
Abstract
Portland cement concrete (PCC) is the construction material most used worldwide. Hence, its proper characterization is fundamental for the daily-basis engineering practice. Nonetheless, the experimental measurements of the PCC’s engineering properties (i.e., Poisson’s Ratio -v-, Elastic Modulus -E-, Compressive Strength -ComS-, and Tensile Strength -TenS-) consume considerable amounts of time and financial resources. Therefore, the development of high-precision indirect methods is fundamental. Accordingly, this research proposes a computational model based on deep neural networks (DNNs) to simultaneously predict the v, E, ComS, and TenS. For this purpose, the Long-Term Pavement Performance database was employed as the data source. In this regard, the mix design parameters of the PCC are adopted as input variables. The performance of the DNN model was evaluated with 1:1 lines, goodness-of-fit parameters, Shapley additive explanations assessments, and running time analysis. The results demonstrated that the proposed DNN model exhibited an exactitude higher than 99.8%, with forecasting errors close to zero (0). Consequently, the machine learning-based computational model designed in this investigation is a helpful tool for estimating the PCC’s engineering properties when laboratory tests are not attainable. Thus, the main novelty of this study is creating a robust model to determine the v, E, ComS, and TenS by solely considering the mix design parameters. Likewise, the central contribution to the state-of-the-art achieved by the present research effort is the public launch of the developed computational tool through an open-access GitHub repository, which can be utilized by engineers, designers, agencies, and other stakeholders.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Portland Cement Concrete (PCC) is the composite material produced by mixing coarse aggregates (i.e., gravel), fine aggregates (i.e., sand), Portland Cement (PC), water, and optionally admixtures (e.g., chemical additives, fly ash, and steel slag) [1,2,3]. PCC is the world's most widely used construction material, mainly employed for constructing buildings and pavements [4,5,6]. Notoriously, the high consumption of time and financial resources for its proper experimental characterization implies that designers must resort to indirect methods [7,8,9]. However, the traditional mathematical models used for these purposes have been confirmed to be inaccurate and unreliable [10,11,12]. The preceding has led the estimation of PCC's engineering properties to focus on developing advanced computational models [13,14,15]. Within this field of research, Artificial Intelligence (AI)-based models stand out for their high precision and ability to adapt to new types of mixture designs not considered during the model creation stage [8, 14, 16].
Table 1 summarizes a literature review on estimating PCC's engineering properties using AI techniques. This table shows that most previous investigations focused on predicting Compressive Strength (ComS) and Tensile Strength (TenS). The preceding is expected since the ComS and TenS are the most relevant properties (regarding the characterization of the PCC's mechanical behaviour) to design structural elements and rigid pavements, respectively [17,18,19]. On the other hand, Table 1 also reveals a critical gap in the state-of-the-art, i.e., in none of the consulted research, Poisson's Ratio (v) and Elastic Modulus (E) are considered output variables. In this regard, the aforementioned computational models did not take into account the strong relationship that exists between the resistance-related properties with the v and E. In other words, previous case studies do not guarantee that for each evaluated dataset (i.e., a set of experimental data), the physical associations between v, E, ComS, and TenS would be simultaneously maintained.
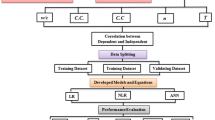
The present research aims to overcome the previously explained literature gap. Consequently, a computational model is proposed using the Long-Term Pavement Performance (LTPP) database as the data source [23]. Specifically, a Machine Learning (ML) technique called Artificial Neural Network (ANN) is employed for this purpose. From the LTPP database, experimental information from multiple PCC samples was extracted. The experimental information includes design variables and laboratory testing results (i.e., v, E, ComS, and TenS). In turn, the PCC's design variables comprise the following parameters: volumetric air content (VairC), volumetric aggregate content (VaggC), volumetric PC content (VpcC), volumetric water content (VwC), gravimetric water-to-cement ratio (GwcR), and specific gravity (Gs). Notoriously, it is expected that the proposed ANN model can be used (by agencies, designers and the scientific community) to forecast the PCC's engineering properties (v, E, ComS, and TenS) when experimental measurements are not feasible.
Below is described the structure of the present manuscript. Initially, Sect. 2 describes the origin of the data used to develop the ML-based model. Next, Sect. 3 introduces the computational methods employed, and the basic concepts of ANNs are also explained. Then, Sect. 4 exhibits a deep discussion about the exactness and accuracy of the proposed computational model. It is important to highlight that the discussion section includes several SHapley Additive exPlanations (SHAP) assessments and running time analyses. Finally, Sect. 5 summarises the research and offers the main findings and conclusions achieved throughout the investigation.
2 Data Source
All the data employed in this investigation was extracted from the LTPP database. The LTPP's information management system has operated since 1988 and is managed by the Federal Highway Administration (i.e., part of the US Department of Transportation) [24,25,26,27]. The LTPP database comprises exhaustive information about design parameters, laboratory characterization of materials, climate variables, in-situ performance, and life-cycle behaviour on over 2500 pavement test sections in the USA and Canada [28,29,30,31].
With the aim of filtering the relevant information (for this study) from the LTPP database, it was decided to solely consider the experimental dataset that simultaneously contains information about VairC, VaggC, VpcC, VwC, GwcR, Gs, v, E, ComS, and TenS. Furthermore, the datasets were manually scanned to discard those with missing information. Consequently, a total number of 75 datasets were finally obtained from experimental/laboratory works that were developed in the US states of Alabama, Arizona, Arkansas, California, Colorado, Delaware, Illinois, Indiana, Iowa, Kansas, Michigan, Missouri, North Carolina, North Dakota, Ohio, Oklahoma, Texas, Washington, and Wisconsin. In this regard, it is essential to highlight that all datasets used in this research are available for free download on the LTPP's website. Table 2 presents the adopted datasets' statistical description (i.e., each variable's minimum, maximum, mean, median, standard deviation, kurtosis, and skewness values). Also, Fig. 1 shows a scatterplot matrix to depict the considered parameters' variability and correlation. From Fig. 1, it is clear that there is no marked trend between the input data (i.e., the design variables comprised by the VairC, VaggC, VpcC, VwC, GwcR, and Gs) and the output data (i.e., the laboratory testing results comprised by v, E, ComS, and TenS).

Correlation and variability of the considered variables. Units: VairC (%); VaggC (%); VpcC (%); VwC (%); GwcR (-); Gs (-); v (-); E (GPa); ComS (MPa); TenS (MPa)
2.1 Definition of New Input Variables
According to Fig. 1, there is no strong correlation between the input and output variables (at least in their current form). Therefore, in order to generate more relationships between the considered properties, it was decided to create four new input variables, namely volumetric water-to-cement ratio (VwcR), volumetric paste content (VpasteC), aggregate-to-paste ratio (AggPasR), and paste to air ratio (PasAirR). Equations (1), (2), (3), and (4) show the mathematical formulations for calculating VwcR, VpasteC, AggPasR, and PasAirR, respectively. In Eq. (1), Gs_pc refers to the specific gravity of the PC, which was assumed as a typical value of 3.1 [32,33,34].
2.2 Feature Scaling
According to Table 2, the input and output variables present different units and magnitudes, making the learning process of ANNs demanding. In order to simplify the artificial learning procedure, it was decided to apply a feature scaling technique called standardization; Eq. (5) shows its mathematical definition [35]. The standardization process transforms data arrays, obtaining a new one with three principal characteristics [36, 37]: (i) mean equal to 0, (ii) standard deviation equal to 1, (iii) and most data points are between the range [− 1, 1]. Table 3 exhibits the basic statistical description of the transformed variables; in this table, it is clear that the standardized variables present the expected (and previously explained) features.
2.3 Data Augmentation
The main limitation of this study is that the employed database is only composed of 75 datasets. That amount of data is minimal; hence, an ML-based computational model created solely by that data could suffer from overfitting phenomena [38,39,40]. In order to avoid overfitting, it was decided to apply two techniques: (i) data augmentation during the data preprocessing stage and (ii) early stopping during the learning process stage. The early stopping technique is explained later in the manuscript. On the other hand, the data augmentation technique is just described below.
Data augmentation is one of the most powerful techniques to avoid overfitting [41,42,43]. Moreover, this technique stands out due to its simplicity [44, 45]. The data augmentation consists of conducting the model's learning process by considering several slightly altered copies of the original datasets together with the authentic ones [46,47,48]. Thus, for this research, it was decided to create 9 modified copies of each of the original datasets. Each modified copy was formed by affecting the authentic values with a pseudo-random distortion of between ± 3%. This low alteration ratio was selected to ensure that the physical consistency of the concrete mix designs was maintained. In this regard, 675 artificial datasets were obtained, which, added to the 75 original datasets, yields a total of 750. For the subsequent learning process (that is, the design of the ANN architecture and its performance assessments), the embraced database was separated as follows: 70% (i.e., 525 datasets) for the training process, 20% (i.e., 150 datasets) for the testing process, and 10% (i.e., the remaining 75 datasets) for the validation. It is crucial to highlight that this classification is accomplished using a random shuffle.
3 Methods
A broad set of ML-based computational techniques can be used for regression/forecasting problems, e.g., ANNs, bagging regressors, decision trees, lasso regression, random forests, and support vector machines [49,50,51,52]. In this research, it was decided to apply ANNs to estimate the PCC's engineering properties (v, E, ComS, and TenS). The ANNs are one of the most popular deep-learning techniques because they allow for establishing correlations between variables that did not present a strong relationship [22, 45, 53]. The internal working of the ANNs is based on replicating the logic of the human brain's neural connections [11, 54, 55]. Specifically, in this study, it was decided to apply a type of ANN called Deep Neural Networks (DNNs). The DNNs are defined as ANNs with at least two hidden layers and densely linked neurons (i.e., it is necessary to establish all the possible connections between neurons) [9, 39, 54]. Figure 2 shows the base architecture of DNNs.

Based on the DNN canonical architecture shown in Fig. 2, the following aspects could be highlighted for this case study: (i) the input layer comprises 10 neurons (i.e., each neuron for each input variable presented in Table 3); (ii) the output layer comprises 4 neurons (i.e., each neuron for each output variable presented in Table 3); and (iii) the number of hidden layers and their number of neurons should be determined. In order to obtain a suitable configuration of the number of hidden layers and neurons, an extensive inspection of the possible combinations was carried out. In this way, the most appropriate DNN architecture was found, as indicated in Fig. 3. According to Fig. 3, there are four hidden layers. Respectively, the first, second, third and fourth hidden layers are composed of 800, 640, 160, and 40 neurons. Therefore, the proposed DNN is formed by 6 layers, 1654 neurons, and 630,604 trainable parameters. The procedure to calculate the total number of trainable parameters is exhibited in Table 4.

Proposed DNN
In Fig. 3, two characteristics stand out: (i) all the hidden layers are affected by the hyperbolic tangent (tanh) activation function, and (ii) the proposed DNN is executed under a first-order gradient-based optimization method called Adamax. On the one hand, tanh is one of the most helpful activation functions because it causes all data coming out of a layer to be between the closed interval from -1 to 1 [57,58,59]. The preceding is particularly desirable in this case study because, according to Table 3, most of the data points (for both input and output variables) are comprehended within that range. In this regard, it was deliberately designed that the output layer would not have an activation function so that the few data outside the interval [− 1, 1] could be adequately predicted. On the other hand, Adamax is a variant of the traditional Adam optimization method [41, 60]. The internal functioning of Adamax is based on the infinity norm concept, which allows a high capacity to modify the learning rate according to the features of the input data [60, 61]. Algorithm 1 explains in detail the optimization procedure applied by Adamax [62, 63]. Also, Table 5 shows the hyperparameter values adopted for this case study.

t - iteration index; m - first moment vector; u - exponentially weighted infinity norm; w - convergence parameter (weight variable); T - number of iterations to reach the convergence; gt - gradient; β1 - exponential decay rate for the first moment estimates; β2 - exponential decay rate for the exponentially weighted infinity norm; lr - learning rate; ε - small constant for numerical stability
In order to make this research reproducible, duplicatable, and replicable, Algorithm 2 shows the simplified pseudocode of the proposed DNN. Further, the authors publicly share the computational model to the following GitHub repository (programmed in Python language): https://github.com/rpoloe/PCC. It is essential to highlight that the authors bring an open license to guarantee the unrestricted use, modification, and distribution of the codes hosted in this repository. From Algorithm 2, four aspects should be discussed: (i) the selected loss function, (ii) the error metrics employed, and (iii) the required number of epochs.
The Mean Square Error (MSE) was chosen as the loss function. Equation (6) explains it [54, 56]. The MSE is one of the most common loss functions because it maximizes the differences between predicted and expected values [55, 64, 65]. Furthermore, four additional error metrics were considered, namely Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), Mean Squared Logarithmic Error (MSLE), and the Logarithm of the Hyperbolic Cosine of the Error (LHCE). Respectively, Eqs. (7), (8), (9), and (10) define the MAE, MAPE, MSLE, and LHCE [54, 56]. On the other hand, the early stopping technique demarcated the required number of epochs (i.e., cycles of training and testing). This technique consists of determining the maximum number of epochs that the optimization process can reach before stopping learning, which is evidenced when, in the error functions (in this case, MSE, MAE, MAPE, MSLE, and LHCE), the assumed error changes from a decreasing trend to an ascending one [40, 54, 66]. In other words, the early stopping technique consists of locating the moment of maximum precision [54, 67, 68]. For the proposed DNN, the instant when learning stagnated varied between 600 and 1400 epochs (depending on the error metrics). Thus, with the aim of adopting a conservative number of epochs, this was set at 500.
where n—number of data points. i—data index. OD—observed/experimental data. ED—estimated data.

Simplified pseudocode to create the proposed DNN
4 Discussion
4.1 Model’s Exactness
Figure 4 compares the measured and predicted values of the PCC's engineering properties through 1:1 line plots. This figure clearly shows that the proposed DNN model can assemble forecasting with almost perfect accuracy. Regardless of the origin of the datasets (i.e., training, testing, or validation), the computational model is able to reproduce the laboratory-tested behaviour. It is paramount to emphasise that the training and testing datasets are employed along the supervised learning process, but the model has no prior knowledge of the validation datasets [69, 70]. Therefore, the validation datasets corroborate whether the DNN architecture can forecast never-before-observed scenarios [71, 72]. Thus, based on Fig. 4, it is possible to recognise the almost perfect estimation capacity of the proposed computational model. Besides, several goodness-of-fit parameters are examined in Fig. 5 and Table 6. These parameters are the previously introduced error metrics and the coefficient of determination (R2). Table 6 shows the goodness-of-fit parameters at the first and last epochs, as well as the “initial/final” error ratio. From this table, the following findings can be drawn. First, at the final epoch, the prediction errors of the DNN model are close to zero (0). Second, the error metrics that best capture the improving behaviour of the DNN architecture through the epochs are MSE and MSLE. Third, at the initial epoch, the accuracy of the estimations according to the R2 parameters was between 2.7–11.7%, 0.5–2.3%, 19.4–24.6%, and 0.4–6.0% for v, E, ComS, and TenS, respectively. Fourth, at the final epoch, the accuracy of the estimations according to the R2 parameters was higher than 99.8% for all the forecasted properties. Also, Fig. 5 provides a detailed explanation of the error evolution along the epochs, which reveals that overfitting and underfitting are not occurring.

Comparison of measured and predicted values (1:1 lines)

Statistical evaluation of the proposed DNN
4.2 SHAP Assessments
Figure 6 exhibits four SHAP assessments on the proposed DNN: a summary plot, a waterfall plot, a decision plot for the training datasets, and a decision plot for the testing datasets. The summary plot represents a SHAP global interpretation of the DNN model, whilst the other charts correspond to SHAP local interpretations [54, 73]. According to these plots, it is possible to draw the following findings. In the summary plot, each input variable has an associated SHAP value. Higher SHAP values indicate more influence on the global predictive response of the DNN model [74, 75]. Therefore, the Gs, VairC, AggPasR, PasAirR, and GwcR are the input variables with more weight in the computational model. Thus, it is clear that creating new variables was a valuable strategy for this case study. In the waterfall plot, the input variables marked with red color (i.e., solely Gs and VairC) display a positive contribution to the output variables, whilst the blue color (i.e., all the input variables except Gs and VairC) denotes a negative one. This behaviour is helpful for the user to understand how the DNN model internally works [76, 77]. Meanwhile, the decision plots do not provide meaningful information individually since they reveal the learning trend followed by the DNN model [75, 77]. However, when comparing the decision plots for the training and testing datasets, it is notable that they follow a very similar trajectory. Hence, it is evidenced that the two phases of the learning process are congruent, which is desired [78, 79].

SHAP assessments for the proposed DNN model
4.3 Running Time
The running time of ML-based computational models is an important parameter to assess the feasibility of their implementation in the daily-basis engineering practice [52, 56]. For this purpose, the proposed DNN model was evaluated using Python's native "TIME" module. Thus, the proposed DNN was executed on 100 independent occasions; Fig. 7 shows these results. According to this graph, the minimum, maximum, and average rutting times were 54.70, 87.47, and 66.01 s, respectively. Also, the standard deviation of the measurements was 10.15 s. Therefore, the proposed DNN requires approximately one minute for its execution, i.e., an acceptable magnitude within the context of civil engineering [52, 54]. It is essential to highlight that the running time depends primarily on the software and hardware used [80,81,82]. Hence, in order to be transparent, the ones used in this research are detailed below. On the one hand, Google Colab (a hosted Jupyter Notebook service) was utilized as the development environment. On the other hand, the NVIDIA® V100 Tensor Core GPU was adopted as the acceleration hardware.

Analysis of running time for the proposed DNN
4.4 Model’s Limitations
The central limitation of the proposed DNN model is associated with the adopted database. The DNN architecture was trained, tested, and validated with 750 datasets. Nonetheless, only 75 datasets were obtained experimentally (from the LTPP database), and the other 675 datasets were artificially created through the data augmentation technique. Although this technique has been widely used in the literature to improve limited databases in ML-related regression problems [42,43,44,45, 83,84,85], the new modified database may not be broad enough to cover all physically/phenomenologically conceivable scenarios [44, 86, 87]. Therefore, the proposed DNN model may not yield highly accurate predictions of engineering properties (v, E, ComS, and TenS) for PCC mix designs that incorporate unconventional proportions of raw materials.
Another limitation of the computational model is that it is designed to forecast ordinary PCC's engineering properties (v, E, ComS, and TenS). In other words, the proposed DNN model is not able to predict the performance-related properties of mix designs that contain additives or supplementary cementitious materials (e.g., blast furnace slag, coal bottom ash, coal fly ash, metakaolin, palm oil ash, rice husk ash, silica fume, and steel slag [4, 88,89,90]). The preceding is particularly important considering that modified PCCs are increasingly used to construct buildings and rigid pavement.
5 Conclusions
In this investigation, an ML-based computational model was developed to estimate the engineering properties of the PCC, namely v, E, ComS, and TenS. Specifically, the ANN technique was employed as the primary computational method. In this regard, the LTPP database was utilized as the data source for the experimental/laboratory information. Eventually, a DNN architecture was proposed and evaluated with 1:1 lines, goodness-of-fit parameters, SHAP assessments, and running time analyses. Thus, the main conclusions that can be drawn from this study are presented below:
-
The data preprocessing techniques (i.e., the definition of new input variables, feature scaling, and data augmentation) were necessary to obtain a proper ML-based computational model.
-
The most suitable DNN architecture comprised one 10-neuron input layer (each neuron for each input variable), four hidden layers, and one 4-neuron output layer (each neuron for each output variable). The hidden layers subsequently had the following number of neurons: 800, 640, 160 and 40. Also, the tanh activation function was added for all the hidden layers.
-
Notoriously, the proposed DNN shows an accuracy higher than 99.8%, which makes it a valuable tool for estimating the engineering properties of PCC when there is no possibility of experimental measurements.
-
The SHAP assessments demonstrated that the input variables more critical for the proposed DNN model were the Gs, VairC, AggPasR, PasAirR, and GwcR.
-
The average running time of the proposed DNN model is approximately one minute, which implies a relatively low time quantity. In this regard, the model's speed is expected to be an attractive feature for potential users.
-
Although the proposed DNN model is limited by the few original datasets, its most significant advantage is that it can be easily used for transfer learning. Accordingly, other researchers and designers can adjust/fine-tune the model for their contexts. Hence, the authors publicly share the computational model assembled in this study through an open-access GitHub repository.
Data availability
The authors publicly share the computational model produced in this research through the following GitHub repository: https://github.com/rpoloe/PCC.
References
Liu, Y.; Du, P.; Tan, K.H.; Du, Y.; Su, J.; Shi, C.: Experimental and analytical studies on residual flexural behaviour of reinforced alkali-activated slag-based concrete beams after exposure to fire. Eng. Struct. 298, 1–14 (2024). https://doi.org/10.1016/j.engstruct.2023.117035
Singh, A.; Bhadauria, S.S.; Thakare, A.A.; Kumar, A.; Mudgal, M.; Chaudhary, S.: Durability assessment of mechanochemically activated geopolymer concrete with a low molarity alkali solution. Case Stud. Constr. Mater. 20, 1–19 (2024). https://doi.org/10.1016/j.cscm.2023.e02715
Singh, P.R.; Vanapalli, K.R.; Jadda, K.: Durability assessment of fly ash, GGBS, and silica fume based geopolymer concrete with recycled aggregates against acid and sulfate attack. J. Build. Eng. 82, 1–17 (2024). https://doi.org/10.1016/j.jobe.2023.108354
Polo-Mendoza, R.; Mora, O.; Duque, J.; Turbay, E.; Martinez-Arguelles, G.; Fuentes, L.; Guerrero, O.; Perez, S.: Environmental and economic feasibility of implementing perpetual pavements (PPs) against conventional pavements: a case study of Barranquilla city, Colombia. Case Stud. Constr. Mater. 18, 1–21 (2023). https://doi.org/10.1016/j.cscm.2023.e02112
Yuanliang, X.; Zhongshuai, H.; Chao, L.; Chao, Z.; Yamei, Z.: Unveiling the role of Portland cement and fly ash in pore formation and its influence on properties of hybrid alkali-activated foamed concrete. Constr. Build. Mater. 411, 1–10 (2024). https://doi.org/10.1016/j.conbuildmat.2023.134336
Yang, Y.; Yao, J.; Liu, J.; Kong, D.; Gu, C.; Wang, L.: Evaluation of the thermal and shrinkage stresses in restrained concrete: new method of investigation. Constr. Build. Mater. 411, 1–14 (2024). https://doi.org/10.1016/j.conbuildmat.2023.134493
Amin, M.N.; Khan, K.; Javed, M.F.; Aslam, F.; Qadir, M.G.; Faraz, M.I.: Prediction of mechanical properties of fly-ash/slag-based geopolymer concrete using ensemble and non-ensemble machine-learning techniques. Materials 15, 1–20 (2022). https://doi.org/10.3390/ma15103478
Cao, R.; Fang, Z.; Jin, M.; Shang, Y.: Application of machine learning approaches to predict the strength property of geopolymer concrete. Materials 15, 1–15 (2022). https://doi.org/10.3390/ma15072400
Huynh, A.T.; Nguyen, Q.D.; Xuan, Q.L.; Magee, B.; Chung, T.; Tran, K.T.; Nguyen, K.T.: A machine learning-assisted numerical predictor for compressive strength of geopolymer concrete based on experimental data and sensitivity analysis. Appl. Sci. 10, 1–16 (2020). https://doi.org/10.3390/app10217726
Nithurshan, M.; Elakneswaran, Y.: A systematic review and assessment of concrete strength prediction models. Case Stud. Constr. Mater. 18, 1–15 (2023). https://doi.org/10.1016/j.cscm.2023.e01830
Moein, M.M.; Saradar, A.; Rahmati, K.; Ghasemzadeh Mousavinejad, S.H.; Bristow, J.; Aramali, V.; Karakouzian, M.: Predictive models for concrete properties using machine learning and deep learning approaches: a review. J. Build. Eng. 63, 1–41 (2023). https://doi.org/10.1016/j.jobe.2022.105444
Ahmed, H.U.; Mohammed, A.S.; Qaidi, S.M.A.; Faraj, R.H.; Hamah Sor, N.; Mohammed, A.A.: Compressive strength of geopolymer concrete composites: a systematic comprehensive review, analysis and modeling. Eur. J. Environ. Civ. Eng. 27, 1383–1428 (2023). https://doi.org/10.1080/19648189.2022.2083022
Mansouri, E.; Manfredi, M.; Hu, J.-W.: Environmentally friendly concrete compressive strength prediction using hybrid machine learning. Sustainability 14, 1–17 (2022). https://doi.org/10.3390/su142012990
Marks, M.; Glinicki, M.A.; Gibas, K.: Prediction of the chloride resistance of concrete modified with high calcium fly ash using machine learning. Materials 8, 8714–8727 (2015). https://doi.org/10.3390/ma8125483
Najm, H.M.; Nanayakkara, O.; Ahmad, M.; Sabri Sabri, M.M.: Mechanical properties, crack width, and propagation of waste ceramic concrete subjected to elevated temperatures: a comprehensive study. Materials 15, 1–32 (2022). https://doi.org/10.3390/ma15072371
Tang, Y.X.; Lee, Y.H.; Amran, M.; Fediuk, R.; Vatin, N.; Kueh, A.B.H.; Lee, Y.Y.: Artificial neural network-forecasted compression strength of alkaline-activated slag concretes. Sustainability 14, 1–20 (2022). https://doi.org/10.3390/su14095214
Shafigh, P.; Asadi, I.; Mahyuddin, N.B.: Concrete as a thermal mass material for building applications—A review. J. Build. Eng. 19, 14–25 (2018). https://doi.org/10.1016/j.jobe.2018.04.021
Rocha Segundo, I.; Silva, L.; Palha, C.; Freitas, E.; Silva, H.: Surface rehabilitation of Portland cement concrete (PCC) pavements using single or double surface dressings with soft bitumen, conventional or modified emulsions. Constr. Build. Mater. 281, 1–15 (2021). https://doi.org/10.1016/j.conbuildmat.2021.122611
Aquino Rocha, J.H.; Toledo Filho, R.D.: Microstructure, hydration process, and compressive strength assessment of ternary mixtures containing Portland cement, recycled concrete powder, and metakaolin. J. Clean. Prod. 434, 1–24 (2024). https://doi.org/10.1016/j.jclepro.2023.140085
Zou, Y.; Zheng, C.; Alzahrani, A.M.; Ahmad, W.; Ahmad, A.; Mohamed, A.M.; Khallaf, R.; Elattar, S.: Evaluation of artificial intelligence methods to estimate the compressive strength of geopolymers. Gels 8, 1–23 (2022). https://doi.org/10.3390/gels8050271
Shah, H.A.; Yuan, Q.; Akmal, U.; Shah, S.A.; Salmi, A.; Awad, Y.A.; Shah, L.A.; Iftikhar, Y.; Javed, M.H.; Khan, M.I.: Application of machine learning techniques for predicting compressive, splitting tensile, and flexural strengths of concrete with metakaolin. Materials 15, 1–36 (2022). https://doi.org/10.3390/ma15155435
Silva, V.P.; Carvalho, R.D.; Rêgo, J.H.; Evangelista, F., Jr.: Machine learning-based prediction of the compressive strength of Brazilian concretes: a dual-dataset study. Materials 16, 1–16 (2023). https://doi.org/10.3390/ma16144977
FHWA. Long-Term Pavement Performance Information Management System User Guide. Fed. Highw. Adm. FHWA-HRT-2, 1–208 (2021)
Karlaftis, A.G.; Badr, A.: Predicting asphalt pavement crack initiation following rehabilitation treatments. Transp. Res. Part C Emerg. Technol. 55, 510–517 (2015). https://doi.org/10.1016/j.trc.2015.03.031
Jia, Y.; Wang, S.; Huang, A.; Gao, Y.; Wang, J.; Zhou, W.: A comparative long-term effectiveness assessment of preventive maintenance treatments under various environmental conditions. Constr. Build. Mater. 273, 1–10 (2021). https://doi.org/10.1016/j.conbuildmat.2020.121717
Yu, Y.; Sun, L.: Effect of overlay thickness, overlay material, and pre-overlay treatment on evolution of asphalt concrete overlay roughness in LTPP SPS-5 experiment: a multilevel model approach. Constr. Build. Mater. 162, 192–201 (2018). https://doi.org/10.1016/j.conbuildmat.2017.12.039
Sollazzo, G.; Fwa, T.F.; Bosurgi, G.: An ANN model to correlate roughness and structural performance in asphalt pavements. Constr. Build. Mater. 134, 684–693 (2017). https://doi.org/10.1016/j.conbuildmat.2016.12.186
Gong, H.; Sun, Y.; Shu, X.; Huang, B.: Use of random forests regression for predicting IRI of asphalt pavements. Constr. Build. Mater. 189, 890–897 (2018). https://doi.org/10.1016/j.conbuildmat.2018.09.017
Gong, H.; Huang, B.; Shu, X.: Field performance evaluation of asphalt mixtures containing high percentage of RAP using LTPP data. Constr. Build. Mater. 176, 118–128 (2018). https://doi.org/10.1016/j.conbuildmat.2018.05.007
Chen, X.; Dong, Q.; Zhu, H.; Huang, B.: Development of distress condition index of asphalt pavements using LTPP data through structural equation modeling. Transp. Res. Part C Emerg. Technol. 68, 58–69 (2016). https://doi.org/10.1016/j.trc.2016.03.011
Gong, H.; Sun, Y.; Hu, W.; Polaczyk, P.A.; Huang, B.: Investigating impacts of asphalt mixture properties on pavement performance using LTPP data through random forests. Constr. Build. Mater. 204, 203–212 (2019). https://doi.org/10.1016/j.conbuildmat.2019.01.198
Rashidian-Dezfouli, H.; Rangaraju, P.R.: Evaluation of selected durability properties of portland cement concretes containing ground glass fiber as a pozzolan. Transp. Res. Rec. 2672, 88–98 (2018). https://doi.org/10.1177/0361198118773198
Ogbodo, M.C.; Akpabot, A.I.: An assessment of some physical properties of different brands of cement in Nigeria. In: IOP Conference Series: Materials Science and Engineering, vol. 1048, pp. 1–5 (2021). https://doi.org/10.1088/1757-899X/1048/1/012013
Zemri, C.; Bachir Bouiadjra, M.: Comparison between physical–mechanical properties of mortar made with Portland cement (CEMI) and slag cement (CEMIII) subjected to elevated temperature. Case Stud. Constr. Mater. 12, 1–12 (2020). https://doi.org/10.1016/j.cscm.2020.e00339
Latifoglu, L.; Ozger, M.: A novel approach for high-performance estimation of SPI data in drought prediction. Sustainability 15, 1–29 (2023). https://doi.org/10.3390/su151914046
Anysz, H.; Zbiciak, A.; Ibadov, N.: The influence of input data standardization method on prediction accuracy of artificial neural networks. Procedia Eng. 153, 66–70 (2016). https://doi.org/10.1016/j.proeng.2016.08.081
Deo, R.C.; Şahin, M.: Application of the Artificial Neural Network model for prediction of monthly Standardized Precipitation and Evapotranspiration Index using hydrometeorological parameters and climate indices in eastern Australia. Atmos. Res. 161–162, 65–81 (2015). https://doi.org/10.1016/j.atmosres.2015.03.018
Chollet Ramampiandra, E.; Scheidegger, A.; Wydler, J.; Schuwirth, N.: A comparison of machine learning and statistical species distribution models: quantifying overfitting supports model interpretation. Ecol. Model. 481, 1–11 (2023). https://doi.org/10.1016/j.ecolmodel.2023.110353
Ookura, S.; Mori, H.: An efficient method for wind power generation forecasting by LSTM in consideration of overfitting prevention. IFAC Pap. 53, 12169–12174 (2020). https://doi.org/10.1016/j.ifacol.2020.12.1008
Piotrowski, A.P.; Napiorkowski, J.J.: A comparison of methods to avoid overfitting in neural networks training in the case of catchment runoff modelling. J. Hydrol. 476, 97–111 (2013). https://doi.org/10.1016/j.jhydrol.2012.10.019
Bahtiyar, H.; Soydaner, D.; Yüksel, E.: Application of multilayer perceptron with data augmentation in nuclear physics. Appl. Soft Comput. 128, 1–9 (2022). https://doi.org/10.1016/j.asoc.2022.109470
Min, R.; Wang, Z.; Zhuang, Y.; Yi, X.: Application of semi-supervised convolutional neural network regression model based on data augmentation and process spectral labeling in Raman predictive modeling of cell culture processes. Biochem. Eng. J. 191, 1–9 (2023). https://doi.org/10.1016/j.bej.2022.108774
Hao, R.; Zheng, H.; Yang, X.: Data augmentation based estimation for the censored composite quantile regression neural network model. Appl. Soft Comput. 127, 1–11 (2022). https://doi.org/10.1016/j.asoc.2022.109381
Demir, S.; Mincev, K.; Kok, K.; Paterakis, N.G.: Data augmentation for time series regression: applying transformations, autoencoders and adversarial networks to electricity price forecasting. Appl. Energy 304, 1–19 (2021). https://doi.org/10.1016/j.apenergy.2021.117695
Hao, R.; Weng, C.; Liu, X.; Yang, X.: Data augmentation based estimation for the censored quantile regression neural network model. Expert Syst. Appl. 214, 1–15 (2023). https://doi.org/10.1016/j.eswa.2022.119097
Shorten, C.; Khoshgoftaar, T.M.: A survey on image data augmentation for deep learning. J. Big Data 6, 1–48 (2019). https://doi.org/10.1186/s40537-019-0197-0
Berrett, C.; Calder, C.A.: Data augmentation strategies for the Bayesian spatial probit regression model. Comput. Stat. Data Anal. 56, 478–490 (2012). https://doi.org/10.1016/j.csda.2011.08.020
Mazzoleni, M.; Breschi, V.; Formentin, S.: Piecewise nonlinear regression with data augmentation. IFAC Pap. 54, 421–426 (2021). https://doi.org/10.1016/j.ifacol.2021.08.396
Polo-Mendoza, R.; Martinez-Arguelles, G.; Peñabaena-Niebles, R.; Covilla-Valera, E.: Neural networks implementation for the environmental optimisation of the recycled concrete aggregate inclusion in warm mix asphalt. Road Mater. Pavement Des. (2023). https://doi.org/10.1080/14680629.2023.2230298
Himmetoğlu, S.; Delice, Y.; Aydoğan, E.K.; Uzal, B.: Green building envelope designs in different climate and seismic zones: multi-objective ANN-based genetic algorithm. Sustain. Energy Technol. Assess. 53, 1–17 (2022). https://doi.org/10.1016/j.seta.2022.102505
Minh, D.; Wang, H.X.; Li, Y.F.; Nguyen, T.N.: Explainable artificial intelligence: a comprehensive review. Artif. Intell. Rev. 55, 3503–3568 (2022). https://doi.org/10.1007/s10462-021-10088-y
Polo-Mendoza, R.; Martinez-Arguelles, G.; Peñabaena-Niebles, R.: A multi-objective optimization based on genetic algorithms for the sustainable design of Warm Mix Asphalt (WMA). Int. J. Pavement Eng. 24, 2074417 (2023). https://doi.org/10.1080/10298436.2022.2074417
Białek, J.; Bujalski, W.; Wojdan, K.; Guzek, M.; Kurek, T.: Dataset level explanation of heat demand forecasting ANN with SHAP. Energy 261, 1–12 (2022). https://doi.org/10.1016/j.energy.2022.125075
Polo-Mendoza, R.; Duque, J.; Mašín, D.; Turbay, E.; Acosta, C.: Implementation of deep neural networks and statistical methods to predict the resilient modulus of soils. Int. J. Pavement Eng. 24, 2257852 (2023). https://doi.org/10.1080/10298436.2023.2257852
Hamim, A.; Yusoff, N.I.M.; Omar, H.A.; Jamaludin, N.A.A.; Hassan, N.A.; El-Shafie, A.; Ceylan, H.: Integrated finite element and artificial neural network methods for constructing asphalt concrete dynamic modulus master curve using deflection time-history data. Constr. Build. Mater. 257, 1–14 (2020). https://doi.org/10.1016/j.conbuildmat.2020.119549
Polo-Mendoza, R.; Martinez-Arguelles, G.; Peñabaena-Niebles, R.: Environmental optimization of warm mix asphalt (WMA) design with recycled concrete aggregates (RCA) inclusion through artificial intelligence (AI) techniques. Res. Eng. 17, 1–15 (2023). https://doi.org/10.1016/j.rineng.2023.100984
Zdravković, S.; Kavitha, L.; Satarić, M.V.; Zeković, S.; Petrović, J.: Modified extended tanh-function method and nonlinear dynamics of microtubules. Chaos Solitons Fractals 45, 1378–1386 (2012). https://doi.org/10.1016/j.chaos.2012.07.009
Wuraola, A.; Patel, N.: Resource efficient activation functions for neural network accelerators. Neurocomputing 482, 163–185 (2022)
Liu, K.; Shi, W.; Huang, C.; Zeng, D.: Cost effective Tanh activation function circuits based on fast piecewise linear logic. Microelectron. J. 138, 1–9 (2023). https://doi.org/10.1016/j.mejo.2023.105821
Kingma, D.P.; Ba, J.L.: Amax: a method for stochastic optimization. In: 3rd International Conference on Learning Representations (ICLR), pp. 1–15 (2015)
Pandi Chandran, P.; Hema Rajini, N.; Jeyakarthic, M.: Optimal deep belief network enabled malware detection and classification model. Intell. Autom. Soft Comput. (2023). https://doi.org/10.32604/iasc.2023.029946
Obayya, M.; Maashi, M.S.; Nemri, N.; Mohsen, H.; Motwakel, A.; Osman, A.E.; Alneil, A.A.; Alsaid, M.I.: Hyperparameter optimizer with deep learning-based decision-support systems for histopathological breast cancer diagnosis. Cancers 15, 1–19 (2023). https://doi.org/10.3390/cancers15030885
Sadykov, M.; Haines, S.; Broadmeadow, M.; Walker, G.; Holmes, D.W.: Practical evaluation of lithium-ion battery state-of-charge estimation using time-series machine learning for electric vehicles. Energies 16, 1–34 (2023). https://doi.org/10.3390/en16041628
Zhang, S.; Lei, H.; Zhou, Z.; Wang, G.; Qiu, B.: Fatigue life analysis of high-strength bolts based on machine learning method and SHapley Additive exPlanations (SHAP) approach. Structures 51, 275–287 (2023). https://doi.org/10.1016/j.istruc.2023.03.060
Nicolson, A.; Paliwal, K.K.: Deep learning for minimum mean-square error approaches to speech enhancement. Speech Commun. 111, 44–55 (2019). https://doi.org/10.1016/j.specom.2019.06.002
Koya, B.P.; Aneja, S.; Gupta, R.; Valeo, C.: Comparative analysis of different machine learning algorithms to predict mechanical properties of concrete. Mech. Adv. Mater. Struct. 29, 4032–4043 (2022). https://doi.org/10.1080/15376494.2021.1917021
Vilares Ferro, M.; Doval Mosquera, Y.; Ribadas Pena, F.J.; Darriba Bilbao, V.M.: Early stopping by correlating online indicators in neural networks. Neural Netw. 159, 109–124 (2023). https://doi.org/10.1016/j.neunet.2022.11.035
Zeng, J.; Zhang, M.; Lin, S.-B.: Fully corrective gradient boosting with squared hinge: fast learning rates and early stopping. Neural Netw. 147, 136–151 (2022). https://doi.org/10.1016/j.neunet.2021.12.016
Singh, V.; Pencina, M.; Einstein, A.J.; Liang, J.X.; Berman, D.S.; Slomka, P.: Impact of train/test sample regimen on performance estimate stability of machine learning in cardiovascular imaging. Sci. Rep. 11, 1–8 (2021). https://doi.org/10.1038/s41598-021-93651-5
Xu, Y.; Goodacre, R.: On splitting training and validation set: a comparative study of cross-validation, bootstrap and systematic sampling for estimating the generalization performance of supervised learning. J. Anal. Test. 2, 249–262 (2018). https://doi.org/10.1007/s41664-018-0068-2
Quinn, T.P.; Le, V.; Cardilini, A.P.A.: Test set verification is an essential step in model building. Methods Ecol. Evol. 12, 127–129 (2021). https://doi.org/10.1111/2041-210X.13495
Straub, J.: Machine learning performance validation and training using a ‘perfect’ expert system. MethodsX 8, 1–6 (2021). https://doi.org/10.1016/j.mex.2021.101477
Polo-Mendoza, R.; Duque, J.; Mašín, D.: Prediction of California bearing ratio and modified proctor parameters using deep neural networks and multiple linear regression: a case study of granular soils. Case Stud. Constr. Mater. 20, 1–17 (2024). https://doi.org/10.1016/j.cscm.2023.e02800
Li, Z.: Extracting spatial effects from machine learning model using local interpretation method: an example of SHAP and XGBoost. Comput. Environ. Urban Syst. 96, 1–18 (2022). https://doi.org/10.1016/j.compenvurbsys.2022.101845
Kim, Y.; Kim, Y.: Explainable heat-related mortality with random forest and SHapley Additive exPlanations (SHAP) models. Sustain. Cities Soc. 79, 1–15 (2022). https://doi.org/10.1016/j.scs.2022.103677
Lin, K.; Gao, Y.: Model interpretability of financial fraud detection by group SHAP. Expert Syst. Appl. 210, 1–9 (2022). https://doi.org/10.1016/j.eswa.2022.118354
Kashifi, M.T.: Investigating two-wheelers risk factors for severe crashes using an interpretable machine learning approach and SHAP analysis. IATSS Res. 47, 357–371 (2023). https://doi.org/10.1016/j.iatssr.2023.07.005
Meng, Y.; Yang, N.; Qian, Z.; Zhang, G.: What makes an online review more helpful: an interpretation framework using XGBoost and SHAP values. J. Theor. Appl. Electron. Commer. Res. 16, 466–490 (2021). https://doi.org/10.3390/jtaer16030029
Scavuzzo, C.M.; Scavuzzo, J.M.; Campero, M.N.; Anegagrie, M.; Aramendia, A.A.; Benito, A.; Periago, V.: Feature importance: opening a soil-transmitted helminth machine learning model via SHAP. Infect. Dis. Model. 7, 262–276 (2022). https://doi.org/10.1016/j.idm.2022.01.004
Tang, Y.; Wang, C.: Performance modeling on DaVinci AI core. J. Parallel Distrib. Comput. 175, 134–149 (2023). https://doi.org/10.1016/j.jpdc.2023.01.008
Dube, P.; Suk, T.; Wang, C.: AI gauge: runtime estimation for deep learning in the cloud. In: 31st International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD), pp. 160–167 (2019)
Aghapour, Z.; Sharifian, S.; Taheri, H.: Task offloading and resource allocation algorithm based on deep reinforcement learning for distributed AI execution tasks in IoT edge computing environments. Comput. Netw. 223, 1–17 (2023). https://doi.org/10.1016/j.comnet.2023.109577
Assaf, A.M.; Haron, H.; Hamed, H.N.A.H.; Ghaleb, F.A.; Dalam, M.E.; Eisa, T.A.E.: Improving solar radiation forecasting utilizing data augmentation model generative adversarial networks with convolutional support vector machine (GAN-CSVR). Appl. Sci. 13, 1–23 (2023). https://doi.org/10.3390/app132312768
Harrou, F.; Dairi, A.; Dorbane, A.; Sun, Y.: Energy consumption prediction in water treatment plants using deep learning with data augmentation. Res. Eng. 20, 1–14 (2023). https://doi.org/10.1016/j.rineng.2023.101428
Liu, K.-H.; Xie, T.-Y.; Cai, Z.-K.; Chen, G.-M.; Zhao, X.-Y.: Data-driven prediction and optimization of axial compressive strength for FRP-reinforced CFST columns using synthetic data augmentation. Eng. Struct. 300, 1–16 (2024). https://doi.org/10.1016/j.engstruct.2023.117225
Mumuni, A.; Mumuni, F.: Data augmentation: a comprehensive survey of modern approaches. Array 16, 1–27 (2022). https://doi.org/10.1016/j.array.2022.100258
Maharana, K.; Mondal, S.; Nemade, B.: A review: data pre-processing and data augmentation techniques. Glob. Transitions Proc. 3, 91–99 (2022). https://doi.org/10.1016/j.gltp.2022.04.020
Walubita, L.F.; Martinez-Arguelles, G.; Polo-Mendoza, R.; Ick-Lee, S.; Fuentes, L.: Comparative environmental assessment of rigid, flexible, and perpetual pavement: a case study of Texas. Sustainability 14, 1–22 (2022). https://doi.org/10.3390/su14169983
Gupta, S.; Chaudhary, S.: State of the art review on supplementary cementitious materials in India—II: characteristics of SCMs, effect on concrete and environmental impact. J. Clean. Prod. 357, 1–19 (2022). https://doi.org/10.1016/j.jclepro.2022.131945
Sharma, R.K.; Singh, D.; Dasaka, S.M.: Investigating supplementary cementitious materials’ effects on stabilized aggregate performance, behaviour, and design aspects. Constr. Build. Mater. 411, 1–16 (2024). https://doi.org/10.1016/j.conbuildmat.2023.134564
Acknowledgements
The authors thank the Department of Science, Technology, and Innovation (COLCIENCIAS) and the Universidad del Norte for funding this investigation through the “Research Project 745/2016, Contract 037-2017, No. 1215-745-59105”.
Funding
Open Access funding provided by Colombia Consortium.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Polo-Mendoza, R., Martinez-Arguelles, G., Peñabaena-Niebles, R. et al. Development of a Machine Learning (ML)-Based Computational Model to Estimate the Engineering Properties of Portland Cement Concrete (PCC). Arab J Sci Eng 49, 14351–14365 (2024). https://doi.org/10.1007/s13369-024-08794-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13369-024-08794-0