
Abstract
Automatic human fall detection is one of the major components in the elderly monitoring system. Detection of human fall in a smart home environment can be utilized as a means to improve the quality of care offered to elderly people thus reducing the risk factor when they are alone. Recently various fall detection approaches have been proposed, among which computer vision based approaches offer promising and effective solutions. In this paper, an analysis of fall detection is carrier out based on the automatic, feature learning in a hybrid approach. Initially, a model is generated using the training dataset that contains samples of both fall and normal active events. Then key frames are extracted from the video sequence that is subjected to two stream classification. The classification results are approved if both the streams project the same results, failing so, additional information are used to classify the fall from the normal activity. The selection of key frames depends on the displacement in the centroid of the detected object have threshold greater than the predefined value. Experiments show that the proposed approach achieves reliable results compared with other methods, and a better result is achieved in our method even when training with fewer training samples.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With advancement in technology, the use of surveillance camera has increased for various applications. Several applications require storage of surveillance data which may be accessed based on demand. Continuous monitoring of surveillance video in real time is a tedious task. Researches try to find the solution for the automatic detection of abnormal events without the influence of human monitoring of the surveillance videos (Tamura et al. 2009; Wang et al. 2016; Noury et al. 2007; Alwan et al. 2006; Nasution et al. 2007). One such application that this paper highlights in the automatic detection of fall events from normal day-to-day activities. Several work on fall detection techniques has been proposed by the researches over the past few decades (Wang et al. 2015; Delahoz and Labrador 2014).
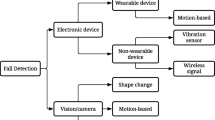
In general fall detection techniques can be classified into two different categories. The first category is based on device-based approaches, which make use of electronic devices to automatically detect fall from activities of normal living activity. This category can be sub classified into wearable device approach and non-wearable device approaches. Wearable device approach (Sixsmith and Johnson 2004; Kerdjidj et al. 2019; Makhlouf et al. 2018; Lara and Labrador 2013) makes use of information gathered from the electronic devices like accelerometer, a gyroscope to detect fall. The major disadvantage in these methods is that the information can be obtained only when the person wear these devices in the body which in real time causes inconvenience when worn every time. Non wearable device approaches are radar based approaches that use embedded devices installed in the living room and detects fall based on floor information such as vibration, pressure obtained from the sensor based embedded devices (Cao et al. 2017; Alwan et al. 2006). However, these methods suffer from a high degree of false alarm rate since any small change in room environment may sense a pressure difference which could not be actually from humans.
The second category is the vision based approach which has gained much attention over the past few years because of the following advantages. The major advantage of this approach is that they do not require any device to be worn for the functionality of the fall detection and thus convenient in using this in real time applications.
This paper is based on the assumption that the posture for an individual differ completely when a person tries to sit or lie on the floor during his normal daily activity and when he falls on the floor by losing his control. The difference in posture helps to detect fall from the normal activity. To avoid the time complexity in classification, selective key frames are used to classify the fall from the normal activity.
The main novelty of this paper includes applying two benchmark methods into one technique and thus increasing the robustness of the fall detection method. This paper is organized as it follows. Section 2 presents a detailed literature review of fall detection systems. Section 3 talks about the proposed methodology for fall detection and the challenges in it. Section 4 presents the evaluation and the discussion of experimental results and Sect. 5 concludes the paper.
2 Related works
In this section, we highlight the recent literature review for each of the category namely wearable device based approach, non wearable device based approach and vision-based approach. The most basic, commonly used wearable device method is based on accelerometer sensors.
Jahanjoo et al. (2017) proposed a method using a multi-level fuzzy min–max neural network. This method extracts the time and frequency domain features along with the accelerometer information which is subjected to linear transformation for dimensionality reduction. The results are finally compared with three other machine-learning algorithms namely, multilayer perceptron (MLP), K-nearest neighbors (KNN) and support vector machine (SVM). Chen et al. (2010) used a tri-axial accelerometer to detect a fall in his approach. This paper highlighted a solution with three-level fall detection criteria that includes a sum vector magnitude of acceleration, acceleration on the horizontal plane and the reference velocity. The results of this study show the effectiveness of the accelerometer data to detect falls from normal activity. Ozcan et al. (2013) made use of wearing an embedded smart camera and proposed a fall detection algorithm by extracting the histograms of edge orientations. The classification of fall activities is finally done using an optical flow-based method. This method is highly prone to false alarm rate due to change in lighting conditions, and when the person who is wearing the camera changes the room.
Wang et al. (2014) introduced a method by utilizing the information from the accelerometer, cardio tachometer and smart sensors, to distinguish the fall from normal daily activities. Based on this method parameters namely, signal magnitude vector (SMV), heart rate, and trunk angle are used to determine the accidental fall from normal activity.
Pierleoni et al. (2015) presented a method by using tri axial accelerometer, gyroscope, and magnetometer to distinct fall from normal activity. The orientation information of the person wearing it is obtained by MARG (Magnetic, Angular Rate, and Gravity) sensor along with the information from 3-axis accelerometer, 3-axis gyroscope, and 3-axis magnetometer used. Sabatini et al. (2016) proposed a method using the barometric altimeter to detect he falls from normal activity. This method is based on two-stage decisional scheme where the first stage of the fall detection algorithm performs prior-to-impact fall detection using the vertical velocity estimate and the second stage analyzes features of impact, height change, and posture change, singularly or in combination with one another, to perform post-impact fall detection. Cao et al. (2012) proposed a fall detection system using the motion sensor present in android based smart phones. The system termed as E-FallD collects the users information such as age, weight and uses an adaptive threshold algorithm to detect the fall from normal event.
All the above mentioned literature is based on wearable approaches that use different sensor devices to be worn in the body. Most of these approaches are effective in its functionality, which in real time causes inconvenience, disturbance to be worn continuously.
However, the limitations in the wearable based approaches can be made to overcome using non wearable and computer vision based approaches. Few research works have been carried in non-wearable based approaches and have gained attention compared to wearable based approaches. Wang et al. (2017a) proposed a low-cost indoor fall detection system by exploiting the phase and amplitude of the fine-grained channel state information (CSI) accessible in commodity Wi-Fi device. This method uses the CSI phase difference for segmenting the fall activity and the sharp power profile decline pattern in the time–frequency domain is exploited to maintain its accuracy in fall segmentation. Though this algorithm was robust against illumination changes, the performance deteriorated with change in environment, moving of furniture’s within the same environment.
Recently, Junior and Adami (2018) proposed a method for fall detection that combined different techniques namely thresholds analysis, device orientation analysis, and decision trees algorithm together to detect fall from normal activity. Garripoli et al. (2014) proposed a method consisting of a radar sensor and base station which communicate with each other to detect the fall activity. This method is implemented via an embedded DSP processor by making use of least-square support vector machines. This method, though robust with change in environment, the major limitation is that in order to detect the fall, the radar sensor should be in communication with the base station round the clock. Wang et al. (2017b) proposed a correlation based method to detect the fall by making use of the radio signals. The evaluation of this technique is done using desktops equipped with commodity 802.11n NIC on three typical indoor scenarios with several layouts of transmitter–receiver links. With multiple activities detected, the efficiency of this method depends on the amount of training dataset involved.
Following a similar approach, Kianoush et al. (2017) proposed a method for joint localization and fall detection of humans inside the industrial area. Based on this technique, the RF based wireless devices are deployed around a workspace, and the received signal strength is used to locate the humans, and their movements. An algorithm based on hidden Markov model is defined to detect the activities in the working area.
Rimminen et al. (2010) proposed a method by using near-field imaging (NFI) floor sensor to detect the locations and patterns of people by extracting three features related to the number of observations, dimensions, and sum of magnitude. Finally, two state Markov chain is used for modeling the fall and non fall activity while the estimation is done using Bayesian filtering.
Although non-wearable approaches have certain advantages, they are also carrier limitations which are to be addressed. Non-wearable are more sensitive to external noise because of the changes that happen externally. However, vision-based approaches overcome the above limitations and have gained a lot of attention because of the practical use in real life.
The commonly used method earlier is the simple thresholding technique to discriminate the fall from an actual daily living activity. Rougier et al. (2007) in proposed a method using the velocity and change in orientation information to detect the fall from normal activity. Rougier and Meunier (2010) proposed fall detection using the motion history information (MHI) which describes the recency of motion information in an image sequence. The MHI likely represents the flow direction of the motion, which help to classify the activity based on the flow direction information. Belshaw et al. (2011) made use of silhouette features, lighting, and flow features to classify the activity under fall or active living. Based on their evaluation, using Multilayer Perceptron Neural Network for classification has achieved better results with a true positive rate of 92% and a false positive rate of 5% on the test dataset. Vishwakarma et al. (2007) introduced a method to detect a moving object using an adaptive background subtraction method and used a finite state machine (FSM) to continuously monitor people and their activities. Though this method extracts features to detect the activity, it does not use any classifier technique which could improve the accuracy under complex environment.
In this paper, a new approach to vision based method is proposed for fall detection based on machine learning algorithm by taking the spatial and temporal information of the video data into consideration. Initially, a fall detection model is generated by using SVM classification from the training dataset. Frames with moving objects having displacement greater predefined threshold are selected and subjected to two-stage classification. The classification result along with other information is used to differentiate the fall from normal activity. The details of the method are presented in the next section.
3 Methodology
The proposed method includes the following module. Detection of human as a foreground object, model generation by training data, key frame extraction and two stream classification using spatial and temporal features. The proposed method combines the advantage of spatial and temporal components during classification. Figure 1 illustrates the overview of the proposed method is shown in Fig. 2 shows the overall flowchart of the proposed method.

Main framework of our proposed method

Flowchart of our proposed method
3.1 Foreground segmentation
The algorithm begins by segmenting the moving foreground person from the scene. One of the commonly used methods for foreground extraction is by using background subtraction which detects the moving person by subtracting the current frame from the background model. In order to segment the moving human of the surveillance video in real time, an adaptive background mixture model is used Stauffer and Grimson (1999) which is fairly robust against illumination changes, and shadows. Each pixel is modeled as a mixture of Gaussian and the algorithm uses an online approximation to update the background. The update policy used here allows the system to adapt the change in lighting condition and objects that stops moving. Each pixel is classified as foreground or background based on the association of the pixel intensity with the background model.
3.2 Training of fall and normal activity postures
In this section, the spatial and temporal model is generated by training the two different classes of data. As stated earlier it is assumed that the fall activity and non-fall activity have different postures. Figures 3, 4 shows some examples of normal and unintentional fall postures. Few samples for both the fall and normal activities are collected from selected videos. These are then trained separately as fall and normal activities and a model is generated using SVM. The spatial model is generated with the training samples that resemble the posture of fall and normal activities. Temporal model is generated with the use of optical flow features obtained by Lucas. Kanade optical flow method discussed in Lucas and Kanade (1981) that consider the displacement of pixels from two different frames. Being a two class classification problem, linear kernel is used in SVM.

Training samples for normal activity

Training samples for fall activity
3.3 Key frame extraction
Random selection of key frame may not yield a better result in classification. This is because randomly key frame selected may not have features that are trained in advance which yield to poor classification. Moreover to train all the possible features is a challenging needless task and is also increases time complexity. Here the key frames are selected based on the assumption two that any abnormal fall that happens has higher horizontal or vertical or both the movement maximum compared to the normal moving activity. To select the frames based on the above-said criteria, the position of centroids of the foreground region is found and frames that have a maximum that has maximum horizontal and vertical displacement are targeted. Figure 5 depicts the result for the absolute difference in movement of the centroid of the foreground object in the horizontal and vertical direction for both fall activities.

Absolute difference of the displacement of the centroid for a fall-13 sequence
3.4 Classification of using key frame
Once the key frames are selected based upon the acceleration of movements from the centroid of the foreground objects, they are subjected to activity detection to classify under two different classes namely fall or normal activity.
3.4.1 Two stream architecture for classification
With several classification architectures available, this approach takes the benefits of spatial–temporal features and thus obtain high gain in classification rate. In order to attain the benefits of both spatial and temporal features, here a hybrid method that uses two different methods for classification are used. The selected key frames from the incoming data are subjected to spatial and temporal classification.
The optical flow vectors are extracted for the key frames are used for temporal classification. The optical flow for both the fall and normal activity differ in its features and this used as a merit for the two different classes in temporal classification set. Figure 6c shows the result of optical flow vectors for a frame number 52 obtained from frame number 51 of a fall sequence.

Optical flow vectors of frame no. 51 and 52 for fall 27-cam0-rgb sequence
If both the classification sets give a different set of class output the final evaluation is done based on the information obtained from change in orientation of the elliptical pattern for the moving foreground object. With several classifiers available, SVM classification is preferred over technique is because of the fact that, linear SVM can be modeled with less training samples and highly efficient for two class linear classification. There are few constrains in implementing fall detection in real time. The most general constrain is that the devices are designed and tested under controlled conditions, where the dataset for falls and normal activities of young people simulated. To collect real time fall detection data from elderly is seldom possible. Another challenge is that the analysis of this approach is tested in with data under daylight illumination condition, while evaluation of the approach under night vision has to done in future.
4 Experimental results
The effectiveness of the proposed system is evaluated in this section. The fall detection method proposed in the paper is implemented using MATLAB on the machine having configuration of Intel Core i5 2.90 GHz CPU with 8 GB of RAM. UR fall detection dataset is used to validate the performance of the algorithm. This dataset contains 70 videos with 30 falls and 40 activities of daily living sequences. Being a vision-based approach, we have considered only the RGB images of the UR dataset sequence.
4.1 Performance measures
In order to evaluate the performance of the proposed method, the following parameters are used. True positives (TP) denotes the number of falls events detected correctly. True negatives (TN) represent the correctly detected normal activities by the algorithm.
False positives (FP) denote the normal activities detected as a fall event and False negatives (FN) represents the number of falls event detected as a normal activity. With the help of TP, TN, FP, FN the parameters namely accuracy and error rate, Sensitivity, Specificity are calculated and compared with other existing systems.
Accuracy denotes the correctness of the classification rate while the error rate represents the incorrect classification rate. The formula to calculate accuracy and error rate are as follows.
Sensitivity is defined as the ability to detect fall events and is given by,
Specificity is defined as the ability of the system to recognize normal activities and is given by,
Precision is also called as a positive predictive value and is given by,
In order to generate the model for classification, a total of 200 samples of the frame from four video sequence are used as training dataset. Two models are generated while one represents the spatial features where each frame are trained individually. The other being temporal model is extracted using the optical flow information from the 250 frames from five different video sequence. The results for video classification for the proposed system with the spatial features and the combined approach are discussed in Tables 1 and 2. Table 1 show the performance of the proposed fall detection approach using spatial features as input, while Table 2 illustrates the performance of the proposed fall detection approach by combining both the spatial and temporal features.
In Table 3, the performance of the proposed technique is compared with the other earlier existing algorithm Kepski and Kwolek (2015). The evaluation parameter namely the accuracy, precision, sensitivity, and specificity of the proposed system is compared with the existing methods. The evaluation is done by considering all the key frames that are subjected to classification.
Based on the evaluation the system outperforms the existing system in terms of accuracy, sensitivity, and specificity. Moreover, the existing system only makes use of the depth information to detect its features. The advantage of the system also lies in the fact that this method does not require foreground technique to yield accurate results. Enhancement has to be made in further research for video data with multi view approach.
5 Conclusion
In this paper, a novel approach to fall detection is analyzed, by integrating the merits of two different systems as one technique. This technique gains novelty by incorporating a system modeled by the spatial and temporal training features of the fall detection data. A two stage SVM classifier is used to detect fall from the normal activity. With two models handling different spatial and temporal features, the experiment shows that the proposed method can be robust in performance with fewer training samples when compared with other state-of-the-art methods. The proposed technique is highly efficient with reduced classification error rate. Also when conflicts occur in the classification of spatial and temporal models additional parameters are used to classify the incoming key frames. Moreover, the system can be further improved and the robustness can be maintained by training with large dataset and cameras with multiple views involved.
Change history
23 May 2022
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s12652-022-03934-6
References
Alwan M, Rajendran PJ, Kell S, Mack D, Dalal S, Wolfe M, Felder R (2006) A smart and passive floor-vibration based fall detector for elderly. Inf Commun Technol 1(2):1003–1007
Belshaw M, Taati B, Snoek J, Mihailidis A (2011) Towards a single sensor passive solution for automated fall detection. Annual International Conference of the IEEE Engineering in Medicine and Biology Society, pp. 1773–1776
Cao Y, Yang Y, Liu W (2012) E-FallD: A fall detection system using android-based smartphone. IEEE International Conference on Fuzzy Systems and Knowledge Discovery, pp. 1509–1513
Cao W, Liu X, Li F (2017) Robust device-free fall detection using fine-grained Wi-Fi signatures. IEEE Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, pp. 1404–1408
Chen G, Huang C, Chiang C (2010) A reliable fall detection system based on wearable sensor and signal magnitude area for elderly residents. International Conference on Smart Homes and Health Telematics, pp. 267–270
Delahoz YS, Labrador M (2014) A survey on fall detection and fall prevention using wearable and external sensors. Sensors 14(10):19806–19842
Garripoli C, Mercuri M, Karsmakers P, Soh PJ, Crupi G, Vandenbosch GA, Schreurs D (2014) Embedded DSP-based tele health radar system for remote in-door fall detection. IEEE J Biomed Health Inform 19(1):92–101
Jahanjoo A, Tahan MN, Rashti MJ (2017) Accurate fall detection using 3-axis accelerometer sensor and MLF algorithm. International Conference on Pattern Recognition and Image Analysis (IPRIA), pp. 90–95
Junior CLB, Adami AG (2018) SDQI–fall detection system for elderly. IEEE Latin Am Trans 16(4):1084–1090
Kepski M, Kwolek B (2015) Embedded system for fall detection using body-worn accelerometer and depth sensor. IEEE 8th International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), pp. 755–759
Kerdjidj O, Ramzan N, Ghanem K, Amira A, Chouireb F (2019) Fall detection and human activity classification using wearable sensors and compressed sensing. J Ambient Intell Humaniz Comput 2019:1–13
Kianoush S, Savazzi S, Vicentini F, Rampa V, Giussani M (2017) Device-free RF human body fall detection and localization in industrial workplaces. IEEE Internet Things J 4(2):351–362
Lara OD, Labrador MA (2013) A survey on human activity recognition using wearable sensors. IEEE Commun Surv Tutor 15(3):1192–1209
Lucas BD, Kanade T (1981) An iterative image registration technique with an application to stereo vision. Proceedings of the 7th international joint conference on Artificial intelligence, pp. 674–679
Makhlouf A, Boudouane I, Saadia N, Amar RC (2018) Ambient assistance service for fall and heart problem detection. J Ambient Intell Humaniz Comput 10(4):1527–1546
Nasution AH, Emmanuel S (2007) Intelligent video surveillance for monitoring elderly in home environments. IEEE 9th Workshop on Multimedia Signal Processing, pp. 203–206
Noury N, Fleury A, Rumeau P, Bourke A, Laighin G, VRialle, Lundy J (2007) fall detection—principles and methods. 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, pp. 1663–1666
Ozcan K, Mahabalagiri AK, Casares M, Velipasalar S (2013) Automatic fall detection and activity classification by a wearable embedded smart camera. IEEE J Emerg Sel Topics Circuits Syst 3(2):125–136
Pierleoni P, Belli A, Palma L, Pellegrini M, Pernini L, Valenti S (2015) A high reliability wearable device for elderly fall detection. IEEE Sens J 15(8):4544–4553
Rimminen H, Lindstrom J, Linnavuo M, Sepponen R (2010) Detection of falls among the elderly by a floor sensor using the electric near field. Inf Technol Biomed IEEE Trans 14(6):1475–1476
Rougier C, Meunier J (2010) 3D head trajectory using a single camera. Int J Future Gener Commun Netw 3(4):43–54
Rougier C, Meunier J, St-Arnaud A, Rousseau J (2007) Fall detection from human shape and motion history using video surveillance. Int Conf Adv Inf Netw Appl Workshops (AINAW) 2:875–880
Sabatini AM, Ligorio G, Mannini A, Genovese V, Pinna L (2016) Prior-to- and post-impact fall detection using inertial and barometric altimeter measurements. IEEE Trans Neural Syst Rehabil Eng 24(7):774–783
Sixsmith A, Johnson N (2004) Smart sensor to detect the falls of the elderly. IEEE Pervasive Comput 3(2):42–47
Stauffer C, Grimson WEL (1999) Adaptive background mixture models for real-time tracking. Proceedings IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No PR00149), 2: 246–252
Tamura T, Yoshimura T, Sekine M, Uchida M, Tanaka O (2009) A wearable airbag to prevent fall injuries. IEEE Trans Inf Technol Biomed 13(6):910–914
Vishwakarma V, Mandal C, Sural S, (2007) Automatic detection of human fall in video. International Conference on Pattern Recognition and Machine Intelligence, pp. 616–623
Wang J, Zhang Z, Li B, Lee S, Sherratt RS (2014) An enhanced fall detection system for elderly personmonitoring using consumer home networks. IEEE Trans Consum Electron 60(1):23–29
Wang S, Chen L, Zhou Z, Sun X, Dong J (2015) Human fall detection in surveillance video based on PCA Net. Multimedia Tools Appl 75(19):11603–11613
Wang K, Cao G, Meng D, Chen W, Cao W (2016) Automatic fall detection of human in video using combination of features. IEEE International Conference on Bioinformatics and Biomedicine, pp. 1228–1233
Wang H, Zhang D, Wang Y, Ma J, Wang Y, Li S (2017a) RT-Fall: a real-time and contactless fall detection system with commodity wifi devices. IEEE Trans Mob Comput 16(2):511–526
Wang Y, Wu K, Ni LM (2017b) WiFall: device-free fall detection by wireless networks. IEEE Trans Mob Comput 16(2):581–594
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article has been retracted. Please see the retraction notice for more detail: https://doi.org/10.1007/s12652-019-01600-y
About this article

Cite this article
Jeffin Gracewell, J., Pavalarajan, S. RETRACTED ARTICLE: Fall detection based on posture classification for smart home environment. J Ambient Intell Human Comput 12, 3581–3588 (2021). https://doi.org/10.1007/s12652-019-01600-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12652-019-01600-y