
Abstract
Social network analytics in health-care is recently catching-all as world is recovering from Covid-19 pandemic and when it comes to dealing with mounting mental health problems in the online community. A technical breakthrough to quickly address this issue is a big bet on researchers to deliver better intelligent mental health scale and support in mental distress risk management. In this paper we aim to build four artificial-intelligence driven models by blending the power of two dominant deep learning neural networks for explaining and predicting mental distress risk in the crowd-sourced online community. The models are simulated using a novel feature construct, which is a combination of numerical and textual data. The numerical data are realized by encoding social networking sites behavior and physical, social, cognitive experiences as part of three axes of psychological distress (depression, anxiety and stress). The textual part of data is made up of social network comments mined to acquire mental distressed cues by applying feature extraction techniques such as word embeddings and glove embeddings techniques. With the hyper-parameter tuning of models, we attained excellent performance (accuracy ~ 99.20%) which proves the efficacy of the proposed hybrid mental distress prediction model well with respect to accuracy in comparison to other related recent existing models with a boost of 0.20%. Our experimental results offer a robust model wherein we achieved zero false positive cases, attained 100% precision and excellent F1 measures. Additionally, we validated our results by using state-of-the-art technique BERT on different ground truth dataset i.e.,, Indian tweets to explore the tweets for psychological-distress prediction. Thus, we present an effectual automated tool for treatment activation of mental distress and supporting decisions in fostering the mental health of online society.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Mental health is the most ignored area of health globally due to the poor consciousness of mental health signs, stigma associated with it, outdated system of services available, lack of preventive measures and shortage of human resources. This was the fact before Covid-19, but the pandemic has further worsened the mental health stats worldwide. Mental health numbers are staggering, in a recent WHO update close to 1 billion people are living with mental disorders with India reported for nearly 15% of the global mental, neurological and substance abuse disorder burden1. The access to quality mental health services health is low relatively to other health services. In low and middle-income countries, more than 75% of people with mental, neurological and substance use disorders do not receive treatment for their condition at all.Footnote 1 In India, the mental illness interference gap is almost 70 to 92% depending on the state, even when in a meta-analysis of community survey it is projected that the pervasiveness of depression and anxiety could be up to 33 per 1,000 persons as reported by WHO (Mental Health in Asia). India congregates 17.7% of the global population but very few survey studies have contributed to assessment of the incidence of mental disorders in India (Sagar et al. 2017).
Social Networking sites (SNS) have become a part of many people’s daily lives as the popularity of virtual connectivity and messaging apps has skyrocketed. The increasing popularity of SNS services has resulted in harmful usage and subsequently opens a way to increase in psychological mental problems in online community. Literature talks greatly about the connection of usage of social media platforms with mental health threat (Karim et al. 2020). Previous research also found that mental health issues due to social media is prevalent in all ages but with respect to gender, females were much more likely to experience mental health than males (Iannotti et al. 2009) (Sagar et al. 2017).
One of the best ways to solve this problem is to investigate the individual’s activities in greater depth. It is a challenge as well as responsibility of researchers and health professionals to find efficient ways to detect the mental health risk as early as possible to foster the mental health of the online community. In (Jo et al. 2017) authors highlighted the link between the computational models and psychological state, suggesting computational framework as fine objective method of assessing the real emotions of the person.
Since a decade the literature argues that Artificial Intelligence(AI) approach have advantages and are more beneficial with report of good performance in diagnosis of mental illness over traditional approaches. In Table 1, we present the comparison on points accentuated in the literature describing both the approaches, we emphasize that it can be considered as key motivation for the interested researchers in the field of fostering the mental health of the online community (Shatte et al. 2019) (Su 2020) (Saqib et al. 2021) (Thieme et al. 2020) (Cho et al. 2019) (Chancellor and De Choudhury 2020).
This paper establishes a framework for evaluating psychological distress episodes in the online society by employing a novel feature construct consisting of person’s overall personal, social and cognitive behavior on social media. The primary aim of this experiment is to put forward a reliable and unfailing processing model that can find the most significant mental risk features from the crowd-sourced dataset to improve the prediction accuracy and lessen the burden on clinicians and healthcare professionals. Following are the main contributions of the paper:
-
The proposed work assimilates a crowd-sourced data particularly from Indian online community with a novel set of feature construct consisting of some essential general information, social networking sites behavior, physical, social and cognitive experiences gathered through three axes of psychological distress (depression, anxiety, stress) combined with logs/postings on social media. We propose that our original dataset can be considered as benchmark for further research in this area.
-
The capabilities and strengths of two leading neural network techniques namely CNN and LSTM are hybridized to develop an automated system to predict mental distress happening in the virtual community and to identify the influential risk factors for mental distress that contribute the most to the diagnosis and treatment.
-
Our work utilizes word embeddings and Glove embeddings techniques, a dense vector representation of words that captures some context of the words on their own to process the logs/texts posted by the online society members and predict their mental distress state. Thus it contributes toward the importance of natural language processing tools in leading to cues related to mental health risk.
-
The study contributes to depict the relationship between various chosen variables with the mental state and explains the correlation between significant factors as causal for psychological distress occurrence. The findings of the dataset examined in the proposed approach is in sync with what literature asserts, thus strengthens and validates the crowd-sourced dataset used for investigating the occurrence of mental distress
-
Lastly, we offer an effective decision-making tool to assist clinicians and health caretakers in the early diagnosis of mental distress risks prevalent in the online society today.
The rest of the paper is aligned as follows: continuation to this section we present the problem statement followed by motivation for this study. Section 2 contains the literature review and related work connecting to this study. Sections 3 describe the methodology consisting of data pre-processing, methods, techniques and proposed algorithm. Section 4 presents results and discussion. Finally conclusion is discussed with future scope and mentioned in Sect. 5.
1.1 Problem Statement
To address the problem of deteriorating mental health of the Indian virtual community due to imprudent online behavior is crucial in the present scenario. This study develops robust Machine Learning models for accurate detection of mental disorders thereby attempting to preserve the mental health of the virtual community. The problem statement for the proposed study is mentioned as follows:
“Mental health issues are part and parcel of imprudent online behavior and may pose a serious threat to virtual society. The need of the hour is to develop a robust user-friendly inexpensive automated model for detection of mental disorders prevalent in online society”
1.2 Motivation
Overwhelming online community face various mental health problems like depression, anxiety, stress, loneliness etc. but they do not disclose their distress and avoid seeking help due to the social stigma or taboo attached to its incidence. The traditional methods of diagnosis of mental health of online society have inherent problems as discussed in Table 1. There is a need for reliable, efficient, in-expensive and non-intrusively automated system to preserve the well-being of the online society. Above mentioned tribulations motivated us to pursue this empirical study in order to play our part in contribution toward the upkeep of the mental health of online community.
2 Literature review
The affliction of mental health in online community has dominantly been discussed at various platforms by stakeholders and health caretakers. With the continued rise in popularity of online platforms in people’s lives in recent years, the research area involving three sectors—social media, health and big data analytics have come together and begun to evolve.
We divided the literature review in two parts: first part focused on general review of studies with the objective of answering the literature research questions (LRQ) mentioned as follows. The answers for these questions are derived from the review papers extensively focused on: machine learning in mental health (Shatte et al. 2019) (Thieme et al. 2020) (Rahman et al. 2020) (Kim et al. 2021), mental health monitoring using machine learning (Belfin et al. 2020) (Garcia-Ceja et al. 2018), predicting mental health from social media (Chancellor & De Choudhury 2020), application of machine learning methods in mental health detection (Abd Rahman et al. 2018), machine learning and natural language processing in mental health (Glaz et al. 2021), AI in mental health (D’Alfonso 2020).
LRQ1: What are the most common characteristics of the mental health that have been used for prediction?
We found following characteristics of the mental health used in various studies:
-
(i)
Types: suicide, psychosis, stress, depression, anxiety, obsessive compulsive disorder, post-traumatic stress disorder, bipolar disorder, eating disorder, anorexia, bulimia, schizophrenia, borderline personality disorder, internet addiction, cyber-relationships, cyber-bullying, information overload.
-
(ii)
Thematic areas or domain for assembling data for prediction of mental health issues: Traditional (Questionnaires), molecular, genomic genetic data, clinical, medical imaging, physiological signal to facial, body expressive and online Behavioral, Integration of multimodal data etc.
-
(iii)
Social Platform: Twitter, Facebook, reddit, live journals, Weibo, web forums, crowd-sourcing, Amazon Mechanical Turk, micro blogs.
LRQ2: What outcomes have been predicted in contributions related to mental health of SNS users?
The studies contributed toward the following outcomes: Risk levels of mostly depression, users’ behavior, attitude, pattern recognition by classifying users at risk/ no risk, brain and facial signals mapping with mental health etc. The literature lacks outcomes related to causal-effect and associations between factors pertinent in contributing toward the mental health risk.
LRQ3: What are the prediction features that are used to build prediction models in mental health detection?
Broadly we came across five types of data being discussed in the literature: (i) Demographic variables (ii) Biological variables: Related to family history, genetic and genomic profiles (iii) Clinical/Electronic health records (iv) Vocal and visual expression data (v) Social media data- Behavioral and linguistic cues from social media data.
LRQ4: What are the techniques/models used for prediction of mental health of SNS users.
In Literature classical machine learning and artificial neural network algorithms such as SVM, LR, RF, NB, AdaBoost, DT, JRip Rule, Markov logic networks, Multinomial LR & NB, SVM with Radial Basis Function, Transductive SVM, MLP, CNN, LSTM etc. are applied for classification task. Recently researchers are building hybrid models to blend the capabilities of individual algorithms for better outcomes. This study utilizes blend of capabilities of CNN and LSTM and develops an efficient mental disorder detection system.
LRQ5: What metrics have been used to evaluate prediction results in mental health of SNS users?
To establish the usefulness of the studies in real situations researchers have mostly employed following strategies: (i) K-fold cross validation & hold-out method (ii) Machine learning metrics—accuracy, precision and recall, F1, sensitivity, specificity and area under the curve (AUC) (iii) few studies used regression-oriented measures as root mean squared error and R value.
In the second part of literature review we explored the recent works related to our study and found that there is high diversity in the machine learning algorithms chosen by researchers. The most frequently used predictive algorithms were SVM, followed by logistic regression, random forest, decision tree, Naive Bayes, XGboost etc. Like in a paper (Haque et al. 2021) authors explored the performance of ML algorithms in the detection of depression in children. The researchers employed RF, XGBoost, DT and NB on a surveyed data and found that RF outperformed the other ML methods in classifying the depressed children class with 95% accuracy and 99% precision.
Currently, deep learning algorithms like CNN, RNN, and LSTM are trendier since they paved a way of better prediction accuracy, learn and get adapted to past experiences. This shift can be attributed to the characteristic of the deep learning algorithms to automatically grasp valuable features without relying on feature engineering and extraction. Literature also suggests that there has been an upward trend in the natural language processing techniques applied to mental illness detection (Zhang et al. 2022).
CNN based models have a general formation composed of a convolutional layer, pooling layer followed by a fully connected layer and are best known for automatic detection of significant features and efficient computational powers (L. Chen et al. 2020a, b). This characteristic is evident from the following studies related to our approach: Researchers in a study employed CNN on a large dataset from social platform to propose a factor graph combined with CNN using stress related texts, visuals, social attributes and achieved ~ 91% accuracy with 93.40 F1 measure (Lin et al. 2017). Another group of researchers used CNN approach to automatically recognize mental illness posts from Reddit and yielded 91.08% accuracy (Gkotsis et al. 2017). In one more study depression was identified in twitter users by using CNN architecture with optimized embeddings and the study reported accuracy, F1, precision and recall as 87.95%, 86.96%, 87.43% and 87.02% respectively (Husseini Orabi et al. 2018). Researchers in a study collected data from mental health related subreddits applied word embeddings and achieved best accuracy with CNN classification algorithm (Kim et al. 2020).
RNN-based structure is useful for text data as it retains the sequence of words and allows previous data to become inputs but has an inherent restriction of remembering long term dependency. However the extension of RNN such as LSTM and GRU neural network models can deal with it by memorizing the important information thus resolving the long-term dependency and returns better results. Investigators in a study used self- reported reddit posts for detection of depression and reported F score as 0.64 for LSTM model (Cong et al. 2018). The researchers (Ahmad et al. 2021) in a study deployed LSTM for analysis of sentiments (positive/negative) from Bangla text and achieved 94% accuracy. Another LSTM model study showed performance as AUC = 0.94 for prediction of suicide using social media posts (Coppersmith et al. 2018).
For the task of detection of mental health issues, fusion of deep learning algorithms with NLP based feature extraction framework has shown better performances and attracted attention of researchers to explore and develop better ways to safeguard the virtual community from the future episode of mental health issues. General deep learning-based structures mainly enclose two layers: an embedding layer and classification layer. Embedding layer is obtained from the conversion of text to real-valued dense vectors which can keep sequence, connotation and context-based information. There are various embedding techniques such as ELMo, GloVe word embedding, word2vec, bidirectional encoder representations and ALBERT, used for analysis of the textual data by researchers(Ramírez-Cifuentes et al. 2021) (Syaputra & Ali 2022). The second layer i.e., classification layer utilizes various kind of deep learning algorithms like CNN, RNN and hybrid architecture to categorize the data into classes.
Recent craze for hybrid-based methods in literature combines several neural networks for mental illness detection such as CNN, RNN, encoder and LSTM, obtains local features along with long dependency features through NLP techniques and can outperform when they are used individually. In a recent study authors trained deep learning models by converting online posts to word embeddings and demonstrated that CNN + LSTM attained 97.65% accuracy and LSTM achieved 97.45% accuracy (Kanaan et al. 2021). Researchers in a study exploited twitter data for depression using a hybrid model (CNN-biLSTM) with word embeddings as input and obtained 94.28% accuracy (Kour & Gupta 2022). In one more recent study, word2vec and BERT with Bi-LSTM was examined by researchers to efficiently sense depression and anxiety indications from social media posts with an accuracy of 98% using the knowledge distillation technique (Zeberga et al. 2022).
In literature few recent studies also talked about potential of multiple features in identifying the multimodal mental disorders in SNS users. Like, the authors in a recent study demonstrated that the effective multimodal representation of features like audio-visual fused with textual data has capabilities to detect different mental disorders (Zhang et al. 2020). In another recent study (Ghosh et al. 2023) two publicly available MRI datasets (OASIS and ADNI) were utilized with low-cost transfer learning architecture (MobileNet) to detect Alzheimer’s disease and researchers achieved 95.24% accuracy with OASIS dataset, 81.94% accuracy in ADNI dataset and 83.97% accuracy in both datasets(merged). In one new approach, authors (Ahmed et al. 2023) proposed a multimodal Neural network to detect multimodal depression by taking multiple features like video, audio, text and EEG. The incorporation of selective drop-outs, attention mechanism and normalization techniques resulted in greater performance with accuracy as 0.96, F1-score as 0.94 and S1 score as 0.94.
According to the findings from the literature we infer that promising results have been achieved by the studies; however, several challenges exist for the automated task of mental illness detection which needs further research: obtaining annotated data for training purpose of the models is labor-intensive, time consuming and expensive method. Related literature talks mostly about acquiring textual data from social media platforms, very few have examined an amalgamation of numerical and textual data to detect mental illness prevalent in online society. During the process of literature review, we did not come across any relevant study in literature dealing with causal-approach of the mental illness, also literature lacks in the studies which highlights the correlation between the features and mental health issues. Further the datasets used in the studies were mostly tagged to western and European countries. Very few studies have utilized Indian population as samples. Our empirical study is a concrete step toward addressing gaps identified in the related literature and we propose to automate the process of prediction of mental distress to effectively foster the mental health of online society.
3 Methodology
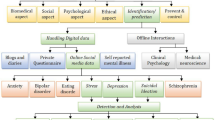
The process of data collection, pre-processing, and construction of mental distress models will be explained in this section followed by model hyper-parameter settings and types of performance metrics utilized to support the model for real world application. Figure 1 present an overview of the phases of the proposed approach in order to investigate the occurrence of mental distress in the virtual community.

The Phases of the proposed Approach
3.1 Data collection and pre-processing
For the purpose of obtaining a robust automated system, we designed a questionnaire that examine the SNS usage behavior (through Bergen social media addiction scale (Andreassen et al. 2012)), three axes of psychological distress ( depression, anxiety, stress) covering physical, social and cognitive experiences ( through DASS (Lovibond & Lovibond 1995)) and draw the emotions through logs/posts. Table 2 describes the items of the questionnaire through which we crowd-sourced the data particularly from the Indian population.
The classification performance of a machine learning model is heavily reliant on the good data encoding schemes. Keeping this in view the first step we employed in pre-processing was to turn the categorical data into numerical using label encoder. In Fig. 2, we illustrate the few tokenized data outcome from the set of encoded features. Next the text data comprising of logs/posts is pre-processed by applying Natural Language Processing (NLP) tools using python libraries. The text data are cleaned using a sequence of NLP steps like stripping, removing null, changing entire text into lower case, removing symbols, tokenization, removing stop words, punctuations and lemmatization. In Fig. 3, we present the outcome of the pre-processing steps applied on the logs/posts of our dataset.

Outcome of few encoded items after label encoding

Outcome of normal and pre-processed logs
3.2 Feature extraction
The efficiency of the text classification lies in the efficient encoding of the unstructured text documents to mathematically computable numerical data while maintaining the semantic and sequence of information in the text. There are different techniques available such as word2vec, word embeddings, glove embeddings etc. to create low dimensional vector space where a large text data is converted to a 2D vector form having an embedding for each word (Kumnunt and Sornil 2020). In order to mine mental distress cues from the logs, we employed word embeddings and Glove embedding methods of feature extraction. A brief overview of the techniques is discussed below:
3.2.1 Word embeddings
This technique aims to digitize the textual data for the purpose of deep learning by characterizing words or sentences as real number vectors. Basically, semantically similar words are mapped close to each other to retain their meanings. Figure 4, describes the steps to accomplish the word embeddings for the proposed method of detecting mental distress cues from the logs shared by the people in the sample. We have textual input data containing 2500 logs, first step toward transforming these into tensors for the learning purpose of the model is to vectorize the logs corpus by turning each log into sequence of integers (integers are the index of a word in the dictionary).The result is a list of integer sequences with varied sizes (as logs do not have same length). Further, “pad sequence” step is initiated to fill the empty values and truncate the larger sequence to make each vector sequence of uniform length Max_log_length. At the end of word embeddings process, the textual data are ready to be joined with the rest of the numerical data in the sample and this word embedding layer become the input to the proposed deep learning model. Further, we also used glove embeddings feature extraction technique to overcome the high dimensionality, sparsity and lack of semantic and syntactic association usually seen in other word embeddings. Glove embeddings is an aggregate global word to word co-occurrence representation showcasing chronological associations to compute relevant features for the classification purpose (Rezaeinia et al. 2019). Figure 5 contains the embedding matrix output obtained from our dataset which will be fed into the models formulated to predict the occurrence of psychological distress in the sample.

Word Embedding process to transform Logs into tensor for the purpose of training models

Embedding Matrix output obtained from our dataset

General algorithm for all 4 models: prediction of mentally distressed / non- distressed users
3.3 Architecture of models for mental distress classification
The classical deep learning models are constructed for prediction of user’s vulnerability toward the mental distress due to their online behavior. Algorithm 1 describes the general operating principle of the models. We chose a combination of CNN and LSTM algorithms with word embeddings and global vector embeddings for evaluating the occurrence of psychological distress due to their individual strengths construed from the literature (LeCun and Bengio 1995) (Hochreiter and Schmidhuber 1997) and pointed out as follows:
-
(i)
CNN is powerful and has ability to extract as many features as possible from the text.
-
(ii)
LSTM has a good hold over memorizing sequence of words in a document and it performs fairly better due to its ability to keep relevant words and discard unnecessary words.
-
(iii)
The goal of word embedding is to reduce dimensionality and use a word to predict the similar words around it thus capturing inter-word semantics. This benefits the computational and generalization power of drawing relevant features.
-
(iv)
Global vector embedding as the word suggests produces global corpus statistics of the text. The representation of text captures word-word statistics or co-occurrence probabilities of words thus enable efficient text classification.
In the following sub-sections, we give details of the basic mathematical background of CNN and LSTM algorithms and describe step by step learning process of deep learning models determined to resolve the design of detecting mental distress risk.
3.3.1 CNN
Convolutional Neural Network is a type of Artificial Neural Networks which simulates the structure of the human brain neurons for the computational purposes. Generally the neural network architecture is composed of input, output and hidden layers. The hidden layers are connected to each other by weighted links. Mathematical activation functions like sigmoid, hyperbolic Tangent Function (Tanh), Rectified Linear Unit function (ReLu), are applied in each layer to determine the output of each layer. In literature, sigmoid is used for binary classification and Tanh provide better outcomes for multi-layer neural networks (Nwankpa et al. 2018). However, activations in sigmoid ranges between [0, 1] easily saturates and falls almost zero blocking the information flow and tanh performs slightly better with output range between [−1, 1] and is zero-centered. In view of this, ReLU is more popular as its activation threshold is 0 when input becomes less than zero resulting in fast convergence and better performance (L. Zhang et al. 2018).
CNN aims to extracts relevant features through the following layers:
-
(i)
Convolution Layer.
The central idea in this layer is the sliding or convolving a pre-determined matrix of weights across the input vector space by one step also called stride capturing the relevant features. The weight matrix also called filters is composed of an activation function which decides whether the input to the next hidden layer is relevant or not in the process of prediction. After each filter a layer of max pooling is applied to reduce the vector dimension and the result of all max pooling layers are joined to build input for next neural network in sequence i.e., LSTM in the proposed approach.
-
(ii)
Activation Layer.
As discussed earlier, activation functions are applied in neural networks to transform it to a non-linear network to make it capable to learn and perform complex tasks. However CNNs applies ReLu activation function reducing non-linearity of the network by replacing each negative output by 0, thus unnecessary features are retained which helps to improve prediction accuracy of the models.
-
(iii)
Regularization.
For the purpose of the better generalization and to improve the accuracy of the models on the unseen data, regularization technique is applied. This technique is managed through functions to systematize complex neural network to avoid over-fitting that affects the performance of the models. We use dropout technique of regularization which penalizes larger weights in order to achieve optimum results.
-
(iv)
Optimization.
During the training phase of deep learning algorithms model parameters like weights, bias and learning rate values are adjusted to reduce the losses and calculated appropriately with optimum values across iterations. There are various optimization approaches like Stochastic Gradient Descent, Adaptive Moment Estimation (Adam), Adagrad etc. We employed Adam optimizer to achieve efficient prediction of mental distress.
Further, we discuss the mathematical concept underlying the CNN feature extraction technique and the description is based on the work presented in (Ghourabi et al. 2020).
Let Zi ∈ Dk represents the k-dimensional input vector corresponding to the ith sample. Let Z ∈ Dnxk denote input vector space, where n is the length of each vector in vector space. For each position j in the vector, let us consider a window vector wj with p consecutive vector, represented as:
A convolution operation involves a filter r ∈ Lpxk, which is applied to the window w to produce a new feature map c ∈ Ln−p+1. Each feature element cj for window vector wj is calculated as follows:
where \(\odot\) is element-wise product, b is a bias term and ƒ is a nonlinear function, in our case, we used Rectified linear unit (ReLU) as nonlinear function which is generally defined as ƒ(y) = max(0,y) i.e., it returns y if the value is positive, elsewhere it returns 0.
The convolutional filter is convoluted on each window of input vector to generate a feature map by applying (3).
A Max pooling layer is added to reduce the high-level dimensionality of vector generated by the convolution operation. This layer reduces the dimension by selecting only important information and removing weak activation information.
The CNN function mentioned in Algorithm 1 works on the above-mentioned principle to extract optimized important features from the dataset and provide input to the LSTM layer of our proposed mental distress model.
3.3.2 LSTM
Although CNN has useful and efficient qualities of mining out relevant features from the data. However, it is unable to link the current information with the past information thus long-term dependencies in the data is ignored. To overcome this we exploit another deep learning method i.e., LSTM which is an extension of Recurrent Neural Network with a memory to hold over certain pattern that is important to keep during the learning process. The mathematical architecture of LSTM can be understood by four components consisting of a memory cell ct and three gates namely input gate it, output gate ot and forget gate ft. During the learning process these units are repeated for each time step (t) and regulates the flow of information inside the model. To update the memory cell (qt and ct) and the hidden state ht, these gates work collectively and the transition functions used in the process is mentioned as (4) (Ghourabi et al. 2020):
where xt is the input vector for LSTM unit, σ is the sigmoid function, tanh denotes hyperbolic tangent function, operator \(\odot\) signify element wise product, W and b denotes weight matrix and bias parameters respectively that are learned during training of model. We used output vector dimensions as 200 and 100 in two LSTM layers with dropout as 0.2 as regularization parameter to avoid the over-fitting of the model. These functions are executed directly after the Max pooling of features as mentioned in Algorithm 1. An illustration of proposed hybrid CNN-LSTM framework is presented in Fig. 6, showing the above explained steps used in the process of prediction of mental distress.

CNN-LSTM hybrid Architecture for prediction of Mental distress
3.4 Hyper-parameter set up
The setting up and tuning of hyper-parameters in a machine learning process is crucial as they directly impact the performance of the models. The prefix ‘hyper’ refers to top-level parameters that governs the learning process of the model and the parameters that result from learning such as weights and biases. Table 3 presents the set of hyper-parameters utilized in the creation of model and subsequently for training purpose of the proposed models to detect mental distress. Table 4 shows the system configuration required for realization of models.
3.5 Performance metrics
Performance review of automated models using metrics helps to quantify progress in order to ascertain their utility in real situations. In order to evaluate models, confusion matrix is plotted in the form of a table (as shown in Fig. 7) which reports the correlation between the predicted values and the actual values. The analysis of the data in confusion matrix is often considered as the source of the performance measurement and provides better insights into the predictive models. The confusion matrix is made up of following four pieces of data:

Confusion matrix
There are many performance measures calculated relative to the components of the confusion matrix. Table 5 shows key classification measures used in this study for the purpose of the assessment of mental distress models.
4 Experimental results
Keeping in mind that there is a relationship between computational models and psychological state (Jo et al. 2017) as well as due to the nature of the problem we first examined and analyzed the numerical and categorical data using the statistical analysis. The relationship between the various features of the dataset is plotted to understand their pattern. In Fig. 8 we show correlation of few variables with mental health issue. It is observed that mental health issue is averagely populated among all age groups, with the people in 21–28 years spending more time on social media. With respect to gender, occurrence of mental health issue is slightly higher in females as compared to males. The analysis of count of frequency in which users use social media shows 20% of users use social media more than 10 + times in a day. Also viewing the analysis of psychological distress axes we observed that 40% of users have experienced the episodes of mental distress (depression, stress, anxiety) but they tend to ignore it and say that ‘they don’t have any mental health issues’. Thus, in order to help such individuals who may go through serious detrimental health issues later on, we can say that our study of automatic detection of mental distress is important and the need of the hour to uphold the wellness of the online community.

Illustration of Correlation of variables with mental health risk of users due to their engagement with social networking sites (a) association of age with mental illness (b) Gender relation with mental illness (c) Frequency of social Media usage (d) Frequency of depression incidence in users with mental illness (e) Frequency of Stress incidence in users with mental illness (f) Frequency of Anxiety incidence in users with mental illness
Further in the next step, we examined the logs/posts of the dataset for the purpose of finding the articulation of the comments i.e., what posts really speak about a person’s wellbeing. The term ‘affect’ in psychology describes the expressions of mood and emotions which plays crucial role in indentifying the well-being of a person (Chen et al. 2020a, b) (Silvera et al. 2008). The affective expressions in virtual community has come into sight for making inferences about person’s mental health status (De Choudhury et al. 2013) (Bazarova et al. 2015). In view of above we formulate the association between frequency of affective words in logs and mental well being by illustrating the word cloud of mental distressed and non-distressed posts in Fig. 9. The size of the words depicts the frequency of the words in the logs and it is visually evident in Fig. 9a, affective words denoting mental illness are frequently present in the logs of distressed group in contrast to the normal words in the logs of the non-distressed group in Fig. 9b. Next we discuss the performance of four deep neural network models constructed using word embeddings and glove embeddings. For the validation purpose we trained our models with 70% training dataset and 30% testing dataset. The first model we realized consisted of three layers–word embedding layer and two LSTM layers. By adding one more dropout layer to this combination we got 98.72% accuracy. Second model consisted of five layers–word embedding layer, a CNN layer, a LSTM layer, Max-pooling and dense layer, achieved 99.20% accuracy. Third model employed pre-trained glove vectors with LSTM capabilities to predict the mental distress in the population with 98.72% accuracy. Finally in the fourth model glove embeddings is employed as the first layer after that Convolutional neural network is added followed by max-pooling to extract only important information and then pass the outcome to the LSTM layer. The testing accuracy we got for this model is around 98.40%. The performance result of all four classification models applied on the dataset along with the hyper parameter setup is presented in Tables 6, 7, 8 and 9 respectively.

Word cloud–(a) Mental distressed logs Vs (b) Non-distressed logs
Furthermore, we present the comparison of all four models with respect to performance metrics like precision, recall and F1 score in Table 10. We accomplished 100% precision for word embeddings combined with CNN-LSTM capabilities. Precision performance metric plays an important role in finding the utility of the models in health sector problems as it denotes the model has produced zero false positives thus evades the trouble and needless intervention which may be caused due to the false alarm. The higher F1 score from the models can be explained by the use of the ReLu activation function having the ability to obstruct negative activation thus returns improved performance as the number of parameters to be learned is reduced.
Finally, in Table 11, we present a comparison of our study with the other related recent studies in literature and found that our hybrid deep neural network model outperformed others in accuracy. We also infer that previous studies are based on analysis of only textual data in contrast to our study where we focused on textual data and causal factors (Social networking site addiction, Depression, Anxiety and Stress state) as well. This explains the novelty of our approach and the empirical outcomes in this study using a novel feature construct is a better step toward the detection and assessment of mental distress risk helping people to cope-up with their problems.
Additionally, first we used crowd-sourced textual data for tuning BERT, a state-of-the-art advanced NLP model. BERT makes contextualized word vectors which makes inference easier based on the context learning (Chandra and Kulkarni 2022). Our dataset result shows an enhanced performance as we achieved 100% accuracy, precision, recall and F1 score. Next, to validate our results, we used 3000 tweets mined from Indian twitter for fine tuning of BERT model and achieved 96% accuracy. The outcome of both these experiments is highlighted in Table 11. The results fortify our objective of exploring the logs for mental-distress cues.
5 Conclusion
Our research contributed toward the identification of mental distress prevalent in online community by experimenting with a hybrid AI model built on novel feature construct consisting of numerical simulation combined with textual analysis which is not present in any related type of study found in literature currently. The advantages of two efficient deep learning algorithms namely convolutional neural network algorithm and Long Short-Term Memory algorithm are hybridized to deliver an efficient automated mental health detection scale. The dataset used to train and test the performance of the models was crowd-sourced and can be considered as benchmark for further research in this area. In order to extract mental cues from text, Glove embeddings layer was pooled with a CNN + LSTM hybrid neural network model and after a fine tuning of hyper-parameters, we achieved a 99.20% accuracy and 100% precision outperforming any models found in literature currently. With zero false positives we reached a greater degree of clarity and efficiency with respect to the disturbance and unnecessary treatment a person may face due to false alarm. Additionally, for validation purpose we exploited a different ground truth dataset from general Indian twitter and employed a modern NLP model called BERT.
We illustrated the association of mental health issues with features like age, gender and frequency of social media usage. Also presented graphically the relationship of depression, stress and anxiety quotient with respect to the mental health state of the people participated in the study. We found that people experience depression, stress and anxiety but prefer not to disclose. It becomes highly important to develop robust automated system which can help such type of people in predicting their mental state thus help them to move on to timely healthy interventions. Our hybrid model is a tangible step toward it and sets up an inexpensive method of collection of experiences of online community to address the challenges of timely detection of mental distress.
The learning from the study brings out a feasible tool wherein apt natural language processing methods are coupled with deep learning capabilities to predict the SNS users’ likeliness of psychological distress risk. However, the study has a limitation in generalizing the outcome attained to the virtual community as a whole, due to the common method bias factor which is unavoidable when data is collected through a self-report questionnaire. Another limitation this study has is the shorter time period of collection of samples. The present cross-sectional study investigated mental health issue by collecting data from a population in a particular time frame, in future we intend to design longitudinal methodology which may be beneficial in establishing a better trait of mental health issues.
As a future scope, we propose to widen the feature construct by capturing the facial experiences and mapping the changes in the brain through an inexpensive method. There are studies in literature related to facial and brain mapping feature analysis but collection of such type of data is expensive and not possible practically in day-to-day life. Finally, we suggest as our future perspective to keep enhancing the automatic detection process of mental distress in order to uphold the online community health.
Data availability
Data will be made available upon reasonable request for further study in this area of research within the limitations of the informed consent by the corresponding author upon acceptance from the co-author.
References
Abd Rahman R, Omar K, Mohd Noah SA, Mohd Danuri MSN (2018) A survey on mental health detection in online social network. Int J Adv Sci Eng Inform Technol 8:1431. https://doi.org/10.18517/ijaseit.8.4-2.6830
Ahmed S, Abu Yousuf M, Monowar MM, Hamid A, Alassafi MO (2023) Taking all the factors we need: a multimodal depression classification with uncertainty approximation. IEEE Access 11:99847–99861
Ahmed A, Yousuf M (2021) Sentiment analysis on bangla text using long short-term memory (LSTM) recurrent neural network. pp 181–192. doi https://doi.org/10.1007/978-981-4673-4_16
Amanat A, Rizwan M, Javed AR, Abdelhaq M, Alsaqour R, Pandya S, Uddin M (2022) Deep learning for depression detection from textual data. Electronics 11(5):676. https://doi.org/10.3390/electronics11050676
Andreassen CS, Torsheim T, Brunborg GS, Pallesen S (2012) Development of a facebook addiction scale. Psychol Rep 110(2):501–517. https://doi.org/10.2466/02.09.18.PR0.110.2.501-517
Bazarova NN, Choi YH, Schwanda Sosik V, Cosley D, Whitlock J (2015) Social sharing of emotions on facebook: channel differences, satisfaction, and replies. In: proceedings of the 18th ACM conference on computer supported cooperative work & social computing, pp 154–164. https://doi.org/10.1145/2675133.2675297
Belfin RV, Kanaga EGM, Kundu S (2020) Application of machine learning in the social network. Recent advances in hybrid metaheuristics for data clustering. Wiley, New Jersey, pp 61–83. https://doi.org/10.1002/9781119551621.ch4
Chancellor S, De Choudhury M (2020) Methods in predictive techniques for mental health status on social media: a critical review. Npj Dig Med 3(1):43. https://doi.org/10.1038/s41746-020-0233-7
Chandra R, Kulkarni V (2022) Semantic and sentiment analysis of selected bhagavad gita translations using BERT-based language framework. IEEE Access 10:21291–21315. https://doi.org/10.1109/ACCESS.2022.3152266
Chen LL, Magdy W, Wolters MK (2020) The effect of user psychology on the content of social media posts: originality and transitions matter. Front Psychol 11:1024. https://doi.org/10.3389/fpsyg.2020.00526
Chen L, Xia C, Sun H (2020b) Recent advances of deep learning in psychiatric disorders. Precis Clin Med 3(3):202–213. https://doi.org/10.1093/pcmedi/pbaa029
Cho G, Yim J, Choi Y, Ko J, Lee S-H (2019) Review of machine learning algorithms for diagnosing mental illness. Psychi Invest 16(4):262–269. https://doi.org/10.30773/pi.2018.12.21.2
Cong Q, Feng Z, Li F, Xiang Y, Rao G, Tao C (2018) X-A-BiLSTM: a deep learning approach for depression detection in imbalanced data. In: 2018 IEEE international conference on bioinformatics and biomedicine (BIBM). https://doi.org/10.1109/BIBM.2018.8621230
Coppersmith G, Leary R, Crutchley P, Fine A (2018) Natural language processing of social media as screening for suicide risk. Biomedical Informatics Insights 10:1178222618792860. https://doi.org/10.1177/1178222618792860
D’Alfonso S (2020) AI in mental health. Curr Opin Psychol 36:112–117. https://doi.org/10.1016/j.copsyc.2020.04.005
De Choudhury M, Counts S, Horvitz E (2013) Social media as a measurement tool of depression in populations. Proc Ann ACM Web Sci Conf WebSci. 13:47–56. https://doi.org/10.1145/2464464.2464480
Garcia-Ceja E, Riegler M, Nordgreen T, Jakobsen P, Oedegaard KJ, Tørresen J (2018) Mental health monitoring with multimodal sensing and machine learning: a survey. Pervasive Mob Comput 51:1–26. https://doi.org/10.1016/j.pmcj.2018.09.003
Ghosh T, Palash MIA, Yousuf MA, Hamid MA, Monowar MM, Alassafi MO (2023) A robust distributed deep learning approach to detect alzheimer’s disease from MRI images. Mathematics 11(12):12. https://doi.org/10.3390/math11122633
Ghourabi A, Mahmood MA, Alzubi QM (2020) A hybrid CNN-LSTM model for SMS spam detection in Arabic and English messages. Future Internet 12(9):156. https://doi.org/10.3390/fi12090156
Gkotsis G, Oellrich A, Velupillai S, Liakata M, Hubbard TJP, Dobson RJB, Dutta R (2017) Characterization of mental health conditions in social media using informed deep learning. Sci Rep 7(1):45141. https://doi.org/10.1038/srep45141
Glaz AL, Haralambous Y, Kim-Dufor D-H, Lenca P, Billot R, Ryan TC, Marsh J, DeVylder J, Walter M, Berrouiguet S, Lemey C (2021) Machine learning and natural language processing in mental health: systematic review. J Med Internet Res 23(5):e15708. https://doi.org/10.2196/15708
Haque UM, Kabir E, Khanam R (2021) Detection of child depression using machine learning methods. PLoS ONE 16(12):e0261131. https://doi.org/10.1371/journal.pone.0261131
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
Husseini Orabi A, Buddhitha P, Husseini Orabi M, Inkpen D (2018) Deep learning for depression detection of twitter users. In: proceedings of the fifth workshop on computational linguistics and clinical psychology: from keyboard to clinic. pp 88–97. doi https://doi.org/10.18653/v1/W18-0609
Iannotti RJ, Janssen I, Haug E, Kololo H, Annaheim B, Borraccino A (2009) Interrelationships of adolescent physical activity, screen-based sedentary behavior, and social and psychological health. Int J Public Health 54(Suppl 2):191–198. https://doi.org/10.1007/s00038-009-5410-z
Jo H, Kim S-M, Ryu J (2017) What we really want to find by Sentiment Analysis: the relationship between computational models and psychological state. ArXiv.
Kanaan R, Haidar B, Kilany R (2021) Detecting mental disorders through social media content. In: 2021 IEEE 3rd international multidisciplinary conference on engineering technology (IMCET), 23–28. https://doi.org/10.1109/IMCET53404.2021.9665555
Karim F, Oyewande AA, Abdalla LF, Ehsanullah RC, Khan S (2020) Social media use and its connection to mental health: a systematic review. Cureus 12(6):15. https://doi.org/10.7759/cureus.8627
Kim J, Lee J, Park E, Han J (2020) A deep learning model for detecting mental illness from user content on social media. Sci Rep 10:11846. https://doi.org/10.1038/s41598-020-68764-y
Kim J, Lee D, Park E (2021) Machine learning for mental health in social media: bibliometric study. J Med Internet Res 23(3):e24870. https://doi.org/10.2196/24870
Kour H, Gupta MK (2022) An hybrid deep learning approach for depression prediction from user tweets using feature-rich CNN and bi-directional LSTM. Multim Tools Appl. https://doi.org/10.1007/s11042-022-12648-y
Kumnunt B, Sornil O (2020) Detection of depression in thai social media messages using deep learning. In: proceedings of the 1st international conference on deep learning theory and applications, pp 111–118. doi https://doi.org/10.5220/0009970501110118
LeCun Y, Bengio Y (1995) Convolutional networks for images, speech, and time series. In: Arbib MA (ed) Handbook of brain theory and neural networks. MIT Press, Cambridge, p 3361
Lin H, Jia J, Qiu J, Zhang Y, Shen G, Xie L, Tang J, Feng L, Chua T-S (2017) Detecting stress based on social interactions in social networks. IEEE Trans Knowl Data Eng 29(9):1820–1833. https://doi.org/10.1109/TKDE.2017.2686382
Lovibond PF, Lovibond SH (1995) The structure of negative emotional states: comparison of the depression anxiety stress scales (dass) with the beck depression and anxiety inventories. Behav Res Ther 33(3):335–343. https://doi.org/10.1016/0005-7967(94)00075-u
Mental health in Asia: The numbers. (n.d.). Retrieved October 27, 2021, from https://www.ourbetterworld.org/series/mental-health/support-toolkit/mental-health-asia-numbers
Nwankpa C, Ijomah W, Gachagan A, Marshall S (2018) Activation functions: comparison of trends in practice and research for deep learning (arXiv:1811.03378). arXiv. http://arxiv.org/abs/1811.03378
Rahman RA, Omar K, Mohd Noah SA, Danuri MSNM, Al-Garadi MA (2020) Application of machine learning methods in mental health detection: a systematic review. IEEE Access 8:183952–183964. https://doi.org/10.1109/ACCESS.2020.3029154
Ramírez-Cifuentes D, Largeron C, Tissier J, Baeza-Yates R, Freire A (2021) Enhanced word embedding variations for the detection of substance abuse and mental health issues on social media writings. IEEE Access 9:130449–130471. https://doi.org/10.1109/ACCESS.2021.3112102
Rezaeinia SM, Rahmani R, Ghodsi A, Veisi H (2019) Sentiment analysis based on improved pre-trained word embeddings. Expert Syst Appl 117:139–147. https://doi.org/10.1016/j.eswa.2018.08.044
Sagar R, Pattanayak RD, Chandrasekaran R, Chaudhury PK, Deswal BS, Lenin Singh RK, Malhotra S, Nizamie SH, Panchal BN, Sudhakar TP, Trivedi JK, Varghese M, Prasad J, Chatterji S (2017) Twelve-month prevalence and treatment gap for common mental disorders: findings from a large-scale epidemiological survey in India. Indian J Psych 59(1):46–55. https://doi.org/10.4103/psychiatry.IndianJPsychiatry_333_16
Saqib K, Khan AF, Butt ZA (2021) Machine learning methods for predicting postpartum depression: scoping review. JMIR Mental Health 8(11):e29838. https://doi.org/10.2196/29838
Shatte ABR, Hutchinson DM, Teague SJ (2019) Machine learning in mental health: a scoping review of methods and applications. Psychol Med 49(9):1426–1448. https://doi.org/10.1017/S0033291719000151
Silvera DH, Lavack AM, Kropp F (2008) Impulse buying: the role of affect, social influence, and subjective wellbeing. J Consum Mark 25(1):23–33. https://doi.org/10.1108/07363760810845381
Su C (2020) Deep learning in mental health outcome research: a scoping review. Transl Psych 26(1):116
Syaputra RA, Ali R (2022) Chapter Ten—Improving mental health surveillance over Twitter text classification using word embedding techniques. In: Jain S, Pandey K, Jain P, Seng KP (eds) Artificial intelligence, machine learning, and mental health in pandemics. Academic Press, NJ, pp 235–258. https://doi.org/10.1016/B978-0-323-91196-2.00014-4
Thieme A, Belgrave D, Doherty G (2020) Machine learning in mental health: a systematic review of the HCI literature to support effective ML system design. ACM Trans Comput Human Int (TOCHI), 27. https://www.microsoft.com/en-us/research/publication/machine-learning-in-mental-health-a-systematic-review-of-the-hci-literature-to-support-effective-ml-system-design/
Zeberga K, Attique M, Shah B, Ali F, Jembre YZ, Chung T-S (2022) A novel text mining approach for mental health prediction using Bi-LSTM and BERT model. Comput Intell Neurosci 2022:1–18. https://doi.org/10.1155/2022/7893775
Zhang L, Wang S, Liu B (2018) Deep learning for sentiment analysis: A survey. WIREs Data Min Knowl Discov 8(4):e1253. https://doi.org/10.1002/widm.1253
Zhang T, Schoene AM, Ji S, Ananiadou S (2022) Natural language processing applied to mental illness detection: a narrative review. Npj Dig Med 5(1):46. https://doi.org/10.1038/s41746-022-00589-7
Zhang Z, Lin W, Liu M, Mahmoud Rady M (2020) Multimodal deep learning framework for mental disorder recognition. pp 344–350. Doi https://doi.org/10.1109/FG47880.2020.00033
Funding
No funds, grants, or other support were received for conducting this study and preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
The manuscript was designed and written together by all the three authors Dr. MKA, Dr. JS and AS. The experiment in the study was performed by the author Anju Singh, analysis and results were reviewed by the authors Dr. MKA and Dr. JS. All the authors contributed equally in this study and vouch for the results reported and protocol adherence during the study. All the three authors edited and approved the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
There is no competing interest’s disclosure relevant to this study and related to any of the authors of this manuscript.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Arora, M.K., Singh, J. & Singh, A. Development of intelligent system based on synthesis of affective signals and deep neural networks to foster mental health of the Indian virtual community. Soc. Netw. Anal. Min. 14, 20 (2024). https://doi.org/10.1007/s13278-023-01179-5
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13278-023-01179-5