
Abstract
Activity recognition is beneficial for continuous health monitoring of smart-home residents, such as patients and elderly people, living in the privacy of their home. We propose an activity recognition approach apposite for a smart home environment. The observations are obtained through multiple sensors deployed at different locations within a smart home. The activities are represented by the features selected from the received observations. The inconsistent order of performing the activities, infrequent occurrences and the presence of overlapping activities make it challenging to select the features with high class representative ability and inter-class discriminative qualities. We select the key features locally within each activity class, which is least affected by the order of performance and the occurrence of other activities. Next, for association of activities, we solve the existing multi-class problem through a specifically designed binary classification with ranking solution, which learns on the correct and incorrect assignments of activities. A comparison of proposed approach with existing methods in terms of recognition accuracy is presented on publicly available ‘Kasteren’ and ‘CASAS’ datasets, representing a range of overlapping and well separated activities of daily life. Our approach tailored towards a smart home environment demonstrates a better accuracy than existing methods.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Technologically driven solutions in health care improve the living standards of elderly people and patients with chronic physical and cognitive impairments (Rashidi et al. 2011; Bouwstra et al. 2009; Okeyo et al. 2014; Forkan et al. 2015; Sorensen et al. 2006; Rialle et al. 2002; Andre and Wolf 2007; Ermes et al. 2011; Mshali et al. 2018; Jalal and Kamal 2018; Garcia et al. 2018). One such solution is the concept of smart homes, equipped with wireless sensor networks, that enables people to live independently at their home under continuous observations (Chen et al. 2010; Wang et al. 2011; Mshali et al. 2018). Recognition of activities, such as eating, sleeping, cooking, appropriate usage of medications and prescribed physical exercises, is a fundamental task in smart homes. Through activity recognition, the changes in the behavior of a patient can be observed and preventive measures from associated risks can be taken.
The activities in a smart home are represented by the sequence of events or actions. Activities can be categorized into different classes such as hand washing and meal preparation. Multiple sensors are used to capture the low level observations such as human object interaction, motion and location (Tapia et al. 2004; Kasteren et al. 2008; Gu et al. 2011; Bao and Intille 2004). These sensor observations are used to generate the activity examples termed as instances of an activity class. We can have multiple instances of an activity class, which can be utilized to train the activity recognition model. The learned model is then used to recognize the newly occurring activity instances.
Most of the existing activity recognition approaches are developed based on the assumption that the activities follow a certain predefined sequence of events; however, it may not always be the case. A single activity can be performed in different ways by different users. Variations may also exist in the instances of the same activity if performed a number of times by the same user. Therefore, it is important to consider the inter and intra subject differences (Atallah and Yang 2009). The existing feature selection methods select a subset of significant features from the entire dataset to represent all the activities (Zhang and Sawchuk 2011; Chen et al. 2010; Fleury et al. 2010). Since the sensors are deployed at geographically different locations, such feature selection approaches becomes less pertinent in the case of smart homes. A feature significant for one activity may not be a representative of other activities in the dataset. The issue is more prominent, when the number of instances significantly varies between the activities and some activities occur more frequently than others. In such cases, the selection of feature can become biased towards activity classes with more number of instances. Also a classification approach alone used for activity recognition may not perform well in the case of corrupted data due to unreliable sensors and overlapping activities. These challenges reflect the importance of a robust activity recognition approach appropriate for smart homes.
In this paper, we propose an activity recognition approach that comprises of the Key Feature Selection (KFS) followed by the activity association approach named as Correct Incorrect Distance Learning and Ranking (CIDLR). KFS method selects the key features of each activity class independent of other activities, hence if we have a total of K activity classes the method extracts K sets of key features unlike the existing methods, which return a single subset of features for all activities. The benefit of KFS is that the selection is not biased towards the more frequently occurring activities and it is independent of the sequence of events in an activity instance. The selected key features are then utilized for activity association using CIDLR, which exploits the characteristics of classification by learning, and ranking techniques. The difference between the correct and incorrect associations of activity instances are learned and ranked in order of dissimilarity from the new instance. CIDLR is primarily based on a binary class solution for a multi-class problem. We further use the learning method rankSVM for the ranking of activities. CIDLR is particularly useful when the activity classes share similar features and the classes are not well separated. The benefit of CIDLR is that its performance remains comparatively more stable than the existing learning approaches based only on classification, which are suitable for well defined and non-overlapping classes, or only ranking approaches based on the dissimilarity measures. We validate the proposed approach in the activity recognition scenario of smart homes and it proves to be more suitable as compared to the existing feature selection and association approaches.
The rest of the paper is organized as follows: Sect. 2 discusses the related work on activity recognition. In Sect. 3, we discuss the proposed key feature selection method and activity association approach based on difference learning. The datasets and evaluation criteria is presented in Sect. 4. In Sect. 5, proposed approach is validated with the existing methods using Kasteren and CASAS datasets. Finally, Sect. 6 draws the conclusions.
2 Related work
Data obtained from ambient or environment interactive sensors, such as reed switches, pressure, motion, analog and binary sensors, can be used for recognition of general activities performed in a smart home, such as preparing meal, eating, sleeping.
Naive Bayes classifier is used for activity recognition, which assigns the label of activity class with the highest probability corresponding to the sequence of activated sensor values (Tapia et al. 2004). Hierarchical-HMM (HHMM) is applied for activity recognition, where the number of events corresponding to each activity in the top layer is fixed (Kasteren et al. 2011). HHMM remains more effective than Hidden Semi Markov Model (HSMM) and HMM. An extension to this approach applies HHMM using variable number of events for each activity to represent different levels of complexity (HHMM-VS) (Alemdar et al. 2014). Incorporation of temporal reasoning with HMM can improve the recognition accuracy (Singla et al. 2008). Long range dependencies in sequential algorithms are obtained by pattern mining, which finds the patterns indicating time segments during the execution of an activity. A probabilistic model is learned to represent the distribution of pattern matches along sequences in an activity, which is integrated with HSMM for recognition of activities (AR-SPM) (Avci and Passerini 2014). In an unsupervised approach, the discontinuous frequent patterns are extracted and similar patterns are grouped in the clusters, while the boosted HMM is applied to learn from the clusters (Rashidi et al. 2011). In a clustering based classification approach, homogeneous activities are grouped into clusters, while learning is applied within each cluster independently to learn the fine-grained differences between the activities (Fahad et al. 2014).
An incremental learning approach using DBN is applied to recognize activities by reconfiguring the previously learned models to adapt the variations within the activities (Lu et al. 2013). The recognition performance and effectiveness of Dempster Shafer Theory (DST) of evidence and DBN approaches are compared for activity classification (Tolstikov et al. 2011), where DST is suitable for uncertainty in the data, while DBN performance depends upon the quality and reliability of the input data. The capabilities of both generative (HMM) and discriminative (CRF) models are also evaluated for activity recognition (Kasteren et al. 2008). CRF is undirected graphical model to label the sequential data and has been applied for classification of activities (Nazerfard et al. 2010).
Principal component analysis (PCA) identifies the discriminative features, while multi-class SVM (one-versus-one) is used for activity classification (Fleury et al. 2010). Information gain is used to select feature subsets, while data balancing is applied to improve the representation of minority classes and Evidence-theoretic K-Nearest Neighbor (ET-KNN) is used for recognition of activities (Fahad et al. 2015c). A general purpose feature collection approach is discussed to extract features across multiple datasets of different type, size and nature for activity recognition. The collection of features is typically organized into the following four categories; that includes time, space, complexity and inter-activity related measures (Chinellato et al. 2016). Latent features are extracted by Beta Process HMM and SVM classifier is trained in a supervised way using these features for recognition of daily activities of a smart home resident (Lu et al. 2017). Inter-class distance based approach is applied to select the best features, while three learning approaches ANN, HMM and NB are used for recognition, among all, ANN performs better (Fang et al. 2014). Three neural network algorithms, Quick propagation, Levenberg Marquardt and Batch Back Propagation have been applied for recognition of human activites, among them Levenberg Marquardt algorithm performed better compared to the other two algorithms (Danaei-mehr et al. 2016).
The representative patterns of activities can be selected by pattern mining and sequence alignment methods, the patterns are then matched with the observed sequences of events for activity recognition (Huang et al. 2010). Activity patterns can be identified in each location using frequent item set mining, while density based clustering is applied to form activity clusters (Hoque and Stankovic 2012). Pattern mining is applied to extract the frequent patterns and Latent Dirichlet Allocation (LDA) is used to cluster the co-occurring sequential patterns, (ADR-SPLDA) (Chikhaoui et al. 2012). Two variants of LDA obtained by replacing the multinomial distribution, LDAGaussian and LDAPoissonvon-Mises, can be used for classification of activities (Rieping et al. 2014). The comparison of five learning classifiers is performed under different challenges in (Fahad et al. 2015a), where SVM demonstrates to be the most robust classifier in activity recognition. Activity recognition can also be improved by separating activities from anomalies, where Support Vectors Data Descriptors (a variant of SVM) has been used for the classification of normal and anomalous behavior patterns of the elderly (Shin et al. 2011). In an online activity recognition approach by Ordonez et al. (2013) evolving neuro-fuzzy classifiers have been used to reflect the changes in the execution of activities. In an activity recognition approach with self-verification of assignments (ARSH-SV), correct/incorrect assignments are learned for label assignment using SVM, while the confidence of assigned label is estimated by measuring the distribution of underlying data through sub-clustering within each activity class Fahad et al. (2015b).
Knowledge driven, evidence based and other hybrid approaches have also been applied for recognition of activities. In a knowledge driven approach, ontological modeling and semantic reasoning are applied for classification of activities (Chen et al. 2012). A hybrid approach combines the ontological and temporal knowledge representation for activity modeling (Okeyo et al. 2014). Partially observable Markov decision process models are built using the user interaction information within the context for activity recognition (Hoey et al. 2011). Temporal reasoning can be incorporated in ontology to recognize the daily activities (Riboni et al. 2011). Clustering can be used to define initial incomplete models through knowledge engineering, which are then used to represent an activity and to aggregate new events, and variations in the activity pattern are learned to get the complete model for activities (Azkune et al. 2015). Recognition approaches based on belief theory are also applied such as Evidence Decision Network (EDN) approach by Mckeever et al. (2010), where the temporal information of domain knowledge i.e start time and duration of the activity is incorporated in the DST. An extension of this work is proposed by Kushwah et al. (2015), where a data fusion approach based on DST is developed to include the temporal evidence of the occurrence of events. An evidential approach (EFA-AR) exploits the combination rule of DST to support conflict resolution by combining the sensor information with common-sense knowledge (Sebbak et al. 2013). Experience Sampling for activity annotation and weakly supervised learning methods, multi-instance learning and graph structure, are also applied (Stikic et al. 2011). In multi-instance learning, the activity data is grouped into bags-of-activities and the labels are assigned to bags instead of activity instances, and the goal is to determine the labels of instances belonging to particular activity provided by the bag’s label. In graph structure, the labels are propagated to the unlabeled neighboring activity instances through feature similarity and time proximity (Stikic et al. 2011).
Existing activity recognition approaches focus on applying different existing algorithms for classification of activities, which exploit all the features or a single selected feature set for all the activities; however we improve the activity recognition through identification of key features within each activity class. The identified key features of each class results in correct separation of the target from the rest of the classes. The second contribution lies in correct label assignment to the activity instances by solving a multi-class problem through a binary SVM, that is particularly effective in the case of overlapping activity classes.
3 Proposed approach
We propose an activity recognition approach for the activities performed by patients or elderly people living independently in smart homes. The approach first selects for each activity class, the key features locally within the class. The selected key features are then used for activity recognition using the proposed difference learning and ranking method. The block diagram of the approach is shown in Fig. 1.
3.1 Key feature selection (KFS)
Let A be the training set of K activity classes: \(A = \left\{ A_{1},\ldots ,A_{k},\ldots ,A_{K} \right\}\). We assume that each activity class \(A_k\) has J activity instances such that \(I = \left\{ I_{1k},\ldots ,I_{jk},\ldots ,I_{Jk} \right\}\). Activity instance \(I_{jk}\) is observed by R binary sensors installed at different locations in a smart home. \(I_{jk}\) is represented by a feature set \(F_{jk}\) of R features such that
The number of features in the feature set is equal to the number of installed sensors. Each feature represents the frequency of the activation of a sensor. For non-activated sensors, a zero is assigned to the corresponding feature such that \(f_{jk}^{r}=0\). Each feature \(f_{jk}^{r}\) is then normalized such that \(0\le \hat{f}_{jk}^r \le 1\). The normalized feature set \(\hat{F}_{jk}\) for \(I_{jk}\) is given by
where \(x^r = {\text {min}}_{j,k} f_{jk}^{r}\) and \(X^r = {\text {max}}_{j,k} f_{jk}^{r}\) for all instances observed by rth sensor in K activity classes.

Block diagram of the proposed approach
Let \(Y_k\) be a set of IDs (\(r_k^*\)) of the selected key features for an activity class \(A_k\). \(Y_k\) is initially empty \((Y_k=\phi )\). In order to find the key features for \(A_k\), we count the number of activity instances within \(A_k\) which have non zero values for the rth feature \({\hat{f}_{jk}^r}\)
where \(\langle \cdot \rangle\) counts the number of elements in a list. \(\varTheta _k^r\) represents the occurrence of a feature in the instances of \(A_k\). The value of \(\beta\) is user defined and allows the minimum number of instances, which can be sufficient for the decision of a key feature and hence cannot have a universally accepted fixed value. We applied the traditionally accepted technique of cross validation on the training data to adjust the value of \(\beta\). The feature which appeared in the most number of activity instances of \(A_k\) is considered as a key feature. The ID \(r_k^*\) of the key feature is found by
If \(r_k^* \notin Y_k\) then \(r_k^*\) is included in \(Y_k\), \((Y_k \cup r_k^*)\). The \(\varTheta _k^r\) is evaluated for the rest of the features in \(A_k\) using Eq. 4. The process is repeated for all activities and we get a set \(Y_k\) for each activity class \(A_k\).
where \(\varPhi\) contains K sets of \(Y_k\).
Each key feature within \(A_k\) is assigned a fixed importance weight \(W^{r^*}_k\), which depends upon the number of key features representing \(A_k\).
where \(|Y_k|\) is the cardinality of \(Y_k\). The same feature when used in different activity classes can be assigned different weight depending upon the number of key features in that activity class. A set \(\varOmega\) of weights for all K activity classes is defined as
Finally, we get the updated feature set \(\overline{F}_{jk}\) for the activity instance \(I_{jk}\) such that
where \(\overline{f}_{jk}^r\) represents the weighted key feature within the feature set given by
The updated feature set \(\overline{F}_{jk}\) representing the activity instance \(I_{jk}\) is then utilized for activity recognition.
3.2 Difference learning from key features
In order to solve the activity recognition problem, we propose a binary classification and ranking approach CIDLR. Let each activity class \(A_k\) is represented by a set of mean features \(M_{k}\):
where \(m_k^{r}\) is the mean representation of each feature within the group of instances of an activity class \(A_k\) and is calculated as
\(M_{k}\) is similar in principle to k-mean. However, k-mean is an unsupervised algorithm, whereas we already have the identified training data grouped into each known class. \(M_k\) is useful to relax the boundary of each activity, avoid over fitting and reduce the size of training data.
For each activity instance \(I_{jk}\) in the training set, we calculate K difference-feature vectors \(\{D_{jk}^{k'}\}_{k'=1}^K\) between the feature set \(\overline{F}_{jk}\) and the K sets of mean features \(M_{k'}\), where \(k'=1 \ldots K\):
where the operator \(\ominus\) performs an element wise subtraction. In order to formulate a binary class problem, for each \(D_{jk}^{k'}\) a target \(T_{D_{jk}^{k'}}\) is defined. If \(\overline{F}_{jk}\) and \(M_{k'}\) belong to the same activity class \(A_k\) such that \(k=k'\) then \(D_{jk}^{k'}\) belongs to the correct class with target \(T_{D_{jk}^{k'}}=T^+_{D_{jk}^{k'}}\). For \(k\ne k'\) the target \(T_{D_{jk}^{k'}}=T^-_{D_{jk}^{k'}}\) (incorrect class) given by
If each activity class has J instances then by using Eq. (13), \(J\times K\) difference-feature vectors \(D_{jk}^{k'}\) have target \(T^+_{D_{jk}^{k'}}=1\) and \(J \times K\times (K-1)\) difference vectors have target \(T^-_{D_{jk}^{k'}}=-1\). The targets \(T^+_{D_{jk}^{k'}}\) are fewer than \(T^-_{D_{jk}^{k'}}\) by 1 : K, which represents an imbalanced problem. A learning method rankSVM by Chapelle and Keerthi (2010) is applied, because results of SVM remains stable and are least effected by the imbalance data. The training data comprises of \(D_{jk}^{k'}\) and their corresponding targets \(T_{D_{jk}^{k'}}\). RankSVM learns on the correct and incorrect differences and returns an R dimensional weight vector S given by
The score vector S is used to rank the obtained difference vectors in order of relevance.
3.3 Activity recognition
Let \(X_{tk^*}\) be the newly detected tth activity instance of an activity class \(A_{k^*}\), where \(k^*=1\dots K\) and the exact value of \(k^*\) is unknown. The objective is to discover the value of \(k^*\) in order to correctly recognize \(X_{tk^*}\). We extract the normalized feature set \(\hat{F}_{tk^*}\) using Eq. 2. \(\hat{F}_{tk^*}\) can have similarity with multiple activity classes with different degree of relevance. By using \(\varPhi\) from Eq. 5 and \(\varOmega\) from Eq. 7, K sets of key features \(\{\overline{F}_{tk}\}_{k=1}^K\) are extracted (Eq. 8) from the single feature set \(\hat{F}_{tk^*}\).
We find K difference vectors \(\{\delta _{tk}\}_{k=1}^K\) between mean feature sets \(\{M_k\}_{k=1}^K\) from Eq. 10, and obtained \(\{\overline{F}_{tk}\}_{k=1}^K\), given by
where \(\delta _{tk}\), represents the element wise difference between the mean \(M_k\) of activity class \(A_k\) and key features of \(A_k\) extracted from \(\hat{F}_{tk^*}\) of \(X_{tk^*}\). Next, we find the cross product \(P_{tk}\) between each difference vector \(\delta _{tk}\) and the weight vector S obtained from rankSVM given by
The score \(P_{tk}\), is the measure of similarity between \(X_{tk^*}\) and \(A_k\). The higher the value of \(P_{tk}\) the closer is \(X_{tk^*}\) to \(A_k\). For \(X_{tk^*}\), the set \(\{P_{tk}\}_{k=1}^K\) for K activities is obtained. Finally, \(X_{tk^*}\) is assigned to the activity class which gives the highest value of \(P_{tk}\) in \(\{P_{tk}\}_{k=1}^K\) given by
where \(L_t\) is the label of the recognized activity class, which is assigned to \(k^*\) such that \(k^*=L_t\).

The experimental setup
4 Experimental setup
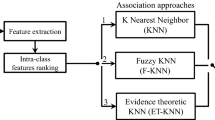
We analyze the performance of the proposed approach for the recognition of activities in smart homes, which can be occupied by patients with chronic disease, physical disability, cognitive impairment or elderly people living independently. The two contributions of this paper are the proposed key feature selection method (KFS) and a correct incorrect distance learning and ranking approach (CIDLR). We evaluate both contributions individually as well as combined. For this purpose, KFS is compared with existing feature selection methods most frequently used in activity recognition problems, i.e. minimum Redundancy Maximum Relevance (mRMR) (Peng et al. 2005) and Information Gain (IG) (Forman 2003; Dhirl et al. 2007). Since CIDLR is based on distance minimization and a learning model, we compare the proposed association approach with existing both learning and non-learning association approaches: Multi-class SVM (MSVM) (Rifkin and Klautau 2004) and Direct Distance Minimization (DDM), respectively. We also evaluate different combinations of feature selection and association methods. Figure 2 shows the flow diagram of the experiments using three feature selection methods combined with the three association approaches. In order to highlight the individual and combined performance, experiments are performed for all possible combinations of feature selection and association methods, which include a-1, a-2, a-3, b-1, b-2, b-3, c-1, c-2 and c-3.
4.1 Dataset selection
The performance of proposed activity recognition approach is investigated on common activities of daily life. The proposed approach focuses on improving the classification performance of the activities performed by a single resident within the smart home. It does not consider the concurrent activities of multiple residents, therefore selected datasets comprised of the activities performed by a single resident or multiple participants performed the same activities independently with high intra-class variations. The validation covers a wide range of activities performed in smart home including spatially overlapping activities sharing similar features and well separated activities.
Datasets used for the evaluation of proposed approach are from the smart home projects: Kasteren by Kasteren et al. (2008) and CASAS by Rashidi and Cook (2009). The Kasteren dataset is collected in a three room apartment for a period of 28 days using 14 state change sensors. It comprises of a total of 245 instances of eight activities. The activities include idle, leaving, toileting, showering, sleeping, breakfast, dinner and drink. The sensor information mapped to form the feature set includes sensor location, sensor activation, sensor deactivation and frequency of activation of a sensor. The CASAS dataset is gathered in a smart apartment comprising of three bedrooms, a bathroom, kitchen and a dining room. The apartment is equipped with motion sensors to detect the user location, analog sensors to get the reading of hot and cold water and a stove burner. The contact switch sensors are used to monitor the open/close status of doors and cabinets, pressure sensors are used to find the usage of key items such as phone book and medicine container. The voice over IP (VOIP) running Asterik software captures the phone usage. The dataset is composed of five activities: telephone use, hand washing, meal preparation, eating and medication and cleaning. The dataset comprises of a total of 120 instances. The sensor information used to form the feature set includes the user location, on/off status of water and burner, absent/present status of item sensors, open/close status of cabinet and sensor activation frequency.
4.2 Evaluation criteria
The performance of proposed approach is measured using the recognition accuracy, which represents the percentage of correctly recognized instances of activities out of the total detected instances of activities.
where \(t=1\dots Z\) and Z is the total number of detected activity instances. The function \(f_t(\cdot )\) can have a binary value. 1 is assigned if class label \(L_k\) is correctly assigned to \(X_{tk^*}\) and 0 otherwise.
We apply leave one out cross validation in which, the data of one day is used for testing while data of remaining days is used for training. The experiments are carried out using Matlab version 7.11 on a 3.3 Ghz dual core desktop system with 3 GB of RAM.
5 Analysis and discussion
Tables 1 and 2 summarize the results of our experiments on the two datasets Kasteren and CASAS, respectively. The proposed KFS is applied to MSVM, DDM and proposed CIDLR association methods. KFS is based on defining K subsets of features for K activity classes whereas the two other feature selection methods mRMR and IG returns a single subset of features from the existing feature set. In association, MSVM is a learning method which classifies a detected instance into the pre-learned activity classes. DDM measures the distances between the detected activity instance and the mean representations of pre-defined activity classes and ranks the activity class in order of minimum distance from the detected activity instance. L1-Norm is used as the distance measure in the DDM.
Table 1 shows the results on Kasteren dataset. When KFS is applied with the three association methods; CIDLR, MSVM and DDM, the highest activity recognition accuracy of \(84.24\%\), \(58.35\%\) and \(73.33\%\) is achieved, whereas, mRMR (\(54.47\%\), \(37.69\%\) and \(50.81\%\)) and IG (\(80.70\%\), \(41.01\%\) and \(68.41\%\)) selection methods achieved less accurate results than KFS. However, a comparatively higher accuracy is achieved by IG (\(80.70\%\)) and mRMR (\(54.47\%\)) when the proposed CIDLR method is applied for association. The highest recognition accuracy of \(84.24\%\) is achieved when KFS and CIDLR approach is combined. The proposed CIDLR method shows the best performance, when combined with the proposed KFS as shown in Tables 1 and 2. Moreover, it can also be observed from the results that the proposed CIDLR used with other feature selection method, such as IG and mRMR, also achieves better performance than the existing classification methods. The results of CIDLR as compared to DDM and MSVM shows combining learning with ranking is more suitable in smart home than classification or ranking alone.
Table 2 shows the experimental results obtained using CASAS dataset. In CASAS dataset, activities are spatially separated within the smart home with least overlapping features. Therefore the obtained results have a high accuracy. A less variation in the results ranging between 94% and 97.5% can be observed between proposed approach and existing methods. However, we are able to achieve the highest accuracy of 97.5%, when KFS is combined with CIDLR approach. While analyzing the KFS method with existing association approaches MSVM and DDM, we are able to achieve the accuracy of 94.26% and 95%, respectively. The achieved results of KFS are comparable to the other feature selection methods IG and mRMR. Similarly, the association method CIDLR achieves comparable or better results than MSVM and DDM for feature selection mRMR and IG.
We further analyze the performance of proposed approach (KFS and CIDLR) by accuracy breakdown for single activities. Table 3 shows the activity level analysis of Kasteren dataset using the proposed approach. The activities of leaving, toileting, showering, sleeping and drink show the recognition accuracy of above 90%. The idle activity is recognized with an accuracy of 81.82% and the errors of this activity are scattered in almost all activities because idle activity may not always have distinguishing features and therefore can be considered as a subpart of a major activity. The recognition errors for the activities are shared due to the overlapping features. For example the two activities, breakfast and dinner are performed in kitchen and share similar objects such as stove burner, kitchen faucets, cabinets and fridge. The activities of breakfast and dinner are recognized with an accuracy of 65% and 58.33% respectively. It can be observed, that breakfast activity is sharing its 20% errors with dinner and sending its 15% errors to the drink activity. Similarly, dinner activity is transferring its 33.33% errors to breakfast and 8.33% to idle activity. The sleeping activity is recognized with 91% accuracy, which shows that majority of its instances are correctly classified; however, its 2% instances are confused with showering, while 4% instances are incorrectly classified as toileting. It may be possible that the toilet is attached with the room, also in between the sleeping activity a toileting activity could occur, both of which result in segmentation error. Moreover, the occurrence of toileting and showering next in the sequence of performed activities could result in some overlapping features. Table 4 shows the recognition results of each activity for CASAS dataset. The activities of Telephone use, hand washing and meal preparation are recognized with 100% accuracy. Although in CASAS dataset there is less error in recognition rate; however, it can be observed that the activity of eating and medication showed an accuracy of 95% with error scattered in handwashing, which shows that sometimes handwashing may have been performed before eating and medication as part of the activity.
Figure 3 shows the comparison of accuracy breakdown of activities on Kasteren and CASAS datasets, when performance of the three association approaches CIDLR, MSVM and DDM is analyzed through the proposed KFS method, while the performance of the three feature selection methods KFS, mRMR and IG is analyzed on proposed association approach CIDLR. In CASAS dataset (Fig. 3c, d) because of a sufficient separability between the activities, the selected sets of feature obtained from all the selection methods were able to recognize activities with accuracy for all the association methods. However, in Kasteren dataset the difference in the results based on individual activity recognition rate is highlighted.

Accuracy breakdown of the activities in Kasteren (a, b) and CASAS (c, d) datasets. The performance comparison of three association approaches CIDLR, MSVM and DDM for KFS method on (a) Kasteren and (c) CASAS dataset. The performance comparison of three feature selection methods KFS, mRMR and IG for association approach CIDLR on (b) Kasteren and (d) CASAS dataset
In Fig. 3a, it can be observed that in Kasteren dataset, CIDLR and DDM association approaches show better performance in the kitchen activities which share similar features, whereas MSVM being a classification approach is not able to recognize the breakfast activity and shows less accuracy in the dinner and drink activities. Therefore, in such overlapping scenarios ranking approaches are more suitable than classification. Figure 3b shows that in case of mRMR, we can observe a high variation in the recognition accuracy of individual activities. The IG feature selection showed comparable results when the proposed association approach CIDLR is applied. The KFS results in the higher or comparable activity recognition rate and remain stable for each activity because KFS selects features for each activity class independent of other classes and therefore it is not biased towards a single activity with higher number of instances in the dataset.
The analysis of the results shows that the proposed KFS method enhances the performance of association approaches CIDLR, MSVM and DDM. It can be observed from the results that the classification approach (MSVM) is suitable for well separated activities, whereas ranking approach (DDM) is better to recognize similar activities such as breakfast, dinner and drink in the discussed dataset. The proposed association approach CIDLR exploits the properties of both classification and ranking approaches and therefore achieves a higher recognition accuracy and shows an overall stable performance.
6 Conclusion
The main focus of this research has been to enhance the accuracy of the activity recognition, which can be useful for remote functional assessment of elderly and people with chronic impairments living in smart homes. In the proposed approach, the key feature selection (KFS) method enables us to get the unbiased and discriminative features to represent each activity class, while the activity association approach CIDLR learns to rank the activities based on similarity from the newly detected instance. The combination of classification by learning with ranking results in a higher recognition rate with stable performance. The proposed activity recognition approach is compared with the existing feature selection (mRMR and IG) and association (MSVM and DDM) approaches. The results showed better recognition accuracy of up to 84.24% in Kasteren dataset and 97.5% in CASAS dataset. The proposed work currently focuses on improving the classification performance of the activities with high intra-class variations performed by a single resident within the smart home. In the future, we aim to extend our work to cover the inter-leaved concurrent activities performed simultaneously by multiple smart-home residents.
References
Alemdar H, Kasteren TV, Niessen M, Merentitis A, Ersoy C (2014) A unified model for human behavior modeling using a hierarchy with a variable number of states. In: Proceedings of IEEE international conference on pattern recognition, Stockholm, pp 3804–3809
Andre D, Wolf DL (2007) Recent advances in free-living physical activity monitoring: a review. J Diabetes Sci Technol 1(5):760–767
Atallah L, Yang GZ (2009) The use of pervasive sensing for behavior profiling—a survey. Pervasive Mob Comput 5(5):447–464
Avci U, Passerini A (2014) Improving activity recognition by segmental pattern mining. IEEE Trans Knowl Data Eng 26(4):889–902
Azkune G, Almeida A, de Ipia DL, Chen L (2015) Extending knowledge-driven activity models through data-driven learning techniques. Expert Syst Appl 42(6):3115–3128
Bao L, Intille SS (2004) Activity recognition from user-annotated acceleration data. In: Proceedings of international conference on pervasive computing, Vienna, pp 1–17
Bouwstra S, Chen W, Feijs LMG, Bambang-Oetomo S (2009) Smart jacket design for neonatal monitoring with wearable sensors. In: Proceedings of IEEE international workshop on wearable and implantable body sensor networks, California, pp 162–167
Chapelle O, Keerthi SS (2010) Efficient algorithms for ranking with SVMs. Inf Retr 13(3):201–215
Chen L, Hoey J, Chris N, Cook DJ, Yu Z (2010) Sensor-based activity recognition. IEEE Trans Syst Man Cybern Part C Appl Rev 42(6):790–808
Chen C, Das B, Cook DJ (2010) A data mining framework for activity recognition in smart environments. In: Proceedings of IEEE international conference on intelligent environments, Kuala Lumpur, pp 80–83
Chen L, Nugent C, Wang H (2012) A knowledge-driven approach to activity recognition in smart homes. IEEE Trans Knowl Data Eng 24(6):961–974
Chikhaoui B, Wang S, Pigot H (2012) Activity discovery and recognition by combining sequential patterns and latent dirichlet allocation. Pervasive Mob Comput 8(6):845–862
Chinellato E, Hogg DC, Cohn AG (2016) Feature space analysis for human activity recognition in smart environments. In: Proceedings of IEEE international conference on intelligent environments, London, pp 194–197
Danaei-mehr H, Polat H, Cetin A (2016) Resident activity recognition in smart homes by using artificial neural networks. In: Proceedings of IEEE international conference on smart grid congress and fair (ICSG), Istanbul
Dhirl CS, Iqbal N, Lee SY (2007) Efficient feature selection based on information gain criterion for face recognition. In: Proceedings of IEEE international conference on information acquisition, Seogwipo-si, pp 523–527
Ermes M, Parkka J, Mantyjarvi J, Korhonen I (2011) Detection of daily activities and sports with wearable sensors in controlled and uncontrolled conditions. IEEE Trans Inf Technol Biomed 12(1):20–26
Fahad LG, Tahir SF, Rajarajan M (2014) Activity recognition in smart homes using clustering based classification. In: Proceedings of IEEE international conference on pattern recognition, Stockholm, pp 1348–1353
Fahad LG, Ali A, Rajarajan M (2015a) Learning models for activity recognition in smart homes. In: Proceedings of international conference on information science and applications, Pattaya
Fahad LG, Khan A, Rajarajan M (2015b) Activity recognition in smart homes with self verification of assignments. Neurocomputing 149:1286–1298
Fahad LG, Tahir SF, Rajarajan M (2015c) Key features identification for activity recognition in smart homes. In: Proceedings of IEEE international conference on communications, London
Fang H, He L, Si H, Liu P, Xie X (2014) Human activity recognition based on feature selection in smart home using back-propagation algorithm. ISA Trans 53(5):1629–1638
Fleury A, Vacher M, Noury N (2010) Svm-based multimodal classification of activities of daily living in health smart homes: sensors, algorithms, and first experimental results. IEEE Trans Inf Technol Biomed 14(2):274–283
Forkan ARM, Khalil I, Tari Z, Foufou S, Bouras A (2015) A context-aware approach for long-term behavioural change detection and abnormality prediction in ambient assisted living. Pattern Recognit 48(3):628–641
Forman G (2003) An extensive empirical study of feature selection metrics for text classification. J Mach Learn Res 3:1289–1305
Garcia CG, Nunez-Valdez ER, Garcia-Diaz V, G-Bustelo BCP, Lovelle JMC (2018) A review of artificial intelligence in the internet of things. Int J Interact Multimed Artif Intell 4(3):7–10
Gu T, Wang L, Chen H, Tao X, Lu J (2011) Recognizing multiuser activities using wireless body sensor networks. IEEE Trans Mob Comput 10(11):1618–1631
Hoey J, Plotz T, Jackson D, Monk A, Pham C, Olivier P (2011) Rapid specification and automated generation of prompting systems to assist people with dementia. Pervasive Mob Comput 7(3):299–318
Hoque E, Stankovic J (2012) Aalo: activity recognition in smart homes using active learning in the presence of overlapped activities. In: Proceeding of IEEE international conference on pervasive computing technologies for healthcare, San Diego, pp 139–146
Huang PC, Lee SS, Kuo YH, Lee KR (2010) A flexible sequence alignment approach on pattern mining and matching for human activity recognition. Exp Syst Appl 37(1):298–306
Jalal A, Kamal S (2018) Improved behavior monitoring and classification using cues parameters extraction from camera array images. Int J Interact Multimed Artif Intell 5(7):1–8
Kasteren TV, Noulas A, Englebienne G, Krose B (2008) Accurate activity recognition in a home setting. In: Proceeding of international conference on ubiquitous computing, Seoul, pp 1–9
Kasteren TV, Englebienne G, Krose B (2011) Hierarchical activity recognition using automatically clustered actions. In: Proceedings of international conference on ambient intelligence, Amsterdam, pp 82–91
Kushwah A, Kumar S, Hegde RM (2015) Multi-sensor data fusion methods for indoor activity recognition using temporal evidence theory. Pervasive Mob Comput 21(1):19–29
Lu CH, Ho YC, Chen YH, Fu LC (2013) Hybrid user-assisted incremental model adaptation for activity recognition in a dynamic smart-home environment. IEEE Trans Hum Mach Syst 43(5):421–436
Lu L, Zhan L, Yi-Ju CQ (2017) Activity recognition in smart homes. Multimed Tools Appl 76(22):2420324220
Mckeever S, Ye J, Coyle L, Bleakley C, Dobson S (2010) Activity recognition using temporal evidence theory. J Ambient Intell Smart Environ 2(3):253–269
Mshali H, Lemlouma T, Magoni D (2018) Adaptive monitoring system for e-health smart homes. Pervasive Mob Comput 43:1–19
Nazerfard E, Das B, Holder LB, Cook DJ (2010) Conditional random fields for activity recognition in smart environments. In: Proceedings of ACM International Health Informatics Symposium, Washington, pp 282–286
Okeyo G, Chen L, Wang H (2014) Combining ontological and temporal formalisms for composite activity modeling and recognition in smart homes. Fut Gen Comput Syst 39:29–43
Ordonez FJ, Iglesias JA, de Toledo P, Ledezma A, Sanchis A (2013) Online activity recognition using evolving classifiers. Exp Syst Appl 40(4):1248–1255
Peng H, Long F, Ding C (2005) Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans Pattern Anal Mach Intell 27(8):1226–1238
Rashidi P, Cook DJ (2009) Keeping the resident in the loop: adapting the smart home to the user. IEEE Trans Syst Man Cybern Part A 39(5):949–959
Rashidi P, Cook DJ, Holder LB, Schmitter-Edgecombe M (2011) Discovering activities to recognize and track in a smart environment. IEEE Trans Knowl Data Eng 23(4):527–539
Rialle V, Duchene F, Noury N, Bajolle L, Demongeot J (2002) Health smart home: information technology for patients at home. Telemed J e-Health 8(4):395–409
Riboni D, Pareschi L, Radaelli L, Bettini C (2011) Is ontology-based activity recognition really effective? IEEE international workshops on pervasive computing and communications, Seattle, pp 427–431
Rieping K, Englebienne G, Krose B (2014) Behavior analysis of elderly using topic models. Pervasive Mob Comput 15:181–199
Rifkin RM, Klautau A (2004) In defense of one-vs-all classification. J Mach Learn Res 5:101–141
Sebbak F, Chibani A, Amirat Y, Mokhtari A, Benhammadi F (2013) An evidential fusion approach for activity recognition in ambient intelligence environments. Robot Auton Syst 61(11):1235–1245
Shin JH, Lee B, Park KS (2011) Detection of abnormal living patterns for elderly living alone using support vector data description. IEEE Trans Inf Technol Biomed 15(3):438–448
Singla G, Cook DJ, Schmitter-edgecombe M (2008) Incorporating temporal reasoning into activity recognition for smart home residents. In: Proceedings of the AAAI workshop on spatial and temporal reasoning, Chicago, pp 53–61
Sorensen S, Duberstein P, Gill D, Pinquart M (2006) Dementia care: mental health effects, intervention strategies, and clinical implications. Lancet Neurol 5(11):961–973
Stikic M, Larlus D, Ebert S, Schiele B (2011) Weakly supervised recognition of daily life activities with wearable sensors. IEEE Trans Pattern Anal Mach Intell 33(12):2521–2537
Tapia EM, Intille SS, Larson K (2004) Activity recognition in the home using simple and ubiquitous sensors. Pervasive Comput 3001:158–175
Tolstikov A, Hong X, Biswas J, Nugent C, Chen L, Parente G (2011) Comparison of fusion methods based on dst and dbn in human activity recognition. J Control Theory Appl 9(1):18–27
Wang Z, Jiang M, Hu Y, Li H (2011) An incremental learning method based on probabilistic neural networks and adjustable fuzzy clustering for human activity recognition by using wearable sensors. IEEE Trans Inf Technol Biomed 16(4):691–699
Zhang M, Sawchuk AA (2011) A feature selection-based framework for human activity recognition using wearable multimodal sensors. In: Proceedings of the international conference on body area networks, Beijing
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Tahir, S.F., Fahad, L.G. & Kifayat, K. Key feature identification for recognition of activities performed by a smart-home resident. J Ambient Intell Human Comput 11, 2105–2115 (2020). https://doi.org/10.1007/s12652-019-01236-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12652-019-01236-y