
Abstract
Recently, the recognition of emotions with electroencephalographic (EEG) signals has received increasing attention. Furthermore, the nonstationarity of brain has intensified the application of nonlinear methods. Nonetheless, metrics like quadratic sample entropy (QSE), amplitude-aware permutation entropy (AAPE) and permutation min-entropy (PME) have never been applied to discern between more than two emotions. Therefore, this study computes for the first time QSE, AAPE and PME for recognition of four groups of emotions. After preprocessing the EEG recordings, the three entropy metrics were computed. Then, a tenfold classification approach based on a sequential forward selection scheme and a support vector machine classifier was implemented. This procedure was applied in a multi-class scheme including the four groups of study simultaneously, and in a binary-class approach for discerning emotions two by two, regarding their levels of arousal and valence. For both schemes, QSE+AAPE and QSE+PME were combined. In both multi-class and binary-class schemes, the best results were obtained in frontal and parietal brain areas. Furthermore, in most of the cases channels from QSE and AAPE/PME were selected in the classification models, thus highlighting the complementarity between those different types of entropy indices and achieving global accuracy results higher than 90% in multi-class and binary-class schemes. The combination of regularity- and predictability-based entropy indices denoted a high degree of complementarity between those nonlinear methods. Finally, the relevance of frontal and parietal areas for recognition of emotions has revealed the essential role of those brain regions in emotional processes.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
In the last years, the increasing interest in affective computing (AC) has converted this area into one of the main research fields in the emotions-related scientific literature [37]. In a digital society in which the presence of human–machine interfaces (HMIs) is in constant expansion, AC has emerged with the aim of endowing those systems with emotional intelligence, making them able to identify and interpret human emotions, and decide which actions to execute accordingly. In other words, AC aims to improve and humanize the interaction and communication between people and machines by assigning human affective capabilities to lifeless systems [17]. In this regard, computers have to acquire emotional data, process the discretized information and provide an adequate response. For that purpose, emotion-aware computing creates affective computational models that can be used to establish emotional interactions between humans and machines. Hence, a proper acquisition and mathematical analysis of emotional information is crucial for the development of those computational models of affective information interpretation and humanized response generation.
With respect to the process of information capture, interest in the assessment of different physiological and biological features for emotions recognition has notably increased recently [12]. The reason is that emotions provoke a series of measurable and quantifiable physiological reactions that, unlike traditional methods of speech and facial gestures, cannot be feigned or hidden [46]. Among the wide number of physiological variables, one of the most studied is the electroencephalography (EEG), which represents the electrical activity generated in the brain due to neural connections. The increasing interest in this physiological variable for emotions recognition is based on the fact that the response against any stimulus is firstly generated in the brain and then spread to the peripheral variables by means of the central nervous system [13]. In this sense, measuring on the source of the emotional impulse reports more information than the secondary effects of brain activity in peripheral physiological systems [13]. The assessment of EEG signals has been traditionally developed from a linear point of view, mainly by means of algorithms based on frequency features like the power spectral density or the asymmetry between brain hemispheres in different frequency bands [28]. However, it is widely known that the brain dynamics follow a completely nonlinear and nonstationary behavior regulated by threshold and saturation phenomena at both cellular and global levels [8]. Hence, the information reported by linear metrics may present some limitations and would not completely describe the brain’s performance [47]. As a result, the application of nonlinear metrics is a suitable method for discovering hidden information about the brain’s performance under different conditions. In fact, nonlinear techniques have already demonstrated their capability to discover new observations that outperform those reported by linear metrics [1].

Emotional model of valence and arousal proposed by Russell
Recently, nonlinear indices have been widely used in emotions recognition research field. In this sense, nonlinear metrics are computed to check their capability to discern between various emotional states. In many works, it is done following the bidimensional model of emotions proposed by Russell [41]. This model distributes all emotional states according to two dimensions, namely valence (pleasantness or unpleasantness of a stimulus) and arousal (activation or deactivation that a stimulus provokes). As can be observed in Fig. 1, Russell’s model can be divided into four quadrants: high arousal/high valence (HAHV), high arousal/low valence (HALV), low arousal/high valence (LAHV) and low arousal/low valence (LALV). This configuration has been selected in diverse studies in which the four quadrants have been assessed and discerned by means of a wide number of nonlinear metrics. For instance, fractal dimension, approximate entropy and spectral entropy were computed to recognize those groups of emotions, obtaining better results with the entropy-based metrics [18]. More recently, the calculation of multiscale sample entropy, fuzzy entropy and Rényi entropy provided relevant differences between the four quadrants at frontal and temporal brain regions [14]. Similar results were obtained with the application of correlation dimension, Lyapunov exponents, recurrent plots and Shannon entropy in another study [43].
In the same line, our research group has demonstrated in last years that certain entropy-based methodologies are able to correctly reveal underlying brain processes in calm and distress conditions [16, 34]. More concretely, those indices are the regularity-based quadratic sample entropy (QSE), symbolic entropies amplitude-aware permutation entropy (AAPE) and permutation min-entropy (PME). Those entropy metrics reported valuable results when discerning between calm and distress, even outperforming results reported by other nonlinear metrics applied to the same problem [16, 34]. Nevertheless, to the best of our knowledge those metrics have never been tested in a higher number of emotional states. Hence, the aim of this study is to verify the efficiency of those indices when detecting an enlarged number of emotions. For that purpose, this is the first time nonlinear entropy metrics QSE, AAPE and PME are computed to discriminate between the four quadrants of the emotional model of valence and arousal.
In this work, a multi-class scheme is firstly proposed in order to discern among the four groups of study simultaneously. In addition, a binary-class analysis is developed to detect different levels of arousal and valence separately. Although the recognition of these dimensions has been studied in many cases, it is important to note that, as far as we know, this is the first time in which valence and arousal are detected taking into account the level of the other dimension. Hence, in binary-class schemes the four emotional states are discerned two by two, according to their levels of valence and arousal, and considering if the counterpart dimension presents a fixed high or low level. Finally, note that both multi-class and binary-class analyses have been designed with the aim of thoroughly evaluating the role and the relationship of each brain region and each nonlinear metric under the different emotional conditions.
The structure of this manuscript is as follows. Section 2 presents a description of the database employed, together with an explanation of the preprocessing procedure, mathematical definition of entropy metrics and statistical analyses and classification process followed. After that, results obtained are presented in Section 3 and discussed in Section 4. Finally, conclusions derived from this study are depicted in Section 5.
Materials and Methods
Database Description
In order to guarantee the reproducibility of this work, and for a posterior comparison with other studies, EEG recordings were obtained from the publicly available Database for Emotion Analysis using Physiological Signals (DEAP) [30]. This dataset was created during an emotional experiment in which a total of 32 healthy volunteers with ages between 19 and 37 (mean age 26.9, 50% male) visualized a series of videoclips with emotional content. More concretely, a total of forty videos of 1 minute length were shown to each participant while EEG and other physiological variables were being recorded. After each visualization, individuals rated their levels of valence and arousal by means of self-assessment manikins (SAM), in which nine intensity levels of each dimension are represented graphically. Finally, the complete dataset contains 1280 samples of emotions covering the whole valence–arousal model.
However, not all samples were assessed in this work. In this sense, samples were selected and included in the four groups of study according to the following criteria: HAHV group (samples with arousal and valence \(\ge\)6), HALV (arousal \(\ge\)6 and valence \(\le\)4), LAHV (arousal \(\le\)4 and valence \(\ge\)6), LALV (arousal and valence \(\le\)4). These values were chosen in order to discard samples that were on the borderline between two quadrants; thus, only trials in which the desired emotion was strongly elicited were included in our dataset. Hence, the number of samples in each group was 267 in HAHV, 101 in HALV, 154 in LAHV and 124 in LALV. It is important to remark that, as in previous studies, only the last 30 seconds of each trial were finally analyzed [30].
Preprocessing of EEG Recordings
EEG signals were acquired with 32 electrodes placed on the scalp according to the international standard 10-20 system of electrodes positioning [29] at a sample frequency of 512 Hz. Before computing the different entropy measures, signals were preprocessed in EEGLAB, a MATLAB toolbox specifically designed for processing and assessment of EEG recordings [11]. The first preprocessing step was downsampling to 128 Hz and referencing to the mean of all electrodes. Then, two forward/backward filtering approaches, high pass at 3 Hz cutoff frequency and low pass at 45 Hz cutoff frequency, were applied to maintain the bands of interest of the EEG spectrum [22]. In addition, as those filters removed baseline and power line interferences, no further actions were needed in this sense. After that, it was necessary to eliminate noise and interferences produced by different sources that could not be canceled in previous preprocessing steps. Concretely, artifacts can be generated by physiological reasons such as eye blinks, heart bumps or facial movements, among others. On the other hand, technical sources such as electrode pops or bad contacts of the electrodes on the scalp can also introduce artifacts in the EEG recordings. As a solution, a blind source separation technique called independent component analysis (ICA) was applied to compute and discard the independent components that were related to artifacts in the EEG signals. Finally, channels containing high-amplitude noise were rejected and reconstructed by interpolation of adjacent electrodes [36].
Entropy metrics
Quadratic Sample Entropy
Quadratic sample entropy (QSE), an improvement of sample entropy (SE), evaluates a time series searching for similar patterns and assigning a nonnegative number to the epoch, using larger values to represent a higher level of irregularity in the signal [32]. This metric represents the probability that two sequences that match for m points also remain similar for m+1 points, being m the window length, at a tolerance r.
Given a time series of length N, \(x(n)=\{x(1),x(2),\ldots ,x(N)\}\), the repetitiveness between vectors \(\mathbf {X}_m(i)=\{x(i),x(i+1)\ldots ,x(i+m-1)\}\) and \(\mathbf {X}_m(j)=\{x(j),x(j+1)\ldots ,x(j+m-1)\}\) is computed through the maximum absolute distance between scalar components:
Then, \(\mathbf {X}_m(i)\) and \(\mathbf {X}_m(j)\) match if distance d is lower than the tolerance r. After that, \(B_i^m(r)\) is calculated as \((N-m-1)^{-1}\) times the number of vectors similar to \(\mathbf {X}_m(i)\), excluding self-matches. After evaluating all vectors of length m, \(B^m(r)\) is computed as the average share of all sequences:
Once this process is repeated for patterns of length \(m+1\), QSE is finally computed as
Amplitude-Aware Permutation Entropy
Amplitude-aware permutation entropy (AAPE) was recently introduced as an improvement of permutation entropy (PE) [3, 5]. This fast metric basically converts the original data into a sequence of symbols with no prior knowledge and evaluates the repetitiveness of ordinal patterns [5]. In this sense, it gives information about the data time structure of the original series with robustness against observational and dynamical noises, thus measuring the degree of predictability of the signal [5].
For computation of PE, the original time series \(x(n)=\{x(1),x(2),\ldots ,x(N)\}\) of length N is transformed into \(N-m+1\) sequences of length m, thus \(\mathbf {X}_m(i)=\{x(i),x(i+1)\ldots ,x(i+m-1)\}\), for \(1\le i \le N-m+1\). The association of each vector \(\mathbf {X}_m(i)\) with an ordinal pattern is defined as the permutation \(\kappa _i = \{r_0,r_1,\ldots ,r_{m-1}\}\) of \(\{0,1,\ldots , m-1\}\) such that \(x(i+r_0) \le x(i+r_1) \le \ldots \le x(i+r_{m-2}) \le x(i+r_{m-1})\). Consequently, vectors \(\mathbf {X}_m\) report a total of m! ordinal patterns \(\pi _k\). After that, their probability of appearance is calculated by means of the relative frequency of each sequence \(\pi _k\):
where \(\delta (u,v)\) represents the variation of the Kronecker delta function to work with patterns:
Finally, PE is obtained as the Shannon entropy of the distribution of probability for all symbols:
The normalization by \(\ln (m!)\) is made to limit PE values between 0 and 1. Hence, a value of 0 corresponds to a completely predictable time series, in which only a pattern \(\pi _k\) can be found. Contrarily, the highest value of 1 is assigned to unpredictable signals where symbols \(\pi _k\) have the same probability of occurrence. However, this metric only contemplates the ordinal structure of sequences to measure the predictability of a signal. Therefore, data related to the amplitude of samples, which might be crucial for predictability estimation, are not considered. As a solution, AAPE was introduced with the aim of solving this limitation [3]. AAPE computes the probability of occurrence of each sequence \(\pi _k\) considering its relative frequency, and also two amplitude-related parameters of vectors \(\mathbf {X}_m\), called average absolute (AA) and relative amplitudes (RA):
The relative frequency of \(\pi _k\) is then obtained as follows:
where K is an adjusting coefficient of AA and RA with a value between 0 and 1 (the recommendation of authors is \(K=0.5\) [3]). AAPE is finally computed making use of the Shannon entropy:
Permutation Min-Entropy
Latterly, a generalization of PE called Rényi permutation entropy (RPE) has been presented [51]. It is based on replacing Shannon entropy by Rényi entropy for a better characterization of rare and frequent ordinal patterns and is defined as [51]:
being order q a bias parameter. In fact, values must range between \(q\ge 0\) and \(q<1\) to enhance rare events. On the contrary, \(q>1\) benefits salient ones. It is important to remark that Shannon entropy is a particular case of Rényi entropy for \(q=1\), which makes RPE a more flexible index than PE. Indeed, RPE has already reported a very complete characterization of different complex dynamics such as physiological signals [25]. In the limit \(q \rightarrow \infty\), RPE converges to the permutation min-entropy (PME). Similarly to PE, this metric is fast, simple and robust to noise and has also demonstrated its suitability for discovering underlying temporal structures in EEG [52]. PME is computed as
Statistical Analysis and Experimental Procedure
For the computation of each entropy metric, 30-seconds preprocessed signals were divided into six nonoverlapped equally sized segments of 5 seconds length (\(N=3840\) samples). The final value of each entropy index was then calculated as the average of all segments. Selection of correct values of input parameters is critical for entropy computation. In this sense, our research group has previously applied the metrics aforementioned for calm and distress recognition; thus, the influence of the selection of these parameters on the final results has already been tested [16, 34]. For this reason, in the present study we used the values recommended in previous works, i.e., \(m=2\) and \(r=0.25\) times the standard deviation of the data for QSE calculation, and \(m=6\) for AAPE and PME computation.
Two different types of analyses were performed in this work. The first one was a multi-class approach in which the four groups of study (HAHV, HALV, LAHV and LALV) were analyzed simultaneously. The normality and homoscedasticity of the entropies distribution were corroborated by means of Shapiro–Wilks and Levene tests, respectively. After that, a one-way analysis of variance (ANOVA) was applied to quantify the statistical significance of each metric at each EEG channel when discerning among emotional states in the four quadrants. In this sense, only values of statistical significance \(\rho <0.05\) were considered as significant.
The second type of analysis followed a binary-class scheme in which regularity- and predictability-based entropy metrics were combined to detect emotional groups two by two. Hence, it was possible to discover which metrics and which brain regions were more relevant when discerning between different levels of arousal and valence separately. It is important to remark that two evaluations were prepared for each dimension of the emotional model. When discerning between high and low levels of valence, samples chosen presented a fixed value of arousal, being it high for the first test, called HAXV, and low for the second test, namely LAXV. Similarly, detection of different levels of arousal was performed with two tests in which valence had a fixed level, high (XAHV) and low (XALV), respectively. Then, a total of four binary-class schemes were computed, two for arousal detection with fixed valence, HAXV and LAXV, and two for valence recognition with fixed arousal, XAHV and XALV. More clearly, the emotional quadrants included in each binary-class scheme were the following: HAXV (HAHV vs. HALV); LAXV (LAHV vs. LALV); XAHV (HAHV vs. LAHV); and XALV (HALV vs. LALV).
Finally, it is worth noting that the combination of QSE+AAPE and QSE+PME metrics were tested to assess the classification performance for both experimental approaches. The combination of AAPE and PME was not considered given the mathematical similarities of these two entropy metrics.
Classification Approach
A similar classification approach was conducted for multi-class and binary-class experiments described in Section 2.4. To prevent overfitting of the classification models, samples were firstly rearranged under a K-fold cross-validation scheme. Thus, for each experiment, a tenfold cross-validation approach was used, where data were randomly rearranged to ensure that every fold was sufficiently representative of the whole [24]. Then, a sequential forward selection (SFS) approach was applied to sequentially select the subset of EEG channels that minimize the misclassification rate in each fold, using a support vector machine (SVM) model as criterion.
With this respect, SVM discriminates data from different categories by finding the decision boundary, or hyperplane, that best discerns between them. Therefore, SVM turns classification into an optimization problem, where the best hyperplane is the one providing the largest margin between categories [6]. Usually, a kernel function is used to provide dissociation between categories in a higher dimension, especially when data are not linearly separable. In this work, a Gaussian kernel with scale 0.35 and box constraint parameter of 1 was used to classify the data. Thus, for each fold, entropy metrics from chosen EEG channels were used as inputs for training the SVM classification model. Then, test data were introduced in the resulting model and different performance metrics were evaluated.
The efficiency of the SVM model constructed in each iteration was assessed in terms of detected true positive (TP), true negative (TN), false positive (FP) and false negative (FN) cases. Concisely, TP and TN correspond to true and false labelled samples correctly classified, respectively. On the other hand, FP are the false labelled samples incorrectly classified as true class and FN correspond to true labelled samples incorrectly classified as false label samples. Then, performance indices like precision (P), recall (R), accuracy (Acc) and F-score (F) were computed. Equation 13 shows the mathematical calculation of precision, also known as positive predictive value, which informs about the probability of successfully making a correct positive classification:
Additionally, equation 14 shows the computation of recall, informing about how sensitive the model is towards identifying the positive class:
Furthermore, accuracy is a global performance metric that measures all the correctly identified cases, considering all of them equally important, as it can be appreciated at equation 15:
However, given the existing sample imbalance among groups, F-score can report a measure of global accuracy more precise than Acc to evaluate the models, using P and R to compute the final score, as can be appreciated at equation 16:
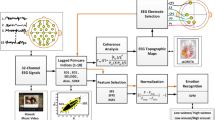
Finally, for the sake of clarity of the methodological procedure followed in the present work, Fig. 2 shows a flowchart with details of the process followed for the recognition of the four quadrants in the emotional space. It is important to highlight that the first node in section “Description of experiments” is marked with (**). This indicates the moment in which the type of analysis, multi-class or binary-class, is chosen. The following steps after this node are similar in both cases.

Flowchart of the methodological procedure followed in this work
Results
Individual Results of Each Metric
First of all, the discriminatory power of each entropy metric was tested separately. In the case of QSE, almost all EEG channels (29 out of 32) distributed among all brain regions of both hemispheres were statistically significant. Hence, QSE is able to properly discern between the four groups of emotions in the majority of brain areas. However, the most statistically significant channels were located in parietal and frontal regions of both brain hemispheres. Those channels were CP2 (\(\rho\)=5.55\(\, \times \, 10^{-6}\)), P4 (\(\rho\)=8.79\(\, \times \, 10^{-6}\)), PO4 (\(\rho\)=2.67\(\, \times \, 10^{-5}\)), Fz (\(\rho\)=2.95\(\, \times \, 10^{-5}\)), AF4 (\(\rho\)=4.63\(\, \times \, 10^{-5}\)), Fp1 (\(\rho\)=5.74\(\, \times \, 10^{-5}\)), AF3 (\(\rho\)=6.24\(\, \times \, 10^{-5}\)) and P3 (\(\rho\)=6.77\(\, \times \, 10^{-5}\)).
In terms of activation or deactivation of brain areas, Fig. 3 shows the mean value of QSE for each channel and each emotional quadrant. As can be observed, higher values of QSE are concentrated in anterior and posterior areas, being central region the less active in all the cases. Concretely, the highest QSE values can be found in left frontal and temporal areas, and in right fronto-central, parietal and occipital regions, thus representing a strongly irregular activity in those regions. It can also be seen that QSE mean level is slightly higher for HALV and LAHV than for HAHV and LALV in all brain areas, being especially notable in right fronto-central and parietal locations. In other words, brain activity is more irregular when experiencing emotions like anger or calm (in HALV and LAHV groups, respectively) than when experiencing happiness or sadness (in HAHV and LALV, respectively).

Representation of mean levels of QSE for all EEG channels in four quadrants of emotional space
With respect to AAPE and PME, results were not as relevant as with QSE. In the case of AAPE, only 3 out of 32 channels, all of them in parietal lobe, were statistically significant. These channels were CP6 (\(\rho\)=0.0045), P4 (\(\rho\)=0.0221) and Pz (\(\rho\)=0.0453). In a similar manner, PME only presented 5 out of 32 statistically significant channels, located in left frontal and right parietal areas. Concretely, these channels were AF3 (\(\rho\)=0.0112), Fp1 (\(\rho\)=0.0257), P4 (\(\rho\)=0.0337), C4 (\(\rho\)=0.0416) and Fz (\(\rho\)=0.0489). Hence, only a few channels from right parietal lobe were able to detect the four emotional quadrants with AAPE and PME. In the latter case, two channels in left frontal lobe were also able to discern between the four groups of study. Furthermore, Fig. 4 presents the mean levels of AAPE and PME for each channel and each emotional state. In this case, both metrics reported similar results referring to the brain regions that present a higher degree of unpredictability, being them left frontal and temporal, and right fronto-central brain areas. Moreover, in both cases there seems to be a slightly higher level of AAPE and PME in HAHV and LALV with respect to HALV and LAHV, which represents a higher predictability of brain dynamics under emotions contained in the last two groups of study.

Representation of mean levels of (a) AAPE and (b) PME for all EEG channels in four quadrants of emotional space
Multiparametric Multi-Class Scheme
The number of channels selected in each of 10 iterations of the SFS approach ranged from 4 to 10 in the case of QSE+AAPE and from 5 to 10 in the case of QSE+PME. For more details, Fig. 5 shows the occurrence rate of the most relevant features for each combination of metrics. As can be observed, most of the selected channels are located in frontal and parietal brain lobes of both hemispheres, in accordance with the results reported by previous ANOVA analyses in which those areas presented the highest statistical significance. Furthermore, it is interesting to remark that highlighted channels of AAPE and PME were selected more times than the most relevant of QSE. Concretely, the channels with maximum occurrence rate for AAPE and PME were selected the 90% of iterations, whereas only a 40% was achieved by QSE channels. In this sense, those channels from AAPE and PME were more relevant for the improvement of performance of the multi-class classification model; hence, they were selected more frequently than channels from QSE. In addition, it can be observed in Fig. 5 that some selected channels from AAPE and PME did not present statistically significant results in ANOVA analysis. However, they were able to explain some cases that other channels could not interpret; therefore, their inclusion in the classification models notably increased the final performance.
After all the classification process, global results obtained are those presented in Table 1. The average accuracy after the ten iterations of the classification process was 93.75% for QSE+AAPE and 96.39% for QSE+PME. Furthermore, in both cases the best precision results were provided by the HALV group (98.76% and 99.74% for QSE+AAPE and QSE+PME, respectively), whereas HAHV group reported the lowest precision outcomes (91.21% and 94.63% for QSE+AAPE and QSE+PME, respectively). On the contrary, recall results from the emotional group of HAHV presented the highest values (98.76% for QSE+AAPE and 99.36% for QSE+PME), whereas the group of HALV was the one with the lowest levels, with a difference of 10-12% with respect to the highest values (87.03% for QSE+AAPE and 89.90% for QSE+PME). Similarly, F-score results were the highest for HAHV group (94.67% for QSE+AAPE and 96.86% for QSE+PME) and the lowest for HALV (92.04% for QSE+AAPE and 94.33% for QSE+PME). Note that Acc and F-score results present similar values; therefore, the unbalanced number of samples among the four groups of study does not affect the classification outcomes. As can be observed, in all the cases the results obtained with the combination of QSE+PME were better than those reported by the combination of QSE+AAPE.

Representation of the occurrence rate of the most selected channels in SFS scheme for each combination of metrics
Multiparametric Binary-Class Scheme
In each case, the SFS approach was computed as in multi-class procedure. The most selected brain regions for each metric are shown in Fig. 6. In the case of different levels of valence with a fixed level of arousal, it can be observed that the posterior half of the brain plays an important role in both QSE+AAPE and QSE+PME for detection of valence variations, since this area is the most selected by the SFS for the three entropy metrics. Furthermore, if arousal level is fixed as high, anterior half of QSE also notably presents relevant information in both combinations of indices. In addition, it should be noted that channels from QSE were selected more times (marked with ** in figure) than those from AAPE and PME in SFS schemes of both combinations.
On the contrary, results for different levels of arousal with a fixed valence are not as consistent. In the case of QSE+AAPE, it can be observed that, for QSE, both anterior and posterior halves of the brain are relevant for detection of different levels of arousal. On the other hand, only the left central area is relevant for AAPE. In the case of QSE+PME, posterior areas are always the most relevant with QSE, while for PME it depends on the fixed level of valence. Hence, anterior region is more chosen with high valence and posterior locations are more selected with a fixed low valence. Besides, it is important to highlight that QSE channels are more selected than AAPE in the combination QSE+AAPE (marked with **). In this respect, QSE provides a higher improvement of the classification accuracy than AAPE for recognition of different levels of the two emotional dimensions. On the contrary, in the case of QSE+PME, QSE was more selected for detection of variable valence (marked with **), whereas PME was chosen more times for variable arousal identification (marked with **). Thus, QSE is more relevant for variable valence detection, whereas PME improves the model more than QSE for arousal classification.

Representation of the most selected brain regions in SFS approach for binary-class schemes. Most selected metrics are marked with **
Table 2 shows results of accuracy, precision, recall and F-score in each case. In line with the results obtained in the multi-class analysis, values of all parameters reported by the combination of QSE+PME were slightly higher than those of QSE+AAPE in the three first schemes (HAXV, LAXV and XAHV). Contrarily, the opposite was obtained for XALV, where the combination of QSE+AAPE outperformed the results provided by QSE+PME. Furthermore, in the combination of QSE+PME, the schemes of distinction between high and low levels of one dimension presented better results when the other dimension was low. Concretely, when discerning between high and low valence, a fixed low arousal (LAXV) reported better results than a fixed high arousal (HAXV). For the combination of QSE+PME, the detection of different levels of valence (HAXV and LAXV) provided better classification outcomes than the recognition of different levels of arousal (XAHV and XALV). Additionally, valence detection was better with a fixed low arousal (LAXV), while arousal distinction provided better results with a fixed high valence (XAHV). Another important aspect is that, in some of the schemes, the unbalanced number of samples among the four quadrants provides notable differences between Acc and F-score results. Concretely, binary schemes in which the group HAHV is included (HAXV and XAHV) present the highest contrast between Acc and F-score outcomes, given the considerable variation in the number of samples in that group with respect to the others.
Discussion
Recently, research in automatic recognition of emotions with EEG recordings and nonlinear metrics has been intensified notably. Concretely, different nonlinear indices for measurement of fractal fluctuations, irregularity, or chaos degree, among others, have been applied to emotions detection with EEG signals obtaining different results. Previous studies have mainly focused on the identification of calm and distress with various entropy metrics such as QSE, AAPE and PME [16, 34]. Given the relevant results reported by these metrics for the detection of two emotions, the next step would be to test their efficiency when discerning among a higher number of emotional states. To the best of our knowledge, this is the first time these nonlinear measures have been computed for detection of the four quadrants in the emotional space with EEG signals. The valuable outcomes presented in the previous section corroborate this hypothesis, thus demonstrating the suitability of these metrics for the detection of emotions with EEG recordings.
In addition, some characteristics of the analysis merit consideration. The binary-class schemes in this study present a main difference with respect to other works also dealing with valence and arousal detection. The distinction between high and low levels of one dimension has been usually done without taking into account the level of the other dimension. For instance, the recognition of samples with high or low arousal is done without considering if the level of valence of those samples is also high or low. It is known that both emotional dimensions are interrelated; hence, each one has a notable influence over the other [31]. For this reason, the distinction between high and low arousal could not be the same depending on the level of valence. In other words, the brain would not present the same differences between high and low levels of one dimension when experiencing either high or low levels of the other dimension. Hence, this is the first time this consideration is taken into account by means of a binary-class assessment in which the distinction between high and low levels of one dimension is made having a fixed level of the other dimension, being it either high or low.
Relevant Brain Regions
For both multi-class and binary-class approaches, the most relevant outcomes were obtained in frontal and parietal areas for the three entropy metrics computed in this study, converting those regions into the most important areas for the recognition of the four groups of emotions. In addition, frontal and parietal electrodes in both hemispheres also reported the highest occurrence rates in the SFS approaches, thus demonstrating the notable contribution of these channels to the final classification models. Interestingly, the relevance of frontal and parietal brain areas for emotions detection has already been depicted in previous studies. For instance, these regions reported more information than the rest of the brain when detecting emotions in patients with disorder of consciousness [20]. Frontal and parietal areas have also reported valuable results of emotional processes in children with autism [38]. In another study, anterior and posterior regions showed most of the information when discerning between four emotional states [43]. Furthermore, previous works recently published by our research group have also demonstrated the implication of frontal and parietal lobes in emotional scenarios [15, 16, 33, 34].
The importance of frontal and parietal brain regions for emotions processing is reinforced by a possible relation between these areas in opposite hemispheres. Indeed, a previous study revealed the possible existence of anatomical cortico-cortical connections between those areas [35]. Later, another study proved that activation of left frontal locations is accompanied with a relative right parietal activation and vice-versa [10]. More recently, similar results were obtained with patients of various mental disorders during meditation sessions [40]. A strong degree of complementarity between both hemispheres has also been described, especially in parietal lobe. In this sense, previous studies have revealed complementary processes between left and right parietal regions under different emotional situations [9, 42]. Furthermore, our previous studies have also demonstrated complementarity of results in parietal lobes of both hemispheres with regularity-based and predictability-based entropy metrics during distress detection [16]. In fact, the assessment of parietal brain areas is essential for emotions recognition because of being related to both dimensions of emotions, valence and arousal [2].
Performance of Metrics
With respect to the performance of each entropy metric separately, almost all channels were statistically significant in the case of QSE, which represents the capability of QSE to discern between the four groups of emotions in the majority of brain areas. On the other hand, only three and five channels presented significant results with AAPE and PME, respectively, thus reporting a lower performance of those metrics with respect to QSE. The variability of results could be a consequence of the mathematical differences of the indices. Hence, QSE evaluates the degree of regularity of a time series by searching for similar patterns along the signal and assessing their repetitiveness [39]. On the other hand, AAPE and PME are based on the transformation of nonstationary signals into sequences of symbols for a posterior evaluation of their predictability [3, 52]. As regularity-based and predictability-based entropies appraise nonlinearity from different points of view, there could be differences in the relevance of the outcomes. However, results could be considered as complementary and thus the combination of these two types of entropy metrics may reveal new information not discovered with them separately. This hypothesis has been already corroborated in a study in which regularity- and predictability-based entropy metrics were successfully combined to discern between healthy subjects, epilepsy patients in a rest state and epilepsy patients during a seizure [27].
For this reason, QSE+AAPE and QSE+PME were combined with the aim of improving the outcomes reported by each index separately when discerning between the four groups of emotions. It is important to remark that AAPE and PME follow analogous approaches for predictability assessment; thus, their combination would not lead to a notable enhancement of their performance. In both multi-class and binary-class models, the complementarity of regularity- and predictability-based entropy indices has been demonstrated in different aspects. First of all, both types of metrics have been selected in the majority of the cases in which they have been combined, thus reinforcing the idea of complementarity between the two types of entropy metrics. The only circumstance in which they were not complementary was for binary-class QSE+AAPE combination for variable valence and low arousal, given that almost any channel from AAPE was selected by the SFS model, and only channels from QSE were chosen. With respect to binary-class approaches, the complementarity of both groups of indices is also justified by the fact that different metrics select different brain areas, so one region is just relevant with one type of entropy, but not for both of them. This also reinforces the complementarity between different brain regions already commented on in this manuscript. In this sense, it is interesting to note that QSE presented more relevant brain regions than AAPE and PME in SFS approaches applied in binary-class schemes, as shown in Fig. 6. This fact is also in accordance with results of ANOVA analyses, in which QSE proved to be able to discern between the four groups of emotions in all brain areas, whereas only a few areas from AAPE and PME presented statistically significant results reflecting their capability to detect those emotions.
In the multi-class scheme, the SVM classifier implemented in this study reported accuracy results of 93.75% for the combination of QSE+AAPE. In the case of QSE+PME, 96.39% of accuracy was obtained. In this sense, the combination of QSE+PME seems more suitable for the recognition of the four emotional groups simultaneously. Results of precision, recall and F-score were also better for QSE+PME than for QSE+AAPE. In the same manner, outcomes derived from binary-class combinations also presented values higher for QSE+PME than for QSE+AAPE, thus suggesting a stronger ability to detect different levels of arousal and valence. Likewise, PME also presented moderately better results than AAPE when ANOVA analysis was applied to each metric separately. Concretely, more EEG channels presented statistically significant results with PME than with AAPE. The reason is that, although both indices are improvements of permutation entropy, there is a crucial difference in their mathematical definition. AAPE is computed by means of Shannon entropy, while PME is based on Rényi entropy for its calculation. Moreover, it has been demonstrated that intricate temporal correlations can be successfully discriminated by estimating the PME [52]. Such a particular ability to unveil the presence of hidden temporal structure could be the source of the higher classification performance.
Computational Complexity and Convergence of Metrics
The computational complexity, or efficiency of the entropy metrics is one of their most important properties that should be considered. In this sense, a previous study has already compared the computational times of SE and PE, among other indices [27]. Precisely, these are the mathematical basis of QSE and AAPE/PME, respectively; therefore, no notable differences would be found between the computational time of SE and PE and the computational time of the metrics estimated in the present work. In the aforementioned study, the computational time of entropies in relation to the length N of the time series was quantified. It was demonstrated that entropy metrics based on ordinal patterns, such as PE, AAPE and PME, present an order O(N), whereas SE and its variants, like QSE, present an order \(O\left( N^\frac{3}{2}\Bigr )\right)\). In this sense, indices based on ordinal patterns are more appropriate for the assessment of great amounts of data in real time. Indeed, the advantages of permutation entropy and its variations in terms of computational complexity have been considered as one of the main strengths of these entropy indices [8]. However, it is important to highlight that given the short duration of EEG recordings analyzed, the differences in terms of computational time of QSE, AAPE and PME are minimal or not-existent.
Another important aspect of the metrics is their convergence, which evaluates if the estimated metrics converge to a determined value considering the length of the time series. It should be noted that the duration of the time series assessed in this work is not sufficiently long to guarantee the convergence in the estimations of the quantifiers computed. Nevertheless, the same length of data is analyzed in all the cases; thus, the effects of the finite size would affect all indices equally. Therefore, the comparison among estimated values in relation to that data length can be considered as robust, and the observation of significant differences in the estimations is directly referable to real changes in the underlying nonlinear dynamics.
Comparison with Other Studies
With respect to the scientific literature, Table 3 shows a number of works in which other nonlinear methods have been applied for recognition of four quadrants of the emotional model with the same database. Therefore, it is possible to directly compare the results obtained in the present study with those reported by other researches. As can be observed, outcomes presented in this manuscript are comparable to other works published so far, thus demonstrating the considerable suitability of QSE, AAPE and PME for emotions detection. Moreover, it is interesting to remark that most of the aforementioned works only focus on the blind combination of a wide number of features in advanced classifiers, without considering the possibility of giving a clinical interpretation of the results. On the contrary, in the present study an SFS approach was implemented to select the most relevant EEG channels and thus reduce the number of input features in the classification models. Hence, it is possible to interpret the results from a clinical point of view, thus discovering which brain areas are the most significant in emotional processes. Furthermore, the degree of contribution of each metric and each brain region in both multi-class and binary-class schemes has also been thoroughly examined with the aim of dealing with emotions recognition from a novel perspective. Indeed, binary-class evaluation has allowed to better understand the relevance of metrics and brain locations in emotional processes by distinguishing between the main dimensions of emotions, which are valence and arousal.
Limitations and Future Lines
Finally, there are some limitations that should be considered. For instance, although DEAP dataset covered the whole emotional space, the number of samples contained in each quadrant is unbalanced, being HAHV the group with a notably higher amount of samples. Hence, it would be interesting to enlarge the number of trials corresponding to the rest of emotional states, with the aim of balancing the amount of samples in each group of the dataset. On the other hand, audiovisual stimuli used in this experiment had a duration of one minute. This length may be excessive and many emotions could be elicited for each trial, thus making it difficult for participants to properly rate their emotional state [30].
Moreover, different improvements could be included in future studies. For instance, only EEG recordings have been analyzed in this work, thus discarding the information contained in the rest of physiological variables also included in DEAP database. For this reason, EEG and peripheral signals will be combined in future works with the aim of verifying the relation between those variables for emotions detection. Furthermore, as mentioned in Section 1, traditional time–frequency metrics usually evaluate signals from a linear point of view, which could be a limitation for a complete assessment of nonlinear brain dynamics. However, some higher-order spectra metrics such as the bispectrum evaluate the nonlinear interactions of a signal [21, 44]. For this reason, this metric will be considered in future studies. In addition, an SVM classification model was chosen because of being the most widely applied in similar studies from other research groups. However, other classification approaches, such as sparse Bayesian [23, 49, 50], C4.5 algorithm [19] or convolutional neural networks [26], among others, have already reported notable results in EEG classification problems. Hence, they will be applied in future works. Finally, as the database assessed in this work is publicly available, the reproducibility and extension of the present experiment are guaranteed for other research groups.
Conclusions
In the present work, entropy metrics QSE, AAPE and PME have been applied for the first time to discern between the four quadrants of the emotional valence-arousal model. Those indices were chosen as one step further after having revealed relevant findings for recognition of calm and negative stress emotional states. Results reported in this manuscript have also demonstrated the efficiency of these nonlinear measures for detection of a higher number of emotions. In this sense, frontal and parietal brain areas of both brain hemispheres have provided the best discriminatory power between the four groups of emotions, thus highlighting the strong implication of these brain regions in emotional processes. Furthermore, valuable outcomes derived from the combination of regularity-based QSE with predictability-based AAPE and PME in both multi-class and binary-class schemes prove the high degree of complementarity between those different types of entropy metrics. In addition, a novel perspective of the detection of valence and arousal in this binary-class approach has corroborated the interrelation between both emotional dimensions. Precisely, it has been demonstrated that there are important differences in the detection of high and low levels of one dimension when considering the level of the other dimension.
References
Abásolo D, Hornero R, Gómez C, García M, López M. Analysis of EEG background activity in Alzheimer’s disease patients with Lempel-Ziv complexity and central tendency measure. Med Eng Phys. 2006;28(4):315–22.
Alia-Klein N, Preston-Campbell RN, Moeller SJ, Parvaz MA, Bachi K, Gan G, et al. Trait anger modulates neural activity in the fronto-parietal attention network. PloS one. 2018;13:(4).
Azami H, Escudero J. Amplitude-aware permutation entropy: Illustration in spike detection and signal segmentation. Comput Meth Prog Bio. 2016;128:40–51.
Bagherzadeh S, Maghooli K, Farhadi J, Soroush MZ. Emotion recognition from physiological signals using parallel stacked autoencoders. Neurophysiology. 2018;50(6):428–35.
Bandt C, Pompe B. Permutation entropy: A natural complexity measure for time series. Phys Rev Lett. 2002;17:174102.
Bonaccorso G. Machine learning algorithms. Packt Publishing Ltd. 2017.
Cai J, Chen W, Yin Z. Multiple transferable recursive feature elimination technique for emotion recognition based on EEG signals. Symmetry. 2019;11(5):683.
Cao Y, Cai L, Wang J, Wang R, Yu H, Cao Y, et al. Characterization of complexity in the electroencephalograph activity of Alzheimer’s disease based on fuzzy ntropy. Chaos. 2015;25(8):083116.
Dasdemir Y, Yildirim E, Yildirim S. Analysis of functional brain connections for positive-negative emotions using phase locking value. Cogn Neurodynamics. 2017;11(6):487–500.
Davidson RJ. Affect, cognition, and hemispheric specialization. In: Emotion, Cognition, and Behavior. Cambridge University Press. New York. 1988;320–365.
Delorme A, Makeig S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J Neurosci Methods. 2004;134(1):9–21.
Dzedzickis A, Kaklauskas A, Bucinskas V. Human emotion recognition: Review of sensors and methods. Sensors. 2020;20(3):592.
Egger M, Ley M, Hanke S. Emotion recognition from physiological signal analysis: A review. Electronic Notes in Theoretical Computer Science. 2019;343:35–55.
Gao Z, Cui X, Wan W, Gu Z. Recognition of emotional states using multiscale information analysis of high frequency EEG oscillations. Entropy. 2019;21(6):609.
García-Martínez B, Martínez-Rodrigo A, Fernández-Caballero A, Moncho-Bogani J, Alcaraz R. Nonlinear predictability analysis of brain dynamics for automatic recognition of negative stress. Neural Comput Appl. 2018;1–11.
García-Martínez B, Martínez-Rodrigo A, Zangróniz R, Pastor JM, Alcaraz R. Symbolic analysis of brain dynamics detects negative stress. Entropy. 2017;19(5):196.
Han J, Zhang Z, Schuller B. Adversarial training in affective computing and sentiment analysis: Recent advances and perspectives. IEEE Comput Intell Mag. 2019;14(2):68–81.
Hatamikia S, Nasrabadi AM. Recognition of emotional states induced by music videos based on nonlinear feature extraction and SOM classiffication. In: 21th Iranian Conference on Biomedical Engineering (ICBME). IEEE. 2014;333–337.
Hou Y, Chen S. Distinguishing different emotions evoked by music via electroencephalographic signals. Comput Intel Neurosc. 2019;2:1–18.
Huang H, Xie Q, Pan J, He Y, Wen Z, Yu R, et al. An EEG-based brain computer interface for emotion recognition and its application in patients with disorder of consciousness. IEEE Trans Affect Comput. 2019.
Ieracitano C, Mammone N, Hussain A, Morabito FC. A novel multi-modal machine learning based approach for automatic classiffication of EEG recordings in dementia. Neural Networks. 2020;123:176–90.
Ismail WW, Hanif M, Mohamed S, Hamzah N, Rizman ZI. Human emotion detection via brain waves study by using electroencephalogram (EEG). International Journal on Advanced Science Engineering and Information Technology. 2016;6(6):1005–111.
Jin Z, Zhou G, Gao D, Zhang Y. EEG classiffication using sparse Bayesian extreme learning machine for brain-computer interface. Neural Comput Appl. 2018;1–9:
Jung Y, Hu J. A K-fold averaging cross-validation procedure. Journal of Nonparametric Statistics. 2015;27(2):167–79.
Kang J, Chen H, Li X, Li X. EEG entropy analysis in autistic children. Journal of Clinical Neuroscience. 2019;62:199–206.
Kaya D. The mRMR-CNN based inffluential support decision system approach to classify EEG signals. Measurement. 2020;156:107602.
Keller K, Unakafov A, Unakafova V. Ordinal patterns, entropy, and EEG. Entropy. 2014;16(12):6212–39.
Kim MK, Kim M, Oh E, Kim SP. A review on the computational methods for emotional state estimation from the human EEG. Comput Math Method M. 2013;573734. https://doi.org/10.1155/2013/573734
Klem GH, Lüders HO, Jasper HH, Elger C. The ten-twenty electrode system of the International Federation. Electroencephalography and Clinical Neurophysiology. 199;52:3–6.
Koelstra S, Muhl C, Soleymani M, Lee JS, Yazdani A, Ebrahimi T, Pun T, Nijholt A, Patras I. DEAP: A database for emotion analysis using physiological signals. IEEE Transactions on Affective Computing. 2012;3(1):18–311.
Kuppens P, Tuerlinckx F, Russell JA, Barrett LF. The relation between valence and arousal in subjective experience. Psychological Bulletin. 2013;139(4):917–40.
Lake DE, Moorman JR. Accurate estimation of entropy in very short physiological time series: The problem of atrial brillation detection in implanted ventricular devices. American Journal of Physiology-Heart and Circulatory Physiology. 2011;300(1):H319–H325325.
Martínez-Rodrigo A, García-Martínez B, Alcaraz R, González P, Fernández- Caballero A. Multiscale entropy analysis for recognition of visually elicited negative stress from EEG recordings. Int J Neural Sys. 2019;29(02):1850038.
Martínez-Rodrigo A, García-Martínez B, Zunino L, Alcaraz R, Fernández-Caballero A. Multi-lag analysis of symbolic entropies on EEG recordings for distress recognition. Frontiers in Neuroinformatics. 2019;13:40.
Nauta WJ. Neural associations of the frontal cortex. Acta Neurobiologiae Experimentalis. 1972;32(2):125–40.
Pedroni A, Bahreini A, Langer N. Automagic: Standardized preprocessing of big EEG data. Neuroimage. 2019;200:460–73.
Poria S, Cambria E, Bajpai R, Hussain A. A review of affective computing: From unimodal analysis to multimodal fusion. Information Fusion. 2017;37:98–125.
Portnova G, Maslennikova A, Varlamov A. Same music, different emotions: Assessing emotions and EEG correlates of music perception in children with ASD and typically developing peers. Advances in Autism. 2018;4(3):85–94.
Richman JS, Moorman JR. Physiological time-series analysis using approximate entropy and sample entropy. American Journal of Physiology-Heart and Circulatory Physiology. 2000;78(6):H2039–H20492049.
Rubia K. The neurobiology of meditation and its clinical effectiveness in psychiatric disorders. Biological Psychology. 2009;82(1):1–11.
Russell JA. A circumplex model of affect. J Pers Soc Psychol. 1980;39(6):1161–78.
Saarimäki H, Gotsopoulos A, Jääskeläinen IP, Lampinen J, Vuilleumier P, Hari R, Sams M, Nummenmaa L. Discrete neural signatures of basic emotions. Cerebral cortex. 2016;26(6):2563–73.
Soroush MZ, Maghooli K, Setarehdan SK, Nasrabadi AM. Emotion recognition through EEG phase space dynamics and Dempster-Shafer theory. Medical Hypotheses. 2019;127:34–45.
Sun L, Feng Z, Lu N, Wang B, Zhang W. An advanced bispectrum features for EEG-based motor imagery classiffication. Expert Syst Appl. 2019;131:9–19.
Vijayan AE, Sen D, Sudheer AP. EEG-based emotion recognition using statistical measures and auto-regressive modeling. Int Conf Comput Intell Comm Tech. 2015;587–91.
Wagh KP, Vasanth K. Electroencephalograph (EEG) based emotion recognition system: A review. In: Innovations in Electronics and Communication Engineering. Springer. 2019;37–59.
Zhang Q, Hu Y, Potter T, Li R, Quach M, Zhang Y. Establishing functional brain networks using a nonlinear partial directed coherence method to predict epileptic seizures. J Neurosci Methods. 2020;329:108447.
Zhang Y, Ji X, Zhang S. An approach to EEG-based emotion recognition using combined feature extraction method. Neuroscience Letters. 2016;633:152–7.
Zhang Y, Wang Y, Jin J, Wang X. Sparse Bayesian learning for obtaining sparsity of EEG frequency bands based feature vectors in motor imagery classiffication. Int J Neural Syst. 2017;27(02):1650032.
Zhang Y, Zhou G, Jin J, Zhao Q, Wang X, Cichocki A. Sparse Bayesian classiffication of EEG for brain-computer interface. IEEE Trans Neural Netw Learn Syst. 2015;27(11):2256–67.
Zhao X, Shang P, Huang J. Permutation complexity and dependence measures of time series. Europhysics Letters. 2013;102(4):40005.
Zunino L, Olivares F, Rosso OA. Permutation min-entropy: An improved quantifier for unveiling subtle temporal correlations. Europhysics Letters. 2015;109(1):10005.
Acknowledgements
This work was partially supported by Spanish Ministerio de Ciencia, Innovación y Universidades, Agencia Estatal de Investigación (AEI) / European Regional Development Fund (FEDER, UE) under DPI2016-440 80894-R, PID2019-106084RB-I00 and 2018/11744 grants, by Castilla-La Mancha Regional Government / FEDER, UE under SBPLY/17/180501/000192 grant, and by Biomedical Research Networking Centre in Mental Health (CIBERSAM) of the Instituto de Salud Carlos III. Beatriz García-Martínez holds FPU16/03740 scholarship from Spanish Ministerio de Educación y Formación Profesional. Luciano Zunino acknowledges the financial support from Consejo Nacional de Investigaciones Científicas y Técnicas (CONICET), Argentina.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of Interest
Authors declare that they have no conflict of interests.
Ethical Approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Rights and permissions
About this article

Cite this article
García-Martínez, B., Fernández-Caballero, A., Zunino, L. et al. Recognition of Emotional States from EEG Signals with Nonlinear Regularity- and Predictability-Based Entropy Metrics. Cogn Comput 13, 403–417 (2021). https://doi.org/10.1007/s12559-020-09789-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12559-020-09789-3