
Abstract
Vibrios have shown their potential as polyhydroxyalkanoates (PHAs) producers, but until recently little information was available about their PHA-related genes. The present study attempts to characterize the phaC genes from a potent PHA-accumulating bacterium, Vibrio azureus strain BTKB33, isolated from marine sediments. The molecular detection of class I PHA synthase gene in the V. azureus strain BTKB33 gave the required amplicon and was confirmed by subsequent seminested PCR; however, a class II PHA synthase gene was not detected. The in silico characterization of the PCR product helped to deduce the presence of class I PHA synthase, particularly a polyhydroxybutyrate polymerase. Sequence alignment of the nucleotide sequence of class I PHA synthase of strain BTKB33 and other related Vibrio sp. showed intra-generic variation within genus Vibrio and this is revealed in the dendrogram. The multiple sequence alignment of the in silico-translated phaC gene of BTKB33 with the protein sequence of PHA synthase of related organisms showed the conserved regions of protein sequences within the genus Vibrio and the dendrogram constructed showed the relatedness based on the deduced amino acid sequences.
Similar content being viewed by others
Introduction
Bacteria accumulate polyhydroxyalkanoates (PHAs) under unbalanced growth conditions of a carbon substrate in excess of other nutrients like nitrogen, sulfur, phosphorus or oxygen (Madison and Huisman 1999; Kim and Lenz 2001). PHAs are strong candidates for biodegradable plastics due to their properties either as thermoplastics or as elastomers, and therefore find applications in domestic (Glazer and Nikaido 1994), agriculture (Holmes 1985; Hocking and Marchessault 1994; Dobbelaere et al. 2001), marine (Asrar and Gruys 2002), medicine (Williams and Martin 2002) and industrial (Chen et al. 2000; Bucci and Tavares 2005) fields. Approximately 140 different hydroxyalkanoic acids are known to be incorporated into PHAs (Steinbuchel 2005), with microbial species from over 90 genera being reported to accumulate these polyesters (Zinn et al. 2001). The variation in PHA composition in bacteria influence its physical and chemical properties and can be modified by several factors, including the type of microorganism in which PHA synthase, a crucial enzyme in PHA synthesis, plays a key role, medium composition and production conditions (Keshavarz and Roy 2010; Singh et al. 2014).
PHAs are mainly of two types, short-chain-length PHAs (scl-PHAs) with 3–5 carbon atoms and medium-chain-length PHAs (mcl-PHAs) with 6–14 carbon atoms. The number of carbon atoms in their side chains modifies their mechanical properties. The scl-PHAs are generally thermoplastics, whereas mcl-PHAs are elastomers. The composition of the monomeric units depends on the substrate used and a class of highly versatile enzymes, the PHA synthase, which are not specific to any one type of hydroxyalkanoic acid (Steinbuchel et al. 1992), but nevertheless crucial in all PHA synthesis (Anderson and Dawes 1990; Madison and Huisman 1999; Rehm and Steinbuchel 1999).
PHA synthases can be categorized into three types based on their primary amino acid sequences and in vivo substrate specificities (Rehm and Steinbuchel 1999). Class I PHA synthases are preferentially active towards coenzyme A thioesters of various scl 3-hydroxyalkanoates comprising three to five carbon atoms, exemplified by polyhydroxybutyrates (PHB), the smallest known PHA having myriad applications in medicine and industry. Class II PHA synthases are active towards coenzyme A thioesters of various mcl-3 hydroxyalkanoates comprising at least five carbon atoms; both types being encoded by the same phaC gene (Trotsenko and Belova 2000). Class III PHA synthases detected in Chromatium vinosum comprise two different subunits, the phaC and the phaE (Trotsenko and Belova 2000), and they prefer coenzyme A thioesters of scl 3-HA. There are reports that bacteria like Rhodococcus ruber (Haywood et al. 1991) and Aeromonas caviae (Fukui et al. 1998) have PHA synthases that exhibit specificity for both scl and mcl-PHAs. McCool and Cannon (2001) reported a fourth class of PHA synthases in Bacillus megaterium, consisting of two subunits, phaC (Bm) and phaR (Bm).
Based on the organization of the gene locus and the structure–function properties of PHA synthase enzymes, the PHA biosynthesis genetic system (pha gene locus) is divided into four (Solaiman and Ashby 2005). The class I locus consists of phaC (coding for PHA synthase), phaA (β-ketothiolase), and phaB (acetoacetyl-CoA reductase) genes, as observed in Wautersia eutropha. The class II locus consists of an operon with two PHA synthase genes (phaC1 and phaC2) flanking a PHA depolymerase gene (phaZ), as seen in Pseudomonas sp. (Solaiman and Ashby 2005). The class III pha operon with class III PHA synthases and the phaA and phaB genes, transcribed in the opposite direction, are found adjacent to these two synthase genes. The class IV pha loci comprising phaR and phaC coding for the two hetero-subunits of the active PHA synthase and a phaB between the two has been reported in Bacillus megaterium (McCool and Cannon 2001).
Phenotypic detection methods such as Sudan black B (Schlegel et al. 1970), Nile blue A (Ostle and Holt 1982) and Nile red (Spiekermann et al. 1999) staining methods have been widely used for screening PHAs accumulation in microbes. These methods are laborious and do not involve differentiation of PHA types. Hence, alternative methods like Fourier transform infrared spectroscopy (Hong et al. 1999) and the polymerase chain reaction (PCR)-based technique (Sheu et al. 2000; Solaiman et al. 2000; Romo et al. 2007) can be used. Vibrios from marine sediments were among the first bacteria to be reported as PHA producers (Baumann et al. 1971; Oliver and Colwell 1973). PHA production in vibrios isolated from marine environments have been reported by several workers (Sun et al. 1994; Rawte and Mavinkurve 2004; Chien et al. 2007; Arun et al. 2009; Wei et al. 2011; Sasidharan et al. 2014). These ubiquitous microbes from the aquatic environment have been implicated as significant PHA producers. The search for novel microbial PHA producers has yielded a potential PHA producing marine Vibrio azureus strain BTKB33 from marine sediments. A PHB content of 426.88 mg/g of cell dry weight was obtained and major bioprocess variables influencing its PHB production were optimized (Sasidharan et al. 2014). Information about the presence of PHA synthase genes in vibrios has been reported only by complete genome sequence analysis of vibrios and is available in NCBI (Heidelberg et al. 2000; Makino et al. 2003; Goudenège et al. 2013). Until recently, little information was available about the phaC genes in vibrios. This study discusses the detection and differentiation of the PHA synthase gene by PCR-based analysis and the in silico analysis of phaC genes in a potent PHB accumulating marine bacterium, V. azureus strain BTKB33.
Materials and methods
Bacterial strains and growth conditions
PHA-producing bacterial strain V. azureus strain BTKB33 (Accession No. HM346671), deposited in Microbial Culture Collection, Microbial Genetic Lab, Dept. of Biotechnology, Cochin University of Science and Technology, Cochin, India, was used. Nutrient agar medium (HiMedia, Mumbai, India) was used for maintenance of the culture. The strain BTKB33 was grown in nutrient medium with 1 % NaCl at 35 °C on a rotary shaker at 120 rpm for 12 h.
Molecular characterization of PHA synthase gene
Genomic DNA extraction was according to Sambrook et al. (2000). The purity of extracted DNA was checked by reading the absorbance ratio A260/A280 using a UV–VIS spectrophotometer (Shimadzu, Japan), followed by the agarose gel electrophoresis (GeNei, Bengaluru, India) and the visualization with G: BOX Fluorescence Gel Documentation system (Syngene, USA).
PCR and semi-nested PCR detection for class I PHA synthase gene
The class I PHA synthase gene represents the gene for scl-PHAs. The PCR reaction for the class I PHA synthase gene (phaC) was performed according to Sheu et al. (2000) and the primer details are as in Table 1. The PCR-based detection involved two steps. In the first PCR reaction, the forward primer phaCF1 and the reverse primer phaCR4 were used. The PCR mixture consisted of 0.5 μL of 100 ng/mL template DNA (100 ng/mL), 2 μL of 2.5 mM of dNTP, 1U units of Taq DNA polymerase (Sigma-Aldrich, India), 2 μL of 10× Taq buffer, 1 M of betain, 0.03 % of DMSO, 1 μL of acetylated BSA, 5 μL of each primers and added sterile distilled water to make a final volume of 20 μL. PCR mixture was pre-incubated at 94 °C for 5 min, 51 °C for 2 min, and 72 °C for 2 min. The PCR cycle consisted of 20 s of denaturation at 94 °C, 45 s of annealing at 61 °C (decreased by 1 s/cycle), and 1 min of extension at 72 °C. This cycle was repeated 35 times and then incubated at 72 °C for 10 min for the final extension. PCR was performed in a thermal cycler (Bio Rad, USA) and the predicted PCR product was ~496 bp in length.
A semi-nested PCR was performed using the above PCR product for the confirmation of the scl-PHA synthase gene in strain BTKB33 using primers phaCF2 and phaCR4. For positive products, 1 μL of 100-fold diluted colony PCR products was used for semi-nested PCR. For negative products, 1 μL of undiluted colony PCR products was directly supplied as DNA templates for semi-nested PCR. PCR reactions were done as detailed above and a predicted product of ~406 bp indicates the presence of positive amplification, visualized after agarose gel electrophoresis (GeNei) with G: BOX Fluorescence Gel Documentation system (Syngene).
PCR for class II PHA synthase gene
The class II PHA synthase gene codes for mcl-PHAs. PCR for class II PHA synthase genes was performed in a thermal cycler (Bio Rad) with the primers I-179 L and I-179R (Table 1) according to Solaiman et al. (2000).
The PCR reaction mixture consisted of 0.5 μL of template DNA (100 ng/mL), 2 μL of 2.5 mM of dNTP, 1 U of Taq DNA polymerase (Sigma-Aldrich, India), 2 μL of 10× Taq buffer, 5 μL of each primers and added sterile distilled water to a final volume of 20 μL. The PCR mixture was pre-incubated at 94 °C for 5 min, 51 °C for 2 min, and 72 °C for 2 min. The PCR cycle was repeated 35 times and consisted of 20 s of denaturation at 94 °C, 45 s of annealing at 57 °C and 1 min of extension at 72 °C, followed by incubation at 72 °C for 5 min and a final incubation at 4 °C (Sujatha et al. 2005). The expected positive PCR product was ~540 bp.
In silico analysis of the sequence
Products after PCR amplification were purified by a gene cleaning kit (GeNei) and were sequenced by Sanger’s Dideoxy method using an ABI 3730 DNA Analyzer (Applied Biosystems, USA). The sequenced PCR products were compared with those available from GenBank using online BLAST tools: nucleotide blast (http://www.ncbi.nlm.nih.gov/blast). Nucleic acid sequences of other PHA synthase genes were obtained from NCBI database. Multiple sequence alignment for the selected nucleotide sequences was done by using the Clustal X program (Thompson et al. 1997) in BIOEDIT software (Hall 1999). The phylogenetic tree was constructed using the Neighbor-Joining method (Saitou and Nei 1987) using the nucleotide-based TN84 evolutionary model in MEGA5: Molecular Evolutionary Genetics Analysis (MEGA) software ve.5.0 (Tamura et al. 2011). The evolutionary distances were computed using the Tajima-Nei method (Tajima and Nei 1984) and are in the units of the number of base substitutions per site. Statistical support for branching was estimated using 1000 bootstrap steps.
The nucleic acid sequence of the PHA synthase from BTKB33 was translated in silico into its corresponding protein sequence by Expasy (http://web.expasy.org/translate) and the deduced amino acid sequence were compared with other protein sequences using Conserved Domain Database services available in NCBI (Marchler-Bauer et al. 2011) using online BLAST tool, blastx (http://www.ncbi.nlm.nih.gov/blast). Multiple sequence alignment for the assembled amino acid sequences was carried out by using the Clustal W program in BIOEDIT software (Hall 1999). The phylogenetic tree was constructed as detailed above with 1000 bootstrap steps. The evolutionary distances were computed using the method outlined by Nei and Kumar (2000) and are in the units of the number of amino acid differences per sequence.
Results and discussion
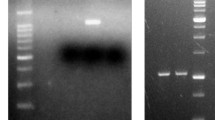
In this study, two separate PCR-based protocols were adopted for the detection and differentiation of the PHA synthase gene in strain BTKB33. The method outlined by Sheu et al. (2000) for the detection of the class I PHA synthase gene (scl-PHA synthase gene) gave the desired amplicon of ~496 bp for the strain BTKB33 and a ~406-bp amplicon for the seminested PCR of the previously obtained PCR products and is represented in Fig. 1. Preliminary PCR analysis showed that strain BTKB33 harbored the class I PHA synthase gene type representing single-chain-length (scl) PHAs. The class II PHA synthase gene (mcl-PHA synthase gene) was not detected by this method (result not shown). Class I PHA synthases among others are important as they are preferentially active towards coenzyme A thioesters of scl 3-HA comprising three to five carbon atoms, including polyhydroxybutyrate (PHB), polyhydroxyvalerate (PHV), polyhydroxybutyrate-valerate (PHBV), etc. There are previous reports on the presence of PHB in vibrios (Chien et al. 2007; Arun et al. 2009; Wei et al. 2011). PHB is the smallest molecule among scl-PHAs coded by class I PHA synthase gene (Anderson and Dawes 1990; Madison and Huisman 1999); the results of the present study concur with the previous one. Chien et al. (2007) studied PHA accumulation in marine vibrios from sediments and identified it as only PHB. It was reported that vibrios produce only PHB despite alteration in carbon sources and these findings conclude that the variety of PHAs produced in marine environments may not be as diverse as in other environments. PHB production in Vibrio sp. was evidenced by the structural characterization by FTIR and NMR analysis (Chien et al. 2007; Arun et al. 2009; Sasidharan et al. 2014).

Semi-nested colony PCR for the identification of single-chain-length (scl) PHA producers; Estimated PCR product length ~406 bp. Lane 1 100-bp ladder; lane 2 PCR product of Vibrio azureus BTKB33
In silico analysis of the partial sequence of phaC gene
The semi-nested PCR product of the class I phaC gene from BTKB33 was sequenced and showed 98 % similarity with the PHA synthase gene of V. parahaemolyticus RIMD 2210633 (Accession no. BA000032) following BLAST analysis. This outcome indicated that the partial gene sequence obtained was indeed that encoding class I PHA synthase and was submitted to GenBank with accession number JQ781052. The class I phaC gene has been observed in the complete genome analysis of vibrios such as V. cholerae, V. parahaemolyticus, V. alginolyticus, V. splendidus, V. harveyi, V. rotiferianus, V. nigripulchritudo, V. owensii, V. campbellii and V. vulnificus and is available in the NCBI database (http://www.ncbi.nlm.nih.gov/). This preliminary study helped to conclude that a PHA synthase class I, specifically a PHB polymerase is present in V. azureus BTKB33. To date, no other information has been reported as to the presence of class II PHA synthase in vibrios. The result of this study is highly relevant considering that this sequence (JQ781052) of the phaC gene is the first deposit in GenBank from the V. azureus species of genus Vibrio, as the review of the description of the V. azureus (Yoshizawa et al. 2009) has not included PHA production by V. azureus. This report adds to the description of this organism and hence can be used as a variable in taxonomic evaluation of the species.
Multiple sequence alignment of the nucleotide sequences of class I PHA synthase from V. azureus strain BTKB33 with other related Vibrio sp. is represented in Fig. 2. Nucleotide sequence from V. azureus strain BTKB33 in comparison showed maximum similarity with that of PHA synthase from V. parahaemolyticus strain RIMD 2210633 (Accession no. BA000032) and V. parahaemolyticus strain BB22OP (Accession no. CP003973), forming a clade. The alignment showed intra-generic variation within genus Vibrio. A dendrogram was constructed with the nucleotide sequence of the class I phaC gene of V. azureus strain BTKB33 with other related Vibrio sp. (Fig. 3). From the tree, it was observed that all the Vibrio strains claded together to form a single clade and separated from the out group Paracoccus denitrificans (Accession no. CP000489). The partial nucleic acid sequence of the phaC gene obtained was translated into its amino acid sequence and aligned using PSI-BLAST. An ORF encoding 74 amino acid residues was obtained, with maximum E value of 6e-43 and 93 % identity with the amino acid sequence of the phaC gene of V. alginolyticus strain 40B (Accession no. NZ ACZB01000148). The deduced amino acid sequence was deposited in GenBank under accession number AFK87747. The multiple sequence alignment of this deduced 74 aminoacid sequence from strain BTKB33 (Accession no. AFK87747), with related bacteria from NCBI (Fig. 4), showed maximum similarity with PHA synthase of other Vibrio sp. like V. alginolyticus 40B (Accession no. ZP 06182878), V. harveyi 1DA3 (Accession no. ZP 06174179), V. parahaemolyticus AQ4037 (Accession no. ZP 05908852) and Vibrio sp. Ex25 (Accession no. ZP04921203) included in this study. In addition, the alignment showed some intra-generic variation within genus Vibrio; the divergence of amino acid sequences is indicated in Fig. 4. On the analysis of the multiple sequence alignment, it was noted that the translated phaC gene sequence of BTKB33 had serine instead of alanine in the 6th position. Likewise, there was cysteine instead of tyrosine in the 22nd and leucine instead of alanine in the 34th positions. Apart from these differences, the multiple sequence alignment clearly revealed the conserved regions of the protein sequences of PHA synthase within the genus Vibrio, if only in this short stretch.

Multiple sequence alignment of the nucleotide sequences of class I PHA synthase from V. azureus strain BTKB33 and other related Vibrio sp. The nucleotide sequences were aligned using Clustal W programme using BIOEDIT software. The identical sequences are marked inside the outline. V.Azureus, V. azureus strain BTKB33 (JQ781052); V.Para1, V. parahaemolyticus strain RIMD 2210633 (BA000032); V.Para2, V. parahaemolyticus strain BB22OP (CP003973); V.Ex025, Vibrio sp. Ex25 (CP001806); V.Furni, V. furnissii (CP002378); V.Vulni, V. vulnificus (AE016796); P.Denitri, Paracoccus denitrificans (CP000489). GenBank accession numbers are presented in brackets

Phylogenetic relationship based on nucleotide sequences of class I PHA synthase gene from V. azureus strain BTKB33 with related taxa. The evolutionary history was inferred using the Neighbor-Joining method (Saitou and Nei 1987). The numbers at the nodes indicate the levels of bootstrap support based on 1000 replicates. The evolutionary distances were computed using the Tajima–Nei method (Tajima and Nei 1984) and are in the units of the number of base substitutions per site. Evolutionary analyses were conducted in MEGA 5.0 (Tamura et al. 2011). Paracoccus denitrificans (Accession no. CP000489) was used as outgroup

Multiple sequence alignment of the amino acid sequence of class I PHA synthase from V. azureus strain BTKB33 and other related bacteria. The protein sequences were aligned using Clustal W programme using BIOEDIT software. The identical sequences are marked inside the outline. V.Azureus, V. azureus strain BTKB33 (AFK87747); V.Algino, V. alginolyticus 40B (ZP 06182878); V.Harveyi, V. harveyi DA3 (ZP 06174179); V.Para, V. parahaemolyticus AQ4037 (ZP 05908852); Ex25, Vibrio sp. Ex25 (ZP04921203); A.Hydro, Aeromonas hydrophila (AAL77053); Acinetobacter, Acinetobacter sp. (AAA52191); Oceanospirillum, Oceanospirillum sp. MED 92 (ZP 01166141); Marinobacter, Marinobacter manganoxydans (ZP 09161036); Halomonas, Halomonas sp. TD01 (ZP 08636397); Methylobacterium, Methylobacterium nodulans ORS 2060 (YP 002501157); Rhodobacter, Rhodopseudomonas palustris HaA2 (YP 486582); Alcaligenes, Alcaligenes eutrophus H16 (AAB24910); Agrobacterium, Agrobacterium tumefacians str. C98 (NP 354598). GenBank accession numbers are presented in brackets
A dendrogram was constructed with deduced amino acid sequence of class I phaC gene of V. azureus strain BTKB33 with other related bacteria and is presented in Fig. 5, which showed that all the Vibrio strains claded separately from the rest of the bacteria included in the study. Within the clade, V. azureus strain BTKB33 showed some divergence from other Vibrio sp. due to the amino acid variations of the class I PHA synthase among them, as already revealed in the sequence alignment analysis.

Phylogenetic tree of deduced amino acid sequence of class I PHA synthase from V. azureus strain BTKB33, related Vibrio sp. and other bacteria. The evolutionary history was inferred using the Neighbor-Joining method (Saitou and Nei 1987). The percentage of replicate trees in which the associated taxa clustered together in the bootstrap test (1000 replicates) are shown next to the branches. The evolutionary distances were computed using the method (Nei and Kumar 2000) and are in the units of the number of amino acid differences per sequence. The analysis involved 15 amino acid sequences. Evolutionary analyses were conducted in MEGA 5.0 (Tamura et al. 2011)
A comparison using the putative conserved domains search service (RPS-BLAST) revealed that the translated protein sequence of phaC of V. azureus strain BTKB33 showed maximum resemblance to the conserved domain model TIGR01838, with an E value of 2.18e-37, which represented the class I subfamily of poly(R)-hydroxyalkanoate synthases, which polymerizes hydroxyacyl-CoAs with three to five carbons in the hydroxyacyl backbone into aliphatic esters, termed poly(R)-hydroxyalkanoic acids.
Conclusion
The outcome of this study allowed us to conclude that the partial phaC gene sequence of Vibrio azureus strain BTKB33 is of class I PHA synthase, especially a poly-β-hydroxybutyrate polymerase. The PHAs extracted from vibrios were characterized as PHB and the molecular characterization of the PHA synthase gene in this study supports these previous findings. PHB are of considerable interest to the polymer industries due to the similarity of their physical and chemical characteristics to synthetic plastics. Their biodegradable nature makes them most interesting potential natural product. This study shows the relatedness of the PHA synthase in strain BTKB33 to that in other vibrio species and their differences from distant organisms based on in silico characterization of the PHA synthase gene. To conclude, marine vibrios which are fast growing and easy to manipulate organisms can serve as an important source for PHB production.
References
Anderson AJ, Dawes EA (1990) Occurrence, metabolism, metabolic role, and industrial uses of bacterial polyhydroxyalkanoates. Microbiol Rev 3:450–472
Arun A, Arthi R, Shanmugabalaji V, Eyini M (2009) Microbial production of poly-beta-hydroxybutyrate by marine microbes isolated from various marine environments. Bioresour Technol 100:2320–2323
Asrar J, Gruys KJ (2002) Biodegradable Polymer (Biopol). In: Doi Y, Steinbuchel A (eds) Biopolymers, vol 4. Wiley-VCH, Weinheim, pp 53–90
Baumann P, Baumann L, Mandel M (1971) Taxonomy of marine bacteria: genus Benekea. J Bacteriol 107:268–294
Bucci DZ, Tavares LBB (2005) PHB packaging for the storage of food products. Polym Test 24:564–571
Chen G, Wu Q, Zhao K, Yu P (2000) Functional polyhydroxyalkanoates synthesized by microorganisms. Chin J Polym Sci 18:389–396
Chien CC, Chen CC, Choi MH, Kung SS, Wei YH (2007) Production of poly betahydroxybutyrate (PHB) by Vibrio spp. isolated from marine environment. J Biotechnol 132:259–263
Dobbelaere S, Croonenborghs A, Thys A, Ptacek D, Vanderleyden J, Dutto JP (2001) Responses of agronomically important crops to inoculation with Azospirillum. Aust J Plant Physiol 28:871–879
Fukui T, Shiomi N, Doi Y (1998) Expression and characterization of (R)-specific enoyl coenzyme A hydratase involved in polyhydroxyalkanoate biosynthesis by Aeromonas caviae. J Bacteriol 180:667–673
Glazer AN, Nikaido H (1994) Microbial Biotechnology - Fundamentals of Applied Microbiology. Cambridge University Press, Cambridge, pp 281–297
Goudenège D, Labreuche Y, Krin E et al (2013) Comparative genomics of pathogenic lineages of Vibrio nigripulchritudo identifies virulence-associated traits. ISME J 7(10):1985–1996. doi:10.1038/ismej.2013.90
Hall TA (1999) Bioedit: a user-friendly biological sequence alignment editor and analysis program for Windows 95/98/NT. Nucleic Acids Symp Ser 41:95–98
Haywood GW, Anderson AJ, Williams GA, Dawes EA, Ewing DF (1991) Accumulation of a poly (hydroxyalkanoate) copolymer containing primarily 3-hydroxyvalerate from simple carbohydrate substrates by simple carbohydrate substrates by Rhodococcus spp. NCIMB 40126. Int J Biol Macromol 13:83–88
Heidelberg JF, Eisen JA, Nelson WC, Clayton RA, Gwinn ML et al (2000) DNA sequence of both chromosomes of the cholera pathogen Vibrio cholerae. Nature 3–406(6795):477–483
Hocking PJ, Marchessault RH (1994) Biopolyesters. In: Griffin GJL (ed) Chemistry and Technology of Biodegradable Polymers. Blackie, London
Holmes PA (1985) Application of PHB: a microbially produced biodegradable thermoplastic. Phys Technol 16:32–36
Hong K, Sun S, Tian W, Chen GQ, Huang W (1999) A rapid method for detecting bacterial polyhydroxyalkanoates in intact cells by fourier transform infrared spectroscopy. Appl Microbiol Biotechnol 51:523–526
Keshavarz T, Roy I (2010) Polyhydroxyalkanoates: bioplastics with a green agenda. Curr Opin Microbiol 13(3):321–326
Kim YB, Lenz RW (2001) Polyesters from microorganisms. Adv Biochem Eng Biotechnol 71:51–79
Madison LL, Huisman GW (1999) Metabolic engineering of poly (3-hydroxyalkanoates): from DNA to plastic. Microbiol Mol Biol Rev 63:21–53
Makino K, Oshima K, Kurokawa K, Yokoyama K et al (2003) Genome sequence of Vibrio parahaemolyticus: a pathogenic mechanism distinct from that of V. cholerae. Lancet 361(9359):743–749
Marchler-Bauer A, Lu S, Anderson JB et al (2011) CDD: a Conserved Domain Database for the functional annotation of proteins. Nucleic Acids Res 39:225–229
McCool GJ, Cannon MC (2001) PhaC and PhaR are required for polyhydroxyalkanoic acid synthase activity in Bacillus megaterium. J Bacteriol 183(14):4235–4243
Nei M, Kumar S (2000) Molecular Evolution and Phylogenetics. Oxford University Press, New York
Oliver JD, Colwell R (1973) Extractable lipids of gram-negative marine bacteria: phospholipid composition. J Bacteriol 114:897–908
Ostle AG, Holt JG (1982) Nile Blue A as a fluorescent stain for poly-b-hydroxy butyrate. Appl Environ Microbiol 44:238–241
Rawte T, Mavinkurve S (2004) Factors influencing polyhydroxyalkanoate accumulation in marine bacteria. Ind J Mar Sci 33:181–186
Rehm BHA, Steinbuchel A (1999) Biochemical and genetic analysis of PHA synthases and other proteins required for PHA synthesis. Int J Biol Macromol 25:3–19
Romo DMR, Grosso MV, Solano NCM, Castano DM (2007) A most effective method for selecting a broad range of short and medium chain length polyhydroxyalkanoate producing microorganisms. Electron J Biotechnol 10:349–357
Saitou N, Nei M (1987) The neighbor-joining method: a new method for reconstructing phylogenetic trees. Mol Biol Evol 4:406–425
Sambrook J, Fritsch EF, Maniatis T (2000) Molecular cloning: a laboratory manual. Cold Spring Harbor Laboratory Press, New York
Sasidharan RS, Bhat SG, Chandrasekaran M (2014) Biocompatible polyhydroxybutyrate (PHB) production by marine Vibrio azureus BTKB33 under submerged fermentation. Ann Microbiol. doi:10.1007/s13213-014-0878-z
Schlegel HG, Lafferty R, Krauss I (1970) The isolation of mutants not accumulating poly-β-hydroxybutyric acid. Arch Mikrobiol 71:283–294
Sheu DS, Wang YT, Lee CY (2000) Rapid detection of polyhydroxyalkanoatea ccumulating bacteria isolated from the environment by colony PCR. Microbiology 146:2019–2025
Singh SB, Grewal A, Kumar P (2014) Biotechnological production of polyhydroxyalkanoates: a review on trends and latest developments. Chin J Biol. doi:10.1155/2014/802984
Solaiman DK, Ashby RD (2005) Rapid genetic characterization of poly (hydroxyalkanoate) synthase and its applications. Biomacromolecules 6(2):532–537
Solaiman DKY, Ashby RD, Foglia TA (2000) Rapid and specific identification of medium-chain-length polyhydroxyalkanoate synthase gene by polymerase chain reaction. Appl Microbiol Biotechnol 53(6):690–694
Spiekermann P, Rehm BHA, Kalscheuer R, Baumeister D, Steinbüchel A (1999) A sensitive, viable-colony staining method using nile red for direct screening of bacteria that accumulate polyhydroxyalkanoic acids and other lipid storage compounds. Arch Microbiol 171:73–80
Steinbuchel A (2005) Non-biodegradable biopolymers from renewable resources: perspectives and impacts. Curr Opin Biotechnol 16:607–613
Steinbuchel A, Hustede E, Liebergesell M, Pieper U, Tim A, Valentin H (1992) Molecular basis for biosynthesis and accumulation of polyhydroxyalkanoic acids in bacteria. FEMS Microbiol 35:274–279
Sujatha KA, Mahalakshmi, Shenbagarthai R (2005) A study on accumulation of PHB in native Pseudomonas isolates LDC-5 and LDC-25. Ind J Biotechnol 4:216–221
Sun W, Cao JG, Teng K, Meighen EA (1994) Biosynthesis of poly-3-hydroxybutyrate in the luminescent bacterium, Vibrio harveyi and regulation by the lux autoinducer N-(3-hydroxybutanoyl) homoserine lactone. J Biol Chem 269:20785–20790
Tajima F, Nei M (1984) Estimation of evolutionary distance between nucleotide sequences. Mol Biol Evol 1:269–285
Tamura K, Peterson D, Peterson N, Stecher G, Nei M, Kumar S (2011) MEGA5: Molecular evolutionary genetics analysis using maximum likelihood, evolutionary distance, and maximum parsimony methods. Mol Biol Evol 28:2731–2739
Thompson JD, Gibson TJ, Plewniak F, Jeanmougin F, Higgins DG (1997) The CLUSTAL X windows interface: flexible strategies for multiple sequence alignment aided by quality analysis tools. Nucleic Acids Res 25:4876–4882
Trotsenko IA, Belova LL (2000) Organization and regulation of polyhydroxybutyrate/valerate biosynthesis in bacteria. Mikrobiologica 69:753–763
Wei YH, Chen WC, Wu HS, Janarthanan OM (2011) Biodegradable and biocompatible biomaterial, polyhydroxybutyrate, produced by an indigenous Vibrio spp. BM-1 isolated from marine environment. Mar Drugs 9:615–624
Williams SF, Martin DP (2002) Applications of PHAs in medicine and pharmacy. In: Doi Y, Steinbuchel A (eds) Biopolymers, vol 4, Wiley-VCH. Weinheim, pp 91–103
Yoshizawa S, Wada M, Kita-Tsukamoto K, Ikemoto E, Yokota A, Kogure K (2009) Vibrio azureus sp. nov., a luminous marine bacterium isolated from seawater. Int J Syst Evol Microbiol 59:1645–1649
Zinn M, Witholt B, Egli T (2001) Occurrence, synthesis and medical application of bacterial polyhydroxyalkanoate. Adv Drug Deliv Rev 53:5–21
Acknowledgments
This study was supported by project grants from the Department of Ocean Development, Government of India (No. DOD /11 – MRDF/1/29/06) and Centre for Marine Living Resources & Ecology- Ministry of Earth Sciences, Government of India (No. MOES/10-MLR/2/2007) given to Dr. Sarita G. Bhat, Dept. of Biotechnology, Cochin University of Science and Technology, Kochi, India.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Sasidharan, R.S., Bhat, S.G. & Chandrasekaran, M. Amplification and sequence analysis of phaC gene of polyhydroxybutyrate producing Vibrio azureus BTKB33 isolated from marine sediments. Ann Microbiol 66, 299–306 (2016). https://doi.org/10.1007/s13213-015-1109-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13213-015-1109-y