
Abstract
This study assessed and mapped the aboveground tree carbon stock using very high-resolution satellite imagery (VHRS)—WorldView-2 in Barkot forest of Uttarakhand, India. The image was pan-sharpened to get the spectrally and spatially good-quality image. High-pass filter technique of pan-sharpening was found to be the best in this study. Object-based image analysis (OBIA) was carried out for image segmentation and classification. Multi-resolution image segmentation yielded 74% accuracy. The segmented image was classified into sal (Shorea robusta), teak (Tectona grandis) and shadow. The classification accuracy was found to be 83%. The relationship between crown projection area (CPA) and carbon was established in the field for both sal and teak trees. Using the relationship between CPA and carbon, the classified CPA map was converted to carbon stock of individual trees. Mean value of carbon stock per tree for sal was found to be 621 kg, whereas for teak it was 703 kg per tree. The study highlighted the utility of OBIA and VHRS imagery for mapping high-resolution carbon stock of forest.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Appropriate measurement, reporting, and verification of carbon stock are vital to make climate change mitigation policy a success (Köhl et al. 2015). Traditional method (e.g. destructive sampling) of estimating forest carbon stock is costly, time-consuming and impractical in inaccessible and difficult terrain (Zhu and Liu 2015). Development of remote sensing techniques and tools has dramatically changed the inventory work (Kushwaha et al. 2014; Yadav and Nandy 2015; Dhanda et al. 2017; Nandy et al. 2019). The satellite imaging technique provides the basis for assessing volume, growing stock, biomass and carbon stocks of forests. Standard pixel-based analysis has been commonly used for this purpose (Duro et al. 2012; Manna et al. 2014; Heyojoo and Nandy 2014; Watham et al. 2016; Nandy et al. 2017; Dang et al. 2019). However, the pixel-based image analysis method uses spectral properties of the pixel and undermines the spatial characteristics of the pixel of interest (Weih and Riggan 2010). The technique is suitable for landscape-level assessment. However, it does not provide precise estimations of forest carbon stock at tree level.
The object-based image analysis (OBIA) method has been revolutionized with the advent of higher resolution imagery. The OBIA considers both the spectral and spatial properties of the pixel and supports the use of multiple bands for multi-resolution segmentation and classification. The spatial properties include scale, size, and context. These properties have made convenient to assess the biomass of individual trees from the high-resolution images and help to get a precise estimation of carbon stock (Jing et al. 2012; Pham and Brabyn 2017; Gonçalves et al. 2017). The OBIA considers several factors such as neighbourhood, context, form, and size of the object to classify an image (Blaschke 2010). Different algorithms have been developed to detect the object as accurately as possible. These algorithms are applied to detect tree crowns too. Most widely used algorithms for tree crown detection are local maxima detection, valley following, template matching, scale-space theory, Markov random fields, and marked point processes (Larsen et al. 2011). Segmentation technique has been found useful in differentiating various tree species in the forest. OBIA creates the segmentation by combining the pixel information (Baral 2011).
Various studies have demonstrated that very high-resolution satellite (VHRS) images provide cost-effective and accurate estimate of forest measurement and monitoring (Weih and Riggan 2010; Immitzer et al. 2012). With ground-based sampling and optical images, a meaningful statistical relationship can be built on forest carbon and canopy reflectance values (Eckert 2012). As VHRS images make it possible to delineate canopy projection area (CPA) of individual trees in the forest (Jing et al. 2012; Karlson et al. 2014), it can be used for building a statistical relationship with carbon. Various studies have established the relationship between CPA and diameter of the tree (Shimano 1997; Hussin et al. 2014; Singh 2014). Therefore, by devising a relationship between ground-based sampling data of carbon and CPA; carbon stock of the forest can be estimated. Various studies (Shah et al. 2011; Singh 2014; Hussin et al. 2014; Karna et al. 2015) have attempted to estimate forest carbon stock integrating VHRS images and field inventory data. The aim of the present study was to assess the feasibility of using OBIA technique with VHRS images to detect and delineate tree crowns so as to assess carbon stock of a forest by establishing a relationship between CPA and carbon.
Materials and Methods
Study Area
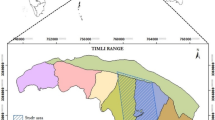
The present study was carried out in Barkot Flux Research Site (BFS) (30° 03′ 52″–30° 10′ 43″ N and 78° 09′ 49″–78° 17′ 09″ E), Uttarakhand, India (Fig. 1), one of the research sites of the AsiaFlux network (http://asiaflux.net/index.php?page_id=36). The effective study area was near the flux tower in Barkot Forest Range, as indicated in Fig. 1. The area is relatively flat and lies in the foothills of northwest Himalaya (Navalgund et al. 2019). The area is situated about 50 km away from south-east of Dehradun. The forest type present in the study area is Tropical Moist Deciduous (Champion and Seth 1968), dominated by sal (Shorea robusta) (Nandy et al. 2017). However, in the effective study area, other than sal, plantations of teak (Tectona grandis) were also present. The study area has a tropical to sub-tropical climate; the temperature ranged from 1.5 to 40.5 °C and the annual rainfall was observed to be 1250 mm during 2017 at BFS. The forests in the study area experience leaf fall from the end of February to the beginning of May (Srinet et al. 2019).

Location of the study area
Field Data Collection
Information related to individual trees such as diameter at breast height (dbh), crown diameter, species name, latitude, and longitude were collected. We collected dbh and crown diameter of the tree purposively to make sure that the entire range of the diameter is covered in the samples. Altogether 38 sample trees were measured which included 19 trees each of sal and teak (Fig. 2).

Distribution of samples on the satellite image
Satellite Data
The WorldView-2 panchromatic and multispectral satellite images of 20 March 2012 were used for this study. Panchromatic and multispectral satellite images have a spatial resolution of 0.5 m and 1.84 m, respectively. The multispectral image consists of eight bands and panchromatic image consists of one band. The details of the WorldView-2 satellite image are given in Table 1.
Methodology
This study was carried out in three stages that are pre-fieldwork on the WorldView-2 images, fieldwork, and statistical analysis. Figure 3 shows the steps that were performed to accomplish this study. Tree identification, measurement of dbh and crown diameter were performed during the field visit.

The approach used for image processing and forest aboveground carbon stock estimation
The statistical analysis was done to obtain the relationship between CPA and carbon stock. The details of the steps are presented in the following sections.
Pan-Sharpening
The pan-sharpening process involves the fusion of high-resolution panchromatic image (PI) and comparatively low-resolution multispectral (MSS) bands on a pixel basis, which enhances the spatial quality of the resulting image besides preserving the spectral properties of MSS bands. The WorldView-2 platform obtains the PI and MSS bands at the same time. The image set comprised PI with a spatial resolution of 0.5 m and eight MSS bands with 1.84 m spatial resolution. Eight different techniques were applied for pan-sharpening of the image viz., NN diffuse resolution merge, subtractive resolution merge, high-pass filter (HPF) resolution merge, resolution merge, modified intensity–hue–saturation (M-IHS) resolution merge, Ehlers fusion, wavelet resolution merge, and hyperspherical colour space (HCS) resolution merge (Fig. 4). The images generated using all the eight techniques were visually compared based on their spatial quality. The HPF resolution merge technique was found to have generated the best pan-sharpened image among all.

Images generated through pan-sharpening techniques
Image Segmentation and Accuracy Assessment
Image segmentation is the process of spatial clustering, which divides the image into non-overlapping sub-divisions called segments or object (Witharana and Lynch 2016). An object is a group of pixels having similar spectral and spatial properties. There are different types of segmentation techniques. In the present study, the multi-resolution image segmentation technique of eCognition software was used. In this technique, the pixels having identical spatial and spectral characteristics are merged to form a single bigger object (Darwish et al. 2003). The merging decisions are based on the local homogeneity criterion. The homogeneity criteria are a combination of colour (spectral values) and shape (compactness and shape). In the present study, multi-resolution segmentation was done using 19, 20 and 21 scale parameters, 0.7 as shape and 0.6 as compactness value (Fig. 5).

Segmented image
Clinton et al. (2010) developed a geometrical segmentation accuracy assessment function in terms of goodness of fit. The goodness of fit of the segmentation is measured by estimating closeness value (D). The D-value measures the “closeness” between the pre-defined polygons, the reference polygons, and the extracted polygons, the segments. Clinton et al. (2010) suggested the calculation of over-segmentation and under-segmentation to assess the overall segmentation results. As the value of D increases the deviation between the segmented object and reference object is large indicating a high mismatch between the objects. D-value of zero means perfect segmentation.
D-value (Clinton et al. 2010) is calculated as:
where \(x_{i}\) represents reference polygons and \(y_{i}\) represents segmented polygons.
In the present study, to assess the D-value, 60 tree crowns were manually digitized from the WorldView-2 image randomly. These polygons (reference polygons) were then overlaid on the segmented images created with the scale factors of 19, 20 and 21. The reference polygons were compared with the segmented polygons (Fig. 6) to calculate the D-value at different scale factors (Table 2).

Segments and manually delineated tree crowns (red colour)
The analysis indicated that for scale factor 19 the D value was the lowest which indicates that the segmentation done with scale factor 19 was the most accurate. In other words, 73% segmentation accuracy was achieved in the study. A similar observation has also been reported by Karna et al. (2015) who found the segmentation accuracy of the panchromatic image of WorldView-2 to be 67%. Singh (2014) found the image segmentation accuracy of WorldView-2 image to be 72%.
Image Classification and Accuracy Assessment
Image classification was carried out with the OBIA approach using eCognition software. Membership function classification approach was used, in which we define criteria in the membership function to limit the classification procedure (Myint et al. 2011). According to defined criteria, classification algorithms evaluate image objects and assign them to a class that best meets the criterion. Classification in eCognition assigns all objects of the image to the class specified by the user. Evaluation of the membership value of an image object against a list of selected classes is done and classification results are updated accordingly. In this study, we used normalized difference vegetation index (NDVI) value for the vegetation classification and brightness value for the shadow. Table 3 shows the classification parameters and their threshold values. The NDVI provides a measure of the amount and vigour of vegetation at the land surface. The magnitude of NDVI value indicates the level of photosynthetic activities in the vegetation (Wong et al. 2003), hence NDVI value was used to differentiate the vegetation (Justice et al. 1985). A study carried out by Bijalwan et al. (2010) found that sal mixed forest has higher NDVI values compared to teak forest. Leaf area index (LAI) for sal is more than teak during pre-monsoon season as teak trees have lesser leaves than sal (Srinet et al. 2019). NDVI value has a strong and positive functional relationship with LAI value. Hence, a higher threshold value of NDVI was used for sal than teak. The image was classified into Shorea robusta, Tectona grandis, and shadow.
Classification accuracy, in the study, was assessed in eCognition after collecting samples from all the classes. Samples for accuracy assessment were collected on the basis of field survey and visual interpretation. The overall accuracy was found to be 83% with kappa statistics of 0.77. Karna et al. (2015) obtained an overall accuracy of 73% for classifying three species using WorldView-2 imagery. Likewise, Baral (2011) observed 66.67% of overall accuracy classifying one species (Shorea robusta) using WorldView-2 Imagery. Singh (2014) found 84.82% overall accuracy for classifying four classes using Worldview-2 imagery.
Aboveground Biomass and Carbon Stock Assessment
Use of allometric equation for estimating biomass is one the most common methods of biomass estimation (Návar 2009; Wang 2006; Yoon et al. 2013). Allometric equations are regional and species-specific. However, allometric equations for estimating carbon stock for the study site are not available. Hence, in the absence of species-specific biomass equation of trees in this study, species-specific volume equations (FSI 1996) were used to estimate the aboveground biomass and carbon stock of trees. Volume of sal and teak trees were calculated using Eqs. 4 and 5:
where \(V\) = stem volume, \(D\) = diameter at breast height.
The volume was multiplied by the species-specific wood density (FRI 2002) to estimate the stem biomass of the trees (Eq. 6). The biomass of the trees were further multiplied by the conversion factor of 0.47 (IPCC 2006) to estimate carbon stock of the trees (Eq. 7):
Results and Discussion
Relationship Between CPA and dbh
In order to estimate tree carbon stock, we established the relationship between the tree attributes: dbh and CPA. CPA is detected and delineated from the VHRS image. Various other studies have also demonstrated a relationship between CPA and dbh of tree and then to carbon stock (Karna et al. 2015; Shah et al. 2011; Singh 2014). In this study also, we established the relationship between dbh and CPA for both sal and teak.
Large difference in CPA was observed between the smallest and the largest CPA of sal. The smallest and the largest CPA estimated were 8.29 m2 and 125.62 m2, respectively. The scatter diagram indicates quadratic relationship between CPA and dbh. The power regression model was developed for sal which resulted into a coefficient of determination value of 0.53 at 95% confidence level. Figure 7 shows the relationship between dbh and CPA for sal.

Relationship between dbh and CPA for sal
In case of teak also large difference was observed. The smallest CPA estimated was 23.75 m2, whereas the largest CPA was 128.61 m2. The power regression model was developed which resulted in a coefficient of determination value of 0.78 at 95% confidence level. Figure 8 shows the relationship between dbh and CPA for teak.

Relationship between dbh and CPA for teak
Regression Relationship Between CPA and Carbon Stock
Non-linear regression model was devised for assessing the relationship between CPA and carbon stock for individual sal trees. Non-linear regression was preferred over simple linear regression model on the basis of values of R2 (Baral 2011; Karna et al. 2015; Shah et al. 2011). The correlation coefficient of model obtained for CPA-carbon relationship was 0.53. Figure 9 presents the non-linear regression between CPA and carbon.

Relationship between carbon stock and CPA for sal
Equation (8) represents the equation for CPA and carbon stock of sal trees, obtained from the regression model:
Karna et al. (2015) found a very similar relation (R2 = 0.47) between CPA and biomass of sal using the high-resolution image. One possible reason for the low value of R2 is the intermingling nature of sal trees in the study site. The result of the study carried out by Shah et al. (2011) demonstrated a similar fact. They observed small value of R2 (0.25) when sal trees were found intermingled; whereas a high value of R2 (0.65) was observed when individual sal trees were clearly identified.
A Pearson’s product-moment correlation was run to assess the relationship between the calculated and predicted value of carbon stock of sal. There was a high positive correlation between the calculated and predicted value of carbon, r = 0.68, p < 0.005, with predicted carbon value explaining 48% of the variation in calculated carbon. Figure 10 depicts the relationship between predicted and calculated carbon stock of sal.

Observed and predicted carbon stock of sal
Likewise, non-linear regression model was devised for assessing the relationship between CPA and carbon stock of teak. The correlation coefficient of the model obtained for CPA-carbon relationship (Fig. 11) for teak was 0.78. The regression equation for CPA and carbon stock of teak, obtained from the model is given in Eq. (9):

Relationship between carbon stock and CPA for teak
Pearson’s product-moment correlation was run to assess the relationship between the calculated and predicted value of carbon stock. There was a high positive correlation between the calculated and predicted value of carbon, r = 0.86, p < 0.0005, with predicted carbon value explaining 74% of the variation in calculated carbon. Figure 12 demonstrated the relationship between predicted and calculated carbon stock.

The relationship between calculated and predicted carbon stock of teak
Carbon Stock
The carbon stock of sal and teak trees was estimated and mapped. Figure 13 depicts the tree carbon stock of the study site. Total carbon stock in the study area was 3.26 million kg and mean C-stock of a tree was found to be 662 kg. In general carbon stock varies from 600 to 800 kg per tree.

Carbon stock map of the study area
The OBIA analysis shows that the area occupied by sal trees (14.71 ha) is more than by teak (7.57 ha). Mean value of carbon stock per tree for sal is 621 kg, whereas the mean carbon stock per tree of teak is 703 kg (Table 4). The OBIA was found to be very effective in assessing carbon stock at the individual tree level. Many other studies have also indicated the usefulness of the OBIA technique in assessing the carbon stock (Baral 2011; Hussin et al. 2014; Singh 2014; Uddin et al. 2015).
Conclusions
Forest biomass and carbon provide means to assess sequestration of carbon and also act as an indicator of the biological and economic value of forest ecosystems. This study showed that it is possible to detect, delineate and count tree crowns, prepare high-resolution land cover maps using VHRS imagery and OBIA technique. The segmentation and classification process provided efficient result on delineation and detection of tree crowns. In this study, a significant relationship between CPA and carbon was also achieved. OBIA provided new opportunities to improve biomass and carbon stock estimation and mapping by delineating and classifying CPA of individual trees.
References
Baral, S. (2011). Mapping carbon stock using high resolution satellite images in sub-tropical forest of Nepal. University of Twente Faculty of Geo-Information and Earth Observation (ITC).
Bijalwan, A., Swamy, S. L., Sharma, C. M., Sharma, N. K., & Tiwari, A. K. (2010). Land-use, biomass and carbon estimation in dry tropical forest of Chhattisgarh region in India using satellite remote sensing and GIS. Journal of Forestry Research,21(2), 161–170.
Blaschke, T. (2010). Object based image analysis for remote sensing. ISPRS Journal of Photogrammetry and Remote Sensing,65(1), 2–16.
Champion, H. G., & Seth, S. K. (1968). A revised survey of the forest types of India. New Delhi: Manager of Publications, Govt. of India.
Clinton, N., Holt, A., Scarborough, J., Yan, L. I., & Gong, P. (2010). Accuracy assessment measures for object-based image segmentation goodness. Photogrammetry Engineering and Remote Sensing,76(3), 289–299.
Dang, A. T. N., Nandy, S., Srinet, R., Luong, N. V., Ghosh, S., & Kumar, A. S. (2019). Forest aboveground biomass estimation using machine learning regression algorithm in Yok Don National Park, Vietnam. Ecological Informatics,50, 24–32.
Darwish, A., Leukert, K., & Reinhardt, W. (2003). Image segmentation for the purpose of object-based classification. In IGARSS 2003. 2003 IEEE International Geoscience and Remote Sensing Symposium. Proceedings (IEEE Cat. No. 03CH37477) (Vol. 3, pp. 2039–2041). IEEE.
Dhanda, P., Nandy, S., Kushwaha, S. P. S., Ghosh, S., Murthy, Y. K., & Dadhwal, V. K. (2017). Optimizing spaceborne LiDAR and very high resolution optical sensor parameters for biomass estimation at ICESat/GLAS footprint level using regression algorithms. Progress in Physical Geography,41(3), 247–267.
Duro, D. C., Franklin, S. E., & Dubé, M. G. (2012). A comparison of pixel-based and object-based image analysis with selected machine learning algorithms for the classification of agricultural landscapes using SPOT-5 HRG imagery. Remote Sensing of Environment,118, 259–272.
Eckert, S. (2012). Improved forest biomass and carbon estimations using texture measures from WorldView-2 satellite data. Remote Sensing,4(4), 810–829.
FRI. (2002). Indian woods: Their identification, properties and uses, Vol. I–VI (Revised Edition). Dehradun: Forest Research Institute, Indian Council of Forestry Research and Education, Ministry of Environment and Forests, Government of India.
FSI. (1996). Volume equations for Forests of India, Nepal and Bhutan. Dehradun: Forest Survey of India, Ministry of Environment and Forests, Government of India.
Gonçalves, A. C., Sousa, A. M., & Mesquita, P. G. (2017). Estimation and dynamics of above ground biomass with very high resolution satellite images in Pinus pinaster stands. Biomass and Bioenergy,106, 146–154.
Heyojoo, B. P., & Nandy, S. (2014). Estimation of above-ground phytomass and carbon in tree resources outside the forest (TROF): A geo-spatial approach. Banko Janakari,24(1), 34–40.
Hussin, Y. A., Gilani, H., van Leeuwen, L., Murthy, M. S. R., Shah, R., Baral, S., et al. (2014). Evaluation of object-based image analysis techniques on very high-resolution satellite image for biomass estimation in a watershed of hilly forest of Nepal. Applied Geomatics,6(1), 59–68.
Immitzer, M., Atzberger, C., & Koukal, T. (2012). Tree species classification with random forest using very high spatial resolution 8-band WorldView-2 satellite data. Remote Sensing,4(9), 2661–2693.
IPCC. (2006). 2006 IPCC guidelines for national greenhouse gas inventories. https://www.ipcc-nggip.iges.or.jp/public/2006gl/index.html.
Jing, L., Hu, B., Noland, T., & Li, J. (2012). An individual tree crown delineation method based on multi-scale segmentation of imagery. ISPRS Journal of Photogrammetry and Remote Sensing,70, 88–98.
Justice, C. O., Townshend, J. R. G., Holben, B. N., & Tucker, E. C. (1985). Analysis of the phenology of global vegetation using meteorological satellite data. International Journal of Remote Sensing,6(8), 1271–1318.
Karlson, M., Reese, H., & Ostwald, M. (2014). Tree crown mapping in managed woodlands (parklands) of semi-arid West Africa using WorldView-2 imagery and geographic object based image analysis. Sensors,14(12), 22643–22669.
Karna, Y. K., Hussin, Y. A., Gilani, H., Bronsveld, M. C., Murthy, M. S. R., Qamer, F. M., et al. (2015). Integration of WorldView-2 and airborne LiDAR data for tree species level carbon stock mapping in Kayar Khola watershed, Nepal. International Journal of Applied Earth Observation and Geoinformation,38, 280–291.
Köhl, M., Lasco, R., Cifuentes, M., Jonsson, Ö., Korhonen, K. T., Mundhenk, P., et al. (2015). Changes in forest production, biomass and carbon: Results from the 2015 UN FAO Global Forest Resource Assessment. Forest Ecology and Management,352, 21–34.
Kushwaha, S. P. S., Nandy, S., & Gupta, M. (2014). Growing stock and woody biomass assessment in Asola-Bhatti Wildlife Sanctuary, Delhi, India. Environmental Monitoring and Assessment,186(9), 5911–5920.
Larsen, M., Eriksson, M., Descombes, X., Perrin, G., Brandtberg, T., & Gougeon, F. A. (2011). Comparison of six individual tree crown detection algorithms evaluated under varying forest conditions. International Journal of Remote Sensing,32(20), 5827–5852.
Manna, S., Nandy, S., Chanda, A., Akhand, A., Hazra, S., & Dadhwal, V. K. (2014). Estimating aboveground biomass in Avicennia marina plantation in Indian Sundarbans using high-resolution satellite data. Journal of Applied Remote Sensing,8(1), 083638.
Myint, S. W., Gober, P., Brazel, A., Grossman-Clarke, S., & Weng, Q. (2011). Per-pixel vs. object-based classification of urban land cover extraction using high spatial resolution imagery. Remote Sensing of Environment,115(5), 1145–1161.
Nandy, S., Ghosh, S., Kushwaha, S. P. S., & Kumar, A. S. (2019). Remote sensing-based forest biomass assessment in northwest Himalayan landscape. In R. R. Navalgund, A. Senthil Kumar, & S. Nandy (Eds.), Remote sensing of Northwest Himalayan Ecosystems (pp. 285–311). Singapore: Springer.
Nandy, S., Singh, R., Ghosh, S., Watham, T., Kushwaha, S. P. S., Kumar, A. S., et al. (2017). Neural network-based modelling for forest biomass assessment. Carbon Management,8(4), 305–317.
Navalgund, R. R., Kumar, A. S., & Nandy, S. (2019). Remote sensing of Northwest Himalayan Ecosystems. Singapore: Springer.
Navar, J. (2009). Allometric equations for tree species and carbon stocks for forests of northwestern Mexico. Forest Ecology and Management,257(2), 427–434.
Pham, L. T., & Brabyn, L. (2017). Monitoring mangrove biomass change in Vietnam using SPOT images and an object-based approach combined with machine learning algorithms. ISPRS Journal of Photogrammetry and Remote Sensing,128, 86–97.
Shah, S. K., Hussin, Y. A., van Leeuwen, L., & Gilani, H. (2011). Modelling the relationship between tree canopy projection area and above ground carbon stock using high resolution geoeye satellite images. In: 32nd Asian conference on remote sensing, ACRS 2011: Sensing for Green Asia. National Sun Yat-sen University Press.
Shimano, K. (1997). Analysis of the relationship between DBH and crown projection area using a new model. Journal of Forest Research,2(4), 237–242.
Singh, N. (2014). Impact of infestation of sal heartwood Borer (Hoplocerambyx Spinicornis) on the carbon stock of sal (Shorea Robusta) forests of Doon Valley. University of Twente Faculty of Geo-Information and Earth Observation (ITC).
Srinet, R., Nandy, S., & Patel, N. R. (2019). Estimating leaf area index and light extinction coefficient using Random Forest regression algorithm in a tropical moist deciduous forest, India. Ecological Informatics,52, 94–102.
Uddin, K., Gilani, H., Murthy, M. S. R., Kotru, R., & Qamer, F. M. (2015). Forest condition monitoring using very-high-resolution satellite imagery in a remote mountain watershed in Nepal. Mountain Research and Development,35(3), 264–278.
Wang, C. (2006). Biomass allometric equations for 10 co-occurring tree species in Chinese temperate forests. Forest Ecology and Management,222(1–3), 9–16.
Watham, T., Kushwaha, S. P. S., Nandy, S., Patel, N. R., & Ghosh, S. (2016). Forest carbon stock assessment at Barkot Flux tower Site (BFS) using field inventory, Landsat-8 OLI data and geostatistical techniques. International Journal of Multidisciplinary Research and Development,3(5), 111–119.
Weih, R. C., & Riggan, N. D. (2010). Object-based classification vs. pixel-based classification: Comparative importance of multi-resolution imagery. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences,38(4), C7.
Witharana, C., & Lynch, H. (2016). An object-based image analysis approach for detecting penguin guano in very high spatial resolution satellite images. Remote Sensing,8(5), 375.
Wong, T. H., Mansor, S. B., Mispan, M. R., Ahmad, N., & Sulaiman, W. N. A. (2003). Feature extraction based on object oriented analysis. In Proceedings of ATC 2003 conference (Vol. 2021).
Yadav, B. K. V., & Nandy, S. (2015). Mapping aboveground woody biomass using forest inventory, remote sensing and geostatistical techniques. Environmental Monitoring and Assessment,187(5), 308.
Yoon, T. K., Park, C. W., Lee, S. J., Ko, S., Kim, K. N., Son, Y., et al. (2013). Allometric equations for estimating the aboveground volume of five common urban street tree species in Daegu, Korea. Urban Forestry & Urban Greening,12(3), 344–349.
Zhu, X., & Liu, D. (2015). Improving forest aboveground biomass estimation using seasonal Landsat NDVI time-series. ISPRS Journal of Photogrammetry and Remote Sensing,102, 222–231.
Acknowledgements
The authors are thankful to the Director, Indian Institute of Remote Sensing, Dehradun, and Centre for Space Science and Technology Education in Asia and the Pacific (CSSEATP), Dehradun, for his support during the study. The authors wish to acknowledge Divisional Forest Officer, Dehradun Forest Division and staff of Barkot Forest Range, Dehradun Forest Division, Government of Uttarakhand, India, and field staff of Barkot Flux Research Site for field support. Thanks are also due to the anonymous reviewers for a critical review of the manuscript.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
About this article

Cite this article
Pandey, S.K., Chand, N., Nandy, S. et al. High-Resolution Mapping of Forest Carbon Stock Using Object-Based Image Analysis (OBIA) Technique. J Indian Soc Remote Sens 48, 865–875 (2020). https://doi.org/10.1007/s12524-020-01121-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12524-020-01121-8