
Abstract
In supply chain management, the vendor managed inventory plays a vital role in production systems to decrease the total costs by reducing the bullwhip effect. The vendor managed inventory (VMI) policy reduces the decision-making levels by which prediction error of demand is reduced. This policy significantly reduces demand variations in inventory management. This paper develops an inventory model based on the vendor-managed policy in which there are single-vendor and multiple retailers. In addition to inventory decisions, the proposed model optimizes an upper limit for inventory levels based on a penalty. To close real-world conditions, we consider integer values for order quantities per cycle for retailers. Moreover, the number of vendor’s orders has an upper limit. The purpose of the developed mathematical model is to find an optimal value for replenishment frequencies of retailers, order quantities, and upper limits on the inventory level of retailers. Since the proposed model is an integer non-linear programming problem (INLP), we employ a metaheuristic optimization approach called the imperialist competitive algorithm. To verify the proposed methodology and algorithm, we compare the obtained solutions with an exact method. In different scenarios, the mathematical model is solved, and the results showed that vendors follow the normal situation in which there is no overstock penalty in such a way that vendors experience backorder inventory problems. The main contribution of this paper was to include the upper limits on the inventory levels in VMI mathematical models along with a verified meta-heuristic algorithm.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In supply chain management, the vendor managed inventory (VMI), sometimes called vendor-managed replenishment, is one of the popular policies to minimize the total costs in warehouse management. Successful suppliers such as JC Penney and Walmart show that this policy significantly mitigates the bullwhip effect (Simchi-Levi et al. 2007). Supply chains are trying to find effective solutions, which are the responsiveness of facilities and distribution networks to best serve a market. The VMI helps supply chains to make better decisions than the past in such a way that it shares inventory levels and sale information of retailers with vendors to control retailer inventory and minimize associated costs (Hudnurkar and Rathod 2012). The significant reduction in the total inventory costs by using VMI policy shows the importance of information sharing in operational levels of supply chains.
The last decade shows significant attention to the integrating supply chains using VMI policy. Darwish and Odah (2010) developed a VMI model for a two-echelon supply chain including retailers and vendors. They used a heuristic to solve the proposed mathematical model. The prior studies have a large focus on the VMI mathematical models such multiple vendors (Sadeghi et al. 2013), a hybrid with redundancy allocation (Sadeghi, Sadeghi, et al. 2014a, b), a three-echelon supply chain (Sadeghi, Mousavi et al., 2014a, b), and fixed shipping cost allocation (Son and Ghosh 2019), and stochastic demand (Pramudyo and Luong 2019). There is scant research on the effect of upper limits of inventory levels on the total inventory cost. Thus, the research questions are How does the tradeoff between ordering and holding look like? How does a vendor behave when there is an upper limit on the inventory?
High inventory costs motivate to focus on supplier–buyer relationships to optimize the total cost from both perspectives. Due to possible limitations on the warehouse capacity, vendors are limited to keep a large quantity of inventory. Moreover, just in time approach encourages vendors to reduce the inventory. Thus, it is important to have a focus on the vendors’ behavior when the inventory is limited.
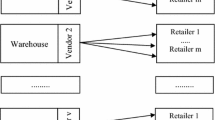
To answer the aforementioned research questions, this research develops the work presented by Darwish and Odah (2010) to consider upper inventory limits as decision variables. The goal of this research is to present a mathematical model for a single-vendor multi-retailer supply chain based on VMI policy in which a vendor has to determine an upper limit for the inventories while there is a constraint on the orders. The objective of the proposed mathematical model is to determine order size, upper limits on the inventory level of retailers, and replenishment frequencies of retailers by a vendor. To solve the proposed mathematical model, we use the imperialist competitive algorithm (ICA) (Sadeghi, Mousavi, et al., 2016a, b) in meta-heuristic optimization.
We organize the paper as follows. Next section presents a short background of VMI. Section 3 presents the proposed mathematical model. The solution algorithm, imperialist competitive algorithm, and results are given in Sects. 4 and 5, respectively. Finally, Sect. 6 shows the conclusion and future research.
2 Prior research
Prior studies conducted a review of VMI from different aspects such as process perspective (Marque`s et al., 2010), based on dimensions (Govindan, 2013), and theoretical developments (Zhao, 2019). To name a few, Bazan et al. (2015) proposed a VMI with consignment stock (VMI-CS) agreement policy in which transportation and production followed a multi-level emission-taxing scheme. Using a neighborhood search algorithm, Hemmati et al. (2015) modeled a VMI policy for a tramp shipping. Following risk preference, Huynh and Pan (2015) formulated a VMI in a two-echelon supply chain. In a case including perishable products, Shaabani and Kamalabadi (2016) developed a multi-period inventory model and then employed a simulated annealing algorithm to obtain the near-optimal solutions. In a case in which the vendor uses the retailer's warehouse to store products, Khan et al. (2016) presented a VMI in which a known fraction of lots is defective. Cai et al. (2017) developed a VMI problem for a two-echelon supply chain with uncertain demand in which there are two substitutable brands in different scenarios. In a single-supplier multi-retailer supply chain, Verma and Chatterjee (2017) presented a nonlinear mixed-integer programming model based on VMI policy to minimize the total costs by finding the optimal values for replenishment frequency and order quantity. Lee et al. (2017) showed that the amount of stock displayed has an effect on demand in VMI systems, and then developed a mathematical model based on consignment stock agreement in which the vendor's stocking policy is assumed to be either forward or backward. Although VMI policy in most cases assumes products are stored in retailers’ warehouse, sometimes it is impossible to follow it. Following this assumption violation, Akbari Kaasgari et al. (2017) presented a mathematical model based on VMI policy in which there were perishable products. They used the particle swarm optimization algorithm to obtain the near-optimal solutions.
Stellingwerf et al. (2019) considered the effect of VMI decision on the environment. Their results show that demand and location are two main factors impacting environment in such a way that these two factor significantly increases the carbon emission and total costs. Sainathan and Groenevelt (2019) considered contracts in vendor managed inventory policy in which a few types of contracts do not follow under vendor-managed inventory.
Inflation plays an important role in inventory models. Esmaeili and Nasrabadi (2021) proposed an inventory model to include effects of inflation on the outcomes in which results indicated that both vendor and retailer can take advantage of proposed decision tool in terms of the total profits. With the advent of technologies, big data is a growing topic in supply chain and operations management. Maheshwari et al. (2021) provided a systematic review of the role of big data in supply chain management. Along with their findings, Talwar et al. (2021) proposed a theoretical framework to use big data in supply chain management. When it comes to disruptions, the ripple effect is inevitable in the supplier–buyer relationships (Hosseini et al. 2020; Li et al. 2021). Hosseini et al. (2020) developed a stochastic model to address the uncertainty in the suppliers’ performance regarding the ripple effect. Their findings showed that high-risk paths can be addressed using the proposed methodology when it comes to disruptions. Maintenance techniques are a vital part of manufacturing processes. Khanna et al. (2016) addressed imperfect production in vendor’s activities which can be resulted in a shortage. Their results showed that the proposed decision tool enables managers to have an optimized decision in buyer-vendor relationships. Moreover, Khanna et al. (2020) developed a vendor managed inventory in which production activities are controlled based on warranty and maintenance policy. Their results showed that inventory managers can handle the uncertainty in VMI models when it comes to maintenance activities. Sustainability development is becoming one of the parts of inventory decisions (Gautam et al. 2019). Kamna et al. (2021) developed a sustainable production inventory model in which agility was addressed in the manufacturing process. Their findings showed that the model has a better outcome when volume agility is included than is not.
3 A mathematical model based on Vendor Managed Inventory
We used the following notations to develop the mathematical model.
Parameters
\(r\) Number of retailers.
\({A}_{V}\) The vendor's ordering cost.
\({A}_{j}\) Ordering cost for retailer \(j\)
\(D\) The vendor's annual demand that is \(D={\sum }_{j=1}^{r}{D}_{j}\)
\({D}_{j}\) Annual demand for \({j}^{th}\) retailer.
\({h}_{V}\) The vendor's holding cost per year.
\({h}_{j}\) Holding cost for retailer \(j\) per year.
\({\pi }_{j}\) Overstock penalty cost for retailer \(j\) per year.
\(S\) Set of all retailers whose upper limits of inventory are exceeded.
\(X\) Maximum number of orders for vendor per year.
Variables
\({q}_{j}\) Order quantity for retailer \(j\) per cycle (decision variable).
\({Q}_{V}\) Total vendor's order quantity per cycle that is \({Q}_{V}=nq\)
\(q\) Order quantity for all retailers per cycle that is \(q = \sum\nolimits_{j = 1}^{r} {q_{j} }\).
\({q}_{1}\) Order quantity for 1th retailer per cycle (decision variable).
\({U}_{j}\) Upper limit on the inventory level of retailer \(j,\) (integer decision variable).
\(n\) Annual replenishment frequency of retailers per cycle (integer decision variable).
To develop the model, there are some assumptions in the proposed supply chain:
-
a)
Retailer’s inventory levels are defined by vendors.
-
b)
Retailers have to share information about inventory levels and sells.
-
c)
There are no stochastic or fuzzy parameters.
-
d)
The model follows the economic order quantity (EOQ) policy.
-
e)
There are two levels of echelons in the proposed supply chain.
Darwish and Odah (2010) developed Eq. (1) based on the VMI policy. For more details, we recommend Darwish and Odah (2010) to the interested readers. We contribute to this model by considering the upper limits of inventory levels (\({U}_{j}\)) as decision variables. Moreover, the number of a vendor’s orders faces a restriction in Eq. (2). Thus, the total cost function is as follows.
s.t,
where the first term is the retailers’ holding cost in Eq. (1). The second term indicates the total order cost for both the vendor and the retailers. The third term presents the vendor’s holding cost. Finally, the penalty cost is shown in the last term for those orders that exceed the upper limit.
Section 3 provides a metaheuristic approach in the optimization to obtain a near-optimal solution including \({q}_{1},n,\) and \({U}_{j}\) for Eq. (1).
4 The proposed solution algorithm: the imperialist competitive algorithm (ICA)
In order to solve integer linear programming models, metaheuristic methods are a powerful and fast approach (Sadeghi and Haapala, 2019). Other approaches such as DNA computing (Molaei et al. 2014) also solve nonlinear problems. Single solution-based search and population-based search such as swarm (Roozbeh Nia et al. 2015; Sadeghi, Niaki, et al. 2016a, b) are two classes in metaheuristic optimization. As a population-based search algorithm, Atashpaz-Gargari and Lucas (2007) developed the imperialist competitive algorithm (ICA) to solve integer linear programming models, which is powerful. ICA shows an accurate and fast solution compared with swarm algorithm and genetic algorithm (Sadeghi 2015). Since the proposed model is an integer linear programming model, it is impossible to find points satisfying Karush–Kuhn–Tucker (KKT) conditions as the solution algorithm suggested by Darwish and Odah (2010) due to integer conditions. Prior studies used the genetic algorithm and the particle swarm optimization to solve the VMI models (Sadeghi et al. 2015). Thus, we employed ICA to solve the proposed mathematical model for two reasons. First, ICA is more accurate and faster than the genetic algorithm and the particle swarm optimization in the VMI models. Second, ICA is a new algorithm used in VMI model optimization.
The following steps show the ICA to solve a mathematical model (Atashpaz-Gargari and Lucas 2007).
4.1 The power of the empires
In order to calculate the power of each imperialist, all imperialists costs (\(c_{i}\)) are normalized; thus, the normalized cost of the \(n^{th}\) imperialist (\(C_{n}\)) is:
Considering Eq. (4), the normalized power of each imperialist (\(p_{n}\)) is as follows.
The empires (e.g., 10) seize the initial colonies based on their power. Therefore, the initial number of colonies (e.g., 100) of the \(n^{th}\) empire (\(N.C._{n}\)) can be calculated as,
4.2 Changing the colonies
In this stage of ICA, the colonies can be improved with assimilation and revolution. It may be that an empire is eliminated, or the positions of the colony and the imperialist exchange together. To consider these conditions, changing the colonies is described as follows.
4.2.1 Assimilation
The imperialist tries to assimilate their colonies with respect to the specification of imperialism. For instance, the colonies, which some of their socio-political characteristics like culture and language are changed by the imperialist, will liken their imperialist. All the colonies completely liken the imperialist if there is continual assimilation. Therefore, to control this condition, a constant coefficient (\(\beta\)), which is greater than one, impresses the process of assimilation. Consequently, the amount of movement of the colony (\(x\)) is,
where \(x\) follows a uniform distribution and \(d\) is the distance between the imperialist and the colony. Since this method of assimilation is restricted to the direct movement, a random amount of deviation (\(\theta\)) impresses the direct movement (see Fig. 1). Thus
where \(\theta\) follows a uniform distribution and \(\gamma\) is an arbitrary number to search around the imperialist. It has been suggested that the values of \(\beta\) and \(\gamma\) be set about 2 and \({\pi \mathord{\left/ {\vphantom {\pi 4}} \right. \kern-\nulldelimiterspace} 4}\) (Rad), respectively (Atashpaz-Gargari and Lucas 2007).

New direction for the colony (Atashpaz-Gargari and Lucas 2007)
4.2.2 Revolution
In ICA, a revolution which is similar to a mutation in the genetic algorithm can prevent presenting a suboptimal solution as the optimal solution. In other words, revolution reduces the convergence speed. The power of colonialism will be increased by incurring less revolution in the colonies. The revolution changes randomly 20 percent of the positions of colonies with a 0.2 revolutions rate (\(P_{r}\)).
4.3 Total power of the empire
After changing colonies in regard to assimilation and revolution, it is probable that an empire is deleted or the positions of the imperialist and the colony replace one another. Therefore, it is reasonable to recalculate the total power for all the empires (\(T.C._{n}\)), which can be modeled by utilizing the total cost (Eq. 9).
where, \(T.C._{n}\) is the total cost for \(n^{th}\) empire and \(\xi\) is an arbitrary number that is less than one. \(\xi\) controls balance between the effect of the colonies and the imperialist on the power of the empire, where the value of ξ is set at about 0.1 (Atashpaz-Gargari and Lucas 2007).
4.4 Imperialistic competition
In the imperialistic competition, an empire seizes the weakest colony from the empire; afterward, the empires must compete for possessing the colonies to stay a powerful empire. Notice that the power of the empires is modeled based on the costs. It is necessary to compute the possession probability of empires to determine the empire that seizes the weakest colony. Thus, the possession probability for each empire is:
where, \(N.T.C._{n}\) is the normalized total cost of the \(n^{th}\) empire, which is calculated as follows.
In order to select an empire to possess a colony, Atashpaz-Gargaria and Lucas (2007) proposed the following method:
First, form the vector \(P\) (see Eq. 12).
Second, according to a uniform distribution (U (0,1)), create a vector with the size of \(P\).
Then, obtain the vector \(D\) that is the difference of \(R\) from \(P\).
Finally, the empire with its index having the highest value in the \(D\) vector, possesses the weakest colony. Considering imperialistic competition, strong empires will eliminate powerless empires as well as divide its colonies between other empires.
4.5 Convergence
There are several termination criteria. First, collapsing all empires to one empire; in other words, the world has only one empire. Second, to determine maximum decades, which means a fixed number of iterations (\(It\)) (Shahvari and Logendran 2016). Third, there is an unchanging best solution for a determined number of iterations. Another method is a combination of the above methods. This paper uses the second method of stopping the ICA that is a fixed number of iterations (i.e., 1000).
5 Results
In this section, we validate both the proposed algorithm, the ICA, and the mathematical model using a global optimal solution in the VMI literature. Table 1 shows a comparsion between the proposed methodology and an exact method. The results show that the solution obtained by the ICA and the exact method (Darwish and Odah 2010) are the same. Note that in Table 1, we used the same examples for ICA optimization and the exact method.
The results presented in Table 1 show the validation of the proposed methodology. In order to solve the mathematical model and consider the behavior of \({U}_{j},\) we solve the mode in 14 different scenario using numerical examples shown in Table 2. We use example data from the work presented by Darwish and Odah (2010). Based on results shown in Table 3, the optimized values for order quantity for the retailer (\({q}_{j}\)) is always lower than upper limits on the inventory level of retailers (\({U}_{j}\)). Therefore, the optimized solutions have a tendency to the situation in which there is not any overstock penalty for the vendor (that is \({U}_{j}>{q}_{j}\)). Note that Fig. 2 shows the convergence of the best costs in ICA in which decade represents iterations in ICA terminologies.

The convergence of the best costs
6 Discussion and managerial implications
This paper contributed to the prior studies in VMI models by including overstock penalty for the vendor. The results were based on an algorithm, verified by the exact method. The results indicated that the vendor avoids shortage due to overstock penalty. The findings had a focus on the vendor’s behavior in terms of keeping inventory in which the vendor was likely to keep as much as inventory to satisfy retailers. From managerial perspectives, the vendor’s behavior can be controlled by imposing an overstock penalty if the management has a plan to follow just in time approach. When it comes to lean implementation, inventory plays an important role in reducing extra inventory. Thus, the proposed decision tool herein can be used to manage vendor’s behavior to reduce the inventory levels.
7 Conclusion and future research
The vendor managed inventory is a well-known business policy to facilitate the relationship between buyer and suppliers (vendor and retailer). We continued the work presented by Darwish and Odah (2010) which is an inventory model in supply chains including a single-vendor and multiple retailers to incorporate their suggestion, which is consideration of upper limits on the inventory level of retailers as decision variables. The contribution of this paper was twofold. First, we developed a non-linear programming model by considering upper limits on the inventory levels as decision variables. Second, we contributed to the VMI literature by developing a meta-heuristic algorithm called imperialist competitive algorithm (ICA) to solve the mathematical model. To close the real-world situation, the number of orders was assumed to be limited. The aim of this paper was to develop a mathematical model to consider a vendor's behavior under a situation in which the upper limits of inventories are relaxed and considered as a decision variable. Does a vendor violate inventory limits and pay penalty to make more profits or follows the penalty policy? To answer this question, we developed a mathematical model. The objective of the model was to determine the order size, the replenishment frequency, and upper limits on the inventory levels to optimize the total cost function. Since the proposed model was an integer nonlinear programming problem, a meta-heuristic optimization called the imperialist competitive algorithm (ICA) was employed to obtain a near-optimal solution. We validate the proposed methodology with an exact method. Based on results, the proposed model provides solutions that follow the condition in which there is not any overstock penalty for the vendor (which means upper limits are higher than orders, that is \({U}_{j}>{q}_{j}\)), which is similar to backorder inventory models in inventory management.
There are some gaps to fill as future studies. For example, here we used a trial-and-error method to tune parameters of the algorithm. Statistical methods, such as Taguchi method, are able to improve the quality of the algorithm. Other views that can be developed in future research are consideration of economic production policy in mathematical modeling and the consideration of inflation rate in prices.
References
Akbari Kaasgari M, Imani DM, Mahmoodjanloo M (2017) Optimizing a vendor managed inventory (VMI) supply chain for perishable products by considering discount: two calibrated meta-heuristic algorithms. Comput Indus Eng 103:227–241
Atashpaz-Gargari E, and Lucas C (2007), Imperialist competitive algorithm: an algorithm for optimization inspired by imperialistic competition, Evolutionary Computation, 2007 CEC 2007 IEEE Congress On, IEEE, pp 4661–4667
Bazan E, Jaber MY, Zanoni S (2015) Supply chain models with greenhouse gases emissions, energy usage and different coordination decisions. Appl Math Model 39(17):5131–5151
Cai J, Tadikamalla PR, Shang J, Huang G (2017) Optimal inventory decisions under vendor managed inventory: substitution effects and replenishment tactics. Appl Math Model 43:611–629
Darwish MA, Odah OM (2010) Vendor managed inventory model for single-vendor multi-retailer supply chains. Eur J Oper Res 204(3):473–484
Esmaeili M, Nasrabadi M (2021) An inventory model for single-vendor multi-retailer supply chain under inflationary conditions and trade credit. J Indus Prod Eng Taylor Francis 38(2):75–88
Gautam P, Kishore A, Khanna A, Jaggi CK (2019) Strategic defect management for a sustainable green supply chain. J Clean Prod 233:226–241
Govindan K (2013) Vendor-managed inventory: a review based on dimensions. Int J Prod Res 51(13):3808–3835
Hemmati A, Stålhane M, Hvattum LM, Andersson H (2015) An effective heuristic for solving a combined cargo and inventory routing problem in tramp shipping. Comput Oper Res 64:274–282
Hosseini S, Ivanov D, Dolgui A (2020) Ripple effect modelling of supplier disruption: integrated Markov chain and dynamic Bayesian network approach. Int J Prod Res Taylor Francis 58(11):3284–3303
Hudnurkar M, Rathod U (2012) Collaborative supply chain: insights from simulation. Int J Syst Assurance Eng Manag 3:122–144
Huynh CH, Pan W (2015) Operational strategies for supplier and retailer with risk preference under VMI contract. Int J Prod Econ 169:413–421
Kamna KM, Gautam P, Jaggi CK (2021) Sustainable inventory policy for an imperfect production system with energy usage and volume agility. Int J Syst Assurance Eng Manag 12(1):44–52
Khan M, Jaber MY, Zanoni S, Zavanella L (2016) Vendor managed inventory with consignment stock agreement for a supply chain with defective items. Appl Math Model 40(15–16):7102–7114
Khanna A, Gautam P, Jaggi CK (2016) Coordinating vendor-buyer decisions for imperfect quality items considering trade credit and fully backlogged shortages. AIP Conf Proc Am Inst Phys 1715(1):020065
Khanna A, Gautam P, Sarkar B, Jaggi CK (2020) Integrated vendor–buyer strategies for imperfect production systems with maintenance and warranty policy. RAIRO Oper Res EDP Sci 54(2):435–450
Lee W, Wang S-P, Chen W-C (2017) Forward and backward stocking policies for a two-level supply chain with consignment stock agreement and stock-dependent demand. Eur J Oper Res 256(3):830–840
Li Y, Chen K, Collignon S, Ivanov D (2021) Ripple effect in the supply chain network: forward and backward disruption propagation, network health and firm vulnerability. Eur J Oper Res 291(3):1117–1131
Maheshwari S, Gautam P, Jaggi CK (2021) Role of big data analytics in supply chain management: current trends and future perspectives. Int J Prod Res Taylor Francis 59(6):1875–1900
Marque`s G, Thierry C, Lamothe J, Gourc D (2010) A review of vendor managed inventory (VMI): from concept to processes. Prod Plan Control 21:547–561
Molaei S, Molaei S, Asl MG, Sadeghi J and Tavakkoli-Moghaddam R (2014) A DNA algorithm for solving vehicle routing problem, Computational Science and Computational Intelligence (CSCI), 2014 International Conference On, Vol. 2, IEEE, pp 125–130
Pramudyo CS, Luong HT (2019) One vendor and multiple retailers system in vendor managed inventory problem with stochastic demand. Int J Ind Syst Eng 31(1):113–136
Roozbeh Nia A, Hemmati Far M, Niaki STA (2015) A hybrid genetic and imperialist competitive algorithm for green vendor managed inventory of multi-item multi-constraint EOQ model under shortage. Appl Soft Comput 30:353–364
Sadeghi J (2015) A multi-item integrated inventory model with different replenishment frequencies of retailers in a two-echelon supply chain management: a tuned-parameters hybrid meta-heuristic. Opsearch 52(4):631–649
Sadeghi J, Haapala KR (2019) Optimizing a sustainable logistics problem in a renewable energy network using a genetic algorithm. Opsearch 56(1):73–90
Sadeghi J, Mousavi SM, Niaki STA (2016a) Optimizing an inventory model with fuzzy demand, backordering, and discount using a hybrid imperialist competitive algorithm. Appl Math Model 40(15–16):7318–7335
Sadeghi J, Mousavi SM, Niaki STA, Sadeghi S (2013) Optimizing a multi-vendor multi-retailer vendor managed inventory problem: two tuned meta-heuristic algorithms. Knowl-Based Syst 50:159–170
Sadeghi J, Mousavi SM, Niaki STA, Sadeghi S (2014a) Optimizing a bi-objective inventory model of a three-echelon supply chain using a tuned hybrid bat algorithm. Transp Res Part E: Logist Transp Rev 70:274–292
Sadeghi J, Niaki STA, Malekian MR, Sadeghi S (2016b) Optimising multi-item economic production quantity model with trapezoidal fuzzy demand and backordering: two tuned meta-heuristics. Eur J Indus Eng 10(2):170–195
Sadeghi J, Sadeghi S, Niaki STA (2014b) A hybrid vendor managed inventory and redundancy allocation optimization problem in supply chain management: an NSGA-II with tuned parameters. Comput Oper Res 41:53–64
Sadeghi J, Taghizadeh M, Sadeghi A, Jahangard R, Tavakkoli-Moghaddam R (2015) Optimizing a vendor managed inventory (VMI) model considering delivering cost in a three-echelon supply chain using two tuned-parameter meta-heuristics. Int J Syst Assurance Eng Manag 6(4):500–510
Sainathan A, Groenevelt H (2019) Vendor managed inventory contracts–coordinating the supply chain while looking from the vendor’s perspective. Eur J Oper Res 272(1):249–260
Shaabani H, Kamalabadi IN (2016) An efficient population-based simulated annealing algorithm for the multi-product multi-retailer perishable inventory routing problem. Comput Ind Eng 99:189–201
Shahvari O, Logendran R (2016) Hybrid flow shop batching and scheduling with a bi-criteria objective. Int J Prod Econ 179:239–258
Simchi-Levi D, Kaminsky P, Simchi-Levi E, Shankar R (2007) Designing and managing the supply chain: concepts, strategies and case studies, 3rd edn. McGraw-Hill, New York
Son JY, Ghosh S (2020) Vendor managed inventory with fixed shipping cost allocation. Int J Logist Res Appl 23:1–23
Stellingwerf HM, Kanellopoulos A, Cruijssen F, Bloemhof JM (2019) Fair gain allocation in eco-efficient vendor-managed inventory cooperation. J Clean Prod 231:746–755
Talwar S, Kaur P, Wamba SF. and Dhir A (2021). Big Data in operations and supply chain management: a systematic literature review and future research agenda. Int J Prod Res, Taylor & Francis. 0(0): 1–26
Verma NK, Chatterjee AK (2017) A multiple-retailer replenishment model under VMI: accounting for the retailer heterogeneity. Comput Ind Eng 104:175–187
Zhao R (2019) A review on theoretical development of vendor-managed inventory in supply chain. Am J Ind Bus Manag 9(4):999–1010
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Najafnejhad, E., Tavassoli Roodsari, M., Sepahrom, S. et al. A mathematical inventory model for a single-vendor multi-retailer supply chain based on the Vendor Management Inventory Policy. Int J Syst Assur Eng Manag 12, 579–586 (2021). https://doi.org/10.1007/s13198-021-01120-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13198-021-01120-z