
Abstract
The study investigated the development of lexical diversity and syntactic complexity, two key indicators of writing quality, in Chinese second language (L2) writing. The Guiraud Index and T-unit length were used to measure lexical and syntactic growth through a cross-sectional design. Seven hundred and sixty-five narrative essays were collected from grade 3–6 students in Singapore’s primary schools. Statistical analyses showed a general upward trend in lexical and syntactic development over the 4 years. In line with a dynamic account, the lexical and syntactic components grew in a non-linear and non-parallel manner with both progress and regress during the process. Furthermore, a trade-off was found between more varied word use and longer sentences in the data, though it faded with grade level. While L2 subsystems tended to compete with each other at earlier stages of language learning, their interactions changed over time. Moreover, variations were observed not only across grade levels but also between learner groups at the same stage of learning. By extending a dynamic approach to writing development at early stages of Chinese learning, the study informs theory regarding the dynamics of L2 growth and has significant implications for the teaching of Chinese writing in the Singapore context.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
A considerable amount of research has suggested that L2 writers’ lexical and syntactic repertoires significantly influence the quality of their texts (e.g., Engber 1995; Laufer and Nation 1995; Sasaki and Hirose 1996). In general, as L2 proficiency increases, learners’ texts display more sophisticated language use, such as wider range of vocabulary and more complex syntax. Relevant studies have typically compared groups of texts in terms of specific features, such as type-token ratio and sentence length, in order to identify the characteristics of different proficiency levels (cf. Leki et al. 2010). This approach, however, only presents a static view of writing products at one moment in time. It is necessary to recognize writing proficiency as a developmental process. Since learners have not mastered the language, their L2 system changes constantly, and developmental discrepancies may exist between subsystems (e.g., lexicon, syntax).
Research from a dynamic perspective looks at dynamic interactions between subsystems of a language as well as the developmental trajectories given different learner characteristics and environmental conditions. In contrast to a static account that focuses on learners’ attainment at a particular point in time, a dynamic account highlights iterative and varied change of a language system over time (de Bot et al. 2007). A central assumption underlying a dynamic account is that L2 development requires resources, including learner capacities (e.g., attention, aptitude, and motivation) and environmental resources (e.g., input, time, and learning materials). When resources are insufficient for distribution over subsystems, competition may appear. While subsystems may compete for resources, they may also support each other when a developmental level is achieved (Verspoor et al. 2008).
As a relatively new approach to L2 development, empirical data are necessary to verify the theoretical concepts against different learner populations and learning environments. While a few studies have examined L2 writing from a developmental view (e.g., Baba and Nitta 2014; Jiang 2012; Kobayashi and Rinnert 2013; Verspoor et al. 2008), the focus has predominantly been on Indo-European language learners and adults who have fully developed cognitive capacities. Further studies that investigate L2 writing development in a population of younger and non-Indo-European language learners are warranted. At a theoretical level, findings from such studies would help to build a comprehensive model of L2 development as a dynamic process across languages and age groups. Practically, they could elucidate to educators how different aspects of writing could change over time in various contexts, which serves as a reference for the design of curriculum and learning material. The current study was the first that explored L2 writing development of Singaporean Chinese learners at the primary level, focusing on measures of lexical diversity and syntactic complexity. The data could inform Chinese language teaching in the Singapore context by providing data on how students’ writing performance changed over the primary school years.
Dynamic Perspective on L2 Development
In the domain of L2 writing, empirical evidence for developmental discrepancies between lexicon and syntax has emerged only recently. Verspoor et al.’s (2008) longitudinal data indicated that while an advanced English learner’s academic writing proficiency generally increased over a three-year period, the developmental trajectory was non-linear with alternating progress and regress. Furthermore, there appeared a trade-off between more varied word use and longer sentences, though the negative correlation was weak. The authors argued that the lexical and syntactic aspects of the L2 system might not develop simultaneously due to limited cognitive and environmental resources. Adopting a cross-sectional design, Verspoor et al. (2012) investigated L2 writing development more broadly through comparing samples from beginning- to intermediate-level Dutch learners of English. Competition between lexicon and syntax was likely to occur at early stages of L2 development. After a lexical threshold was reached, the learner then focused on syntactic complexity. At later stages, lexical and syntactic subsystems supported each other and developed simultaneously. The authors noted that the observations were made on a particular group of learners at a specific environment and thus required further evidence for generalization.
While the two studies illuminated the dynamics of L2 writing development, no conclusions can be drawn regarding whether a significant link exists between lexicon and syntax and how they compete or support each other in the developmental course. Furthermore, the studies involved advanced or college-level learners. Given that language proficiency and age are key variables in L2 writing, it is possible that growth patterns differ across learner groups. Thus, there is a great need for a broader empirical data base before theoretical formulations of L2 writing development are made. The present study attempted to contribute to the emerging literature by examining L2 writing development in Chinese. Employing a cross-sectional design, the study compared essays written by Chinese learners from grade 3, 4, 5, and 6 in Singapore primary schools. The four grade levels represent progressive stages of writing development—from the point of starting to write Chinese essays to the point of completing the primary education. The investigation focused on how lexical diversity and syntactic complexity changed over time in young Chinese learners’ writing and how the two components interact with each other.
Indices of Lexical Diversity and Syntactic Complexity in Written Production
As an integral part of lexical competence, lexical diversity refers to the range and the variety of vocabulary utilized in a text (van Hout and Vermeer 2007). It is typically measured through a type-token ratio (TTR), a ratio of the total number of words to the number of unique types of words, indicating how often a new word type appears in a text. The higher the ratio, the more lexical diversity there is. A problem with the simple algorithm of TTR is its sensitivity to text length, as the ratio falls with the increasing number of tokens. In order to minimize the effect of text length, the study adopted the Guiraud Index of lexical diversity. The mathematical transformation of TTR is calculated by dividing the number of types by the square root of the number of tokens (Guiraud 1954, as cited in Daller and Xue 2007). The Guiraud Index is more stable than the base TTR and is useful in distinguishing among L2 proficiency levels (Daller and Xue 2007; van Hout and Vermeer 2007). In a review of 39 studies conducted between 1974 and 1995, Wolfe-Quintero et al. (1998) found that adjusted TTR was one of the best indices of lexical diversity. Research has also revealed high correlations between the Guiraud Index and other widely accepted indicators of lexical diversity, such as the D-measure (Treffers-Daller 2013).
The premise behind lexical diversity measures is that more diverse lexicon indicates higher vocabulary proficiency. Two recent studies (Crossley et al. 2011a; Crossley et al. 2012) demonstrated that lexical diversity was a significant predictor of lexical proficiency scores rated by human experts in L2 written samples. Longitudinal data suggested that generally learners’ lexicon became more diverse over the course of L2 development and that lexical diversity measures reflected differences between L2 developmental stages (e.g., Bulté et al. 2008; David 2008). Lexical diversity has also been shown positively correlated with the quality of written texts (e.g., Engber 1995; Grant and Ginther 2000; Yu 2009).
The measurement of lexical diversity is challenging in Chinese as the language has very few inflectional morphemes that could indicate syntactic functions of words. For example, in the sentence wǒ huà le yīfú huà ‘I painted a painting’ the second and the last word are identical in form but are considered to be two word types because the former is a verb and the latter is a noun. In the present study, part-of-speech (POS) tagging was used to identify word types based on their syntactic distributions. All the words were manually labeled with POS-tags according to the Part-of-Speech Tagging Guidelines for the Penn Chinese Treebank (3.0) (Xia 2000b). The POS tagset has 33 tags, which have been used to annotate the Chinese Treebank, a widely used corpus that currently has 500 thousand words (Xue et al. 2005). Lexical diversity is higher if a word is used in different than in the same syntactic contexts.
In addition to lexical diversity, syntactic complexity is a very important indicator of L2 development. Syntactic complexity is defined as the range of syntactic structures and their degree of sophistication in language production (Ortega 2003). Among a variety of measures, T-unit length is most extensively employed, as it is robust and easy to compute (Wolfe-Quintero et al. 1998). A T-unit, or minimal terminable unit of language, is the shortest amount of words that could form a grammatical sentence (Hunt 1970). A T-unit contains only one independent clause plus all the subordinate clauses attached to it. Coordinate clauses joined by coordinating conjunctions are considered different T-units. Jiang (2012) applied T-unit measures to L2 Chinese writing development, where a T-unit was defined as “A single main clause that contains one independent predicate plus whatever other subordinate clauses or non-clauses are attached to, or embedded within, that one main clause.” For example, the complex sentence nàgè cōngmíng de nánhái hěn huì dǎ lánqiú ‘The boy who is smart plays basketball very well’ is considered to be one T-unit, while the compound sentence nàgè nánhái hěn cōngmíng, érqiě tā hěn huì dǎ lánqiú ‘The boy is very smart, and he plays basketball very well’ is considered to be two T-units. A longer T-unit usually indicates greater syntactic complexity with more subordination, relativization, and/or more non-clausal phrases. While immature writers often string together short, simple T-units, they gradually consolidate more ideas into fewer but longer T-units as the syntactic system develops.
A large number of studies have confirmed that T-unit length is a reliable measure of syntactic maturity and serves as a valid index of L2 proficiency in written production (e.g., Lu 2011; Verspoor et al. 2012; Henry 1996; Ishikawa 1995). Similar to previous studies on English learners, Jiang (2012) found that Chinese L2 learners produced increasingly longer T-units over three years. In addition to its reliability, T-unit length is widely used because a T-unit is easily identifiable and requires minimal syntactic parsing (Mackey and Gass 2005). This is especially crucial to L2 teachers and language program administers who need an effective and straightforward means to measure the learners’ level of proficiency (Larsen-Freeman 1983). Although some sentence-based complexity indices are also useful (e.g., sentence length), the boundary of a Chinese sentence is unclear and often difficult to define due to the lack of formal marks, the nature of thematic prominence, and the frequent omission of major sentence components (Ho 1993). Szmrecsanyi (2004) demonstrated comparable results obtained via three measures of syntactic complexity—word counts, node counts, and counts of markers of embeddedness—and hence recommended length as a most time-effective and straight forward proxy for syntactic complexity.
Method
The present study investigated L2 writing development of young Chinese learners in Singapore, an ethnically and linguistically diverse country that embraces a bilingual education policy. While English serves as the medium for all content-area education, the student’s ethnic mother tongue is required as a single subject (Dixon 2005). Over the decades, English has held its dominant status in education, business, and government administration. In the predominantly English-speaking environment, students learn Chinese from the first grade and start to write essays from the third grade (2007 Chinese Language (Primary) Syllabus).
The study analyzed writing samples of Singaporean students at grade 3, 4, 5, and 6, from the time they are required to write Chinese essays till the end of their primary education. Analyses focused on lexical diversity, measured by the Guiraud Index, and syntactic complexity, measured by T-unit Length. The objectives of the study were two folds. The first was to uncover the patterns of lexical and syntactic development of young Chinese learners in the Singapore context. The second was to examine the interaction between lexicon and syntax at different stages of L2 learning. Cross-sectional comparisons were performed among four levels of writing in order to gain insight into the changes over the developmental course.
Writing Samples
The writing samples used in this study were collected from the students who had grown up in predominantly English-speaking homes. The participating students were all Chinese with Min, Cantonese, or Mandarin as a heritage language. A home language survey was administered to the students to determine what language(s) they spoke at home. All the students included in the study most often spoke English with their family members and friends, and English was the language they first spoke. They had started to learn Chinese as a subject from the first grade in English-medium schools. To these students, Chinese was offered as a second language. They had cultural heritage but did not have regular exposure to Chinese at home (Reynolds et al. 2009).
These students were from three primary schools with different levels of average scores in the Primary School Leaving Examination (PSLE) Chinese examination. School A had achieved results well above the national average; School B had scored around the national average; School C had been below the national average. All the students in these schools followed the regular stream of Chinese language education, where Chinese was taught as a single subject from the first grade, while all the other subjects were instructed in English.
The writing samples were all narratives written in class with the same topic across schools and grade levels. The topics included yījiàn nánwàng de shì ‘an unforgettable event’ and kuàilè de yìtiān ‘a happy day,’ which were familiar to students and closely related to their daily life. The data collection took place in the second semester for all the four grade levels. The sampling included grade 3–6 from each of the three schools—188 samples for grade 3, 195 for grade 4, 193 for grade 5, and 189 for grade 6. Altogether, 765 essays were collected.
Data Processing and Analysis
The data were processed according to the following steps. The handwritten texts were first typed into electronic files, where non-existing Chinese characters were replaced with the correct alternatives. The minimal alternations were for the convenience of data input and processing while maintaining the writer’s original meaning. The percentage of the replaced characters was only around 1.4 % of the total number of tokens and thus had little influence on the result of lexical complexity analysis. Next, since Chinese has no space between words, the raw data were segmented into lexical items using the Stanford Word Segmenter (Green and DeNero 2012), an open source tool for word segmentation in Chinese, followed by manual checking to ensure accuracy. All the words were manually labeled with POS based on the tagset of the Penn Chinese Treebank. Words with different POS were regarded as different word types. T-units were then identified according to the definition in Jiang (2012), and the length of a T-unit was measured in terms of words. To ensure the reliability of annotation, the data processing involved double checking by two Chinese-speaking researchers who had received training on 10,000 sentences. During the training session the researchers compared their annotations and discussed the conflicting cases in order to bring a consensus among them. Finally, the Guiraud Index and T-unit length were computed for each writing sample to indicate lexical diversity and syntactic complexity, respectively. The group Guiraud Index and T-unit length were then calculated by averaging the value of each text.
Statistical analyses examined Chinese learners’ lexical and syntactic growth across grade levels. A one-way between-groups analysis of variance (ANOVA) was performed for each of the Guiraud Index and T-unit length in order to reveal the effect of grade level on the two target measures. The level of statistical significance was set at 0.05 and for all pairwise comparisons following any ANOVA significant results.
Results
Development of Lexical Diversity
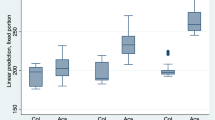
The Guiraud Index was computed for each grade level and each school. As shown in Table 1 and Fig. 1, there was an overall positive growth for the measure of lexical diversity in the writing samples, with an average of 7.20 for grade 3, 7.90 for grade 4, 8.98 for grade 5, and 9.05 for grade 6. When looking at the data of each school, the developmental trends varied. School C exhibited a continuous rise in lexical diversity with a significant increase from grade 5 to 6, whereas the value of the Guiraud Index decreased during the last year for School A and B.

Distribution of the Guiraud Index by grade level and school
A one-way ANOVA showed that there was a significant main effect of grade level on lexical diversity (F[3761] = 124.68, p = .000). Tukey’s post hoc comparisons of grade levels revealed significant differences in lexical diversity for all pairs (p = .000) except between grade 5 and 6 (p > .05). Levene’s test of equality of error variances was not significant (p > .05), indicating that the assumption of homogeneity of variances was fulfilled across groups.
Development of Syntactic Complexity
Average T-unit length was computed for each grade level and each school. Table 2 and Fig. 2 show that syntactic complexity generally increased with grade level −5.03 words for grade 3, 5.18 words for grade 4, 5.46 words for grade 5, and 5.70 words for grade 6. As in the lexical measure, the patterns of syntactic development differed across schools. School A and B demonstrated increasingly longer T-units in their writing from grade 3–6, whereas School C remained almost unchanged from grade 5 to 6.

Distribution of T-unit length by grade level and school
A one-way ANOVA indicated a significant effect of grade level on average T-unit length (F[3761] = 51.77, p = .000). Tukey’s post hoc tests confirmed significant differences between all grade levels (p < .05). Levene’s test revealed that the assumption of equal variances was met (p > .05).
Correlation between Lexical Diversity and Syntactic Complexity
In order to examine the relationship between the lexical and syntactic aspects of L2 writing, correlations were calculated using Spearman’s rho non-parametric correlation coefficients, given that developmental data are unlikely to be normally distributed.
Correlation analysis was performed for each grade level, and the results indicated changing patterns of interaction between lexicon and syntax. For grade 3 and 4, a significant negative correlation existed between the lexical and syntactic measures, with r = −.23 and r = −.19, respectively (p < .01). That is, increased diversity in lexical choice tended to accompany decreased complexity in synaptic construction, and vice versa. The negative correlation became even weaker and marginally significant at grade 5 (r = −.14, p = .06). For grade 6, the correlation turned positive but was very weak and statistically insignificant (r = .08, p > .05). At this stage, there was no clear link between lexical diversity and syntactic complexity.
In short, as indicated by the negative correlation between lexical diversity and syntactic complexity, competition did occur between the two components, especially in the earlier stages of L2 learning. Furthermore, the competition appeared to weaken with levels of development and showed a tendency of turning into a mutually supportive interaction. The findings suggested there was indeed an interactive relationship between L2 lexicon and syntax and that their interactions yielded varied patterns during the developmental course.
Discussion
The first research question of the study concerned the patterns of lexical and syntactic development over 4 years of Chinese learning. It was addressed by comparing writing samples of learners from grade 3 to grade 6 in primary school. In general, the results indicated positive growth in lexical diversity and syntactic complexity across grade levels. In other words, there was an upward trend over time in both measures, which paralleled the findings from previous studies on writing development in Indo-European languages (e.g., Spoelman and Verspoor 2010; Verspoor et al. 2008). The second research question of the study addressed the interaction between the measures of lexical diversity and syntactic complexity during L2 writing development. When looking at data from each grade level, a trade-off occurred between a more varied word use and longer T-units in the writing. An increase in lexical diversity coincided with a decrease in syntactic complexity and vice versa, though the competitive relationship became weaker over the years. The allocation of attention to one aspect of writing might be at the expense of the other due to resource limitations (Skehan 2009). The finding was consistent with Verspoor et al.’s (2012) argument that lexicon-syntax competition was more likely to occur at early stages of L2 learning.
The findings demonstrated that although there was a positive developmental trend over time, L2 components develop in a non-linear and non-parallel manner. The growth of lexicon and syntax were in different rates and showed varied interaction patterns at different points in time. In other words, the growth was not a function of time alone but was affected by complex internal and external variables. While Verspoor et al. (2008)’s microgenetic data pointed to a trend toward a possible competitive relation between the two language components, the present study demonstrated a significant, though weak, negative correlation between them. On the one hand, there exists evidence from various languages and learner groups showing that lexical and syntactic development is disparate, with competition dominating mutual support, especially at early stages of learning. On the other hand, the competitive relationship between lexical diversity and syntactic complexity seems not strong, as suggested by the weak correlation found in all previous research.
In particular, the negative correlation faded with grade level in the present study. It is possible that as learners’ language proficiency increased, the lexical and syntactic processes consumed less resources, resulting in less competition. It is also likely that the learners paid more attention to certain aspects of the language and/or adopted specific learning or writing strategies as they prepared for the upcoming PSLE at the end of the sixth year. To improve their PSLE scores, 6 graders were usually required to memorize model essays and consider various aspects of essay writing, such as content, essay structure and format in addition to language usage. For one thing, students’ cognitive resources might have been spread over a variety of tasks, resulting in selection of information that gained access to working memory. For another, students might have concentrated on particular aspects of learning due to availability of time and/or input from teachers. From a dynamic perspective, no single factor can directly explain the change of a language system. Further investigation is necessary to confirm whether the lexicon-syntax correlation would turn into positive or become disconnected as learners proceed to even higher levels of L2 development.
A similar finding in the current study and Jiang (2012) was that T-unit length generally increased with proficiency level in L2 writing. The main effect of proficiency level was significant. Nevertheless, the average T-unit length obtained in this study (5.03–5.70 words) was smaller than that in Jiang’s study (6.67–7.20 words). The two studies differed in learner characteristics and task type. First, the writing samples in this study were produced by 3–6 graders who received Chinese instruction from grade 1, whereas those in Jiang (2012) were written by college students in their first, second, and third year of Chinese learning. It was noteworthy that, compared to the younger writers, the college-level writers used longer sentences even though they had learned the language for a relatively short time. The distinction in syntactic complexity between the two groups of writers could be due to learner variables as well as the related instructional differences. Moreover, while Jiang (2012) utilized a letter-writing task, the current study involved writing of narratives. The writing tasks chosen could affect syntactic production.
Variation across learner groups was also observed in the present study. The data of School A, B, and C deviated from the general upward trends in both indicators and differed from each other across grade levels. School A and B showed an increase in syntactic complexity but a decrease in lexical diversity from grade 5 to 6, whereas School C showed a significant positive growth in lexicon but no change in syntax during the same period. The deviations of the individual school cases were likely to reflect sampling errors due to the fact that the study only included a limited number of participants from three schools with different levels of average scores in PSLE Chinese. A larger sample would help to reduce the impact of sampling errors. Furthermore, the individual school results suggested that both progress and regress are integral to L2 development and that the lexical and syntactic development of these sub-groups were affected by variables other than grade level. Variation in the data could not be solely attributed to the factor tested.
In sum, the findings in the current study are very much in line with those in the previous research showing that L2 subsystems develop in a non-linear and non-parallel manner and have a changing relationship to each other over time. It is important to note that the purpose of the current study was not to present a generalization regarding Chinese learners’ performance. Rather, it was intended to bridge the gap between generalization and individual differences in L2 writing development. On the one hand, this study demonstrates that it is difficult to discriminate consistently among the levels of L2 writing proficiency based on a single index or even a set of indices, given that considerable variation exists between language components and between learner groups. While some learners might perform better in one aspect of language usage than in another, a distinct pattern could be found for other learners at the same stage of learning. L2 development is unpredictable because it emerges from constant and complex interactions between the system, the environment, and the internal sources (de Bot et al. 2007). On the other hand, group norms could still reflect individual variation and vice versa. The findings in the current research are consistent with those from microgenetic studies (e.g., Spoelman and Verspoor 2010; Verspoor et al. 2008) in two aspects. First, lexical diversity and syntactic complexity tend to rise with grade level regardless of learners’ L1 background, L2 proficiency, age of learning, etc. Moreover, competition occurs between the lexical and syntactic components, despite different interactive patterns reported by various studies. In fact, developmental research has suggested that microgenetic and cross-sectional data are highly comparable with respect to the patterning of change when the overall amount of change is similar (Siegler 2006; Siegler and Svetina 2002).
Conclusion
The investigation extended a dynamic approach to L2 writing development at early stages of Chinese learning. While the growth patterns may not be generalizable to other populations, they show that writing development is a multi-dimensional phenomenon characterized by varying interaction between language components at different learning stages. Building on this study, further research is needed in order to better understand the dynamic nature of L2 writing development. While the present study only focused on lexical diversity and syntactic complexity, it is worthwhile to examine other lexical and syntactic measures as well as their interactive relationships. Moreover, there is a need to investigate L2 Chinese development in a longitudinal study, which will facilitate inspection of language use with regard to temporal changes. This would allow a comparison with the results obtained from this cross-sectional study, which only measured language growth at four time points over 4 years.
A key pedagogical implication of dynamic L2 development is that language pedagogy has to be process-oriented. The process of learning entails changes in the L2 system, which bring a generally upward trend in the proficiency of language use. In this regard, pedagogy should aim at enacting change rather than concentrate on an error-free end product. Moreover, the learner may not be able to distribute their resources to multiple dimensions of writing simultaneously. Thus, the instructional design has to be recursive, helping the learner to approach writing in manageable steps and allowing them to reconsider their work. Finally, since various components of the L2 system are interconnected, change in one component may be related to variation in others. This explains why there is no simple cause–effect relationship between teaching and learning. Rather, multiple factors can cumulatively lead to learning. This suggests the importance of taking a holistic view of instruction and remaining adaptive in teaching practice by actively reflecting on the dynamics of a learner group.
References
Baba, K., & Nitta, R. (2014). Phase transitions in the development of writing fluency from a complex dynamic systems perspective. Language Learning, 64(1), 1–35.
Bulté, B., Housen, A., Pierrard, M., & van Daele, S. (2008). Investigating lexical proficiency development over time: The case of Dutch-speaking learners of French in Brussels. French Language Studies, 18, 277–298.
Crossley, S. A., Salsbury, T., & McNamara, D. S. (2012). Predicting the proficiency level of language learners using lexical indices. Language Testing, 29(2), 240–260.
Crossley, S. A., Salsbury, T., McNamara, D. S., & Jarvis, S. (2011). Predicting lexical proficiency in language learners using computational indices. Language Testing, 28(4), 561–580.
Daller, H., & Xue, H. (2007). Lexical richness and the oral proficiency of Chinese EFL students. In H. Daller, J. Milton, & J. Treffers-Daller (Eds.), Modelling and assessing vocabulary knowledge (pp. 150–164). Cambridge: CUP.
David, A. (2008). A developmental perspective on productive lexical knowledge in L2 oral interlanguage. French Language Studies, 18, 315–331.
de Bot, K., Lowie, W., & Verspoor, M. (2007). A dynamic systems theory approach to second language acquisition. Bilingualism, Language and Cognition, 10, 7–21.
Dixon, L. Q. (2005). Bilingual education policy in Singapore: An analysis of its sociohistorical roots and current academic outcomes. International Journal of Bilingual Education and Bilingualism, 8(1), 25–47.
Engber, C. (1995). The relationship of lexical proficiency to the quality of ESL compositions. Journal of Second Language Writing, 4(2), 139–155.
Grant, L., & Ginther, A. (2000). Using computer-tagged linguistic features to describe L2 writing differences. Journal of Second Language Writing, 9, 123–145.
Green, S., & DeNero, J. (2012). A class-based agreement model for generating accurately inflected translations. Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, 1, 146–155.
Henry, K. (1996). Early L2 writing development: A study of autobiographical essays by university-level students of Russian. The Modern Language Journal, 80(3), 309–326.
Ho, Y. (1993). Aspects of discourse structure in Mandarin Chinese. Liangton: Edwin Mellen.
Hunt, K. W. (1970). Recent measures in syntactic development. In M. Lester (Ed.), Reading in applied transformational grammar (pp. 179–192). Nueva York: Holt, Rinehart and Wiston.
Ishikawa, S. (1995). Objective measurement of low-proficiency EFL narrative writing. Journal of Second Language Writing, 4(1), 51–69.
Jiang, W. (2012). Measurements of Development in L2 Written Production: The Case of L2 Chinese. Applied Linguistics, 34, 1–24.
Kobayashi, H., & Rinnert, C. (2013). L1/L2/L3 writing development: longitudinal case study of a Japanese multicompetent writer. Journal of Second Language Writing, 22, 4–33.
Larsen-Freeman, D. (1983). Assessing global second language proficiency. In H. Seliger & M. Long (Eds.), Classroom oriented research in second language acquisition. Rowley, MA: Newbury House Publishers.
Laufer, B., & Nation, P. (1995). Vocabulary size and use: lexical richness in L2 written production. Applied Linguistics, 16(3), 307–322.
Leki, I., Cumming, A. H., & Silva, T. (2008). A synthesis of research on second language writing in English. New York, NY: Routledge.
Lu, X. (2011). A corpus-based evaluation of syntactic complexity measures as indices of college-level ESL writers’ language development. TESOL Quarterly, 45(1), 36–62.
Mackey, A., & Gass, S. M. (2005). Second language research: Methodology and design. Mahwah, NJ: Lawrence Erlbaum.
Ortega, L. (2003). Syntactic complexity measures and their relationship to L2 proficiency: A research synthesis of college-level L2 writing. Applied Linguistics, 24, 492–518.
Reynolds, R. R., Howard, K. M., & Deak, J. (2009). Heritage language learners in first-year foreign language courses: A report of general data across learner subtypes. Foreign Language Annals, 42(2), 250–269.
Sasaki, M., & Hirose, K. (1996). Explanatory variables for EFL students’ expository writing. Language Learning, 46, 137–174.
Siegler, R. S. (2006). Microgenetic analyses of learning. In W. Damon, R. Lerner, D. Kuhn & R.S. Siegler (Eds.), Handbook of child psychology: Vol 2. Cognition, perception, and language (6th ed.). Hoboken, NJ: Wiley.
Siegler, R. S., & Svetina, M. (2002). A microgenetic/cross-sectional study of matrix completion: Comparing short-term and long-term change. Child Development, 3, 793–809.
Skehan, P. (2009). Modeling second language development: Integrating complexity, accuracy, fluency, and lexis. Applied Linguistics, 30, 510–532.
Spoelman, M., & Verspoor, M. (2010). Dynamic patterns in development of accuracy and complexity: A longitudinal case study in the acquisition of Finnish. Applied Linguistics, 31, 532–553.
Szmrecsanyi, B. (2004). On operationalizing syntactic complexity. Jadt-04, 2, 1032–1039.
Treffers-Daller, J. (2013). Measuring lexical diversity among L2 learners of French: an exploration of the validity of D, MTLD and HD-D as measures of language ability. In S. Jarvis & M. Daller (Eds.), Vocabulary knowledge: Human ratings and automated measures (pp. 79–104). Amsterdam: Benjamins.
van Hout, R., & Vermeer, A. (2007). Comparing measures of lexical richness. In H. Daller, J. Milton, & J. Treffers Daller (Eds.), Modelling and assessing vocabulary knowledge (pp. 93–115). Cambridge: CUP.
Verspoor, M., Lowie, W., & van Dijk, M. (2008). Variability in second language development from a dynamic systems perspective. The Modern Language Journal, 92, 214–231.
Verspoor, M., Schmid, M. S., & Xu, X. (2012). A dynamic usage based perspective on L2 writing. Journal of Second Language Writing, 21(3), 239–263.
Wolfe-Quintero, K., Inagaki, S., & Kim H.-Y. (1998). Second language development: Measures of fluency, accuracy & complexity. Hawaii: Second Language Teaching and Curriculum Center, University of Hawaii Press.
Xia, F. (2000b). The part-of-speech tagging guidelines for the Penn Chinese Treebank (3.0). IRCS Report 00–07. Philadelphia, PA: University of Pennsylvania.
Xue, N., Xia, F., Chiou, F.-D., & Palmer, M. (2005). The Penn Chinese Treebank: Phrase structure annotation of a large corpus. Natural Language Engineering, 11(2), 207–238.
Yu, G. (2009). Lexical diversity in writing and speaking task performances. Applied Linguistics, 31(2), 236–259.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Hsieh, Y. An Exploratory Study on Singaporean Primary School Students’ Development in Chinese Writing. Asia-Pacific Edu Res 25, 541–548 (2016). https://doi.org/10.1007/s40299-016-0279-0
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40299-016-0279-0