
Abstract
Biometric technology knows a large attention in the recent years. In the biometric security systems, the personal identity recognition depends on their behavioral, biological or physical characteristics. Currently, a number of biometrics technologies are developed and one of the most popular biometric trait is finger-knuckle-print (FKP) due to the user-friendly and the low cost. This paper presents a new approach, where the deep learning is applied to create a multi-modal biometric system based on images of FKP modalities which extracted their features by principal component analysis Network (PCANet). In the proposed structure, PCA is employed to learn two-stage of filter banks followed by simple binary hashing and block histograms for clustering at feature vectors, which is adopt as input for classification by linear multiclass Support Vector Machine (SVM). To improve the recognition rates, a multimodal biometric system based on matching score level fusion scheme was generated. Using an available FKP database, we conducted a series of identification experiments and the obtained results show that the design of our identification system achieves an excellent recognition rate and having high anti-counterfeiting capability.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The security of information is ensuring that the only authorized users are able to access the required contents, thereby entails confidentiality of exchange information. It essentially provided by authentication user whereby an individual identity is verified through traditional means such as: username and password, smart-cards, keys, etc. These traditional ways are largest candidate for forgotten, guessed or cracked through hacker and also at risk of lost, duplicated and steal. Many of these limitations can be ameliorated by the incorporation of biometric authentication methods.
Biometric security is one of the best primary functions of security system which is based on the measurement and statistical analysis of persons physical and behavioral characteristics, such as face, fingerprint, hand geometry, iris, DNA, signature, voice, etc. (Belgacem et al. 2015; Upadhayay and Yadav 2013), that can be used for automated recognition. Biometric technologies offer several advantages over traditional authentication schemes and they have more reliable characteristics than other methods. One of the advantages of biometric methods is the requirement of the person to be presented at the time of authentication. Furthermore, it is difficult to attack biometric systems because it require more time, money, experience and it is unlikely for a user to repudiate having accessed the content using biometrics. Thus, a biometrics based authentication scheme is a powerful alternative into security systems (Baochang 2010). For instances, biometrics can be used in conjunction with passwords to enhance the security offered by the authentication system. All biometric technologies differ according to security level, social acceptability, reliability, cost, performance, etc. The most acceptable biometric technology is these extracted from hand due to their higher discriminatory which based on the fact that each human hand is highly unique. In our days, the physical technology, which has been attracting much attention, is the finger-knuckle-print (FKP) modality (Kumar and Ravikant 2009). In this modality, several features can be used such as structure and shape (e.g. length, width and thickness, joints); characteristics of the skin surface such as creases and ridges in fingers. There are several main factors which make a person’s FKP unique, among these factors, the ease of the use as well as the rich texture information seems to be the most significant, which makes the biometric system work with higher accuracy.
In pattern recognition system, feature extraction is the process by which key features are selected or improved for the sample (generally sample is in form of image). In biometrics systems, as one of pattern recognition applications, the feature extraction process is based on a set of algorithms; the method varies depending on the type of image characteristics such as texture, line and shape. In recent years, high hopes were invested in biometrics systems, mostly thanks to modern algorithms like machine learning and artificial intelligence. Thus, the continuous search led to the developing a modern methods called deep learning. These methods are rapidly drew significant attention in order to use it in texture classification (Angelov and Gu 2017). The deep learning technique is subfield of machine learning research (Ghazi and Ekenel 2016; Taigman et al. 2014) which applied learning algorithms to scan multiple levels of representation to modeling complex relation within the data. Thus, it’s identified high level features and concepts based on the lowest of them. This hierarchical structure of features called deep structure, and most of these models are based on the methodology of supervised or no-supervised learning of representations. Principal tools for success of deep learning in image classification is the use of convolutional architectures (Oquab et al. 2014; Deng 2013). Recently, one of mostly deep learning methods is based on principal component analysis (PCA). So, a PCA deep neural network (PCANet) consists of multiple trainable stages stacked on top of each other (Tian et al. 2015), each stage generally comprises of convolutional filter bank layer, a nonlinear processing is adopted for feature extraction as well as texture patterns analysis and classified. However, learning a network useful for classification critically depends on expertise of parameter tuning and some setting tricks (Feng et al. 2015).
Unimodal biometric systems, where they use only one biometric source, possess many limitations such as noise in sensed data, spoof attacks, intra-class variations and non-universality. Almost all the limitations in unimodal systems can be reduced through using multiple biometric characteristics, such systems are called multimodal biometric systems (Kaur et al. 2014). Indeed, these systems are worked by several types of information provided from different biometric inputs, in which a combination process, of two or more biometric modalities, is applied. In multimodal biometric system, combination of information can occur at any level of system. Furthermore, based on the level of fusion, various techniques can be used to integrate the information from two or more different. Thus, the fusion can be applied at any of the following levels (Sudhamani et al. 2012): fusion at the sensor or image level where the combination of raw biometric data is taken. Fusion at feature extraction level where a combination of the different feature vectors is obtained. Fusion at the matching scores level: the different match score, for each sub-system, were combined. Finally, fusion at the decision level: a vote between the different sub-systems decisions is used to make final decision.
The objective of our study is trying to design a biometric system based on new machine learning method which are deep architecture. The major motivation behind this objective is the hierarchical learning structures of this method which have powerful ingredients to create a more sophisticated identification system dedicated to image classification, which could serve as a use to train and to adapt with different traits biometrics. In recognition system, although information processing requires deep architectures to extract the structures and to build internal representations, a simple PCA-Network architecture can be represent a good baseline. Finally, in the recent years, several experimental results justify the use of deep learning processing for future application in biometrics field. In our proposed biometric system, several fingers of the hand are used. For that, our system can work in a unimodal or multimodal way. In this last way, the fusion is performed at matching scores level by using same fusion rules.

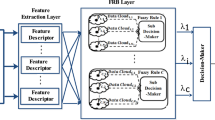
Block-diagram of the proposed PCANet based unimodal biometric system
The remainder of this paper is organized in three big sections. The first one, which concerned with the theoretical framework, describes the proposed biometric system design. In this section, feature extraction process, classifier, matching process as well as fusion strategies are discussed. Whereas, the second section, is reserved for experimental results in which several tests are executed and then discussed. Finally, conclusions and some perspectives are given in last section.
2 Methodology
The idea behind our methodology is to look at the PCANet technique as a deep learning method, through their stages, into a biometric image classification.
2.1 Proposed system design
In Fig. 1, we show the block-diagram of the proposed unimodal biometric system based on the FKP images. Like all biometric systems, this system work into two phases; the first is the enrollment phase. In this phase, the feature vectors are extracted from the all Region of Interest (ROI) sub-images (Zhang et al. 2003) by PCA Network. After that, these feature vectors will be as a training data used to create SVMStruct. Training data is a matrix where each column corresponds to a feature vector. In the second phase, devoted to the identification, the same method is applied, on finger test image, for extract the feature vector and then it uses as an input to the SVM classifier in order to find the person which own the same test finger.
2.2 PCANet based feature extraction
Compared with the classical feature extraction methods, one of the foremost advantages offered by the deep learning based feature extraction methods is flexibility and so its discriminative (Donahue et al. 2013; Gu et al. 2018) because it is possible to use a higher level features into multiple levels of representation to extract some discriminant information of the image trait. Hence, a lot of feature extraction methods rely on deep learning techniques have been proposed in literature (Razavian et al. 2014) and PCANet technique is one of these techniques. Thus, this technique provides a reliable solution to extract the majority of information in image which can be used in a greater range of pattern recognition systems to discriminate the images. In contrast to other deep learning techniques, like Convolutional Neural Networks (CNN) (Krizhevsky et al. 2012) and Deep Belief Networks (DBN) (Hinton et al. 2006), PCANet method offer some advantages such as their very suitability for texture analysis as well as their simplicity (complexity relatively simple vis-a-vis almost all deep learning techniques).
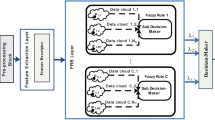
The PCANet model (Meraoumia et al. 2016) cascades many filter bank convolutions (extracted from input image by PCA technique, Chan et al. 2015) with an intermediate mean normalization step, followed by two other steps which are the binary hashing and the histogram composition step. PCANet algorithm can execute multiple stages of PCA filters to extract higher level feature vectors. We give hereafter an example of two stages PCANet based feature extraction method (see Fig. 2).

Example of the PCANet extracts features from an FKP image
In the first stage, the filter banks are estimated by performing principal components (PCA) technique over a set of vectors where each vector represents the \(k_1 \times k_1\) points around each pixel. Before performing this technique, the mean of each vector must be subtracted from it (normalization process). After applying PCA over the normalized vectors, a \(k_1\cdot k_1 \times L_1\) retained, where \(L_1\) is the primary eigen vectors. Next, each principal component (\(1\ldots L_1\)) is a filter and may be converted to \(k_1 \times k_1\) kernel which is convolved with the input image. So, using \(L_1\) vectors (\(L_1\) convolution filter), we can convert the input image I into \(L_1\) output filtered images:
where \(I^{s_1}_{F_i}\) (\(i\in [1\ldots L_1]\)) denote the \(i^{th}\) filtered image using the \(\mathcal {F}^{s_1}_i\) filter for the first stage and \(*\) denotes the discrete convolution. In the second stage, the same algorithm used in the first stage is iterated over each of the \(L_1\) output filtered images (\(I^i_{F}\)):
where \(I^{s_2}_{F_{ij}}\) (\(i\in [1\ldots L_1]\) and \(j\in [1\ldots L_2]\)) denote the jth filtered image using the \(\mathcal {F}^{s_2}_j\) filter (with size of \(k_2 \times k_2\)) for the second stage. If the number of filters in second stage equal to \(L_2\), the output of the last convolution layer produce \(L_1 \cdot L_2\) output filtered images. Subsequently, the finally outputs (\(I^{s_2}_{F_{ij}}\)) are converted into binary format by using a Heaviside step function (Meraoumia et al. 2016) which their value is one for positive entries and zero otherwise, this step called binary hashing step.
where \(I^{B}_{ij}\) is a binary image. After that, around each pixel, the vector of \(L_2\) binary bits is viewed as a decimal number:
where \(I^{D}_{i}\) is an image whose every pixel is an integer in the range \([0,~2^{L_{2}-1}]\). Finally, the histograms of the obtained images are computed and then concatenated to form a feature vector which represents the input image, this step called histogram composition. Thus, the feature vector of the input image I is then defined as:
where \(\upsilon _{i}\) denotes the histogram of the \(I^{D}_{i}\) image. Lastly, it is important to note that in the PCANet technique it must choose the optimal values of the PCANet parameters which are the number of stages (N), the filters sizes in each stage (\(k_1, k_2,\ldots k_N\)) and the number of filters in each stage (\(L_1, L_2,\ldots L_N\)).
2.3 Multiclass SVM classification
In the original work which uses PCANet deep learning (in biometric system based on face modalities), a multiclass Support Vector Machine (SVM) classifier (Gu and Angelov 2018) is used. This classifier is a supervised machine learning algorithm which can be used for both classification and regression challenges. However, it is receiving increasing attention and have shown superior performance in pattern recognition (Kasabov 2007). For that, we used a multiclass linear SVM operate on the extracted feature vector for each image. The specific algorithm used was one-against-others support vector classification. Thus, in this algorithm, binary SVMs (Pang et al. 2011) are combined in either one-against-others, each of the binary SVMs separates a single class from all remaining classes (SVM-pairwise scheme). These classifiers are arranged in trees where each node represents an SVM. It is important to note that in our scheme, two additional classifiers (Radial Basis Function (RBF) (Esposito et al. 2000) and Random Forest Transform (RFT) (Chang et al. 2017) are tested and compared with the multiclass SVM classifier .
2.4 Matching and normalization process
During the identification process, the characteristic of the test FKP image, corresponding to each person, is analyzed by the PCANet deep learning. Then the similarity/dissimilarity between two given feature vectors is computed. For that, the obtained feature vector should enter a scores computing process. This process is made against SVM classifier, which will be calculated depending on their used algorithm.
2.4.1 Matching process
In our system, the matching process is based on classification score. The SVM classifying a such observation (or feature vector) X by the signed distance from X to the decision boundary ranging from \(-\infty\) to \(+\infty\) (Nakanishi and Sodani 2010). For a score joined to class C, a positive score indicates that X is predicted to be in C, a negative score indicates otherwise. The predicting score for the observation X into the positive class, f(x) is the trained SVM classification function:
where \((\alpha _{1}, \alpha _{2},\ldots , \alpha _{n}, b)\) are the estimated SVM parameters, \(G(x_{j},x)\) is the dot product in the predictor space between X and the support vectors, and the sum includes the training set observations. The score for predicting X into the negative class is X, f(x).
If \(G(x_{j},x)=x_{j}'x\) (the linear kernel), then the score function reduces to:
where s is the kernel scale and \(\beta\) is the vector of fitted linear coefficients.
2.4.2 Normalization process
Normalization is a process that changes the different distance values in a common domain. One of efficient technique used in normalization process is the Min–Max technique which is the process of transforming the different scores to values between 0 and 1 (Fierrez-Aguilar et al. 2005). The lowest (min) value is set to 0 and the highest (max) value is set to 1. This provides an easy way to compare values that are measured using different scales of measure. Min–Max normalization is defined as:
where \(\widetilde{D}\) denotes the normalized similarity/dissimilarity scores. However, these scores are compared, and the highest score is selected. Therefore, the best score is \(\widetilde{d}_o\) and its equal to:
where N denote number of references vectors in system database. Finally, this score is used for decision making in which a threshold \(T_o\) is used to regulates the system decision. The system infers that pairs of biometric samples generating scores lower than or equal to \(T_o\) are mate pairs. Consequently, pairs of biometric samples generating scores higher than \(T_o\) are non mate pairs.
2.5 Fusion technique
Currently, fusion at the matching score level appears to be the most useful fusion level because of its good performance and simplicity (Karki and Selvi 2013). In this stage normalized matching scores are fused to generate an output score, from different unimodal sub-systems, which is then used for making the final decision. During our series of tests, four different fusion schemes are experimented which are Sum-score, Min-score, Max-score and Weighted-score rules (Sudhamani et al. 2012). Thus, if the scalar \(\widetilde{d}_i\) represents the score of the ith sub-system and \(F_{s}\) represents the fusion score. Therefore, \(F_{s}\) is given by:
-
1.
Sum-score rule: \(F_{s}=\sum _{i=1}^{k}\widetilde{d}_{i}\)
-
2.
Min-score rule: \(F_{s}=min(\widetilde{d}_{1}, \widetilde{d}_{2}\ldots , \widetilde{d}_{k})\)
-
3.
Max-score rule: \(F_{s}=max(\widetilde{d}_{1}, \widetilde{d}_{2}\ldots , \widetilde{d}_{k})\)
-
4.
Weighted–Sum-score rule: \(F_{s}=\sum _{i=1}^{k}w_{i}\widetilde{d}_{i}\)
with k is the number of combined biometric sub-system and the weight of ith sub-system, \(w_{i }\), is defined as:
where \(\mathcal {E}_{i}\) denote the Equal Error Rate (EER) of each biometric sub-systems and \(\sum _{i=1}^{k}w_{i}=1\).
3 Experimental results
3.1 Experimental datasets
To evaluate the performance of the proposed biometric system and choose their appropriate parameters, a database of FKP images is required. Thus, our experiment tests were performed using the FKP Database from the Poly University (The Hong Kong Polytechnic University 2018). The database has a total of 7920 images from 660 different fingers obtained by 165 persons. This dataset including 125 males and 40 females. Among them, 143 subjects were 20–30 years old and the others are 30–50 years old. These images are collected in two separate sessions. The average time interval between the first and the second sessions were about 25 days. The maximum and minimum intervals were 96 and 14 days, respectively. In each session, the subject (person) was asked to provide 12 image samples for each of Left Index Fingers LIF, Left Middle Fingers LMF, Right Index Fingers RIF and Right Middle Fingers RMF. Therefore, 48 image samples from 4 finger types were collected from each person.
3.2 Identification test results
In this section, the identification tests results are divided into three parts. In the first part, a series of experiments were carried out to select the best PCANet parameters (number of conventional fitters and block overlap percentage) yield the best performance. The tests results in the second part are devoted to evaluate the performance of the unimodal and multimodal biometric identification systems. Finally, in the last section, a comparison study is made.
A biometric identification system can work into two modes: open-set identification and closed-set identification modes. In open-set mode, the system indicate that the person presenting the acquired biometric data is an enrolled person or not in the system database. In the closed-set mode, the system select the identity of the person whose reference has the highest degree of similarity with the acquired biometric data. In our study, the proposed method was tested through the two modes. It is important to note that each FKP image must be preprocessed to obtain only the area information of the finger knuckle (ROI sub-image). In our work, we use the preprocessing method described in Zhang et al. (2003).
3.2.1 PCANet parameters selection
The performance of PCANet deep learning model depends on tuning parameters. For that, we conducted a series of experiments to select the best parameters which give a minimum errors rates. Thus, in our work, we empirically choose the number of stages equal to two-stages. In the first stage, we change everytime the number of PCA filters from 1 to 3 with a fixed number of PCA filters in second stage which equal to 2. The problem we address is as follows: we want to choose the number of \(\left[ K_{1}, K_{2}\right]\) PCA filter and the block overlap percentage such that the EER is minimized. By varying the filter number from 1 to 3 in first stage and block overlap percentage from 0 to 75%, we can illustrate, in Table 1, the system performance as a function of the number of PCA filters selection in each stage for various block overlap percentage. The reason Table 1 was generated was to show how these parameters might have an effect on the performance of our system. From this table, we observe that the identification accuracy becomes very high at [3, 2] filter number (3 filters for first stage and 2 filters for second stage), where it actually exceeds 98.788% (EER = 1.212%) and strong decrease in identification accuracy as we go to lower size (it is important to note that, the filter size used for this test is \(5\times 5\) and all tests are executed using LIF modality). Also, another’s series of tests is performed to select the optimum filter size with their corresponding block overlap percentage. Thus, several sizes are tested which are \((3\times 3, 5\times 5, 7\times 7\cdots 13\times 13)\), and the given results are plotted in Fig. 3. From this figure, it is very clear that a filter size equal to \(\left[ 13\times 13 \right]\) and an overlapped block equal to 50% are enough to achieve good accuracy with a very lower EER equal to 0.919 %.

The PCANet parameters test results
However, the results given in this part demonstrate that a filter number equal to 3 and 2 in the first and second stage, respectively, a filter size of \(13\times 13\) and a block overlap percentage of 50% can offer better results in terms of system accuracy. Therefore, we have decided to choose these parameters in the rest of our study.
3.3 Identification performances

Unimodal open/closed-set identification test results under different fingers. a The ROC curves (FRR against FAR), b the ROC curves (GAR against FAR) and c the CMC curves
In the system-design phase, three images are randomly selected of twelve images of each person were used in the enrolment stage to create the system database; the remaining nine images were used to evaluate the system performance. Thus, a total of 123,255 comparisons (database size equal to 165) were made. The genuine experiments were performed by comparing three test images with the corresponding class in the database in which 1485 genuine scores were made. Similarly, nine images with each class, for impostor experiments, were compared with all references in database which give 121,770 impostor experiments. Thus, identification occurs when the biometric system attempts to determine the identity of an individual for that a feature vector is extracted and compared to all the vectors in a system database. In this part, the identification tests results are divided into two sub-parts. Firstly, we present the performance of the unimodal biometric systems using PCANet technique in order to select the finger modality yield the best performance. Subsequently, in the second sub-parts, the multimodal identification systems performances are tested. As mentioned above, these systems are based on fusion at matching score level, for that the several fusion rules as well as several combination are evaluated in order to the best multimodal system.
3.3.1 Unimodal identification performances
This sub-section describes the results of the proposed open-set identification unimodal system when we use individually, information from four modality LIF, LMF, RIF and RMF of each person. Thus, we can see in Table 2 the test results for all finger types. From this table, it’s clear that the LMF and RIF fingers offer better results in terms of the EER. In this case, the identification system can achieve an EER of 0.673% at a threshold \(T_{0}\) = 0.715 and \(T_{0}\) = 0.703 for LMF and RIF modalities, respectively. Also in this table, we can observe the LIF modality gives EER = 0.919% at a threshold \(T_{0}\)= 0.705 for LIF modality. Finally, in the case of using RMF modality, EER = 1.077% with \(T_{0}\)= 0.687. So, the performance of of our system is very acceptable compared with several state-of-art of FKP based biometric identifier accuracies when we can justified with the efficiency of the proposed method. The ROC curves for four fingers modalities are shown in Fig. 4a, which plot the False Rejected Rate (FRR) against the False Accept Rate (FAR). The experimental results indicate that the LMF and RIF modalities are very efficiency at the EER point and their performances are equal. These modalities is better than the perform of the LIF and RMF modalities in terms of EER. In Fig. 4b, the ROC curves (Genuine Acceptance Rate (GAR) against FAR) provide a more details for the performance of proposed unimodal open-set identification systems.

The ROC curves for multimodal open-set identification test results (fusion at matching score level). a The LIF–LMF combination, b the RIF–RMF combination and c the ALL combination
Similarly, at closed-set identification systems tests, we compare the performance of the different fingers modalities to determine the best modality. The results for all fingers are also presented in Table 2. From analyzing this table we can see that the Rank-One Recognition (ROR) is between 95.150 and 97.300%. So, the system can achieve higher accuracy at the LMF modality compared with the other fingers modality which is produced a ROR equal to 97.300% with a Rank of Perfect Recognition (RPR) of 102 . The RIF followed by LIF and RMF modalities can produce a ROR equal to 96.830% (RPR = 136), 95.750% (RPR = 111) and 95.150% (RPR = 145), respectively. To summarize the closed-set identification experiments, graphs showing the Cumulative Match Characteristics (CMC) curves using all unimodal systems were generated in Fig. 4c. In conclusion, the obtained identification rates for FKP modalities are very efficiency and make this proposed biometric systems applicable in the reality.
3.3.2 Multimodal identification performances
Recently, research in the field of biometrics for identification purposes, has increasingly investigated the use of multiple biometric modalities (multimodal biometrics). Multimodal biometrics refers to the use of more than one biometric modality for person identification. The multimodal systems are expected to be more reliable due to the presence of multiple templates security. A number of these systems have been proposed and that differ from one another in terms of their architecture, the number and choice of modalities and the methods used for the integration or fusion of information.
The objective of this sub-part is to evaluate and improve the performance of the unimodal biometric identification system by using multiple modalities information from the different finger types. The important phase to improve the accuracy of the multimodal biometric system is the choice of the fusion level as well as the technique deployed for data fusion. In our work, we choose only the matching score level because it’s usually preferred as it’s relatively easy and it can easily combine the scores presented by the different modalities. It’s noted that, in our tests, only three different combinations of finger types for the fusion purpose are tested: two fingers for the same hand (LIF–LMF, RIF–RMF) and four fingers (LIF–LMF–RIF–RMF for simplified it’s noted ALL). The idea behind using fusion at matching score level is possibility to combine the scores obtained from different fingers modalities with a simple rules. The overall score is then sent to the decision module for accepting or rejecting a person.

The CMC curves for multimodal closed-set identification test results (fusion at matching score level). a The LIF–LMF combination, b the RIF–RMF combination and c the ALL combination
Thus, to find the better of the all combinations as well as fusion rules, for the open-set identification mode, with the lowest EER, Table 3 were generated. The results in Table 3 show that firstly, generally the use of fusion process can improve the performance of system and provide a better result than the best unimodal identification system. Secondly, combinations with higher number of finger types give the best systems accuracies. Thus, from Table 3, we can observe that the ALL combination with almost any fusion rule (Sum, Wht and Max) reduces the EER to zero (100% improvement). Poor result can be provided by the Min rule, in this case, EER was reduced only to 0.538% (\(\simeq\) 80% improvement). In LIF–LMF and RIF–RMF combinations, the EERs are very close (between 0.022 and 0.098%) in the cases of Sum, Wht and Max rules and (0.404 to 0.673%) into Min rule. For these combinations, a considerable improvement is obtained especially for using the ALL combination with Sum, Wht and Max rules. The ROC curves in Fig. 5a–c present a direct comparison of the performances obtained using four rules by using fusion based on LIF–LMF, RIF–RMF and ALL combinations respectively.
Furthermore, to validate our idea we have run other tests for the closed-set identification mode. To determine the best combination as well as fusion rule, a table containing the results for all combinations and fusion rules has been obtained (see Table 4). The experiments which are described in Table 4 suggest that the identification rate (ROR) for the ALL combination, with Sum,Wht and Max rules is greater than the corresponding ones in unimodal system, so as ROR is given as 100.00% with lowest RPR of 1 in both cases. On the other hand, although the Min rule is provided ROR equal to 98.110% with RPR equal to 86 but it always improve the system performance. As in the open-set identification case, the results in LIF–LMF and RIF–RMF combinations did not live up of higher performance such as the ALL combination. The rest of results can be clearly seen in Table 4. Also, the curves in Fig. 6 which plot the CMCs curves for all cases demonstrate the capability of reducing the identification error rates by combining all fingers in the matching score level. Where Fig. 6a presents comparison of the different rules fusion based on LIF–LMF combination and the same presentation Fig. 6b, c for RIF–RMF and ALL combinations respectively.
3.3.3 Comparative study
In order to show the effectiveness of the PCANet deep learning using different classifiers, a comparison study conducted using some classifier is performed. Thus, in this comparison, PCANet as a feature extraction method is used. This method can capture the information from the texture in an image and provides a very robustness to effectively describes the image characteristics. Thus, two test classifiers: Radial Basis Function (RBF) and Random Forest Tree (RFT) are used and their obtained results are compared with SVM classifier. In these experiments, the results obtained for the identification tests are giving an idea on better classifier which will entirely depend on proposed process. As such, the ensemble of experiments tends to be quite powerful. The comparative study is divided into two sub-parts, the performance of the unimodal and multimodal systems. The objective of this section is to choose the system yield the best performance.
Unimodal identification In open-set identification mode, the results obtained for the identification tests are given in terms of EER. Table 5 shows the baseline results obtained using the three classification algorithms. These results demonstrate the capability of SVM in reducing identification error rate. From this table, it is observed that the use of SVM system leads to reduce the lowest EER offered by the rest unimodal systems. However, it is also seen that this capability is considerably improved through the LMF modality (EER = 0.673% and \(T_{0}\) = 0.715). On the other hand, it is observed that using the rest of the systems produce limited efficiency. Also the LMF modality gives the best performance by using RBF classifier (EER = 1.305%, \(T_{0}\) = 0.673) and RFT (EER = 1.547%, \(T_{0}\) = 0.509). Similarly, the second mode of identification (closed-set mode) was tested for all classifier and the results are reported in Table 5 for comparison. Also, it is clear that using SVM improves the system performance, as compared with the RBF and RFT systems. In the case of using SVM, a ROR of 97.30% with a lowest RPR = 102 is achieved by the LMF modality. Using RBF, ROR was 94.41% with RPR = 139 and RFT gives the result ROR = 92.12% and RPR = 147 for a database size of 165 persons. Based on the results, it should be noted that absolutely the system based on SVM classifier is very efficiency than this based on RBF and RFT classifiers.
Multimodal identification This sub-part examines the investigations into the effectiveness of the three classifiers (RBF, RFT and SVM) in both open-set and closed-set multimodal biometrics systems. At the matching score level fusion, it is possible to combine scores obtained from different fingers modalities by using rules: Sum, Min, Max and Wht.
For that, the experimental results for the open-set identification mode respecting all combinations and fusion rules are presented as EER in Table 6. The results in Table 6 show that the use of fusion resulted in better performance than the best unimodal systems. Moreover, it is observed that the SVM with ALL combinations successfully reduces the EER to zero for the fused biometrics which in this case is efficiency than several previous works obtained using FKP biometric. Using the RBF and RFT classifiers provide a considerable improvement EER equal to 0.237 and 0.002% for the ALL combination. The Table 6, presents a direct comparison of the performances obtained by using fusion based on these combinations.
The experimental results for the closed-set identification mode are presented in Table 7. As the experimental results show in SVM case, the identification rate for the ALL combination with Sum, Max and Wht rules are also greater than the corresponding ones in the RBF and RFT cases; and can give (ROR = 100%, RPR = 1). On the other hand, the RFT is provided very efficiency accuracy in this mode, the Sum rule for the ALL combination is provided ROR equal to 99.93% with RPR equal to 4. As in RBF case, the ALL combination provides cogent performance such as ROR = 98.58% and RPR = 50 by using Sum rule. Table 7 presents comparison of the different rules fusion based on all combination all bests cases.
Finally, in order to select the best biometric identification system with a lowest error, a comparative study of the effectiveness of the best unimodal and multimodal identification systems based on the previous experimental results is made. The performance of the identification system is significantly improved by using the fusion of all finger types and can give a GAR equal to 100% while the unimodal identification give only a GAR equal to 97.300%. Thus, it’s clear that the multimodal identification systems demonstrate this efficiency and give an excellent identification rate and higher accuracy. As for proposed classifier, the PCANet-SVM achieved a perfect performance (EER = 0%, ROR = 100%) superior to existing state of the art techniques and proves the fusibility and capability in the fields of biometric security.
4 Conclusion
This paper provides a multimodal biometric systems based on fusion of the sub-systems outputs at matching score level by using the FKP database (which consists LIF, LMF, RIF and RMF fingers). In this context, we have implemented the PCANet deep learning technique. The PCANet processes input images by cascaded stages of PCA filters, binary hashing and block histograms. This networks have been characterized by using the collection of parameters such as the number of stages, the number and size of filters and overlapping rate of patches. For our identification system using the combination of multiple fingers and by using the training PCANet for feature extraction process because it’s extremely simple and efficient and SVM classifier to overcome some of the limitations of unimodal systems. The experimental results show that the combination of fingers modalities images have given performs better against the one finger modality and results up to EER of 0.000% for open-set identification and a ROR of 100% for closed-set identification. From the precedent experiments, the proposed technique presented simplicity and yet refreshing perspective to convolutional deep learning networks and justification of its effectiveness in the fields of biometric security. For further improvements, our future work will project to construct a more complicated and more sophisticated filters possibly or deeper by using more number of stages. Also, we will leave as future work to apply PCANet with a much larger datasets or different biometric traits like hand geometry, iris and palmprint, etc. Furthermore, we can use other deep learning algorithms such as Convolutional Neural Networks (CNN) (Schmidhuber 2015), Deep Belief Networks (DBN) (Hinton et al. 2006) and Deep Autoencoders (Marchi et al. 2015).
References
Angelov P, Gu X (2017) MICE: multi-layer multi-model images classifier ensemble. In: 3rd IEEE international conference on cybernetics (CYBCONF 2017), Exeter, UK, pp 1–8. https://doi.org/10.1109/CYBConf.2017.7985788
Baochang Z (2010) Local derivative pattern versus local binary pattern: face recognition with high-order local pattern descriptor. IEEE Trans Image Process 19(2):533–544
Belgacem N, Fournier R, Nait-Ali A, Bereksi-Reguig F (2015) A novel biometric authentication approach using ECG and EMG signals. J Med Eng Technol 39(4):226–238
Chan T, Jia K, Gao S, Lu J, Zeng Z, Ma Y (2015) PCANet: a simple deep learning baseline for image classification. IEEE Trans Image Process 24:5017
Chang Y, Li W, Yang Z (2017) Network intrusion detection based on random forest and support vector machine. In: IEEE international conference on computational science and engineering (CSE) and IEEE international conference on embedded and ubiquitous computing (EUC), vol 1, pp 635–638
Deng L (2013) A deep convolutional neural network using heterogeneous pooling for trading acoustic invariance with phonetic confusion. In: Proceedings of IEEE international conference of acoustic speech signal process (ICASSP), pp 6669–6673
Donahue J, Jia Y, Vinyals O (2013) DeCAF: a deep convolutional activation feature for generic visual recognition. Comput Sci 50(1):815–830
Esposito A, Marinaro M, Oricchio D, Scarpetta S (2000) Approximation of continuous and discontinuous mappings by a growing neural RBF-based algorithm. Neural Netw 12:651–665
Feng ZY, Jin LW, Tao DP, Huang SP (2015) DLANet: a manifold-learning-based discriminative feature learning network for scene classification. Neurocomputing 157:11–21
Fierrez-Aguilar J, Ortega-Garcia J, Gonzalez-Rodriguez J (2005) Target dependent score normalization techniques and their application to signature verification. IEEE Trans Syst Man Cybern C Appl Rev 35(3):418–425
Ghazi MM, Ekenel HK (2016) A comprehensive analysis of deep learning based representation for face recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops, Las Vegas, USA, pp 34–41
Gu X, Angelov PP (2018) Self-organising fuzzy logic classifier. Inf Sci 447:36–51. https://doi.org/10.1016/j.ins.2018.03.004
Gu X, Angelov PP, Zhang C, Atkinson PM (2018) A massively parallel deep rule-based ensemble classifier for remote sensing scenes. IEEE Geosci Remote Sens Lett 15(3):345–349. https://doi.org/10.1109/LGRS.2017.2787421
Hinton GE, Osindero S, Teh Y-W (2006) A fast learning algorithm for deep belief nets. Neural Comput 18(7):1527–1554
Karki MV, Selvi SS (2013) Multimodal biometrics at feature level fusion using texture features. Int J Biometr Bioinf 7(1):58–73
Kasabov N (2007) Evolving connectionist systems: the knowledge engineering approach, 2nd edn. Springer, New York
Kaur G, Yadav AK, Chaudhary S (2014) An improved approach to multibiometrics security. Int J Comput Sci Commun 5(1):181–187
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: Advances in neural information processing systems 25. Curran Associates, Inc., New York, pp 1097–1105
Kumar A, Ravikant Ch (2009) Personal authentication using finger knuckle surface. IEEE Trans Inf Forensics Secur 4(1):98–109
Marchi E, Vesperini F, Eyben F, Squartini S, Schuller B (2015) A novel approach for automatic acoustic novelty detection using a denoising autoencoder with bidirectional LSTM neural networks. In: IEEE international conference on acoustics, speech, and signal processing (ICASSP’15), IEEE, Brisbane, Australia, p 5
Meraoumia A, Korichi M, Bendjenna H, Chitroub S (2016) Multispectral palmprint identification method using rotation invariant variance measures. In: IEEE international conference on information technology for organizations development (IT4OD), Fez, Morocco, pp 1–6
Meraoumia A, Laimeche L, Bendjenna H, Chitroub S (2016) Do we have to trust the deep learning methods for palmprints identification? In: Proceedings of the mediterranean conference on pattern recognition and artificial intelligence, Tebessa, Algeria, pp 85–91
Nakanishi I, Sodani Y (2010) SVM-based biometric authentication using intra-body propagation signals. In: Seventh IEEE international conference on advanced video and signal based surveillance (AVSS), pp 561–566
Oquab M, Bottou L, Laptev I, Sivic J (2014) Learning and transferring mid-level image representations using convolutional neural networks. In: Proceedings of IEEE conference of computer vision pattern recognition, pp 1717–1724
Pang S, Ban T, Kadobayashi Y, Kasabov N (2011) Personalized mode transductive spanning SVM classification tree. Inf Sci 181(11):2071–2085
Razavian AS, Azizpour H, Sullivan J (2014) CNN features off-the-shelf: an astounding baseline for recognition. In: Computer vision and pattern recognition workshops, pp 24–29
Schmidhuber J (2015) Deep learning in neural networks: an overview. Neural Netw 61:85–117
Sudhamani MJ, Venkatesha MK, Radhika KR (2012) Revisiting feature level and score level fusion techniques in multimodal biometrics system. In: Proceedings of international conference on multimedia computing and systems (ICMCS), pp 881–885
Taigman Y, Yang M, Ranzato MA, Wolf L (2014) DeepFace: closing the gap to human-level performance in face verification. In: Proceedings of the IEEE conference on computer vision and pattern recognition, Columbus, USA, pp 23–28, 1701–1708
The Hong Kong Polytechnic University (PolyU) (2018) Finger-Knuckle-Print Database. http://www.comp.polyu.edu.hk/~biometrics/FKP.htm
Tian L, Fan CX, Ming Y, Jin Y (2015) Stacked PCA network (SPCANet): an effective deep learning for face recognition. In: Proceedings of IEEE international conference digital signal processing, pp 1039–1043
Upadhayay R, Yadav RK (2013) Kernel principle component analysis in face recognition system: a survey. Int J Adv Res Comput Sci Softw Eng 3(6):348–353
Zhang D, Kong W, You J, Wong M (2003) Online palmprint identification. IEEE Trans Pattern Anal Mach Intell 25(9):10411050
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Chlaoua, R., Meraoumia, A., Aiadi, K.E. et al. Deep learning for finger-knuckle-print identification system based on PCANet and SVM classifier. Evolving Systems 10, 261–272 (2019). https://doi.org/10.1007/s12530-018-9227-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12530-018-9227-y