
Abstract
The optimization calculation process of big data chaos model cannot be optimized in the global scope and has uncertain factors. A new optimization calculation method of big data chaos model is proposed in this work based on the improved genetic algorithm. The proposed work is an attempt to analyzes and extracts the correlation dimension, the maximum Lyapunov exponent, and the time series using mathematical modeling. It is analyzed from the observed outcomes that the original parameters are genetically operated by real number coding, and the absolute value of the error time integral performance index is regarded as the minimum objective function for parameter selection. This work introduces a square term and penalty function of the input control to find the optimal index and fitness function. The next generation population is produced until the parameters converge or meet the requirements. The method proposed in this article achieves average running time of 0.85 for correlation dimension, 0.74 for Lyapuno index and 0.76 for time series entropy, thereby outperforming the traditional method. The simulation experiment results show that the proposed method has a high optimization ability.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
For big data, efficient search and optimization calculation process is very important. The optimization process cannot be characterized by any mathematical conditions. Therefore, whether it is analyzed from the perspective of mathematics or calculation, the optimization calculation problem is a huge challenge (Go et al. 2019). It has the disadvantages of not being able to achieve the best in the global scope and having many uncertain factors. The proposed work presents an optimization method based on an improved genetic algorithm, which analyzes and extracts the correlation dimension, the largest Lyapunov exponent, and the time series (Song and Ma 2018; Li et al. 2020).
The mathematical modelling through computer simulation, which is performed on a computer, and intended to estimate the behavior of or the result of a real world or actual framework. Figure 1 presents the mathematical modelling process, which represents the running of a system. It can be utilized to investigate and acquire new bits of knowledge into innovation and to estimate system’s performance for its complexity for logical solutions (Safaei et al. 2016).

Process of mathematical modelling
In the examinations on nonlinear dynamical frameworks the authors sorted out that, since no logical answer for the majority of nonlinear frameworks can be acquired, the entire set of solutions can be researched in the supposed phase space spanned by the arrangement of variables needed for a total description of conditions of the framework (Quarteroni 2009). A couple of years after the fact, while exploring the three-body issue, it is observed that little perturbations can profoundly influence the solution (Jong 2002). To explore nonlinear dynamimcs, the authors have presented the ideas of phase portrait, segment, orbit, return map, bifurcation, fixed point, etc. A large portion of these ideas were utilized by Andronov's school during the 20 s (Yuan et al. 2014) still the first representation in the phase space of a now called “chaotic arrangement” was because of the arrangement Edward Norton Lorenz (Ay and Arnosti 2011). The alleged Lorenz attractor accordingly represents the primary chaotic attractor ever drawn. From the Lorenz's paper publication during mid of 70 s very few papers were published. Among the individuals who added to the development of “chaos hypothesis,” turbulence from one study can be considered (Zeigler et al. 2018), also about bifurcation (Oliva et al. 2017), the new clamorous attractors (Santos et al. 2003), 12. Xiang hypothesis for presence of chaos in guide (Xiang et al. 2010). These commitments, published before 1980, and highlights the word “chaos” just as related procedures to research these new sorts of solutions.
The present work introduces a square term and penalty function of the input control to find the optimal index and fitness function. The selection operation completed through the fitness ratio method and the optimal retention strategy. The population processed through selection, crossover, and mutation operators. The contribution of the proposed method is a big data chaotic model optimization calculation using an improved genetic algorithm for the analysis and extraction of correlation dimension, largest Lyapunov exponent, and time series. The real number coding is implemented to perform genetic operations on the original parameters. The absolute value of the error time integral performance index is regarded as the minimum objective function for parameter selection, and the square term and penalty function of the input control are introduced in the objective function. Then the optimal index and fitness function are obtained, and the fitness ratio method and optimal retention strategy completes the selection operation. The population is processed through selection, crossover and mutation operators. The processes involve the population selection, crossover and mutation to produce the next generation population and this process continues until the converge requirements met. This proposed chaotic model based on genetic algorithm, analyzes and extracts the correlation dimension, largest Lyapunov exponent, and the time series. The simulation experiment results show that the proposed method has a high optimization ability.
The remaining part of this manuscript is arranged as: Sect. 2 presents the recent work carried out in the field of optimization calculation. Section 3 comprises of the Lyapunov Exponent extraction followed by the optimization calculation process of big data chaos model based on improved genetic algorithm in Sect. 4. Simulation results as analyzed in Sect. 5, which is further followed by the conclusion of work in Sect. 6.
2 Literature review
In order to understand the effect of learning and cognitive procedure of distance beginners. Wen et al. designed a chaotic recognition cognitive learning framework based on chaos optimization along with analysis of big data. The model considers learners' knowledge inspiration, learning mission necessities and the rate of modification of cognitive directions, and transforms the learning procedure of reserve learning into multi-objective optimization. Experimental outcomes indicates that the model can efficiently increase the teaching superiority of distance teaching progressions in colleges and universities, and has the expansibility and compatibility (Wen et al. 2019). Chen et al. proposed a framework of arc model on the basis of experimental evaluation to measure the ability of the model to predict molten pool changes and thermodynamics involved in the welding procedure. The computational methodology adopted considered on the basis of dynamics of computational fluid approach and applied using a finite volume approach on D3 field of computation. Line electrodes along with arc plasma and work pieces are regarded as auto consistent approaches. The significant welding constraints, containing arc current, rate of wire feeding, thickness of work piece, geometry and speed of welding, kinds of metal alloy for work piece and wire, are set to modifiable constraints. By adjusting these constraints, the concert of arc welding can be projected, and various situations can be matched to enhance the performance of welding (Chen et al. 2020). He et al. proposed a new semi-implicit solution strategy for Sm-link equations to resolve nonlinear numerical equations after the discretization of mathematical models. The outcomes show that the average complete deviation among experimental information and calculated values is 8.8% and 8.2%, respectively. By analyzing the dynamic development of ventilation drying, it is establish that the drying process is carried out from both ends of the pipe to the center. In addition, the results show that the uneven distribution of liquid retention may decrease the effectiveness of dehydrated air in the later stage of drying process. Therefore, we recommend that when the water vapor at the channel spreads the minimum set value, the drying process will be transferred to the immersion test stage. Finally, many factors affecting the drying process studied (He et al. 2020).
Yin et al. discussed the connection among revise likelihood and process efficiency. The progression purpose of process efficiency is proposed to drive the overlapping iterative procedure of multi-coupled actions. The development procedure with input data apprise is studied, and an imitation ideal is projected to acquire precise develop iteration process. It is very valuable to examine the risks in the expansion process, and has moral flexibility and adaptability. The scheming technique of procedure value of overlapping iterative procedure is specified, and the optimization ideal of invention growth process is delivered (Yin et al. 2019).
Structures, frameworks and individuals together creates a dynamic system, and like the climate, are made out of cooperating elements which are embedded into feedback hoops and are sensitive to little changes. Disposing of undesirable model may cause a magnification of mistakes in model predictions. These predictions are of no use after a specific measure of time. These frameworks are nonlinear dynamic frameworks which are delicate and unpredictable in detail because they are open either to outside influences or to their own delicate internal fluctuations. One work suggest a comprehensive quality wherein everything influences all the other things. This idea additionally underlies Gaia Theory about the development of firmly coupled frameworks. Building environmental frameworks are unpredictable unique frameworks since they include the building and its frameworks; the processes which occur in planning, designing, developing and building operating; the information and communication frameworks; and the individuals who are utilizing the building (Sharma and Kumar 2019; Sharma et al. 2019a). New models are expected to comprehend in a more profound manner how changes in these ecological, financial and social factors affect building execution and this requires an integrated approach (Li et al. 2012; Bhalaik et al. 2020). This is relevant to the development industry which has tended to not receive the assembling mechanical designing mindset (Rafiei et al. 2013; Rathee et al. 2020). Intelligent buildings are another conspicuous model indicating a hierarchical structure of complex control systems (Jiang et al. 2012; Dhiman et al. 2021a). The original definition of intelligent structures was carried out when buildings were outfitted with IT (Pathak et al. 2018; Dhiman et al. 2021b) but has enlarged in importance during recent years. Presently it is usually recognized that an intelligent building should have the capability to learn and change its presentation for its occupants to meet variations in the environment (Qureshi and Yusuf 2019; Poongodi et al. 2020). Intelligent structures introduce the idea of the human being as an essential piece of the system, instead of the individual outside of the framework, which can be better understood with regards to complex adaptive socio-ecological systems (Sharma et al. 2019b). A particular challenge of considering intelligent structures is to create models that join the real factors of complex hierarchical systems with myriad of intelligent segments and human natures, rather than to exclude them away (Sharma and Kumar 2017).
3 Extraction of Lyapunov exponent
The chaotic characteristic parameter of big data is the Lyapunov exponent, so the calculation of this parameter is an important step to extract the chaotic characteristic.
Lyapunov exponent can describe the chaotic intensity of big data, and it has many description forms. This paper uses the largest Lyapunov exponent, which is described as follows:
Hypothesis \(\beta_{{n_{1} }}\), \(\beta_{{n_{2} }}\) are two points that are infinitely close in space, and the distance between them can be described as \(\beta_{{n_{1} }} - \beta_{{n_{2} }} = \delta_{0} < < 1\) use \(\delta_{\Delta n}\). Describe over a period of time \(\Delta n\). After, starting at 2 points \(\beta_{{n_{1} }}\), \(\beta_{{n_{2} }}\). The distance between the 2 trajectories, which is \(\delta_{\Delta n} = \beta_{{n_{1} + \Delta n}} - \beta_{{n_{2} + \Delta n}}\). Then the largest Lyapunov exponent can be described as:
Assuming that λ is a positive number, the exponentials of adjacent orbits are separated, which is chaos. Because the distance between the two orbits is usually relatively close, the formula (1) is only in \(\delta_{\Delta n}\). It is valid when the value is relatively small. Otherwise, the separation efficiency of adjacent tracks will be greatly reduced, and formula (1) does not hold.
4 The optimization calculation process of big data chaos model based on improved genetic algorithm
Based on the above analysis of the chaotic feature extraction results of big data, an enhanced genetic algorithm with adaptive boundary and mutation is used to optimize the chaotic model. The precise development is as follows:
4.1 Chromosome coding method
This text chooses the real number encoding form. Assuming that the parameters to be optimized are described by M, using them as components to form a row vector with M dimensions, the individual code can be obtained: \(P = \left[ {p_{1} ,p_{2} , \ldots ,p_{M} } \right]\); where P represents an individual, \(p_{i}\) as a component randomly formed in the parameter space of the i-th parameter, M is used to describe the total amount of all parameters that need to be optimized. Each individual in this article has three components in different directions \(k_{p}\), \(k_{i}\), \(k_{{\text{d}}}\), the value range is 0.001–50.
4.2 Calculate fitness function
The absolute value of the error time essential enactment index is taken as the minimum objective function of the optimization process, to obtain the dynamic process that meets the requirements. Introduce and regulate the input square term, thereby reducing the possibility of excessive control. In order to prevent overshoot, this article also introduces a penalty function. If overshoot, the overshoot is regarded as one of the optimal indicators. If e(t) ≥ 0, the optimal indicator can be described as:
If e(t) > 0, the optimal index can be described as:
Among them, e(t) is used to describe the system error, u(t) is used to describe the data output, \(t_{u}\) used to describe the rise time. \(w_{1}\), \(w_{{2}}\), \(w_{{3}}\), \(w_{{4}}\) used to describe the weight.
The fitness function can be described as:
4.3 The optimal preservation plan and the optimization of the selection operator
The probability of each individual being selected is proportional to its fitness. Use \(f_{i}\) describe the fitness value of an individual, the probability of the individual being selected \(P_{s}\). It can be described as:
In order to avoid deleting individuals with high fitness values, this article stipulates that individuals with high fitness values in each generation do not need to be genetically manipulated and can directly enter the next generation, thereby improving the overall operating efficiency.
4.4 Adaptive crossover and mutation algorithm
Crossover rate \(p_{e}\) and mutation rate \(p_{m}\) perform adaptive adjustment calculations
In summary, using the improved genetic algorithm to optimize the correlation dimension, Lyapunov exponent, and time series h, the detailed process is depicted in Fig. 2.

Flowchart of the optimization calculation process
First obtain the basic range of all parameters to implement the encoding operation; then randomly generate n individuals to form the initial population; and then find the fitness function value \(f_{i}\). Finally, the operation of the population is completed through selection, crossover, and mutation operators to form the next generation population; the second and third steps are repeated until the requirements are met or the parameters are converged (Wu et al. 2019; Rodriguez and Diaz 2018).
5 Experimental results analysis and discussion
In order to verify the effectiveness of this method, relevant experimental analysis is needed. The experiment uses Intel Core 2 Due T7600@2.33 GHz, 4 GB memory, HITACHI PATA 7200 rpm 500 GB hard disk PC, Windows7 SP1 operating system, and simulates in MATLAB 7.0 environment.
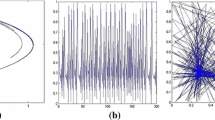
Figure 3 illustrates sensitivity at initial conditions from time series. From the experimentation, it is observed that with little change in system parameters can lead to the substantial change in a system. As any point in a framework's history can be considered as another beginning stage or starting point, the term of butterfly impact, which refers to the framework’s sensitivity to the early conditions. Bifurcations are firmly connected with attractors as they signifies to any subjective change starting with one sort of attractor to other, which presents a hop in phase space. Such unpredictable dynamics can be clarified by the panarchy structure as depicted in Fig. 3 indicating how a framework, made of numerous progressive systems and versatile subsystems, works at discrete scales, depending upon how much the adaptive pattern of each sub-framework is synchronized. It portrays the key attributes of every complex framework: change and stability. Conversely, inside the chaotic regions, more modest zones of stable periodicity are detectable and these areas show up at a lot more limited size. Such redundancy of similar example at various scales is distinguished as fractal. These perceptions give a clarification with respect to why the chaotic framework is dynamic and nonlinear: it is difficult to predict the result for a given initial state. The connection between the elements, states in the framework can’t be predicted and these connections change nonlinearly and erratically over the time span (Bhalaik et al. 2020). Figure 3 presents the shows illustration of sensitivity to initial conditions from the Lorenz tumultuous time arrangement.

Sensitivity illustration at initial conditions
Table 1 describes the comparison results of the average value and standard deviation of the method in this paper and the traditional simulated fishing method.
Analysis of Table 1 displays that the process in this paper can accurately obtain the global optimal value of all chaotic parameters, and the optimization performance is particularly special stable. However, the traditional simulation fishing method can only find the optimal value of Lyapunov exponent, which leads to poor optimization performance (Hamdi and Abie 2014; Li et al. 2018).
Table 2 describes the comparison outcomes of the iteration number and running time of the technique in this paper and the traditional simulated fishing method. More elaborative comparison of these values is done in Fig. 4 for clear understanding. The mathematical modelling through computer simulation, which is performed on a computer, and intended to estimate the behavior of or the result of a real world or actual framework. The experimental analysis shows that the proposed method has a high optimization capability. The simulation experiment results show that the proposed method has high optimization ability. The selection operation is completed through the fitness ratio method and the optimal retention strategy. The population is processed through selection, crossover, and mutation operators. This proposed chaotic model based on genetic algorithm, analyzes and extracts the correlation dimension, the largest Lyapunov exponent, and the time series.

Comparative analysis of different parameters of the proposed method and the traditional method
Analysis of Fig. 4 displays that the technique in this paper can quickly converge to the global extreme every time, while the traditional simulated fishing method is both as there are precocious or local optimal situations. The running period of the technique in this paper is only about half of the traditional simulated fishing method, which verifies the efficiency of the method presented in this paper.
6 Conclusion
This paper proposes a big data chaotic model optimization calculation method based on an improved genetic algorithm, which overcomes the shortcomings that the big data chaos model optimization calculation process cannot achieve the global optimization and has uncertain factors. The selection operation is completed through the fitness ratio method and the optimal retention strategy. The population is processed through selection, crossover, and mutation operators. The square term and penalty function of the input control are introduced in the function to find the optimal index and fitness function. By implementing the improved genetic algorithm to optimize the correlation dimension, Lyapunov exponent, and time series, the system presents higher improvement. The experimental analysis displays that the method projected can quickly cover the global extreme every time, while the traditional simulated fishing method is both as there are precocious or local optimal situations. The method proposed in this article achieves average running time of 0.85 for correlation dimension, 0.74 for Lyapuno index and 0.76 for time series entropy, thereby outperforming the traditional method. Thus, the running time of the method in this paper is about half of the traditional simulated fishing method, which verifies the efficiency of the proposed method.
References
Ay A, Arnosti DN (2011) Mathematical modeling of gene expression: a guide for the perplexed biologist. Crit Rev Biochem Mol Biol 46(2):137–151
Bhalaik S, Sharma A, Kumar R, Sharma N (2020) Performance modeling and analysis of WDM optical networks under wavelength continuity constraint using MILP. Recent Adv Electr Electron Eng Former Recent Pat Electr Electron Eng 13(2):203–211
Chen FF, Xiang J, Thomas DG, Murphy AB (2020) Model-based parameter optimization for arc welding process simulation. Appl Math Model 81:386–400
De Jong H (2002) Modeling and simulation of genetic regulatory systems: a literature review. J Comput Biol 9(1):67–103
Dhiman G, Oliva D, Kaur A, Singh KK, Vimal S, Sharma A, Cengiz K (2021a) BEPO: a novel binary emperor penguin optimizer for automatic feature selection. Knowl Based Syst 211:106560
Dhiman G, Singh KK, Soni M, Nagar A, Dehghani M, Slowik A, Cengiz K (2021b) MOSOA: a new multi-objective seagull optimization algorithm. Expert Syst Appl 167:114150
Go YT, Yoon YS, Lee IB, Lee SY (2019) Mathematical modeling and simulation of carbon monoxide absorption column for blast furnace gas and Linz–Donawitz gas separation by COSORB process. J Chem Eng Jpn 52(5):439–446
Hamdi M, Abie H (2014) Game-based adaptive security in the Internet of Things for eHealth. In: 2014 IEEE international conference on communications (ICC), pp 920–925. IEEE
He Q, Li C, Xue J, Chen J (2020) Modeling and simulation of isothermal process of natural gas pipeline drying with dehydrated air. Drying Technol 38(11):1400–1410
Jiang H, Kwong CK, Chen Z, Ysim YC (2012) Chaos particle swarm optimization and T-S fuzzy modeling approaches to constrained predictive control. Expert Syst Appl 39(1):194–201
Li C, Zhou J, Kou P, Xiao J (2012) A novel chaotic particle swarm optimization based fuzzy clustering algorithm. Neurocomputing 83:98–109
Li X, Zhao H, Murphy AB (2018) SF6-alternative gases for application in gas-insulated switchgear. J Phys D Appl Phys 51(15):153001
Li X, Dong M, Li S, Feng Z, Zhang Z, Li W, Lu J (2020) A numerical study of the ammonia desulfurization in the spray scattering tower. Chem Eng Process Process Intensif 155:108069
Oliva D, Abd El Aziz M, Hassanien AE (2017) Parameter estimation of photovoltaic cells using an improved chaotic whale optimization algorithm. Appl Energy 200:141–154
Pathak J, Wikner A, Fussell R, Chandra S, Hunt BR, Girvan M, Ott E (2018) Hybrid forecasting of chaotic processes: using machine learning in conjunction with a knowledge-based model. Chaos Interdiscip J Nonlinear Sci 28(4):041101
Poongodi M, Sharma A, Vijayakumar V, Bhardwaj V, Sharma AP, Iqbal R, Kumar R (2020) Prediction of the price of Ethereum blockchain cryptocurrency in an industrial finance system. Comput Electr Eng 81:106527
Quarteroni A (2009) Mathematical models in science and engineering. Notices AMS 56(1):10–19
Qureshi S, Yusuf A (2019) Mathematical modeling for the impacts of deforestation on wildlife species using Caputo differential operator. Chaos Solitons Fractals 126:32–40
Rafiei S, Maghsoodloo S, Noroozi B, Mottaghitalab V, Haghi AK (2013) Mathematical modeling in electrospinning process of nanofibers: a detailed review. Cell Chem Technol 47:323–338
Rathee G, Sharma A, Saini H, Kumar R, Iqbal R (2020) A hybrid framework for multimedia data processing in IoT-healthcare using blockchain technology. Multimed Tools Appl 79(15):9711–9733
Rodriguez M, Diaz I (2018) Model transformations and integration for process plant simulation, optimization and visualization. In: Computer aided chemical engineering, vol 43, pp 285–286. Elsevier
Safaei MR, Jahanbin A, Kianifar A, Gharehkhani S, Kherbeet AS, Goodarzi M, Dahari M (2016) Mathematical modeling for nanofluids simulation: a review of the latest works. Model Simul Eng Sci
Santos CA, Spim JA, Garcia A (2003) Mathematical modeling and optimization strategies (genetic algorithm and knowledge base) applied to the continuous casting of steel. Eng Appl Artif Intell 16(5–6):511–527
Sharma A, Kumar R (2017) A framework for pre-computated multi-constrained quickest QoS path algorithm. J Telecommun Electron Comput Eng JTEC 9(3–6):73–77
Sharma A, Kumar R (2019) Computation of the reliable and quickest data path for healthcare services by using service-level agreements and energy constraints. Arab J Sci Eng 44(11):9087–9104
Sharma A, Rathee G, Kumar R, Saini H, Varadarajan V, Nam Y, Chilamkurti N (2019a) A secure, energy-and sla-efficient (sese) e-healthcare framework for quickest data transmission using cyber-physical system. Sensors 19(9):2119
Sharma A, Singh PK, Sharma A, Kumar R (2019b) An efficient architecture for the accurate detection and monitoring of an event through the sky. Comput Commun 148:115–128
Song J, Ma X (2018) Simulation and optimization research of distribution process based on flexsim for L clothing company
Wen J, Zhang W, Shu W (2019) A cognitive learning model in distance education of higher education institutions based on chaos optimization in big data environment. J Supercomput 75(2):719–731
Wu P, Wang Y, Wan P (2019) Study on simulation of stamping process and optimization of process parameters of fender. Adv Mater Sci Eng 2019
Xiang Y, Arora JS, Abdel-Malek K (2010) Physics-based modeling and simulation of human walking: a review of optimization-based and other approaches. Struct Multidiscip Optim 42(1):1–23
Yin F, Gao Q, Ji X (2019) Simulation and optimization of overlapped iteration process with multi-coupled activities based on value analysis. Concurr Eng 27(1):57–67
Yuan X, Xiang Y, He Y (2014) Parameter extraction of solar cell models using mutative-scale parallel chaos optimization algorithm. Sol Energy 108:238–251
Zeigler BP, Muzy A, Kofman E (2018) Theory of modeling and simulation: discrete event & iterative system computational foundations. Academic Press
Funding
No funding.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Research involving human participants and/or animals
This article does not contain any studies with animals performed by any of the authors.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Yang, J., Sharma, P. & Ikbal, M.A. Mathematical modeling and simulation of data chaos model optimization calculation process. Int J Syst Assur Eng Manag (2021). https://doi.org/10.1007/s13198-021-01426-y
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13198-021-01426-y