976–2017) at site location (i.e., Duhok station) were used (Fig. 1). The time series analysis of rainfall data was done on a monthly, seasonally, and yearly basis. Monthly rainfall data series is obtained by adding up daily data every month. The monthly rainfall data of this station had less than 5% gaps. The gaps in the rainfall data of a particular station were filled by regression analysis. Historical records of monthly rainfall data series have been provided from the Directorate of Duhok Dam in the Kurdistan Region.
Methods
In this study, different statistical methods were applied to the rainfall data series. A brief description of each of these statistical techniques used in this paper is presented below.
Moving average method
A moving average is a time series formed by averaging several consecutive values from another time series. It's a kind of mathematical convolution (Hyndman 2011). If we represent the original time-series by X1, …, Xn, then a moving average of the time series is written as
That is, the trend-cycle estimate at time t is obtained by averaging the time series values within the k period of t. Observations that are close in time may have similar values.
Quality control of the rainfall data series
The quality control method used was the outlier detection for rainfall data series using Mandel’s k method (Wilrich 2013; Jaafar and Al-Lami 2019). The k statistic detects differences between variances. The Mandel’s k statistic (Mandel 1985, 1991) can be found by
where \({S}_{j}\) is a series of (p) sample variances, each being based on observed value (n). To identify the amount of variance that is probably not normal, the statistic h can be used to calculate critical values and confidence violations for a particular level of importance (Wilrich 2013). The formula for the critical value is given by the following formula:
where \(F_{v1,v2;\alpha }\) the quantity (α) of the distribution (F) for the freedom degrees (v1 and v2).
Mann–Kendall (MK) test
The MK trend test (Mann 1945; Kendall 1975) is based on the correlation between time series ranks and sequences. For a given time series {Xi, i = 1, 2, 3, …, n}, the null hypothesis (H0) assumes it is assumed to be independently distributed (no trend), and the alternative hypothesis (H1) suppose it is a monotonous tendency. The MK test statistic calculated as follows:
where X is a univariate time-series, i and j are the time indices associated with individual values, n is the number of data points and the sgn is determined as follows:
As documented in Mann (1945) and Kendall (1975), the statistic S under the null hypothesis is approximately normally distributed for n ≥ 8 with mean and variance as follows:
where t represents tie and q represents the number of tied groups. The standardised test statistic (Z) can be specified by the following equation:
The null hypothesis is rejected at a significance level (α) if \(\left| {Z_{s} } \right| > Z_{{{\text{crit}}}}\), where \(Z_{{{\text{crit}}}}\) is the value of the standard normal distribution with an exceedance probability of α/2, where α is the statistical significance level concerned. In this study levels of significance at 10%, 5%, 1%, were adopted.
Modified Mann–Kendall test
A modified MK test was adopted to reduce the effect of serial correlation on the trend results of the MK test. The median slope (Ti) of the trends was estimated using the Sen Approach (Steven-Brauner 1997) as recommended by Hamed and Rao (1998) and Yue and Wang (2004), the data series are de-trended by Eq. 10. The amended variance of the MK test statistic is obtained from the following equation:
The degree of tendency is predicted by Sen’s estimator (Sen 1968). Here, the slope (Ti) of all data pairs is computed as median slope Ti of the identified trend, i.e., the Sen’s estimator of the slope is the median of these N values of Xi data series (Steven-Brauner 1997), and the Sen`s estimator is given by
The \({\text{Var}}\left( S \right)\) is the variance of the MK test statistic based on the original data. The modified standardized MK test statistic by Hamed and Rao (1998) can be written as
The correction factor (CF) introduced by Hamed and Rao (1998) is given by
where n is the actual number of observations. The slope of the trends was estimated using the Sen Approach (Eq. 12) as recommended by Hamed and Rao (1998) and Yue et al. (2002), among many others. \(r_{k}\) is calculated by replacing the sample data \(X_{i}\) by the respective ranks \(X_{i}\) in the below equation (Salas et al. 1980):
In addition, the continuous independence hypothesis is tested by the lag-1 autocorrelation coefficient as H0: r1 = 0 against H1: |r1|> 0. The t test statistic has a t-distribution with (n − 2) degrees of freedom (Cunderlik and Burn 2004). In the case of |t|≥ tα/2, the null hypothesis of continuous independence at the significance level α is rejected.
Innovative trend analysis (ITA) method
In the ITA method, the data series were divided into two equal sub-series from the first time series to the end-time series, and both parts (i.e. sub-series) were separately sorted in ascending order. Then, depending on the method of the 2D Cartesian coordinate system, the first part was plotted on the horizontal axis (X-axis) and the second part was plotted on the vertical axis (Y-axis). If the data points in the scatter plot were on the 1:1 (i.e. 45°) line, it indicates that the data have no trend. If the data points accumulate below the 1:1 line, it indicates that there is a negative (i.e. a decreasing) trend present in the data series. If the data points are above the 1: 1 line, this indicates a positive (i.e., increasing) trend in the data series (Sen 2012). In addition, this study used two confidence intervals (± 10%) to help readers better understand the difference between rainfall datapoints and trendless lines without statistical effects (Alifujiang et al. 2020).
Pettitt change point test
The Pettitt change point test is a nonparametric approach developed by Pettitt (1979) to detect change points in time series data. This test can detect when time (t) may have occurred in the time series data. The null hypothesis of this test is that there is no shift in the time series at the time (t), and the alternative hypothesis is that there is a change point at a time (t). The test statistic is calculated as follows:
where Xi and Xj are the magnitudes of the rainfall data series at the time i and j, respectively, and Xi precedes Xj in time. To evaluate the test over the entire study period (T) these D statistics are summarized as follows:
If the two samples X1, …, Xt and Xt + 1, …, XT are from the same population, the statistics Ut,T are considered. The test statistic Ut,T, is evaluated for all possible values of t in the range 1 to T. Identify the point in time t (year) when a sudden shift occurs in the time series. The following statistic is used:
If the KT is significantly different from zero, a change point will occur in t years. This corresponds to the time when the absolute values of Ut,T are obtained. This is done by a hypothesis test based on the resampling method.
Testing the homogeneity of trends
In the current study, six homogeneity tests (Van Bell and Hughes, Runs, Pettit, SNH, BR, and VNR tests) have been adopted on the rainfall data series. It is worth mentioning that none of these six homogeneity tests have been previously applied to Duhok station from 1976 to 2017 and on rainfall data series separately. The details of each of these six tests have been explained below:
Van Belle and Hughes (Chi-square) test is a nonparametric approach that was developed by Van Belle and Hughes (1984). In this test the statistic (i.e. \(\chi_{{{\text{homogeneous}}}}^{2}\)) is calculated as
The values of \((Z_{i} )\) and \((\overline{Z})\) are computed by
where Si is the MK statistic for month i, and the χ2homogenous has a Chi-square distribution. The χ2homogenous between months is compared with the critical value for the Chi-square (χ2) distribution with m − 1 df. If χ2homogenous is not significant, then a valid test of the general trend is possible by referring to the assumed α = 0.05 for the Chi-square (χ2) distribution with 1 df. If χ2homogenous is significant the null hypothesis of homogeneous monthly trend direction must be rejected.
Runs test was developed by Swed and Eisenhart (1943). The estimated Zc statistic value (Eq. 22) is compared to the Z-test value of the two-sided hypothesis test at a significance level of 5%. If the Zc statistic value is greater than the z-test value, Ho is rejected, so the H1 hypothesis is accepted and the time series under investigation is a statistically significant inhomogeneous series:
In Eq. 22, Zc is the test value. N is the number of data. Ni is the number of data smaller than the median. Nj is the number of data greater than the median. and r is the number of runs of the data that are above and below the critical value. The runs test rejects the null hypothesis if |Zc| is greater than Z1-α/2. For a large sample runs tests (that is, both Ni and Nj are greater than 10), the test statistic is compared to the standard normal table (that is, Z1-α/2). That is, at the 5% significance level, a test statistic with an absolute value greater than 1.96 at a significance level of 5% indicates non-randomness. For a small sample runs test, there are tables for determining critical values that depend on the values of Ni and Nj (Mendenhall and Reinmuth 1982).
Pettitt test is a nonparametric rank test developed by Pettitt (1979). The time-s analysis of the homogeneity test provides information according to the level of significance used. The Pettitt test rejects the null hypothesis (H0: no break, homogeneous) if the year was a significant break in a trend for a corresponding station. The rank of the data series is used to calculate the test statistic and ignore the normality of the data series (Pettitt 1979). Below is a brief description of the Pettitt test:
where ri is the ranks of the data series. If there is a break in year K, the statistics will be maximum or minimum near the year k = K. Critical values for \(X_{K}\) at the 5% significance level depending on the sample size is given in Table 1.
Standard normal homogeneity (SNH) test is a parametric test which was proposed by Alexanderson (1986). The null hypothesis is the same for the Pettitt test. Alexnderson (1986) describes statistics for comparing the average of the first year of a record with the average of the last year. The test statistic Tk is computed as
where
If there is a change point in the data series, Tk reaches its maximum near of k = K. The test statistic To is computed as follows:
If To is greater than the critical value, the null hypothesis is rejected. The critical value of To is based on the sample size reported by Alexanderson (1986), as shown in Table 1.
Buishand range (BR) test is a parametric test that was developed by Buishand (1982). The null hypothesis is the same as the Pettitt test. This test is based on the adjusted partial sums calculated by the following equation:
where \(\overline{y}\) is the average of the data time series, the test statistic is defined as
The null hypothesis is accepted, when the value is less than the critical values based on sample size (n) given by Buishand (1982), as shown in Table 1.
Von Neumann rate (VNR) test is a nonparametric test which is developed by Von Neumann (1941). It uses the ratio of the mean square successive (year to year) difference to the variance. The VNR ratio (N) is calculated as
The critical values based on sample size (n) can be taken from Buishand (1982), as shown in Table 1.
In a hypothesis test, the critical value is a point on the test distribution that is compared to the test statistic to determine if the null hypothesis is rejected (Statistics Online 2021). The critical values of the six adopted homogeneity tests (Table 1) mentioned above were used to test the hypothesis of the rainfall time series (i.e. monthly, seasonal and annual data series) during the period 1976–2020 (42-year data length; i.e. 42-year sample size) at α = 5% significance level.
Results and discussion
Moving average rainfalls
The average annual rainfall (AAR) with 3 years moving average annual rainfalls (MAAR) for the data period ranging between 1976 to 2017 for the Duhok station considered in this study is shown in Fig. 2. It can be observed in Fig. 2 that the AAR ranges between 19.7 mm for the years 1978 and 75.8 mm for the year 1994. While the average annual rainfall value equals 44.6 mm for the study period of 1976–2017. In Fig. 2, by considering moving AAR of 3 years, it shows that the MAAR is ranging between 15.2 mm and 68.4 mm for the monthly duration data. It is worth mentioning that the highest monthly rainfall of 330.4 mm occurred in January 2013.

Average annual rainfall (AAR) with 3-year moving average annual rainfalls (MAAR) for Duhok station in Kurdistan region, Iraq during 1976–2017
Results of quality control of the rainfall data series
The quality control of monthly, seasonal and annual rainfall data series of Duhok station were tested using Mandel’s k statistic method to detect the outlier, as described in “Methods”. The results of Mandel’s k method in Fig. 3 showed that no outlier was detected in the rainfall data series of Duhok station. The most common reasons for outliers to appear in climate data are equipment errors related to incorrect data entry related to observers, or equipment relocations, changes, or rare equipment maintenance delays (Jaafar and Al-Lami 2019). The rainfall data measurements and the availability of each station play a major role in identifying the causes of outliers in the results due to the detailed information in the station data. This information is not available at Duhok station. Therefore, there is no evidence of the reason for the outliers of the station under study.

Detected outliers for the Duhok station (alpha = 0.05)
Trend in rainfall data series by ITA method, MK test and Modified MK test
This study used the ITA method to determine trends in monthly, seasonal, and annual rainfall data series for the study period from 1976 to 2017, as described in “Methods”. In general, the results of applying the ITA method (Figs. 4, 5, 6) show that most data points fall under the 1:1 line, implying an overall downward trend. However, the characteristics of patterns in different rainfall data series are quite different. On a monthly scale, as shown in Fig. 4, concerning the two confidence interval bands (10% and -10%), the results show a clear increasing trend of all the values (i.e., low, medium, and high) in January with data generally falling above the 10% relative band. In February and March, most of the rainfall points below 110 mm per month have no trend, while, from 110 and up to 180 mm per month shows a decreasing trend, and the precipitation above 200 mm per month shows an increasing trend.

Results of applying the ITA method for monthly rainfall data at Duhok station (1976–2017)

Results of applying the ITA method for seasonal rainfall data at Duhok station (1976–2017)

Results of applying the ITA method for AAR at Duhok station (a) non-monotonic trends (b) the trends of each cluster (low, medium and high)
Decreasing trends were detected in both April, May and October. In general, the low rainfall values show a steady decrease in the first subseries more than the second subseries in April. The same situation is evident in October, except for the low values. While, in May the rainfall data points in low values change more abruptly than the medium and high values. In June, July and August the rains are very rare and sporadic almost every year. In September an increasing trend is indicated inside the 10% bands, but there are not many rainfall data points. Most rainfall data points show decreasing trend areas in November outside the 10% bands of all the values (i.e., low, medium, and high). Finally, in December, the low rainfall points in the upper triangular show an increasing trend. This means that there is an increase in the low rainfall in the second halves of the observed data (1997–2017) compared to that in the first halves (1976–1996). However, there are not many rainfall data points in the middle and high categories, a decreasing trend is obvious.
On a seasonal scale, as shown in Fig. 5, the results show that most of the rainfall points below 75 mm per month have no trend, while, from 75 mm up to 120 mm per month show a decreasing trend with data generally falling under the 10% relative band in Spring. In the Summer season (i.e., June, July and August), the region is dry. Most rainfall data points indicate a decreasing trend area in Autumn, outside the 10% bands of low and medium values. In Winter an increasing trend is observed inside the 10% bands for most of the rainfall points.
The results on an annual scale as shown in Fig. 6 show an increasing trend for low values of the rainfall points below 30 mm per month. Also, the rainfall points from 30 to 40 mm per month show a decreasing trend with data generally falling under the 10% relative band. For the medium values, a steady decreasing trend is observed for all the annual rainfall data points inside the 10% bands. Even though there are not many rainfall data points in high values, most of the data points indicate a decreasing trend outside the 10% bands.
The results of the MK test for the case of non-autocorrelated rainfall series for trend detection in monthly, seasonal and annual rainfall series are shown in Fig. 7. It can be observed in Fig. 7, that the trend results of the MK test at monthly, seasonal and annual rainfall scales are statistically insignificant at three levels of significance (i.e., 10%, 5%, and 1%) except for the January and Winter series. The increase in rainfall trends in January and Winter were statistically significant at a 10% significance level (Fig. 7). Even though most of the trends were non-significant at the 10%, 5% and 1% significance levels, more than half of the total monthly series show an upward trend. In the case of seasonal rainfall data series, Summer and Winter seasons have rising trends, whereas falling trends are observed in both Spring and Autumn seasons. In addition, there was an increasing trend of annual precipitation in 42 years (study period of 1976–2017).

MK trend test result of rainfall in Duhok station (1976–2017)
The results of the Modified MK test for the autocorrelated series for trend detection in the monthly, seasonal and annual series are shown in Table 2. Sen’s slope estimator and CF are also shown in Table 2. Depending on the correlation factor (i.e., r1 > ± 0.278), the five series are autocorrelated out of 17 series at the 10% and 5% significance levels. On the monthly scale, it has been found that the highest magnitude of Sen’s slope estimator is 1.134 (in January) and the lowest magnitude of Sen’s slope is -0.413 (in November). Furthermore, on the seasonal scale, it has been found that the highest value of Sen’s slope estimator is 0.446 (in Winter). On an annual scale, it was found that the value of Sen’s slope estimator (i.e., 0.181) is higher than the monthly and seasonal scales.
Tables 3 and show a comparison among the results of the trend tests (i.e., MK test, Modified MK test and 42 years the ITA method) for monthly, seasonal and annual rainfall data over a 42-year study period. The results in both Table 3 and provide information on the evolution of the patterns of the rainfall time series in terms of the evaluation of the low and high values. Moreover, the ITA method is another aspect of the MK and Modified MK tests. As shown in Table 3, the low and high values of all rainfall series were evaluated individually according to the ITA method. The results in Table 3 show that according to both MK and Modified MK trend tests, an increasing trend for 8 of the 12 months at selected stations in the study area and a decreasing trend for the remaining 4 months. In addition, depending on the trend slope, the results of the ITA method show, an increasing trend is apparent in 6 of the 12 months.
In the case of seasonal time series, the results of the three trends tests (i.e., MK test, Modified MK test and the ITA method) show that Summer and Winter seasons have rising trends, whereas falling trends are observed in both Spring and Autumn seasons. Also, it has been found that the trend results on the annual scale (i.e., AAR) showed an increasing trend for the three trends tests. In general, it can be observed in Table 3 that using the TFPW approach, which considers the effect of serial correlation on trend results, resulted from a slight increase in the range of trends and its statistical significance in rainfall data series (i.e., Zc statistics). Table 3 also shows that the trend slope of the ITA method is higher for the data series which significantly increase (e.g., January and Winter) than those which insignificantly increase or decrease (e.g., February to December).
It can be observed in Table 4 that according to both the MK test and Modified MK test, there is no significant trend in most of the rainfall series (i.e., monthly, seasonal and annual) except for January and Winter, where the rainfall time series have increased significantly. Whereas the results of the ITA method indicate that increasing trends exist in 3 months (i.e., January, October and December) out of 12 months for high rainfall series. According to the low rainfall series, 1 month (i.e., January) shows an increasing trend, and the November and Winter series show a decreasing trend.
Depending on both the MK test and Modified MK test, it can be observed in Table 4 that 11 out of 17 rainfall series (i.e., monthly, seasonal andr annual rainfall series) show an increasing trend, and 4 of the 17-rainfall series are showing a decreasing trend. This outcome is compatible with Sen’s Slope values in Table 2. In the case of applying the ITA method, for high values, 8 out of 17 rainfall series show an increasing trend and 5 show a negative trend at low values.
Abrupt shift in rainfall data
The Pettitt change-point test is used to identify abrupt changes (shift) in the average rainfall time series in Duhok station. The direction of the shift in the average is determined by comparing the average of the subseries before the shift and after the shift. Figure 8 of the Pettitt test shows that there has been a significant positive shift occurred after 1990. The Pettitt test shows that the Duhok station has positive trends at the 10% significance level. In addition, it is found that the mean of the AAR data after the change point is higher (i.e., 46.89) than the mean prior to the change point (i.e., 41.30) with a rate of change of 13%. Furthermore, the MK test statistics prior to and after the change point (i.e., Zc = 0.274 and Zc = − 0.896, respectively) are smaller compared to the MK test statistic for the complete data series (i.e., Zc = 0.542). The observed AAR is characterized by quick transitions that can be described as "jumps" of the same year, but these jumps are not significant except in 1990 which shows a significant positive shift jump (see Fig. 8). The AAR data show that since the year 1990 (i.e., change point year), the high increasing change in AAR is sudden and prolonged happened in 3 years (1992, 1993, and 1994). However, unlike it was expected by previous scenarios based on 1992, 1993 and 1994, the AAR data since 1995 shows a decrease and after 1995 the AAR data series return nearly to the same level prior to 1990. Indeed, trends of AAR, are obtained by MK and Modified MK trend tests, also the ITA method showed increasing changes within the period 1976–2017 in Duhok station, which indicates an increasing trend (see Table 3). The AAR analysis (Fig. 8) suggests a rainfall increase in the upcoming years. Moreover, the rainfall data indicate that a high probability of sudden and prolonged changes in the rainfall data series.

Pettit change point test results for Duhok station showing a positive shift in the mean of the AAR data (circle represents change point)
Homogeneity of trends in rainfall data series
As stated in “Methods”, the homogeneity of the rainfall data of the Duhok station in the Kurdistan region, Iraq was tested using each of Van Bell and Hughes homogeneity, Runs, Pettit, SNH, BR, and VNR tests. In the application of homogeneity tests, the rainfall time series (monthly, seasonal and annual time series) were considered separately. The results of each method were evaluated for a significance level of 95% and the inhomogeneities were detected. The critical values obtained from each of the above-mentioned homogenous tests are shown in Table 1. The data of the months June to August have been neglected due to very limited rainfall, hence all statistical parameters of the adopted homogeneity tests are close to zero. In the current study, the methods for testing the homogeneity of the series may be classified into two groups:
Group 1: Van Belle and Hughes (1984) test was applied to monthly and seasonal rainfall data. The computed χ2homogenous value (i.e. χ2homogenous = 3.51) for Van Belle and Hughes (1984) test was found to be less than the critical value of the χ2homogenous at α = 0.05 (that is 19.68 for df = 11). The calculated χ2homogenous value was not significant, so the χ2trend value was then compared to the critical value of the χ2trend at α = 0.05. Since Duhok station had χ2trend value (i.e., χ2trend = 0.082) less than the critical value of the χ2trend (that is 3.84 for df = 1) its monthly rainfall trends were inhomogeneous, which indicates that the trends in all months had a different direction. For seasonal data (i.e., Spring, Summer, Autumn and Winter), the computed χ2homogenous value (i.e., χ2homogenous = 1.218) for the Van Belle and Hughes (1984) test was found to be less than the critical value of the χ2homogenous at α = 0.05 (which is 7.81). Since the calculated χ2homogenous value was not significant, the χ2trend value was compared to the critical value of the χ2trend at α = 0.05. Since Duhok station had a χ2trend value (i.e., χ2trend = 0.001) was below than the critical value of the χ2trend (that is 3.84 for df = 1), its seasonal rainfall trends were inhomogeneous, indicates that the trends in all seasons had a different direction.
Group 2: Runs, Pettitt, SNH, BR and VNR tests were applied to the monthly seasonal and annual rainfall data series. In Table 5, it can be observed that most of the rainfall time series pass the critical test values (Table 1) of the five adopted tests at the 95% significance level. The results of the Runs test show that non-homogeneous was detected only in September (significant negative shifts). The results of the Pettitt, SNH and BR tests show that the inhomogeneity is generally detected between the years 1994 and 2007. It can also be observed in Table 5, that the inhomogeneity is detected in September using Pettitt, SNH and VNR tests, while Table 2 shows that rainfall data series on January and September was found to be inhomogeneous by applying the BR test at a significance level of 95%. The outcome of the Pettitt, SNH, BR and VNR tests homogeneity tests in the current study is similar to the outcome of the studies by AL-Lami et al. (2014) and Agha et al. (2017) who analyzed rainfall data and found the homogeneity for all stations located in northern Iraq. It should be noted that AL-Lami et al. (2014) used data for the period 1980 to 2010, while Agha et al. (2017) used data for the period 1943 to 2010 and our data period covers 1976 to 2017.
Conclusion
In this study, quality control, trend tests and homogenous tests were applied to monthly, seasonal and annual data series for a study period of 1976–2017 at site location in Duhok city, Kurdistan Region, Iraq. The quality control technique used was the outlier detection using Mandel’s K methods at 5ioa n% significance level. The Mann–Kendall (MK), Modified MK tests and Innovative Trend Analysis (ITA) trend tests have been applied to identify trends in the rainfall data series at the 10%, 5% and 1% significance levels. Pettitt Change Point test has been employed to determine the direction and timing of a change point. The homogeneity of the data times series at the selection station has been examined using the Van Bell and Hughes homogeneity, Runs, Pettit, standard normal homogeneity, Buishand Range, and Von Neumann rate tests.
The results of the Mandel k method show that no outliers were found in the monthly, seasonal, and annual rainfall data series of the selected station. The results of the MK test show that the number of positive trends is greater than the number of negative trends, especially in the time series the individual rainfall. The statistical Zc value of the MK test represent both an increasing and a decreasing trend in the study area, but this increase or decrease is not significant, except for the January and Winter series. The increase in rainfall trends in January and Winter was statistically significant with the 10% significance level. The use of the Modified MK test, which accounts for the impacts of serial correlation on-the results, has resulted in a slight increase in the magnitude of trend and its statistical significance in rainfall data series. Monthly time series were found to have the most significant trend in January with a significance level of 5%, and the seasonal time series were found to have the most significant trend in Winter. Sen's slope also shows positive and negative slope values according to the MK test value and the modified MK trend test. There are 11 out of 17 rainfall series with a positive trend and Zc and increasing Sen’s slope magnitude, and there are 4 out of 17 rainfall series with negative Zc value and Sen’s Slope.
The results of the ITA method indicated that increasing trends were observed in January, October and December for the high rainfall series, while according to the low rainfall series, January shows an increasing trend and November show a decreasing trend. The difference between the MK test and Modified MK test in the monthly, seasonal and annual rainfall series was small. The Pettit test results showed that there was a significant positive shift since 1990. In the case of homogeneity of the rainfall data series, the entire time series (most of monthly, seasonal and annual series) is homogeneous. Finally, the present study concluded that there is evidence of some change in the trend of rainfall data series during the 1976–2017 study period at Duhok station in the Kurdistan Region, Iraq.
References
Abbasa N, Wasimia SA, Al-Ansari N (2016) Assessment of climate change impact on water resources of Lesser Zab, Kurdistan, Iraq using SWAT model. Engineering 8:697–715. http://file.scirp.org/pdf/ENG_2016102711410207.pdf
Agha OMA, Bağçac Ç, Şarlak N (2017) Homogeneity analysis of precipitation series in north Iraq. IOSR J Appl Geol Geophys 5(3):57–63
Alashan S (2020) Innovative trend analysis methodology in logarithmic axis. Konya J Eng Sci 8(3):573–585
Alexanderson HA (1986) A homogeneity test applied to precipitation data. Int J Climatol 6:661–675
Alifujiang Y, Abuduwaili J, Maihemuti B, Emin B, Groll M (2020) Innovative trend analysis of precipitation in the lake Issyk-Kul basin, Kyrgyzstan. Atmosphere 11:332
AL-Lami AM, AL-Timimi YK, AL-Salihi AM (2014) The homogeneity analysis of rainfall time series for selected meteorological stations in Iraq. Iraqi Acad Sci J 10(2):60–77
Al-Salihi AM, Al-lami AM, Altimimi YK (2014) Spatiotemporal analysis of annual and seasonal rainfall trends for Iraq. Al-Mustansiriyah J Sci 25:153–168
Barbero R, Fowler HJ, Blenkinsop S, Westra S, Moron V, Lewis E, Chan S, Lenderink G, Kendon E, Guerreiro S, Li X-F, Villalobos R, Ali H, Mishra V (2019) A synthesis of hourly and daily precipitation extremes in different climatic regions. Weather Climate Extremes 26:100219
Breinl K, Lun D, Müller-Thomy H, Blöschl G (2021) Understanding the relationship between rainfall and flood probabilities through combined intensity-duration-frequency analysis. J Hydrol 602(126759):1–19
Buishand T (1982) Some methods for testing the homogeneity of rainfall records. J Hydrol 58:11–27
Chibuike M, Kunda J, Eze J, Ayodotun A (2014) Mathematical study of monthly and annual rainfall trends in Nasarawa State, Nigeria. IOSR J Math 10(1):56–62
Chowdhury S, Al-Zahrani M (2013) Implications of climate change on water resources in Saudi Arabia. Arab J Sci Eng 38:1959–1971
Cunderlik JM, Burn DH (2004) Linkages between regional trends in monthly maximum flows and selected climatic variables. ASCE J Hydrol Eng 9(4):246–256
Duhok Province (2015) General board of tourism. http://bot.gov.krd/duhok-province
Gao X, Peng S, Wang W, Xu J, Yang S (2016) Spatial and temporal distribution characteristics of reference evapotranspiration trends in Karst area: a case study in Guizhou Province, China. Meteorol Atmos Phys 128:677–688
Güçlü YS (2018) Multiple Şen-innovative trend analyses and partial Mann–Kendall test. J Hydrol 566:685–704
Güçlü YS (2020) Improved visualization for trend analysis by comparing with classical Mann-Kendall test and ITA. J Hydrol 584:124674
Hajani E (2020) Climate change and its influence on design rainfall at-site in New South Wales state, Australia. J Water Climate Change 11(S1):251–269
Hajani E, Rahman A (2017) Design rainfall estimation: comparison between GEV and LP3 distributions and at-site and regional estimates. Nat Hazards 93(1):67–88
Hajani E, Rahman A (2018) Characterising changes in rainfall: a case study for New South Wales, Australia. Int J Climatol 38:1452–1462
Hajani E, Rahman A, Ishak E (2017) Trends in extreme rainfall in the state of New South Wales, Australia. Hydrol Sci J 62(13):2160–2174
Hamed K, Rao A (1998) A Modified Mann–Kendall trend test for auto-correlated data. J Hydrol 204:182–196
Hyndman RJ (2011) Moving averages. International Encyclopaedia of Statistical Science, pp 866–869
Intergovernmental Panel on Climate Change, IPCC (2014) Climate change 2014: Assessment Synthesis Report, Geneva, Switzerland. http://www.ipcc.ch/report/ar5/syr
Jaafar AJ, Al-Lami AM (2019) Quality control of annual precipitation measurement for selected stations in Iraq. Al-Mustansiriyah J Sci 30(4):9–17
Joshua JK, Ekwe MC (2013) Indigenous mitigation and adaptation strategy to drought and environmental changes in Nigerian section of lake CHAD basin. Int J Appl Res Nat Prod 2(5):1–14
Kendall MG (1975) Rank correlation methods. Griffin Publishers, London, p 202
Mamoon A, Rahman A (2017) Rainfall in Qatar: is it changing? Nat Hazards 85:453–470
Mandel J (1991) The validation of measurement through interlaboratory studies. Chemom Intell Lab Syst 11:109–119
Mandel J (1985) A new analysis of interlaboratory test results. In: ASQC quality congress transaction, Baltimore, pp 360–366
Mann HB (1945) Non-parametric tests against trend. J Econom 13:245–259
Maragatham RS (2012) Trend analysis of rainfall data—a comparative study of existing methods. Int J Phys Math Sci 2:13–18
Meena M (2020) Rainfall statistical trend and variability detection using Mann–Kendall test, Sen’s slope and coefficient of variance - a case study of Udaipur district (1957–2016). Appl Ecol Environ Res 8(1):34–37
Mendenhall W, Reinmuth J (1982) Statistics for management and economics, 4th edn. Duxbury Press, Pacific Grove
Modarres R, Sarhadi A (2009) Rainfall trends analysis of Iran in the last half of the twentieth century. J Geophys Res 114:1–9
Mustafa YT, Ali RT, Saleh RM (2012) Monitoring and evaluating land cover change in the Duhok city, Kurdistan region-Iraq, using Remote sensing and GIS. IJEI Int J Eng Invent 1(11):28–33
Nashwan MS, Shahid S, Abd Rahim N (2019) Unidirectional trends in annual and seasonal climate and extremes in Egypt. Theor Appl Climatol 136:457–473
Ongoma V, Chen H (2017) Temporal and spatial variability of temperature and rainfall over East Africa from 1951 to 2010. Meteorol Atmos Phys 129:131–144
Othman HA (2008) Urban planning strategies, towards sustainable land use management in Duhok City Kurdistan Region, Iraq. Higher Institute of Planning University of Duhok, Duhok
Packman JC, Kidd CHR (1980) A logical approach to the design storm concept. Water Resour Res 16(6):994–1000
Pettitt AN (1979) A non-parametric approach to the change-point detection. J Appl Stat 28:126–135
Pilgrim DH, Cordery I (1975) Rainfall temporal patterns for design floods. J Hydraul Div 101(1):81–95
Salas JD, Delleur JW, Yevjevich V, Lane WL (1980) Applied modelling of hydrologic time series. Water Resources Publication, Littleton
Sen PK (1968) Estimates of the regression coefficient based on Kendall’s Tau. J Am Stat Assoc 63(324):1379–1389
Sen Z (2012) Innovative trend analysis methodology. J Hydrol Eng 17(9):1042–1046
Statistics Online (2021) Basic statistical concepts: hypothesis testing (critical value approach). https://online.stat.psu.edu/statprogram/reviews/statistical-concepts/hypothesis-testing/critical-value-approach.
Steven-Brauner J (1997) Nonparametric estimation of slope: Sen's method in environmental pollution. Environmental Sampling and Monitoring Primer
Swed F, Eisenhart C (1943) Tables for testing randomness of grouping in a sequence of alternatives. Ann Math Stat 14:66–87
Tarekegn N, Abate B, Muluneh A, Dile Y (2021) Modeling the impact of climate change on the hydrology of Andasa watershed. J Model Earth Syst Environ. https://doi.org/10.1007/s40808-020-01063-7
Van Belle VG, Hughes JP (1984) Nonparametric tests for trend in water quality. Water Resour Res 20(1):127–136
Von Neumann J (1941) Distribution of the ratio of the mean square successive difference to the variance. Ann Math Stat 13:367395
Wang Y, Xu Y, Tabari H, Wang J, Wang Q, Song S, Hu Z (2020) Innovative trend analysis of annual and seasonal rainfall in the Yangtze River Delta, eastern China. Atmos Res 231:104673
World Climate Guide, WCG (2019) Climate-Iraq. https://www.climatestotravel.com/climate
Wijngaard JB, Kleink Tank AM, Konnen GP (2003) Homogeneity of 20th century european daily temperature and precipitation series. Int J Climatol 23:679–692
Wilrich PT (2013) Critical values of Mandel’s h and k, the Grubbs and the Cochran tests statistic. AStA Adv Stat Anal 97(1):1–10
Yue S, Wang C (2004) The Mann–Kendall test modified by effective sample size to detect trend in serially correlated hydrological series. J Water Resour Manag 18(3):201–218
Yue S, Pilon P, Cavadias G (2002) Power of the Mann–Kendall and Spearman’s Rho tests for detecting monotonic trends in hydrological series. J Hydrol 259:254–271
Yue S, Pilon P, Phinney B (2003) Canadian streamflow trend detection: impacts of serial and cross-correlation. Hydrol Sci J 48(1):51–63
Acknowledgements
Authors thanks the Directorate of Duhok Dam in Kurdistan region for supplying the rainfall data used in this study.
Author information
Authors and Affiliations
Contributions
EH conducted this study, prepared the paper, analyzed 90% of the data; ZK prepared the data, analyzed 10% of the data, and contributed to writing the introduction; both authors proofread and approved the final manuscript.
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Hajani, E., Klari, Z. Trends analysis in rainfall data series in Duhok city, Kurdistan region, Iraq. Model. Earth Syst. Environ. 8, 4177–4190 (2022). https://doi.org/10.1007/s40808-022-01354-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40808-022-01354-1