
Abstract
Providing a choice of reinforcers is a commonly used strategy with children with autism spectrum disorder; however, less is known about the differential effectiveness and efficiency of providing choices before or after responding during acquisition tasks. Therefore, we evaluated reinforcer choice using untaught targets prior to and following responding. Results showed faster acquisition of targets in the consequence condition for 2 of 3 participants. These data provide preliminary support that providing choice prior to responding may not result in the most efficient acquisition for some individuals.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Teachers commonly provide choice among reinforcers during instruction for learners with autism spectrum disorder (ASD; Howell, Dounavi, & Storey, 2018; Peterson, Lerman, & Nissen, 2016). Two approaches for doing so are for a teacher to provide a choice of reinforcer prior to (antecedent choice) or following (consequence choice) a response requirement. Antecedent choice may be advantageous because it may function as an establishing operation or be discriminative for task responding. Consequence choice may be advantageous because it can capture momentary fluctuations in preference and choice itself may function as a reinforcer (Peterson et al., 2016; Toussaint, Kodak, & Vladescu, 2016).
Peterson et al. (2016) evaluated maintenance task response persistence during antecedent and consequence choice conditions as the response requirement increased (i.e., progressive-ratio schedule) with four participants with ASD. Two participants showed higher levels of responding during the antecedent choice condition, whereas no difference in responding across conditions was observed for the other two participants. However, these results may be limited to the use of progressive-ratio schedules with mastered tasks. That is, it is unclear if similar outcomes would be observed when teaching new responses using reinforcement schedules often arranged during acquisition tasks. Thus, the purpose of the current study was to replicate and extend Peterson et al. by evaluating the effectiveness and efficiency of antecedent and consequence choice during skill acquisition.
Method
Participants
Three children diagnosed with ASD who had recent histories with auditory-visual conditional discrimination instruction participated in the study. All participants received services based on the principles of applied behavior analysis (ABA) in a private school for students with ASD. Olivia, a 5-year-old girl, had been receiving ABA services for at least 2 years and had at least 5 months’ experience with token economies. She received a total score of 111.5 on the Verbal Behavior Milestones Assessment and Placement Program (VB-MAPP; Sundberg, 2008), scored a 69 (qualitative description: extremely low) on the Peabody Picture Vocabulary Test, Fourth Edition (PPVT-4; Dunn & Dunn, 2007), and scored a 71 (moderately low) on the Expressive Vocabulary Test, Second Edition (EVT-2; Williams, 2007). Ted, a 6-year-old boy, had been receiving ABA services for at least 2.5 years and had at least 2.5 years’ experience with token economies. He received a total score of 101.5 on the VB-MAPP, a 35 (extremely low) on the PPVT-4, and a 20 (extremely low) on the EVT-2. Grant, a 9-year-old boy, had been receiving ABA services for at least 5 years and had at least 5 years’ experience with token economies. He received a total score of 148.5 on the VB-MAPP, a 46 (extremely low) on the PPVT-4, and a 53 (extremely low) on the EVT-2.
Setting and Materials
The study was conducted in an empty room at the participants’ school. Materials present for each session included a desk, chairs, data sheets, pencils, a timer, stimuli binders, token boards, tokens, choice boards, and putative reinforcers. The experimenter sat beside the participant at the desk.
The stimuli binders contained one sheet for each trial in a session. Each trial sheet consisted of a white piece of paper containing three stimuli spaced equidistantly apart. We affixed a blank piece of colored paper (colors were assigned based on the results of a color preference assessment) on top of each trial sheet. The paper prevented the participant from viewing the comparison array prior to the beginning of the trial.
Experimental Design, Measurement, Interobserver Agreement, and Procedural Integrity
We used an adapted alternating-treatments design (Sindelar, Rosenberg, & Wilson, 1985) embedded within a nonconcurrent multiple-baseline design to evaluate the effectiveness and efficiency of antecedent and consequence choice of the putative reinforcer.
The experimenter recorded unprompted and prompted correct and incorrect responses. We defined an unprompted and a prompted correct response as the participant pointing to the comparison stimulus that corresponded to the auditory sample stimulus prior to or following the experimenter’s prompt, respectively. We defined an unprompted and a prompted incorrect responses as the participant engaging in an error of commission or omission prior to or following the experimenter’s prompt, respectively. The experimenter recorded the total duration of each session, which included pointing to and tacting the choice binder, affixing a picture to the token board, and the reinforcement interval, using a digital timer. We started the timer immediately prior to establishing attending behavior prior to the first trial of the session and stopped the timer following the terminal component of the last trial in the session. A second timer was used to record the reinforcer interval duration.
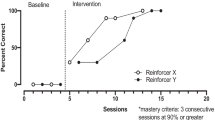
Only the percentage of unprompted correct responses is depicted in Figure 1 and was calculated for each session by dividing the number of unprompted correct responses by the number of trials and multiplying by 100. We calculated total training sessions to mastery by adding the number of training sessions conducted per condition. We calculated exposures to mastery by adding the number of training trials conducted per condition. We calculated total training time by adding the session durations per condition.

Percentage of unprompted correct responding across the consequence and antecedent conditions for Olivia, Ted, and Grant. BL = baseline
A second observer independently scored participant responding and session duration in vivo for an average of 35% (range 30%–39%) of sessions across participants. Trial-by-trial interobserver agreement (IOA) was calculated by dividing the number of agreements by the number of agreements plus disagreements and converted that ratio into a percentage. An agreement was scored if the second observer recorded the same dependent variables as the primary observer within the trial. A disagreement was scored if the second observed recorded any different dependent variables from those recorded by the primary observer within the trial. Duration IOA was calculated by dividing the smaller duration by the larger duration and multiplying by 100%. Mean agreement for unprompted correct responding was 99.4% (range 89%–100%), 100%, and 99% (range 89%–100%) for Olivia, Ted, and Grant, respectively. Mean agreement for session duration was 99% (range 86%–100%), 96% (range 95%–100%), and 94% (range 96%–100%) for Olivia, Ted, and Grant, respectively.
An observer collected procedural integrity (PI) data for an average of 33% (range 29%–40%) of sessions for all participants. PI was collected using a three-item checklist of correct experimenter behaviors (available from the first author) for each trial and was calculated by dividing the total number of correct experimenter behaviors by the total number of correct and incorrect experimenter behaviors and multiplying by 100. PI was 100%, 99% (range 96%–100%), and 99% (range 93%–100%) for Olivia, Ted, and Grant, respectively.
Preference Assessments and Token Economy
The experimenter conducted separate edible and leisure item paired-stimulus (PS) preference assessments (Fisher et al., 1992) using instructor-identified edible and leisure items. The experimenter standardized the size of the edibles included in the PS preference assessment such that each edible was a consistent size across presentations. The PS preference assessments were conducted once prior to the beginning of the evaluation. A picture of any item approached at least once was affixed to each participant’s choice board. A color PS preference assessment was conducted using 10 colored pieces of paper. Two colors approached during an approximately equal percentage of trials were assigned as condition-correlated stimuli to enhance discrimination across the antecedent and choice conditions.
We created distinct token boards and a corresponding set of tokens for each condition. Each token board consisted of a colored rectangular board with four pieces of Velcro (three to attach tokens, one to attach the picture of the backup putative reinforcer). Tokens consisted of three colored buttons. Participants had the opportunity to select a picture of an edible or toy that would be traded for three tokens either prior to or following earning all tokens. Selections were made via a colored choice board, which consisted of a rectangular board with 15 pictures of edibles and toys from the preference assessments. We provided the toy or a small piece of the edible and replaced it following consumption for 1 min. Token boards were reset at the beginning of each session.
Pretest and Stimuli Assignment
We conducted pretests to identify targets (based on individual treatment goals) for each participant. Specific pretest procedures are available from the first author, but we discarded any potential target that the participant selected for more than one unprompted correct response during the pretest. Following the pretest, we assigned three exemplars of three targets to the antecedent and consequence choice conditions. We assigned targets to conditions using a logical analysis (Wolery, Gast, & Ledford, 2014) that considered the number of syllables in each target name, the redundancy of phonemes across target names, and the physical similarity across targets. A list of targets is available from the first author.
General Procedure
A constant prompt delay with a gesture prompt (i.e., experimenter pointing to the correct comparison stimulus) was used to teach unknown targets. The beginning training sessions included trials conducted at a 0-s prompt delay. During 0-s trials, the experimenter presented the auditory sample stimulus, flipped the blank page, immediately re-presented the auditory sample stimulus while gesturing to the correct comparison stimulus, and allowed the participant 5 s to respond. Prompted correct responses resulted in praise and a token. Following prompted incorrect responses, the experimenter presented the next trial. The experimenter continued to implement the 0-s prompt delay until the participant responded for two consecutive sessions with at least 89% prompted correct responses. Then, the prompt delay was increased to 5 s. During trials conducted with a 5-s prompt delay, the experimenter presented the auditory sample stimulus, flipped the blank page, and allowed the participant 5 s to respond. Unprompted correct responses resulted in praise and a token. Following unprompted incorrect responses, the experimenter simultaneously re-presented the sample stimulus, provided a gesture prompt, and allowed the participant 5 s to respond. Prompted correct responses resulted in praise and a token. Prompted incorrect responses resulted in the presentation of the next trial. We continued to deliver a token and praise following prompted correct responses until the participant demonstrated unprompted correct responses during 56% or more of trials. Thereafter, we delivered praise only following prompted correct responses and a token and praise following unprompted correct responses. Training continued until participants demonstrated 100% unprompted correct responses for two consecutive sessions. We conducted nine trial sessions in a randomized without-replacement fashion. A minimum of 2 min elapsed between sessions. We conducted one to four sessions per day, 1 to 5 days a week.
Baseline
The experimenter opened the stimulus binder, delivered the auditory sample stimulus, flipped the blank page, and allowed 5 s for the participant to respond. The experimenter provided a brief verbal statement (e.g., “OK”) following unprompted correct or incorrect responses. The experimenter delivered praise for appropriate collateral behavior (e.g., sitting appropriately at the table) approximately every three trials during the intertrial interval in an attempt to maintain participant responding.
Antecedent Choice
We prompted a touch of the antecedent choice binder and a tact of the corresponding color. Next, we presented the choice board and said, “Pick what you want to work for.” We repeated this direction every 5 s until the participant selected a picture. We prompted affixing the picture to the token board. The experimenter opened the stimulus binder, delivered the auditory sample stimulus, and flipped the blank page. After three tokens were earned, the experimenter removed work materials, presented the token board, and said, “You earned [name of backup reinforcer selected].” We delivered the selected backup reinforcer.
Consequence Choice
The consequence choice condition was similar to that of the antecedent choice condition with the following exceptions. After three tokens were earned, the experimenter removed work materials, presented the choice board, and said, “Pick what you want.” We repeated this direction every 5 s until the participant selected a picture, and we prompted affixing the picture to the token board. We delivered the selected backup reinforcer.
Results and Discussion
Figure 1 depicts the percentage of unprompted correct responses for Olivia, Ted, and Grant. During the treatment comparison, Olivia (top panel) demonstrated mastery responding in 60 (540 training trials; 324 min, 45 s training time) and 61 (549 training trials; 323 min, 11 s training time) training sessions in the antecedent and consequence choice conditions, respectively. From Session 85 on, we prompted Olivia’s hands down for 1 s following the auditory sample stimulus to increase the likelihood she was scanning the array. Ted (middle panel) demonstrated mastery responding in 42 (378 training trials; 289 min, 54 s training time) and 35 (315 training trials; 225 min, 4 s training time) training sessions in the antecedent and consequence choice conditions, respectively. Grant (bottom panel) demonstrated mastery responding in the consequence condition in 21 training sessions (189 training trials; 121 min, 32 s training time). Although Grant demonstrated an increase in unprompted correct responding following the initiation of training, we terminated training in the antecedent condition after 51 training sessions (459 training trials, 263 min, 18 s training time).
The antecedent and consequence choice conditions were similarly effective for Olivia. This finding is similar to the results for two participants from Peterson et al. (2016), who demonstrated similar patterns of responding during the antecedent and consequence choice conditions. Similar levels of responding across conditions may have occurred because the token exchange schedule was a fixed ratio 3. We selected this schedule to allow for multiple opportunities to choose the reinforcer within session and because it was similar to what was used in the participants’ typical programming. It is possible that differences across conditions may have emerged had the token exchange schedule been larger. Additionally, because the total number of exchange opportunities varied based on participant responding, it is possible that this variable also influenced responding. Future researchers may evaluate similar choice arrangements using longer response chains or leaner schedules of reinforcement to determine if antecedent or consequence choice is differentially sensitive to these variables. Additionally, it may be possible that differences may have emerged if moderately preferred (rather than highly preferred) items were arranged. It may be the case that the value of choice increases as item preference decreases, and researchers may consider evaluating the relative effects of item preference within the context of choice arrangements.
The consequence choice condition resulted in more efficient acquisition for Ted and Grant. Our finding that the consequence choice condition was most efficient for two participants differs from that of Peterson et al. (2016), who showed antecedent choice led to higher levels of responding for two participants. Our studies differed along a variety of dimensions such that these differences may have contributed to the inconsistent findings. We included unknown targets that required prompts and prompt-fading procedures, whereas Peterson et al. used mastered targets. Additionally, we used a token economy in which participants earned and exchanged tokens on a fixed-ratio schedule, whereas Peterson et al. arranged a progressive-ratio schedule and no token economy. The methodological differences combined with different outcomes suggest the need for future researchers to directly replicate Peterson et al. and identify the conditions under which antecedent and consequence choice are most beneficial. Nonetheless, our findings suggest that reinforcer choice following correct responding may lead to more efficient skill acquisition than antecedent choice does for some participants.
It is worth noting that a picture of a putative reinforcer was affixed to the token board in the antecedent condition but not in the consequence condition during participant responding. It is possible that the picture had discriminative effects that influenced responding. However, the stimuli associated with choosing (i.e., the choice board) were present in both conditions such that the influence of the picture on the token board per se is unknown. Additionally, all participants had recent histories with selecting reinforcers both prior to and following responding, although instructors tended to offer antecedent choice for the current participants. Although it is unknown the extent to which this history may have influenced responding in the current study, it may be a relevant variable for future researchers to evaluate (Coon & Miguel, 2012). We observed similar levels of responding—undifferentiation—across conditions for participants until mastery was achieved in one condition (Ted and Grant) or both conditions (Olivia). Although attempts were made to equate targets across sets, it is possible that faulty stimulus control may have developed such that an irrelevant feature of one or more stimuli in a set was exerting control over responding in some cases. Future researchers could conduct intrasubject replications to establish the generality of findings when teaching similar and different skills. Because the option to choose a reinforcer prior to or following task responding may influence the speed at which skills are acquired, thoughtful consideration should be employed in arranging reinforcement systems with students with ASD. Understanding the influence of choice parameters within skill acquisition programs can aid practitioners in determining optimal teaching arrangements.
Implications for Practice
-
1.
Evaluates relative effectiveness and efficiency of antecedent and consequence choice on the acquisition of auditory-visual conditional discriminations.
-
2.
Demonstrates that choice as a consequence can lead to more efficient acquisition for some participants.
-
3.
Provides a framework for practitioners to evaluate whether a choice of preferred items as an antecedent or consequence will lead to more efficient skill acquisition.
-
4.
Prompts consideration of assessing additional targets to evaluate the generalizability of results.
References
Coon, J. T., & Miguel, C. F. (2012). The role of increased exposure to transfer-of-stimulus-control procedures on the acquisition of intraverbal behavior. Journal of Applied Behavior Analysis, 45, 657–666. https://doi.org/10.1901/jaba.2012.45-657.
Dunn, M., & Dunn, L. M. (2007). Peabody picture vocabulary test (4th ed.). Circle Pines: AGS.
Fisher, W. W., Piazza, C. C., Bowman, L. G., Hagopian, L. P., Owens, J. C., & Slevin, I. (1992). A comparison of two approaches for identifying reinforcers for persons with severe and profound disabilities. Journal of Applied Behavior Analysis, 25, 491–498. https://doi.org/10.1901/jaba.1992.25-491.
Howell, M., Dounavi, K., & Storey, C. (2018). To choose or not to choose? A systematic literature review considering the effects of antecedent and consequence choice upon on-task and problem behavior. Review Journal of Autism and Developmental Disorders. Advance online publication. https://doi.org/10.1007%2Fs40489-018-00154-7.
Peterson, C., Lerman, D. C., & Nissen, M. A. (2016). Reinforcer choice as an antecedent versus consequence. Journal of Applied Behavior Analysis, 49, 286–293. https://doi.org/10.1002/jaba.284.
Sindelar, P. T., Rosenberg, M. S., & Wilson, R. J. (1985). An adapted alternating treatment design for instructional research. Education & Treatment of Children, 81, 67–76.
Sundberg, M. L. (2008). Verbal behavior milestones assessment and placement program: The VP-MAPP. Concord: AVB Press.
Toussaint, K. A., Kodak, T., & Vladescu, J. C. (2016). An evaluation of choice on instructional efficacy and individual preference among children with autism. Journal of Applied Behavior Analysis, 49, 170–175. https://doi.org/10.1002/jaba.263.
Williams, K. T. (2007). Expressive vocabulary test (2nd ed.). Minneapolis: Pearson Assessments.
Wolery, M., Gast, D. L., & Ledford, J. R. (2014). Comparison designs. In D. L. Gast & J. R. Ledford (Eds.), Single case research methodology: Applications in special education and behavioral sciences (pp. 297–345). New York: Routledge.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethical Approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
Informed Consent
Informed consent was obtained from all individual participants included in the study.
Conflicts of Interest
All authors declare they have no conflicts of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Gureghian, D.L., Vladescu, J.C., Gashi, R. et al. Reinforcer Choice as an Antecedent Versus Consequence During Skill Acquisition. Behav Analysis Practice 13, 462–466 (2020). https://doi.org/10.1007/s40617-019-00356-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40617-019-00356-3