
Abstract
This study examines the impact of improved rice varieties on household wellbeing measured by headcount poverty reduction and household total annual consumption across different agroecological regions of Nepal by using cross-sectional data of Nepal living standard survey III. The propensity score matching method was used to evaluate the impact on wellbeing of adopter and non-adopter farmers. The results indicate that adoption of improved rice varieties increased the adopter households’ annual agricultural earning and consumption expenditure by almost US$ 153–185 and US$ 643–907, respectively. Adoption of rice varieties has statistically significant and positive welfare effects on large and small farmers compared to the medium farmers. Large and small farmers on the other hand tend to have more impact on household expenditure and agricultural earning as compared to the medium farmers. Technological adoption has statistically significant and negative impact on poverty among the large farmers. We conclude that an investment on breeding research and wider dissemination of improved crop varieties will help to enhance household wellbeing and reduce poverty of the farmers.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Agriculture contributes more than one-third to the total gross domestic product (GDP), and it is a main source of employment for nearly two-third of the total workforce in Nepal [15]. Among different crops grown in different agroecologies of Nepal, rice is the main staple food crop that contributes 50 % of food requirement. Low-lying flood plain (Terai region) is the food basket of Nepal contributing three quarter of the rice production [31]. With average productivity around 2.56 t/ha, rice covers 1440 thousand hectares (ha) of land and contributes almost one-fifth of total gross domestic production (GDP) and nearly a half of the agricultural gross domestic product (AGDP) comes from rice alone. Although production and productivity of rice in Nepal increased during last four decades, productivity of this crop is still very low compared to other South Asian countries [34].
The Nepalese government has designed various plans and programs to alter the state of agricultural system of Nepal and to provide benefit to a large number of growers in the country. Nepal Agriculture Research Council (NARC) is responsible to breed improved varieties suitable for different climatic conditions, and Department of Agriculture (DOA) is mandated to disseminate improved agrotechnologies to the farmers. Almost 55 improved rice varieties have been released over the period of 40 years [34], and these varieties have been disseminated to the farmers in different parts of Nepal. Despite all of the pro-farmers strategies to promote the adoption of improved agrotechnologies including varieties, very limited have been achieved so far [23]. Demand of cereals exceeds supply which makes Nepal one of the most food insecure countries [26]. Agricultural innovations and technological improvements can increase the production, enhance food security, increase farm income and also reduces production risks [12].
Agriculture influences household wellbeing indirectly through providing employment, savings and expenditure [18]. De Janvry et al. [19] classified agricultural technology into different categories: yield-increasing and cost-saving technology, risk-mitigating technology, quality improving technology and technologies that alter externalities. Several studies [5, 6, 9, 35, 36, 39] found the positive and significant impact of adoption of improved varieties on household welfare measured by household income, household expenditure and reduction in poverty. For instance, adoption of improved maize varieties had significant positive impact on household welfare measured in terms of per capita expenditure in Mexico [9]. Adoption of NERICA rice varieties had significantly enhanced technical efficiency of smallholder rice producers in Ghana [6] and impacted significantly on household expenditure in Benin [1]. Adoption of improved technologies on producing different crops significantly reduced household poverty [36, 39], enhanced food security [33, 35], improved farm assets profile [37] and increased adaptive capacity of the farmers under volatile climatic conditions [10, 13].
In Nepal, La Rovere et al. [28] examined the impact of hill maize research project on improving livelihood by using participatory research tool. Various studies conducted in Nepal used descriptive analysis to show the significance of adoption of improved varieties, but empirical studies to evaluate the impact of improved rice varieties on household wellbeing by using propensity score matching are lacking. The propensity score matching (PSM) approach controls for the self-selection issue, where treatments are non-randomly assigned in observational studies [29]. This study aims to bridge the research gap by applying propensity score matching (PSM) to evaluate the impact of improved rice varieties on household wellbeing by using the nationally representative data collected from all agroecological regions of Nepal. Since different group of farmers based on land holdings benefit differentially through varietal adoption, we wanted to examine the differential impact of adoption of improved rice varieties on wellbeing and poverty across land holding sizes. Since notion of household economic wellbeing is multi-dimensional and is better understood by examining simultaneously at household income and household expenditure, there are definitional and scope issues with respect to measuring each of these items. It is worthwhile to look at these elements comprehensively to ensure that all the measures of wellbeing are taken into account critically [30]. Thus, the proposed study used both household earning and household expenditure as the main indicators of wellbeing.
Sampling and Sources of the Data
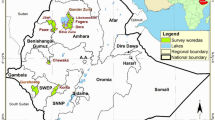
The current study used secondary data, which consists of large data set of farm household of Nepal living standard survey (NLSS) III (2010/11) of Central Bureau of Statistics (CBS), Nepal [14]. NLSS survey covers multiple topics related to household welfare. CBS already conducted two Surveys (NLSS I in 1995/96 and NLSS II in 2003/2004), and all of these surveys adopted Living Standard Measurement Survey (LSMS) methodology developed by World Bank [24]. Total sample size of the survey was 7200 households selected from 600 primary sample units (PSUs). The PSUs consist of either individual wards or sub-wards or groups of contiguous wards in same Village Development Committee (VDC) and ensure that each PSU contains at least 30 households. Among them, 100 PSUs with 1200 households interviewed in the NLSS I or NLSS II were selected for re-interviewing in the NLSS III and rest of the 6000 households were selected from 500 PSUs as the cross-sectional samples. The PSUs were selected with probability proportional to size, the measure of size being the numbers of households in each ward. A total of 12 households were enumerated from each of the selected PSUs.Footnote 1 The total of 3350 sample households out of 7200 households, who own land, have been selected purposively from all the three agroecological regions. The household interviewed throughout the country is presented in Fig. 1.

Map of Nepal showing sampled households
NLSS provides large numbers of data set on agricultural activities including the demographic characteristics, wage, income from farm and non-farm activities, and employment status of both agricultural and non-agricultural sectors, loan status of the households, land sizes, consumption expenditure in various food and non-food activities and inputs used for the production of various crops in different ecological regions. The distribution of the sampled households as per land size shows that more than half of the households (53 %) are smallholders (<0.5 ha) (Table 1). Among them, approximately 8 % are adopters and around 46 % households are non-adopters. Likewise, a little more than two-fifths households are medium land holders (0.5–2 ha) and nearly the lowest (6 %) sample households are large land holders (>2 ha). Not much difference is observed in the land size categories between adopter and non-adopter households. In other word, it does not indicate any stable correlation between land holdings and technological adoption.
Empirical Methodology
Poverty Index
The existing literatures [7, 17, 29, 35, 37] show that technological adoption has positive and significant impact on households’ wellbeing. Economic wellbeing in this study is measured by proxy criteria such as total household food and non-food expenditure, annual household agricultural earning and headcount poverty reduction based on the household food and non-food expenditure over the last 12 months. Mendola [29] used per capita income level to measure the headcount poverty. We used per capita annual consumption expenditure as proxy criteria for impact on poverty as mentioned in Asfaw et al. [8]. The Foster–Greer–Thorbecke (FGT) method was used to calculate poverty index. Based on FGT, poverty indicators such as headcount poverty index, poverty gap ratio and severity of poverty were calculated as:
where P α is the FGT poverty measures; N is the total number of households; q is the number of poor households; µ is the poverty line; y i is the income of the poor household i.
Different values of α (α = 0, 1, 2) provide different measures of poverty. When α = 0, the poverty measure \(P_{0}\) is the incidence of poverty that is proportion of households whose income is below the poverty line. When α = 1, \(P_{1}\) is the poverty gap measure. The poverty gap is equal to the incidence of poverty multiplied by the average gap between the poverty line and the income of a poor household, expressed as a percentage of the poverty line. Thus, it takes into account the depth of poverty. If α = 2, \(P_{2}\) takes into account the degree of inequality among the poor households, as well as the depth of the poverty and number of poor households. This poverty-gap squared is referred to as a severity of poverty [22].
There are several factors, which might have influenced the household wellbeing. Simply attributing difference in the household wellbeing between technology adopters and non-adapters is tricky and biased without considering others methodological issues such as data type, sampling procedures, selection of comparison groups. To precisely measure the impact of program intervention (adoption of improved rice varieties, for instance) on the outcome variable such as household wellbeing, the exposure to the technology should be randomly assigned. By doing so, the effects of observable and unobservable characteristics between the control and intervention groups are the same. This random assignment produces impact that is completely attributable to the program intervention. On the contrary, when the program intervention is non-randomly assigned, adoption decisions are expected to be influenced by both observable and non-observable heterogeneity that might be correlated with the outcome variable [35].
While the experimental data are collected through randomization process, information on the counterfactual would be normally obtained and causal inference would be resolved. But in the case of non-experimental data where data are collected from cross-sectional survey, counterfactual situation cannot be identified. Balancing test is normally conduced to identify counterfactual situation to figure out whether the differences among covariates have been eliminated between the two groups of the matched sample. In that time, comparison group is considered as possible counterfactual [4]. When adoption is not randomly distributed and the households are self-selected for the intervention, the adopters and non-adopters may be systematically not similar [5]. The causal effect obtained by comparing a treatment group with a non-experimental group could be biased because of problems of self-selection or systematic judgments. PSM is used to correct the issue of self-selection bias due to difference in observed characteristics between comparison and control group [20, 36]. To examine the factors which influence farmers’ decision to adopt improved rice varieties in different agroecological regions of Nepal, we used a logit model. Logistic regression is used to find out the key determinants of farmers’ decision on adoption of improved agrotechnologies [2, 7, 32].
Propensity Score Matching (PSM) Technique
Matching involves the comparison of treatment and control units which are similar in terms of their observable characteristics. When the actual difference between any two groups is captured in the observable (pre-adoption) covariates, matching can provide unbiased estimates of the treatment effects [20]. One of the important features of propensity score matching (PSM) is that unmatched units will be thrown away, once the units are matched for estimating the treatment impact. Various studies [5, 6, 9, 16, 33, 35–37, 39] have applied nonparametric PSM test to evaluate the impact of technological adoption on household’s wellbeing. PSM is applied, where program intervention is not randomly assigned and self-selection into the treatment might lead to a biased result [35]. The decision to adopt technology will be determined by a set of socioeconomic variables, and these household socioeconomic characteristics also affect household wellbeing. For instance, technology adoption may be positively related to household wellbeing. In this case, the relationship among technology adoption, household wellbeing and economic status of the household is confounded [36]. It may be likely that those who have already been economically empowered would have higher chance of adopting technology or household’s economic status has been enhanced due to technological adoption. Such non-random program assignment leads to self-selection. To tackle the issue of self-selection and then examine the impact of improved varietal adoption on household income and poverty, we used PSM (see Dehejia and Wahba [20] and Wooldridge [38] for further detail on PSM).
A problem arises when using non-experimental data, because only one of these two situations such as adoption or not adoption can actually be observed; that is, either Y i1 or Y i0 is observed for each farming household but not both. Where Y i1 be the value of welfare when household i is subject to treatment (1), and Y i0 is the value of the same variable for control group or non-adopters (0). The treatment effect for a single observation is shown as τ i = Y i1 − Y i0. In non-experimental setting, the treatment and comparison samples are drawn from distinct groups. In a randomized experiment, the treatment and control group samples are randomly taken from the same population, and hence, the treatment effect for the treated group is more or less similar to the treatment effect for the untreated group. Thus, the treatment effect for the treated population can be presented as:
where T i = 1(=0) if the ith unit was assigned to treatment (control). The problem of unobservability is summarized by the fact that we can estimate \(E\left( {Y_{i1} /_{{T_{i} = 1}} } \right)\), but not \(E\left( {Y_{i0} /_{{T_{i} = 1}} } \right)\).
The difference, \(\tau^{e} = E\left( {Y_{i1} /_{{T_{i} = 1}} } \right) - E\left( {Y_{i0} /_{{T_{i} = 0}} } \right)\), can be estimated, but is potentially a biased estimator of τ. Instinctively, if Y i0 for the treated and comparison units systematically differs, then in observing only Y i0 for the comparison group and Y i0 cannot be estimated for the treated group. As a matter of fact, it produces a large amount of bias and randomization helps to prevent such bias [20]. If technology is randomly assigned to households, unobserved counterfactuals can be simply replaced, \(E\left( {Y_{i1} /_{{T_{i} = 0}} } \right)\), with actual expenditure \(E\left( {Y_{i1} /_{{T_{i} = 1}} } \right)\). Conditional Independence Assumption (CIA) along with overlap condition reduces selection bias when participation in a program is determined by observable characteristics [25].
where Y i = T i Y i1 + (1 − T i )Y i0 (the observed value of the outcome) and \(\underline{ | |}\) is the symbol for independence. The treatment and control groups do not systematically differ from each other. When (T i = 1), we observe Y i1; when (T i = 0) we observe \(Y_{i0}\). The average effect of treatment on the treated (ATT) is defined as
The ATT is the difference between two terms with the first term being the welfare indicator for the treated group which is clearly observable. The second term represents the welfare indicator of the treated group (also called counterfactual situation and not observable). PSM compares and matches the difference between the outcome of adopter (treated) and non-adopters (control) with akin inherent characteristics. It can only control observable characteristics but not unobserved variables [5]. Several techniques have been used to compare adopters and non-adopters with similar propensity scores. The most widely used techniques consist of nearest neighbor matching (NNM) and kernel-based matching (KBM). The NNM technique uses individuals from the adopters and non-adopters, who are closer with each other in terms of propensity scores as matching partners while KBM is nonparametric method that uses the weighted average of the outcome variable for all individuals in the groups of non-adopters to construct the counterfactual outcome. The latter gives more preference to those observations that provide a better match. The weighted average then is compared with the outcome for the groups of adopters. The difference estimates the impact of treatment on treated [4].
Results and Discussion
Descriptive Statistics
The average age of sampled household head is about 49 years, and average household size is found to be around six persons. There are more females in the household compared to males (Table 2). The average households agricultural earning is around US$ 224Footnote 2 per annum while the total average annual agricultural spending is approximately US$ 177. Likewise, an average annual household expenditure was nearly US$ 2885. On average, sample household head has completed 12 years of education.
The mean irrigated and total land holdings by a household are found to be approximately 0.4 and 0.7 ha, respectively. On average, a household has nearly 4 parcels of land. Around 32 % of the households rented in and sharecropped lands. The result further shows that 12 % of household has taken loans and almost 32 % of household received remittances from abroad. Similarly, poverty statistics illustrates that around 21 % of the sampled household heads are below the consumption poverty line. The results also show that about 15 % of the households have used improved paddy seeds in Nepal.
Table 3 presents the t test and Chi-square comparison of average of selected variables between adopters and non-adopters of improved rice varieties. It is observed that covariates are clearly distinguishable in terms of socioeconomic and biophysical characteristics between adopter and non-adopters. Around four-fifths of the households are male headed, and there is a significant difference in the distributions of gender of the household head between the adopters and non-adopters. The average landholding of the adopters households is significantly higher (0.8 ha) compared to the non-adopter household (0.7 ha). There is significant difference between the years of schooling of adopters (11.4 years) and non-adopters (11.9 years) household head.
There is also significant difference in terms of access to different agricultural services (such as market, lending institutions and agricultural centers) between the adopters and non-adopters of improved paddy growers. Distances to the agricultural service facilities are lesser to the adopters compared to non-adopters. Farmers nearby market facilities are more likely to adopt [11, 39]. FGT indicators are found to be lower in adopter households compared to non-adopters. Likewise, adopter households have significantly higher annual expenditures (US$ 4109) compared to the non-adopters households (US$ 2603). The total annual average agricultural earning of adopters’ household is around US$ 479 and significantly higher than the annual average agricultural earning of US$ 178 of non-adopter households. It implies that improved rice technologies might have contributed on income. Likewise on remittances, nearly 37 % of adopters’ households receive remittances as compared to 31 % for non-adopters. However, it is important to investigate whether a portion of remittance income is invested in adopting improved agricultural practices [10].
An individual in Nepal is considered to be poor if their annual food and non-food per capita consumption is below the US$ 264,Footnote 3in average 2010–2011 price, on which food poverty line is US$ 163 and non-food per capita annual consumption is below US$ 100 [12]. It is found that per capita food consumption of adopter’s household member is US$ 727 per annum compared to the US$ 588 of member of non-adopter household (Table 4). Besides that, other poverty indices such as headcount poverty ratio, poverty gap and severity of poverty are also higher in non-adopters category. Nearly 22 % households from counterfactual groups are below the poverty line compared to 15.3 % of adopters. The official statistics, however, reported that still 25.4 % of the total population live below the poverty line [14]. The poverty gap index measures the extent to which individual fall below the poverty as a proportion of the poverty line. The greater the gap, the deeper is the poverty. The non-adopter households had poverty depth of 49.4 % relative to 33 % of adopter households. The government needs to speed almost 50 and 33 % of the consumption poverty line (US$ 264) each year on each non-adopter and adopter household, respectively, to bring them above the poverty line.
Estimation of Propensity Score
While non-parametrically estimating the technological impact on household wellbeing, propensity scores for the treatment variables need to be specified. It should hold the Conditional Independent Assumption (CIA) which states that all the covariates should be included into predict the propensity score, even if they are not statistically significant. The propensity score denotes the estimated propensity of being an adopter. The dependent variable takes the value of 1, if the household is an adopter and 0 otherwise. The larger the score, the more likely is an individual to adopt improved varieties [38]. To fulfill the assumption of CIA, such explanatory variables should be included which are the most important determinants of income and also associated with technological adoption [29]. A logit model was used to predict the probability of adopting the improved paddy varieties.
Numbers of parcels, household size, livestock numbers, remittances receiving household and land tenure status positively and significantly affect adoption decision of improved paddy varieties (Table 5). The better-off households generally have more access to improved varieties [5]. Holding larger numbers of plots, land tenure status, receiving remittances are the proxy indicators of better-off household. A household having these characteristics would more likely to adopt improved varieties. The larger the size of a family, the more likely it is to use improved seeds. The finding is in line with Kansiime et al. [27] and Adesina et al. [2]. Since most of the technologies employed by farmer normally require more labor inputs, only larger families could afford adoption of improved seeds. Famers with larger number of holdings and livestock population are likely to adopt improved varieties. Basically smallholders are risk averse and seem to avoid improved varieties due to high cost associated with it, while large land holders prefer to take risks because it is affordable for them [36].
The result also shows that remittance-receiving households are more likely to adopt improved rice varieties. Remittance provides regular sources of income for agricultural households, who can utilize that resource for consumption smoothening and enhancing agricultural productivity by investing on improved technologies including varieties [26]. Gender of the household head has negatively significant impact on adoption decision of improved rice variety. Household heads’ level of education, farm size, access to credit facilities and extension services have significant effect on decision to technological adoption. In particular, education of the household head, access to credit facilities, frequent visits by extension officers tend to facilitate adoption of improved rice varieties, which is in consistent with the previous findings [3, 10]. When capturing the difference in the intensity of adoption of improved paddy varieties across regions, region dummies have been included. It is found that region dummy for Terai is positive and significant, and dummy for hill is found to be positive only in reference to mountain region. It might be that government-targeted agriculture development programs have been focussed on Terai region. Terai is an accessible area with a large number of agricultural research stations, academic/training institutions, service centers and NGOs which have been providing and disseminating improved agrotechniques.
Figure 2 presents the distribution of the propensity scores as well as region of common support.Footnote 4 Histogram does not include non-adopters whose estimated propensity score is less than the minimum estimated propensity score for the adopter units by common restrictions. The figure clearly shows the bias in the distribution of the propensity scores between the group of adopters and non-adopters. Therefore, proper matching is essential. Common support condition will remove the bad matches.

Propensity score distribution and common support for propensity score distribution treated on support indicate the individuals in the adoption group who find a suitable match, whereas treated off support indicates the individuals in the adoption group who did not find a suitable match
Estimation of the Impact of Improved Rice Adoption
Table 6 depicts the average treatment effects of adopting improved paddy varieties on headcount poverty index, annual agricultural earning and expenditure of household. The empirical results illustrate that the adoption of improved paddy varieties has a positive and significant impact on the household agricultural earning and household annual consumption but negative effect on poverty. Our results are in concordance with [9, 29] and [4], who found positive impact of technological adoption on household wellbeing.
More specifically, the matching results from both KBM and NNM show that adoption of improved rice varieties increases the household annual agricultural earning by US$ 153 and US$ 185, respectively, compared to the non-adopter household. The causal impact of adoption of improved rice variety on the household agricultural earning in Nepal is positive and significant, and it ranges between US$ 153 to US$ 185. Likewise, household annual consumption expenditure is higher by US$ 643–US$ 907 per annum to the household who adopts improved rice varieties than the non-adopter households. Both NNM and KBM estimate that adoption of improved rice did not have any significant impact on reducing poverty of the adopting households.
Table 7 presents the findings for the casual impacts of the adoption of improved rice varieties on annual household agricultural earning, expenditure and headcount poverty status for different categories of land ownerships. The results generally illustrate that adoption of improved rice varieties tends to have positive and significant impact on household annual agricultural earning and expenditures but negative impact on poverty within the households of different farm categories. Intuitively, when there is more production relative to demand, price falls and farmers get lesser benefit. Although their earning is higher, net profit is not as high as their gross earning. Producers will be highly benefitted in the beginning, and consumers will be benefited eventually due to the technology transfer [21]. Based on the stratification by land size, the income effect of adoption of improved rice increases with increasing land size. The impact of adoption is higher on annual agricultural earning and annual expenditure among the households with larger farm size, as compared to the households with small and medium size land. This demonstrates a positive correlation between income and farm size. Impact of improved varieties has less effect on reducing poverty on small and medium size land holders. The results illustrate that technological adoption has statistically significant effect on reducing poverty among the large farmers by more than 13 % compared to small and medium size land holders. Although technological adoption impacts wellbeing of all farmers by increasing annual income and household expenditure, small and medium farmers still fall below the poverty line. The increasing income level could not be enough to pull them out of the poverty line. These findings are consistent with [4, 29, 9].
Figure 3 shows that covariates are balanced across adopter and non-adopter groups in sample matched or weighted by propensity score (less bias in the various covariates after matching between them). Particularly, the conditions of common support and balancing appear to be satisfied. There is sufficient overlapping in the propensity scores of the adopter and non-adopter households before matching. Median-standardized biasness among covariates has been reduced after matching, and there is no significant difference between various covariates (Table 8).

Pre- and post-matching bias reduction for different matching estimators
In Table 2, difference in the values of exogenous variables between two groups can be observed before matching. By matching, significant reduction in the differences in the control and treatment groups is seen. For all the exogenous variables, differences have been eliminated. Clearly, after matching, the differences are no longer statistically significant, suggesting that matching helps to reduce the bias associated with the observables characteristics.
Conclusions
The study focuses on the impact of adoption of improved rice varieties on the household wellbeing measured by annual agricultural earning, household expenditure and headcount poverty in Nepal by using the secondary data obtained from Nepal living standard survey (NLSS) III. In the non-experimental data, people’s participation to program is not randomly assigned. There is always possibility of self-selection bias as the educated and rich farmers are more likely to participate in the program. Propensity score matching (PSM) helps reduce this bias and produce representative results.
Though several studies showed that there is a casual relationship between household wellbeing and adoption of improved seeds, establishing relationship between technological adoption and household wellbeing is mostly complex and challenging. Benefits obtained from adoption of improved agriculture technology influenced the poor directly, by raising the income of farming household and indirectly by creating employment opportunities, raising wage rate and reducing food price [29]. Since more than two-thirds of the population of Nepal depend on agriculture with its subsistence mode of production, significant proportion of rice growers depend on traditional rice varieties for long time. It is more obvious that adopting improved agrotechniques including better provision of agroinputs will enhance crop productivity and livelihood security of those depend on agriculture.
Based on the PSM estimation, the adoption of improved rice varieties has positive and significant impact on household annual agricultural earning and expenditure. The results indicate that adoption of improved rice varieties increased the household annual agricultural earning by US$ 153–185. Similarly, household consumption expenditure of the adopters increased by US$ 643–907 per annum compared to the non-adopters. The results further show that adoption of improved rice varieties helped to reduce poverty by 13 % of large farming households compared to the small and medium size farming households. The finding indicates that productivity enhancing technology will enhance the level of farmers’ income and per capita expenditures, thereby increasing their chances of reducing poverty. Technological adoption on household wellbeing across land ownership categories reveals a statistically significant and positive welfare effects on all categories of farm owners. Adoption has statistically significant and negative impact on poverty among the large farmers. The government should, therefore, focus agricultural extension services for small and medium land holders as compared to large land holders.
For improving household wellbeing of large segment of the farming communities especially from the rural areas, government should invest on implementing targeted programs for small and medium farmers. Specific targetted programs such as motivations to adopt improved varieties and improved agroinputs to small and medium size farming households will raise their level of income and which will ultimately help them to overcome the poverty. The policy implication of the given study is that new and innovative technology should always be explored to replace old and outmoded one so that efficiency in the production will be obtained to improve the household wellbeing.
Notes
For detailed information on sampling procedure, refer to the Weblink: http://cbs.gov.np/wp-content/uploads/2012/02/Statistical_Report_Vol1.pdf).
Source: Nepal Central Bank (Nepal Rastra Bank), exchange rate US$ 1 = Rs 73, date: January 22, 2011.
Converting at the exchange rate of US$ 1 = NRs 73, date: January 22, 2011 of Nepal Central Bank (Nepal Rastra Bank).
The common support is defined as 0 < p(D = 1|X) < 1. By the overlap condition, the propensity score is bounded away from 1 and 0, excluding the details of the distribution of p(x) [9].
References
Adekambi SA, Diagne A, Simtowe FP, Biaou G (2009) The impact of agricultural technology adoption on poverty: the case of NERICA rice varieties in Benin. In: International Association of Agricultural Economists’ 2009 Conference, Beijing, China, vol 22, p 2009
Adesina AA, Mbila D, Nkamleu GB, Endamana D (2000) Econometric analysis of the determinants of adoption of alley farming by farmers in the forest zone of southwest Cameroon. Agric Ecosyst Environ 80:255–265
Akudugu MA, Guo E, Dadzie SK (2012) Adoption of modern agricultural production technologies by farm households in ghana: What factors influence their decisions? J Biol Agric Healthc 2:1–13
Ali A, Abdulai A (2010) The adoption of genetically modified cotton and poverty reduction in Pakistan. J Agric Econ 6:175–192
Amare M, Asfaw S, Shiferaw B (2012) Welfare impact of maize-pigeonpea intensification in Tanzania. Agric Econ 43:27–43
Asante BO, Wiredu AN, Martey E, Sarpong DB, Mensah-Bonsu A (2014) Nerica adoption and impacts on technical efficiency of rice producing households in Ghana: implications for research and development. Am J Exp Agric 4:244–262
Asfaw A, Admassie A (2004) The role of education on the adoption of chemical fertiliser under different socioeconomic environments in Ethiopia. Agric Econ 30:215–228
Asfaw S, Kassie M, Simtowe F, Lipper L (2012) Poverty reduction effects of agricultural technology adoption: a micro-evidence from rural Tanzania. J Dev Stud 48:1288–1305
Becerril J, Abdulai A (2010) The impact of improved maize varieties on poverty in Mexico: a propensity score-matching approach. World Dev 38:1024–1035
Bhatta GD, Aggarwal PK (2015) Coping with weather adversity and adaptation to climate variability: a cross-country study of smallholder farmers in South Asia. Clim Dev 8(2):145–157. doi:10.1080/17565529.2015.1050978
Bhatta GD, Doppler W (2011) Smallholder peri-urban farming in Nepal: a comparative analysis of farming systems. J Agric Food Syst Commun Dev 1:163–180
Bhatta GD, Ojha HR, Aggarwal PK, Suileman VR, Sultana P, Thapa D, Mittal N, Dahal KR, Thomson P, Ghimire L (2015) Agricultural innovation and adaptation to climate change: empirical evidence from diverse agro-ecologies in South Asia. Environ Dev Sustain. doi:10.1007/s10668-015-9743-x
Bhatta GD, Aggarwal PK, Shrivastava AK, Sproule S (2015) Is rainfall gradient a factor of livelihood diversification? Empirical evidence from around climatic hotspots in Indo-Gangetic Plains. Environ Dev Sustain. doi:10.1007/s10668-015-9710-6
CBS (2011) Nepal living standard survey III. Central Bureau of Statistics, Kathmandu
CBS (2014) Population monograph of Nepal volume III 2014. Central Bureau of Statistics, Kathmandu
Challa M, Tilahun U (2014) Determinants and impacts of modern agricultural technology adoption in west Wollega: the case of Gulliso district. J Biol Agric Healthc 4:63–77
D’Souza G, Cyphers D, Phipps T (1993) Factors affecting the adoption of sustainable agricultural practices. Agric Resour Econ Rev 22:159–165
De Janvry A, Sadoulet E (2002) World poverty and the role of agricultural technology: direct and indirect effects. J Dev Stud 38:1–26
De Janvry A, Dustan A, Sadoulet E (2011) Recent advances in impact analysis methods for ex-post impact assessments of agricultural technology: options for the CGIAR. University of California, Berkeley
Dehejia RH, Wahba S (2002) Propensity score-matching methods for non-experimental causal studies. Rev Econ Stat 84:151–161
Dontsop-Nguezet PM, Diagne A, Okoruwa VO, Ojehomon V (2011) Impact of improved rice technology on income and poverty among rice farming household in Nigeria: a local average treatment effect (LATE) approach. In: Contributed paper prepared for the 25th conference of the Centre for the Studies of African Economies (CSAE), St. Catherine College, University of Oxford, UK, pp 1–31
Foster J, Greer J, Thorbecke E (2010) The Foster–Greer–Thorbecke (FGT) poverty measures: 25 years later. J Econ Inequal 8:491–524
Ghimire R, Huang WC, Shrestha RB (2014) Factors affecting adoption of improved rice varieties among rural farm households in central Nepal. Rice Sci 22:1
Grosh M, Glewwe P (2000) Designing household survey questionnaires for developing countries: lessons from 15 years of the living standards measurement study. World Bank, Washington
Heinrich C, Maffioli A, Vazquez G (2010) A primer for applying propensity-score matching. Inter-American Development Bank, Washington, DC
Joshi KD, Conroy C, Witcombe JR (2012) Agriculture, seed, and innovation in Nepal: industry and policy issues for the future. International Food Policy Research Institute (IFPRI), Washington, DC
Kansiime MK, Wambugu SK (2014) Determinants of farmers’ decisions to adopt adaptation technologies in eastern Uganda. J Econ Sustain Dev 5:189–199
La Rovere R, Mathema S, Dixon J, Aquino-Mercado P, Gurung KJ, Hodson D, Flores D (2008) Economic and livelihood impacts of maize research in hill regions in Mexico and Nepal: including a method of collecting and analyzing spatial data using google earth. CIMMYT, Mexico
Mendola M (2007) Agricultural technology adoption and poverty reduction: a propensity-score matching analysis for rural Bangladesh. Food Policy 32:372–393
Meyer BD, Sullivan JX (2003) Measuring the well-being of the poor using income and consumption (No. w9760). National Bureau of Economic Research
MoAD (2012) Statistical information on Nepalese agriculture. Ministry of Agricultural Development, Kathmandu
Mukhopadhyay SK (1994) Adapting household behavior to agricultural technology in West Bengal, India: wage labor, fertility, and child schooling determinants. Econ Dev Cult Change 43(1):91–115
Mulugeta T, Hundie B (2012) Impacts of adoption of improved wheat technologies on households’ food consumption in southeastern Ethiopia. In: 2012 Conference, August 18–24, 2012, Foz do Iguacu, Brazil (No. 126766) International Association of Agricultural Economists
Pant KP, Aryal M (2014) Varietal effects on price-spread and milling recovery of rice in Nepal. J Agric Environ 15:18–29
Shiferaw B, Kassie M, Jaleta M, Yirga C (2014) Adoption of improved wheat varieties and impacts on household food security in Ethiopia. Food Policy 44:272–284
Simtowe F, Kassie M, Asfaw S, Shiferaw B, Monyo E, Siambi M (2012) Welfare effects of agricultural technology adoption: the case of improved groundnut varieties in rural Malawi. In: International Association of Agricultural Economists (IAAE) triennial conference, Foz do Iguaçu, Brazil, pp 18–24
Smale M, Mason N (2014) Hybrid seed and the economic well-being of smallholder maize farmers in Zambia. J Dev Stud 50:680–695
Wooldridge JM (2010) Econometric analysis of cross section and panel data. MIT press, Cambridge
Wu H, Ding S, Pandey S, Tao D (2010) Assessing the impact of agricultural technology adoption on farmers’ well-being using propensity-score matching analysis in rural china. Asian Econ J 24:141–160
Acknowledgments
The authors are highly indebted to Central Bureau of Statistics (CBS) of Nepal for providing and allowing us to use data for analysis. We also would like to express our gratitude to Binod Shrestha for his technical assistance. Finally, we also thank the anonymous referees and the journal editor for their comments and suggestions that substantially improved the article quality.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Budhathoki, N., Bhatta, G.D. Adoption of Improved Rice Varieties in Nepal: Impact on Household Wellbeing. Agric Res 5, 420–432 (2016). https://doi.org/10.1007/s40003-016-0220-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40003-016-0220-z