
Abstract
Achieving carbon emission targets requires an accurate analysis of trends in the rise and fall of carbon emissions. Due to economic growth and energy demand, China's emissions have increased dramatically in the past three decades. To this end, China has pledged to a carbon emissions peak by 2030, which has resulted in a large number of policy initiatives to cut emissions. Therefore, this study aims to present the generalized structure of machine learning (ML) derived group method of data handling (g-GMDH) as an improved alternative for analyzing and predicting China's future CO2 emission trends. The study used annual data from 1980 to 2019 for gross domestic product, total natural resource rent, industrialization, urbanization, renewable energy, and non-renewable energy consumption to forecast the CO2 emissions trend from 2020 to 2043. The CO2 prediction results indicate that China will reach its CO2 emission peak in 2033. Sensitivity analysis results revealed that industrialization, non-renewable energy, and urbanization significantly impacted the model's output and contributed the most to CO2 emissions. In contrast, renewable energy consumption contributed the least to CO2 emissions. The findings of this study can provide valuable guidelines for decision-makers as they set CO2 reduction goals and implement appropriate energy-saving and emission-reduction initiatives.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
As the top carbon emitter in the world, the Chinese government on September 2020 announced at the UN General Assembly that China will endeavor to reach its peak CO2 emissions by 2030 (Normile 2020). To achieve this task, China has implemented numerous policies to reduce carbon emissions, such as the National Key Energy-saving and Low-Carbon Technology Promotion Catalog to enhance the development of low-carbon technologies (NDRC 2017). Also, the nationwide emission trade scheme (ETS) industries in the pilot areas (Hubei, Guangdong, Beijing, Shenzhen, Tianjin, Chongqing, and Shanghai provinces) reduced CO2 emissions by 15.5% and energy usage by 22.8%, mainly through modifying the industrial structure and technical productivity (Hu et al. 2020). By 2021, the seven pilot provinces had generated an estimated 11.4 billion Yuan in expenses while accumulating 480 million tons of carbon dioxide equivalent (Zhang et al. 2022a). However, because of its detrimental effect on China's economic progress, many researchers continue to dispute the effectiveness of a carbon ETS. For instance, Hübler et al. (2014) evaluated China's carbon ETS using the computable general equilibrium (CGE) model. They found that it reduced gross domestic product (GDP) by around 1% in 2020, and they predict that it may reduce welfare by about 2% by 2030.
A carbon tax was recommended by the National Development and Reform Commission (NDRC), and the Ministry of Finance (MOF) was to be implemented in China by the year 2012; however, the Chinese government did not do so until 2021 (Zhang et al. 2022b). This scheme was proposed to reduce carbon emissions and energy consumption through carbon taxes. Chi et al. (2014) discovered that a carbon tax helped control emissions and energy conservation, and Fu et al. (2021) argued that China should consider implementing carbon taxes that range from 18.37 to 38.25 Yuan per ton. However, establishing a carbon pricing device is difficult due to the rate's unpredictability and its effects on the environment, the energy industry, and the economy.
Apart from ETS, National Key Energy-Saving, and carbon tax, future attempts at realizing the 2030 carbon emissions target in China are centered on the "15th Five-Year Plan". These include policies aimed at ensuring the share of non-fossil energy will reach around 25% regarding the energy mix; carbon emissions per unit of GDP will drop by more than 65% compared with the 2005 level. Also, the country must strive to achieve an adequate and low-carbon energy infrastructure in the industrial sector by ensuring that renewable sources produce 50% of transmitted electricity. Other policies include urban planning and development geared toward green and low-carbon development. Efforts will be put into developing green cities, towns, and communities and improving resource utilization efficiency by attempting to reduce resource consumption and cut carbon emissions (NDRC 2021).
A growing amount of empirical literature has projected China's CO2 emissions. However, empirical evidence frequently produces inconsistent results due to variances in methodology, sample periods, and numerous CO2 indicators. From Table 1, studies that have forecasted a 2030 peak in emissions include the usage of the China-in-Global Energy Model (C-GEM) Zhang et al. (2016), and the logarithmic mean divisia index (LMDI) and decoupling index (LMDI-D) approach (Li and Qin 2019). Both predictions differ from a 2025 peak obtained via the Multi-objective optimization model Yu et al. (2018) and a 2028 to 2030 prediction obtained via the feasible generalized least squares (FGLS) model (Zhang et al. 2021). In addition, Li et al. (2018) used the grey and impacts on ecosystems (I), which are the product of the population size (P), affluence (A), and technology (T) (IPAT) model to assert the feasibility of 2030 peak emissions, provided the GDP in China is lower than 151,426.15 billion. Using the Chinese Integrated MARKAL-EFOM System, Zhang and Chen (2021) also noted that the 2030 peak emission depends on renewable energy sources reaching 60% of total energy consumption by 2050. The conventional predictive models mentioned above are highly accurate, have a small number of parameters, are quite easy to train, and are used for linear sequences. The capacity of these models to fit nonlinear sequences, however, is inferior to that of machine learning techniques.
In order to overcome the limitations of these prediction models, numerous machine learning methods have been applied which can handle nonlinear sequences. For instance, the Recurrent Neural Network (RNN) has a relationship between the data and time making it suitable for time series analysis. RNN can create sequence-to-sequence mapping between input and output data by adding cyclical connections to neurons. As a result, the input from the time step before influences the output of every subsequent time step. RNN, therefore, accomplishes the "memory" attribute. RNN usage in predicting carbon emissions in China includes Feng et al. (2019) employing the RNN methodology to estimate the regional transport rate of emissions in Hangzhou City. However, because the RNN depends on the data over a lengthy period, gradient disappearance and explosion issues arise during model training (Yin et al. 2019). The problem of minimal gradients is known as the disappearing gradient problem. The disappearing gradient problem mainly affects the lower layers of the network and makes them more challenging to train. Similarly, if the gradient associated with weight becomes extremely large, the updates to the weight will also be extensive. This can cause the gradients to become unstable, preventing the algorithm from converging. This problem of huge gradients is known as the exploding gradients problem.
One means of overcoming RNN limitations concerning sequential data processing is using Long short-term memory (LSTM) developed by (Hochreiter and Schmidhuber 1997). In contrast to RNNs, LSTMs use memory blocks to replace the hidden layer, which can effectively address the issues of gradient disappearance and explosion during RNN training (Sundermeyer et al. 2015). Several studies have employed LSTM to predict carbon emissions in China; case in point, Fan et al. (2022) employed the LSTM technique and confirmed that China will reach a carbon emission peak in 2030. Using sixteen potential input variables to predict carbon emissions (Huang et al. 2019) confirmed that LSTM has higher predictive accuracy than that (Back propaganda neural network) BPNN. But because the LSTM approach contains so many parameters, it is difficult to calculate. Consequently, the LSTM's training period is lengthy (Sorkun et al. 2020).
This study contributes a new perspective to the extant literature by employing the robust generalized structure of the group method of data handling (g-GMDH) as an improved neural network to predict CO2 emissions in China. The g-GMDH neural network possesses a self-organizing nature to automatically tune model parameters and generate the optimal CO2 emission model structure while using less computation time. The g-GMDH has a better adaptation and generalization ability with the advantage of not being prone to over fit and can perform excellently even when the predictive variables are irregular. Also, unlike other standard machine learning models trained to forecast CO2 emissions, the g-GMDH neural network does not require a manual adjustment of learning parameters to generate the best outcome. Based on significant sources of carbon emissions, the g-GMDH uses reproducible models to select predictors and thresholds to deliver carbon emissions intensity prediction from 2020 to 2043. The g-GMDH model performance in predicting carbon emissions was further compared with Long Short-Term Memory (LSTM). Furthermore, this study investigates the impact of influencing factors on CO2 emissions and then, distinguishes which indicator has the most and least significant effect on CO2 emission.
Economic output from the secondary industry in China is the primary determinant of CO2 emissions (Fan et al. 2015), with China's population expansion and urbanization linked to increased environmental degradation, resource consumption, and CO2 emissions in recent years (Mendonça et al. 2020; Ridzuan et al. 2020; Chai et al. 2020). Natural resources, industrialization, and urbanization are therefore considered in the g-GMDH model employed in this study because they all have an indirect effect on CO2 emissions due to energy use. Table 1 reports related works done in forecasting CO2 emissions in China, and Fig. 1 reports the trend of CO2 emissions in China and globally from 1980 to 2019.

Trend of CO2 emissions in China and globally from 1980–2019
Materials and methods
Data handling and processing procedures
The input variables used include renewable energy consumption, non-renewable energy consumption, total natural resource rent, industrialization, economic growth, and urbanization. Carbon emission (CO2), which will serve as our output variable, is the byproduct of CO2 emissions from burning fossil fuels. As for input variables, total natural resource rent (TNRR) is the accumulation of coal (soft and hard) rents, oil rentals, forest rents, mineral rents, natural gas rents, and other rents. Gross domestic product GDP per capita (constant 2015 US$) is a gauge of economic expansion: The total use of biomass, solar, wind, hydropower, and geothermal energy is called renewable energy (REN). The total consumption of petroleum, gas, coal, and other liquids is known as non-renewable energy (NREN): Urbanization (URB) is indicated by the population of cities. Industrialization (IND) is measured as a value-added percentage of GD. Variables are changed to logarithms to evaluate estimated coefficients of elasticity and smoothness (Riti et al. 2017).
This research periodically employs annual data covering 1980 to 2019. Data for TNRR, IND, URB, and GDP were taken from the World Bank's World Development Indicators online database (WDI, 2021). Data on renewable energy consumption, carbon dioxide (CO2) emissions, and non-renewable energy consumption were obtained from the US Energy Information Administration (US-EIA, 2021). The summary of the data description and statistical data analysis are reported in (Tables 2 and 3).
During data processing, feature selection (variable selection) was performed to identify and omit irrelevant, unwanted, and redundant features from data that will not contribute to the accuracy of the forecasting model or could reduce the model's precision. Pearson correlation coefficient (R) was used to estimate the relative importance of the input parameters with the output parameter (Eq. 1). The correlation coefficient (R) values always lie between − 1 and + 1. In this case, the values close to positive indicate a similar association between the two variables, while the values close to zero show a weak association between the two-variables pair, and the values close to negative indicate an inverse association between independent variables (Mahmoud et al. 2019).
where ui and ti denote the individual sample points indexed with i, n represents the size of the samples, \(\overline{u}\) denotes the mean sample, and analogously for \(\overline{t}\).
The input parameters R-values are REN, NREN, TNRR, IND, GDP, and URB, with the output parameters of CO2 shown in Fig. 2. The normalization processing was done using Eq. 2:

Heat map showing the correlation coefficient matrix of the input variables of REN, NREN, TNRR, IND, GDP, and URB with the output parameters of CO2
Equation 2, \(x\) is the actual value, \(X_{{{\text{NORM}}}}\) signifies the dataset normalized value, \(x_{\min }\) and depicts the minimum value and \(x_{\max }\) the maximum value. The selected technique enables the computational learning algorithm to execute faster, improves the model's correctness, reduces over fitting, and also it decreases the complexity of the model (Al-Abadi et al. 2020).
LSTM neural network
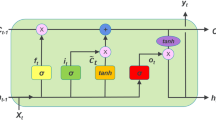
Long short-term memory (LSTM) neural network is a recurrent neural network (RNN) designed to handle long-term dependencies in sequential data. LSTM networks use special units, including a "memory cell," that can maintain information over time and regulate the flow of information through the network, which makes it ideal for processing and predicting data with long-term dependencies. The basic idea behind using LSTM neural network is to model the complex relationships between various factors influencing China's carbon emissions. Therefore, the network takes in the historical emissions data and influencing factors suits of REN, NREN, TNRR, IND, GDP, and URB to learn patterns and trends in the data, allowing it to make predictions about future emissions. The advantage of using an LSTM network for this application is its ability to handle long-term dependencies in the data, in which the first stage in the LSTM process is identifying precisely what kind of data can travel through the cell state. Figure 3. shows the LSTM neural network structure.

Structure of LSTM neural network (Ahmed et al. 2022a)
Equations (3)–(10) demonstrate the update of the LSTM memory cells. From (Fig. 3), the notations for each equation are \(x_{t}\) representing the input vector, \(\sigma\) representing the sigmoid function \(f_{t} ,o_{t} ,{\text{and }}i_{t}\) are values of forget gate, output gate, and input gate, respectively.\(W_{f} ,W_{i} ,W_{C} ,{\text{and }}W_{o}\) are the weight matrices of gate and cell states. \(h_{t}\) is the hidden state of the LSTM. \(\tilde{c}_{t}\) represents the temporary vector for the cell states, \(c_{t}\) is the vector for the cell states, and. \(b_{f} ,b_{o} ,b_{i} ,{\text{ and }}b_{C}\) are bias vectors of forget gate, output gate, input gate, and temporary cell state.
The forget gate controls the decision using sigmoid, which produces a 0 to 1 value ft based on the prior output ht−1 and the recent input xt. It determines whether or not the previous information Ct−1 learned at the last minute has been transferred entirely or partially. Equation 3 shows the ft formula.
The second step is determining what data should be added to the cell state. To produce it and decide which values should be changed, the input gate uses a sigmoid. After that, a tanh layer is employed to construct a new candidate value \(\tilde{c}_{t}\), as reported in Eqs. 4 and 5. The following are lists of computing processes:
The process of forgetting undesired information and adding new information is the third step. The old cell state Ct-1 is multiplied by ft which ignores all unrequired information, and then, it is added to \(i_{t} \tilde{c}_{t}\) that will give the new cell state Ct as shown in Eq. 6
The output of the LSTM model is generated last. The tan h layer compresses the internal state Ct, which is then multiplied by the output gate \(o_{t}\) as illustrated in Eqs. 7 and 8:
The equations above \(W^{x}\) depict the weights between the inputted layer and inputted node x; the weights between the inputted node and hidden layers are characterized by \(W^{h}\); b portrays the bias term, \(\sigma\) which denotes the sigmoid function. Also, all three gates are sigmoid units \(\sigma\), as defined in the equation
And tanh is expressed in Eq. (10):
Generalized structure of GMDH (g-GMDH) model
The g-GMDH neural network is an advanced data analysis, prediction, and modeling tool, offering numerous advantages in a wide range of applications. Firstly, its robustness and adaptability allow it to effectively handle complex, nonlinear, and noisy data, making it suitable for diverse domains (Shen et al. 2019). Secondly, the automatic model selection feature eliminates the need for predefined structures, iteratively generating and evaluating models to find the optimal fit while reducing overfitting risk. Additionally, g-GMDH's interpretability fosters a better understanding of relationships between input and output variables, aiding informed decision-making. Its scalability enables the efficient processing of large datasets through parallel processing capabilities, making it an excellent choice for big data applications and real-time analysis. Lastly, the network's reduced training time, attributed to its inductive nature and iterative model generation process, allows for faster model development and deployment, enhancing overall performance and efficiency.
The g-GMDH neural network is well-suited for predicting carbon emissions because it can handle large and complex datasets, and it can automatically identify and extract relevant features from the data. By analyzing historical data on carbon emissions, the g-GMDH neural network can learn patterns and relationships that can then be used to make accurate predictions about future emissions. The GMDH model's goal is to identify a function \(\hat{f}\) that is used as an estimation rather than an actual function, f, to evaluate the output (CO2), y, in the presence of a given input vector U = (u1, u2, u3, …, un), as close to its actual output as possible, p (CO2,). As a result, if you have a single output and n data pairs with numerous inputs, you will get:
The GMDH network may be trained to evaluate output values t using any given input vector \(U = u_{i1} ,u_{i2} ,u_{i3} ,....,u_{in}\), implying:
To tackle this difficulty, GMDH creates a general relationship in the framework of a mathematical description of output and input parameters termed the reference. The goal is to find the GMDH network that minimizes the square difference between the expected and actual output, as follows:
The Kolmogorov–Gabor polynomial, also identified as the polynomial series, which is the Volterra functions complex discrete form (Anastasakis and Mort 2001; Najafzadeh and Azamathulla 2013), can represent the general relationship between input and output parameters in the mode of:
Equation 14 can be simplified by the simplified GMDH network's partial quadratic polynomial equation (Shen et al. 2019)
This network of associated neurons generates the mathematical association between the input–output variables stated in Eq. 13. The weighting Eq. 14 coefficients are calculated using regression techniques to reduce the variation between an actual (p) and anticipated (y) output as each variable pair of ui and uj input is minimized (Armaghani et al. 2020). Figure 4. depicts the GMDH network design in a schematic form.

Type of the GMDH network design
A tree of polynomials is formed using the quadratic equation from the provided Eq. 14, in which the weighting coefficients can be calculated using the least square approach method. The quadratic function of weighting coefficients Wi is obtained to optimally match the output in the entire set of output-input data pairs as follows:
To fit the general form of GMDH algorithms, the possibilities for dual independent variables among the overall n input parameters are drawn. To construct the regression polynomial described in Eq. 16, which suits the dependent observations better in the least-square sense. Consequently \(C_{n}^{2} = {{n\left( {n - 1} \right)} \mathord{\left/ {\vphantom {{n\left( {n - 1} \right)} 2}} \right. \kern-0pt} 2}\), observations can create quadratic polynomial neurons \(\left\{ {(p_{i} ;u_{xi} ,u_{yi} ); \, (i = 1,2,3....M)} \right\}\) for various \(x, \, y \in \left\{ {1, \, 2,3, \, . \, . \, . \, .n} \right\}\) in the feed-forward network's first layer. M data triples can now be created \(\left\{ {(p_{i} ;u_{xi} ,u_{yi} ); \, (i = 1,2,3....M)} \right\}\), making use of \(x, \, y \in \left\{ {1, \, 2,3, \, . \, . \, . \, .n} \right\}\) the form of:
The following matrix expression can be expressed directly for each row of the m data triples using the quadratic sub-expression indicated in Eq. 14 as follows:
a illustrates an unknown vector of quadratic polynomial weighting factors in Eq. 12:
Superscript, T, indicating the matrix transposition:
Standard equations are solved using the least-square approach, which is developed from the concept of multiple regression analysis, which is in the form of:
For the entire set of m triples data, Eq. 21 signifies the optimum quadratic weighting coefficients given the vector in Eq. 1. To tackle the issue of linear dependency and equation complexity, the generalized Group Method of Data Handling (GMDH) can build a higher-order polynomial (Ivakhnenko, 1968). By minimizing the fitness function in Eq. 22, the training sub-samples are used to construct the optimal model structure:
The fitness function is based on the d-fold cross-validation criteria, which randomly selects training and testing subsamples considering all information in data samples. A comprehensive search is conducted on models classified of similar complexity, allowing the entire search termination rule to be planned. The models are compared to the measured samples, and the process is repeated till the criterion is reached. Because of the constraint imposed by the computation period time, it is suggested to increase parameters because of the criterion value after specific iterations' layer and calculation time while putting the models together. Then, for the chosen set of best variables, complete arranging approaches are used until progress is minimal. This gives the option of including more information components in the input and saving successful elements between layers to get the best model. In the first phase, the user defines the data sample for the model. In the second level, several layers are used to express model complexity. In the third step, the best models are created, and in the fourth step, the best model is chosen. During the fifth stage, discriminating criteria are used to complete the extra model definition, as shown in Fig. 5.

Flowchart of the generalized structure of combinatorial GMDH algorithm
Model validation
The g-GMDH neural network is a powerful and versatile tool for forecasting carbon emissions, as it can effectively model and predict complex relationships between various influencing factors. The g-GMDH network relies on inductive modeling and self-organization principles, making it capable of handling nonlinear data and adapting to changing patterns. As a result, it is well-suited for capturing intricate connections between factors such as gross domestic product, total natural resource rent, industrialization, urbanization, renewable energy, and non-renewable energy, which contribute to carbon emissions.
When choosing influencing factors as input variables, it is vital to consider several factors to set up an accurate and trustworthy carbon emission forecast model. There are several criteria, including data availability, interpretability, correctness, relevance, and consistency. The influencing elements should be relevant to carbon emission prediction, and the data used should be accurate, reliable, and easily accessible over a specific time. The data should also be consistent across chosen time and cover a broad range of factors that contribute to carbon emissions. When applied to carbon emission forecasting, the g-GMDH neural network iteratively generated CO2 models, automatically selecting the optimal fit based on predefined criteria. This process helped to reduce overfitting, improving the accuracy and reliability of emission forecasts. Furthermore, the interpretability of the CO2 g-GMDH model enabled a better understanding of emission trends and the underlying relationships between contributing factors.
The (g-GMDH) model and Long Short-Term Memory (LSTM) algorithms were implemented in MATLAB R2021a with Windows 10 operating system. The root mean square error (RMSE), mean absolute error (MAE), and correlation coefficient (R) were utilized as statistical indicators to analyze the results of the predicted CO2 models. A correlation coefficient (R) near 1 indicates optimal model performance. On the other hand, if the MAE and RMSE values approach zero when comparing models, the model is a reliable predictor. Equations 23, 24, and 25 provide mathematical expressions for RMSE, MAE, and R (Asante-Okyere et al. 2018; Okon et al. 2021)
whereas N stands for the number of data points, \(\overline{y}_{i}\) signifies the mean number for the measured variables,\(y_{i}\) stands for the actual carbon emission values, the expected carbon emission is characterized by \(Y_{i}\), and the mean values of the predicted variable are \(\overline{Y}_{i}\) (Adeniran et al. 2019; Ahmadi and Chen 2019). If the MAE and RMSE values approach 0 during training, the model has performed well. The trained model's ability to function effectively when validated using withheld testing data, on the other hand, is given greater weight. As a result, if the test results are favorable, the best-performing model with improved generalization capacity can be chosen if (MAE and RMSE) approach zero (Asante-Okyere et al. 2018).
Results and discussion
Performance indicators and error analysis of CO2 emissions in China
CO2 emissions models were produced from the primary data set by gathering and identifying numerous factors and dynamic development characteristics affecting carbon emission in China before 2019. The generalized structure of the GMDH (g-GMDH) model had the best overall performance compared to the most used machine learning algorithm of Long Short-Term Memory (LSTM). From the training results, the g-GMDH had the lowest error margin of 0.019 and 0.0105 for RMSE and MAE, respectively, which was less than 27% to 35% of computation time better than the LSTM techniques during CO2 emissions prediction. On the other hand, the LSTM CO2 model archived RMSE and MAE values of 0.0440 and 0.09035, respectively, during training Table 3. To practically assess the ability of the trained models, they were tested on withheld data distributed from 2008 to 2019. These data did not contribute to the development of the CO2 models; therefore, they can provide an unbiased assessment of any new dataset.
It was discovered that the g-GMDH CO2 model was the best-performing model, which generated predictions close to the actual CO2 emissions values. This was seen from the results shown in Fig. 6 that g-GMDH obtained the least RMSE and MAE values of 0.1162 and 0.3722, respectively. The LSTM produced CO2 prediction having error margins scores of 0.2257 and 0.4815 for RMSE and MAE, respectively, as reported in Table 4. The least RMSE and MAE score from g-GMDH indicates that the CO2 prediction results do not deviate much from the measured CO2 value. Therefore, the least RMSE value of 0.1162 during testing makes the proposed CO2 model the best and most stable CO2 emissions model compared to the LSTM technique.

RMSE and MAE error analysis for g-GMDH and LSTM during CO2 emissions forecast
The g-GMDH model is a self-organizing model in which the model's topology optimizes itself based on the data input of influencing elements for carbon emission and actual CO2. The g-GMDH avoids the issue of overfitting that plagues ANN and standard ML by objectively picking the CO2 model with optimum complexity, which proves the noise resistance ability exhibited by g-GMDH. The performance of the developed predictive CO2 models for g-GMDH and LSTM, as compared to the actual CO2 data, is presented using the Taylor diagram (Fig. 6). The Taylor diagram was drawn to show and interpret the correlation coefficient, root means square error, and standard deviation of the models. The results during CO2 forecasting reveal that the best-performing CO2 predictive model is g-GMDH, as it performed perfectly compared to the LSTM CO2 model (Fig. 7).

Evaluation of g-GMDH and LSTM CO2 models using Taylor diagram
Forecasting China's carbon dioxide emissions
The g-GMDH is a proper self-organizing technique and tool for categorizing data collection and presenting a suitable output (CO2) based on the data observed for appropriate forecasting problems, including time series (Yahya et al. 2019). The g-GMDH algorithm produced excellent results in estimating greenhouse gas emissions and was used to examine the CO2 emissions trend from 2020 to 2043. The dataset was divided into two consecutive segments of training and testing datasets to forecast carbon emissions. The training set was used for estimating parameters and learning the models, which were distributed from 1980 to 2007. The testing set was used to measure the predictive performance of the CO2 emissions model and was distributed from 2008 to 2019, and then, carbon emissions were forecasted from 2020 to 2043. From 1980 to 2019, two parts were used in this approach to predict more accurate results. Following the above-mentioned technique, the algorithm predicted China's CO2 emissions yearly from 2020 to 2043. The deviation from the measured CO2 value can be examined visually (Figs. 8 and 9).

CO2 emission intensity forecast for g-GMDH

CO2 emission intensity forecast for LSTM
The historical pattern of CO2 emission in China, as shown in Fig. 8, demonstrates a constant increase in CO2 emission over the sampled period. From this study's projection, the Chinese nation will achieve its carbon emission peak in 2033. This finding is in-line with Zhou et al. (2022), who found that under the current policy implementations, China will reach a carbon emissions peak in 2035. This finding contradicts the commitment made at the UN general assembly by the Chinese government to reach its peak by 2030. The reported result may be primarily because the high GDP expansion cancels out the emission-reduction advantages of energy-related technology advancements and energy structure optimization. This finding demonstrates that the peak goals cannot be successfully attained under the current energy policy objectives. Comparison of actual CO2 and predicted CO2 models performance of g-GMDH and LSTM can be examined visually from Fig. 10.

Comparison of CO2 emission prediction performance of g-GMDH and LSTM CO2 models
The energy and industrial sector, predominantly fueled by coal, is China's key source of carbon emissions. Industrialization, fossil fuel energy, and urbanization contributed the most to environmental distortion. They accounted for 42.4%, 41.1%, and 39.95%, respectively, as seen in Fig. 11. Findings regarding fossil fuel energy conform with that of (Wang et al. 2019). The more significant the proportion of coal used, the greater the region's dependency on fossil fuels in overall energy consumption. Also, in line with the findings of Zhou et al. (2019), the energy consumption structure is thought to have detrimental effects on emissions reduction. Between 2012 and 2014, China was said to have used over half of the world's coal in power generation, thus considerably increasing CO2 emissions. After 2014, there was a pause in CO2 emissions rise as the Chinese government implemented several initiatives to reduce CO2 emissions (Ahmed et al. 2022b). Furthermore, carbon emissions began an upward trend again in 2016. China burnt roughly 64% of coal to meet its energy mandate in 2019 (IEA 2020) and accounting for 52% of worldwide coal consumption, according to Enerdata (2019).

The percentages of contributing variables in predicting CO2 emissions
Industrialization in developing countries degrades the environment and harms people (Valadkhani et al. 2019). Increasingly we have seen a significant amount of industrialization in recent decades regarding social and economic development. However, legislated laws to limit fossil fuel use from industrialization activities have not been successfully applied. As a result, a rise in fossil fuel usage fulfills the energy mandate, considered the most severe environmental hazard that causes global warming. Furthermore, in China, urbanization is connected to industrial development, characterized by high energy consumption and low energy efficiency, resulting in environmental damage. Consistent with our findings, other workers have concluded that a higher level of urbanization increases carbon intensity (Rehman and Rehman 2022).
Because China is the world's fastest-growing economy, and its GDP has expanded dramatically over the last 40 years, the beneficial influence of economic expansion on its expanding footprint seems plausible. In every economic sector, the rise in income has boosted resource consumption. As a result, currently, China is the largest consumer of energy and has the highest overall environmental footprint globally. Subsequently, as the economy grows, energy issues become more prevalent in meeting the population's energy needs. For example, large-scale population migration results in consumption and production activities, implying that migration has an ecological impact (Gao et al. 2021). Natural resource richness reduces reliance on imported energy sources. It favors using domestic energy sources that are less polluting, such as natural gas, which helps to alleviate environmental degradation (Joshua et al. 2020). However, in China, this is not the case, as coal, a high-pollutant energy source, is widely used to meet energy demands. Because the Chinese use of natural resources is unsustainable, energy plans should be developed and executed to minimize reliance on traditional, high-polluting energy sources, such as fossil fuel energy sources which are the primary cause of environmental distortion. According to the Global Energy Statistical Yearbook 2021, China has met 28 percent of its energy needs with renewable energy. Our findings suggest that China can effectively cut CO2 emissions with increased investments in renewable energy sources Li (2020), essential for meeting CO2 emission reduction goals (Magazzino et al. 2021).
Utilizing inductive modeling and self-organization principles showed the effectiveness of the g-GMDH neural network when forecasting carbon emissions in China. It showed its ability to model complex relationships between various influencing factors. The network iteratively generated and evaluated the CO2 model automatically, selecting the optimal model to reduce overfitting and enhance accuracy. The interpretability of the CO2 emission g-GMDH model supports a better understanding of emission trends for China and its contributing factors, enabling the development of targeted policies and strategies for carbon emission reduction and climate change mitigation which can be adapted worldwide.
Conclusion
This study adopted the Group Method of Data Handling (GMDH) technique to anticipate carbon emissions in China from 2020 to 2043 via input elements which included economic development, total natural resource rents, renewable and non-renewable energy, industrialization, and urbanization. To attain this goal, the study initially validated the GMDH model's prediction capacity by examining which input variable has the most significant impact on carbon emissions using actual data. Reported findings revealed that the most critical factors influencing carbon emissions were industrialization, fossil fuel energy use, and urbanization.
In contrast, renewable energy had the lowest impact on carbon emissions across the period studied. The GMDH model's predicted carbon emission values were close to the actual values. We also confirmed from the GMDH model that carbon emissions in China will likely peak around 2033 and fall slowly but steadily until 2043. To achieve the 2030 carbon emissions peaking target, a careful implementation of the pertinent energy economic structure and clean energy architecture by the Chinese government while upholding a sustainable economy is outlined in the "14th and 15th Five-Year Planned" policies.
References
Adeniran AA, Adebayo AR, Salami HO, Yahaya MO, Abdulraheem A (2019) A competitive ensemble model for permeability prediction in heterogeneous oil and gas reservoirs. Appl Comput Geosci 1:100004
Ahmadi MA, Chen Z (2019) Comparison of machine learning methods for estimating permeability and porosity of oil reservoirs via petro-physical logs. Petroleum 5:271–284
Ahmed M, Shuai C, Ahmed M (2022a) Analysis of energy consumption and greenhouse gas emissions trend in China, India, the USA, and Russia. Int J Environ Sci Technol 20:2643
Ahmed M, Shuai C, Ahmed M (2022b) Influencing factors of carbon emissions and their trends in China and India: a machine learning method. Environ Sci Pollut Res 29:48424
Al-Abadi AM, Handhal AM, Al-Ginamy MA (2020) Evaluating the Dibdibba Aquifer productivity at the Karbala-Najaf plateau (Central Iraq) using GIS-based tree machine learning algorithms. Nat Resour Res 29:1989–2009
Anastasakis L, Mort N (2001) The development of self-organization techniques in modelling: a review of the group method of data handling (GMDH). Research Report-University of Sheffield Department of Automatic Control and Systems Engineering
Armaghani DJ, Momeni E, Asteris PG (2020) Application of group method of data handling technique in assessing deformation of rock mass. Metaheur Comput Appl 1:1–18
Asante-okyere S, Shen C, YevenyoZiggah Y, Moses Rulegeya M, Zhu X (2018) Investigating the predictive performance of Gaussian process regression in evaluating reservoir porosity and permeability. Energies 11:3261
Cai K, Wu L (2022) Using grey Gompertz model to explore the carbon emission and its peak in 16 provinces of China. Energy Build 277:112545
Chai J, Shi H, Lu Q, Hu Y (2020) Quantifying and predicting the water-energy-food-economy-society-environment nexus based on bayesian networks—a case study of China. J Clean Prod 256:120266
Cheng Y, Gu B, Tan X, Yan H, Sheng Y (2022) Allocation of provincial carbon emission allowances under China’s 2030 carbon peak target: a dynamic multi-criteria decision analysis method. Sci Total Environ 837:155798
Chi Y, Guo Z, Zheng Y, Zhang X (2014) Scenarios analysis of the energies’ consumption and carbon emissions in China based on a dynamic CGE model. Sustainability 6:487–512
den Elzen M, Fekete H, Höhne N, Admiraal A, Forsell N, Hof AF, Olivier JG, Roelfsema M, van Soest H (2016) Greenhouse gas emissions from current and enhanced policies of China until 2030: Can emissions peak before 2030? Energy Policy 89:224–236
Ding S, Zhang M, Song Y (2019) Exploring China’s carbon emissions peak for different carbon tax scenarios. Energy Policy 129:1245–1252
Enerdata (2019) Coal and lignite domestic consumption. . https://yearbook.enerdata.net/coal-lignite/coal-world-consumptiondata.html
Fan T, Luo R, Xia H, Li X (2015) Using LMDI method to analyze the influencing factors of carbon emissions in China’s petrochemical industries. Nat Hazards 75:319–332
Fan R, Zhang X, Bizimana A, Zhou T, Liu J-S, Meng X-Z (2022) Achieving China’s carbon neutrality: predicting driving factors of CO2 emission by artificial neural network. J Clean Prod 362:132331
Feng R, Zheng H-J, Gao H, Zhang A-R, Huang C, Zhang J-X, Luo K, Fan J-R (2019) Recurrent neural network and random forest for analysis and accurate forecast of atmospheric pollutants: a case study in Hangzhou, China. J Clean Prod 231:1005–1015
Fu Y, Huang G, Liu L, Zhai M (2021) A factorial CGE model for analyzing the impacts of stepped carbon tax on Chinese economy and carbon emission. Sci Total Environ 759:143512
Gao C, Tao S, He Y, Su B, Sun M, Mensah IA (2021) Effect of population migration on spatial carbon emission transfers in China. Energy Policy 156:112450
Guo X, Pang J (2023) Analysis of provincial CO2 emission peaking in China: Insights from production and consumption. Appl Energy 331:120446
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9:1735–1780
Hu Y, Ren S, Wang Y, Chen X (2020) Can carbon emission trading scheme achieve energy conservation and emission reduction? Evidence from the industrial sector in China. Energy Econ 85:104590
Huang Y, Shen L, Liu H (2019) Grey relational analysis, principal component analysis and forecasting of carbon emissions based on long short-term memory in China. J Clean Prod 209:415–423
Hübler M, Voigt S, Löschel A (2014) Designing an emissions trading scheme for China—An up-to-date climate policy assessment. Energy Policy 75:57–72
IEA (2020) Report extract Final consumption. https://www.iea.org/reports/key-world-energy-statistics-2020/final-consumption
Ivakhnenko AG (1968) The group method of data of handling; a rival of the method of stochastic approximation. Sov Autom Cont 13:43–55
Jin H (2021) Prediction of direct carbon emissions of Chinese provinces using artificial neural networks. PLoS ONE 16:e0236685
Joshua U, Bekun FV, Sarkodie SA (2020) New insight into the causal linkage between economic expansion, FDI, coal consumption, pollutant emissions and urbanization in South Africa. Environ Sci Pollut Res 27:18013–18024
Li Y (2020) Forecasting Chinese carbon emissions based on a novel time series prediction method. Energy Sci Eng 8:2274–2285
Li H, Qin Q (2019) Challenges for China’s carbon emissions peaking in 2030: a decomposition and decoupling analysis. J Clean Prod 207:857–865
Li N, Zhang X, Shi M, Zhou S (2017) The prospects of China’s long-term economic development and CO2 emissions under fossil fuel supply constraints. Resour Conserv Recycl 121:11–22
Li F, Xu Z, Ma H (2018) Can China achieve its CO2 emissions peak by 2030? Ecol Ind 84:337–344
Li W, Zhang S, Lu C (2022) Exploration of China’s net CO2 emissions evolutionary pathways by 2060 in the context of carbon neutrality. Sci Total Environ 831:154909
Li D, Shen L, Zhong S, Elshkaki A, Li X (2023a) Spatial and temporal evolution patterns of material, energy and carbon emission nexus for power generation infrastructure in China. Resour Conserv Recycl 190:106775
Li R, Liu Q, Cai W, Liu Y, Yu Y, Zhang Y (2023b) Echelon peaking path of China’s provincial building carbon emissions: considering peak and time constraints. Energy 271:127003
Liu S, Jiang Y, Yu S, Tan W, Zhang T, Lin Z (2022) Electric power supply structure transformation model of China for peaking carbon dioxide emissions and achieving carbon neutrality. Energy Rep 8:541–548
Magazzino C, Mele M, Schneider N (2021) A machine learning approach on the relationship among solar and wind energy production, coal consumption, GDP, and CO2 emissions. Renew Energy 167:99–115
Mahmoud AA, Elkatatny S, Ali AZ, Abouelresh M, Abdulraheem A (2019) Evaluation of the total organic carbon (TOC) using different artificial intelligence techniques. Sustainability 11:5643
Mendonça AKDS, De Andrade ConradiBarni G, Moro MF, Bornia AC, Kupek E, Fernandes L (2020) Hierarchical modeling of the 50 largest economies to verify the impact of GDP, population and renewable energy generation in CO2 emissions. Sustain Product Consump 22:58–67
Mi Z, Wei Y-M, Wang B, Meng J, Liu Z, Shan Y, Liu J, Guan D (2017) Socioeconomic impact assessment of China’s CO2 emissions peak prior to 2030. J Clean Prod 142:2227–2236
Najafzadeh M, Azamathulla HM (2013) Group method of data handling to predict scour depth around bridge piers. Neural Comput Appl 23:2107–2112
NDRC (2017) National Key Energy-Saving Low-Carbon Technology Promotion Catalog (2017) (in Chinese)
NDRC 2021. National Development and Reform Commission
Normile D (2020) China’s bold climate pledge earns praise-but is it feasible? Science 370(6512):17–18
Okon AN, Adewole SE, Uguma EM (2021) Artificial neural network model for reservoir petrophysical properties: porosity, permeability and water saturation prediction. Model Earth Syst Environ 7:2373–2390
Rehman E, Rehman S (2022) Modeling the nexus between carbon emissions, urbanization, population growth, energy consumption, and economic development in Asia: evidence from grey relational analysis. Energy Rep 8:5430–5442
Ren F, Long D (2021) Carbon emission forecasting and scenario analysis in Guangdong Province based on optimized fast learning network. J Clean Prod 317:128408
Ridzuan NHAM, Marwan NF, Khalid N, Ali MH, Tseng M-L (2020) Effects of agriculture, renewable energy, and economic growth on carbon dioxide emissions: evidence of the environmental Kuznets curve. Resour Conserv Recycl 160:104879
Riti JS, Song D, Shu Y, Kamah M (2017) Decoupling CO2 emission and economic growth in China: Is there consistency in estimation results in analyzing environmental Kuznets curve? J Clean Prod 166:1448–1461
Shen C, Asante-Okyere S, YevenyoZiggah Y, Wang L, Zhu X (2019) Group method of data handling (GMDH) lithology identification based on wavelet analysis and dimensionality reduction as well log data pre-processing techniques. Energies 12:1509
Shi C, Zhi J, Yao X, Zhang H, Yu Y, Zeng Q, Li L, Zhang Y (2023) How can China achieve the 2030 carbon peak goal—a crossover analysis based on low-carbon economics and deep learning. Energy 269:126776
Sorkun MC, Incel ÖD, Paoli C (2020) Time series forecasting on multivariate solar radiation data using deep learning (LSTM). Turkish J Electr Eng Comput Sci 28:211–223
Sundermeyer M, Ney H, Schlüter R (2015) From feedforward to recurrent LSTM neural networks for language modeling. IEEE/ACM Trans Audio, Speech, Lang Process 23:517–529
Valadkhani A, Smyth R, Nguyen J (2019) Effects of primary energy consumption on CO2 emissions under optimal thresholds: evidence from sixty countries over the last half century. Energy Econ 80:680–690
Wang Z, Zhu Y, Zhu Y, Shi Y (2016) Energy structure change and carbon emission trends in China. Energy 115:369–377
Wang S, Li C, Zhou H (2019) Impact of China’s economic growth and energy consumption structure on atmospheric pollutants: Based on a panel threshold model. J Clean Prod 236:117694
Xu G, Schwarz P, Yang H (2019) Determining China’s CO2 emissions peak with a dynamic nonlinear artificial neural network approach and scenario analysis. Energy Policy 128:752–762
Xu G, Schwarz P, Yang H (2020) Adjusting energy consumption structure to achieve China’s CO2 emissions peak. Renew Sustain Energy Rev 122:109737
Yahya NA, Samsudin R, Shabri A, Saeed F (2019) Combined group method of data handling models using artificial bee colony algorithm in time series forecasting. Procedia Comput Sci 163:319–329
Yang M, Liu Y (2023) Research on the potential for China to achieve carbon neutrality: a hybrid prediction model integrated with elman neural network and sparrow search algorithm. J Environ Manage 329:117081
Yin Q, Zhang R, Shao X (2019) CNN and RNN mixed model for image classification. MATEC Web of Conferences
Yu S, Zheng S, Li X, Li L (2018) China can peak its energy-related carbon emissions before 2025: evidence from industry restructuring. Energy Econ 73:91–107
Zeng S, Su B, Zhang M, Gao Y, Liu J, Luo S, Tao Q (2021) Analysis and forecast of China’s energy consumption structure. Energy Policy 159:112630
Zhang X, Karplus VJ, Qi T, Zhang D, He J (2016) Carbon emissions in China: How far can new efforts bend the curve? Energy Econ 54:388–395
Zhang F, Deng X, Xie L, Xu N (2021) China’s energy-related carbon emissions projections for the shared socioeconomic pathways. Resour Conserv Recycl 168:105456
Zhang M, Ge Y, Liu L, Zhou D (2022a) Impacts of carbon emission trading schemes on the development of renewable energy in China: Spatial spillover and mediation paths. Sustain Product Consum 32:306–317
Zhang Y, Qi L, Lin X, Pan H, Sharp B (2022b) Synergistic effect of carbon ETS and carbon tax under China’s peak emission target: a dynamic CGE analysis. Sci Total Environ 825:154076
Zhang S, chen W (2021) China’s energy transition pathway in a carbon neutral vision. Engineering
Zhou N, Price L, Yande D, Creyts J, Khanna N, Fridley D, Lu H, Feng W, Liu X, Hasanbeigi A (2019) A roadmap for China to peak carbon dioxide emissions and achieve a 20% share of non-fossil fuels in primary energy by 2030. Appl Energy 239:793–819
Zhou S, Li W, Lu Z, Lu Z (2022) A technical framework for integrating carbon emission peaking factors into the industrial green transformation planning of a city cluster in China. J Clean Prod 344:131091
Acknowledgement
This work was supported by Humanities and Social Sciences Foundation of the Ministry of Education of China (No. 22YJA790030), and by the Fundamental Research Funds for the Central Universities, China University of Geosciences, Wuhan, China (CUG2642022006).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors have no known competing financial interest or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Editorial responsibility: Shahid Hussain.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Bosah, C.P., Li, S., Mulashani, A.K. et al. Analysis and forecast of China's carbon emission: evidence from generalized group method of data handling (g-GMDH) neural network. Int. J. Environ. Sci. Technol. 21, 1467–1480 (2024). https://doi.org/10.1007/s13762-023-05043-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13762-023-05043-z